上篇文章我們在服務器上部署了Hive并將它的Metastore存盤在了MySQL上,本文介紹一下Hive的資料型別以及常用的一些屬性配置,關注專欄《破繭成蝶——大資料篇》,查看更多相關的內容~
目錄
一、Hive的資料型別
1.1 基本資料型別
1.2 集合資料型別
1.2.1 介紹
1.2.2 示例
1.3 資料型別轉換
二、常用的屬性配置
2.1 HiveServer2服務
2.2 Hive的互動命令
2.3 Hive的其他命令
2.4 常用的屬性配置
2.4.1 查詢顯示表頭資訊
2.4.2 顯示當前資料庫名稱
2.4.3 配置Hive資料倉庫位置
2.4.4 配置Hive運行日志資訊存放位置
2.4.5 引數配置的優先級
一、Hive的資料型別
1.1 基本資料型別
Hive的基本資料型別有10種,如下所示:
| Hive資料型別 | 對應的Java資料型別 | 長度 |
| TINYINT | byte | 1byte有符號整數 |
| SMALINT | short | 2byte有符號整數 |
| INT | int | 4byte有符號整數 |
| BIGINT | long | 8byte有符號整數 |
| BOOLEAN | boolean | 布爾型別,true或者false |
| FLOAT | float | 單精度浮點數 |
| DOUBLE | double | 雙精度浮點數 |
| STRING | string | 字符系列,可以指定字符集,可以使用單引號或者雙引號,相當于資料庫的varchar型別 |
| TIMESTAMP |
| 時間型別 |
| BINARY |
| 位元組陣列 |
1.2 集合資料型別
1.2.1 介紹
| 資料型別 | 描述 | 語法示例 |
| STRUCT | 通過“點”符號訪問元素內容,例如,如果某個列的資料型別是STRUCT{one STRING, two STRING},那么第1個元素可以通過欄位.one來參考, | struct() 例如struct<person:string, city:string> |
