萬物皆可Embedding系列會結合論文和實踐經驗進行介紹,前期主要集中在論文中,后期會加入實踐經驗和案例,目前已更新:
- 萬物皆可Vector之語言模型:從N-Gram到NNLM、RNNLM
- 萬物皆可Vector之Word2vec:2個模型、2個優化及實戰使用
- Item2vec中值得細細品味的8個經典tricks和thinks
- Doc2vec的演算法原理、代碼實作及應用啟發
- Sentence2Vec & GloVe 演算法原理、推導實與現
后續會持續更新Embedding相關的文章,歡迎持續關注「搜索與推薦Wiki」
Sentence2vec
Sentence2vec 是2017年發表于ICLR(國際學習展示回憶)的一篇論文,其全稱為:A Simple but tough-to-beat baseline for sentence embeddings
下面來看一下論文所介紹的內容(論文的內容比較晦澀難懂,小編水平也不高,如果不當之處,評論區留言,感謝!),
1、概述
論文主要提出了一種無監督的,基于單詞詞向量計算句子embedding的方法,稱之為Smooth Inverse Frequecy(SIF),使用加權平均的方法從word embedding到sentence embedding,然后再基于句子的embedding進行相似度計算,下面使用Sentence2vec來代替模型的思想,
論文中提出的計算方法比直接平均求句子embedding的方法效果要好一些,在一些任務中甚至比RNN、LSTM模型表現還要好一些,
與該論文中思路比較相近的做法有:
- 直接使用詞語的平均embedding來表示句子,即不帶權平均
- 使用TF-IDF值作為權重,進行帶權計算(前提是句子中沒有大量重復的詞語,且使用tfidf值作為權重沒有理論依據)
通過引入SIF,結合詞語embedding加權計算句子embedding,不僅表現較好,而且有較好的魯棒性,論文中提到了三點:
- 使用不同領域的語料訓練得到的不同詞語embedding,均取得了不錯的效果,說明演算法對各種語料都比較友好
- 使用不同語料計算得到的詞頻,作為詞語的權重,對最終的結果影響很小
- 對于方法中的超引數, 在很大范圍內, 獲得的結果都是區域一致的, 即超引數的選擇沒有太大的影響
2、理論
a)潛在變數生成模型
在介紹Sentence2vec之前,先看一下潛在變數生成模型(latent variable generative model),其將語料的生成程序看作是一個動態的程序,第 t t t個單詞是在第 t t t步生成的,每個單詞 w w w 對應一個實值向量 R d R^d Rd,這個動態程序是通過 discourse vector c t ∈ R d c_t \in R^d ct?∈Rd 隨機游走驅動的,discourse vector表達的是 what is being talked about,
discourse vector
c
t
c_t
ct? 和 單詞的向量
v
w
v_w
vw? 的內積表達的是 discourse和word之間的相關性,并且假設
t
t
t時間觀測到的
w
w
w 的概率為這個內積的對數線性關系(log linear),運算式為:
P
r
[
w
?
e
m
i
t
t
e
d
a
t
t
i
m
e
t
∣
c
t
]
∝
e
x
p
(
<
c
t
,
v
w
>
)
Pr[w \, emitted at time t | c_t] \propto exp(<c_t, v_w>)
Pr[wemittedattimet∣ct?]∝exp(<ct?,vw?>)
由于 c t c_t ct? 是較小幅度的隨機游走生成的, c t c_t ct? 和 c t + 1 c_{t+1} ct+1? 之間只是相差一個很小的隨機差向量,因此相鄰的單詞由相似的discourses vector 生成,另外計算表明這種模型的隨機游走允許偶爾 c t c_t ct? 有較大的 jump,通過這種方法生成的詞向量,與word2vec(CBOW)和Glove是相似的,
b)Sentence2vec 在隨機游走上的改進
在給定句子 s s s的情況下,對控制該句子的向量 discourse vector 進行最大似然估計, 我們觀察到在句子生成單詞的時候,discourse vector c t c_t ct? 變化特別小,為了簡單起見,認為其是固定不變的,為 c s c_s cs?,可以證明 對 c s c_s cs? 的最大似然估計就是該句中所有單詞向量的平均,
Sentence2vec對模型的改進為增加了兩項平滑(smoothing term),原因是:有些單詞在背景關系之外出現,可能會對discourse vector產生影響;有些常見的停用詞和discourse vector幾乎沒有關系,
兩項平滑技術為:
- 1、在對數線性模型中引入 了累加項 $ \alpha p(w) , , ,p(w)$ 表示的是單詞 w w w在整個語料中出現的概率, α \alpha α 是一個超引數,這樣即使和 c s c_s cs?的向量內積很小,這個單詞也有概率出現
- 2、引入糾錯項 c 0 ∈ R d c_0 \in R^d c0?∈Rd (a common discourse vector),其意義是句子的最頻繁的意義可以認為是句子的最重要組成部分,常常可以與語法聯系起來. 文章中認為對于某個單詞, 其沿著 c 0 c_0 c0?方向的成分較大(即向量投影更長), 這個糾正項就會提升這個單詞出現的概率.
