原文鏈接:http://tecdat.cn/?p=18348
“應用線性模型”中,我們打算將一種理論(線性模型理論)應用于具體案例,通常,我會介紹理論的主要觀點:假設,主要結果,并進行示范來直觀地解釋,這里查看一個真實的案例研究,它包含真實資料,2400個觀測值,34個變數,

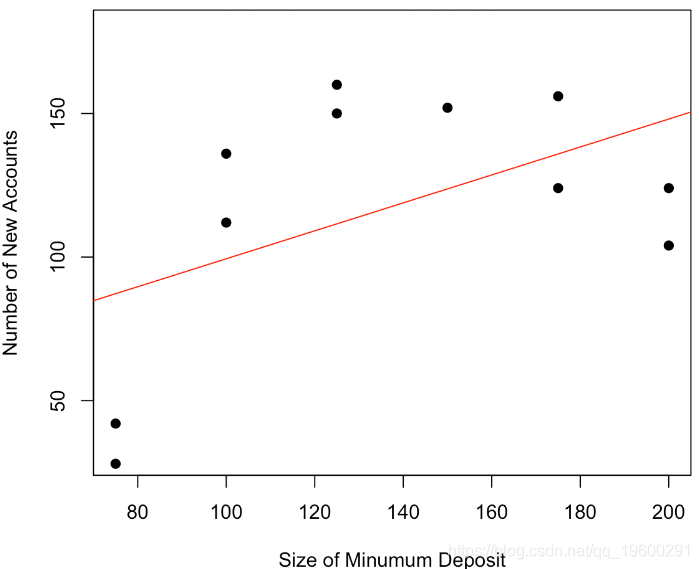
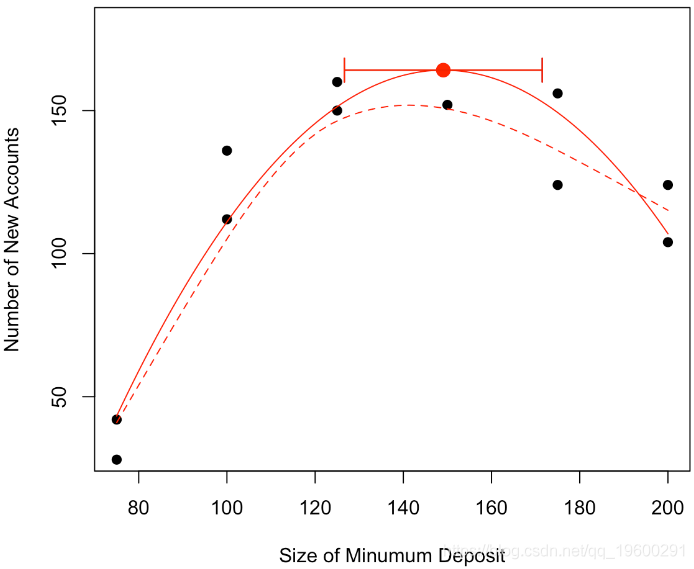
這里只有11個觀察值,一個簡單的線性模型,讓我們對這些資料進行線性回歸
plot(base,pch=19,ylim=c(30,180))
abline(lm(y~x,data=base),col="red")回歸線(最大程度地減少誤差平方和)是紅色曲線
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 50.7225 39.3979 1.287 0.23
x 0.4867 0.2747 1.772 0.11我們可以清楚地看到我們的曲線似乎是凹的,開始時增加,結束時減少,可以進行非引數平滑
scatter.smooth(x, y,
lpars = list(col = "red") 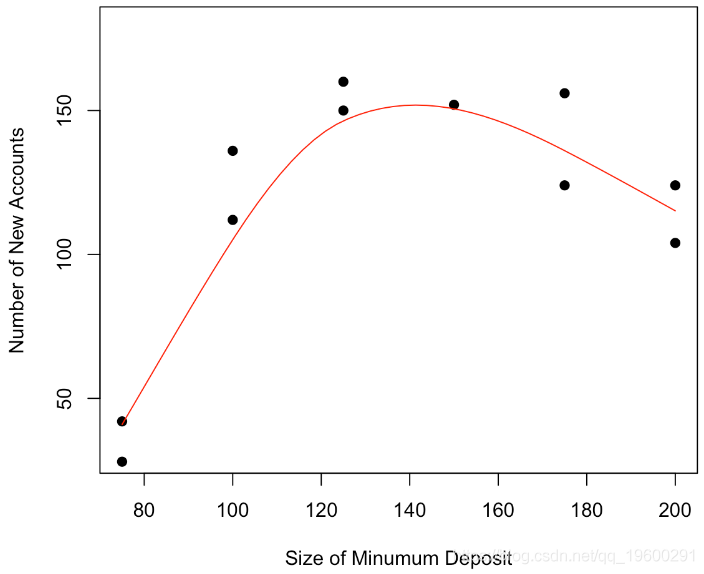
我們可以進一步回答“最大數目在哪里嗎”,可以建議一個值,找到一個置信區間嗎?
