R語言---Seewave包和tuneR在聲音分析中的應用①關于聲音及簡單分析
- 關于聲音分析
- 時振幅引數化
關于聲音分析
在R中的聲音分析主要應用于生物聲學和生態聲學的分析,當然在情緒調節、城市噪音評估和神經科學中的腦語音處理等許多領域都有相關的涉及和應用,
其聲音分析主要原理就是利用傅里葉變換(或傅里葉逆變換)實作時域和頻域的相互轉換,進行傅里葉分析(Fourier analysis),
舉一個簡單的例子,人之所以能在同一段歌曲中既能聽到鼓點伴奏聲,又可以聽到唱歌人的聲音,其大腦就起到了傅里葉變換的功能,當然這個程序也可以是有選擇性的(即提高專注度,可只聽人聲而忽略鼓聲),

時振幅引數化
Let’s do it
1.首先,在野外環境收集聲音階段,你需要慎之又慎,需要你盡可能收集到清晰的聲音,(該程序是十分重要的,較高的SNR能幫助你在之后的分析中,減少時間的浪費!)
2.加載相關的包
library(audio)
library(seewave)
library(tuneR)
匯入聲音(需要區分你的音頻檔案格式)以及保存聲音
主要分為MP3,wav,flac三種格式進行檔案的讀取
.wav:未壓縮格式
.mp3: 有損壓縮格式,資訊減少,時間,幅度和頻率引數可能會受損,
.flac: 無損壓縮格式
(建議你選取.wav格式或.flac是一個比較適用于資料分析的檔案格式)
readWave()
(當然你如果獲得的是一堆音頻,可以將其檔案名匯入至file中,以便后續進行回圈計算)
file.name.sum<-dir(“Sample”, pattern=“wav
∣
m
p
3
|mp3
∣mp3”)
最簡單的保存方法就是:savewav(wave.sound)(直接將你的聲音保存到預先設定的路徑)
3.收集wave 不一定都是完美的,你需要進行預剪切,并通過示波器查看效果
sample<-extractWave(sample, from= , to= , xunit=“time”)
cutw(wave, f, channel=1, from = NULL, to = NULL, choose = F,
plot = F)
oscillo(sample)#不需要設定引數,可直接快速查看
oscillo(sample, f=sample@sample_rate, alab=“Amplitude (Pa)”)
axis(side=2, las=2)
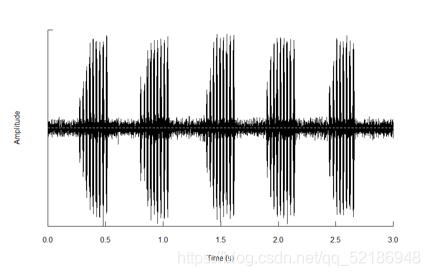
有時候,你收集的音頻十分混亂,但你仍想從中找到一些有用的資訊
#利用fir()去找尋不同頻率下的波段,通過濾波獲得你所需的音波
利用from和to來確定你需要分析的時間段
sample_filt <- fir(sample, from=NULL, to=NULL, output=“Wave”)
通過identify=T 來確定波段的位置
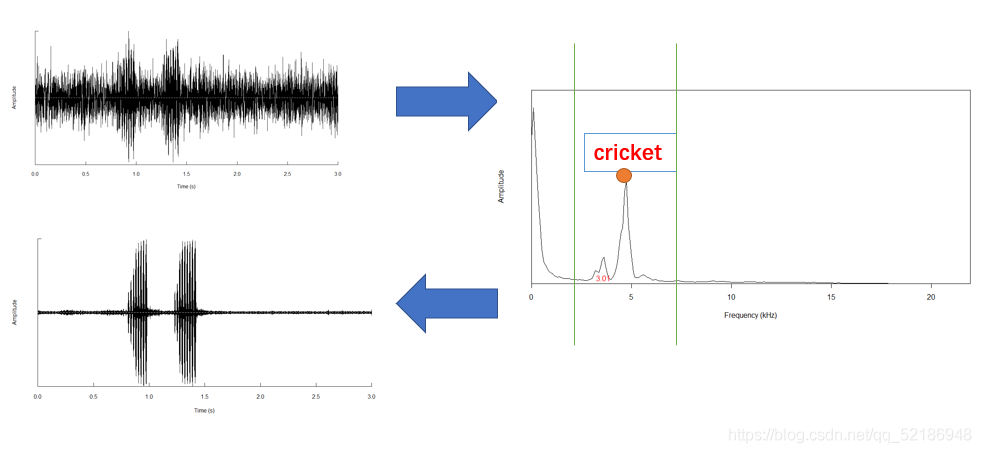
4.SNR檢驗,以保證你聲音質量的高低
如果音波產生程序中,有噪音摻雜其中
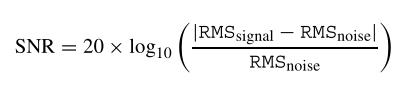
sample_SNR_1923_1<- 20*log10(rms(sample_1_cut)/rms(sample_noise_1))
如果雜音沒有摻雜其中,
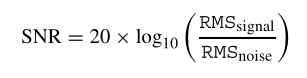
5. 接下來,你可以通過代碼獲得一些聲音的資訊
crest(sample)#波峰,c波峰因數、val樣本值、loc最大峰時的樣本
max(sample@left) - min(sample@left)#peak-to-peak
E <- sum(sample@left^2)#能量
n <- length(sample@left)#波長
P <- E/n#平均功率
RMS <- sqrt§#均方根
處理一堆檔案你可以套用修改下面的循壞
#library(moments)
for (i in 1:length(file.name.sum)) {
kurtosis.sum<-kurtosis(readWave(paste(file.name.sum[i], sep=" "))@left)
print(as.data.frame(kurtosis.sum))
}
data.frame(E,P,RMS)#建立data.frame將這些東西整合起來
還可以通過summary()來獲得關于波的一些經典統計量
6.時振幅引數化
測量振幅的方法有兩種方式:分別是手動測量和自動測量
a.手動測度
oscillo(sample, identify=TRUE)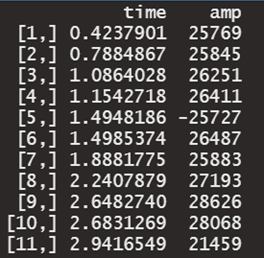
for(i in 1:n) { # loop with n iterations
