前言
最近發現有挺多人喜歡徑向基函式(Radial Basis Function,RBF)神經網路,其實它就是將RBF作為神經網路層間的一種連接方式而已,這里做一個簡單的描述和找了個代碼解讀,
之前也寫過一篇,不過排版不好看,可以戳這里跳轉
國際慣例,參考博客:
-
維基百科徑向基函式
-
《模式識別與智能計算——matlab技術實作第三版》第6.3章節
-
《matlab神經網路43個案例分析》第7章節
-
tensorflow2.0實作RBF
-
numpy的實作
理論
基本思想
用RBF作為隱單元的“基”構成隱藏層空間,隱藏層對輸入矢量進行變換,將低維的模式輸入資料變換到高維空間內,使得在低維空間內的線性不可分問題在高維空間內線性可分,
詳細一點就是用RBF的隱單元的“基”構成隱藏層空間,這樣就可以將輸入矢量直接(不通過權連接)映射到隱空間,當RBF的中心點確定以后,這種映射關系也就確定 了,而隱含層空間到輸出空間的映射是線性的(注意這個地方區分一下線性映射和非線性映射的關系),即網路輸出是隱單元輸出的線性加權和,此處的權即為網路可調引數,
徑向基神經網路的節點激活函式采用徑向基函式,定義了空間中任一點到某一中心點的歐式距離的單調函式,
我們通常使用的函式是高斯函式:
?
(
r
)
=
e
?
(
?
r
)
2
\phi(r) = e^{-(\epsilon r)^2}
?(r)=e?(?r)2
在《Phase-Functioned Neural Networks for Character Control》論文代碼中有提到很多徑向基函式:
kernels = {
'multiquadric': lambda x: np.sqrt(x**2 + 1),
'inverse': lambda x: 1.0 / np.sqrt(x**2 + 1),
'gaussian': lambda x: np.exp(-x**2),
'linear': lambda x: x,
'quadric': lambda x: x**2,
'cubic': lambda x: x**3,
'quartic': lambda x: x**4,
'quintic': lambda x: x**5,
'thin_plate': lambda x: x**2 * np.log(x + 1e-10),
'logistic': lambda x: 1.0 / (1.0 + np.exp(-np.clip(x, -5, 5))),
'smoothstep': lambda x: ((np.clip(1.0 - x, 0.0, 1.0))**2.0) * (3 - 2*(np.clip(1.0 - x, 0.0, 1.0)))
}
下圖是徑向基神經元模型
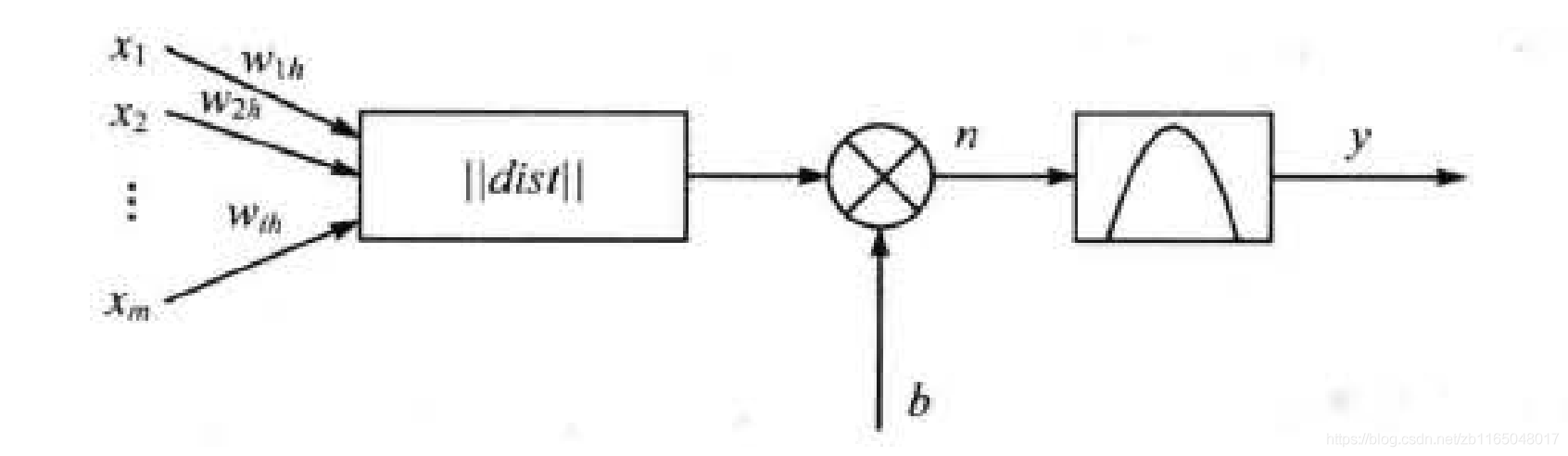
徑向基函式的激活函式是以輸入向量和權值向量(注意此處的權值向量并非隱藏層到輸出層的權值,具體看下面的徑向基神經元模型結構)之間的距離||dist||作為自變數的,圖中的b為閾值,用于調整神經元的靈敏度,徑向基網路的激活函式的一般運算式為
R
(
∥
d
i
s
t
∥
)
=
e
?
