我們之前學習zookeeper集群節點搭建時一直都是搭建集群數為2n+1,不管是自己搭建還是公司搭建都是2n+1,至于為什么是2n+1一直都是一個模糊的概念,今天我重點學習了一下zookeeper翻閱了大量的資料大概理解了一下,現將其整理記錄下來,
首先我們要先理解一下zookeeper的選舉機制
得到的票數/集群的總數 > 50%就成leader(這句話很關鍵)

- 當啟動了130,130就會投自己一票 此時的到的總票數 1/3=30%
- 啟動129:
129與130進行新一輪投票
129 投自己一票 1/3
130 投自己一票 1/3 - pk投票
pk規則(選舉的規則)
3.1. 對比事物id(zxid)誰大就該投誰
假如出現事物id相同
3.2. 比較服務器id誰大(myid),就改投誰,130=3 129=2
130勝出,129改投130
130 票數 2/3 = 66% > 50% leader - 128啟動時同理所以130必定當選leader
所以這個時候建議服務器性能比較好,設定他的id值大一些
當我們了解了zookeeper選舉機制后就能來講為什么集群需要2n+1個
1、防止由腦裂問題造成的集群不可用,
關于腦裂首先我們來講一下什么是腦裂
在"雙機熱備"高可用(HA)系統中,當聯系兩個節點的"心跳線"斷開時(即兩個節點斷開聯系時),本來為一個整體、動作協調的HA系統,就分裂成為兩個獨立的節點(即兩個獨立的個體),由于相互失去了聯系,都以為是對方出了故障,兩個節點上的HA軟體像"裂腦人"一樣,“本能"地爭搶"共享資源”、爭起"應用服務",就會發生嚴重后果:
1)或者共享資源被瓜分、兩邊"服務"都起不來了;
2)或者兩邊"服務"都起來了,但同時讀寫"共享存盤",導致資料損壞(常見如資料庫輪詢著的聯機日志出錯),兩個節點相互爭搶共享資源,結果會導致系統混亂,資料損壞,對于無狀態服務的HA,無所謂腦裂不腦裂,但對有狀態服務(比如MySQL)的HA,必須要嚴格防止腦裂
[但有些生產環境下的系統按照無狀態服務HA的那一套去配置有狀態服務,結果就可想而知]
首先,什么是腦裂?集群的腦裂通常是發生在節點之間通信不可達的情況下,集群會分裂成不同的小集群,小集群各自選出自己的master節點,導致原有的集群出現多個master節點的情況,這就是腦裂,
腦裂導致的問題
引起資料的不完整性:集群中節點(在腦裂期間)同時訪問同一共享資源,而且沒有機制去協調控制的話,那么就存在資料的不完整性的可能,
服務例外:對外提供的服務出現例外,
現在我們來說一下現在我們來說一下Zookeeper 集群中的"腦裂"場景說明
