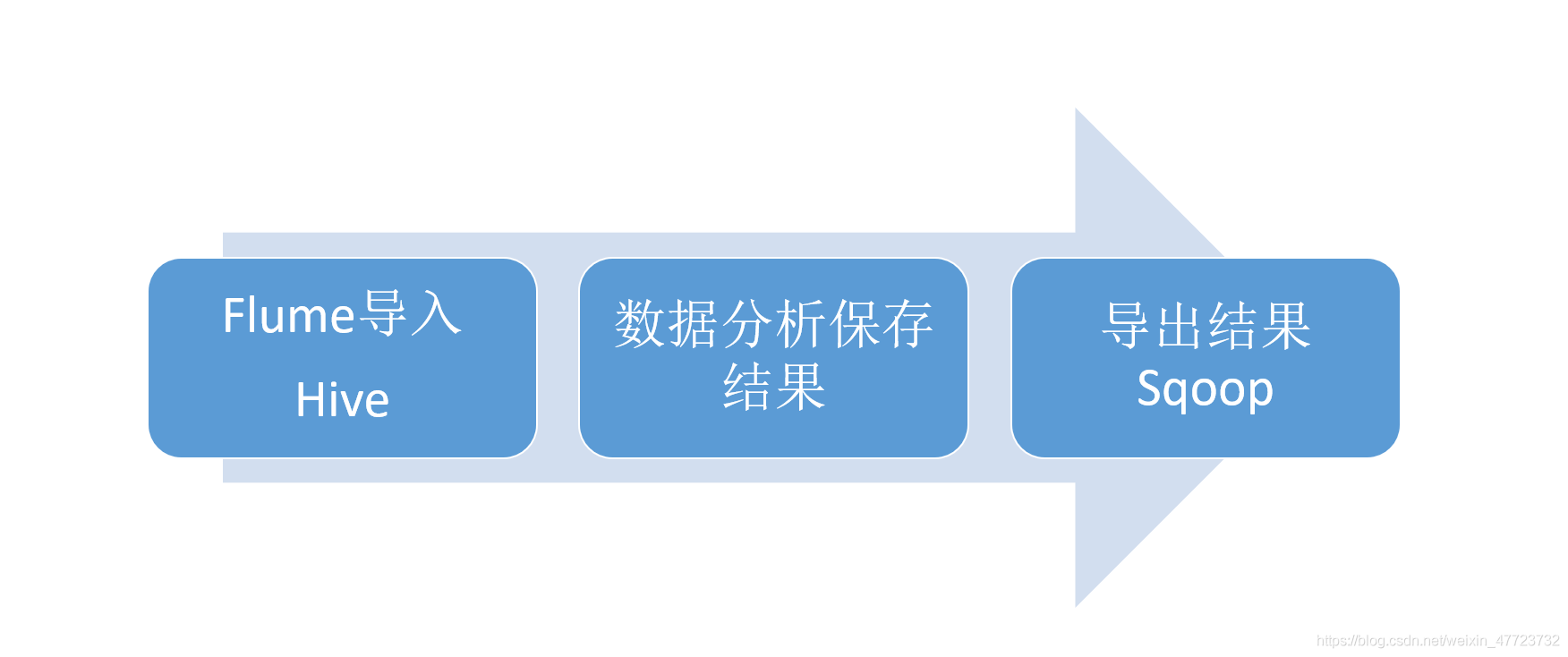
前面我們介紹了Hadoop環境下,分析淘寶大資料案例的程序及方法,根據分析效果還不錯,實驗效果也體現了大資料的資料集大的一個特點,本次實驗我們假設了一個實際場景:假設現在有一個省份的學生選課資料需要你去分析,那么在資料集復雜和龐大的面前,我們的Hadoop是否還實用,這里所說的資料集復雜是因為有多個資料表需要你去采集,分析也需要進行多表連接,
 對Hadoop里面的hive的認識,我覺得沒有MySQL智能和方便,那么為什么我們還要去使用Hadoop里面的hive呢,因為大資料集,后面我們會引入spark這個引擎,會極大地方便我們開始新的旅途!
對Hadoop里面的hive的認識,我覺得沒有MySQL智能和方便,那么為什么我們還要去使用Hadoop里面的hive呢,因為大資料集,后面我們會引入spark這個引擎,會極大地方便我們開始新的旅途!
