前言
本次打卡用于鞏固知識,在一些細節上進行了一定程度的展開和說明,溫故而知新,
Mission01 企業收入的多樣性
題目:一個企業的產業收入多樣性可以仿照資訊熵的概念來定義收入熵指標:
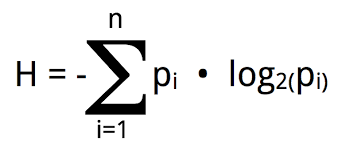
其中pi是企業該年某產業收入額占該年所有產業總收入的比重,在Company.csv中存有需要計算的企業和年份,在Company_data.csv中存有企業、各類收入額和收入年份的資訊,現請利用后一張表中的資料,在前一張表中增加一串列示該公司該年份的收入熵指標 I,
步驟一 觀察資料
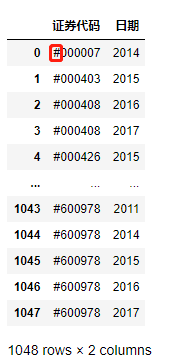
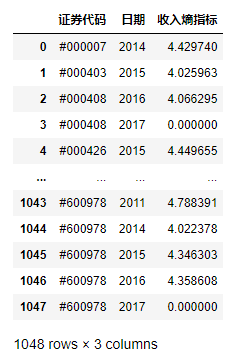
df1 = pd.read_csv('./data/mission01/Company.csv')
df1
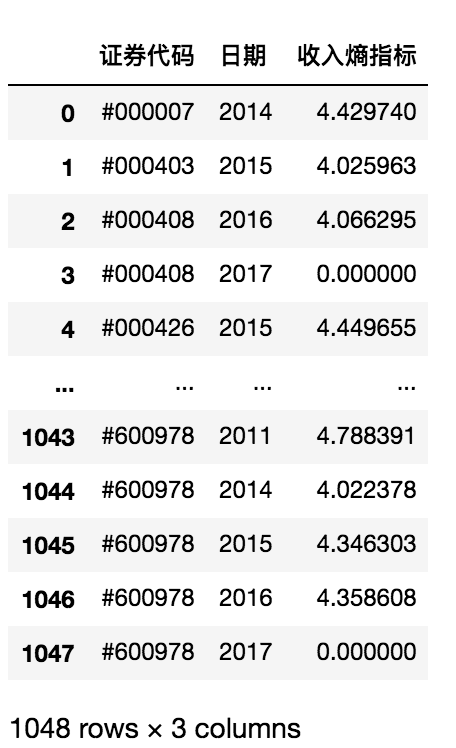
df2 = pd.read_csv('./data/mission01/Company_data.csv')
df2
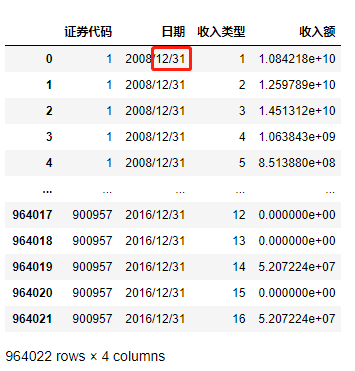
這里發現了表1和表2中股票代碼和日期格式的不同,在之后的操作中要進行處理,
步驟二 細節處理
#這里考慮到收入占比需要保證為大于0,否則會對log運算產生影響
df2 = df2[df2['收入額'] > 0]
df2['日期'] = df2['日期'].apply(lambda x:x[:4])
df2.set_index(['證券代碼','日期'],inplace=True)
df2=df2['收入額']
df2
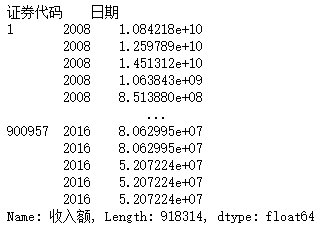
我們將日期修改為只保留年份,并將表2的索引設定為證券代碼和日期,最后在列展示方面只保留收入額這一列,最后得到的df2為收入額不為0的擁有多級行索引的待處理Series型資料,值為不同企業不同年份的收入,
步驟三 構造自定義方法
#用于求收入熵的方法
def getEntropy(x):
p = x/x.sum()
res = -(p*np.log2(p)).sum()
return res
#用于求一家公司某一年份的收入熵
def getTotalEntropy(x):
#拿到每一行的公司代碼和年份資料