對于一個集群,想要提高這個集群的可用性,通常會采用多機房部署,比如現在有一個由6臺zkServer所組成的一個集群,部署在了兩個機房:
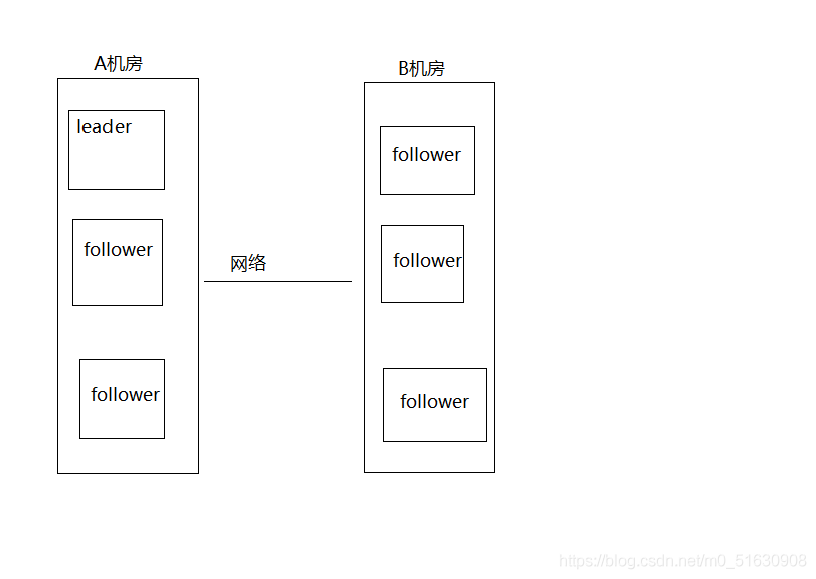
正常情況下,此集群只會有一個Leader,那么如果機房之間的網路斷了之后,兩個機房內各自的zkServer還是可以相互通信的,如果不考慮過半機制,那么就會出現每個機房內部根據選舉都將選出一個Leader,這就是資訊不可達問題
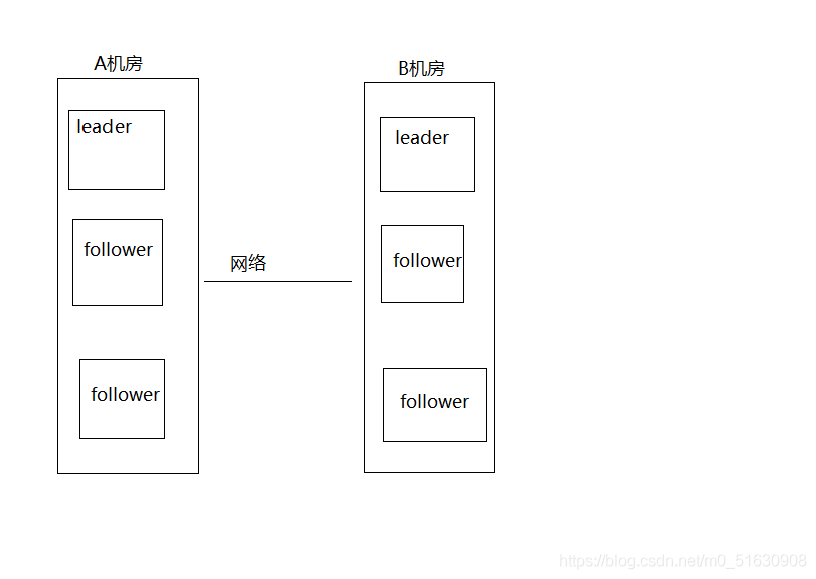
這就相當于本來是同一個集群的,被分成了不同的兩個集群,兩個集群都根據選舉出現了兩個leader,這就是腦裂現象,對于這種情況,其實也可以看出來,原本應該是統一的一個集群對外提供服務的,現在變成了兩個集群同時對外提供服務,如果過了一會,斷了的網路突然聯通了,那么就會出現問題,兩個集群剛剛都對外提供服務了,兩個機房中誰才是那個leader ,資料該由誰去解決,資料沖突問題怎么解決,
在集群中單機房中也會出現腦裂問題
我們從上述簡介中可以知道,假設一個集群、動作協調的節點A和節點B,節點A和B之間通過heartBeat來檢查對方的存活狀態,負責協調保證整個集群服務的可用性,正常情況下,如果節點A通過心跳檢測不到B的存在的時候,就會接管B的資源,同理節點B檢查不到B的存活狀態的時候也會接管A的資源,如果出現網路故障,就會導致A和B同時檢查不到對方的存活狀態認為對方出現例外,這個時候就會導致A接管B的資源,B也會接管A的資源,也會出現多個leader的情況
原本是統一的一個集群對外提供服務的,現在變成了兩個集群同時對外提供服務,兩個集群都對外提供服務了,這就是腦裂導致的資訊不一致,
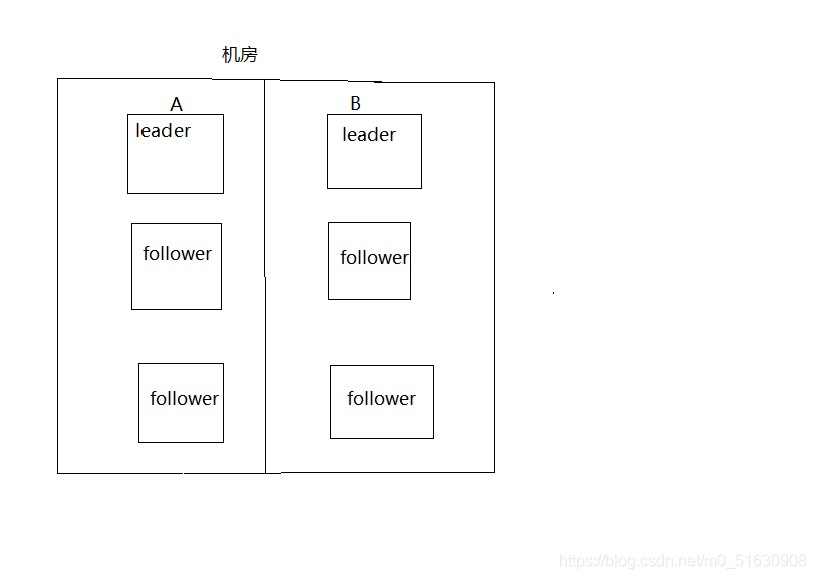
下面舉例說一下為什么采用奇數臺節點,就可以防止由于腦裂造成的服務不可用:
(1) 假如zookeeper集群有 5個節點,分別放在了不同的機房假設機房中放的個數不同(這樣也模模擬出了 同一機房發生腦裂的問題),現在網路突然波動,發生了腦裂,腦裂成了A、B兩個小集群:
第一種情況 A機房 : 1個節點 ,B 機房:4個節點
第二種情況 A機房 : 2個節點, B機房 :3個節點
可以看出,上面這兩種情況下當網路恢復時,A、B中總會有一個小集群滿足 可用節點數量 > 總節點數量/2,所以zookeeper集群仍然能夠選舉出leader , 仍然能對外提供服務,并且能整合資料,只不過是有一部分節點失效了而已,
(2) 假如zookeeper集群有4個節點,同樣發生腦裂,腦裂成了A、B兩個小集群:
第一種情況 A機房 : 1個節點 ,B 機房:3個節點
第二種情況 A機房 : 2個節點, B機房 :2個節點
可以看出,情況1 是滿足選舉條件的,與(1)中的例子相同, 但是情況2 就不同了,因為A和B都是2個節點,都不滿足 可用節點數量 >總節點數量/2 的選舉條件, 所以此時zookeeper就徹底不能提供服務了,
在同一個機房中也是一樣的,在奇數個服務器中,不管腦裂成什么情況個數不同的集群,只要是集群多的推選出leader票數必定大于1/2,
所以綜合上面兩個例子可以看出: 在節點數量是奇數個的情況下, zookeeper集群總能對外提供服務(即使損失了一部分節點);如果節點數量是偶數個,會存在zookeeper集群不能用的可能性(腦裂成兩個均等的子集群的時候),
在生產環境中,如果zookeeper集群不能提供服務,那將是致命的 , 所以zookeeper集群的節點數一般采用奇數個,
2、在容錯能力相同的情況下,奇數臺更節省資源,
(1) 假如zookeeper集群1 ,有3個節點,3/2=1.5 , 即zookeeper想要正常對外提供服務(即leader選舉成功),至少需要2個節點是正常的,換句話說,3個節點的zookeeper集群,允許有一個節點宕機,
(2) 假如zookeeper集群2,有4個節點,4/2=2 ,
即zookeeper想要正常對外提供服務(即leader選舉成功),至少需要3個節點是正常的,換句話說,4個節點的zookeeper集群,也允許有一個節點宕機,
那么問題就來了, 集群1與集群2都有
允許1個節點宕機的容錯能力,但是集群2比集群1多了1個節點,在相同容錯能力的情況下,本著節約資源的原則,zookeeper集群的節點數維持奇數個更好一些,
3.確保事務能夠順利進行
| 先看圖再分析 |
|---|
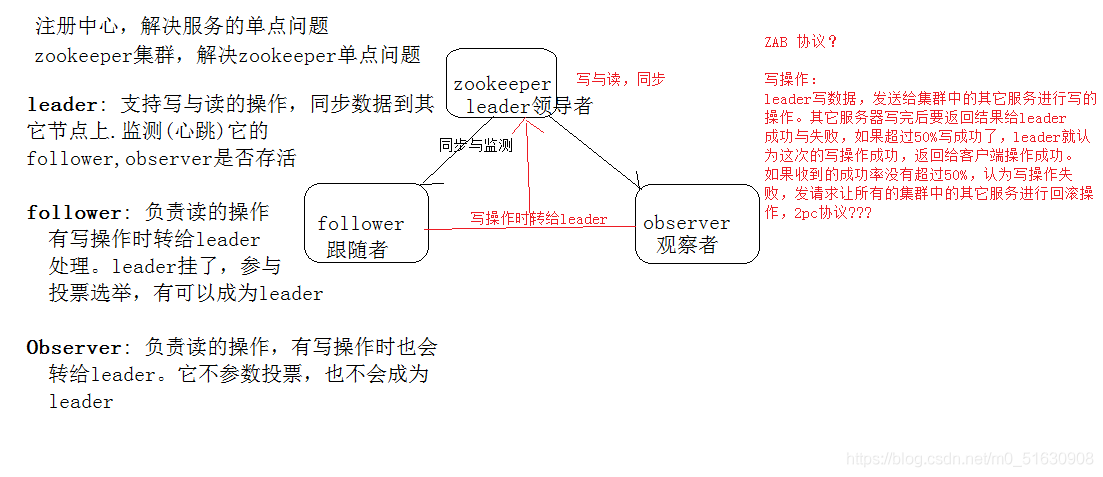
對于zookeeper的 create, setData, delete 等有寫操作的請求,則需要統一轉發給leader 處理, leader
需要決定編號、執行操作,這個程序稱為一個事務,ZAB的事務2pc, 3pc(TCC)
舉個例子寫操作時leader寫資料,發送給集群中的其他服務進行寫的操作,其他服務器寫完要回傳結果給leader成功或者是失敗,如果超過50%寫成功了,leader就認為這次寫操作成,回傳給客戶端操作成功,如果收到的成功率沒有超過50%,認為操作失敗,發送請求讓所有集群中的其他服務進行回滾操作(2pc協議)
