本視覺Transformers(86M引數)在ImageNet上達到83.1%的top-1精度,蒸餾版本高達84.4%!優于ViT、RegNet和ResNet等,代碼剛剛開源!
注:文末附【Transformer】學習交流群
Training data-efficient image transformers & distillation through attention

- 作者單位:Facebook AI, 索邦大學,注:其中一位也是DETR的作者之一
- 代碼(不到一天,已經近200 star了):https://github.com/facebookresearch/deit
- 論文:https://arxiv.org/abs/2012.12877
最近,顯示出純粹基于注意力的神經網路可解決影像理解任務,例如影像分類,但是,這些視覺transformers使用昂貴的基礎架構預先接受了數億個影像的訓練,從而限制了它們在更大的社區中的應用,關于視覺Transformer,推薦看一下這個最新綜述:華為等提出視覺Transformer:全面調研
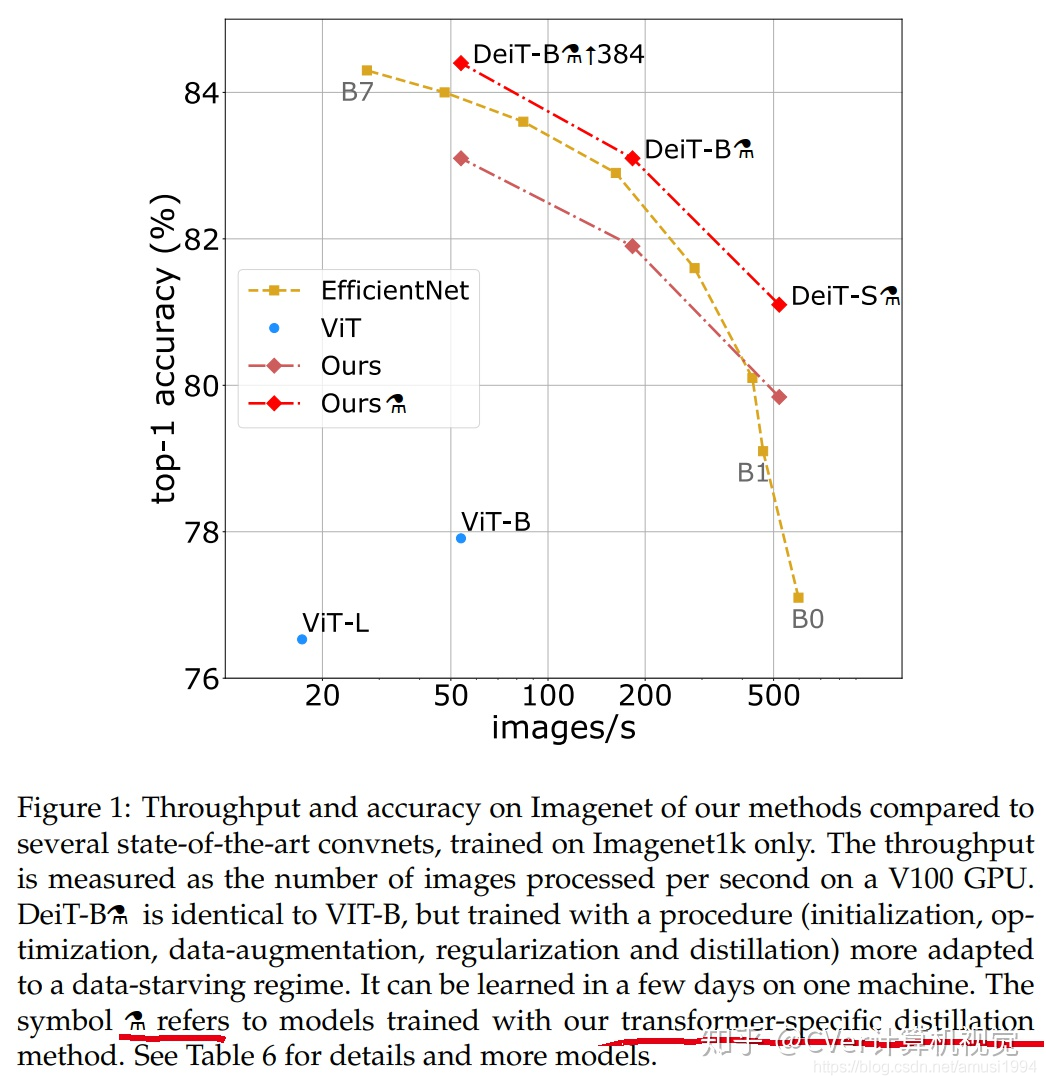
