可視化復習
可視化是什么,可視化的定義,
:可視化(Visualization)是利用計算機圖形學和影像處理技術,將資料轉換成圖形或影像在螢屏上顯示出來,并進行互動處理的理論、方法和技術,
information visualization&& scientic visualization定義及區別
科學可視化:科學可視化側重于使用計算機圖形學來創建可視化圖形,這些影像有助于理解復雜的,通常是大量的科學概念或結果的數字表示
資訊可視化:資訊可視化是通過互動的可視化界面對抽象資料進行處理,
資訊可視化與科學可視化的主要區別首先是:科學可視化通常是觀察基于物理的、有幾何屬性的資料,而資訊可視化則用來顯示各式各樣的抽象資料;其次,科學可視化的用戶多是高層次的專業作業者,而資訊可視化的用戶則主要是非技術人員,要為難以形象表達的抽象資料設計更加容易理解的表現形式,使資訊可視化面臨更大的挑戰,
資訊可視化的可視化目的和科學可視化不同,科學可視化的目的要求是真實地反映,要求忠實地“直譯”,而資訊可視化的可視化目的則是要從大量抽象資料中發現一些新的資訊,它不僅僅使簡單的反映,而且要求能夠創造性地反映,能夠把隱藏在可視化物件深處或可視化物件之間的資訊挖掘出來,它是一種知識和價值創造的程序,且資訊可視化主要是通過使用互動式可視化界面來進行抽象資料的交流
visual analytics (可視分析,把人放在回路中,也就是人看到資料,互動分析資料)
可視化分析是一門通過可視化互動界面進行分析推理的學科,
BoxPlot會畫
辛普森悖論(什么情況下會發生,以及怎么解決)
散點圖矩陣到平行坐標系之間的轉換,平行坐標系,散點圖的限制以及怎么解決
批判的可視化分析
幾個設計原則 (不能失真,資訊量最大化,采用黃金比例作圖)
資料(圖形)完整性,即直方圖要有0基準線,比較的是長度還有到基準線的距離,但是直方圖就不需要了,比較的是角度,還要注意圖形的寬高比,45°原則(經驗法則是傾斜45度,以盡量減少視覺判斷斜率的誤差)
部分資料可能不太真實,選擇完整的資料,明智的選擇坐標比
lie factor && data-Ink Ratio
lie factor :數字的表示應該與所測量的資料成正比,也就是不能失真

線段就是線段比,若是多邊形就要用面積比
data-Ink:資訊量最大化
data-ink Ratio:用盡量少的墨水表達盡量多的資料 data-ink/total ink in graphic
但現在彩印都不是什么問題,所以就盡量做出可視化效果好的可視化
圖示垃圾:圖表中分散注意力的不必要的元素,要會判斷,
有的不必要的元素可能更吸引人們的眼球,視覺裝飾的元素,useful junk,能幫助人們更容易的理解記憶資料
color map
彩虹顏色圖是基于可見光光譜中顏色的順序,只是基于光的顏色,有的時候可視化的效果并不好,人們并不能自己選擇
缺乏知覺秩序,人們并不知道那種顏色對應于高或者低的陣列
Tufte Principles
(1)圖形的完整性,或這資料的完整性
(2)Lie factor,不能失真
(3)data-ink 資訊量最大化,用最小的墨水代表盡量多的資料
(4)避免有害圖示垃圾
Perception of Color 色彩感知
人眼處理color的流程:大致:光線照射進入視網膜,錐狀體細胞受到刺激,有三種錐狀體細胞對應紅綠藍三原色,對不同波長的顏色敏感度不同,三原色按照不同的比例混合成最后的顏色,然后人們就有了顏色的認知
CIE LAB color space&& HUE color space
L :亮度 A:紅綠對比 B:黃藍對比
軸的縮放表示“顏色距離”
rainbow color的缺點
(1)人們通常把顏色分類
(2)顏色不是自然有序的
(3)不同的明度來強調某些標量值
(4)低亮度顏色(藍色)可能會隱藏高頻值
則么構造Quantitative Data(不是必須掌握的)
圖形感知設計原則
experssiveness(表達能力)如果語言中的句子(即可視化)表達了資料集中的所有事實,并只有資料中的事實,那么這組事實就可以用可視化語言來表達(把事實表達出來,不能特意忽略資料來追求結果)
effectiveness(有效性)如果一個可視化表達的資訊比另一個可視化表達的資訊更加容易理解,那么這個可視化比另一個可視化更加有效(更快更容易的表達資訊,更容易被理解)
圖形感知:觀察者對資訊的視覺編碼的解釋,并從而對圖形中的資訊進行解碼的能力
Just Noticeable Difference JND(最小可覺差,是差別閾限值(difference threshold)的另一種稱法,)掌握定義即可
