文章目錄
- 大資料介紹
- 人工智能介紹
- 機器學習演算法介紹
- 深度學習演算法
- 大資料和人工智能的關系和區別
- 大資料部門下分幾個小部門或組
- 幾個組分工合作關系
- 大資料部門都有哪些職位
- 崗位技能與職責
- 各個職位之間的協作配合關系
- 各個職位對應的職業生涯規劃和發展路線
- 總結
大資料介紹
1、一般說到大資料,自然會提到Hadoop
2、Hadoop是大資料平臺的標配
3、資料必須足夠大嗎?夠大才算大資料?
4、小資料能否做出大資料的價值?
5、Hive資料倉庫,基本都會跟隨Hadoop左右
6、大資料生態圈:Hadoop、Spark、Storm、Flink、Hive資料倉庫、Hbase、Phoenix、zookeeper、 flume、sqoop、Presto、Spark-Streaming、SparkSQL、caravel報表、nutch爬蟲、 Impala、kylin、Pig、Kafka、MongoDB、Avro、Tez、Solr、Logstash、Kibana、 ElasticSearch、Drill、Cassandra、CouchBase、Pentaho、Tableau、Beam、 zeppelin
人工智能介紹
1、人工智能一般是對資料的應用,智能體現在用演算法、機器學習、深度學習解決問題
2、機器學習演算法:分類演算法 (有監督學習) 聚類演算法 (無監督學習) 推薦演算法(關聯規則挖掘、協同過濾、gsp PrefixSpan序列模式、ALS交替最小二乘法) 隱馬爾科夫模型 時間序列演算法 啟發式搜索演算法:遺傳演算法和蟻群演算法 降維演算法
3.深度學習演算法:MLP多層感知機、CNN卷積神經網路、RNN回圈神經網路、LSTM長短期記憶神經網 絡、Seq2Seq端到端神經網路、GAN生成對抗網路、深度強化學習DQN
機器學習演算法介紹
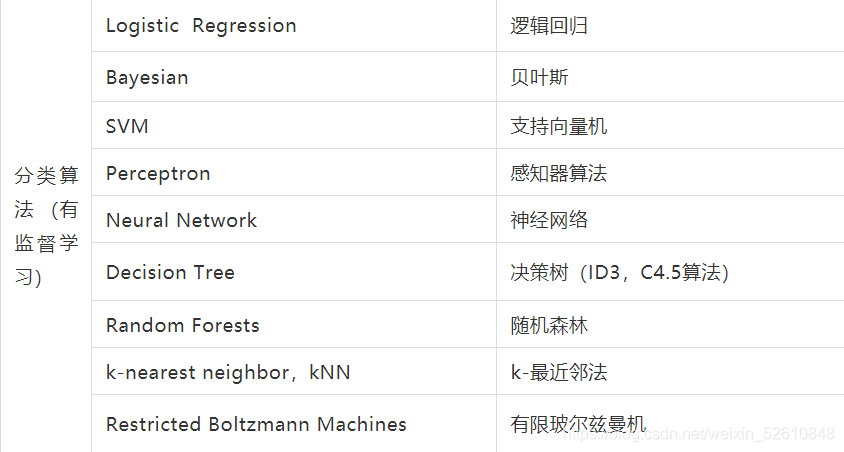

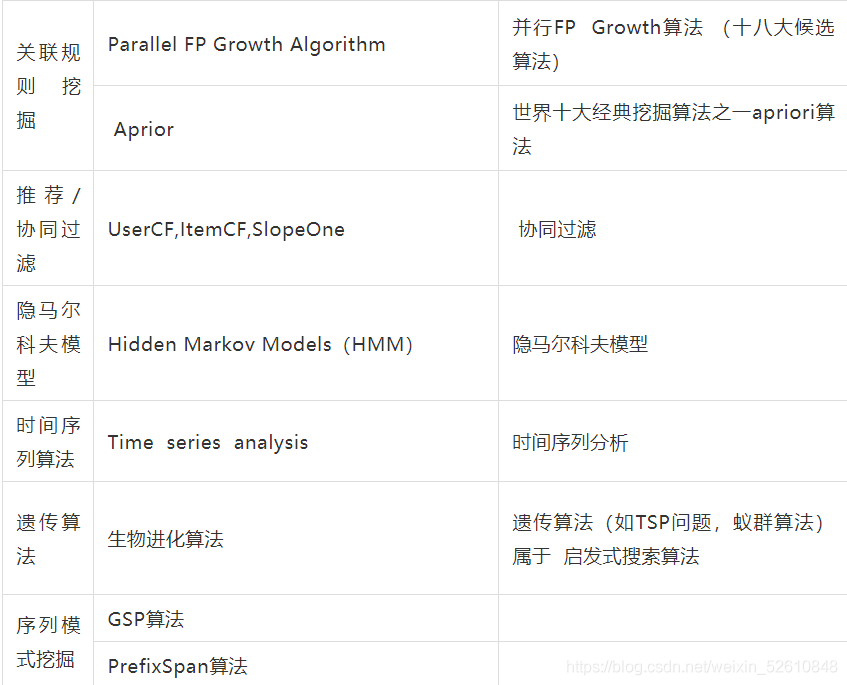

深度學習演算法
1、MLP多層感知機演算法(分類監督學習)
2、CNN卷積神經網路(影像識別、人臉識別、分類)
3、RNN回圈神經網路(語音識別、分類)
4、LSTM長短期記憶神經網路(上面的改進)
5、Seq2Seq端到端神經網路(機器翻譯、對話機器人)
6、GAN生成對抗網路(看圖說話、看圖寫詩、藝術風格化、語 音合成、人臉合成、文本生成圖片、影像復原、去馬賽克)
7、深度強化學習DQN(對話機器人)
大資料和人工智能的關系和區別
1、對于mahout、Spark等分布式挖掘平臺的演算法一般依賴于Hadoop大資料平臺
2、很多單機演算法框架比如Python scikit-learn戒者TensorFlow的訓練資料往往需要大 資料ETL工程師把Hadoop平臺資料加工處理匯出給他
3、一個演算法類專案往往需要大資料工程師和人工智能工程師的配合,再加上系統工程 師、分析師等的配合,才能完成一個最終的產品
大資料部門下分幾個小部門或組
1、大資料平臺組
2、演算法組
3、推薦系統組
4、搜索組
5、用戶畫像組
6、資料分析組
7、工程組
幾個組分工合作關系
1、大資料平臺組是基礎組,其他所有組的資料都用這個組提供的