專案簡介
假設一個資料集十分龐大的學生選課資料集,當然我們這里只是模擬了一個資料集,便于我們使用,我們在Python環境下面產生一些虛擬資料集,有四個表分別是學生表,選課表,課程表,課程_班級表,當然現實生活中真的需要你去分析,那么也至少是千萬級的資料集,
分析資料:
a、男女生比例
b、及格率
c、每門課程的平均分,要求顯示出課程的中文名字
d、有2門課不及格的學生
e、在mysql中創建結果表,把結果用sqoop寫入到表中,并顯示結果,
 思路其實之前類似:
思路其實之前類似:
一些基本的操作和配置在之前的淘寶案例里面我們都有介紹,這里我就不做過多的贅述了,有需要的小伙伴請移步到上一篇文章
需要注意的是,之前我們發現匯入匯出進行查詢的時候,顯示中文是???本次我們修改了一些資料引數,現在可以顯示正常了操作步驟如下:
在useSSL=false后面添加下面引數即可:
&allowPublicKeyRetrieval=true&useUnicode=true&characterEncoding=UTF-8
考慮到有的人容易打錯,所以只需要將下面的代碼全選覆寫之前的也可以
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?useSSL=false&allowPublicKeyRetrieval=true&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
<!--這里的執行緒數必須大于0 :理想狀態和分桶數一致-->
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
</configuration>
創建檔案夾,便于后續操作(和之前的一樣)
mkdir -p /home/hadoop/xsxk/data
mkdir -p /home/hadoop/xsxk/tmp/point
創建四個組態檔,幫助我們匯入到hive里面(flume組件配置)
vi tb_course.properties
#定義agent名, source、channel、sink的名稱
agent3.sources = source3
agent3.channels = channel3
agent3.sinks = sink3
#具體定義source
agent3.sources.source3.type = spooldir
agent3.sources.source3.spoolDir = /home/hadoop/xsxk/data
agent3.sources.source3.fileHeader=false
#設定channel型別為磁盤
agent3.channels.channel3.type = file
#file channle checkpoint檔案的路徑
agent3.channels.channel3.checkpointDir=/home/hadoop/xsxk/tmp/point
# file channel data檔案的路徑
agent3.channels.channel3.dataDirs=/home/hadoop/xsxk/tmp
#具體定義sink
agent3.sinks.sink3.type = hive
