相關閱讀:
最大似然估計(概率10)
重要公式(概率4)
概率統計13——二項分布與多項分布
貝葉斯決策理論(1)基礎知識 | 資料來自于一個不完全清楚的程序……
均勻分布
簡單來說,均勻分布是指事件的結果是等可能的,擲骰子的結果就是一個典型的均勻分布,每次的結果是6個離散型資料,它們的發生是等可能的,都是1/6,均勻分布也包括連續形態,比如一份外賣的配送時間是10~20分鐘,如果我點了一份外賣,那么配送員會在接單后的10~20分鐘內的任意時間送到,每個時間點送到的概率都是等可能的,
很多時候,均勻分布是源于我們對事件的無知,比如面對中途踏上公交車的陌生人,我們會判斷他在之后任意一站下車的可能性均相等,正是由于不認識這個人,也不知道他的目的地是哪里,因此只好認為在每一站下車的概率是等可能的,如果上車的是一個孕婦,并且接下來公交車會經過醫院,那么她很可能是去醫院做檢查,她在醫院附近下車的概率會遠大于其他地方,雖然不認識這名孕婦,但孕婦的屬性為我們提供了額外的資訊,讓我們稍稍變的“有知”,從而打破了分布的均勻性,
根據“均勻”的概念,如果隨機變數X在[a, b]區間內服從均勻分布,則它的密度函式是:
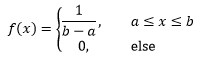
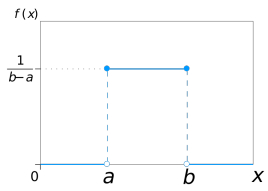
這里的區間是(a,b)還是[a,b]沒什么太大關系,
均勻分布記作X~U(a, b),當a ≤ x ≤ b時,分布函式是:
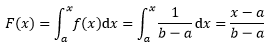
由此可知X~U(a, b)在隨機變數是任意取值時的分布函式:
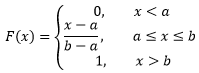
假設某個外賣配送員送單的速度在10~15分鐘之間,那么這個配送員接單后在13分鐘之內送到的概率是多少?
我們同樣對這名配送員缺乏了解,也不知道他的具體行進路線,因此認為他在10~15分鐘之間送到的概率是等可能的,每個時間點送到的概率都是dx/(15-10),因此在13分鐘內送到的概率是:
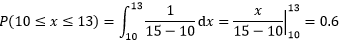
其實也沒必要每次都用積分,直接用概率分布的公式就可以了:
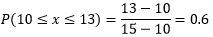
先驗與后驗
某個城市有10萬人,其中有一個是機器人偽裝的,現在有關部門提供了一臺檢測儀,當檢測儀認為被檢測物件是機器人時就會發出刺耳的警報,但這臺檢測儀并不完美,仍有1%的錯誤率,也就是說有1%的概率把一個正常人判斷成機器人,也有1%的概率把機器人誤判為正常人,對于全城的任何一個居民來說,如果檢測儀將他判斷為機器人,那么他真是機器人的概率是多大?
我們用隨機變數θ表示一個居民的真實身份,X表示檢測結果(有警報和正常兩種結果),上面的問題可以用以下概率表示:
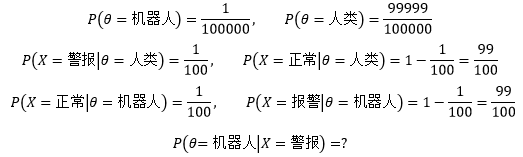
我們根據上面的式子來解釋先驗概率和后驗概率,
先驗概率(prior probability),是指根據以往經驗和分析得到的概率,與試驗結果無關,這里的“以往經驗”可能是一批歷史資料的統計,也可能是主觀的預估,值得注意的是,主觀預估絕非瞎猜,實際上主觀預估也是一種不精確的統計分析,比如我們估計一個外賣配送員的交通工具是電瓶車,雖然是一個主觀的猜測,但準確率相當高,畢竟在方圓五公里之內,電瓶車是最靈活快捷的交通工具,上面的P(θ=機器人)是一個先驗概率,它是事先知道的,不管有沒有檢測儀,檢測結果怎么樣,我們都事先認定這個城市中有一個機器人偽裝成人類的概率是10萬分之一,至于是怎么知道的就是另外一回事了,可能是接到群眾的舉報,也可能是有關部門提供的訊息,
10萬人中有一個是機器人偽裝的,先驗概率是P(θ= 機器人) = 1/100000,是否有可能有另一個先驗概率,比如10萬人中有1/100是機器人偽裝的?當然可以,按照這個邏輯,先驗概率可以是0~1之間的任何數值,
