
網上雖然有很多利用 TensorFlow 實作 yolov3 的代碼和文章,但感覺講解得還不夠透徹,對于新手而言,存在一定的理解難度,本文目的是為了從零開始構建 yolov3 目標檢測網路,對網路和代碼細節做詳細地介紹,使大家對 TensorFlow 的使用方法有一個基本的掌握,
本文主要包含以下四個方面的內容:
- 為什么選擇學習 TensorFlow,以及如何安裝 TensorFlow?
- 為什么選擇介紹 yolov3 目標檢測網路?
- 深度學習前向推理的整個流程是什么樣的?
- 對 yolov3 網路構建部分進行詳細的代碼介紹,
1 why TensorFlow ?
1.1 TensorFlow 特點
很多入門深度學習的同學都會有類似的困惑,市面上有很多開源框架,如 PyTorch、Caffe、MXNet、PaddlePaddle等,該如何進行選擇呢?在我看來,TensorFlow 的生態建設是最完整的,因為:
- 在開發語言方面,它支持 python 開發、C++ 開發、JavaScript 開發、Swift 開發;
- 在模型開發方面,支持資料輸入預處理、模型構建、模型訓練、模型匯出全流程;
- 在模型部署方面,支持在移動設備、嵌入式設備、服務端多種方式部署;
- 在硬體平臺方面,支持在 CPU、GPU、TPU、RPI 等不同硬體上運行;
- 在開發工具方面,支持 TensorBoard 訓練可視化、TensorFlow Hub 豐富的模型庫
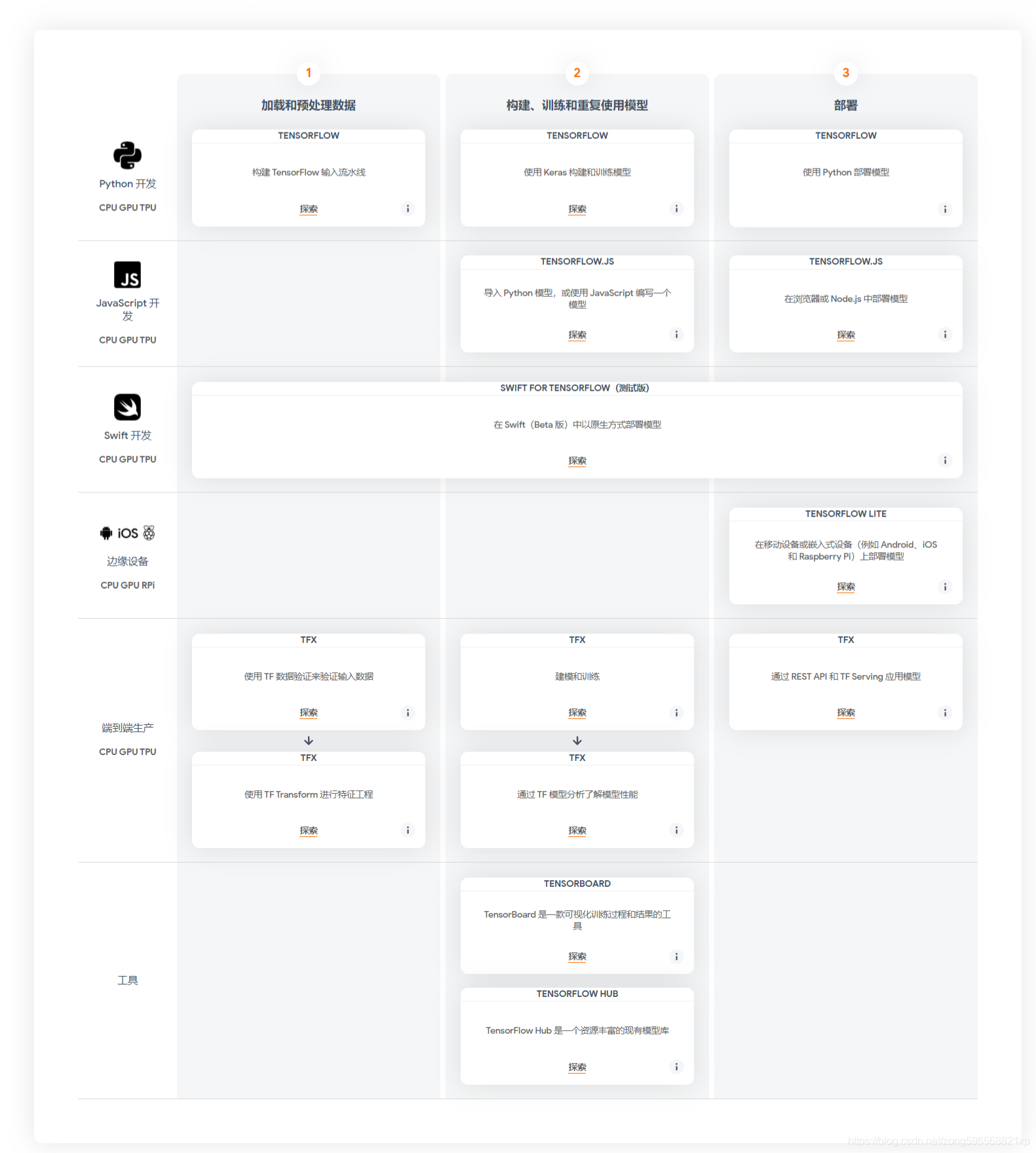
基于 TensorFlow 豐富的生態特點,我將 TensorFlow 作為開發的第一框架,便于自己快速在生產環境中部署深度學習模型,
1.2 TensorFlow 安裝
在官方安裝教程中,介紹了兩種安裝方法,分別是 pip 軟體包管理器以及 docker 容器兩種方式,同時還提供了在 Google Colab 上除錯的方法(需要科學上網),
docker 可以有效的對環境進行隔離,容器中已經配置好了相關環境,可以免去很多手動安裝操作,但對于 docker 操作不熟悉的同學來說,使用起來不太方便,
為了避免環境之間的影響,這里我推薦使用 conda 來創建虛擬環境,本文不介紹 conda 的安裝及使用方法,沒有安裝的同學可以參考相關教程,
創建 conda 環境,安裝GPU 版本的 TensorFlow
conda create -n tensorflow-gpu-2 python=3.7
conda activate tensorflow-gpu-2
pip install tensorflow-gpu經過以上步驟,會在你的系統中安裝好最新版本的 TensorFlow,
2 why yolov3?
yolov3 作為 one-stage 目標檢測演算法典型代表,在工業界應用非常廣泛,尤其是對于實時性要求較高的場合,yolov3 及其各種變體基本上是第一選擇,雖然現在已經有 yolov4 和 yolov5 更先進的演算法,但也都是在 yolov3 的基礎上改進而來,因此有必要先掌握 yolov3 再學習 yolov4 和 yolov5,
yolov3 原論文寫得還是很“隨意”的,很多技術細節沒有講,但這并不妨礙大家對他的肯定,關于對 yolov3 的解讀,推薦兩篇文章,分別是《深入淺出Yolo系列之Yolov3&Yolov4&Yolov5核心基礎知識完整講解》以及《你一定從未看過如此通俗易懂的YOLO系列(從V1到V5)模型解讀!》,