我們可以考慮一個二次模型,換句話說,我們的預測將是 拋物線,
lm(y~x+I(x^2),data=base)
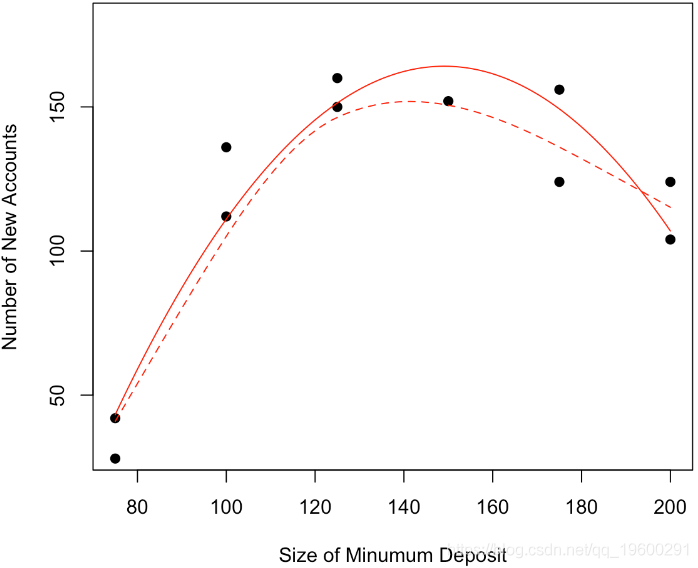
我們可以看到,該模型不僅在視覺上看起來更加符合實際,如果我們看一看回歸的結果,該模型也更好
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.255e+02 5.589e+01 -5.824 0.000394 ***
x 6.569e+00 8.744e-01 7.513 6.84e-05 ***
I(x^2) -2.203e-02 3.143e-03 -7.011 0.000111 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1現在我們可以證明,對于形式為y =β2x2 +β1x +β0的拋物線,最優值以x?=θ= ?β1 /2β2來獲得,那么θ的自然估計量就是θ= ?β 1 /2β2,通過最小化誤差平方和,但是如何獲得該估計量的方差?通過考慮以下因素,我們自然可以嘗試Delta方法
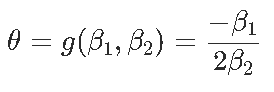
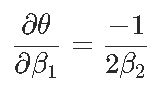
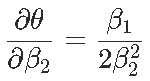
(漸近)方差在這里
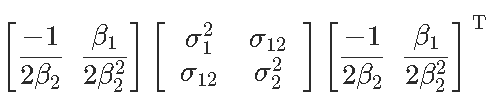
是