∥
d
i
s
t
∥
R(\parallel dist \parallel) = e^{-\parallel dist \parallel}
R(∥dist∥)=e?∥dist∥
下圖是以高斯核為徑向基函式的神經元模型:
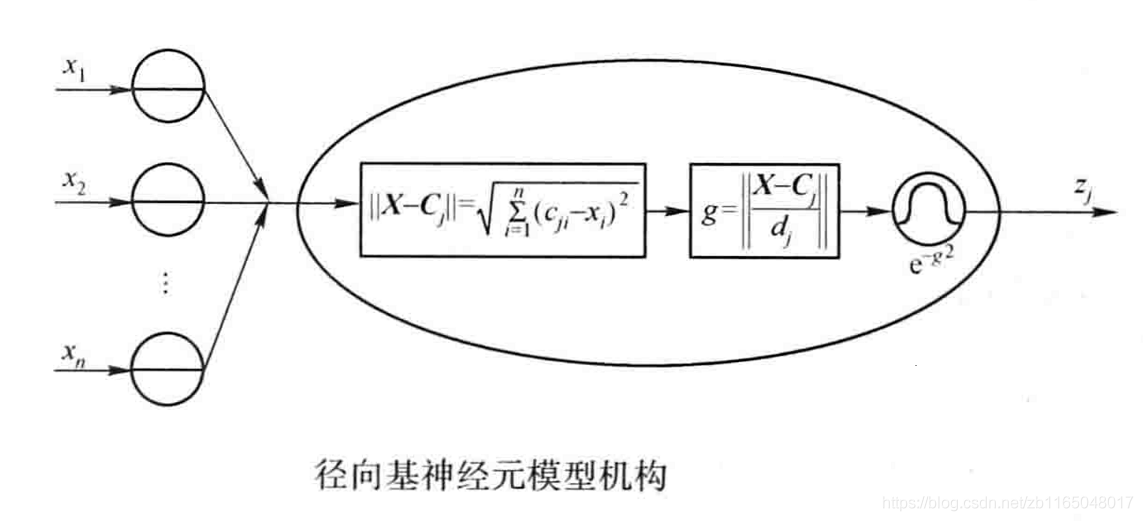
對應到激活函式運算式:
R
(
x
p
?
c
i
)
=
exp
?
(
?
1
2
σ
2
∥
x
p
?