yolov3 整體結構如圖所示,可以看到尺寸為 416 x 416 的輸入圖片進入 Darknet-53 網路后得到了 3 個分支,這些分支在經過一系列的卷積、上采樣以及合并等操作后得到三個尺寸不一的 feature map,形狀分別為 [13, 13, 255]、[26, 26, 255] 和 [52, 52, 255],對這三個尺度的 feature map 經過一系列的后處理,即可得到輸入影像的目標檢測框,
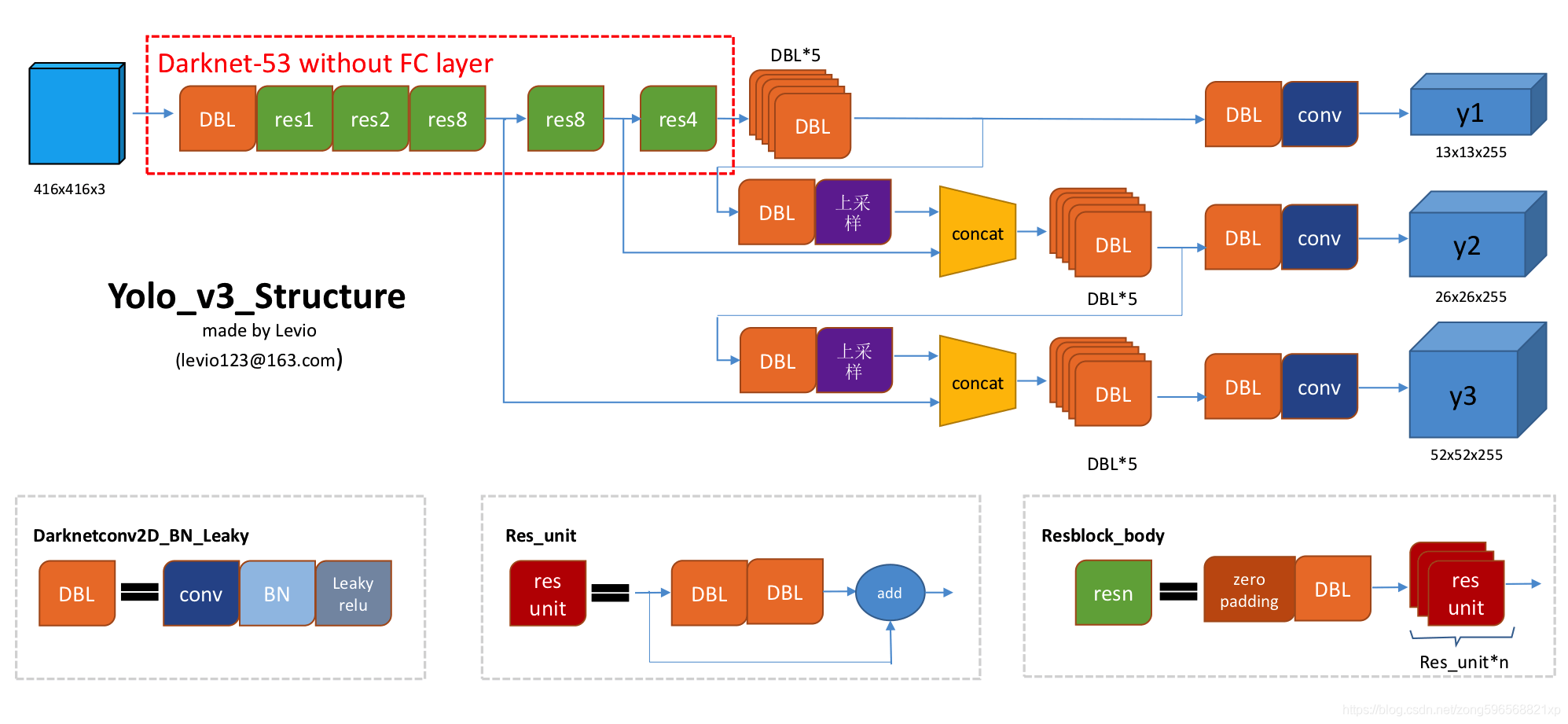
yolov3 主要有以下幾個特點:
- 采用 darknet53 作為特征提取網路;
- 多尺度預測,輸出三個分支,分別是 8 倍、16 倍、32 倍下采樣,分別實作對小目標、中目標、大目標的檢測;
- 每個尺度使用三種寬高比的 anchor 進行預測,所以總共包含 9 個 anchor;
- 網路的三個基本組件,分別是 DBL、res unit、 rexn,具體細節參考上圖;
- 沒有池化層和全連接層,通過改變卷積核的步長來調整張量的尺寸;
通過上邊的歸納,相信你對 yolov3 的演算法原理有了基本的了解,接下來重點介紹代碼實作部分,
3 show me code
3.1 總體流程
要完成一個深度學習模型的推理,我們要依次完成以下步驟:
- 定義模型輸入
- 定義模型輸出
- 加載權重檔案
- 準備輸入資料
- 模型前向推理
- 輸出后處理
- 結果可視化
總體代碼如下(代碼是在 YunYang1994/TensorFlow2.0-Examples 的基礎上修改的),本質上深度學習模型推理都是類似的流程,只不過不同的演算法在網路實作部分會有差異,
# 1、定義模型輸入
input_size = 416
input_layer = tf.keras.layers.Input([input_size, input_size, 3])
# 2、定義模型輸出
# 獲得三種尺度的卷積輸出
# 具體實作見 YOLOv3 函式說明
feature_maps = YOLOv3(input_layer)
bbox_tensors = []
# 依次遍歷小、中、大尺寸的特征圖
for i, fm in enumerate(feature_maps):
# 對每個分支的通道資訊進行解碼,得到預測框的大小、置信度和類別概率
# 具體操作見 decode 函式說明
bbox_tensor = decode(fm, i)
bbox_tensors.append(bbox_tensor)
# 3 加載權重檔案
# 根據上邊定義好的輸入輸出,實體化模型
model = tf.keras.Model(input_layer, bbox_tensors)
# 加載權重檔案
utils.load_weights(model, "./yolov3.weights")
# 輸出模型資訊
model.summary()
# 4、準備輸入資料
image_path = "./docs/kite.jpg"
original_image = cv2.imread(image_path)
original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