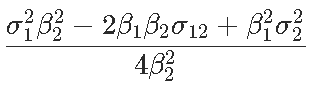
然后我們通過用未知量的估計值替換未知值來獲得此漸近方差的估計量,
theta=-beta[2]/(2*beta[3])
theta
[1] 149.0676
s2=t(dg) %*% sigma %*% dg
s2
[,1]
[1,] 94.59911
sqrt(s2)
[,1]
[1,] 9.726207換句話說,如果假設估計量的正態性,我們有以下置信區間
arrows(vx-qt(.975,n-3)*sqrt(s2),vy,
我們還可以嘗試另一種策略 ,對于我們的二次模型,我們通常在高斯假設下對數似然函式
logL = function(pm){
-sum(log(dnorm (base$y-(b0+b1*base$x+b2*base$x^2)) ,0,b3
}在這里,第一個方法是引入θ(其中拋物線的最大值是)作為模型引數之一-例如代替β2
logL = function(pm){
-sum(log(dnorm( base$y-b0+b1 base$x-.5*b1/theta base$x^2) ,0,b3
如果我們尋找最大似然函式,我們得到
optim(par=c(-213,3.5,110,2),logL)
$par
[1] -325.5 6.5 149.0 13.6
$value
[1] 44.3 這與我們之前的計算是一致的,第二個方法是分析似然函式:我們說在多元引數中,一個比另一個更重要,在給定θ的情況下,其他函式才最大化,從技術上講,引數θ的輪廓對數似然是
logL=function(theta){