companyCode = int(x[0][1:])
year = str(x[1])
if (companyCode,year) in df2.index:
return df2.loc[(companyCode,year)].agg(getEntropy)
else:
return 0
#df1中的資料df2不一定存在 所以要提前判斷
df1['收入熵指標']=df1.apply(getTotalEntropy,axis=1)
df1
思路:利用apply方法對表1行進行遍歷,對每一行通過表2的對應資訊計算收入熵指數后回傳,
注意,表1中的部分行不在表2中,所以在自定義方法中計算收入熵之前需要做一個包含關系判斷,
另外,對于熵的計算,將負收入和零收入直接去掉,這樣丟棄資料可能會損失一部分資訊,
完整代碼
#用于求收入熵的方法
def getEntropy(x):
p = x/x.sum()
return -(p*np.log2(p)).sum()
#用于求一家公司某一年份的收入熵
def getTotalEntropy(x):
#拿到每一行的公司代碼和年份資料
companyCode = int(x[0][1:])
year = str(x[1])
#df1中的資料df2不一定存在 所以要提前判斷
if (companyCode,year) in df2.index:
return df2.loc[(companyCode,year)].agg(getEntropy)
else:
return 0
df1 = pd.read_csv('./data/mission01/Company.csv')
df2 = pd.read_csv('./data/mission01/Company_data.csv')
#處理表2資料
df2 = df2[df2['收入額'] > 0]
df2['日期'] = df2['日期'].apply(lambda x:x[:4])
df2.set_index(['證券代碼','日期'],inplace=True)
df2=df2['收入額']
#遍歷表1的行 求每行的收入熵指標
# df1['收入熵指標']=df1.apply(getTotalEntropy,axis=1)
df1.insert(2,'收入熵指標',df1.apply(getTotalEntropy,axis=1))
df1
注:這里最終在插入行時使用了insert方法,通過的是絕對位置插入的,此處不能像python索引一樣使用負數,如果想要動態插入,需要提前獲取整個列索引的長度,