original_image_size = original_image.shape[:2]
image_data = utils.image_preporcess(np.copy(original_image), [input_size, input_size])
image_data = image_data[np.newaxis, ...].astype(np.float32)
# 5、模型前向推理
pred_bbox = model.predict(image_data)
pred_bbox = [tf.reshape(x, (-1, tf.shape(x)[-1])) for x in pred_bbox]
pred_bbox = tf.concat(pred_bbox, axis=0)
# 6、輸出后處理,
bboxes = utils.postprocess_boxes(pred_bbox, original_image_size, input_size, 0.3)
bboxes = utils.nms(bboxes, 0.45, method='nms')
# 7、結果可視化
image = utils.draw_bbox(original_image, bboxes)
image = Image.fromarray(image)
image.save("result.jpg")
# image.show()其中模型定義、資料后處理是關鍵,這里對其具體的實作進行介紹
3.2 網路結構
代碼中的 common.convolutional() 和 common.upsample() 是實作卷積層和上采樣操作,其定義在工程中 common.py 檔案中,這里不再進一步展開,
def YOLOv3(input_layer):
# 輸入層進入 Darknet-53 網路后,得到了三個分支
route_1, route_2, conv = backbone.darknet53(input_layer)
# 見上圖中的橘黃色模塊(DBL),一共需要進行5次卷積操作
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv = common.convolutional(conv, (3, 3, 512, 1024))
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv = common.convolutional(conv, (3, 3, 512, 1024))
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv_lobj_branch = common.convolutional(conv, (3, 3, 512, 1024))
# conv_lbbox 用于預測大尺寸物體,shape = [None, 13, 13, 255]
conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3*(NUM_CLASS + 5)),
activate=False, bn=False)
conv = common.convolutional(conv, (1, 1, 512, 256))