c
i
∥
2
)
R(x_p-c_i)=\exp{\left(-\frac{1}{2\sigma^2}\parallel x_p - c_i \parallel^2 \right)}
R(xp??ci?)=exp(?2σ21?∥xp??ci?∥2)
其中X代表輸入向量,C代表權值,為高斯函式的中心,
σ
\sigma
σ是高斯函式的方差,可以用來調整影響半徑(仔細想想高斯函式中
c
c
c和
σ
\sigma
σ調整后對函式圖的影響);當權值和輸入向量的距離越小,網路的輸出不斷遞增,輸入向量越靠近徑向基函式的中心,隱層節點產生的輸出越大,也就是說徑向基函式對輸入信號在區域產生回應,輸入向量與權值距離越遠,隱層輸出越接近0,再經過一層線性變換映射到最終輸出層,導致輸出層也接近0,
結構
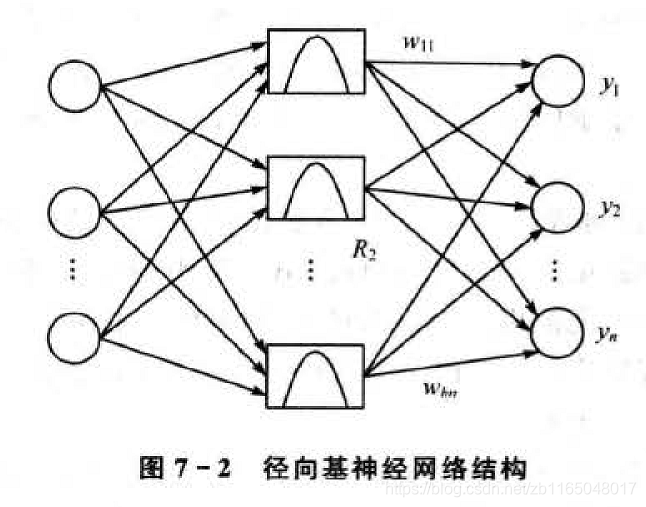
RBF是具有單隱層的三層前向網路,
-
第一層為輸入層,由信號源節點組成,
-
第二層為隱藏層,隱藏層節點數視所描述問題的需要而定,隱藏層中神經元的變換函式即徑向基函式是對中心點徑向對稱且衰減的非負線性函式,該函式是區域回應函式,具體的區域回應體現在其可見層到隱藏層的變換是通過徑向基函式計算,跟其它的網路不同,以前的前向網路變換函式都是全域回應的函式,
-
第三層為輸出層,是對輸入模式做出的回應,
輸入層僅僅起到傳輸信號作用,輸入層和隱含層之間可以看做連接權值為1的連接,輸出層與隱含層所完成的任務是不同的,因而他們的學習策略也不同,輸出層是對線性權進行調整,采用的是線性優化策略,因而學習速度較快;而隱含層是對激活函式(格林函式,高斯函式,一般取后者)的引數進行調整,采用的是非線性優化策略,因而學習速度較慢,
引數
徑向基函式需要兩組引數:
- 基函式中心
- 方差(寬度)
隱層到輸出層只需要一組引數:
- 權值
優點
- 逼近能力,分類能力和學習速度等方面都優于BP神經網路
- 結構簡單、訓練簡潔、學習收斂速度快、能夠逼近任意非線性函式
- 克服區域極小值問題,原因在于其引數初始化具有一定的方法,并非隨機初始化,
缺點
- 如果中心點是樣本中的資料,就并不能反映出真實樣本的狀況,那么輸入到隱層的映射就是不準確的
- 如果使用有監督學習,函式中心是學習到的,但是如果中心點選取不當,就會導致不收斂,
各層的計算
首先初始化引數:中心、寬度、權值
不同隱含層神經元的中心應有不同的取值,并且與中心的對應寬度能夠調節,使得不同的輸入資訊特征能被不同的隱含層神經元最大的反映出來,在實際應用時,一個輸入資訊總是包含在一定的取值范圍內,
中心
-
方法1
《模式識別與智能計算》中介紹了一種方法:將隱含層各神經元的中心分量的初值,按從小到大等間距變化,使較弱的輸入資訊在較小的中心附近產生較強的回應,間距的大小可由隱藏層神經元的個數來調節,好處是能夠通過試湊的方法找到較為合理的隱含層神經元數,并使中心的初始化盡量合理,不同的輸入特征更為明顯地在不同的中心處反映出來,體現高斯核的特點:
c j i = min ? i + max ? i ? min ? i 2 p + ( j ? 1 ) max ? i ? min ? i p c_{ji} = \min i + \frac{\max i-\min i}{2p}+(j-1)\frac{\max i-\min i}{p} cji?=mini+2pmaxi?mini?+(j?1)pmaxi?mini?
