寫在前言:【著作權宣告】本作品為作者原創,請勿在未與作者聯系的情況下隨意盜取、抄錄文章;作者水平有限,若閱讀時發現錯誤,歡迎向作者留言提問,在此敬謝全體讀者!
文章目錄
- 程式設計導引
- 資料結構
- 程式設計導引概述
- 程式
- 演算法
- 高級語言
- 基本的資料結構
- 線性結構(1:1)(基本上=>線性表)
- 線性表(==最常用且最簡單的一種資料結構==)
- 線性表的存盤結構(*或稱為物理結構*)(陣列與鏈表)
- ==操作受限的線性表==
- 堆疊
- 佇列
- ==樹形結構==(1:n)
- ==圖形結構==(n:m)
- 軟體程序
- 程式設計方法
- 模式化方法
- 結構化程式設計方法
- 面向物件程式設計方法
- 面向程序程式設計方法
- 軟體生命周期(軟體程序----軟體工程)
- ==瀑布模型==:
- 定義階段
- 計劃
- 需求分析
- 開發階段
- 設計
- 編碼實作 [^12]
- 軟體測驗[^13]:
- 維護階段
- 部署[^14]:
- 軟體維護[^15]
- 瀑布模型的優缺點
- 優點
- 缺點
- RUP模型
- Scrum模型
- ICONIX模型
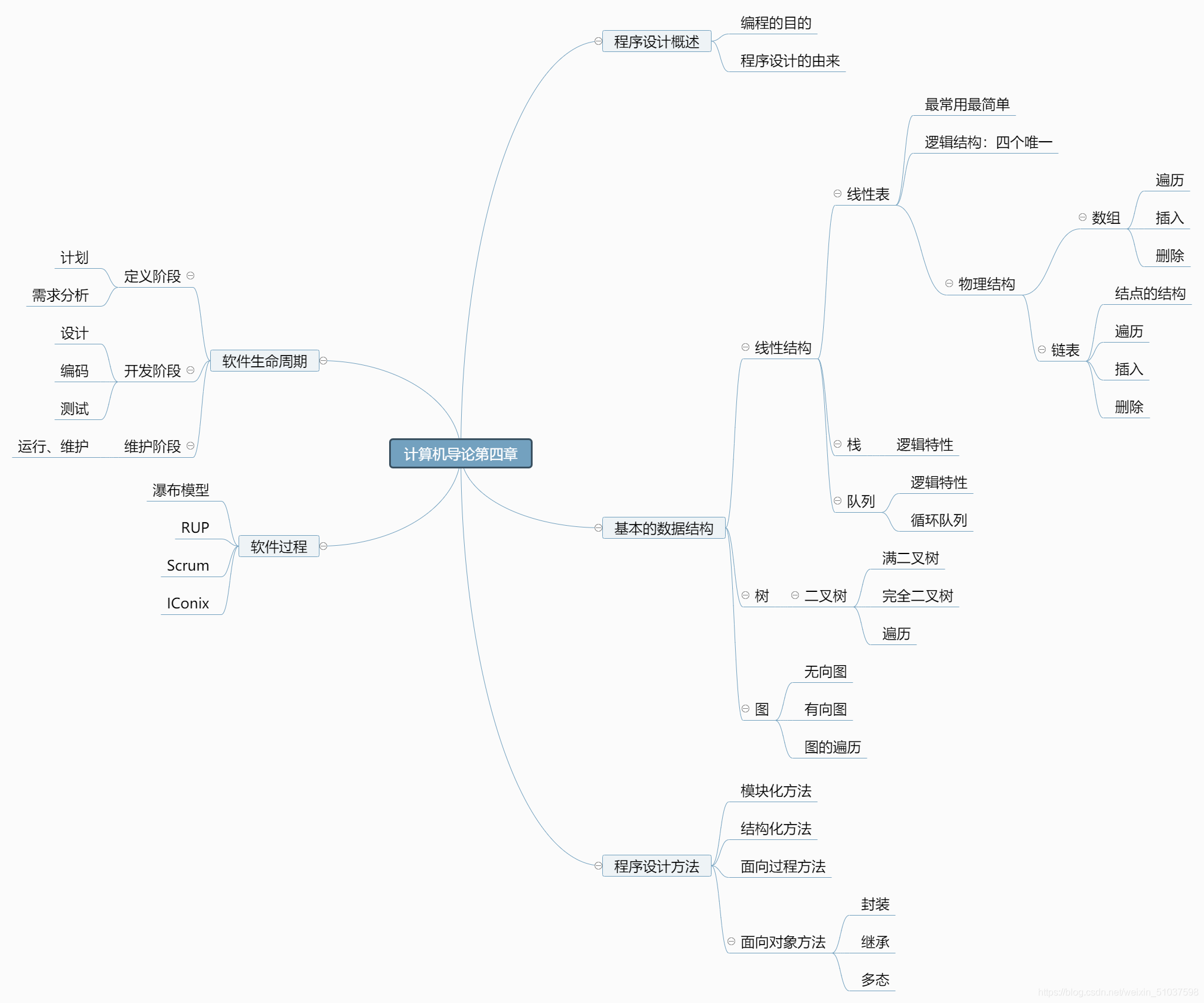
程式設計導引
資料結構
程式設計導引概述
有幾個重要的概念:程式;演算法;高級語言
程式
- 程式的概念:計算機程式是一組計算機能識別和執行的指令,運行于電子計算機上,滿足人們某種需求(或為幫助用戶解決問題的資訊化工具,【程式是一個指令序列(或可理解為檔案集合)】
- 程式設計語言的概念:用于書寫計算機程式的語言,人與計算機打交道時交流資訊的一類媒介和工具,由陳述句(statement)組成,(注:代碼需符合語言規范)
- 大致運行程序:程式以某些程式設計語言撰寫,運行于某種目標結構體系上,打個比方,程式就如同以英語(程式設計語言)寫作的文章,要讓一個懂得英語的人(編譯器)同時也會閱讀這篇文章的人(結構體系)來閱讀、理解、標記這篇文章,一般的,以英語文本為基礎的計算機程式要經過編譯、鏈接而成為人難以解讀,但可輕易被計算機所解讀的數字格式,然后放入運行,(come from 度娘)
演算法
- 概念:演算法(Algorithm)是指解題方案的準確而完整的描述,是一系列解決問題的清晰指令,演算法代表著用系統的方法描述解決問題的策略機制,(百度解釋)
(Wby暴力解釋:演算法即解決問題的方法,其可 以自然語言、流程圖、程式(編程語言)等形式展現) - 評判演算法好壞的因素:
- 時空復雜度
時空復雜度即為時間復雜度與空間復雜度,
(1)顧名思義,一個為時間上的開銷,一個是計算機記憶體空間的開銷(簡言之:占位元組的多少),
(2)一般的演算法不可兼顧兩者,魚和熊掌不可兼得,
例:遞回----時間復雜度低、效率高,但是空間復雜度高(一次又一次地為形參開辟記憶體空間), - 計算機的運行范圍
(1)硬體(硬碟容量、CPU性能、記憶體容量等)是否支持、是否在其承受能力范圍內、其性能是否達標等等
(2)軟體(如作業系統OS)
高級語言
- 計算機程式設計語言經過了從低級到高級的發展程序,
語言處理程式經歷了機器語言、匯編語言、高級語言三個層次,
- 機器語言:計算機直接使用的二進制形式的程式語言或機器代碼,
- 匯編語言:一種面向機器的用符號表示的低級程式設計語言(助記符) ,相當于機器指令的助記符號,與機器語言很接近,
【以上兩者均受機器的限制,通用性不高】 - 高級語言:易被人們理解,完全符號化的程式設計語言
- 計算機只能識別和執行機器語言,高級語言撰寫的程式(源代碼)必須經過“翻譯(都是系統程式----編譯器或解釋器)”才能被執行,
- 編譯(編譯系統):編譯是指在應用源程式執行之前,就將程式源代碼 “翻譯” 成目標代碼(機器語言),
(1)利:其目標程式可以脫離其語言環境獨立執行,使用比較方便、效率較高,
(2)弊:應用程式一旦需要修改,必須先修改源代碼,再重新編譯生成新的目標檔案才能執行,只有目標檔案而沒有源代碼,修改很不方便,
(通常認為C為編譯型語言) - 解釋程式(python)解釋一句執行一句,不產生目標代碼,
執行方式類似于日常生活中的 “同聲翻譯” ,應用程式源代碼一邊由相應語言的解釋器 “翻譯” 成目標代碼(機器語言),一邊執行,
(1)弊:效率比較低,而且不能生成可獨立執行的可執行檔案,應用程式不能脫離其解釋器,
(2)利:這種方式比較靈活,可以動態地調整、修改應用程式,
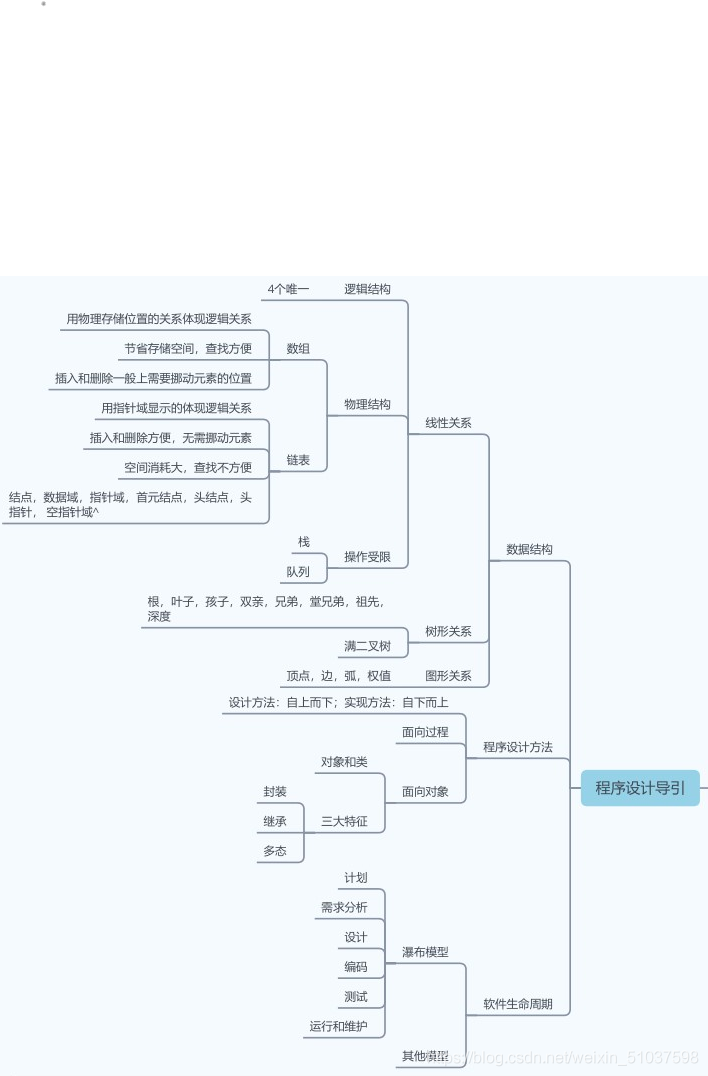
基本的資料結構
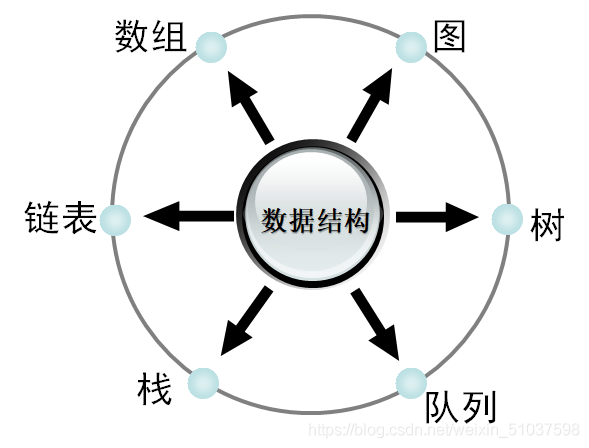
- 邏輯結構分為三種線性結構、圖形結構、樹形結構,其中線性結構的存盤結構(即線性表在記憶體中的體現形式)有陣列(順序存盤)與鏈表(鏈式存盤)
- 邏輯結構:客體在自然環境下的狀態,與計算機無關