agent3.sinks.sink3.hive.metastore = thrift://hadoop:9083
agent3.sinks.sink3.hive.database = xsxk
agent3.sinks.sink3.hive.table = tb_course
agent3.sinks.sink3.serializer = DELIMITED
agent3.sinks.sink3.serializer.delimiter = ","
agent3.sinks.sink3.serializer.serdeSeparator = ','
agent3.sinks.sink3.serializer.fieldnames = code,name,period,credit
agent3.sinks.sink3.batchSize = 90
#組裝source、channel、sink
agent3.sources.source3.channels = channel3
agent3.sinks.sink3.channel = channel3
vi tb_course_class.properties
#定義agent名, source、channel、sink的名稱
agent3.sources = source3
agent3.channels = channel3
agent3.sinks = sink3
#具體定義source
agent3.sources.source3.type = spooldir
agent3.sources.source3.spoolDir = /home/hadoop/xsxk/data
agent3.sources.source3.fileHeader=false
#設定channel型別為磁盤
agent3.channels.channel3.type = file
#file channle checkpoint檔案的路徑
agent3.channels.channel3.checkpointDir=/home/hadoop/xsxk/tmp/point
# file channel data檔案的路徑
agent3.channels.channel3.dataDirs=/home/hadoop/xsxk/tmp
#具體定義sink
agent3.sinks.sink3.type = hive
agent3.sinks.sink3.hive.metastore = thrift://hadoop:9083
agent3.sinks.sink3.hive.database = xsxk
agent3.sinks.sink3.hive.table = tb_course_class
agent3.sinks.sink3.serializer = DELIMITED
agent3.sinks.sink3.serializer.delimiter = ","
agent3.sinks.sink3.serializer.serdeSeparator = ','
agent3.sinks.sink3.serializer.fieldnames = code,semester,teacher_id,course_code
agent3.sinks.sink3.batchSize = 90
#組裝source、channel、sink