Mission02 組隊學習資訊表的變換
題目:請把組隊學習的隊伍資訊表變換為如下形態,其中“是否隊長”一列取1表示隊長,否則為0
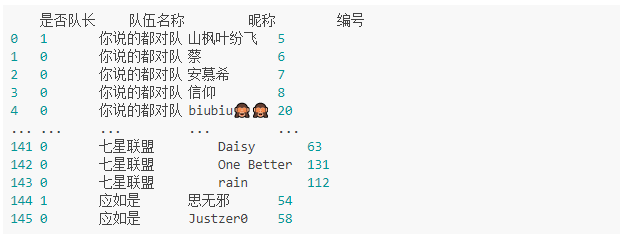
步驟一 讀取資料并獲取有效資訊
#步驟一 讀取資料并獲取有效資訊
df = pd.read_excel('./data/mission02/pandas_team.xlsx')
#儲存隊伍名和最多人數
teams = df['隊伍名稱']
#截取表格
df = df[df.columns[2:]]
max_num = df.shape[1]//2
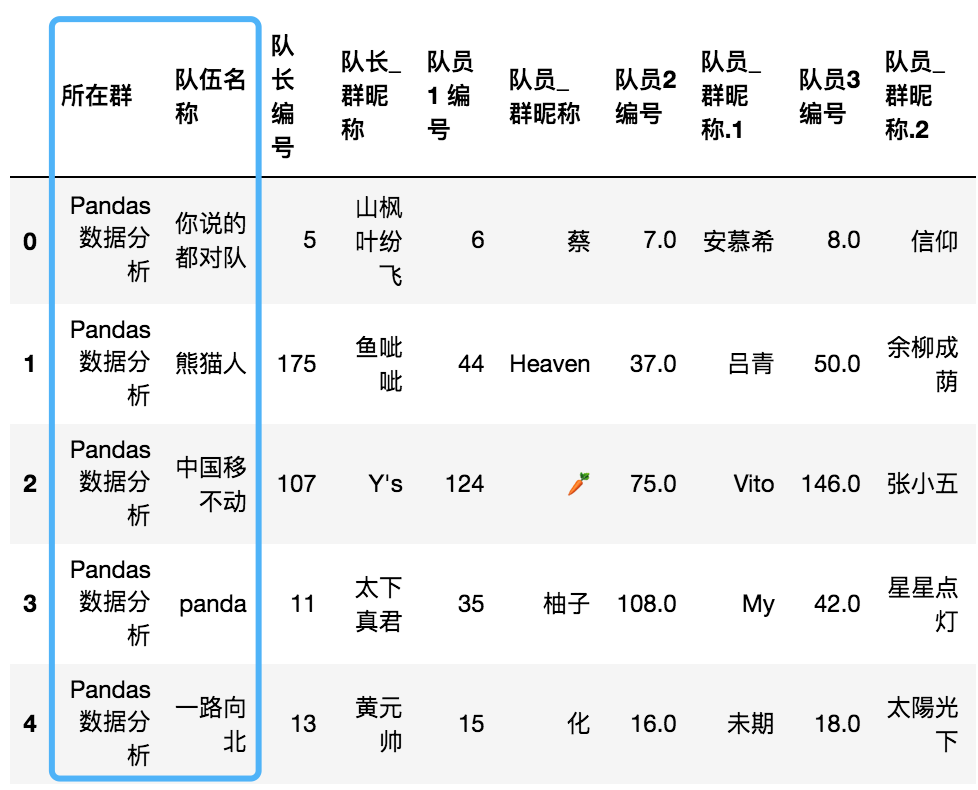
思路:讀取資料,用teams變數儲存隊伍資訊,用max_num變數儲存每隊最多人數,去掉資料表的前兩列,
步驟二 新建列索引并改變
#第二步
max_num = df.shape[1]//2
team_num = df.shape[0]
#構建列索引
a = [x for x in range(max_num)]
cols = pd.MultiIndex.from_product([a,['編號','昵稱']])
df.columns = cols
df.head()
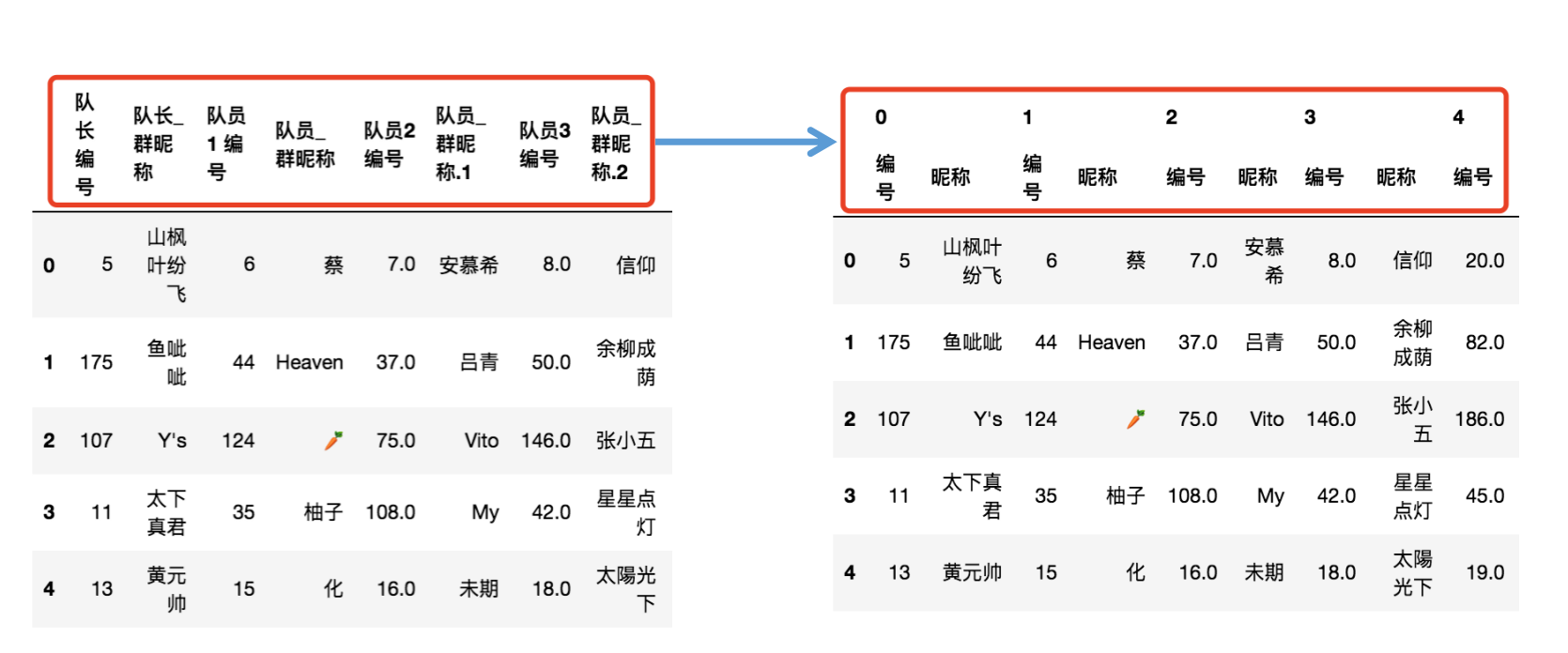
思路:利用多級索引中from_product(笛卡爾積的創建方式)創建新的索引,對列索引進行重構,利用第一層列索引映射到每只隊伍的資訊,以便后續操作,
步驟三 變形
df = df.stack()
df.head()
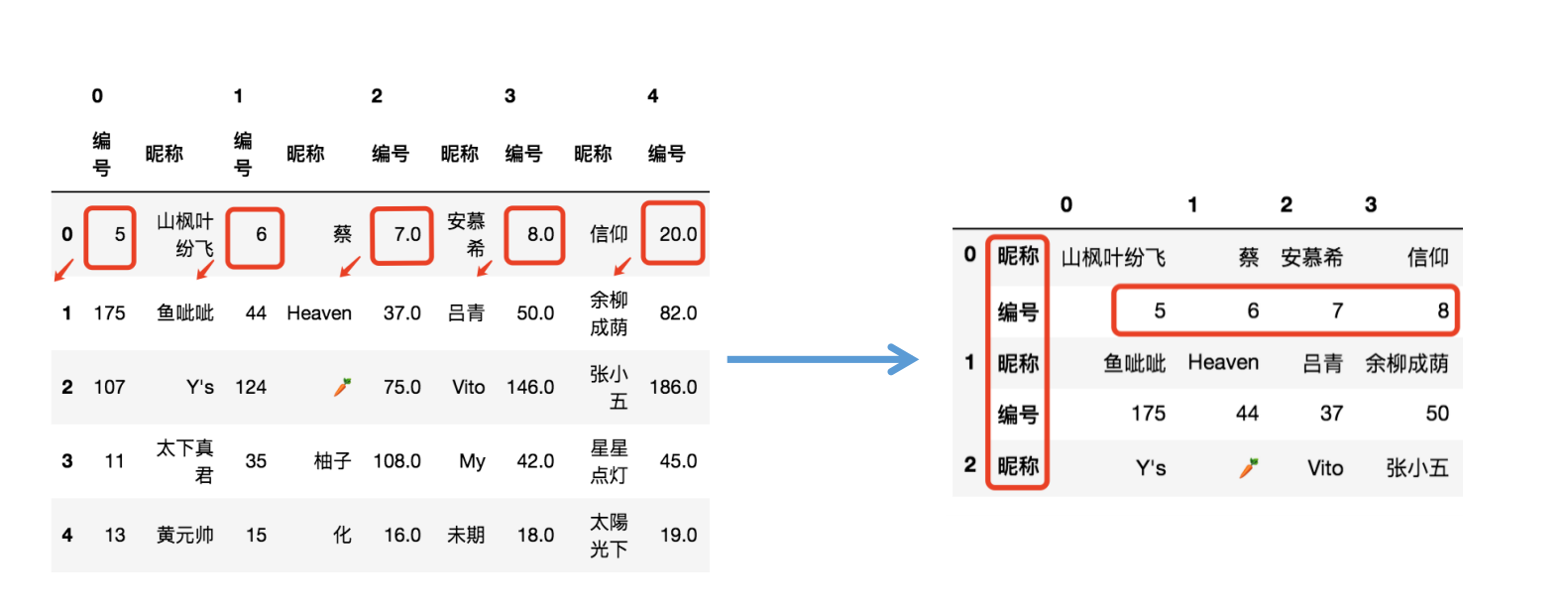
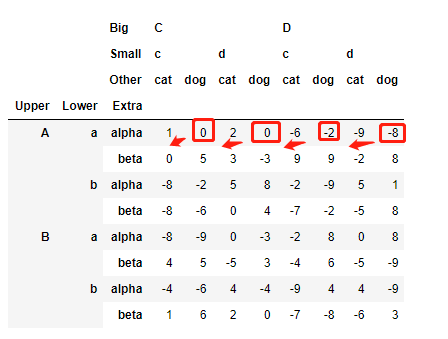
思路:利用stack將列索引的最后一層移動到行索引的最后一層,這里用到了stack的斜移特性,效果如下,需要注意的是經過變形后編號的dtype型均變為int型,
df = df.T
df.head()
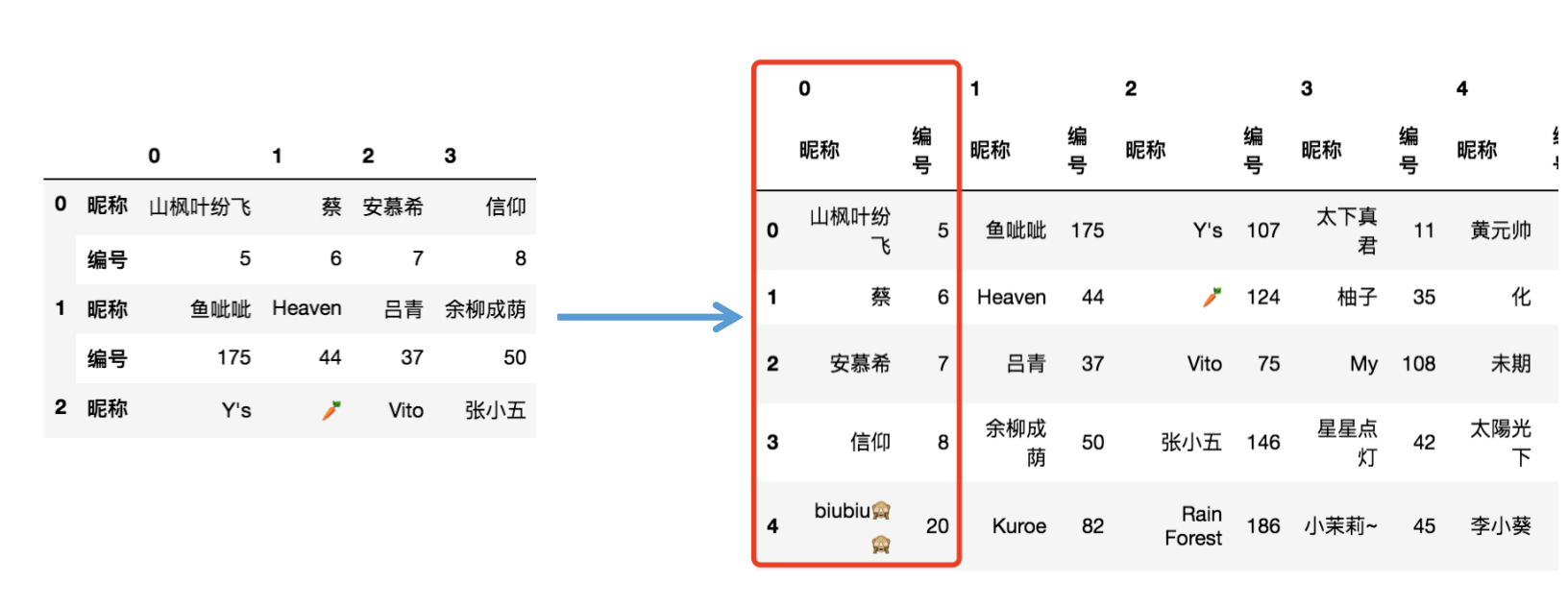
思路:然后將資料表進行轉置,得到右圖,第一層列索引即指向每一隊的資訊,紅框中代表第一隊資訊,此時輪廓已經初現,
步驟四 堆疊
res = []
[res.append(df[i]) for i in range(len(teams)]