- 存盤結構:存盤于計算機記憶體中的結構,演算法基于存盤結構(wby暴力解釋)【存盤時需注意:存盤的不僅有資料元素還有他們之間的關系】
- 用途:必要時可以自己封裝程式—>引入概念:資料型別
- 資料型別(Data Type):
(1)確定資料型別后即可確定:
? 分得多大空間
? 表示多大范圍
? 能做何種運算
(2)兩種資料型別:
- 通用、基本的資料型別:數值型別(整型浮點型)、布爾型型別、字串型別
- 自定義資料型別(即C中的結構體)
可將多種基本資料型別(資料項)組合為一個資料元素,在記憶體中以第一個資料地址(即起始地址)代表該元素的地址,【因:資料元素里的每一個資料項是連續且遞增的】
全體的資料元素稱為資料物件;更大:整體資料集
線性結構(1:1)(基本上=>線性表)
線性表(陣列、鏈表)、堆疊、佇列、串,其中堆疊與佇列為操作受限的線性表
線性表(最常用且最簡單的一種資料結構)

- 特點(邏輯結構):四個唯一:
- 存在唯一被稱為“第一個”的資料元素
- 存在唯一被稱為“最后一個”的資料元素
- 除第一個元素以外,所有的資料元素均只有一個‘前驅’
- 除最后一個元素外,所以的資料元素均只有一個‘后繼’
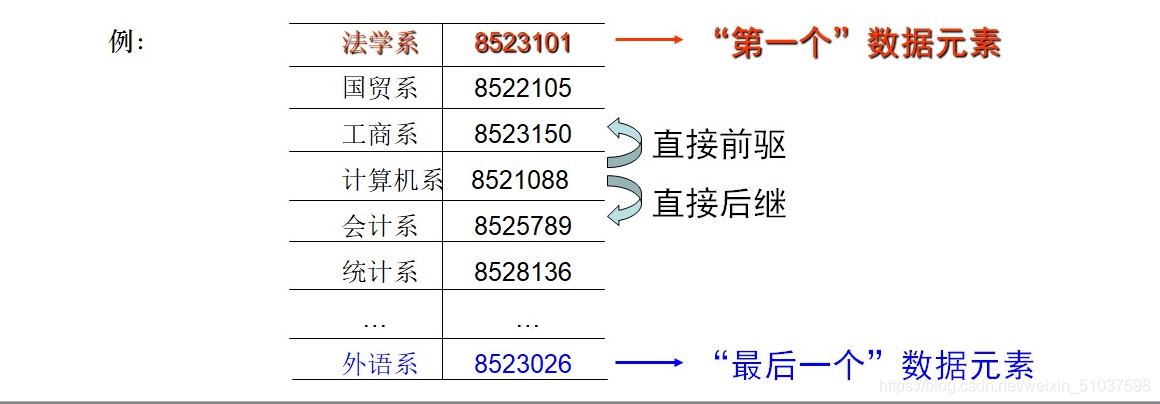
- 應用:花名冊,關系型資料庫等等
線性表的存盤結構(或稱為物理結構)(陣列與鏈表)
- 認識基本操作:
- 遍歷:對每一個元素進行訪問并只訪問(print)一次
- 插入
- 洗掉
- 順序存盤結構(一維陣列)
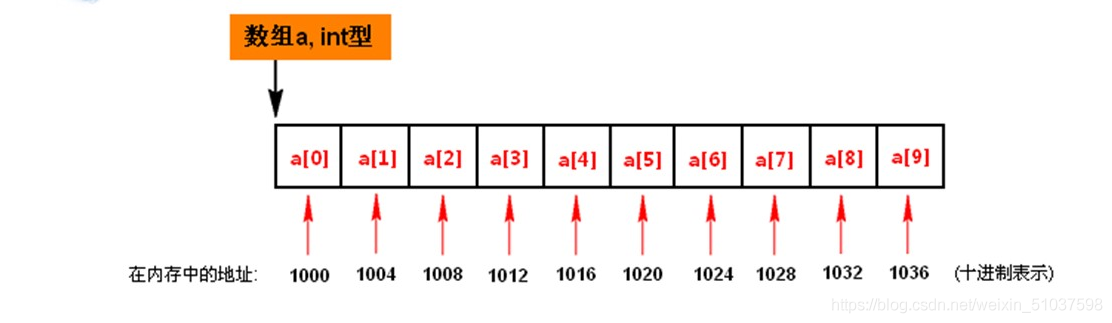
(注:上圖中“在記憶體中的地址”為方便起見,自定義為了十進制,但實際上,真正在計算機內部,地址用二進制表示)
- 概念:用一組地址連續的存盤單元(位元組為最小的存盤單元)(存盤單元的唯一標識:地址)依次存放(即存放空間連續)(實作了用物理存盤位置體現邏輯關系,無需指標)線性結構中的資料元素【實際計算機作業時:由資料線先從記憶體中讀取資料,后將資料傳遞給地址線】
- 核心:用物理存盤位置的關系體現邏輯關系
所有元素都是同一種資料型別,一個元素代表一個(或多個)位元組,所有元素必須連續存放(位元組相連), - 操作原理:確定資料型別后即可確定:
? 分得多大空間
? 表示多大范圍
? 能做何種運算
例: * int型:4B(位元組)
* 字符型:1B(字符即a,b,A之類)
因 為順序結構–>知道第一個資料元素的起始地址
–>知道該元素是第幾個元素