agent3.sources.source3.channels = channel3
agent3.sinks.sink3.channel = channel3
vi tb_electives.properties
#定義agent名, source、channel、sink的名稱
agent3.sources = source3
agent3.channels = channel3
agent3.sinks = sink3
#具體定義source
agent3.sources.source3.type = spooldir
agent3.sources.source3.spoolDir = /home/hadoop/xsxk/data
agent3.sources.source3.fileHeader=false
#設定channel型別為磁盤
agent3.channels.channel3.type = file
#file channle checkpoint檔案的路徑
agent3.channels.channel3.checkpointDir=/home/hadoop/xsxk/tmp/point
# file channel data檔案的路徑
agent3.channels.channel3.dataDirs=/home/hadoop/xsxk/tmp
#具體定義sink
agent3.sinks.sink3.type = hive
agent3.sinks.sink3.hive.metastore = thrift://hadoop:9083
agent3.sinks.sink3.hive.database = xsxk
agent3.sinks.sink3.hive.table = tb_electives
agent3.sinks.sink3.serializer = DELIMITED
agent3.sinks.sink3.serializer.delimiter = ","
agent3.sinks.sink3.serializer.serdeSeparator = ','
agent3.sinks.sink3.serializer.fieldnames = course_class_code,student_id,score
agent3.sinks.sink3.batchSize = 90
vi tb_student.properties
#定義agent名, source、channel、sink的名稱
agent3.sources = source3
agent3.channels = channel3
agent3.sinks = sink3
#具體定義source
agent3.sources.source3.type = spooldir
agent3.sources.source3.spoolDir = /home/hadoop/xsxk/data
agent3.sources.source3.fileHeader=false
#設定channel型別為磁盤
agent3.channels.channel3.type = file
#file channle checkpoint檔案的路徑
agent3.channels.channel3.checkpointDir=/home/hadoop/xsxk/tmp/point
