機器學習(Machine Learning)
百度搜索 : 機器學習涉及概率論、統計學、逼近論、凸分析、演算法復雜度理論多門學科,研究計算機怎樣模擬、實作人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能 . 是人工智能的核心,使計算機具有智能的根本途徑,應用遍及人工智能的各個領域,主要使用歸納、綜合 .
什么是建模
建模是指利用模型學習已知結果的資料集中的變數特征,通過一系列方法提高模型的學習能力,最終對一些結果未知的資料集輸出相應的結果.
可以表達成 y=f(x) 其中x代表樣本的特征, y是輸出的結果
機器學習方法
監督學習Supervised learning
監督學習兩大問題: 分類classification、 回歸regression
監督常見模型:
- 最近鄰( KNN ): 適用于小型資料集 , 是很好的基準模型 , 容易解釋 .
- 線性模型( Linear Regression ): 非常可靠的首選演算法 , 適用于非常大的資料集 , 也適用于高維資料.
- 樸素貝葉斯( Naive Bayes ): 只適用于分類問題 , 比線性模型速度還快 , 適用于非常大的資料集和高維資料 , 精度通常要低于線性模型.
- 決策樹( Decision Tree ): 速度很快 , 不需要資料縮放 , 可以可視化 , 很容易解釋 .
- 隨機森林( Random Forest ): 幾乎比單棵決策樹的表現要好 , 魯棒性很好 , 非常強大 , 不需要資料縮放 , 不適用于高維稀疏資料.
- 梯度提升決策樹: 精度通常比隨機森林略高. 與隨機森林相比 , 訓練速度更慢 , 但預測速度更快 , 需要的記憶體也更少 . 比隨機森林需要更多的引數調節 .
- 支持向量機( SVM ): 對于特征含義相似的中等大小的資料集很強大 , 需要資料縮放 , 對引數敏感 .
- 神經網路 : 可以構建非常復雜的模型 , 特別是對于大型資料集而言 , 對資料縮放敏感 , 對引數選取敏感 , 大型網路需要很長的訓練時間 .
每個模型都有自己的優缺點, 復雜度也不一樣, 設定正確的引數對于性能至關重要.輸入資料的方式也很敏感,尤其是特征的縮放.
無監督學習unsupervised learning
無監督學習: 資料集只給特征,不給標簽,不需要人為標注給出語料答案.
無監督學習包括沒有已知輸出、沒有知道學習演算法的各類機器學習, 無監督學習中只有輸入資料, 需要從這些資料中自己學習挖掘資訊.
兩種型別的無監督學習:資料集變換與聚類
經典的演算法:k-聚類、主成分分析
半監督學習semi supervised learning
半監督學習介于監督學習和無監督學習兩者之間,已知資料和部分資料對應標簽,有一部分資料無標簽.
模型學習已知標簽和未知標簽的資料 , 將輸入資料映射到標簽的程序 .
強化學習reinforcement learning
強化學習是一種學習模型 , 它不會直接給你解決方案 , 需要通過試錯的方式去尋找 , AlphaGo就是用的強化學習 .
資料集分類
訓練集、驗證集、測驗集
訓練集: 結果已知,用于模型訓練擬合的資料樣本, 占總體的70%~80%
驗證集:結果已知,不參與模型訓練的擬合程序, 用于驗證已經訓練過的模型效果.同時對模型中的超引數進行選擇
測驗集:結果未知,測驗機器訓練結果的準確性,或是利用模型輸出結果的資料集
測驗機與訓練集最好獨立分割,不可重復使用.