res = pd.concat(res)
res
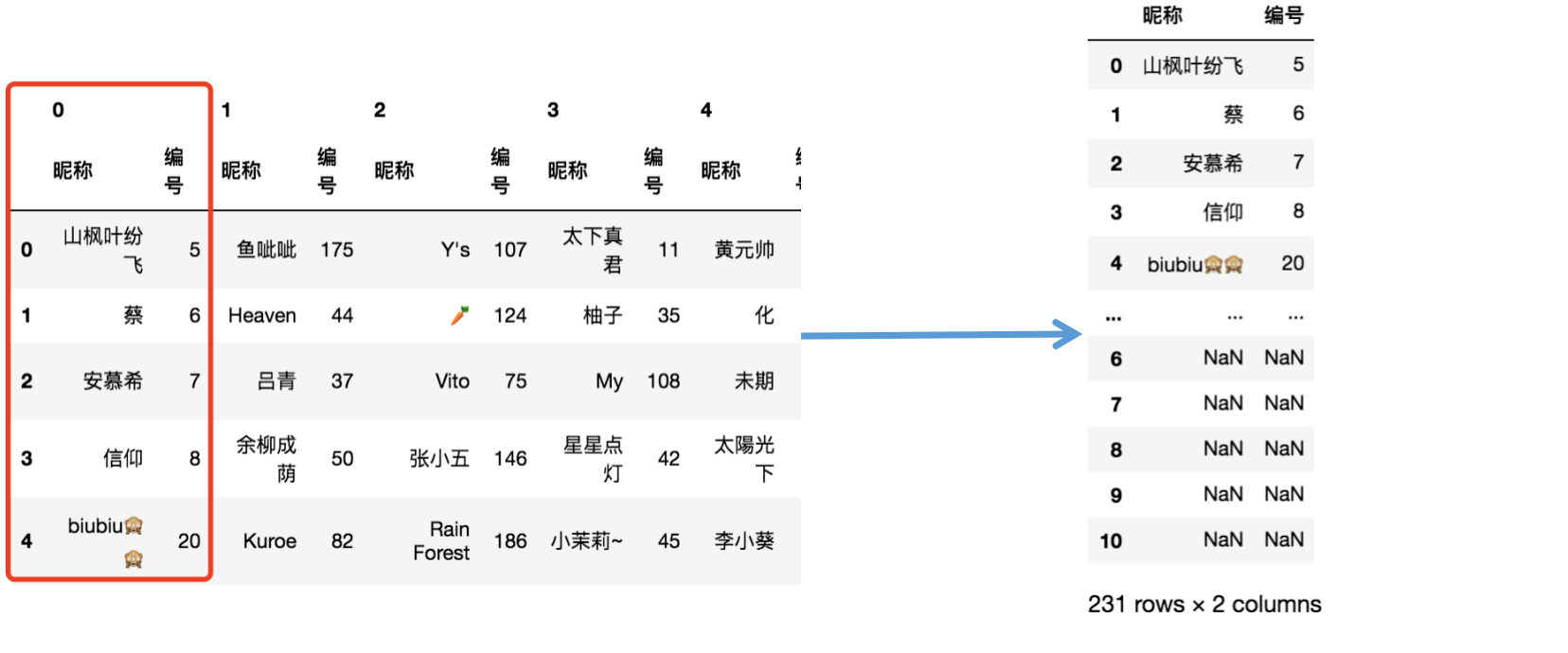
思路:按第一層列索引利用concat方法將每只隊伍的資訊進行堆疊,得到右圖所示資料圖,
步驟五 構造額外資訊列
captain_col = np.array([[1]+[0]*(max_num-1)]*len(teams)).flatten()
teamname_col=[[x]*max_num for x in teams.values]
teamname_col = np.array(teamname_col).flatten()
print(captain_col.shape)
(231,)
print(teamname_col.shape)
(231,)
res.insert(0,'是否隊長',captain_col)
res.insert(1,'隊伍名稱',teamname_col)
res

思路:利用在步驟一拿到的隊伍資訊和人數資訊,構建兩列新的資訊列,然后使用insert方法將其插入到資料表中,
步驟六 剔除無用資訊
res = res[~res['編號'].isna()]
res.reset_index(drop=True,inplace=True)
res
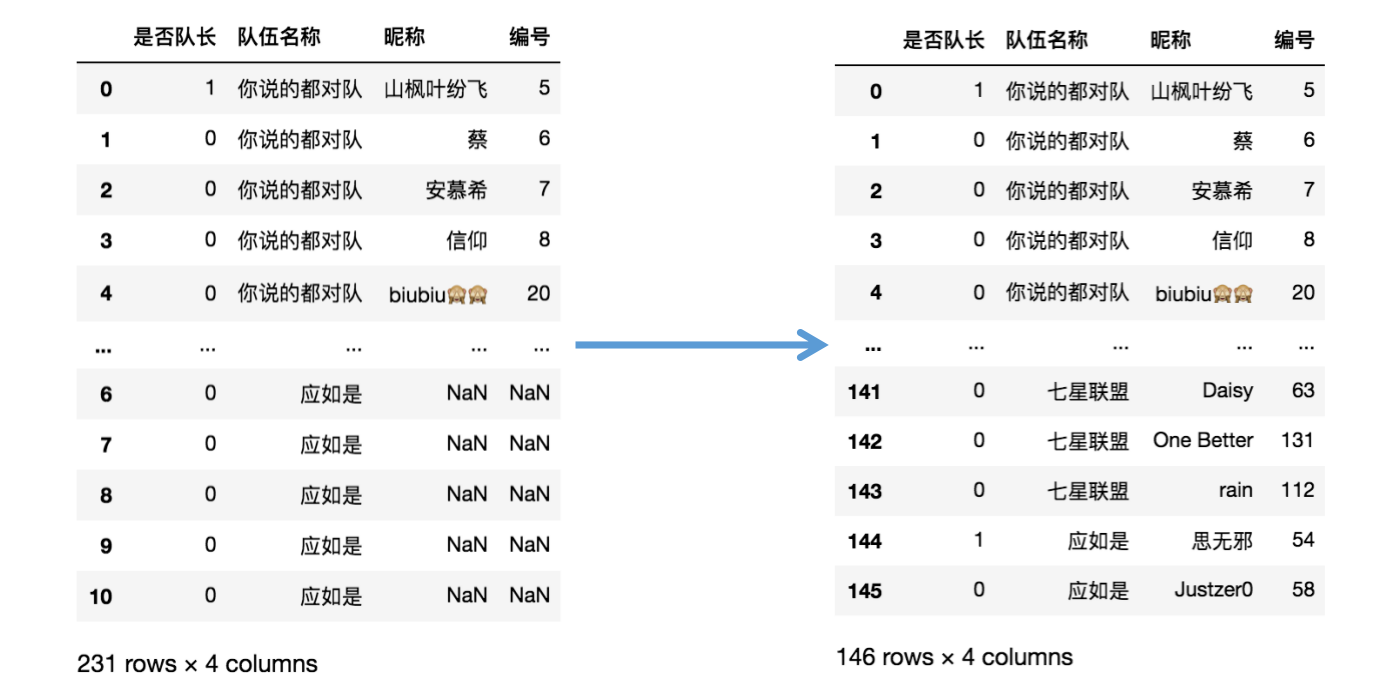
思路:利用df行的訪問方式去掉編號為NaN的行,同時將行索引重置為默認索引,
完整代碼
#步驟一 獲取資料
df = pd.read_excel('./data/mission02/pandas_team.xlsx')
teams = df['隊伍名稱']
df = df[df.columns[2:]]
max_num = df.shape[1]//2
#步驟二 改變列索引
cols = pd.MultiIndex.from_product([[x for x in range(max_num)],['編號','昵稱']])
df.columns = cols
#步驟三 變形
df = df.stack().T
#步驟四 堆疊
res = []
[res.append(df[i]) for i in range(len(teams))]
res = pd.concat(res)
#步驟五 插入新列
res.insert(0,'是否隊長',np.array([[1]+[0]*(max_num-1)]*len(teams)).flatten())