其中p為隱層神經元總個數,j為隱層神經元索引,i為輸入神經元索引, max ? i \max i maxi是訓練集中第i個特征所有輸入資訊的最小值,$\max i $為訓練集中第i個特征所有輸入資訊的最大值, -
方法2
《43案例分析》中介紹的是Kmean使用方法,就是傳統的演算法,先隨機選k個樣本作為中心,然后按照歐氏距離對每個樣本分組,再重新確定聚類中心,再不斷重復上面的步驟,直到最終聚類中心變化在一定范圍內,
寬度
寬度向量影響著神經元對輸入資訊的作用范圍:寬度越小,相應隱含層神經元作用函式的形狀越窄,那么處于其他神經元中心附近的資訊在該神經元出的回應就越小;就跟高斯函式影像兩邊的上升下降區域的寬度一樣,按照《模式識別與智能計算》,計算有點像標準差的計算(但是此處原文沒有帶平方,不過我覺得應該帶上,詳細可以查閱這個YouTube視頻,不帶平方,萬一出現負數是無法求根的):
d
j
i
=
d
f
1
N
∑
k
=
1
N
(
x
i
k
?
c
j
i
)
2
d_{ji}= d_f\sqrt{\frac{1}{N}\sum_{k=1}^N(x_i^k-c_{ji})^2}
dji?=df?N1?k=1∑N?(xik??cji?)2
?
當然也可以用《43案例分析》里面說的,利用中心之間的最大距離
c
m
a
x
c_{max}
cmax?去計算,其中h是聚類中心個數:
d
=
c
m
a
x
2
h
d = \frac{c_{max}}{\sqrt{2h}}
d=2h
?cmax??
輸入層到隱層的計算
直接套入到選擇的徑向基函式中:
z
j
=
exp
?
(
?
∣
∣
X
?
C
j
D
j
∣
∣
2
)
z_j = \exp\left(- \left|\left|\frac{X-C_j}{D_j} \right|\right|^2\right)
zj?=exp(?∣∣∣∣?∣∣∣∣?Dj?X?Cj??∣∣∣∣?∣∣∣∣?2)
其中
C
j
C_j
Cj?就是第j個隱層神經元對應的中心向量,由隱層第j個神經元所連接的輸入層所有神經元的中心分量構成,即
C
j
=
[
C
j
1
,
C
j
2
,
?
?
,
C
j
n
]
C_j = [C_{j1},C_{j2},\cdots,C_{jn}]
Cj?=[Cj1?,Cj2?,?,Cjn?];
D
j
D_j
Dj?為隱層第j個神經元的寬度向量,與
C
j
C_j
Cj?對應,
D
j
D_j
Dj?越大,隱層對輸入向量的影響范圍就越大,而且神經元間的平滑程度就更好,
隱層到輸出層的計算
就是傳統的神經網路里面,把核函式去掉,變成了線性映射關系:
y
k
=
∑
j
=
1
p
w
k
j
z
j
y_k = \sum_{j=1}^p w_{kj}z_j
yk?=j=1∑p?wkj?zj?
其中k是輸出層神經元個數,
權重迭代
直接使用梯度下降法訓練,中心、寬度、權重都通過學習來自適應調節更新,
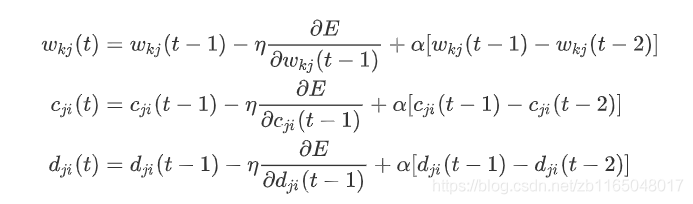
其中 η \eta η為學習率, E E E為損失函式,一般就是均方差,
訓練步驟
- 先初始化中心、寬度、最后一層權重
- 計算損失,如果在接受范圍內,停止訓練
- 利用梯度更新的方法更新中心、寬度、權重
- 回傳第二步
代碼實作
有大佬利用keras實作過基于Kmeans的高斯RBF神經網路層,代碼戳這里
首先利用sklearn里面的庫構建一個K-means層
from keras.initializers import Initializer
from sklearn.cluster import KMeans
class InitCentersKMeans(Initializer):
""" Initializer for initialization of centers of RBF network
by clustering the given data set.