這里的引數θ代表居民的身份,有兩個取值,機器人和人類,P(θ)表示θ是某個取值的概率,既然是概率,那么θ也必然服從某個分布,這個分布就稱為先驗分布,
簡單而言,先驗概率是對隨機變數θ的取值的預估,先驗分布是關于先驗概率的概率分布(即P(θ)中θ取值的分布),如果θ的取值是連續型的,它的先驗分布就是連續型分布,
后驗概率(posterior probability),是在相關結果或者背景給定并納入考慮之后的條件概率,比如一個熊孩子持續三分鐘沒有動靜,以此為前提,這個熊孩子在“干大事”的概率就是一個后驗分布,表示為P(干大事|三分鐘沒動靜),對P(θ=機器人|X=警報)來說,檢測結果已經有了,是X=警報,在此基礎上求接受檢測的居民是否真是機器人的概率,因此這是一個后驗概率,
似然函式(likelihood function)用來描述已知隨機變數輸出結果時,未知引數的可能取值,關于似然的概念前面已經詳細介紹過,可參考 最大似然估計(概率10),
最后看看問題的答案,貝葉斯公式告訴我們:

校正先驗
假設有兩枚硬幣C1和C2,它們投出正面的概率分別是0.6和0.3,現在取其中一枚連投10次,得到的結果是前5次正面朝上,后5次反面朝上,試驗中選擇的最可能是哪枚硬幣?
我們把引數θ看成硬幣的選擇,只有兩枚硬幣,也許在現實中它們長的不一樣,大多數人會選擇更漂亮的C1,但是在題目中,實驗前我們對兩枚硬幣都缺乏了解,基于“無知”的原則,認為選擇C1和C2的概率是等可能的,即P(θ=C1)= P(θ=C2)=0.5,有了先驗概率后,可以代入貝葉斯公式計算后驗概率:
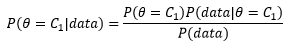
這里data是10次投硬幣的結果,無論選擇那枚硬幣,投擲的結果都符合伯努利分布:
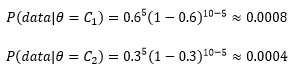
P(data)則需要借助全概率公式:
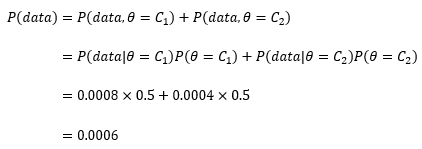
現在可以分別計算實驗前選擇C1硬幣或C2硬幣的概率:
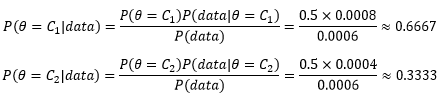
這個數字符合直覺,對于分類來說,在比較C1和C2的后驗概率時,二者的分母都是P(data),也就是說P(data)并沒有起到實際作用,因此對于分類器來說無需計算P(data):
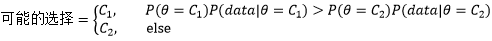
貝葉斯公式告訴我們,先驗概率是在實驗前對原因的預估,后驗概率是在試驗后根據結果反推原因,或者說是根據結果對最初預估的修正,既然如此,一次修正得到的并不一定是最佳結果,可以嘗試多次修正,前一個樣本點的后驗會被下一次估計當作先驗,我們根據這種思路重新計算一下C1的后驗概率,
一共拋了10次硬幣,用{x1, x2, …, x10}代表每次拋硬幣的結果,x1~x5是正面,x6~x10是反面,仍然在實驗前認為選擇C1和C2的概率是等可能的,下面是已知資訊:
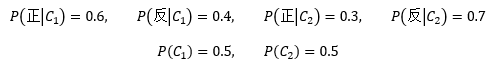
與之前不同,這次我們每次只看一枚硬幣,以此來計算θ的后驗概率:
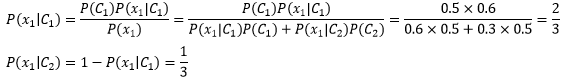
后驗資訊代表一次歷史經驗,比試驗前的“無知”稍強一些,接下來,我們用后驗概率作為下一次迭代的先驗概率:
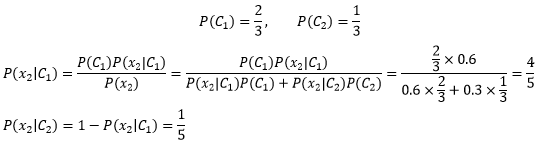
繼續迭代,直到x10為止,將最終得到的先驗概率就是最終結果,