res.insert(1,'隊伍名稱',np.array([[x]*max_num for x in teams.values]).flatten())
#步驟六 去掉無用資料
res = res[~res['編號'].isna()]
res.reset_index(drop=True,inplace=True)
res
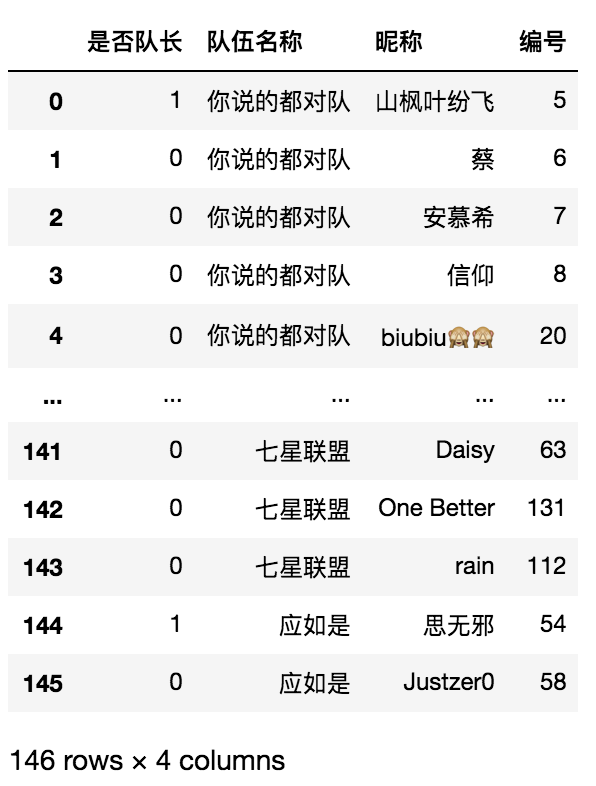
Mission03 復仇者聯盟2020大戰
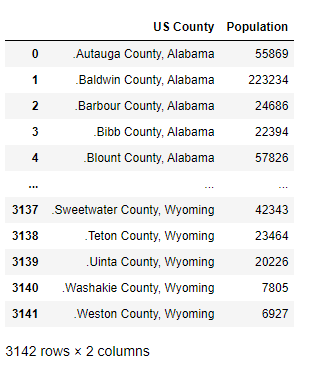
資料展示:
#人口數各縣
df1 = pd.read_csv('./data/mission03/county_population.csv')
#大選投票情況
df2 = pd.read_csv('./data/mission03/president_county_candidate.csv')
我們可以看到表1和表2中對于county列的表示是不同的,提前進行修改:
df1['US County'] = df1['US County'].apply(lambda x:x.split(',')[0][1:])
df1
這里避免每個州的縣有重名的情況,特意查看了一下:
df1['US County'].sort_values()

并未出現重名的情況,
問題1 統計有效縣
步驟一 分組統計
#統計每個縣的有效投票數
county_votes = df2.groupby('county')['total_votes'].sum()
county_votes
思路:統計每個縣的有效投票數,并存入county_votes變數中,型別為Series,
步驟二 自定義方法
def myfunc(x):
if x[0] in county_votes:
if county_votes[x[0]]>=x[1]//2:
return True
return None
return None
res = df1.apply(myfunc,axis=1)
print(res.count())
2292
思路:資料主體為表1,遍歷單位為表1的每行資料,注意需要判斷該縣是否存在于投票的縣中,然后進行數值比較,最后通過回傳非預設值和預設值的資料型別方便使用count方法進行統計,
完整代碼
def myfunc(x):
if x[0] in county_votes:
if county_votes[x[0]]>=x[1]//2:
return True
return None
return None
#統計每個縣的有效投票數
county_votes = df2.groupby('county')['total_votes'].sum()
res = df1.apply(myfunc,axis=1)
print(res.count())
2292
問題2 復仇者排名
步驟一 獲得排名串列
去除無意義的資料:
#根據候選人進行分組,求得每位候選人的得票綜述
ranklist = df2.groupby('candidate')['total_votes'].sum()
#篩掉前面兩個無意義的“候選人”,并對其余有效候選人按票數高低進行排序
ranklist = ranklist.iloc[2:].sort_values(ascending=False).index
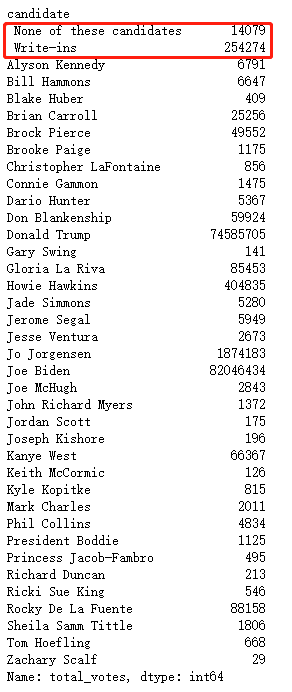

思路:利用groupby對候選人列進行分組,求得每位候選人總的得票數,并剔除掉非候選人,使用sort_values方法獲取候選人串列(按得票數從高到低),
步驟二 獲得各洲投票情況
此步用來獲得每位候選人在每個州的得票情況:
df2_demo = df2.groupby(['state','candidate'])['total_votes'].sum()
df2_demo
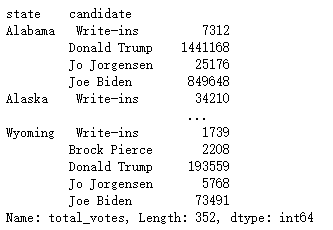
思路:利用groupby方法按洲和候選人進行分組,對得票數進行匯總,存入df2_demo變數中,型別為Series,行索引為兩層,
res = df2_demo.to_frame().unstack()
res.head()
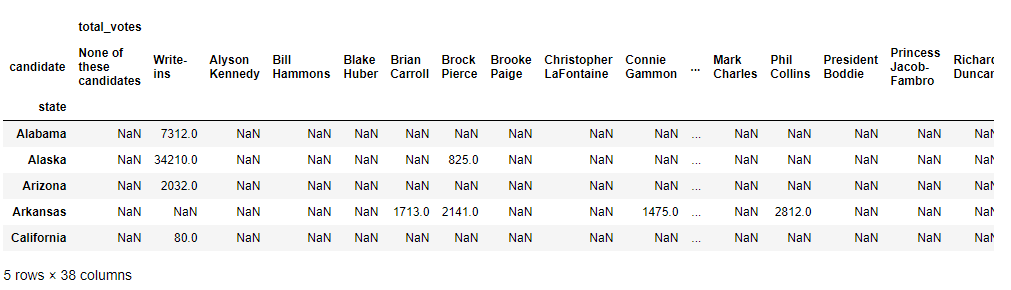
思路:利用unstack()方法將已經轉變為df的資料進行行索引移動,得到res為有效候選人在每個洲的選票情況,
步驟三 排序
直接利用第一步求出的候選人排名ranklist進行訪問,注意在訪問前要洗掉列索引的第一層索引:
#直接訪問index
res.droplevel(0,axis=1)[ranklist]
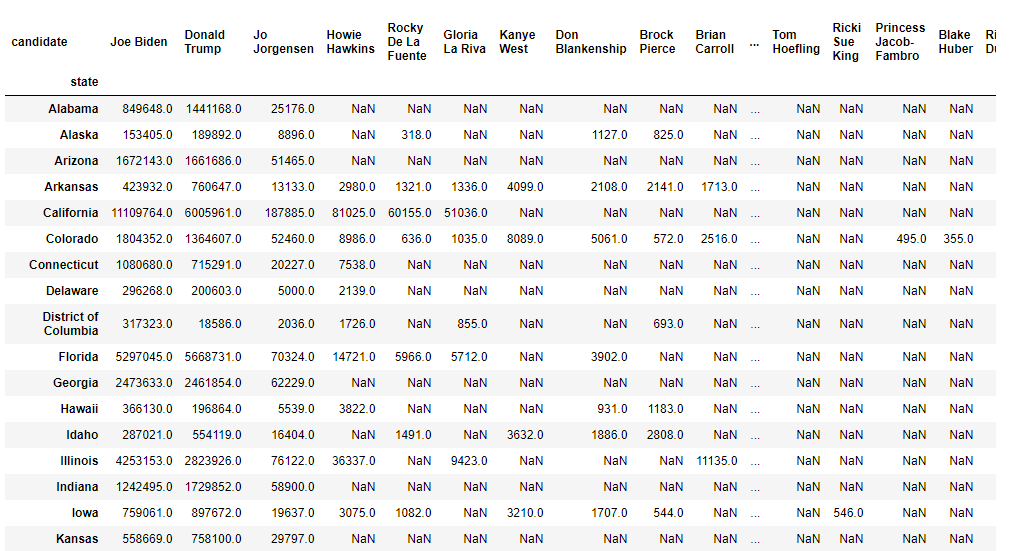
完整代碼
#根據候選人進行分組,求得每位候選人的得票綜述
ranklist = df2.groupby('candidate')['total_votes'].sum()
