Scrapy作為一個優秀的爬蟲框架,盡管其體系已相當成熟,但實際操作中其實還是需要借助其他插件的力量來完成某些網站的爬取作業,今天記錄一下博主爬蟲路上的一些坑及解決方案,避免大家走太多彎路,
一、DEBUG: Filtered duplicate request: GET xxx - no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates)
對網站全站爬取資料時,遇到了這個報錯,
Scrapy會對request的URL去重(RFPDupeFilter),需要在scrapy.Request方法中傳遞多一個引數,dont_filter=True,
# 示例
yield scrapy.Request(url=self.urlList[self.urlIndex], callback=self.parse, dont_filter=True)
二、多個爬蟲集成selenium
如果你看過我上一篇Scrapy博文,就知道我是如何將selenium集成到Scrapy中,
其實,正確的做法,是需要將ChromeDriver的配置,轉移到middlewares中,不然如果按照我上一篇博文那么去寫,將其配置寫在具體的各個蜘蛛里的話,先是會導致代碼冗余,關鍵是還會導致啟動一個蜘蛛的時候,會啟動多個ChromeDriver,
三、關于ChromeDriver的配置細則
直接上代碼:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") # 無頭(靜默)模式
chrome_options.add_argument("--disable-gpu") # 禁用GPU加速
chrome_options.add_experimental_option('prefs', {"profile.managed_default_content_settings.images": 2}) # 非headless模式下不加載圖片
chrome_options.add_argument('blink-settings=imagesEnabled=false') # headless模式下不加載圖片
driver = webdriver.Chrome(chrome_options=chrome_options)
# 瀏覽器靜默模式下,最大化視窗是無效的 driver.maximize_window()
driver.set_window_size(1920, 1080) # 設定瀏覽器視窗大小
某些網站對不同的解析度所展示的內容不一,所以最好在同一的解析度下去抓取網頁,設定driver瀏覽器視窗的方法有兩個driver.maximize_window()和driver.set_window_size(1920, 1080),需要注意的是maximize_window在headless模式下無效,所以推薦使用set_window_size,