JND模型可以用在影像對比度拉伸,以及高清影像、視頻等,
JND是測量兩種感覺心理差別程度的數量單位,
在刺激中大多數連續的變化是在離散的步驟中被感知
演算法(韋伯定律)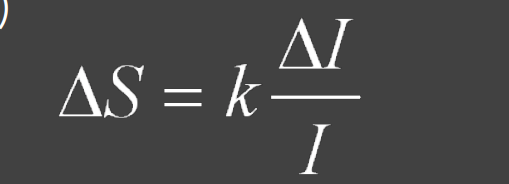
最小可覺察誤差(JND, Just Noticeable Distortion)用于表示人眼不能察覺的最大影像失真,體現了人眼對影像改變的容忍度,
Gestalt Principles 格式塔原則
1、圖形與背景的關系原則(figure-ground),當我們觀察的時候,會認為有些物體或圖形比背景更加突出,
2、接近或鄰近原則(proximity),接近或鄰近的物體會被認為是一個整體,
3、相似原則(similarity),刺激物的形狀、大小、顏色、強度等物理屬性方面比較相似時,這些刺激物就容易被組織起來而構成一個整體,
4、封閉的原則(closure),有時也稱閉合的原則,有些圖形是一個沒有閉合的殘缺的圖形,但主體有一種使其閉合的傾向,即主體能自行填補缺口而把其知覺為一個整體,
5、共方向原則(common fate),也有稱共同命運原則,如果一個物件中的一部分都向共同的方向去運動,那這些共同移動的部分就易被感知為一個整體,
6、熟悉性原則(familiarity),人們對一個復雜物件進行知覺時,只要沒有特定的要求,就會常常傾向于把物件看作是有組織的簡單的規則圖形,
7、連續性原則(continuity),如果一個圖形的某些部分可以被看作是連接在一起的,那么這些部分就相對容易被我們知覺為一個整體,
8.知覺恒常性(perceptual constancy),人們總是將世界知覺為一相當恒定以及不變的場所,即從不同的角度看同一個東西,落在視網膜上的影響是不一樣的,但是我們不會認為是這個東西變形了,
1)明度恒常性
2)顏色恒常性
3)大小恒常性
4)形狀恒常性
9.對稱原則
對稱的原則指出,當我們感知物體時,我們傾向于將他們視為圍繞這個物體形成的對稱形狀,大多數物體可以被分為兩個或者兩個以上對稱的部分,當我們看到兩個對稱的未連接元素時,我們無意識地將它們整合成一個連貫的物件(或感知),物件越相似,它們就越傾向于分組,
10 連通性否決了鄰近性、大小、顏色和形狀[來自Ware 04
高維資料
表達成向量
高維資料投到低維資料,低維資料要盡可能的保持高維資料的結構
j降維的好處
(1):更少的存盤 (2)更快的運算速度 (3)噪聲去除(提高資料質量)(4)互動式可視化
降維的幾個方面:
(1)線性與非線性 (2)監督與非監督 (3)全域與區域 (4)特征向量與相似度
PCA(主成分分析,線性方法)線性的,非監督的,全域的,特征向量
優點就是快,缺點是展現的有限性
PCA(Principal Component Analysis),即主成分分析方法,是一種使用最廣泛的資料降維演算法,PCA的主要思想是將n維特征映射到k維上,這k維是全新的正交特征也被稱為主成分,是在原有n維特征的基礎上重新構造出來的k維特征,PCA的作業就是從原始的空間中順序地找一組相互正交的坐標軸,新的坐標軸的選擇與資料本身是密切相關的,其中,第一個新坐標軸選擇是原始資料中方差最大的方向,第二個新坐標軸選取是與第一個坐標軸正交的平面中使得方差最大的,第三個軸是與第1,2個軸正交的平面中方差最大的,依次類推,可以得到n個這樣的坐標軸,通過這種方式獲得的新的坐標軸,我們發現,大部分方差都包含在前面k個坐標軸中,后面的坐標軸所含的方差幾乎為0,于是,我們可以忽略余下的坐標軸,只保留前面k個含有絕大部分方差的坐標軸,事實上,這相當于只保留包含絕大部分方差的維度特征,而忽略包含方差幾乎為0的特征維度,實作對資料特征的降維處理,
Metric MDS(多維標度)在低維空間盡量保持高維空間兩個點之間的距離
優點是精確,可以根據多個準則評估樣本間差異,缺點是計算成本高,耗時
非線性的,無監督的,全域的,相似性的
演算法:梯度下降型

MDS
MDS初始資料是給出的相關性的資料,也是兩個點之間的距離矩陣,我們現在要用這些距離矩陣在低維空間還原出在高維空間的分布
線性方法:將低緯度表示為高緯度的線性組合
非線性:更復雜,但通常更強大,準確
SNE
SNE高維空間資料分開的,但到了低維空間,資料反而擁擠在一起,所以提出了t-SNE,t-SNE 用t分布代替了SNE里的高斯分布
t-SNE:非線性的,區域的,無監督的,相似性的