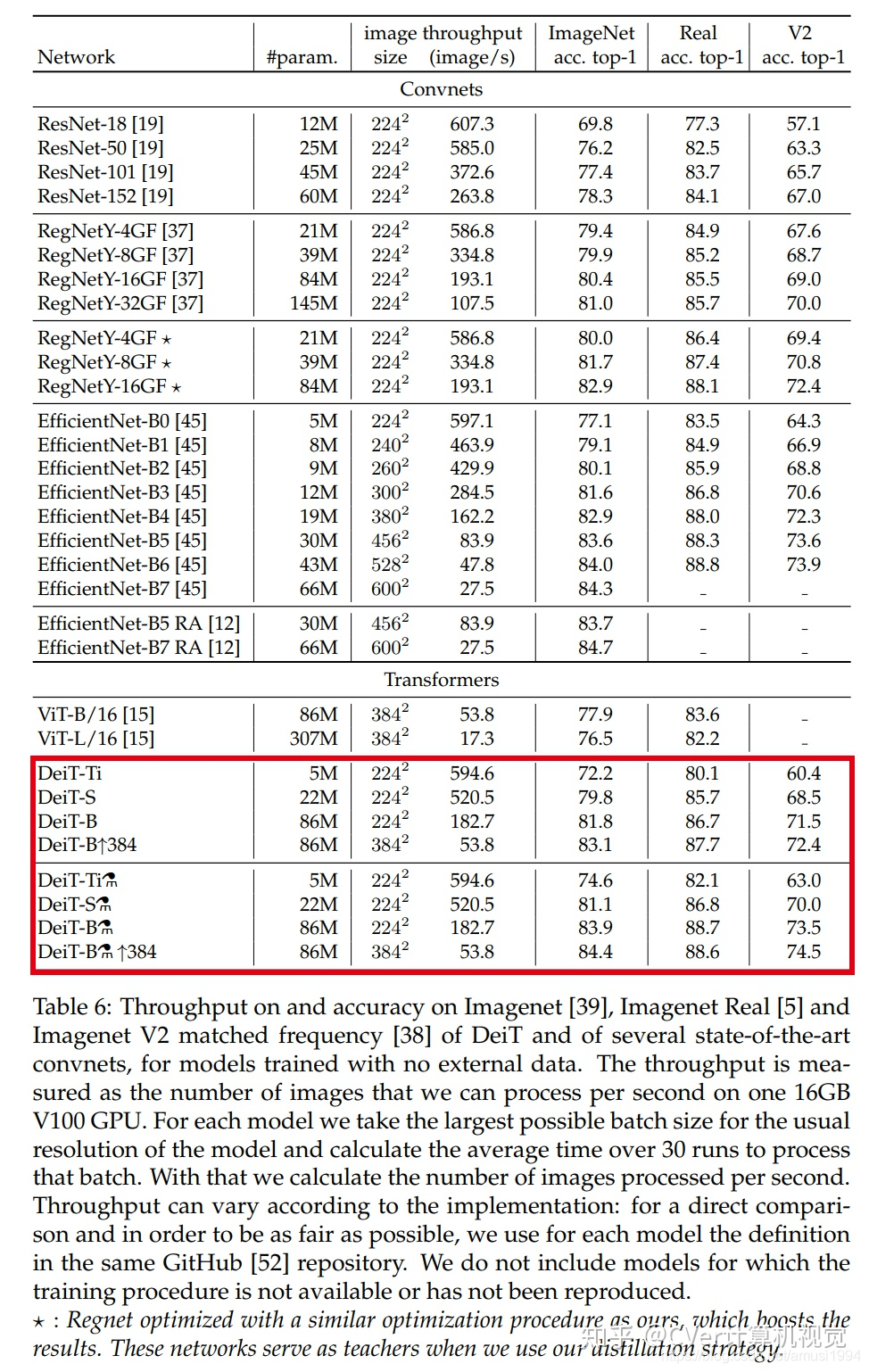
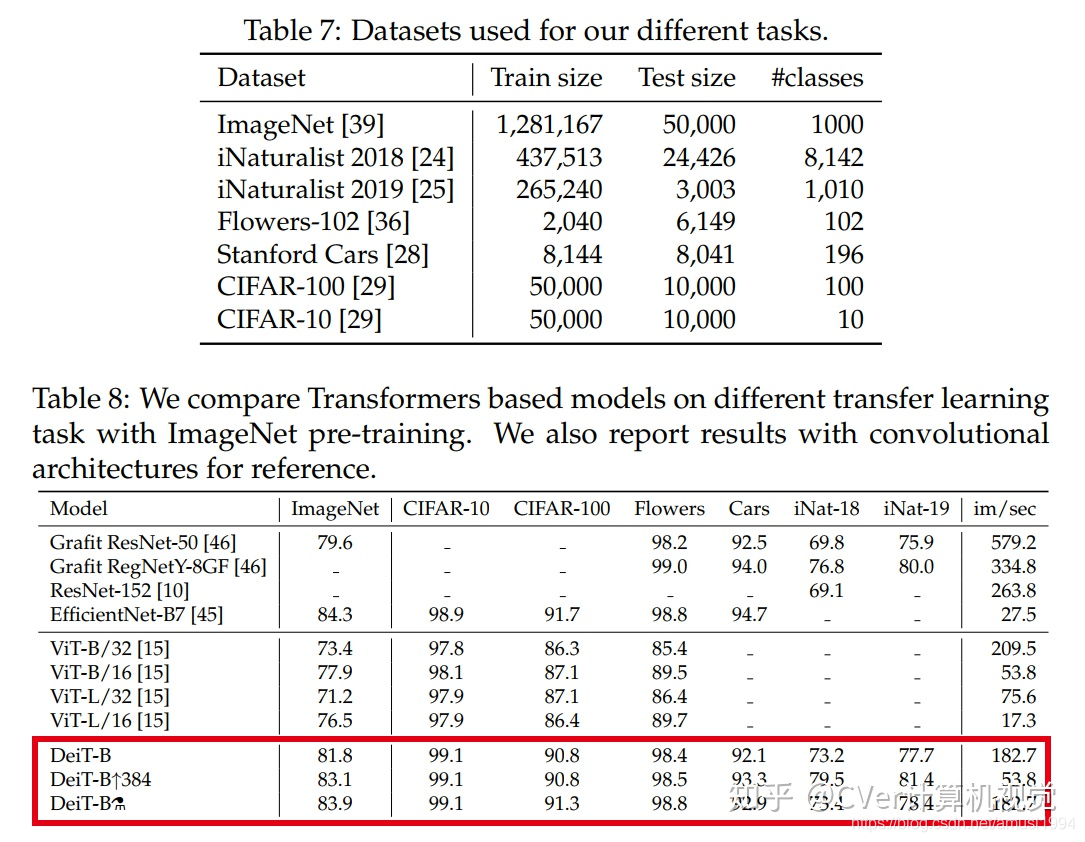
在這項作業中,通過適當的訓練計劃,我們僅通過在Imagenet上進行訓練即可生產出具有競爭力的無卷積transformers,我們不到三天就在一臺計算機上對其進行了訓練,我們的視覺transformers(86M引數)在ImageNet上無需外部資料即可達到83.1%的top-1精度(單幅評估),我們共享我們的代碼和模型,以加快社區在這方面的研究進展,