# 這里的 upsample 使用的是最近鄰插值方法,這樣的好處在于上采樣程序不需要學習,從而減少了網路引數
conv = common.upsample(conv)
conv = tf.concat([conv, route_2], axis=-1)
conv = common.convolutional(conv, (1, 1, 768, 256))
conv = common.convolutional(conv, (3, 3, 256, 512))
conv = common.convolutional(conv, (1, 1, 512, 256))
conv = common.convolutional(conv, (3, 3, 256, 512))
conv = common.convolutional(conv, (1, 1, 512, 256))
conv_mobj_branch = common.convolutional(conv, (3, 3, 256, 512))
# conv_mbbox 用于預測中等尺寸物體,shape = [None, 26, 26, 255]
conv_mbbox = common.convolutional(conv_mobj_branch, (1, 1, 512, 3*(NUM_CLASS + 5)),
activate=False, bn=False)
conv = common.convolutional(conv, (1, 1, 256, 128))
conv = common.upsample(conv)
conv = tf.concat([conv, route_1], axis=-1)
conv = common.convolutional(conv, (1, 1, 384, 128))
conv = common.convolutional(conv, (3, 3, 128, 256))
conv = common.convolutional(conv, (1, 1, 256, 128))
conv = common.convolutional(conv, (3, 3, 128, 256))
conv = common.convolutional(conv, (1, 1, 256, 128))
conv_sobj_branch = common.convolutional(conv, (3, 3, 128, 256))
# conv_sbbox 用于預測小尺寸物體,shape = [None, 52, 52, 255]
conv_sbbox = common.convolutional(conv_sobj_branch, (1, 1, 256, 3*(NUM_CLASS +5)),
activate=False, bn=False)
return [conv_sbbox, conv_mbbox, conv_lbbox]3.3 darknet53
darknet53 網路結構如圖所示,主要是由卷積層、殘差模塊組成,
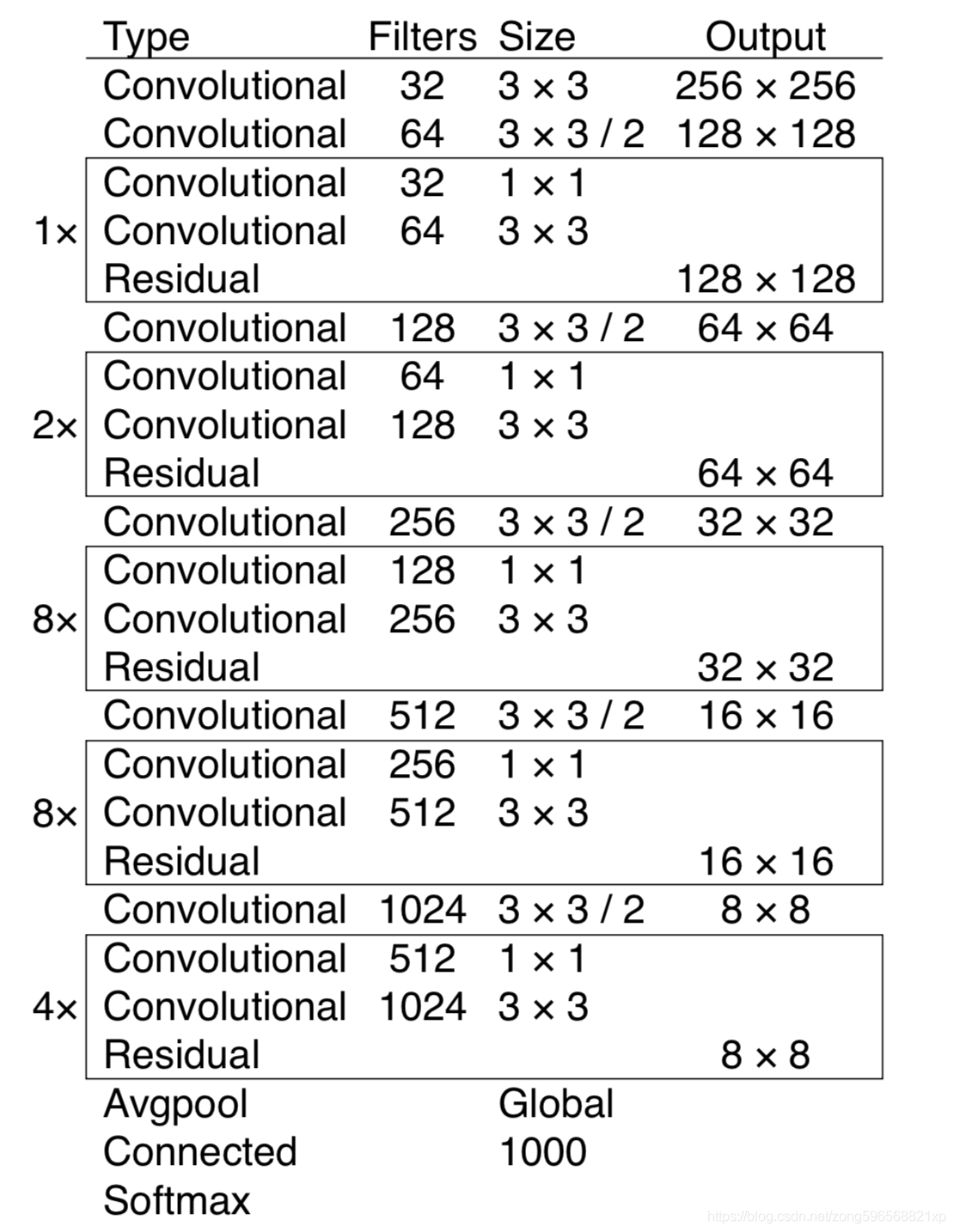
利用 common.residual_block() 實作殘差連接,
def darknet53(input_data):
input_data = common.convolutional(input_data, (3, 3, 3, 32))