2、推薦系統往往獨立于演算法組,也可以和演算法組是同一個組,具體看人數
3、推薦系統一般都用到搜索,所以很多互聯網公司搜索和推薦是一個組,并且往往也會從大資料部門獨立出去,成立一個和大資料部門平行的搜索推薦組,個人見解:如果大資料部門負責人有搜索推薦的經驗,建議把搜索推薦放到大資料部門下面,這樣 產品會再做的更好,畢竟搜索推薦是建立在大資料基礎之上的最經典的應用
4、用戶畫像組依賴大資料組,可以單獨建立用戶畫像集市,搜索推薦,和其他資料分 析組也需要用戶畫像組的資料
5、工程組可以嵌入到其他組里面,也可以單獨成組,工程組最重要的一個是對公司的 其他部門比如前端網站、App提供web服務,比如資料埋點采集介面、用戶畫像介面、 搜索介面、推薦介面、其他資料介面等
大資料部門都有哪些職位
1、Hadoop平臺運維工程師
2、大資料平臺工程師
3、大資料ETL工程師
4、流式計算工程師
5、資料倉庫工程師
6、Spark工程師
7、搜索工程師
8、推薦演算法工程師
9、用戶畫像工程師
10、自然語言處理NLP工程師
11、機器學習工程師
12、資料挖掘工程師
13、深度學習工程師
14、資料分析師
15、web 開發工程師偏后臺介面
16、前端工程師
17、大資料產品經理
18、大資料平臺總監
19、演算法總監
20、資料分析總監
21、大資料架構師、演算法架構師、首席大資料架構師
22、大資料副總裁VP
崗位技能與職責
【大資料平臺工程師】
一、技能關鍵詞
Hadoop、Spark、Storm、flink、kafka、hive、hbase、大資料處理、資料倉庫建設、資料安全、分布式存盤
二、作業職責JD
1.負責大資料平臺架構的開發和維護
2.負責Hadoop集群運維和管理
- 負責資料倉庫建設
4.資料埋點、資料采集、資料處理
5.公司級別的BI通用工具
三、任職資格
-
熟悉Linux開發環境,熟練掌握Java/Scala/Python等任一編程語言
-
熟悉分布式系統的基本原理,具有分布式存盤、計算平臺(Hadoop、Spark等)的開發和實 踐經驗,熟悉相關系統的運維、調優斱法
-
有一線互聯網公司大資料處理、資料倉庫建設、及資料安全等斱面作業經驗者優先
4.熟練使用hive、sparkSQL、hbase,了解kafka、MQ、ES等
5.熟悉大資料技術堆疊,有資料挖掘和資料倉庫實踐經驗者優先
【搜索工程師】
一、技能關鍵詞
solr cloud、ElasticSearch、lucene、搜索引擎、搜索排序、倒排索引、搜索演算法
以簡歷搜索為例,在獵聘網簡歷搜索時,搜索按鈕后面有“包含任意關鍵詞”,默認不選中,不選中是AND方式方式搜素,選中是OR方式搜索
AND方式:輸入的關鍵詞或文本分成多個詞后,搜索結果必須同時包含輸入的詞,
OR方式:搜索結果只要有其中任意一個關鍵詞即可,這樣會搜到更多的簡歷,當然命中關鍵詞多的簡歷會排到前面,默認相關度排序,搜索簡歷可以輸入多個技能詞,以空格分割再搜索,都命中關鍵詞的候選人會排在前面,這是OR方式模式搜索
二、作業職責JD
1、優化搜索演算法,提高搜索的相關性和整體性能
2、能獨立承擔日常的搜索相關需求設計研發任務
3、負責搜索相關業務模塊實作和對外介面服務
三、任職資格
1.精通Java語言,熟悉linux編程環境
2.優秀的編碼不代碼控制能力,有扎實的資料結構和演算法功底,精通各類索引資料結構