-sum(log(dnorm( base$y- b0+b1*base$x-.5*b1/theta*base$x^2 ,0,b3)
optim(par )$value
我們可以繪制結果
plot(v1,-v2,type="l",xlim=range(base$x)
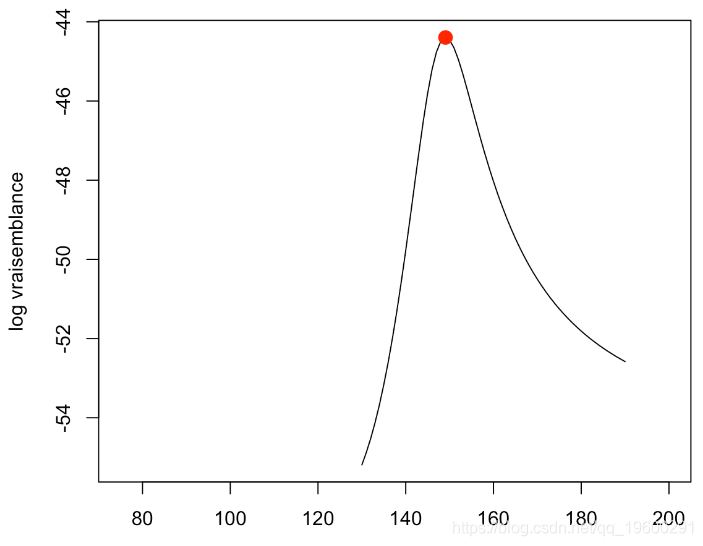
在這里達到最大值
opt
$minimum
[1] 149.068這與我們的計算是一致的,然后,我們可以得到結果的似然比檢驗,
abline(h=ref,lty=2,col="red")
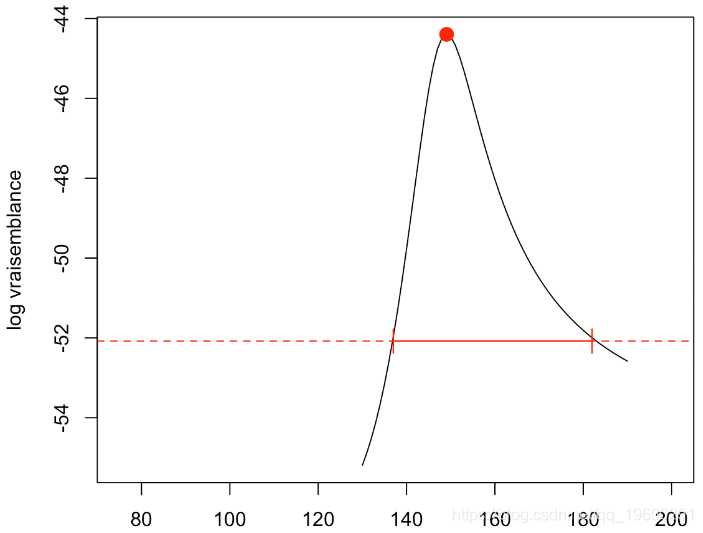
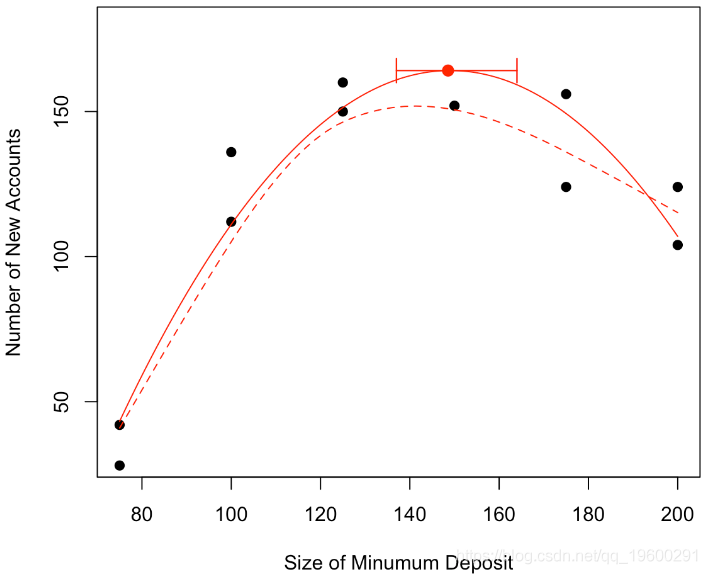
然后我們可以在初始圖中繪制置信區間
points(vx,vy,pch=19,cex=1.5,col="red")
arrows(min(v1[id]),vy,max(v1[id]),vy,code=3,angle=90,
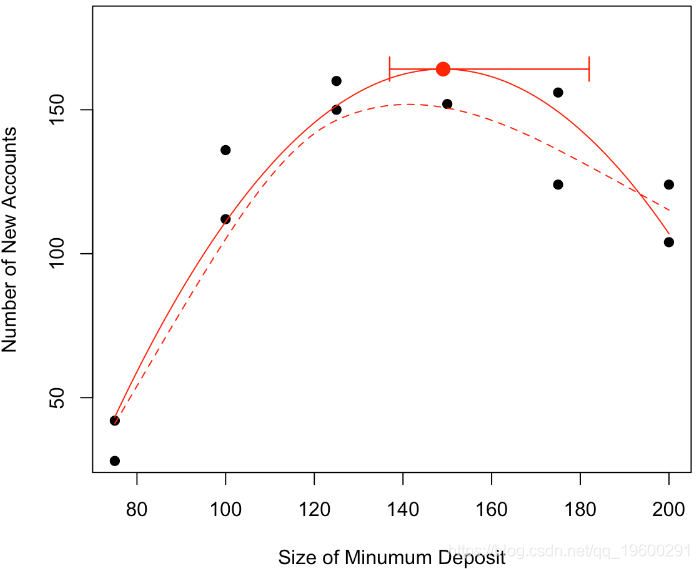
就像大多數統計技術一樣,這些都是漸近結果,僅憑11個觀察結果無法保證其有效性,
另一個解決方案是使用模擬,我們假設觀測值是模型,并且是噪聲,我們可以將非引數模型(區域平滑)作為模型并假設高斯噪聲,為了生成其他樣本,我們將觀測值保存在x中,另一方面,對于y,我們將使用y +ε,其中ε將根據正態分布繪制
loess.smooth(x = newbase$x, y= newbase$y
lines(reg$x,reg$y