–>知道其資料型別(int/字串型/其他)
便可確定該元素的地址
- 優缺點
(1)優點:隨機存取、查找方便、節省存盤空間
(2)缺點:一般插入、洗掉需移動(多次賦值變數實作)元素位置(除末尾)——>插入1:移動時遵循后面先動原則,洗掉則相反
- 遍歷的實作:
用下標(=>索引)按照上述操作原理,從頭–>尾
注:下標=>索引,但不能畫等號,因:下標僅為正數值,而索引正負皆可(正、逆索引)
- 鏈式存盤(分單向、雙向鏈表、回圈鏈表多種,下面僅詳細說明單向鏈表)(鏈表=>python中的串列)
注:鏈表=>python,但不能畫等號,因:資料型別----鏈表中的資料項資料型別一點相同,但串列則可不同(其可包含數值型、字串型、字典、元組、甚至是串列);串列是python封裝好的,但其性能非最佳,
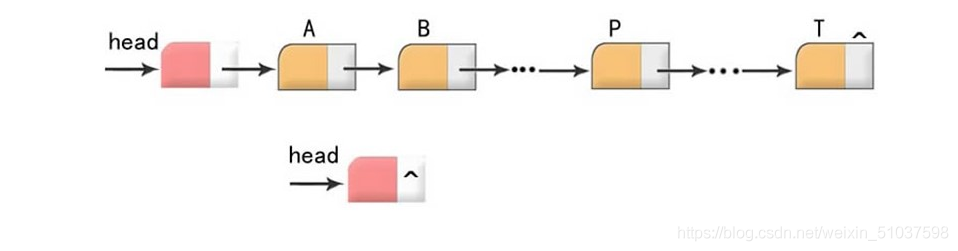
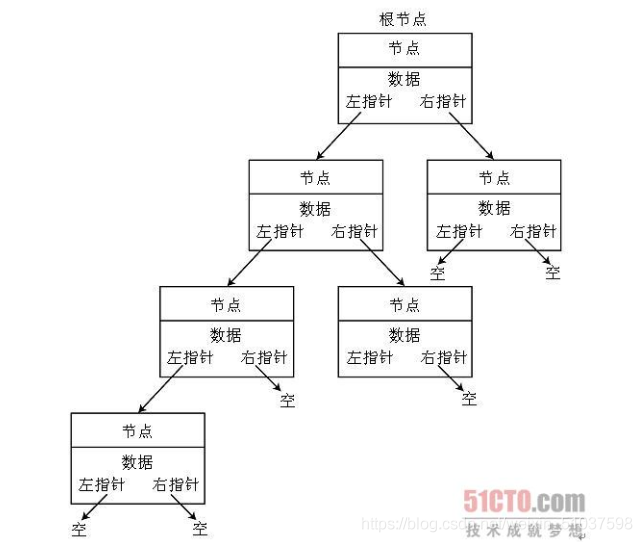
- 幾個概念:重點是將以下幾個概念連接起來,了解結點的結構
(1)結點:資料域2(前)+指標3域4(后)(如上圖中的A、B、P、T)【注:資料域與指標域空間必連續】
(2)首元結點(如上圖A)怎么找到?
①頭指標:僅存放首元結點的指標域
☆②頭結點(比較常用):存放首元結點的位置(有資料域和指標域,但資料域為空[如上圖中紅色背景區域])【引入目的:方便程式員的操作,減少程式員寫代碼的復雜度】
(3)“^”空指標域
即null(表尾常用到,即:最后一個元素地址域為空)
(4)單鏈表兩種形式(如上圖所示)
①第一個為存放完整的鏈表
②第二個為空鏈表----代碼表示:
if head==null:
print(“這是一個空鏈表”) - 核心:用指標域顯示的體現邏輯關系
- 優缺點
(1)優點:插入5、洗掉6無需移動元素
(2)缺點:占記憶體大(或空間消耗大)(資料+指標---->關系顯示占空間)、查找不便(需從頭找)
操作受限的線性表
堆疊與佇列
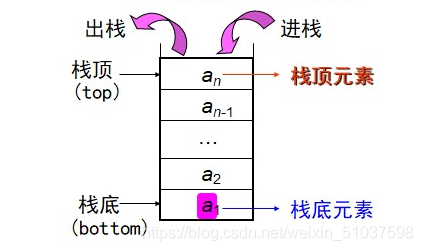
堆疊
順序堆疊、鏈堆疊
- 邏輯特性:后進先出(LIFO結構)(出入個數不管)【注:不可說成 先進后出!!】(類似糖葫蘆)
- 定義:操作受限的線性表(滿足四個唯一)
操作受限:限定在表尾進行插入或洗掉操作
【注:出堆疊順序與入堆疊順序不一定相同】 - 應用
- 十進制轉二進制:除二取余,倒取余數
- 函式:后呼叫的先回傳
- 輸入法:增刪改