糾正后的單詞
w
w
w在句子
s
s
s中出現的概率為:
P
r
[
w
?
e
m
i
t
t
e
d
i
n
s
e
n
t
e
n
c
e
s
∣
c
s
]
=
α
p
(
w
)
+
(
1
?
α
)
e
x
p
(
<
c
s
~
,
v
w
>
)
Z
c
s
~
Pr[w \, emitted in sentence s | c_s] = \alpha p(w) + (1-\alpha) \frac{exp(<\tilde{c_s}, v_w>)}{Z_{\tilde{c_s}}}
Pr[wemittedinsentences∣cs?]=αp(w)+(1?α)Zcs?~??exp(<cs?~?,vw?>)?
其中:
- c s ~ = β c 0 + ( 1 ? β ) c s , c 0 ⊥ c s \tilde{c_s} = \beta c_0 + (1- \beta) c_s, c_0 \perp c_s cs?~?=βc0?+(1?β)cs?,c0?⊥cs?
- $ \alpha, \beta$為超引數
- Z c s ~ = ∑ w ∈ V e x p ( < c s ~ , v w > ) Z_{\tilde{c_s}} = \sum_{w \in V} exp(<\tilde{c_s}, v_w>) Zcs?~??=∑w∈V?exp(<cs?~?,vw?>) 是歸一化常數
從上面的公式中也可以看出,一個與 c s c_s cs? 沒有關系的詞語 w w w 也可以在句子中出現,因為:
- α p ( w ) \alpha p(w) αp(w) 常數項
- 與 common discourse vector c 0 c_0 c0?的相關性
c)計算句子相關性
句子的向量,即上文提到的
c
s
c_s
cs? 可以通過最大似然函式去生成,這里假設組成句子的詞語
v
w
v_w
vw?是統一分散的,因此這里歸一化
Z
c
Z_c
Zc? 對于不同句子的值都是大致相同的,即對于任意的
c
s
~
\tilde{c_s}
cs?~?,
Z
Z
Z值都是相同的,,在這個前提下,得到的似然函式為:
p
[
s
∣
c
s
]
=
∏
w
∈
s
p
(
w
∣
c
s
)
=
∏
w
∈
s
[
α
p
(
w
)
+
(
1
?
α
)
e
x
p
(
<
v
w
,
c
s
~
>
)
Z
]
p[s | c_s] = \prod_{w\in s} p(w|c_s)= \prod_{w \in s} [\alpha p(w) + (1-\alpha) \frac{ exp(<v_w, \tilde{c_s}>) }{Z}]
p[s∣cs?]=w∈s∏?p(w∣cs?)=w∈s∏?[αp(w)+(1?α)Zexp(<vw?,cs?~?>)?]
取對數,可得:
f
w
(
c
s
~
)
=
l
o
g
[
α
p
(
w
)
+
(
1
?
α
)
e
x
p
(
<
v
w
,
c
s
~
>
)
Z
]
f_w(\tilde{c_s}) = log [\alpha p(w) + (1-\alpha) \frac{ exp(<v_w, \tilde{c_s}>) }{Z}]
fw?(cs?~?)=log[αp(w)+(1?α)Zexp(<vw?,cs?~?>)?]