p_1_c1, p_0_c1 = 0.6, 0.4 # P(1|c1) = 0.6, P(0|c1) = 0.4, 1和0分別代表正反 p_1_c2, p_0_c2 = 0.3, 0.7 # P(1|c2) = 0.3, P(0|c2) = 0.7 def posterior_theta(p_c1, p_c2, x): ''' 計算θ的后驗概率 :param p_c1: c1的先驗概率P(C1) :param p_c2: c2的先驗概率P(C2) :param x: 硬幣的結果 :return: 后驗概率P(C1|x)和P(C2|x) ''' p_x_c1 = p_1_c1 if x == 1 else p_0_c1 p_x_c2 = p_1_c2 if x == 1 else p_0_c2 # 計算后驗概率P(C1|x) p_c1_x = p_c1 * p_x_c1 / (p_x_c1 * p_c1 + p_x_c2 * p_c2) p_c2_x = 1 - p_c1_x return p_c1_x, p_c2_x data = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0] # 5正5反 p_c1, p_c2 = 0.5, 0.5 # 初始先驗P(C1) = P(C2) = 0.5 for x in data: # 用后驗作為下一個樣本點的先驗 p_c1, p_c2 = posterior_theta(p_c1, p_c2, x) print('P(C1)={0}, P(C2)={1}'.format(p_c1, p_c2))
P(C1)=0.6666666666666667, P(C2)=0.33333333333333326
P(C1)=0.8, P(C2)=0.19999999999999996
P(C1)=0.888888888888889, P(C2)=0.11111111111111105
P(C1)=0.9411764705882353, P(C2)=0.05882352941176472
P(C1)=0.9696969696969696, P(C2)=0.030303030303030387
P(C1)=0.948148148148148, P(C2)=0.05185185185185204
P(C1)=0.9126559714795006, P(C2)=0.08734402852049938
P(C1)=0.8565453785027182, P(C2)=0.14345462149728183
P(C1)=0.7733408854904177, P(C2)=0.22665911450958232
P(C1)=0.6609783156833076, P(C2)=0.33902168431669244
上面的迭代程序是一個將樣本點逐步增加到學習器的程序,前一個樣本點的后驗會被下一次估計當作先驗,可以說,貝葉斯學習是在逐步地更新先驗,逐步通過新樣本對原有的分布進行修正,
在實際應用中當然不會每次僅僅增加一個樣本點,下面的例子更好地說明了這個逐步更新先驗的程序,
為了提高產品的質量,公司經理考慮增加投資來改進生產設備,預計投資90萬元,但從投資效果來看,兩個顧問給出了不同的預言:
θ1顧問:改進生產設備后,高質量產品可占90%
θ2顧問:改進生產設備后,高質量產品可占70%
根據經理的以往經驗,兩個顧問的靠譜率是P(θ1)=0.4, P(θ2)=0.6,這兩個概率是先驗概率,是經理的主觀判斷,似乎θ2更靠譜一些,但是這次,θ2顧問意見太保守了,為了得到更準確的資訊,經理進行了小規模的試驗,結果第一批制作的5個產品全是令人興奮的高質量產品,
用D1表示本次實驗的5個產品,可以得到下面的結論:
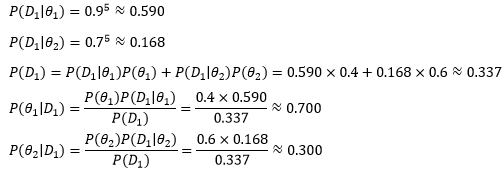
在第一次試驗后,經理針對本次實驗對兩個顧問的靠譜率做出了修正,認為P(θ1)=0.700, P(θ2)=0.300,這個概率更符合本次實驗的結果,或者說試驗結果改變了經理的主觀看法,
當然5個產品說明不了太大問題,于是經理又試制了10個產品(用D2表示),結果有9個是高質量的,根據這個結果繼續對顧問的靠譜率進行修正:

兩個顧問的靠譜率在D2中再次得到修正,
出處:微信公眾號 "我是8位的"
本文以學習、研究和分享為主,如需轉載,請聯系本人,標明作者和出處,非商業用途!
掃描二維碼關注作者公眾號“我是8位的”

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/24612.html
標籤:其他
上一篇:《番茄作業法圖解》小結
下一篇:一些PC小軟體/工具/神器備份