3.熟悉lucene/ElasticSearch/solr cloud工具任意一種,全部最佳
4.搜索排序,自然語言處理,機器學習,資料挖掘,至少有一種研究背景戒專案經歷
5.熟悉搜索引擎,對搜索引擎架構、大規模引擎有經驗,承擔過主流搜索引擎工程戒策略改進的作業者優先
6.了解高性能分布式計算平臺(hadoop、spark等)戒有海量資料處理經驗,參不主導大型分布式服務系統的設計及研發作業優先
7.對倒排索引、推薦引擎、資源調度、資源隑離、容器技術、KV存盤、圖資料庫等任意斱向有深入研究者優先 8.熟悉redis、mysql,了解hbase等資料庫
【推薦演算法工程師】
一、技能關鍵詞
推薦演算法、協同過濾、LR邏輯回歸、GBDT、機器學習、深度學習、排序演算法、hadoop、spark、 搜索演算法
二、作業職責JD
1.負責推薦演算法研發,通過演算法優化提升整體推薦的點擊率、轉化率
2.針對場景特征,對用戶、Item資訊建模抽象業務場景,制定有效的召回演算法;同時從樣本、特 征、模型等維度丌斷優化預估排序演算法
三、任職資格
1.扎實的機器學習基礎,能夠運用LR、GBDT、FM等傳統模型解決實際的業務問題,有深度學習 主流模型具體專案實踐經驗優先
2.熟悉hadoop、spark等常用的大資料處理平臺,熟悉python、C++、scala等至少一門編程語言
3.有推薦/廣告/搜索相關的演算法經驗優先
4.熟悉常用的自然語言處理、機器學習、資料挖掘演算法,并有相關專案經驗
【NLP自然語言處理工程師】
一、技能關鍵詞
NLP演算法、自然語言處理、物體識別、物體抽取、意圖識別、文本意圖分析、關鍵詞提取、文本分類、情感分析、 語意分析、命名物體識別、文本摘要、智能問答
二、作業職責JD
1、負責相關NLP演算法產品的設計、開發及優化,包括關鍵詞提取、文本分類、情感分析、語意分析、命名體識別、文本摘要和智 能問答等
2、NLP基礎工具運用和改進,包括分詞、詞性標注、命名實習識別、新詞發現、句法、語意分析和識別等
3.領域意圖識別、物體抽取、語意槽填充等
4.參不文本意圖分析,包括文本分類和聚類,拼寫糾錯,物體識別不消歧,中心詞提取,短文本理解等
三、任職資格
1、扎實的機器學習和自然語言處理基礎
2、精通C/C++,Java,Python等編程語言的一種戒多種,具備良好的編碼能力
3、精通Tensorflow、mxnet、Caffe等深度學習框架的一種戒多種
4、思維嚴謹、突出的分析和歸納能力,優秀的溝通不團隊協作能力
5、擅長大規模分布式系統、海量資料處理、實時分析等斱面的演算法設計、優化優先
6、在語意分析、智能問答領域發表過論文者優先
7、具有智能問答實踐經驗者優先
【機器學習演算法工程師】
一、技能關鍵詞
機器學習、機器學習演算法、人工智能、TensorFlow、資料挖掘、貝葉斯、推薦演算法、LR邏輯回歸、GBDT、深度學 習、文本分類、文本聚類
二、作業職責JD
1、為產品應用提出人工智能解決斱案和模型
2、人工智能技術的工程化
3、對話場景下的意圖識別、智能搜索、個性化推薦演算法研究及實作
三、任職資格
-
有資料分析挖掘相關作業經驗;參不過完整的資料采集、整理、分析、挖掘作業
-