# file channel data檔案的路徑
agent3.channels.channel3.dataDirs=/home/hadoop/xsxk/tmp
#具體定義sink
agent3.sinks.sink3.type = hive
agent3.sinks.sink3.hive.metastore = thrift://hadoop:9083
agent3.sinks.sink3.hive.database = xsxk
agent3.sinks.sink3.hive.table = tb_student
agent3.sinks.sink3.serializer = DELIMITED
agent3.sinks.sink3.serializer.delimiter = ","
agent3.sinks.sink3.serializer.serdeSeparator = ','
agent3.sinks.sink3.serializer.fieldnames = id,name,gender,birthdate,phonenumber,major_class
agent3.sinks.sink3.batchSize = 90
#組裝source、channel、sink
agent3.sources.source3.channels = channel3
agent3.sinks.sink3.channel = channel3

注意在vi里面的操作,不知道的請移步上一篇文章,這樣我們創建了四個檔案,到時候我們只需要啟動四個不同監聽就可以同時都四個表的資料了
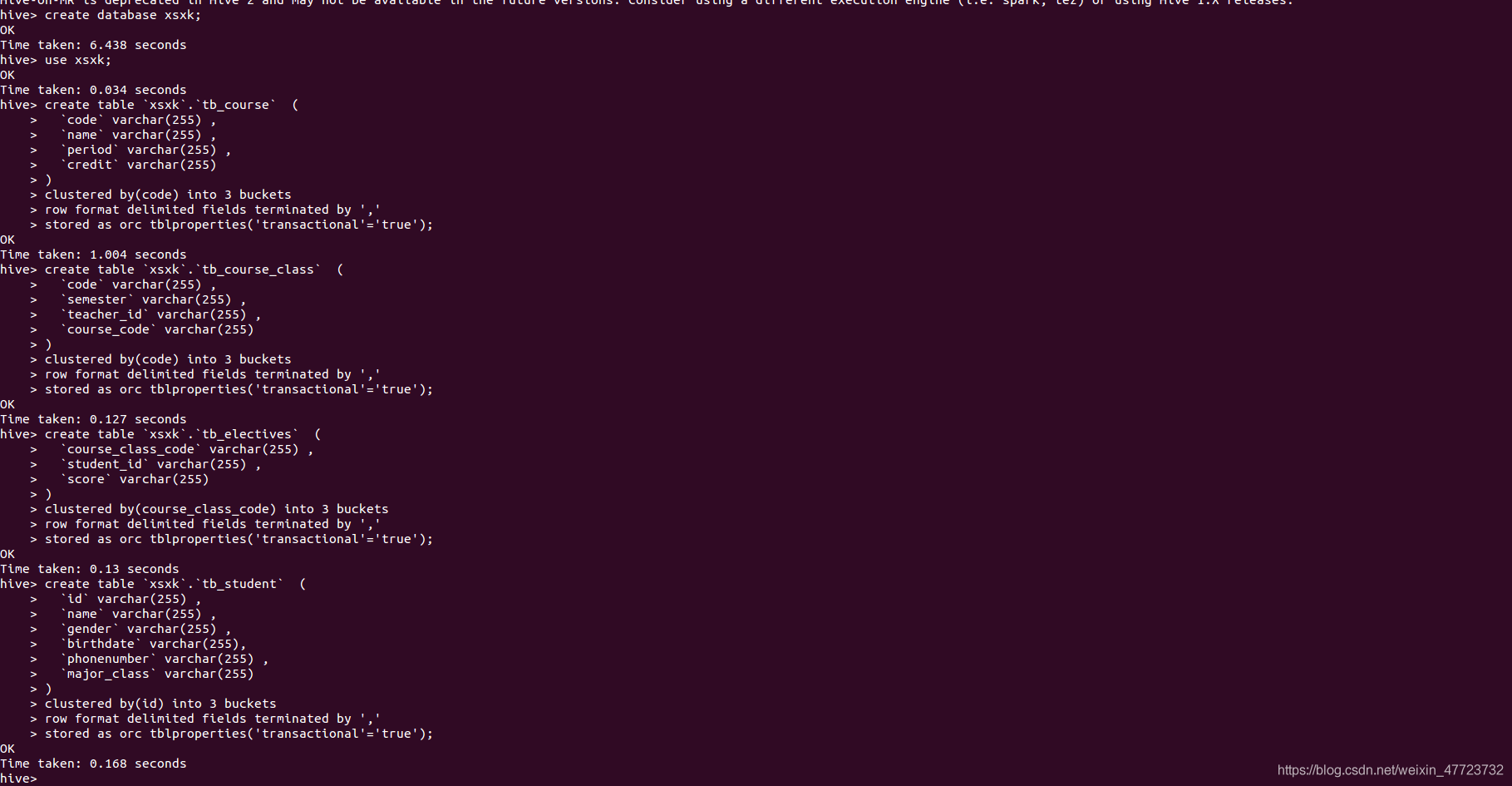
在hive里面創建相應的四個表
啟動hive
hive
create database xsxk;
use xsxk;
create table `xsxk`.`tb_course` (
`code` varchar(255) ,
`name` varchar(255) ,
`period` varchar(255) ,
`credit` varchar(255)
)
clustered by(code) into 3 buckets
row format delimited fields terminated by ','
stored as orc tblproperties('transactional'='true');
create table `xsxk`.`tb_course_class` (
`code` varchar(255) ,
`semester` varchar(255) ,
`teacher_id` varchar(255) ,
`course_code` varchar(255)
)
clustered by(code) into 3 buckets
row format delimited fields terminated by ','
stored as orc tblproperties('transactional'='true');
create table `xsxk`.`tb_electives` (
`course_class_code` varchar(255) ,
`student_id` varchar(255) ,
`score` varchar(255)