| MAP | MAP是一組鍵-值對元組集合,使用陣串列示法可以訪問資料,例如,如果某個列的資料型別是MAP,其中鍵->值對是’one’->’xzw’和’two’->’yxy’,那么可以通過欄位名[‘two’]獲取最后一個元素 | map() 例如map<string, int> |
| ARRAY | 陣列是一組具有相同型別和名稱的變數的集合,這些變數稱為陣列的元素,每個陣列元素都有一個編號,編號從零開始,例如,陣列值為[‘one’, ‘two’],那么第2個元素可以通過陣列名[1]進行參考, | Array() 例如array<string> |
Hive有三種復雜資料型別STRUCT、ARRAY和MAP,STRUCT與C語言中的Struct類似,它封裝了一個命名欄位集合,ARRAY和MAP與Java中的Array和Map類似,復雜資料型別允許任意層次的嵌套,
1.2.2 示例
1、現有如下的資料
[{
"name": "xzw",
"loc": ["qd" , "zb"],
"city": {
"ta": 4,
"qd": 3
}
"subject": {
"dm": "Python" ,
"reg": "bigdata"
}
},
{
"name": "yxy",
"loc": ["bj" , "sh"],
"city": {
"bj": 1,
"sh": 3
}
"subject": {
"dm": "Java" ,
"reg": "AI"
}
}]2、首先我們需要構造一下匯入Hive中的資料檔案,資料檔案如下所示:
xzw,qd|zb,ta:4|qd:3,Python|bigdata
yxy,bj|sh,bj:1|sh:3,Java|AI值得注意的是,MAP,STRUCT和ARRAY里的元素間關系都可以用同一個字符表示,這里用“|”,構造好的test.txt檔案放到/root/files目錄下,
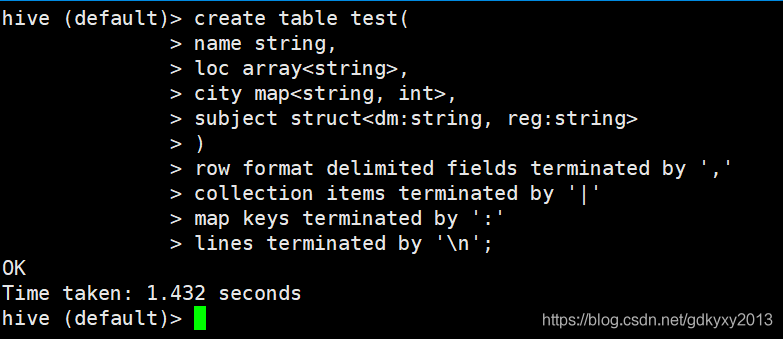
3、創建Hive表
create table test(
name string,
loc array<string>,
city map<string, int>,
subject struct<dm:string, reg:string>
)