#篩掉前面兩個無意義的“候選人”,并對其余有效候選人按票數高低進行排序
ranklist = ranklist.iloc[2:].sort_values(ascending=False).index
#獲得每位候選人在每個州的得票情況
df2_demo = df2.groupby(['state','candidate'])['total_votes'].sum()
res = df2_demo.to_frame().unstack()
#去掉第一層列索引后直接訪問index
res.droplevel(0,axis=1)[ranklist]
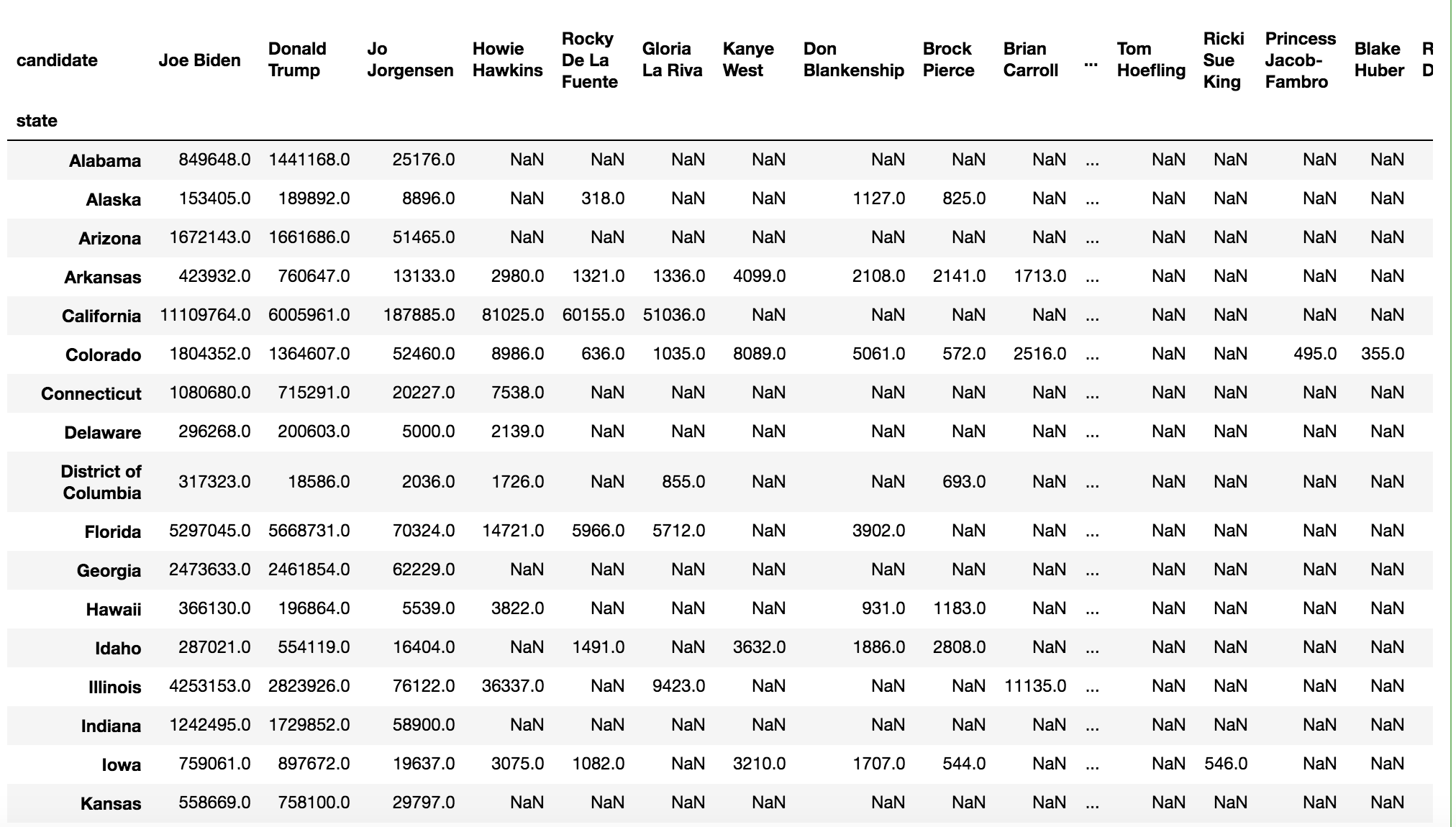
整體思路:分三步走,前兩步可以并行,首先求出每位候選人的總票數排名,存入Index資料中,這里需要注意去掉無用的前兩個值,然后利用groupby和unstack方法獲得每位候選人在不同州的得票情況,最后利用Index進行索引訪問得到需要的資料,
問題3 求驢驢洲
步驟一 資料預處理
#只保留有用的列
use_cols = ['state','county','candidate','total_votes']
df2 = df2[use_cols]
df2
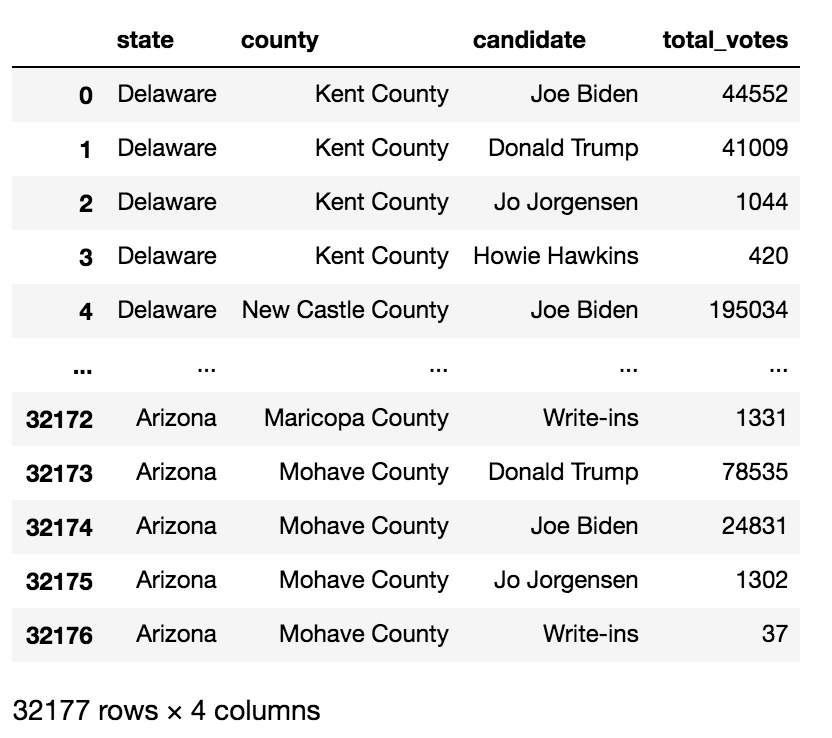
思路:只取4列,為下一步變形操作做準備,
步驟二 長寬表轉換
#長表轉寬表
res = df2[use_cols].pivot(index=['state','county'],columns='candidate',values='total_votes')
res
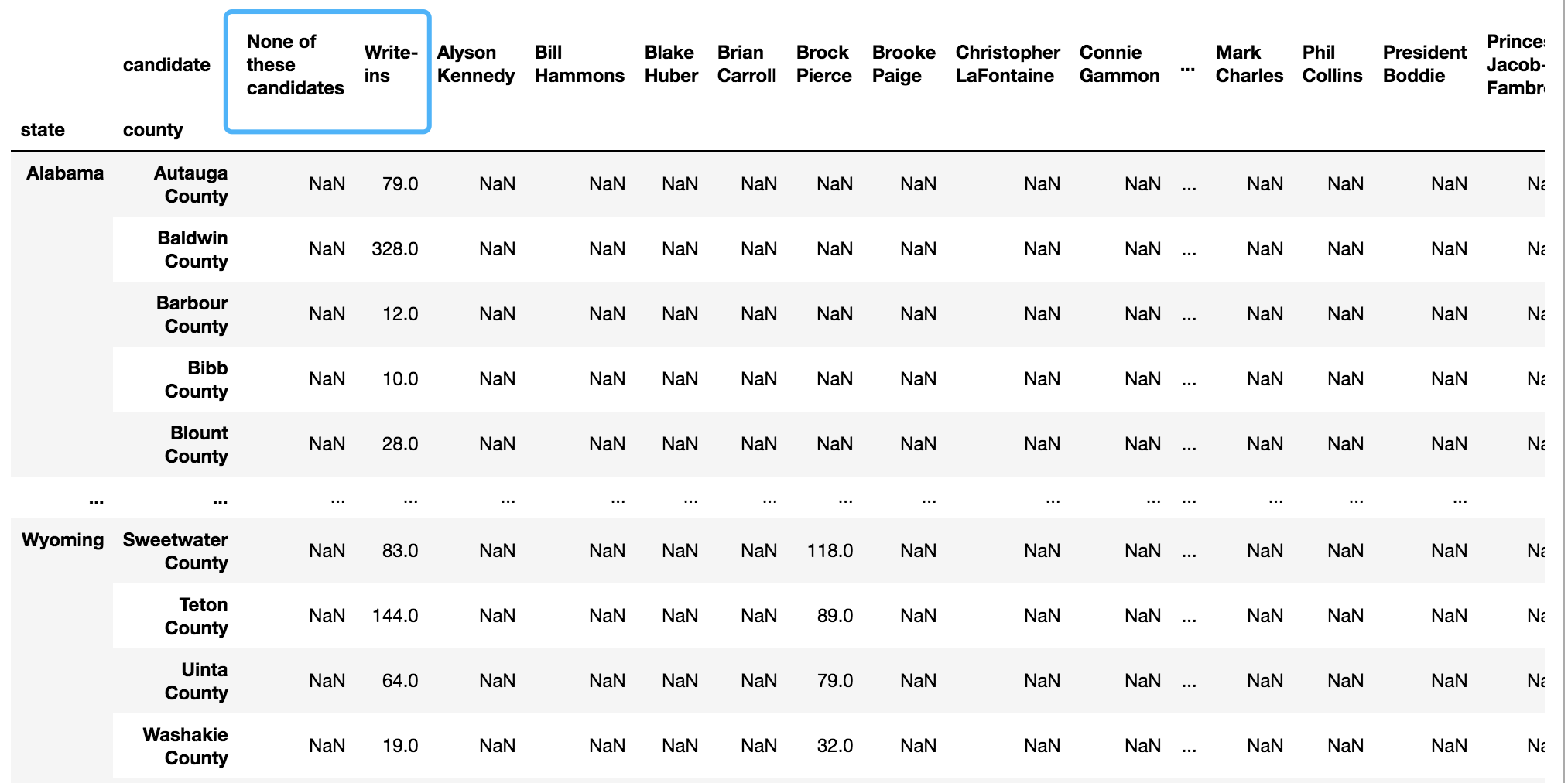
思路:步驟一得到的資料表是關于候選人的長表,根據題意用pivot方法將其轉換寬表,注意,此處由于計算的是兩者的得票率之差,所以要算入藍色框中的兩列,
步驟三 計算比率之差
#統計每個縣所有人的投票和,并計算J和D的得票率之差,存到BT列
res = res.apply(lambda x:x/x.sum(),axis=1)[['Joe Biden','Donald Trump']]
res.insert(0,'BT',res['Joe Biden']-res['Donald Trump'])
res
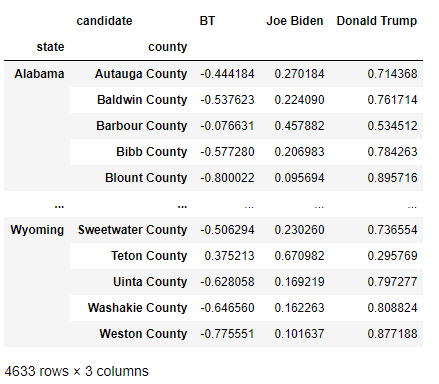