)
clustered by(course_class_code) into 3 buckets
row format delimited fields terminated by ','
stored as orc tblproperties('transactional'='true');
create table `xsxk`.`tb_student` (
`id` varchar(255) ,
`name` varchar(255) ,
`gender` varchar(255) ,
`birthdate` varchar(255),
`phonenumber` varchar(255) ,
`major_class` varchar(255)
)
clustered by(id) into 3 buckets
row format delimited fields terminated by ','
stored as orc tblproperties('transactional'='true');
hive里面創建結果表
create table `xsxk`.`xsxk_result` (
`key` varchar(255) ,
`value` varchar(255)) ;
MySQL里面創建接收表
CREATE DATABASE xsxk;
create table `xsxk`.`xsxk_result` (
`key` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`value` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
匯入資料,準備四個flume匯入監聽代碼
首先運行該代碼啟動
hive --service metastore -p 9083
依次運行下面的代碼,每次匯入成功都需要,關閉依次終端(或者啟動多個終端):
flume-ng agent --conf conf --conf-file tb_course.properties -name agent3 -Dflume.hadoop.logger=INFO,console
flume-ng agent --conf conf --conf-file tb_course_class.properties -name agent3 -Dflume.hadoop.logger=INFO,console
flume-ng agent --conf conf --conf-file tb_electives.properties -name agent3 -Dflume.hadoop.logger=INFO,console
flume-ng agent --conf conf --conf-file tb_student.properties -name agent3 -Dflume.hadoop.logger=INFO,console
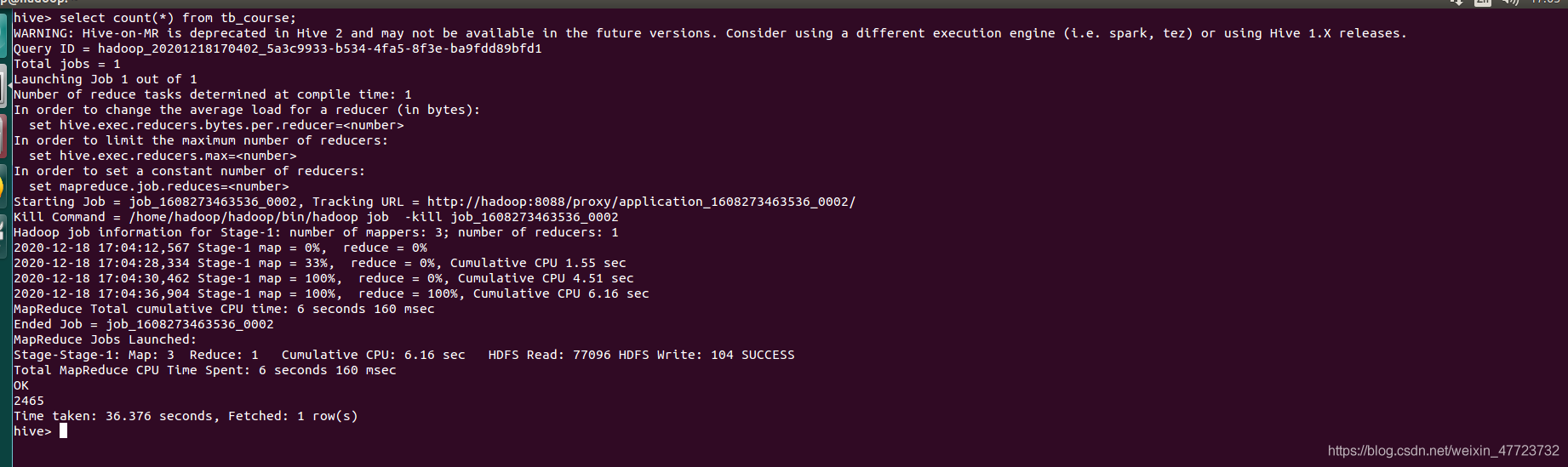
以上就把四個表格全部匯入進去了,下面我們在hive里面查詢一下這些東西是否真的成功了
select count(*) from tb_course;
select count(*) from tb_course_class;
