使用Flume作為Spark Streaming資料源
- 一、安裝Flume
- 二、使用netcat資料源測驗Flume
- 三、使用Flume作為Spark Streaming資料源
- 1.對組態檔進行配置
- 2.遇到的問題
- 3.正常運行Spark Streaming
一、安裝Flume
鏈接:https://pan.baidu.com/s/1fE8YStngEVY3ixFN0qOPRA
提取碼:519w
對其進行解壓
tar -zxvf apache-flume-1.7.0-bin.tar.gz
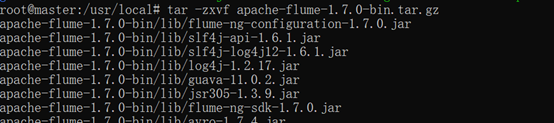
測驗是否安裝成功
./bin/flume-ng version

二、使用netcat資料源測驗Flume
啟動Flume
flume-ng agent --conf conf --conf-file conf/flume-conf.properties.example --name a1 -Dflume.root.logger=INFO,console
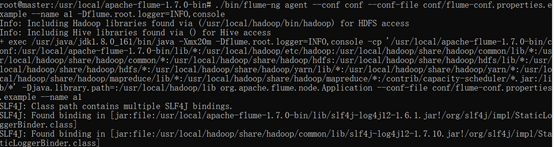
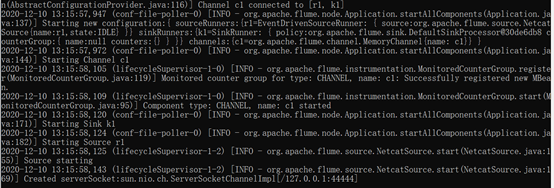
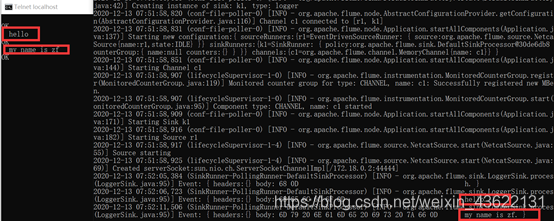
使用telnet連接(因為使用的是docker搭建的集群,所以我將docker容器的44444埠映射到宿主機的44444,直接telnet宿主機的埠連接flume發送訊息)
telnet localhost 44444

三、使用Flume作為Spark Streaming資料源
1.對組態檔進行配置
把Flume Source設定為netcat型別,從終端上不斷給Flume Source發送各種訊息,Flume把訊息匯集到Sink,這里把Sink型別設定為avro,由Sink把訊息推送給Spark Streaming
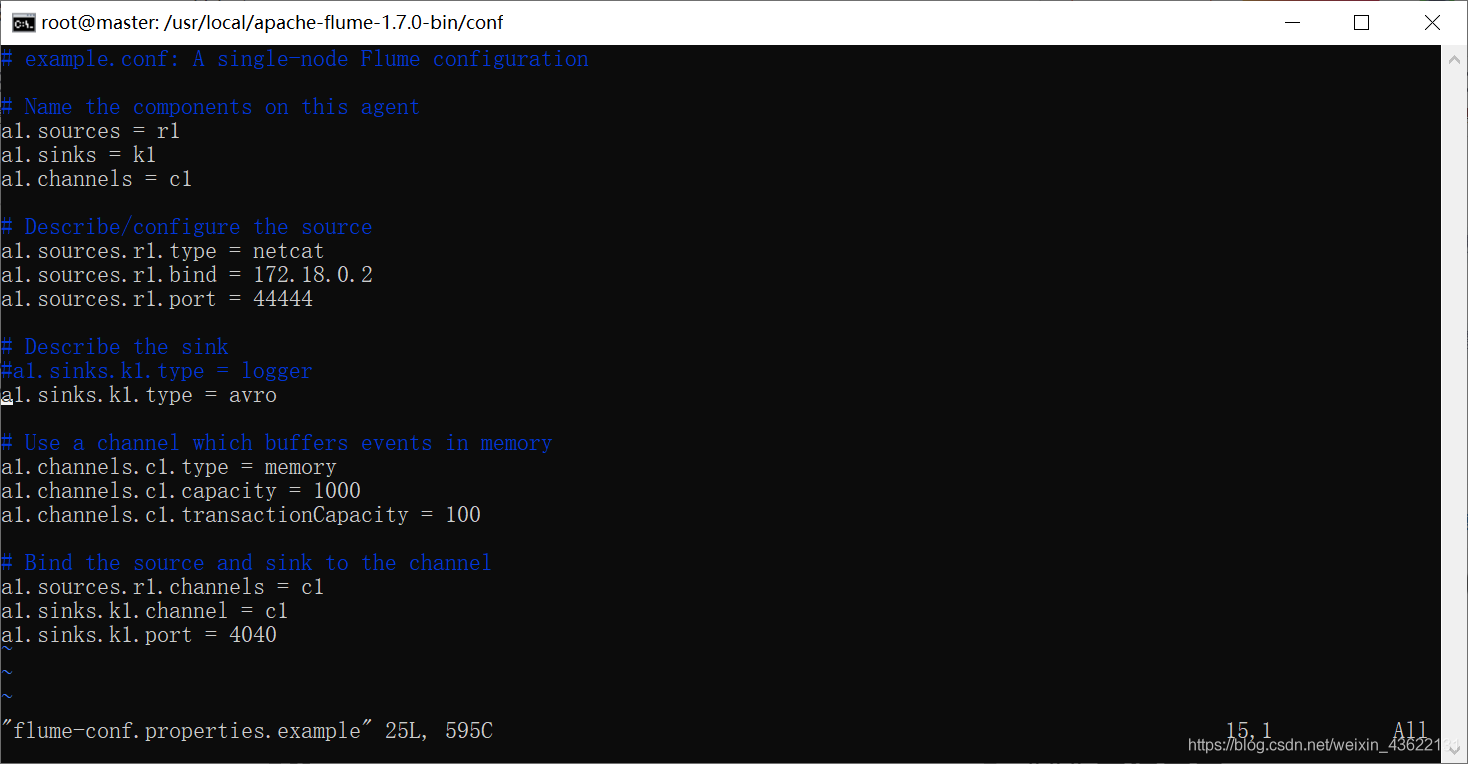
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
# 這里44444是接收資料的埠,可以使用telnet連接來發送資料
a1.sources.r1.type = netcat
a1.sources.r1.bind = 172.18.0.2
a1.sources.r1.port = 44444
# Describe the sink
# 這里的hostname是sink匯總資料后發送的主機,port是發送到的埠
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 10.0.75.1
a1.sinks.k1.port = 55555
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.遇到的問題