row format delimited fields terminated by ','
collection items terminated by '|'
map keys terminated by ':'
lines terminated by '\n';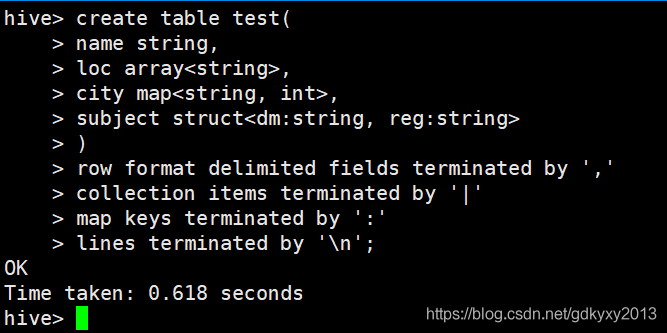
4、加載資料到Hive表中
load data local inpath '/root/files/test.txt' into table test;
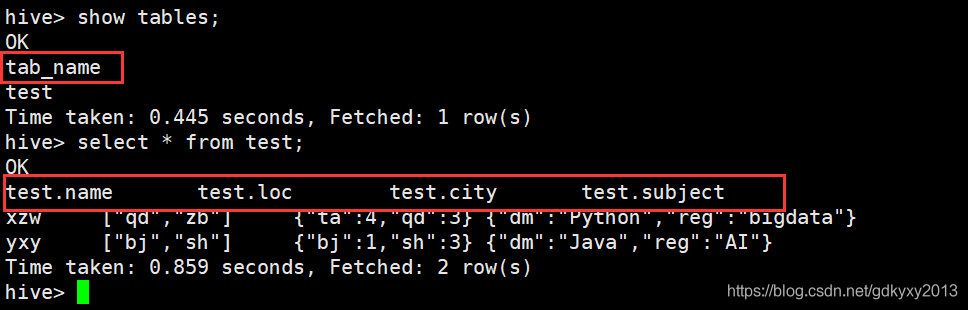
5、查詢測驗
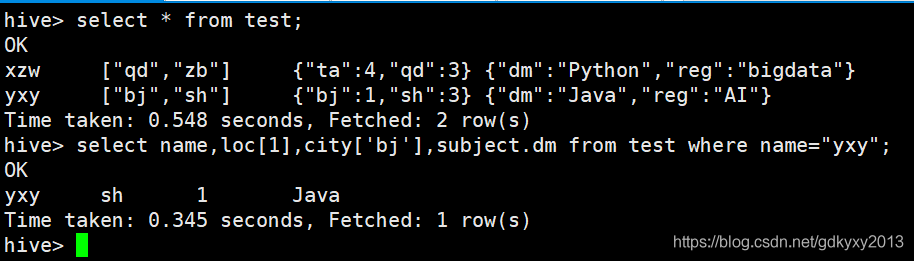
1.3 資料型別轉換
Hive的資料型別是可以進行隱式轉換的,其規則如下:
(1)任何整數型別都可以隱式地轉換為一個范圍更廣的型別,如TINYINT可以轉換成INT,INT可以轉換成BIGINT,
(2)所有整數型別、FLOAT和STRING型別都可以隱式地轉換成DOUBLE,
(3)TINYINT、SMALLINT、INT都可以轉換為FLOAT,
(4)BOOLEAN型別不可以轉換為任何其它的型別,
(5)可以使用CAST操作顯示進行資料型別轉換,例如CAST('1' AS INT)將把字串'1' 轉換成整數1;如果強制型別轉換失敗,如執行CAST('X' AS INT),運算式回傳空值 NULL,二、常用的屬性配置
在講解常用的屬性配置之前,我們先來看一下怎樣訪問或者是連接Hive以及Hive常用的一些互動命令等,這對后續屬性配置的講解有一個打基礎的作用,
2.1 HiveServer2服務
HiveServer2(HS2)是服務器介面,使遠程客戶端執行對Hive的查詢和檢索結果,換句話說,可以使用JDBC通過HiveServer2服務對Hive進行訪問,以下便是如何開啟HiveServer2服務,
1、首先通過以下命令啟動HiveServer2服務:
hiveserver22、啟動beeline
beeline
3、連接HiveServer2服務
通過以下命令連接HiveServer2服務:
!connect jdbc:hive2://master:10000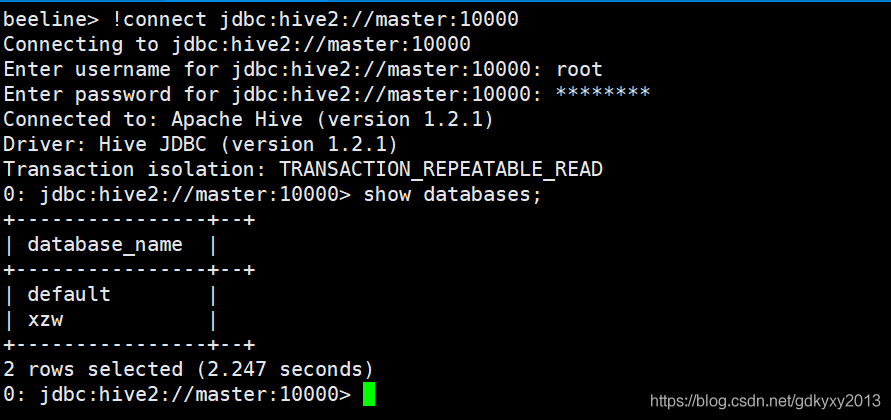
2.2 Hive的互動命令
可以通過如下命令,查看Hive都有哪些互動命令:
hive -help
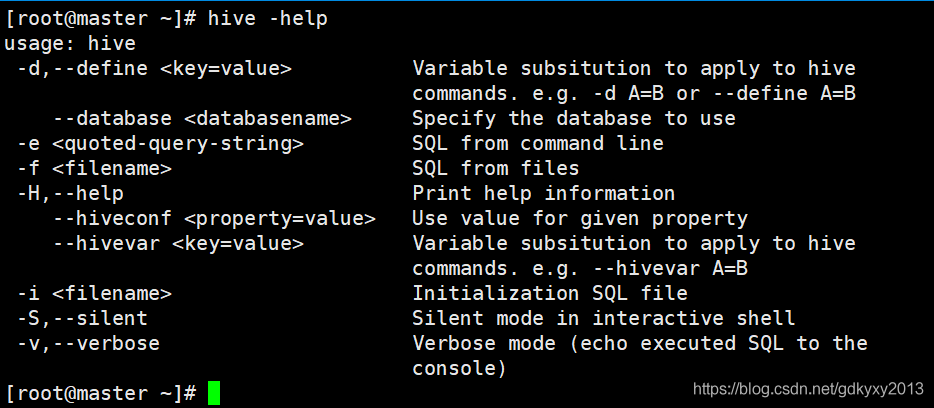
常用的互動命令可以參考我的另外一篇博客:《Hive通過-f呼叫sql檔案并進行傳參》,
2.3 Hive的其他命令
1、在命令列查看hdfs檔案系統
dfs -ls /;
2、在命令列查看本地檔案系統
!ls /root/files;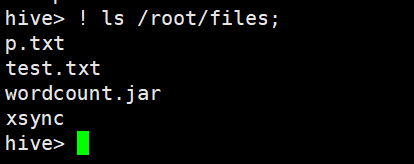
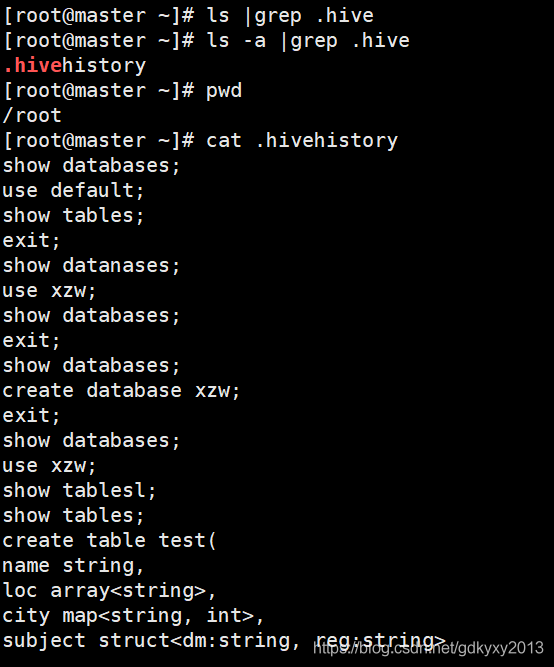
3、查看在Hive中輸入的歷史命令
在根目錄下有一個叫做.hivehistory的命令,如下圖所示:
2.4 常用的屬性配置
2.4.1 查詢顯示表頭資訊
在hive-site.xml中添加如下配置:
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
2.4.2 顯示當前資料庫名稱
在hive-site.xml中添加如下配置:
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
2.4.3 配置Hive資料倉庫位置
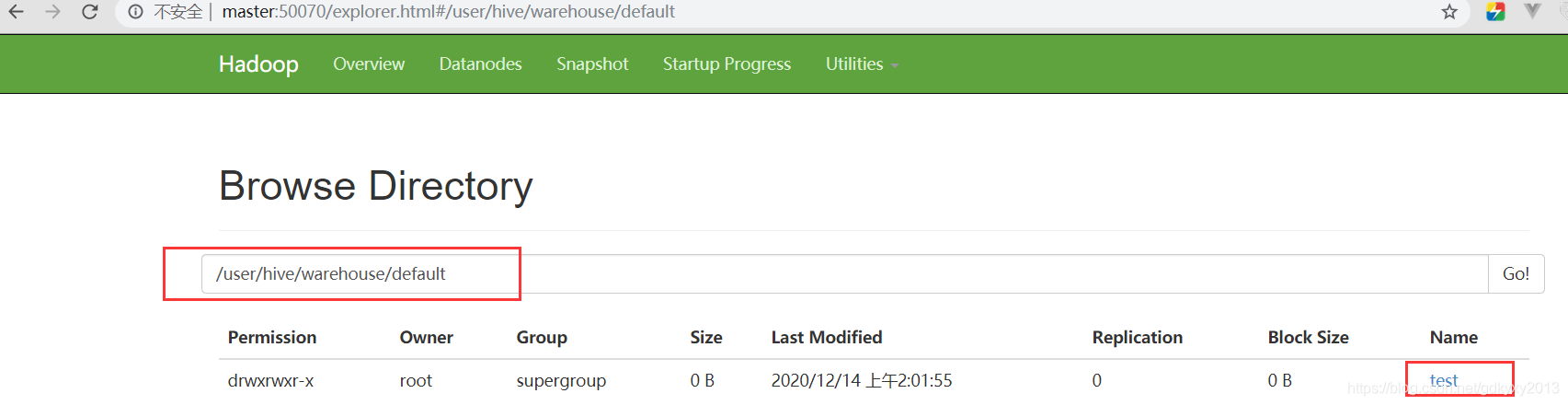
默認資料倉庫的最原始位置是在hdfs上的/user/hive/warehouse路徑下,在倉庫目錄下,沒有對默認的資料庫default創建檔案夾,如果某張表屬于default資料庫,它會直接在資料倉庫目錄下創建一個檔案夾,在hive-site.xml中添加如下配置解決此問題:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse/default</value>
<description>location of default database for the warehouse</description>
</property>
并修改執行權限:
hdfs dfs -chmod g+w /user/hive/warehouse/default在default資料庫中新建一張表進行測驗:
可以發現在default資料庫中新建的表都出現在了hdfs上的default目錄下:
2.4.4 配置Hive運行日志資訊存放位置
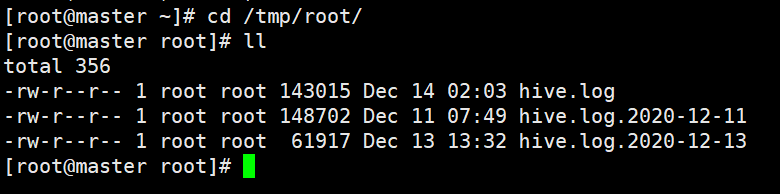
默認情況下,Hive的日志資訊存放在/tmp/root/目錄下:
修改hive-log4j.properties檔案將日志資訊放到指定位置,這里有個問題出現了,有的小伙伴發現在hive測conf目錄下,沒有這個組態檔,所以,在修改這個組態檔之前,還需要進行一步下面的操作:
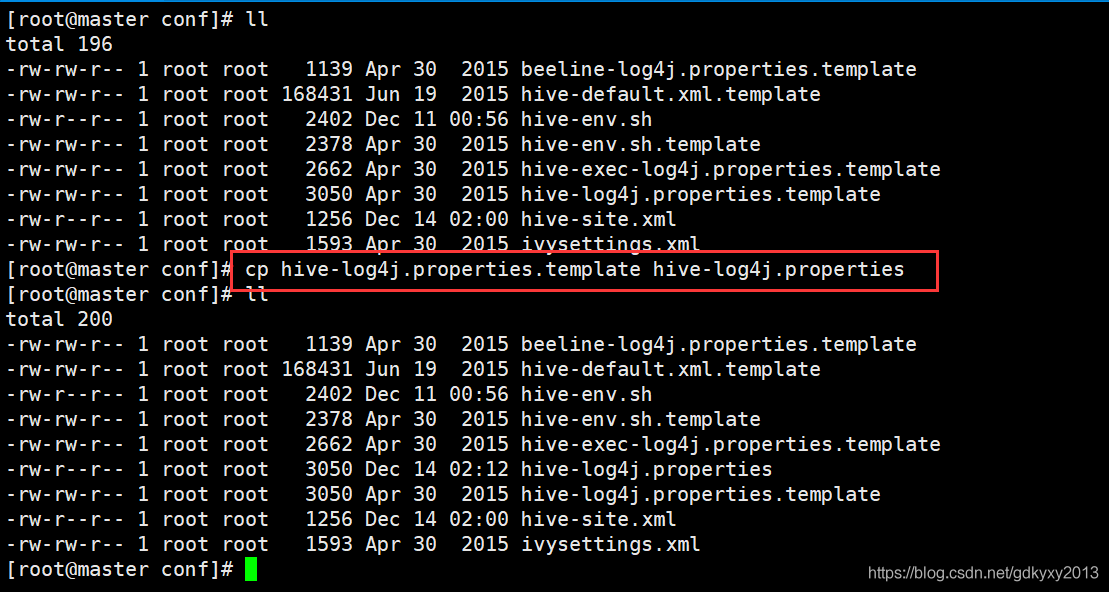
此時,修改組態檔中的對應引數即可:
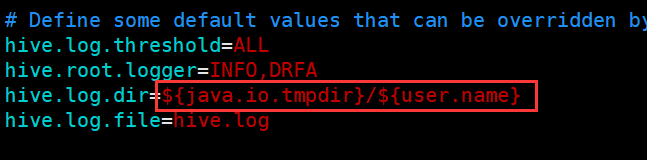
2.4.5 引數配置的優先級
在Hive的引數配置中,有三種引數的配置方式,分別如下,
1、通過組態檔,默認的組態檔是hive-default.xml,用戶自定義的組態檔是hive-site.xml,用戶自定義配置會覆寫默認配置,另外,Hive也會讀入Hadoop的配置,因為Hive是作為Hadoop的客戶端啟動的,Hive的配置會覆寫Hadoop的配置,組態檔的設定對本機啟動的所有Hive行程都有效,2、在命令列中通過set添加配置,例如:set mapred.reduce.tasks=100;,這種方式是臨時修改組態檔,當Hive下次啟動時,將會失效,3、在啟動Hive時通過設定引數-hiveconf來設定,例如:hive -hiveconf mapred.reduce.tasks=10,同樣的,這種方式是臨時修改組態檔,當Hive下次啟動時,將會失效,
上述三種設定方式的優先級為修改組態檔<命令列引數<引數宣告,
本文到此就接近尾聲了,你們在此程序中遇到了什么問題,歡迎留言,讓我看看你們都遇到了哪些問題~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/234231.html
標籤:其他
上一篇:機器學習基礎概念