- 存盤:順序堆疊、鏈堆疊----堆疊頂指標;堆疊底指標
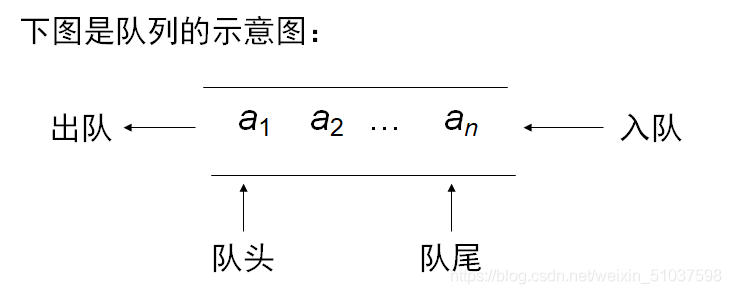
佇列
回圈佇列、鏈佇列
- 邏輯特性:先進先出(FIFO結構)
- 定義:操作受限的線性表(同上)
操作受限:只能在表頭洗掉,表尾插入
【注:入堆疊順序與出堆疊順序一定相同】 - 應用
- 軟體在CPU中運行(就緒佇列的調度演算法:先來先服務演算法FCFS)
- 列印機(排隊)
- 存盤:鏈式存盤----隊頭指標(front);隊尾指標(rear)
概念:假溢位----刪一個其空間可回圈利用
樹形結構(1:n)
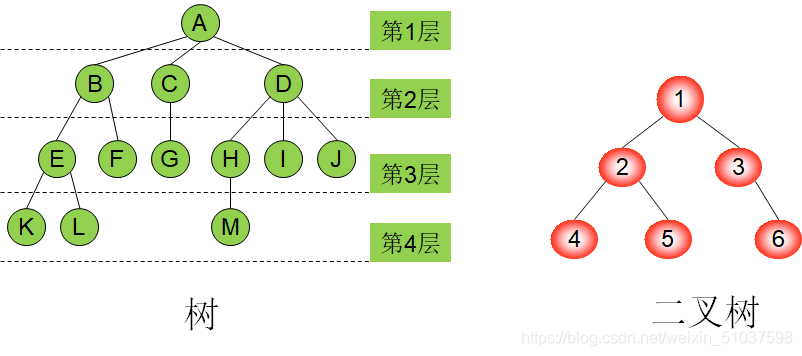
- 本質:遞回
- 認識幾個概念:
- 雙親(僅一個前驅)、祖先(符合自然倫理認知:家族譜)
- 左右孩子、兄弟、堂兄弟(符合自然倫理認知)
- 根節點(圖中A或1)、葉子結點(無直接后繼的結點)
- 深度:樹有幾層
- 特點:除了根節點后的其他結點 組成了若干互不相交的子樹
- 特例:二叉樹
- 定義:每個節點max2個樹(2個分支:左、右支)
- 關系:顯示地左右指標
- 特殊:滿二叉樹:左右指標全滿
n層有2^n-1個結點 - 完全二叉樹:標號位置同
min:2^(n-1)
max:2^n-1滿二叉樹
- 應用:解壓縮檔案(哈夫曼)
- 存盤:補成完全二叉樹后存盤或遍歷;二叉鏈表:左孩子|資料|右孩子
- 遍歷方式:非完全二叉樹與完全二叉樹分別的遍歷方式
圖形結構(n:m)
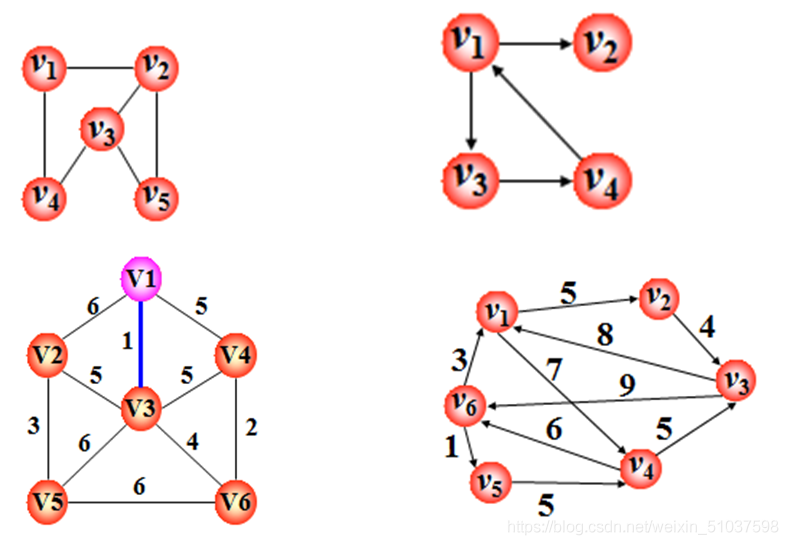
- 幾個概念:
- 頂點(也有資料):v1,v2,v3……
- 邊(雙行道“——”)【無向圖】;弧(單行道“——>”)【有向圖】;關系圖中僅出現邊或弧
- 邊或弧上的值:權值(或叫代價time or cost or distance)
- 邊的數目:度
- 弧①出度:–>
②入度:<–
度數=出度數+入度數 - 帶權值的圖叫網(無向網或有向網)(上圖中下方的兩圖)
- 存盤
順序不能存,鏈式存盤 - 應用
- 最小生成樹演算法
- 最短路徑問題(電信公司或銀行或景區酒店的選址)
- 圖的遍歷
軟體程序
程式設計方法
四種程式設計方法:模塊化方法、結構化程式設計方法、面向物件程式設計方法、面向程序程式設計方法
概念:自上而下
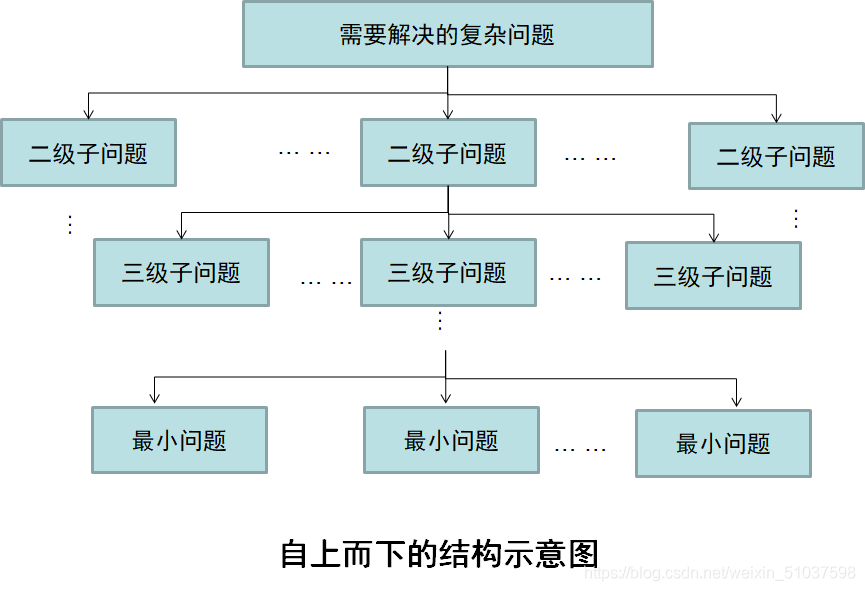