模型在真實資料上預測的結果誤差越小越好,模型在真實環境中的誤差叫做泛化誤差,最終的目的是希望訓練好的模型泛化誤差越低越好,
評價指標TP/FP/FN/TN
- True positive(TP): 真正例,將正例正確預測為正例數;
- False positive(FP): 假正例,將負例錯誤預測為正例數;
- False negative(FN):假負例,將正例錯誤預測為負例數;
- True negative(TN): 真負例,將負例正確預測為負例數,
P/N代表預測值,如預測值與真實值一樣,則是真x例,反之是假x例,
文字模型、圖片模型、策略分析
文字模型:用于機器檢測語料中的命中目標: 大多是文字、陳述句、關鍵詞,多應用于對文字語料爬取資訊等進行風險識別、黑詞識別等
圖片模型:用于機器檢測圖片中的命中目標: 也可對藝術字,變體字進行識別,或識別對圖片中的敏感標志、人物、政治宗教、風險物品進行捕捉、定位、識別
策略分析:在明確策略應用場景, 通過驗證策略命中資料是否正確,分析策略誤殺資料的特征.給出優化方案
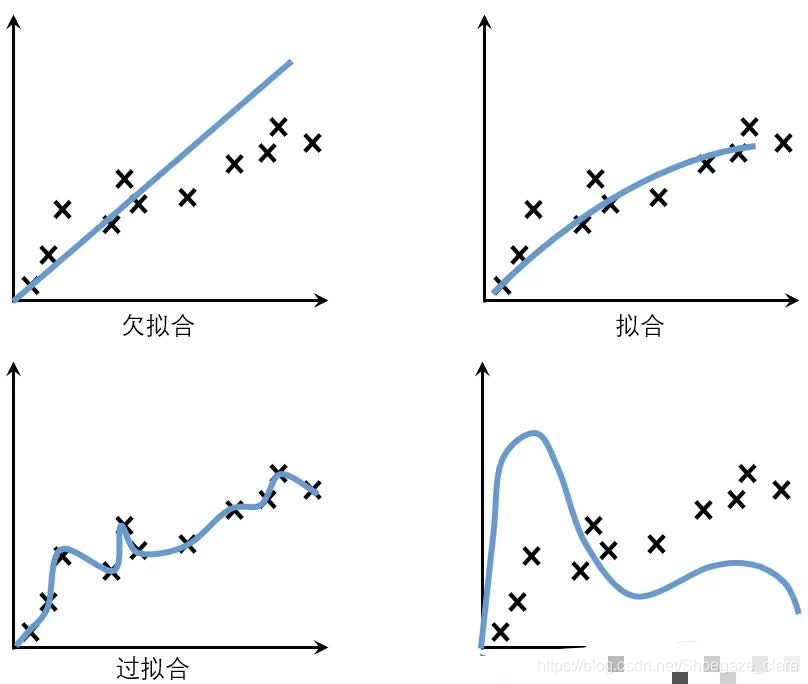
模型的泛化與擬合
泛化: 指機器學習演算法對新鮮樣本的適應能力, 學習目的是學到隱含在資料背后的規律,對具有同一規律的測驗集以外的資料,經過訓練也能給出合適的輸出,該能力稱為泛化能力,
即 : 經訓練樣本訓練的模型需要對新樣本做出合適的預測,這是泛化能力的體現
把模型訓練的程序比作人類學習程序
欠擬合:泛化能力弱,新題老題不會做
過擬合:泛化能力弱,遇到新題就懵逼
不收斂:新題舊題全靠猜
擬 合:學霸,新題舊題大概率都可做出來
模型的準確率、召回率、正確率
(二分類問題中的重要指標,其中語料同樣本)
模型準確率:機器分類正確的正例樣本 占 分類為正例樣本總數中的比例
分類為正例樣本包括 : 真正例TP + 假正例FP(將負例判斷成正例)
precision = TP/(TP+FP)
模型召回率:機器分類正確的正例樣本 占 真正正例樣本總數的比例
真正正例樣本總數包括: 真正例TP+ 假負例(將正類錯誤判斷為負類數)
Recall = TP/(TP+FN)
模型正確率:指機器分類判斷正確的數量
accuracy = TP+TN / (TP+FN+FP+TN)
模型衰減與模型迭代
模型衰減:如隨著時間的推移和線上素材的復雜性和多樣性,機器訓練模型的準確性會慢慢衰減. 其他應用場景暫不涉及
模型迭代:為了避免模型衰減帶來應用效果結果不準確,通過定期的語料樣本迭代,優化機器模型,保證模型應用效果
以上持續更新中
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234230.html
標籤:其他
上一篇:Linux命令總結