DecisionTreeClassifier與紅酒資料集
1.重要引數
criterion
Criterion這個引數正是用來決定不純度的計算方法的,sklearn提供了兩種選擇:
1)輸入”entropy“,使用資訊熵(Entropy)
2)輸入”gini“,使用基尼系數(Gini Impurity)
不填默認基尼系數,填寫entropy使用資訊增益通常就使用基尼系數,資料維度很大,噪音很大時使用基尼系數,維度低,資料比較清晰的時候,資訊熵和基尼系數沒區別,當決策樹的擬合程度不夠的時候,使用資訊熵
random_state & splitter
random_state用來設定分枝中的隨機模式的引數,默認None,在高維度時隨機性會表現更明顯,低維度的資料隨機性幾乎不會顯現,輸入任意整數,會一直長出同一棵樹,讓模型穩定下來,
splitter是用來控制決策樹中的隨機選項的,有兩種輸入值,
輸入”best",會優先選擇更重要的特征進行分枝,
輸入“random",樹會因為含有更多的不必要資訊而更深更大,并因這些不必要資訊而降低對訓練集的擬合,可防止過擬合,
max_depth
限制樹的最大深度,超過設定深度的樹枝全部剪掉,這是用得最廣泛的剪枝引數,在高維度低樣本量時非常有效,建議從max_depth = 3開始嘗試,看看擬合的效果再決定是否增加設定深度,可以有效限制過擬合,
min_samples_leaf & min_samples_split
min_samples_leaf 限制一個子節點的分支至少包含多少個樣本,
建議從min_samples_leaf = 5 開始檢測擬合度進行調參,
max_features限制分枝時考慮的特征個數,超過限制個數的特征都會被舍棄,在不知道決策樹中的各個特征的重要性時,可能會導致模型學習不足,
min_impurity_decrease
min_impurity_decrease限制資訊增益的大小,資訊增益小于設定數值的分枝不會發生
2.進行紅酒資料集的訓練
作出回歸樹
from sklearn import tree # 匯入樹
from sklearn.datasets import load_wine # 生成資料集的模塊
from sklearn.model_selection import train_test_split # 訓練集測驗集分類
import pandas as pd
import matplotlib.pyplot as plt
import graphviz # 用于畫出決策樹
# 實體化資料
wine = load_wine()
# 使用pandas轉化為表的形式
table = pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
# print(table)
# print(wine.feature_names) #特征名稱
# print(wine.target_names) #標簽名
# 測驗集與訓練集的分類
# wine.data 資料集
# wine.target 標簽集
# test_size=0.3表示30%作為測驗集,70%作為訓練集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
# print(Xtrain.shape) #查看資料結構
# 實體化分類樹
clf = tree.DecisionTreeClassifier(criterion = "entropy"
,random_state = 30
,splitter = "random"
#,max_depth =
,min_samples_leaf = 5
,min_samples_split = 5
)
clf = clf.fit(Xtrain, Ytrain) # 將資料帶入訓練,fit()是用于訓練的介面
score = clf.score(Xtest, Ytest) # 回傳預測的準確度
print("測驗集的準確度:",score)