【wby暴力解釋:自下而上的分解、自下而上的實作】
模式化方法
概念:模塊化方法是一種傳統的軟體開發方法,該方法通常將待開發軟體劃分為一些功能相對獨立的模塊,模塊與模塊之間定義相應的介面,各個模塊可以分別單獨開發、除錯、運行、測驗,最后再將多個模塊組合起來,進行整體測驗,從而完成整個軟體的開發,
【wby暴力解釋:大問題分解為小模塊(內部獨立且有功能)---->整合:介面(合作)---->整體:測驗】
結構化程式設計方法
? 采用自上而下、逐步求精的設計方法和單入口、單出口的控制結構(下圖為常見的三種控制結構:順序結構、選擇結構、回圈結構)
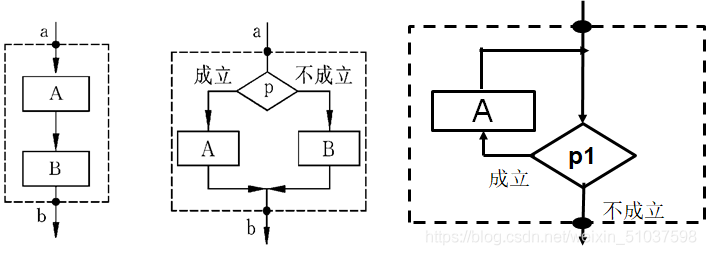 ? 模塊易于識別,每個模塊符合單入口、單出口;
? 模塊易于識別,每個模塊符合單入口、單出口;
? 應該控制goto陳述句使用
面向物件程式設計方法
- 概念:面向物件(Object Oriented,OO)方法的出發點和基本原則,是盡可能地模擬現實世界中人類的思維方式,使開發軟體的方法和程序盡可能地接近人類解決問題的方法和程序,
- ☆它具備四個要點:
– 物件是組成客觀世界的基本元素
– 物件是屬于某個類7的
– 繼承性8
– 訊息傳遞9
- 基本手段:抽象
- 抽象是人類認識問題的基本手段之一,是選擇性忽略,抽象的程序,就是對問題進行分析和認識的程序,
- ☆三大特征:
封裝(屬性----自然屬性與行為屬性 為內部不可見的整體,進行分類,分裝)
繼承(物件—>類,同一類的物件具有相同點)
多型(不同物件反應不同---->模塊的個性化)
面向程序程式設計方法
wby暴力解釋:主要注意步驟,哪一步要干什么,一步一步解決問題,問題求解的程序有唯一確定的代碼(一步到位式),不需模擬人類思維,不用 因人對功能需求的增加 而做出變化,
軟體生命周期(軟體程序----軟體工程)
眾多模型,如瀑布模型、RUP、Scrum、Iconix,在此詳細介紹一種模型:瀑布模型
瀑布模型:
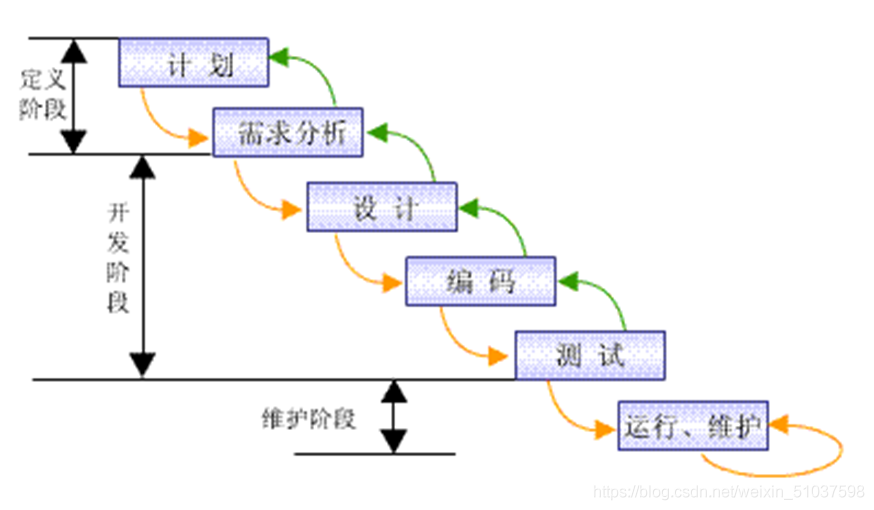
定義階段
計劃

進行可行性研究
- 技術可行性
- 資金可行性
- 社會可行性
需求分析
- 概念:軟體需求分析就是把軟體計劃期間建立的軟體可行性分析 求精和細化,分析各種可能的解法,是確定系統必須完成哪些作業,也就是對目標系統提出完整、準確、清晰、具體的要求,
- 軟體需求包括三個不同的層次:
業務需求、用戶需求和功能需求(也包括非功能求), - 工具:
用例圖10、包圖、類圖、序列圖、活動圖、功能結構圖
開發階段
設計
畫圖(UML圖11)、資料庫設計
編碼實作 12
軟體測驗13:
仿真測驗、性能測驗、穩定性測驗、集成測驗、介面測驗、白盒例外測驗、單元測驗
維護階段
部署14:
將軟體(網頁)放到服務器上
軟體維護15
瀑布模型的優缺點
優點
– 為專案提供了按階段劃分的檢查點
– 當前一階段完成后,您只需要去關注后續階段
缺點
– 在專案各個階段之間極少有反饋,
– 只有在專案生命周期的后期才能看到結果,
– 通過過多的強制完成日期和里程碑來跟蹤各個專案階段,
– 不適應用戶需求的變化
RUP模型
- RUP模型(Rational Unified Process,統一軟體開發程序,統一軟體程序)是一個面向物件且基于網路的程式開發方法論,
- 因為軟體越發復雜,不可能一次性就能把軟體做的完整,而RUP可以用迭代開發來更好的應對變化,使軟體的實踐更加完整,
Scrum模型
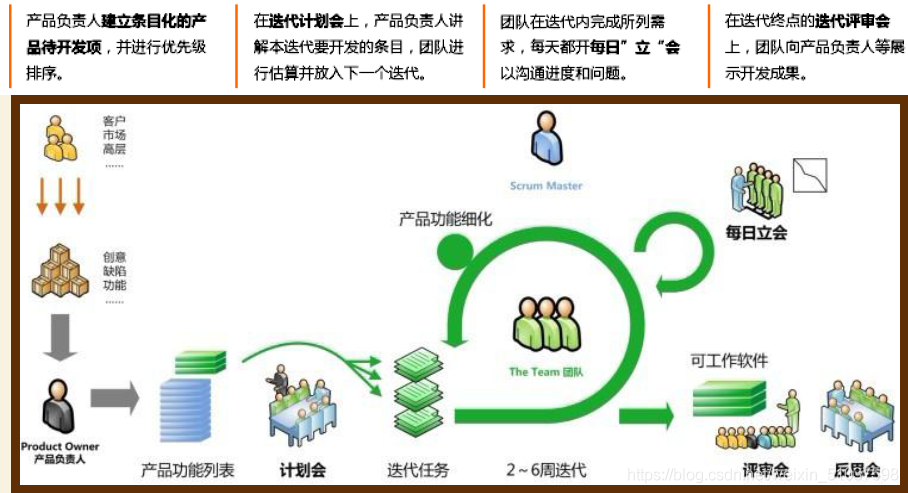
Scrum是一種迭代式增量軟體開發程序,通常用于敏捷軟體開發,Scrum包括了一系列實踐和預定義角色的程序骨架,
ICONIX模型
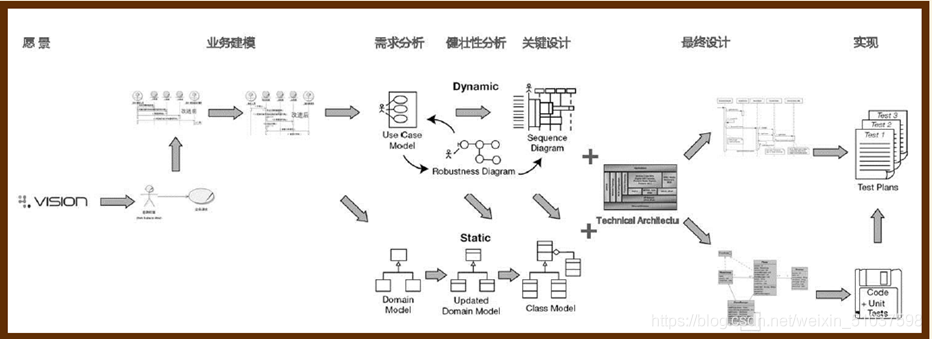
- ICONIX是盡早進入編碼階段,縮短分析設計周期的軟體開發方法
- ICONIX程序是一種以最少步驟實作從用例到代碼OOAD[object-oriented analysis and design]方法學,并覆寫了軟體程序中所有關鍵的環節,
寫在最后:本篇文章中的所有圖片及個別段落出自于河北師范大學軟體學院內部資料
1.最后有個空位,向后推進,2.洗掉一個資料,再插入,3.移動(實際上為多次賦值操作)例:(以python為例)a[6]=a[5], a[5]=a[4], a[4]=20 ??
資料域:存放資料 ??
指標:①本質:后繼元素的地址②用途:描述元素間關系 ??
指標域【或叫后繼域】:存放下一個結點的地址,以方便查找 ??
插入:找一個結點(生成空間---->資料域+指標域),先把資料存下防止丟失(資料域中),再存下下一個結點的地址(指標域中)【最后一個元素地址域為空(不連續)】
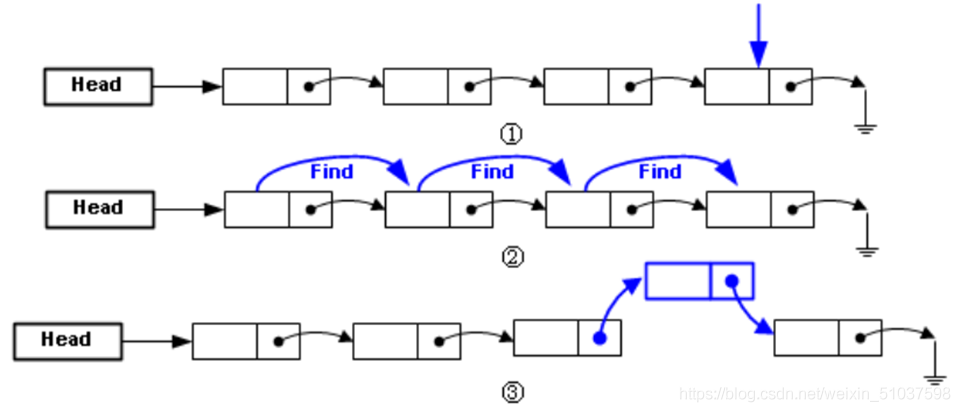 ??
??洗掉:改 洗掉結點 前的一個結點 的指標域 即可(一步賦值) ??