四、反爬蟲進階
往往某些網站,會配置反爬蟲機制,諸如換USER_AGENTS換IP這些已經爛大街的操作我在這里就不提及了,
使用過selenium爬蟲的人,都知道其實就算使用了模擬瀏覽器去訪問某些網站,還是會被認定為爬蟲做驗證碼攔截,而往往這個時候,你就算人工去做驗證操作,網頁往往還是一動不動,為什么?這里先推薦一個B站的視頻給大家稍微科普一下,
被攔截的示例如下:
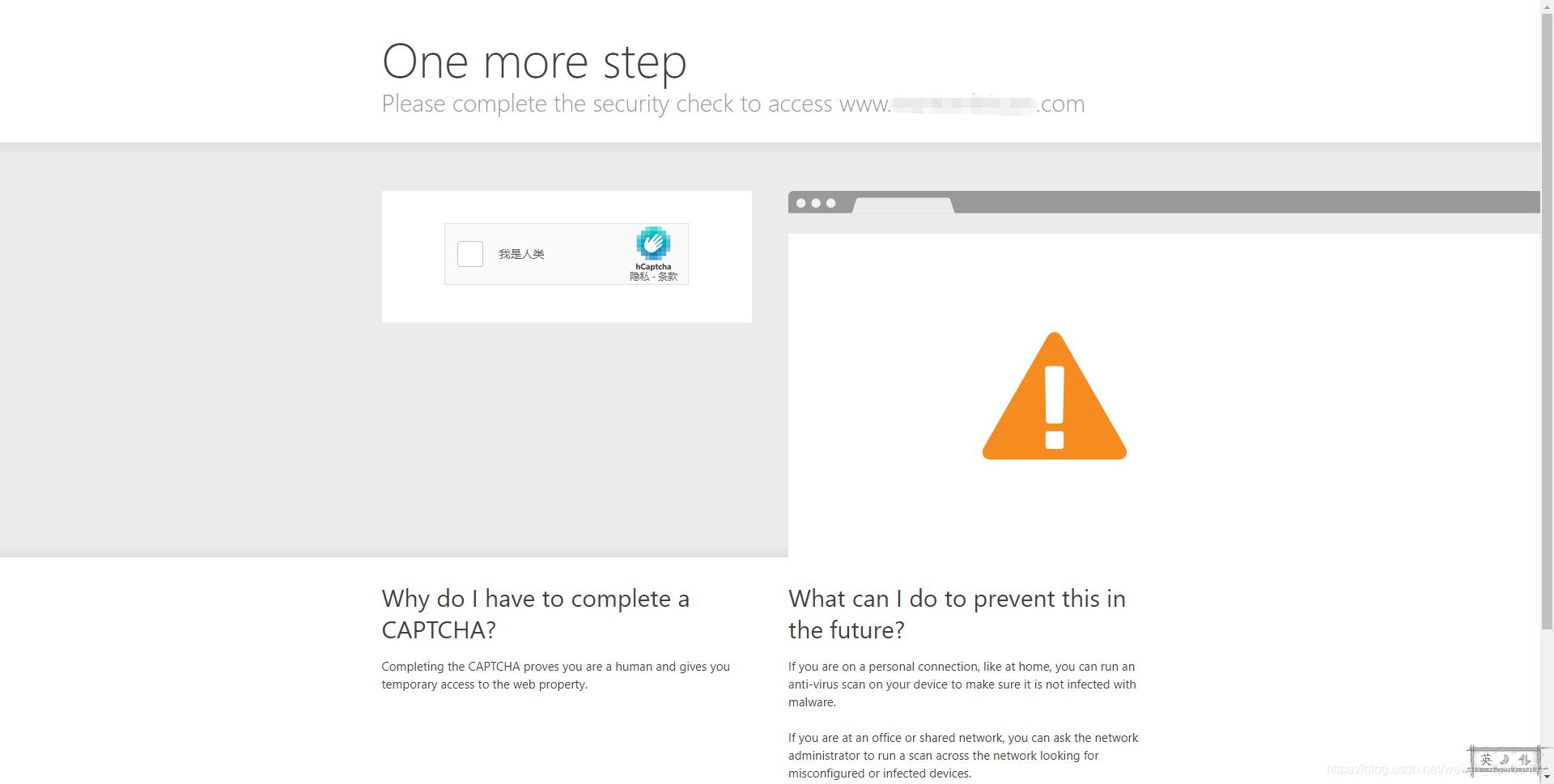
這是因為你所啟動的瀏覽器,仍有太多你看不見的爬蟲特征,這里給大家推薦一個冷門的插件selenium-stealth,這款插件可以集成selenium抹去ChromeDriver上的蜘蛛痕跡,
至于插件的原理,建議感興趣的再自行研究stealth.min.js這個東西,
示例使用代碼如下:
from selenium_stealth import stealth
chrome_options = Options()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(chrome_options=chrome_options)
stealth(driver,
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
可以結合上邊的代碼添加Options配置,
順帶提一點,使用headless模式跟stealth插件后,會導致ajax異步加載資料的網站,load不出來資料,原因不詳,建議爬取這種網站的時候,如果該網站沒有什么驗證,可以將stealth關閉,或者關閉無頭模式爬取,
五、繞過CloudFlare
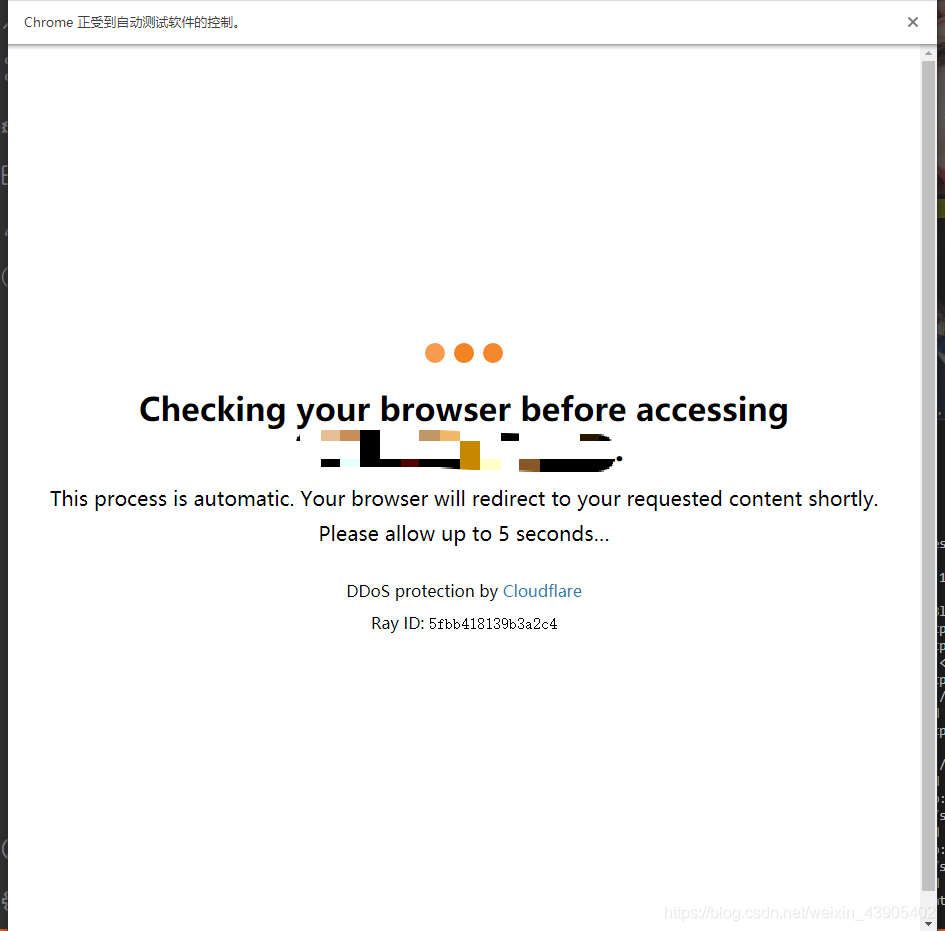
相信大家做爬蟲的,對五秒盾CloudFlare并不陌生,至于如何去繞過五秒盾的檢測,推薦大伙一個插件cloudflare-scrape,專門用于繞過CloudFlare,
實際操作流程請自行查看檔案,可以拿這個網站練練手wallhere,
不過實際操作中,有些網站就算用了這個插件也繞不過,比如博主想要爬取的網站就繞不過五秒盾,作為爬蟲菜雞,博主也不深究當場放棄(其他繞行方式不會),
總結
這個世界上奇葩的網站多得是,遇到過令人作嘔的商品具有六種格式的價格形式的;也遇到過網站禁用了js,用不了xpath的;還遇到過無限滾動加載,一個頁面幾千個DOM導致ChromeDriver假死的…
不扯淡了,路還很長,Keep learning…
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/236550.html
標籤:其他