input_data = common.convolutional(input_data, (3, 3, 32, 64), downsample=True)
for i in range(1):
input_data = common.residual_block(input_data, 64, 32, 64)
input_data = common.convolutional(input_data, (3, 3, 64, 128), downsample=True)
for i in range(2):
input_data = common.residual_block(input_data, 128, 64, 128)
input_data = common.convolutional(input_data, (3, 3, 128, 256), downsample=True)
for i in range(8):
input_data = common.residual_block(input_data, 256, 128, 256)
route_1 = input_data
input_data = common.convolutional(input_data, (3, 3, 256, 512), downsample=True)
for i in range(8):
input_data = common.residual_block(input_data, 512, 256, 512)
route_2 = input_data
input_data = common.convolutional(input_data, (3, 3, 512, 1024), downsample=True)
for i in range(4):
input_data = common.residual_block(input_data, 1024, 512, 1024)
return route_1, route_2, input_data3.4 decode 處理
yolov3 網路的三個分支輸出會被送入 decode 模塊對 feature map 的通道資訊進行解碼,輸出的是預測框在原圖上的 [x, y, w, h, score, prob]
def decode(conv_output, i=0):
"""
return tensor of shape [batch_size, output_size, output_size, anchor_per_scale, 5 + num_classes]
contains (x, y, w, h, score, probability)
"""
conv_shape = tf.shape(conv_output)
batch_size = conv_shape[0]
output_size = conv_shape[1]
# 對 tensor 進行 reshape
conv_output = tf.reshape(conv_output, (batch_size, output_size, output_size, 3, 5 + NUM_CLASS))
# 按順序提取[x, y, w, h, c]
conv_raw_dxdy = conv_output[:, :, :, :, 0:2] # 中心位置的偏移量