res[[i]] <- oscillo(readWave(file.name.sum[i]), identify=TRUE)
}
如果你的音頻檔案很多,非常建議你不要使用for回圈來進行手動測量,
b.自動測度
其原理:參考設定幅度閾值跟蹤振幅隨時間的變化,低于固定閾值的任何事件都被視為暫停事件,而高于固定閾值的任何事件都被視為信號事件,則被記錄,
envlpe <- env(sample, plot=FALSE)
max.env <- max(envlpe)#利用Hilbert amplitude envelope可獲得最大envelope
max.env
timer()#自動測度
具體引數設定可通過?timer()尋求幫助
通過該公式你可獲得一下結果:
a. 信號事件的持續時間(以秒為單位)
b. 暫停事件的持續時間(以秒為單位)
c. 間斷時間比
d. 信號開始的時間位置
e. 信號結束的時間位置
f. 檢測第一個事件是否產生信號(TURE OR FALSE)
*設定timer()引數是十分棘手的,你必須依靠經驗而且根據你所測量的音頻而決定,
但檢測引數精確與否的方法是確定的,
ex:
res <- timer(sample, msmooth=c(49,90),threshold=5,envt=“hil”)
res2 <- timer(sample, msmooth=c(49,90), threshold=4.9,envt=“hil”, dmin=0.18)
res3<-timer(sample, threshold=5.45, ssmooth=140, envt=“hil”)
length(resKaTeX parse error: Expected 'EOF', got '#' at position 3: s)#? mean(ress) # mean of signal duration
sd(resKaTeX parse error: Expected 'EOF', got '#' at position 5: s) #? standard-devia…p) # mean of pause duration
sd(res$p) # standard-deviation of signal duration
同上,回圈如下:
for (i in 1:length(file.name.sum)) {
res<-timer(readWave(paste(file.name.sum[i], sep=" ")),threshold=5, msmooth=c(50,0),envt=“hil”,plot=F)
msd.sum<-mean(resKaTeX parse error: Expected 'EOF', got '#' at position 4: s) #? mean of signal…s) # standard-deviation of signal duration
mpd.sum<-mean(resKaTeX parse error: Expected 'EOF', got '#' at position 4: p) #? mean of pause …p) # standard-deviation of signal duration
print(data.frame(msd.sum,ssd.sum,mpd.sum,spd.sum))
}
is first event a pause?
res$first==“pause”
calculation of the period
period <- res
s
+
r
e
s
s+res
s+resp[-1]
mean of the period
mean(period)
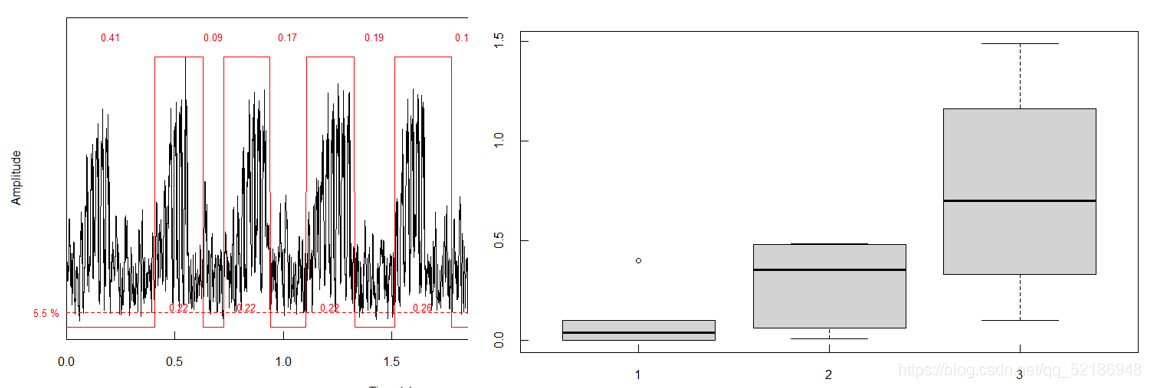
boxplot(res
s
,
r
e
s
2
s,res2
s,res2s,res3$s)
這里我們可以使用**boxplot()**去檢測誤差分布,以選擇較好的自動測度引數
(在實際應用的程序中,針對不同音頻檔案需要進行不同的調整,已滿足你的要求,但隨著設定引數和經驗累計,針對某一生物的音頻所設定的引數可能是在一定區間變化,并不會有較大波動,)
下期講著重針對滑動視窗去探討如何進行時振幅引數化的具體細節,
希望該分享能對大家在聲音分析方面有所幫助,
由于筆者水平有限,分享難免有遺漏之處,敬請各位讀者批評指正!
關于聲音分析的細節和更為詳盡的代碼,還請你去仔細閱讀這本書**《Sound Analysis and Synthesis with R》**,以達到你聲音分析的要求,
Peng Han
(E-mail: penghan_eco@qq.com)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/237989.html
標籤:其他
下一篇:創建一個簡單的tcp客戶端