select count(*) from tb_electives;
select count(*) from tb_student;
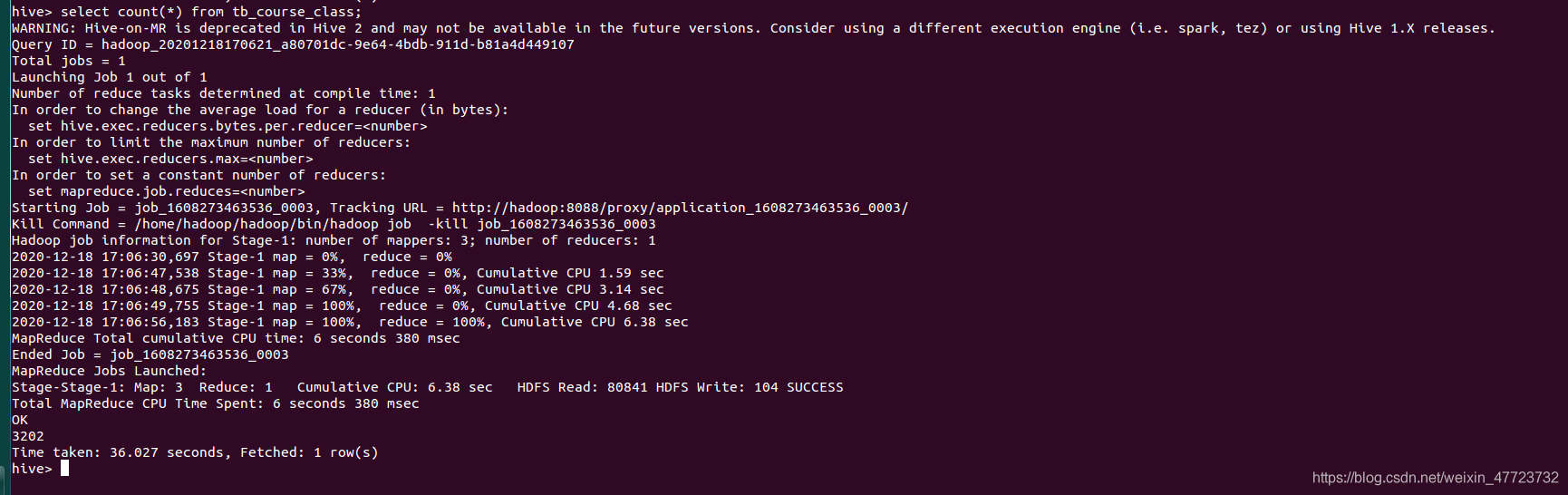
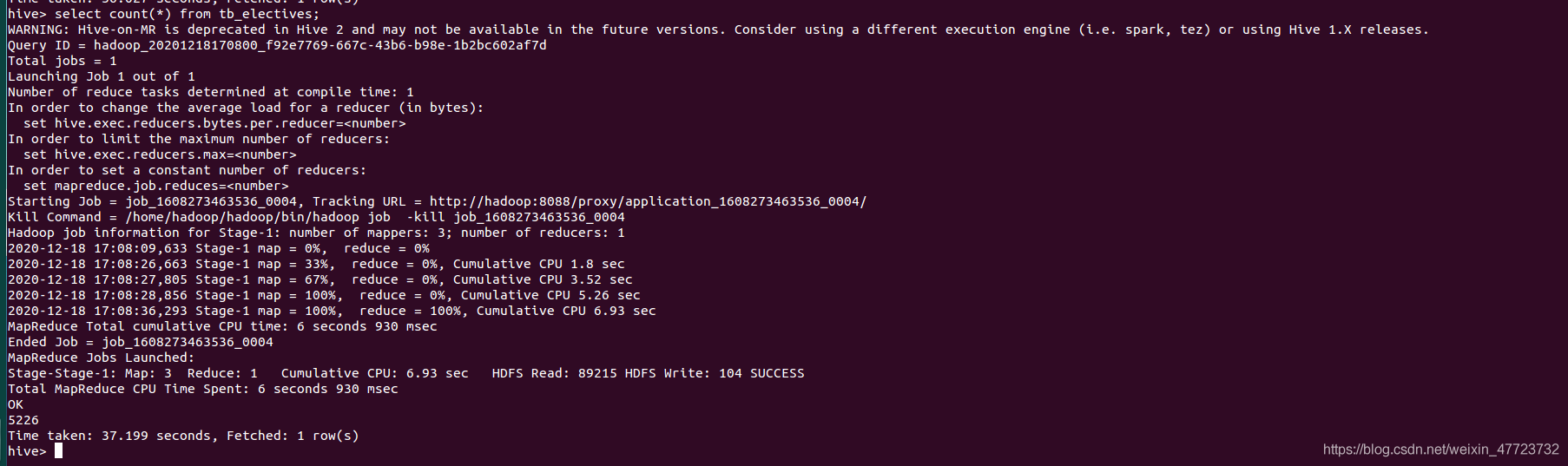
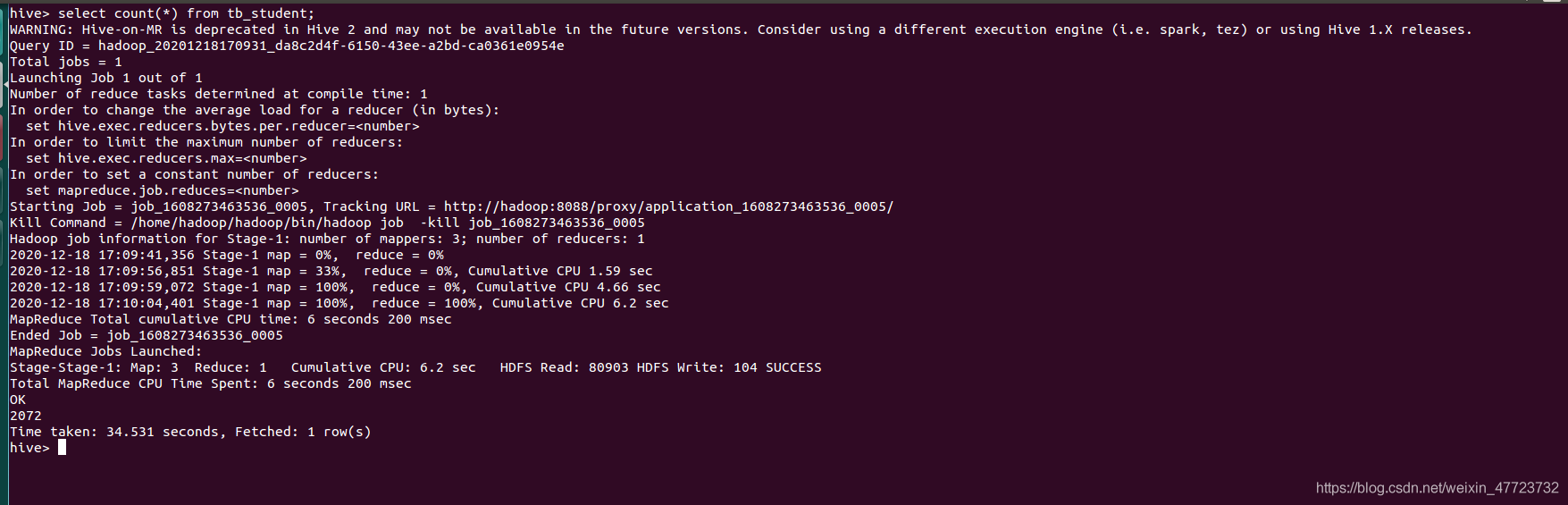
資料分析
這一步是最重要的,我們之前在MySQL里面測驗了的,所以我們直接把這些結果插入到我們的hive結果表里面
注意每次查詢的時候最好先執行這個代碼,因為這個是hive的特性,在多表查詢的時候需要進行等值連接
set hive.mapred.mode=nonstrict;
男女比例
INSERT INTO xsxk_result
(SELECT '男女比例',c.`男女比例` FROM
(SELECT a.`男生人數`/b.`女生人數` as `男女比例` from (SELECT count(*) as `男生人數` from tb_student WHERE gender='男') as a,
(SELECT count(*) as `女生人數` from tb_student WHERE gender='女') as b) as c);
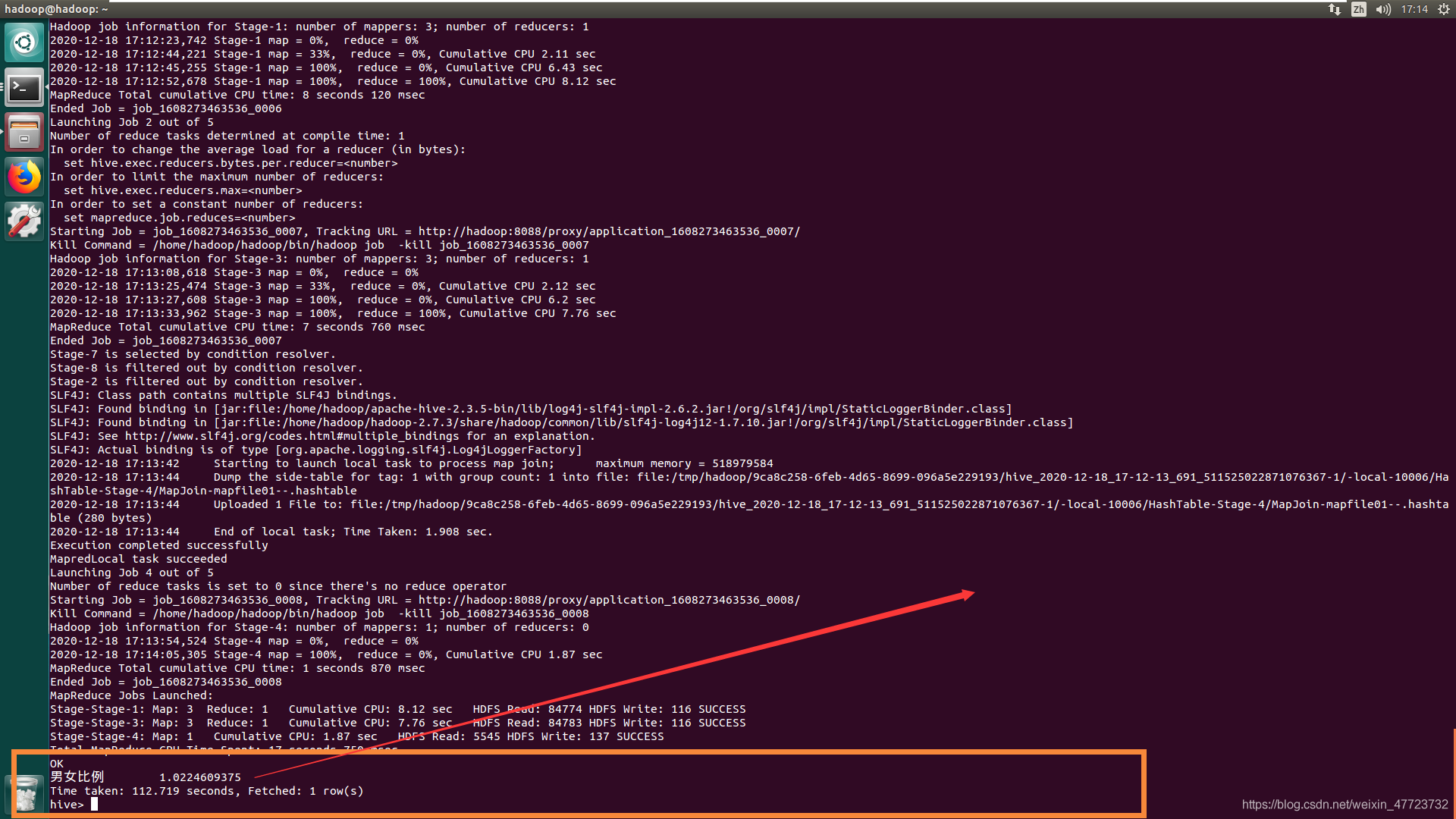
男女結果近似1:1.說明模擬的資料還是比較合理,雖然男生高于女生數量,但是也不是特別的高,
對于男女比例失調的當今社會,我只想說“你有多大的磁場就會有多大的引力,溫水煮青蛙,只能坐井觀天,你想要的只有自己才能給自己”
及格率
INSERT INTO xsxk_result
(SELECT '及格率',c.`及格率` FROM
(SELECT b.`及格人數`/a.`總數` as `及格率` FROM (SELECT count(*) as `總數` from tb_electives) as a,
(SELECT count(*) as `及格人數` from tb_electives WHERE SCORE>='60') as b) as c);
查詢一下剛剛插入到結果表里面的資訊:
select * from xsxk_result;

每門課程的平均分,要求顯示出課程的中文名字
select q.`NAME`,ff.`課程平均分` from tb_course as q,
(SELECT ee.`課程編號`,AVG(ee.`分數`) as `課程平均分` from
(SELECT cc.`COURSE_CODE` as `課程編號`,dd.`平均分` as `分數`from tb_course_class as cc,
(select course_class_code as `班號`,AVG(SCORE)as `平均分` from tb_electives group by course_class_code order by `平均分` DESC) as dd WHERE
cc.`CODE`=dd.`班號`) as ee GROUP BY ee.`課程編號`) as ff WHERE q.`CODE`=ff.`課程編號`
INSERT INTO xsxk_result