下載鏈接:
鏈接:https://pan.baidu.com/s/1aSitpOXvNfODXItgBvd7wA
提取碼:7xvu
將上面兩個jar包放到spark的jars目錄下(版本要與spark的版本匹配),如果沒有加上述jar包會出現下面錯誤:
沒有添加第一個jar包的錯誤:


沒有添加第二個jar包的錯誤

上述操作完成后又出現了一個問題,發現還是少jar包

只需要將該jar包放到spark集群的jars目錄下即可(注意版本對應)
鏈接:https://pan.baidu.com/s/1cJx58u6BGgTgBsYF1jct3w
提取碼:1usm
這里我使用的是idea連接spark集群來提交專案的,可以看我之前寫的博客:IDEA連接spark集群
import java.io.FileWriter
import java.net.{InetAddress, InetSocketAddress}
import org.apache.spark._
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.flume.{FlumeReceiver, FlumeUtils, SparkFlumeEvent}
import org.apache.spark.streaming.flume._
// 關防火墻
object streaming {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("streaming").set("spark.executor.memory", "2048m")
// .set("spark.driver.host", "10.0.75.1")
.set("spark.driver.cores", "2")
.setMaster("local") //spark://127.0.0.1:7077
.setJars(List("D:\\自然語言處理\\spark\\out\\artifacts\\SparkExample_jar\\spark.jar")) // maven打的jar包的路徑
.set("spark.driver.allowMultipleContexts", "true")
//3、創建StreamingContext
val ssc = new StreamingContext(conf,Seconds(2))
val stream = FlumeUtils.createStream(ssc, "10.0.75.1", 55555, StorageLevel.MEMORY_ONLY_SER_2) // Print out the count of events received from this server in each batch
stream.count().map(cnt => "Received " + cnt + " flume events." ).print()
val words = stream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_,1))
val results = words.reduceByKey(_+_)
//開啟計算
ssc.start()
ssc.awaitTermination()
}
}
這里我原本使用的是standlone模式,即setMaster設定的是spark://127.0.0.1:7077,但是會出現下面問題,可能是idea連接spark集群的弊端,目前我還沒有解決該問題