# Arguments
X: matrix, dataset
"""
def __init__(self, X, max_iter=100):
self.X = X
self.max_iter = max_iter
def __call__(self, shape, dtype=None):
assert shape[1] == self.X.shape[1]
n_centers = shape[0]
km = KMeans(n_clusters=n_centers, max_iter=self.max_iter, verbose=0)
km.fit(self.X)
return km.cluster_centers_
構建RBF層的時候,第一層初始化使用上面的Kmeans初始化
self.centers = self.add_weight(name='centers',
shape=(self.output_dim, input_shape[1]),
initializer=self.initializer,
trainable=True)
第二層用一個線性加權的層
self.betas = self.add_weight(name='betas',
shape=(self.output_dim,),
initializer=Constant(
value=self.init_betas),
# initializer='ones',
trainable=True)
計算時候:
def call(self, x):
C = K.expand_dims(self.centers)
H = K.transpose(C-K.transpose(x))
return K.exp(-self.betas * K.sum(H**2, axis=1))
但是此處我覺得有問題,這里的寬度向量好像沒有體現出來,所以我重寫了一個:
def call(self, x):
C = K.expand_dims(self.centers)
XC = K.transpose(K.transpose(x)-C)
D = K.expand_dims(K.sqrt(K.mean(XC**2,axis=0)),0)
H = XC/D
return K.exp(-self.betas * K.sum(H**2, axis=1))
可以看原作者的代碼,作者是用于二維資料的擬合;
也可以看我的代碼,基于原作者代碼,做的二維資料分類
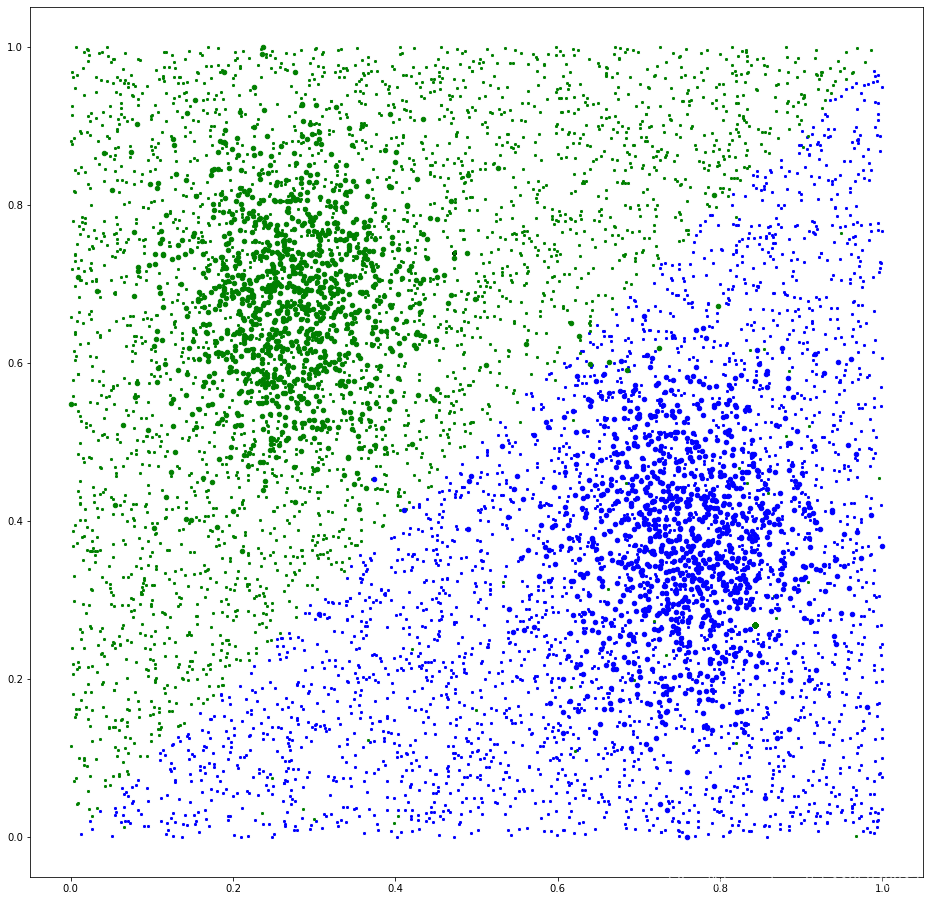
小點為訓練集,大圓點為測驗集
后記
RBF可以用于插值、分類;在論文《Phase-Functioned Neural Networks for Character Control》還用來更改地形,也就是說圖形、影像通用,說明還是蠻重要的,這里主要介紹了一下理論,后續再去做擴展性研究,
完整的python腳本實作放在微信公眾號的簡介中描述的github中,有興趣可以去找找,同時文章也同步到微信公眾號中,有疑問或者興趣歡迎公眾號私信,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/233092.html
標籤:AI