# apply回傳每個測驗樣本所在的葉子節點的索引
print(clf.apply(Xtest))
# predict回傳每個測驗樣本的分類/回歸結果
print(clf.predict(Xtest))
# feature_name 特征名
# class_name 標簽名
# filled 是否使用顏色,不純度越高顏色越淺
# rounded 是否使用圓角邊框
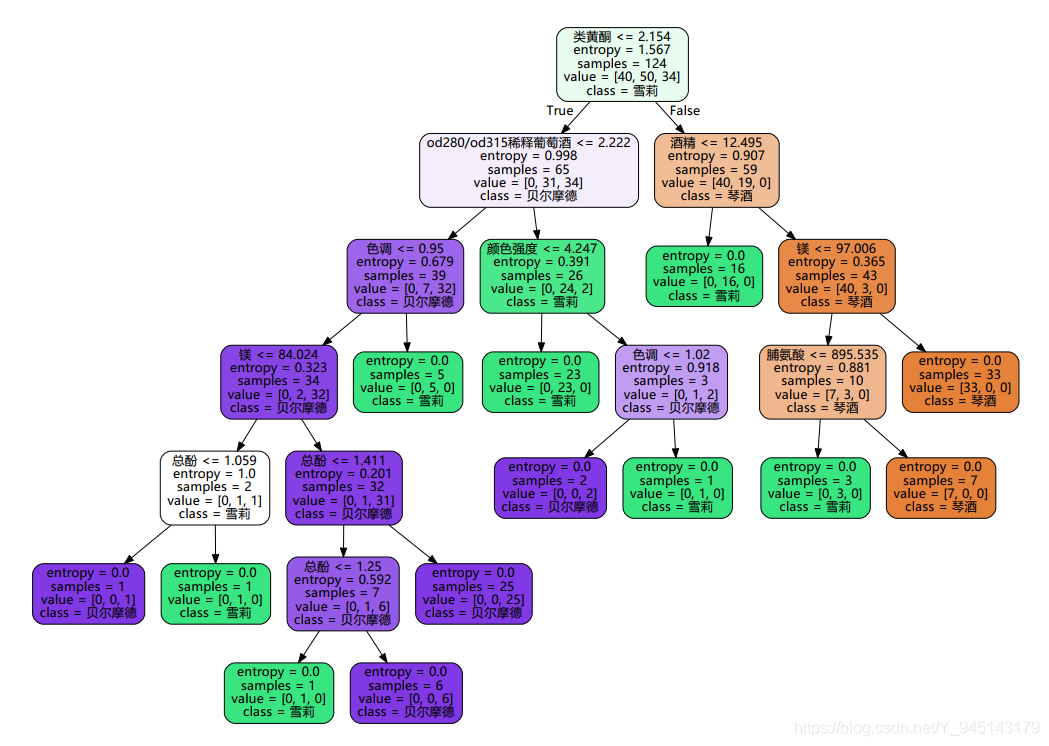
feature_name = ['酒精','蘋果酸','灰','灰的堿性','鎂','總酚','類黃酮','非黃烷類酚類','花青素','顏色強度','色調','od280/od315稀釋葡萄酒','脯氨酸']
dot_data = tree.export_graphviz(clf
,out_file = None
,feature_names= feature_name
,class_names=["琴酒","雪莉","貝爾摩德"]
,filled=True
,rounded=True
)
# 畫出決策樹
graph = graphviz.Source(dot_data.replace('helvetica','"Microsoft YaHei"'), encoding='utf-8')
graph.render('wine')
# 將特征名稱與特征的重要性做表查看
print([*zip(feature_name,clf.feature_importances_)])
分類樹展示
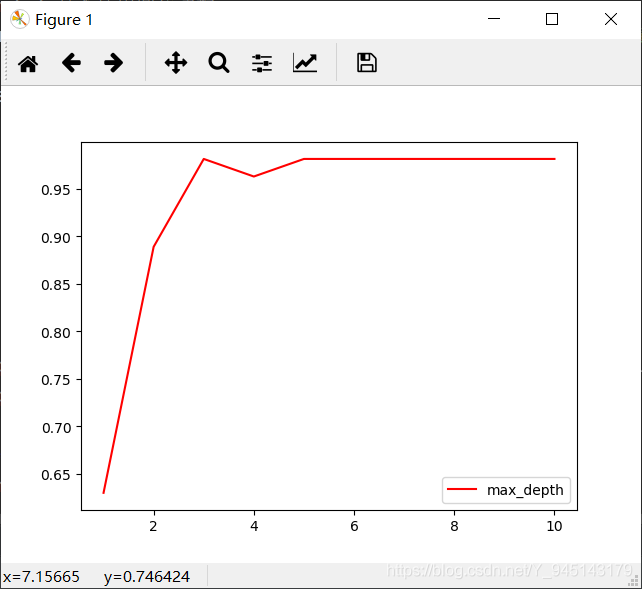
3.超引數的學習曲線
超引數的學習曲線,是一條以超引數的取值為橫坐標,模型的度量指標為縱坐標的曲線,它是用來衡量不同超引數取值下模型的表現的線,在我們建好的決策樹里,我們的模型度量指標就是score,
from sklearn import tree # 匯入樹
from sklearn.datasets import load_wine # 生成資料集的模塊
from sklearn.model_selection import train_test_split # 訓練集測驗集分類
import pandas as pd
import matplotlib.pyplot as plt
import graphviz # 用于畫出決策樹
# 實體化資料
wine = load_wine()
# 使用pandas轉化為表的形式
table = pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
# print(table)
# 測驗集與訓練集的分類
# wine.data 資料集
# wine.target 標簽集
# test_size=0.3表示30%作為測驗集,70%作為訓練集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
# print(Xtrain.shape) #查看資料結構
# 繪制調參曲線
test = [] # 用于存盤每次引數設定的score結果
for i in range(10):
clf = tree.DecisionTreeClassifier(criterion = "entropy"
,random_state = 30
,splitter = "random"
,max_depth = i+1
,min_samples_leaf = 5
,min_samples_split = 5
)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
超引數學習曲線展示
由于劃分訓練集和測驗集時的隨機性,所以每次運行得出的分類樹與超引數學習曲線都會有所不同
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/241984.html
標籤:其他