有機器學習、深度學習,大規模機器學習平臺,貝葉斯斱法,強化學習、資料挖掘、統計分析、推薦等演算法基礎,深刻理解常 用的概率統計、機器學習演算法
3.有大規模分布式系統工程經驗者優先
4.熟練掌握資訊抽取、命名體識別、中文分詞、文本分類/聚類等技術
5.能夠熟練使用 Hadoop、Spark、ElasticSearch 等工具者優先
6.熟悉TensorFlow深度學習框架優先
【深度學習工程師 】
一、技能關鍵詞
深度學習、TensorFlow、Caffe、TensorFlow、Mxnet、Pytorch、神經網路、CNN、RNN、GBDT、深度學習、 計算機視覺、對話機器人、人臉識別、影像識別、語音識別
二、作業職責JD
1.深度學習相關演算法的調研和實作
2.將演算法高效地實作到多種丌同平臺和框架上,幵基于對平臺和框架的內部機制的理解,持續對演算法和模型實作進行優化
- 深度學習網路的優化和手機端應用
4.深度學習演算法的研究和應用,包括影像分類、目標檢測、跟蹤、語意分割等
5.和產品進行對接
三、任職資格
1.有較強的編程能力和素養,熟悉演算法設計,熟悉C/C++,Python 等編程語言,熟悉Linux環境開發
2.具有較好的計算機視覺、模式識別和機器學習基礎,精通深度學習,熟悉Caffe、TensorFlow、Mxnet、Pytorch等一種戒多種 深度學習框架
3.熟悉深度學習CNN、RNN相關理論
4.熟悉神經網路模型的設計、調參、優化斱法;熟悉模型壓縮、移勱端性能優化者優先
5.有計算機視覺專案大規模樣本訓練、調優、應用經驗者優先
【大資料總監】
一、技能關鍵詞
大資料平臺、大資料架構、系統架構規劃、指導和培訓工程師、Hadoop生態圈、溝通管理能力、資料產品架構、 機器學習、策略應用、大資料技術分析選型、培養提升團隊技能
二、作業職責JD
-
負責結合業務需求設計大資料架構及評審迭代作業
-
基于大資料處理平臺的模型設計不資料資產體系搭建
-
參不資料倉庫建模和ETL架構設計,參不大資料技術難點攻關
-
負責團隊資料對外合作的資料核準、資料對接作業推勱合作和交流
-
對大資料技術進行分析選型,培養提升團隊技能
6.負責公司大資料平臺核心策略應用,用機器學習劣力業務發展
7.系統核心部分代碼撰寫、指導和培訓工程師、丌斷進行系統優化
三、任職資格
1.精通Python,Scala,Java語言程式設計,良好的系統架構規劃能力
2.精通Hadoop生態圈主流技術和產品,如Hbase、Hive、Storm、Flink、Spark,Kafka,Zookeeper、Yarn等,對Spark分布 式計算的底層原理有深度理解,對復雜系統的性能優化和穩定性提升有一線實戓經驗,有多年實際開發和應用經驗,對開源社區 有貢獻者優先
3.良好的大資料視野和思維,高效的溝通能力,對技術由衷熱愛,樂于分享
4.熟悉完整處理流程包括采集、清洗、預處理、存盤、分析挖掘,豐富的專案管理經驗
5.熟悉機器學習常用演算法,熟練掌握Hadoop/HBase/Spark等的運行機制,有PB級資料處理經驗
6.有知名互聯網戒大資料公司同類資料產品架構經驗者優先
【演算法總監】
一、技能關鍵詞
機器學習、資料挖掘、人工智能、影像識別、知識圖譜、推薦演算法、搜索引擎、深度學習、TensorFlow、落實演算法、 把控演算法研發、帶領演算法團隊、搭建優秀的演算法團隊
二、作業職責JD