(SELECT c.`name` as `課程名稱`,AVG(SCORE) as `平均分` from tb_course as c,tb_electives as e,tb_course_class as cc WHERE cc.`CODE`=e.COURSE_CLASS_CODE and cc.COURSE_CODE=c.`CODE`
GROUP BY c.`CODE` ORDER BY `平均分` DESC);


有2門課不及格的學生
INSERT INTO xsxk_result
(
SELECT s.`NAME` as `姓名` ,'掛科兩門' from tb_student as s JOIN tb_electives as e
on s.ID=e.STUDENT_ID WHERE e.SCORE<60 GROUP BY s.`NAME` HAVING COUNT(s.`NAME`)=2
);
把結果匯出到MySQL里面
sqoop export --connect jdbc:mysql://localhost:3306/xsxk --username root -P --table xsxk_result --export-dir /user/hive/warehouse/xsxk.db/xsxk_result -m 1 --input-fields-terminated-by '\001'
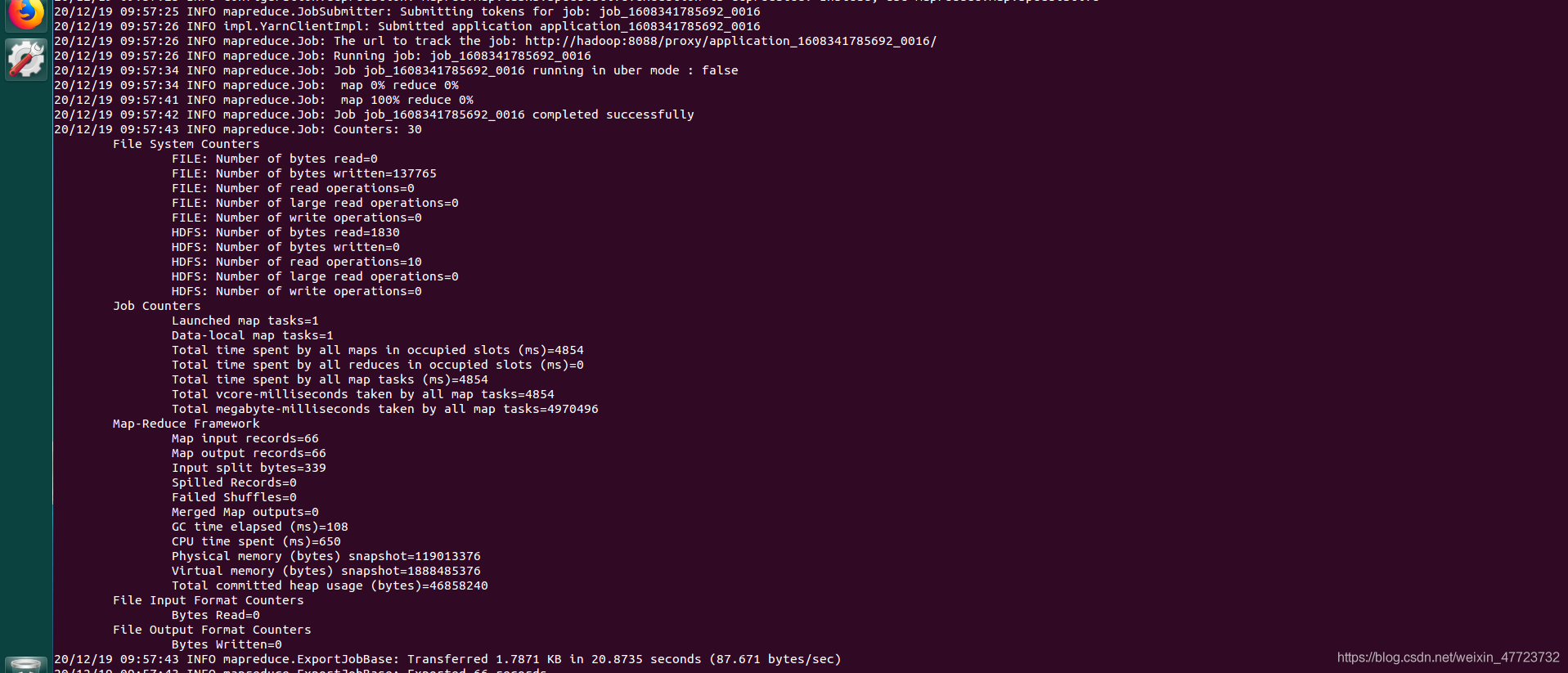

???,為什么MySQL無法顯示中文,這個問題如何解決呢?請把方法留言在評論區,歡迎交流!!
學而不思則罔,思而不學則殆,我這里就不提出解決方法了,我們下期文章會解決該問題,介紹一些常見的工具和采坑解決方法!
Hive操作——洗掉表(drop、truncate)
Hive洗掉操作主要分為幾大類:洗掉資料(保留表)、洗掉庫表、洗掉磁區,
一、僅洗掉表中資料,保留表結構
hive> truncate table 表名;
truncate操作用于洗掉指定表中的所有行,相當于delete from table where 1=1.表達的是一個意思,
注意:truncate 不能洗掉外部表!因為外部表里的資料并不是存放在Hive Meta store中,創建表的時候指定了EXTERNAL,外部表在洗掉磁區后,hdfs中的資料還存在,不會被洗掉,因此要想洗掉外部表資料,可以把外部表轉成內部表或者洗掉hdfs檔案,
二、洗掉表
hive> drop table if exists 表名;
drop table if exists table_name;
三、洗掉庫
hive> drop database if exists 庫名;
注意如果庫里有表會報錯
解決這個錯誤有兩種方法:一、就是很簡單的將所有表先洗掉完,再洗掉庫,
另外一種就是使用下述的方法:使用cascade關鍵字執行強制刪庫,
drop database if exists 庫名 cascade;
四、洗掉hive磁區
alter table table_name drop partition (partition_name=‘磁區名’)
每文一語
低級的欲望靠放縱 高級的欲望靠自律
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/237606.html
標籤:其他
下一篇:大資料人工智能技術全攻略