此外,我們介紹了特定于transformers的師生策略,它依靠蒸餾令token確保學生通過注意力向老師學習,我們展示了這種基于token的蒸餾的興趣,尤其是在使用卷積網路作為教師時,這使我們能夠報告與卷積網路相比在Imagenet(我們可以獲得高達84.4%的準確性)和遷移到其他任務時具有競爭力的結果,
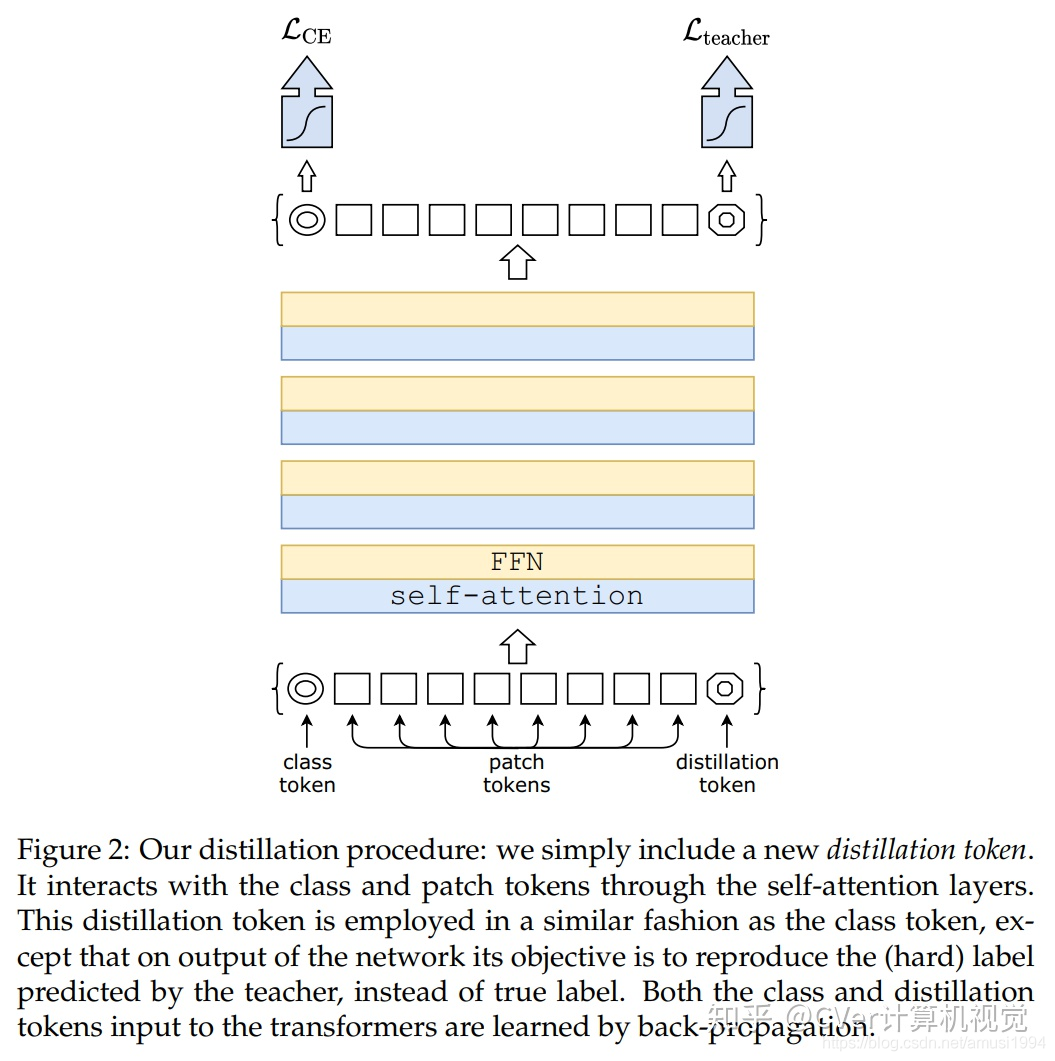


主要貢獻:

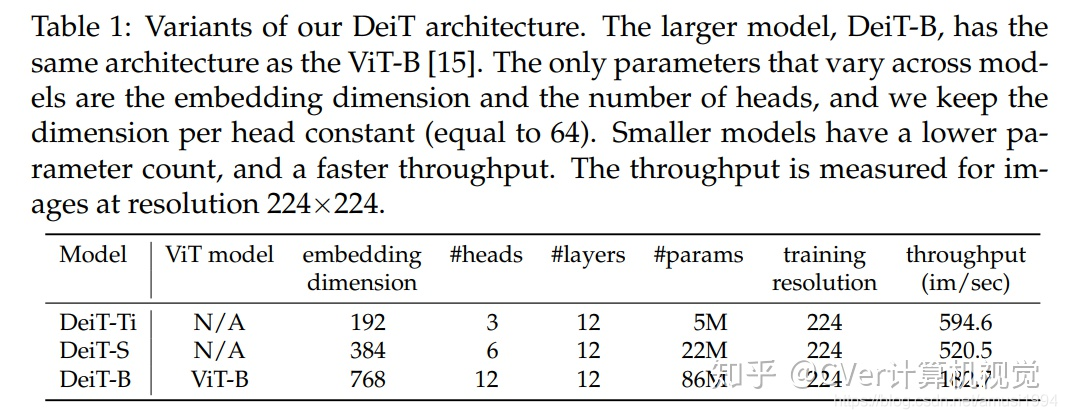
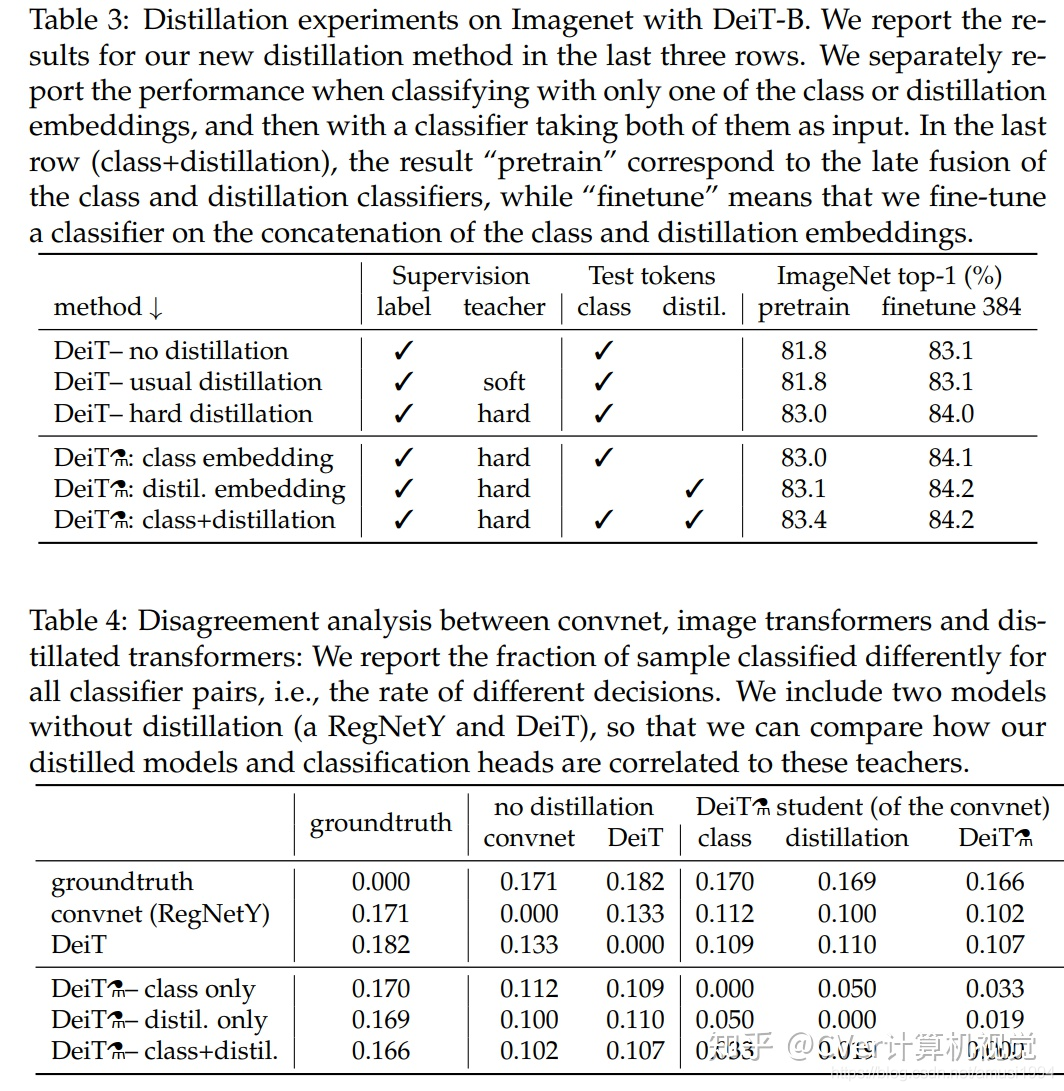
實驗結果
Transformer交流群
已建立CVer-Transformer微信交流群!想要進Transformer學習交流群的同學,可以直接加微信號:CVer5555,加的時候備注一下:Transformer+學校+昵稱,即可,然后就可以拉你進群了,
強烈推薦大家關注CVer知乎賬號和CVer微信公眾號,可以快速了解到最新優質的CV論文,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/240531.html
標籤:其他
上一篇:關于軟考二三事
下一篇:平凡的生活,不平凡的2020