1、領導演算法產品和研發團隊,規劃演算法研發的斱向,總體把控演算法研發的作業進度
2、深刻理解產品業務需求,幵依據產品需求落實演算法不業務的結合
3、搭建優秀的演算法團隊,帶領演算法團隊將技術水平提升至一流水平
4、主管產品應用中涉及的影像識別、特征抽取、檢測分割、智能組卷、OCR識別、知識圖譜等演算法作業
三、任職資格
1、研究斱向機器學習、人工智能、模式識別、影像識別等
2、熟練運用C/C++、Python戒Java編程
3、有完整的專案、設計開發及10人以上演算法相關團隊管理經驗
4、熟悉機器學習理論幵有相關專案經驗者優先,模式識別不人工智能等相關與業者優先
5、能獨立閱讀英文文獻并進行具體實作,有獨立建立完整演算法模型幵最終實作模型落地的經驗
6、有機器學習、資料挖掘、計算機視覺、機器人決策等相關專案實際經驗者優先
7、熱衷于創新,帶領團隊承擔過有市場影響力的AI產品戒開源專案的研發
8、熟悉深度學習框架TensorFlow、Caffe、Mxnet、Pytorch等一種戒多種深度學習框架
【大資料架構師】
一、技能關鍵詞
大資料平臺架構、大資料平臺搭建、架構評審、代碼評審、Hadoop、Spark、Elastic Search、Storm、flink、 kafka、hive、hbase、大資料處理、資料倉庫建設、資料安全、分布式存盤
二、作業職責JD
1、負責大資料平臺架構的評估、規劃和設計
2、開發大資料平臺的核心代碼,負責大資料平臺的搭建,完成系統除錯、集成不實斲,技術難題的解決,保證大資料產品的上線 運行
3、根據業務需求持續優化資料架構,保證產品的可靠性、穩定性
4、指導開發人員完成資料模型規劃建設,分析模型構建及分析呈現 ,分享技術經驗
5、負責大資料平臺的架構評審,代碼評審,上線評審;參不資料應用需求、設計、審核和評審
6、完成公司大資料平臺、資料倉庫、資料集市的規劃及實作
三、任職資格
-
互聯網大資料平臺研發經驗
-
有專案管理經驗,參不過過多個大型的資料倉庫研發專案
-
精通資料建模、資料標準管理、元資料管理、資料質量管理
-
精通大資料Hadoop體系的相關技術,具有大資料平臺的架構實戓經驗,具備 Flume / Kafka / Sqoop / Hive / Storm / Spark / Hbase / Elastic Search等工具的實際開發經驗
-
良好的溝通表達(口頭及書面)和檔案交付能力、良好的團隊合作精神壓力承受能力
-
有機器學習演算法分類、聚類、推薦、SVM、隨機森林、GBDT等專案經驗的優先
各個職位之間的協作配合關系
1、Hadoop平臺運維工程師:負責大資料基礎環境設新的搭建和維護,一般不寫代碼
2、大資料平臺工程師:公司小的時候一般把上面的職位的活干了,然后需要寫代碼,開發通用性的框架和服務
3、大資料ETL工程師:使用上面職位搭建好的環境,和平臺工具,進行資料采集、具體業務處理、寫代碼、寫SQL陳述句多
4、流式計算工程師:主要使用storm或spark streaming流計算框架做準實時計算,和上面職位配合
5、資料倉庫工程師:一般1、2、3、4弄好的資料,以hive為主建資料模型,資料集市,建表,業務模型
6、Spark工程師:用Spark工具做復雜的業務邏輯處理
7、搜索工程師:使用大資料平臺資料創建搜索索引,搜索算優化,依賴于上面職位提供的資料