經過一系列推導,可得最終的目標函式為:
a
r
g
m
a
x
∑
w
∈
s
f
w
(
c
s
~
)
arg max \sum_{w \in s} f_w(\tilde{c_s})
argmaxw∈s∑?fw?(cs?~?)
其正比于:
∑
w
∈
s
α
p
(
w
)
+
α
v
w
\sum_{w \in s} \frac {\alpha}{p(w) + \alpha} v_w
w∈s∑?p(w)+αα?vw?
其中
α
=
1
?
α
α
Z
\alpha = \frac{1-\alpha} {\alpha Z}
α=αZ1?α?
因此可以得到:
- 最優解為句子中所有單詞向量的加權平均
- 對于詞頻更高的單詞 w w w, 權值更小, 因此這種方法也等同于下采樣頻繁單詞
最后, 為了得到最終的句子向量 c s c_s cs?, 我們需要估計 c 0 c_0 c0?.,通過計算向量 c s ~ \tilde{c_s} cs?~?的first principal component(PCA中的主成分), 將其作為 c 0 c_0 c0?,最終的句子向量即為 c s ~ \tilde{c_s} cs?~?減去主成份向量 c 0 c_0 c0?,
d)整體演算法流程

3、實作
作者開源了其代碼,地址為:https://github.com/PrincetonML/SIF
Glove
1、概述
論文中作者總結了目前生成embedding的兩大類方法,但這兩種方法都有其弊端存在
- 基于矩陣分解,弊端為因為是基于全域進行矩陣的構建,對于一些高頻詞,在演算法優化的程序中,占的權重比較大
- 基于滑動視窗,不能直接對語料庫的單詞進行共現建模,使用的是滑動視窗,沒有辦法利用資料的共現資訊
因此作者提出了一種基于語料庫進行資訊統計,繼而生成embedding的演算法-Glove,下面就來具體看下對應的演算法原理,
2、演算法推導程序
字符的定義:
- X X X 表示單詞的共現矩陣, X i j X_{ij} Xij? 表示 單詞 j j j在單詞 i i i的背景關系中出現的次數,即在指定的視窗內,單詞 i , j i,j i,j的共現次數
- X i X_i Xi? 表示 任何一個單詞 k k k 和單詞 i i i的共現次數總和, ∑ k X i k \sum_{k} X_{ik} ∑k?Xik?
- P i j = P ( j ∣ i ) = X i j / X i P_{ij}=P(j|i)=X_{ij} / X_i Pij?=P(j∣i)=Xij?/Xi?,表示單詞 i , j i,j i,j的共現次數在單詞 i i i 出現次數總和的概率
論文中給出了一個簡單的例子,來數目如何從共現矩陣中提取出有意義的資訊,如下圖所示:
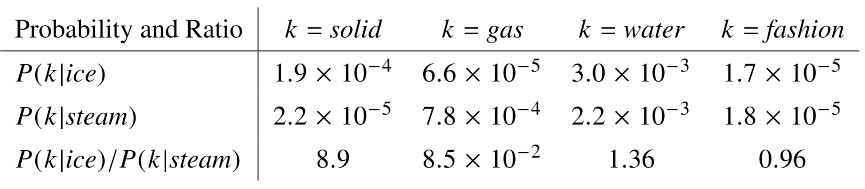
上圖想要說明的資訊是,如果單詞 k k k 和單詞 i i i的相關度比 k k k 和 j j j的相關度大的話, P ( i k ) / P ( j k ) P(ik) / P(jk) P(ik)/P(jk)的值會很大,差距越大,比值越大;同理如果 k k k和 i i i的相關度比 k k k和 j j j的相關度小的話, P ( i k ) / P ( j k ) P(ik) / P(jk) P(ik)/P(jk)的值會很小,差距越大,比值越小;如果 k k k和 i , j i, j i,j都不想關的話, P ( i k ) / P ( j k ) P(ik) / P(jk) P(ik)/P(jk)的值會接近于1,
上述的討論說明了詞向量的學習應該是基于共現概率的比率而不是概率本身,因此假設可以通過函式
F
F
F來學習到詞向量,函式
F
F
F可以抽象為:
F
(
w
i
,
w
j
,
w
~
k
)
=
P
i
k
P
j
k
F(w_i, w_j, \tilde{w}_k) = \frac{P_{ik}} {P_{jk}}
F(wi?,wj?,w~k?)=Pjk?Pik??