根據上述描述我們可以清楚的了,假設我們搭建的zookeeper節點是6臺服務器的話在進行,在進行事務操作時只有2臺收到了成功,這個時候成功的zookeeper服務器一共有三臺(包括leader自己)那么此時3/6=50% 的這個時候就沒辦法判斷是否成功
當節點是奇數時就可以準確的得知是否操作成功,
假設有7臺服務器,在進行操作時有3臺服務器讀取成功,這個時候一共有四臺服務器讀取成功4/7>50%當只有2臺成功時3/7<50%,那么就可以很簡單的判斷出寫操作是否成功
| 擴展知識內容 |
|---|
1.zookeeper核心
Zookeeper的核心是原子廣播,這個機制保證了各個Server之間的同步,實作這個機制的協議叫做Zab協議,Zab協議有兩種模式,它們分別是恢復模式(選主)和廣播模式(同步),當服務啟動或者在領導者 崩潰后,Zab就進入了恢復模式,當領導者被選舉出來,且大多數Server完成了和leader的狀態同步以后,恢復模式就結束了,狀態同步保證了leader和Server具有相同的系統狀態,
? 為了保證事務的順序一致性,zookeeper采用了遞增的事務id號(zxid)來標識事務,所有的提議(proposal)都在被提出的時候加上了zxid,實作中zxid是一個64位的數字,它高32位是epoch用來標識leader關系是否改變,每次一個leader被選出來,它都會有一個新的epoch,標識當前屬于那個leader的統治時期,低32位用于遞增計數,
2、Zookeeper 的讀寫機制
? Zookeeper是一個由多個server組成的集群
? 一個leader,多個follower
?每個server保存一份資料副本
? 全域資料一致
? 分布式讀寫
? 更新請求轉發,由leader實施
3、Zookeeper 的保證
? 更新請求順序進行,來自同一個client的更新請求按其發送順序依次執行
? 資料更新原子性,一次資料更新要么成功,要么失敗
? 全域唯一資料視圖,client無論連接到哪個server,資料視圖都是一致的
? 實時性,在一定事件范圍內,client能讀到最新資料
4、Zookeeper節點資料操作流程
1.在Client向Follwer發出一個寫的請求
2.Follwer把請求發送給Leader
3.Leader接收到以后開始發起投票并通知Follwer進行投票
4.Follwer把投票結果發送給Leader
5.Leader將結果匯總后如果需要寫入,則開始寫入同時把寫入操作通知給Leader,然后commit;
6.Follwer把請求結果回傳給Client
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/243983.html
標籤:其他