思路:利用apply方法逐行進行處理,并將得到的結果列利用insert方法插入資料表中,
步驟四 分組聚合
res = res.groupby('state')['BT'].median()>0
list(res[res].index)
['California',
'Connecticut',
'Delaware',
'District of Columbia',
'Hawaii',
'Massachusetts',
'New Jersey',
'Rhode Island',
'Vermont']
思路:對state進行分組,然后使用官方API自帶的median()方法求中位數,利用Series的布爾型別的索引訪問求得結果,
完整代碼
#資料裁剪
use_cols = ['state','county','candidate','total_votes']
df2 = df2[use_cols]
#長表轉寬表
res = df2[use_cols].pivot(index=['state','county'],columns='candidate',values='total_votes')
#統計每個縣所有人的投票和,并計算J和D的得票率之差,存到BT列
res = res.apply(lambda x:x/x.sum(),axis=1)[['Joe Biden','Donald Trump']]
res.insert(0,'BT',res['Joe Biden']-res['Donald Trump'])
#求出驢驢洲
res = res.groupby('state')['BT'].median()>0
list(res[res].index)
['California',
'Connecticut',
'Delaware',
'District of Columbia',
'Hawaii',
'Massachusetts',
'New Jersey',
'Rhode Island',
'Vermont']
思路:利用長寬表轉換方法統計每位候選人在每個縣的得票情況,然后利用apply方法逐行進行操作,求出BT指數并插入到資料表中,最后利用groupby對每個州進行分組,對州內的所有縣的BT指數進行聚合操作,判斷其中位數是否大于0,最后回傳所謂的“驢驢洲”,
完結撒花
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/243984.html
標籤:其他