類:具有共性問題的物件的集合
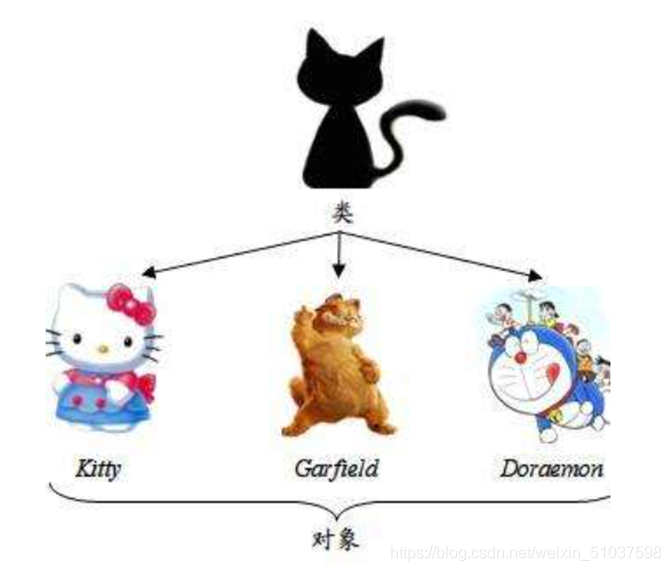
引入目的:使代碼修改min化(同一類有相同點,可以根據相同點來歸類) ??繼承性:繼承①方法
②屬性:自然屬性(不變)與行為屬性(變化) ??傳遞命令---->行為 ??
用例圖:
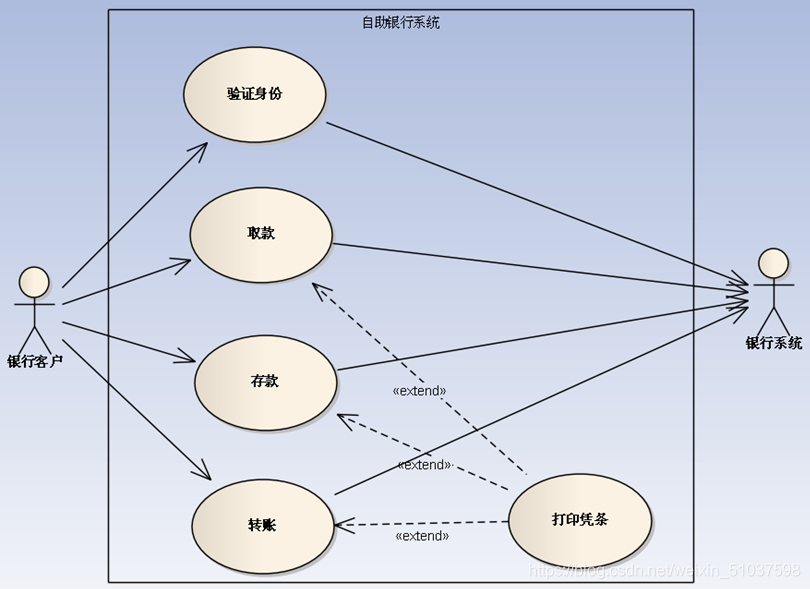 ??
??UML圖:
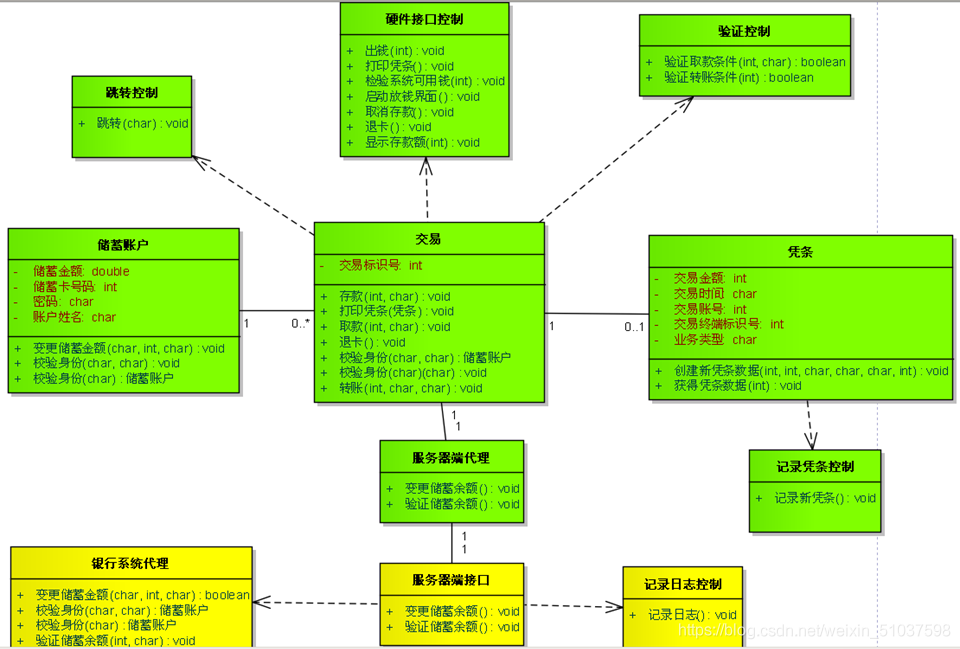 ??
??編碼實作:
 ??
??軟體測驗:
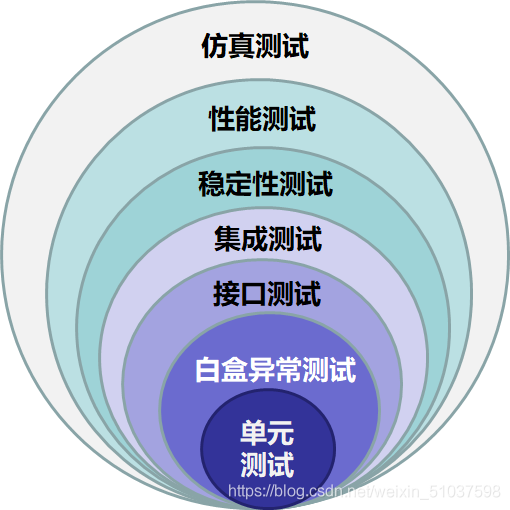 ??
??部署
 ??
??軟體維護
表面:
實際其背后:
 ??
??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/237646.html
標籤:其他