其中
w
w
w表示的是詞向量,
P
i
k
P
j
k
\frac{P_{ik}} {P_{jk}}
Pjk?Pik?? 可以從語料中計算得到,函式
F
F
F依賴于一些尚未指定的引數,但因為一些必要的條件,函式
F
F
F可以進一步的被確定,
由于向量空間具有線性結構,因此可以對詞向量進行差分,函式
F
F
F可以轉化為:
F
(
w
i
?
w
j
,
w
~
k
)
=
P
i
k
P
j
k
F(w_i - w_j, \tilde{w}_k) = \frac{P_{ik}}{P_{jk}}
F(wi??wj?,w~k?)=Pjk?Pik??
雖然函式F可能是一個比較復雜的結構,比如神經網路,但這樣做,會使我們試圖捕獲的線性結構消失,因此為了避免這個問題,我們可以先對向量做個內積,可以轉化為:
F
(
(
w
i
?
w
j
)
T
w
~
k
)
=
P
i
k
P
j
k
F((w_i - w_j)^T \tilde{w}_k) = \frac{P_{ik}}{P_{jk}}
F((wi??wj?)Tw~k?)=Pjk?Pik??
上述公式中左側是減法,右側是除法,這很容易讓人聯想到指數運算,因此限定函式
F
F
F為指數函式,此時有:
e
x
p
(
w
i
T
w
k
?
w
j
T
w
k
)
=
e
x
p
(
w
i
T
w
k
)
e
x
p
(
w
j
T
w
k
)
=
P
i
k
P
j
k
exp(w_i^Tw_k - w_j^Tw_k) = \frac{exp(w_i^Tw_k)}{exp(w_j^Tw_k)} = \frac{P_{ik}}{P_{jk}}
exp(wiT?wk??wjT?wk?)=exp(wjT?wk?)exp(wiT?wk?)?=Pjk?Pik??
此時,只需要確保等式兩邊分子和分母相等即可,即:
e
x
p
(
w
i
T
w
k
)
=
P
i
k
,
e
x
p
(
w
j
T
w
k
)
=
P
j
k
exp(w_i^T w_k) = P_{ik}, exp(w_j^Tw_k) = P_{jk}
exp(wiT?wk?)=Pik?,exp(wjT?wk?)=Pjk?
進一步,可以轉化為語料中的所有詞匯,考察
e
x
p
(
w
i
T
w
k
)
=
P
i
k
=
X
i
k
X
i
exp(w_i^T w_k) = P_{ik} = \frac{X_{ik}}{X_i}
exp(wiT?wk?)=Pik?=Xi?Xik??,即:
w
i
T
w
k
=
l
o
g
(
X
i
k
X
i
)
=
l
o
g
X
i
k
?
l
o
g
X
i
w_i^T w_k = log (\frac{X_{ik}}{X_i}) = log X_{ik} - logX_i
wiT?wk?=log(Xi?Xik??)=logXik??logXi?
由于上式左側
w
i
T
w
k
w_i^T w_k
wiT?wk? 中,調換
i
i
i 和
k
k
k 的值不會改變其結果,即具有對稱性,因此,為了確保等式右側也具備對稱性,引入了兩個偏置項,即:
w
i
T
w
k
=
l
o
g
X
i
k
?
b
i
?
b
k
w_i^T w_k = log X_{ik} - b_i - b_k
wiT?wk?=logXik??bi??bk?