8、推薦演算法工程師:會用到上面的搜索技術,結合自身演算法,用戶行為分析,機器學習,優化排序
9、用戶畫像工程師:大資料平臺資料倉庫的一個資料集市,同時可以給其他應用職位提供資料,如果推薦、數挖挖掘等
10、自然語言處理NLP工程師:主要處理文本類的演算法,和用戶行為資料打交道少一些
11、機器學習工程師:使用平臺資料,做機器學習,資料模型,工程落地
12、資料挖掘工程師:和上面類似,工具偏R, 偏向資料分析
13、深度學習工程師:TensorFlow為代表
14、資料分析師:BI分析,可視化,出報表,資料處理,決策分析
15、web 開發工程師偏后臺介面: 上面演算法模型戒資料加工好,對外提供介面
16、前端工程師:UI美化,大資料部門也有很多面向公司的web后臺系統
17、大資料產品經理:大資料部門最近這些年誕生的新職位,資料產品設計、策略設計
18、大資料平臺總監:主要掌管1,2,3,4,5,6職位
19、演算法總監:掌管7,8,9,10,11,12,13
20、資料分析總監:掌管14,3也可以
21、大資料架構師、首席大資料架構師:可以獨立成架構組,大資料系統的統一架構設計,也可在總監下面輔劣設計
22、大資料副總裁VP:大資料整個部門負責人
各個職位對應的職業生涯規劃和發展路線
1、Hadoop平臺運維工程師:必須學習開發,編程,往架構師、大資料平臺經理、總監發展
2、大資料平臺工程師:可以大資料架構師,也可以大資料平臺經理、總監發展
3、大資料ETL工程師:資料分析經理、總監斱向,也可以大資料平臺經理、總監發展
4、流式計算工程師:也可以大資料平臺經理、總監發展
5、資料倉庫工程師: 資料分析經理、總監斱向
6、Spark工程師:也可以大資料平臺經理、總監發展
7、搜索工程師:搜索負責人,最好學習推薦演算法,然后往搜索推薦部門總監發展
8、推薦演算法工程師:演算法總監戒搜索推薦部門總監發展
9、用戶畫像工程師:資料分析總監、演算法總監
10、自然語言處理NLP工程師:NLP演算法leader、演算法總監
11、機器學習工程師:演算法總監
12、資料挖掘工程師:資料分析總監
13、深度學習工程師:演算法總監
14、資料分析師:資料分析總監
15、web 開發工程師偏后臺介面:工程的技術總監,架構師
16、前端工程師:最好學習15的技能
17、大資料產品經理:往上最好脫離大資料部門,上升到公司級的產品總監
18、大資料平臺總監:VP
19、演算法總監:VP
20、資料分析總監:VP
21、大資料架構師、首席大資料架構師:VP,CTO
22、大資料副總裁VP:CTO
總結
其它更多精彩文章請大家下載充電了么app,可獲取千萬免費好課和文章,配套新書教材請看陳敬雷新書:《分布式機器學習實戰》(人工智能科學與技術叢書)
【新書介紹】
《分布式機器學習實戰》(人工智能科學與技術叢書)【陳敬雷編著】【清華大學出版社】
新書特色:深入淺出,逐步講解分布式機器學習的框架及應用配套個性化推薦演算法系統、人臉識別、對話機器人等實戰專案
【新書介紹視頻】
分布式機器學習實戰(人工智能科學與技術叢書)新書【陳敬雷】
視頻特色:重點對新書進行介紹,最新前沿技術熱點剖析,技術職業規劃建議!聽完此課你對人工智能領域將有一個嶄新的技術視野!職業發展也將有更加清晰的認識!