于是我使用了本地模式便沒有該問題
3.正常運行Spark Streaming
開啟后Spark Streaming正常運行
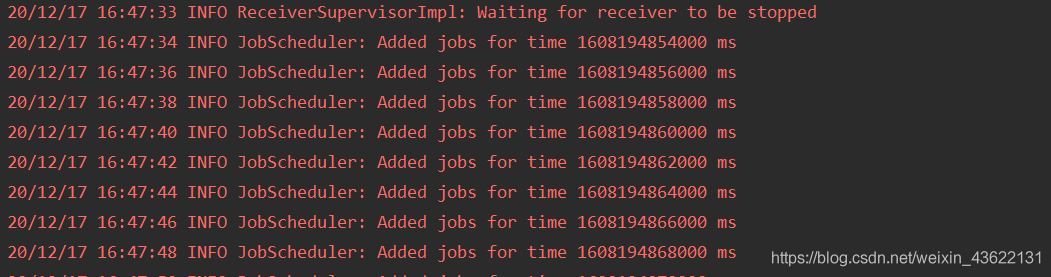
打開flume
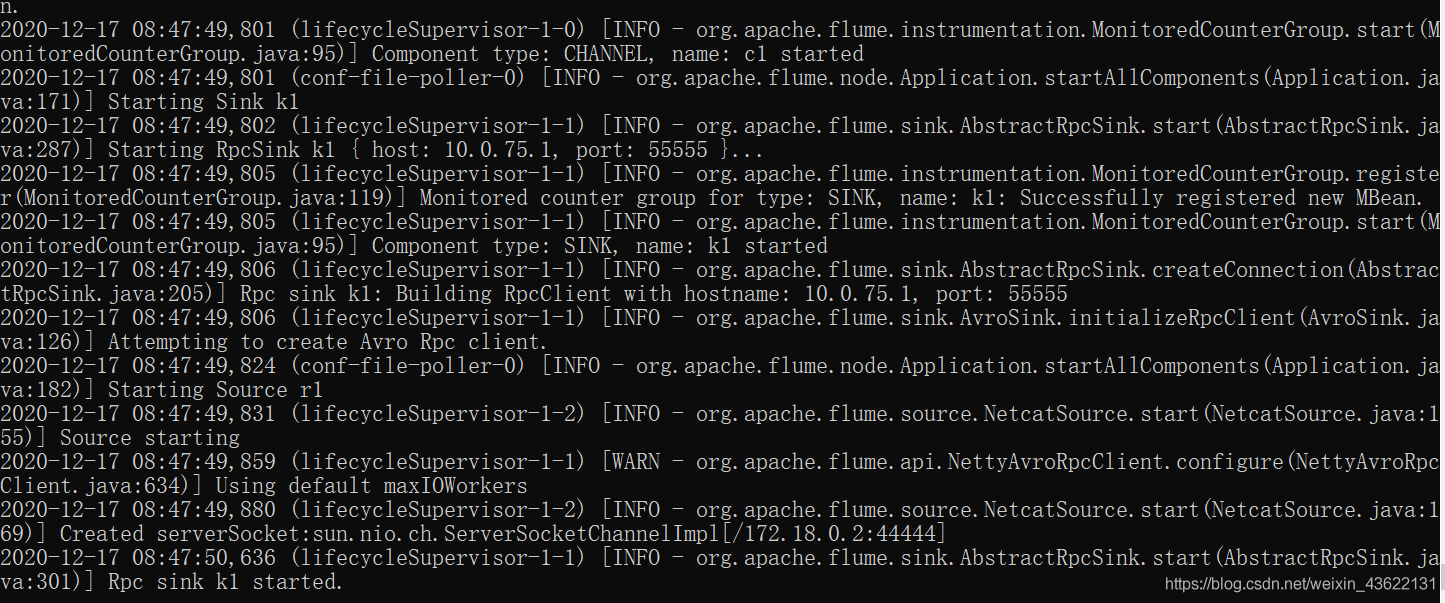
可以看到Spark Streaming已經連接上了flume

下面使用telnet連接flume的44444埠發送資料
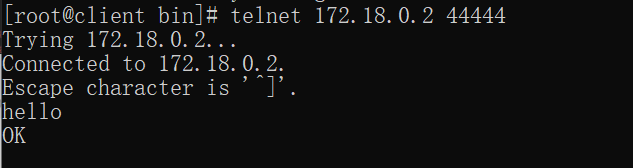
可以看到Spark Streaming已經接收到了發送的資料,但是這里只是日志里體現出來了,代碼中的輸出陳述句并沒有輸出,該問題還未解決

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/236551.html
標籤:其他
上一篇:Scrapy爬蟲踩坑記錄