此時,
l
o
g
X
i
log X_i
logXi? 已經包含在
b
i
b_i
bi?中,因此,此時模型的目標就轉化為通過學習詞向量的表示,使得上式兩邊盡量接近,因此,可以通過計算兩者之間的平方差來作為目標函式,即:
J
=
∑
i
,
k
=
1
V
(
w
i
T
w
~
k
+
b
i
+
b
k
?
l
o
g
X
i
k
)
2
J = \sum_{i,k=1}^{V} (w_i^T \tilde{w}_k + b_i + b_k - log X_{ik})^2
J=i,k=1∑V?(wiT?w~k?+bi?+bk??logXik?)2
但是這樣的目標函式有一個缺點,就是對所有的共現詞匯又是采用相同的權重,因此,作者對目標函式進行了進一步的修正,通過語料中的詞匯共現統計資訊來改變他們在目標函式中的權重,具體如下:
J
=
∑
i
,
k
=
1
V
f
(
X
i
k
)
(
w
i
T
w
~
k
+
b
i
+
b
k
?
l
o
g
X
i
k
)
2
J = \sum_{i,k=1}^{V}f(X_{ik}) (w_i^T \tilde{w}_k + b_i + b_k - log X_{ik})^2
J=i,k=1∑V?f(Xik?)(wiT?w~k?+bi?+bk??logXik?)2
這里
V
V
V 表示詞匯的數量,并且權重函式
f
f
f 必須具備一下的特性:
- f ( 0 ) = 0 f(0)=0 f(0)=0,當詞匯共現的次數為0時,此時對應的權重應該為0
- f ( x ) f(x) f(x) 必須時一個非減函式,這樣才能保證當詞匯共現的次數越大時,其權重不會出現下降的情況
- 對于那些太頻繁的詞, f ( x ) f(x) f(x) 應該能給予他們一個相對小的數值,這樣才不會出現過渡加權
綜合以上三點特性,作者提出了下面的權重函式:
f
(
x
)
=
{
(
x
/
x
m
a
x
)
a
i
f
?
x
<
x
m
a
x
1
o
t
h
e
r
w
i
s
e
f(x) = \left\{\begin{matrix} (x / x_{max})^a & if \,x < x_{max}\\ 1 & otherwise \end{matrix}\right.
f(x)={(x/xmax?)a1?ifx<xmax?otherwise?
作者在實驗中設定 x m a x = 100 x_{max} = 100 xmax?=100,并且發現 α = 3 / 4 \alpha = 3/4 α=3/4時效果比較好,函式的影像如下圖所示:
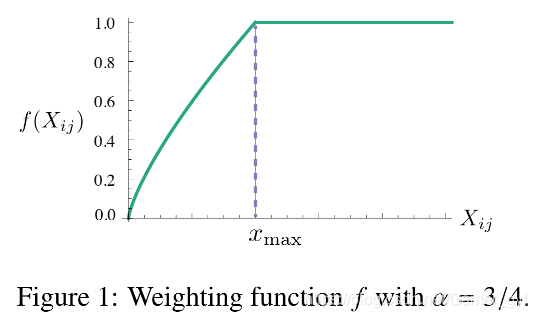
3、總結
以上就是有關 G l o V e GloVe GloVe原理的介紹,作者其實也是基于最開始的猜想一步一步簡化模型的計算目標,最后看GloVe的目標函式時發現其實不難計算,但是要從最開始就想到這樣一個目標函式其實還是很難的,最后做一下總結:
- G l o v e Glove Glove綜合了全域詞匯共現的統計資訊和區域視窗背景關系方法的優點,可以說是兩個主流方法的一種綜合,但是相比于全域矩陣分解方法,由于 G l o V e GloVe GloVe不需要計算那些共現次數為0的詞匯,因此,可以極大的減少計算量和資料的存盤空間
- 但是 G l o V e GloVe GloVe把語料中的詞頻共現次數作為詞向量學習逼近的目標,當語料比較少時,有些詞匯共現的次數可能比較少,筆者覺得可能會出現一種誤導詞向量訓練方向的現象

掃一掃 關注微信公眾號!號主 專注于搜索和推薦系統,嘗試使用演算法去更好的服務于用戶,包括但不局限于機器學習,深度學習,強化學習,自然語言理解,知識圖譜,還不定時分享技術,資料,思考等文章!
 CSDN認證博客專家
圖書作者
推薦系統研究者
CSDN認證博客專家
圖書作者
推薦系統研究者
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/239161.html
標籤:AI