conv_raw_dwdh = conv_output[:, :, :, :, 2:4] # 預測框長寬的偏移量
conv_raw_conf = conv_output[:, :, :, :, 4:5] # 預測框的置信度
conv_raw_prob = conv_output[:, :, :, :, 5: ] # 預測框的類別概率
# 好了,接下來是畫網格,其中,output_size 等于 13、26 或者 52
y = tf.tile(tf.range(output_size, dtype=tf.int32)[:, tf.newaxis], [1, output_size])
x = tf.tile(tf.range(output_size, dtype=tf.int32)[tf.newaxis, :], [output_size, 1])
xy_grid = tf.concat([x[:, :, tf.newaxis], y[:, :, tf.newaxis]], axis=-1)
xy_grid = tf.tile(xy_grid[tf.newaxis, :, :, tf.newaxis, :], [batch_size, 1, 1, 3, 1])
xy_grid = tf.cast(xy_grid, tf.float32) # 計算網格左上角的位置,即cx cy的值
# 根據上圖公式計算預測框的中心位置
# 這里的 i=0、1 或者 2, 以分別對應三種網格尺度
pred_xy = (tf.sigmoid(conv_raw_dxdy) + xy_grid) * STRIDES[i] # 計算預測框在原圖尺寸上的x y
pred_wh = (tf.exp(conv_raw_dwdh) * ANCHORS[i]) * STRIDES[i] # 計算預測框在原圖尺寸上的w h
pred_xywh = tf.concat([pred_xy, pred_wh], axis=-1) # 拼接起來
pred_conf = tf.sigmoid(conv_raw_conf) # 計算預測框里object的置信度
pred_prob = tf.sigmoid(conv_raw_prob) # 計算預測框里object的類別概率
return tf.concat([pred_xywh, pred_conf, pred_prob], axis=-1)3.5 后處理
從網路結構拿到檢測框之后,就需要對框進行后處理了,包括根據閾值去掉得分低的檢測框、NMS過濾掉多余的檢測框等,然后再把框在原圖上繪制出來,就完成了整個檢測流程,
4 summary
通過本文的介紹,相信大家對 TensorFlow 的特點以及實作目標檢測演算法的流程有一個基本的了解,在后續的文章中,我會進一步的介紹如何訓練 yolov3 網路,以及如何在生產環境中部署 yolov3 網路,敬請期待!
本文由 TensorFlow 社區作者創作,文章已入選 “TensorFlow 開發者出道計劃” 精選推薦,關注 TensorFlow 社區,參與社區共建,點擊這里了解更多, 全能社區,一起建設!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/242337.html
標籤:AI