for(i in 1:20) simu(TRUE)
lines(loess.smooth(x = base$x, y= base$y, evaluation = 501)
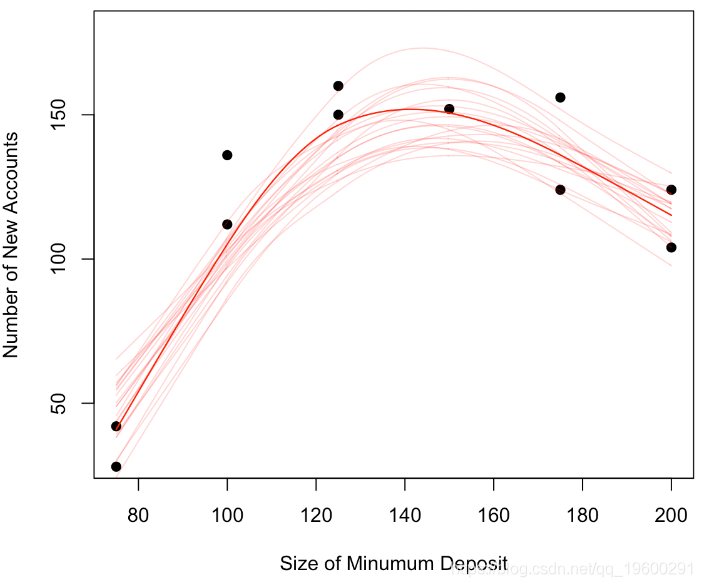
給定資料的不對稱性,我們再次使用非引數模型,并且我們通過數值計算最大值,我們重復10,000次,
hist(V,probability = TRUE
lines(density(V)
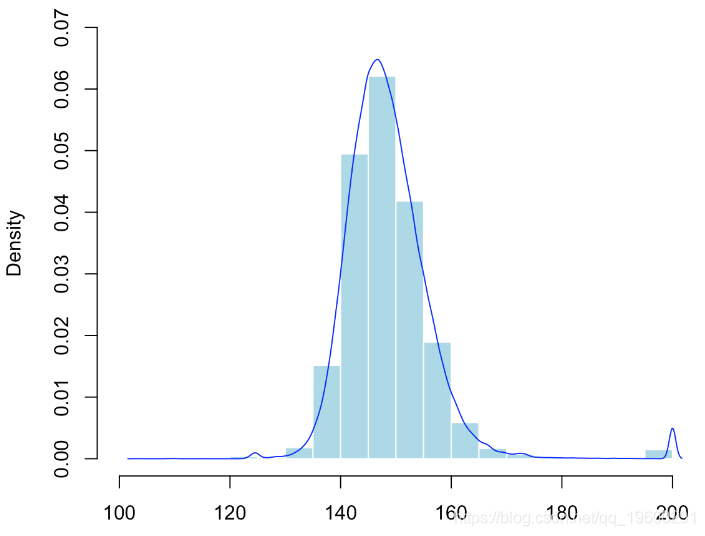
在這里,我們有在10,000個模擬樣本上觀察到的最大值的經驗分布,我們可以通過經驗分位數來獲得置信區間
arrows(quantile(V,.025 ,vy,quantile(V,.975

最受歡迎的見解
1.R語言多元Logistic邏輯回歸 應用案例
2.面板平滑轉移回歸(PSTR)分析案例實作
3.matlab中的偏最小二乘回歸(PLSR)和主成分回歸(PCR)
4.R語言泊松Poisson回歸模型分析案例
5.R語言回歸中的Hosmer-Lemeshow擬合優度檢驗
6.r語言中對LASSO回歸,Ridge嶺回歸和Elastic Net模型實作
7.在R語言中實作Logistic邏輯回歸
8.python用線性回歸預測股票價格
9.R語言如何在生存分析與Cox回歸中計算IDI,NRI指標
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/235423.html
標籤:AI
下一篇:關于測驗的用例