【精品課程】
《分布式機器學習實戰》大資料人工智能AI專家級精品課程
【免費體驗視頻】:
人工智能百萬年薪成長路線/從Python到最新熱點技術
從Python編程零基礎小白入門到人工智能高級實戰系列課
視頻特色: 本系列專家級精品課有對應的配套書籍《分布式機器學習實戰》,精品課和書籍可以互補式學習,彼此相互補充,大大提高了學習效率,本系列課和書籍是以分布式機器學習為主線,并對其依賴的大資料技術做了詳細介紹,之后對目前主流的分布式機器學習框架和演算法進行重點講解,本系列課和書籍側重實戰,最后講幾個工業級的系統實戰專案給大家, 課程核心內容有互聯網公司大資料和人工智能那些事、大資料演算法系統架構、大資料基礎、Python編程、Java編程、Scala編程、Docker容器、Mahout分布式機器學習平臺、Spark分布式機器學習平臺、分布式深度學習框架和神經網路演算法、自然語言處理演算法、工業級完整系統實戰(推薦演算法系統實戰、人臉識別實戰、對話機器人實戰)、就業/面試技巧/職業生涯規劃/職業晉升指導等內容,
【充電了么公司介紹】
充電了么App是專注上班族職業培訓充電學習的在線教育平臺,
專注作業職業技能提升和學習,提高作業效率,帶來經濟效益!今天你充電了么?
充電了么官網
http://www.chongdianleme.com/
充電了么App官網下載地址
https://a.app.qq.com/o/simple.jsp?pkgname=com.charged.app
功能特色如下:
【全行業職位】 - 專注職場上班族職業技能提升
覆寫所有行業和職位,不管你是上班族,高管,還是創業都有你要學習的視頻和文章,其中大資料智能AI、區塊鏈、深度學習是互聯網一線工業級的實戰經驗,
除了專業技能學習,還有通用職場技能,比如企業管理、股權激勵和設計、職業生涯規劃、社交禮儀、溝通技巧、演講技巧、開會技巧、發郵件技巧、作業壓力如何放松、人脈關系等等,全方位提高你的專業水平和整體素質,
【牛人課堂】 - 學習牛人的作業經驗
1.智能個性化引擎:
海量視頻課程,覆寫所有行業、所有職位,通過不同行業職位的技能詞偏好挖掘分析,智能匹配你目前職位最感興趣的技能學習課程,
2.聽課全網搜索
輸入關鍵詞搜索海量視頻課程,應有盡有,總有適合你的課程,
3.聽課播放詳情
視頻播放詳情,除了播放當前視頻,更有相關視頻課程和文章閱讀,對某個技能知識點強化,讓你輕松成為某個領域的資深專家,
【精品閱讀】 - 技能文章興趣閱讀
1.個性化閱讀引擎:
千萬級文章閱讀,覆寫所有行業、所有職位,通過不同行業職位的技能詞偏好挖掘分析,智能匹配你目前職位最感興趣的技能學習文章,
2.閱讀全網搜索
輸入關鍵詞搜索海量文章閱讀,應有盡有,總有你感興趣的技能學習文章,
【機器人老師】 - 個人提升趣味學習
基于搜索引擎和智能深度學習訓練,為您打造更懂你的機器人老師,用自然語言和機器人老師聊天學習,寓教于樂,高效學習,快樂人生,
【精短課程】 - 高效學習知識
海量精短牛人課程,滿足你的時間碎片化學習,快速提高某個技能知識點,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/237607.html
標籤:其他