將距離轉換為概率,距離越遠,概率越低,最小化高維空間和低維空間的概率分布差異
SNE是通過仿射(affinitie)變換將資料點映射到概率分布上,主要包括兩個步驟:
a) SNE構建一個高維物件之間的概率分布,使得相似的物件有更高的概率被選擇,而不相似的物件有較低的概率被選擇,
b) SNE在低維空間里在構建這些點的概率分布,使得這兩個概率分布之間盡可能的相似,
優點:
對于不相似的點,用一個較小的距離會產生較大的梯度來讓這些點排斥開來,
這種排斥又不會無限大(梯度中分母),避免不相似的點距離太遠
缺點:
(1)主要用于可視化,很難用于其他目的,比如測驗集合降維,因為他沒有顯式的預估部分,不能在測驗集合直接降維;比如降維到10維,因為t分布偏重長尾,1個自由度的t分布很難保存好區域特征,可能需要設定成更高的自由度,
(2)t-SNE傾向于保存區域特征,對于本征維數(intrinsic dimensionality)本身就很高的資料集,不可能完整的映射到2-3維的空間
(3)t-SNE沒有唯一最優解,且沒有預估部分,如果想要做預估,可以考慮降維之后,再構建一個回歸方程之類的模型去做,但是要注意,t-sne中距離本身是沒有意義,都是概率分布問題,
(4)訓練太慢,有很多基于樹的演算法在t-sne上做一些改進
t-SNE的優化:
Barnes-Hut-SNE:一組相似的點看作是一個點
提前壓縮(early compression):開始初始化的時候,各個點要離得近一點,這樣小的距離,方便各個聚類中心的移動,可以通過引入L2正則項(距離的平方和)來實作,
提前夸大(early exaggeration):在開始優化階段,p_{ij}乘以一個大于1的數進行擴大,來避免因為q_{ij}太小導致優化太慢的問題,比如前50次迭代,p_{ij}乘以4
t-SNE(t分布隨即鄰域嵌入)t-SNE與MDS的關聯,與PCA的區別
基本的圖布局演算法
什么叫好的一個圖
corrsing(應該是交叉邊)要少,面積要小,寬高比不要極端
最小化總邊長,最小化最大邊長,最小化邊長的方差,彎曲要少
邊夾角最小角度的最大化,尤其與直線繪制對稱相關
在繪制反射對稱和旋轉對稱的時候顯示圖形的對稱性,對于有向圖邊指向指定方向的程度
力導向圖 Force-Direct layout
基本思想:開始把節點的位置隨機初始化,我們把節點想象為物理粒子,這個粒子有引力和斥力,引力就是那些邊的作用,在粒子間斥力和引力的不斷作用下,粒子們從隨機無序的初態不斷發生位移,逐漸趨于平衡有序的終 態,同時整個物理系統的能量也在不斷消耗,經過數次迭代后,粒子之間幾乎不再發生相對位移,整個系統達到一種穩定平衡的狀態,即能量趨于零,
優化:也是用的Barnes-Hut演算法,將相似的點看作一個點,用四叉樹實作,最后優化的演算法復雜度為O(nlgn)
改進:
限制迭代步長,過長震蕩,過短太慢
設定溫度引數,從而允許節點在程序中更早地移動更大的距離,然后逐漸限制其向末端移動
檢測兩個節點之間的距離是否為零(通過在第20行的if陳述句中添加else子句),在這種情況下,在某些情況下在兩個節點之間產生較小的作用力隨機方向,將它們推開,沒有這個,如果兩個節點碰巧有相同的鄰居,它們可能永遠永遠被彼此“卡住”
更改與兩個力的強度之比相對應的單個引數,布局的最終??形狀將取決于𝐾𝑟/𝐾𝑠和𝐿
模擬彈簧,我們可以消除排斥力,而是模擬所有相鄰節點之間長度為𝐿的彈簧,以及所有相距兩個邊緣的節點之間的長度為2𝐿的彈簧,并可能模擬相隔三個邊緣的節點之間的長度為3𝐿的彈簧,等等, ,,達到一定的限制,多余的彈簧將有助于分散網路,就像原始的排斥力一樣,只要邊的數量不是太高,并且彈簧沒有太多,計算時間就可能比𝑂(𝑁2)小得多,
缺點:對很大的圖進行力導向圖演算法的時候,很多點聚集在一起就像一個大雪球,可視化效果差
大圖可視化的缺點:可讀性,擴展性,視覺復雜性
斥力由庫侖定律定義Fr=Kr/r^2; Kr為系數
引力是由胡克定律定義的:Fs=Ks(d-L) d是距離,L是最短壓縮到的距離
鄰接矩陣
?優點:不交叉,能表示額外資訊 如權重,可以很清楚的顯示兩個點之間是否有邊
?缺點:難以讀圖,路徑不清晰,受螢屏解析度限制,所需空間N2
優化的鄰接矩陣:在重心排序和添加弧圖之后,多弧圖是多余的,但減少了眼睛運動從矩陣內部到最近弧的距離,通過使用重心啟發式將節點“拉近”到它們的鄰居,這將使邊(填充在矩陣單元中)更靠近矩陣的對角線,從而使某些圖案與節點的位置相吻合細胞,給定適當的行和列順序,某些子圖(圖中節點和邊的子集)對應于鄰接矩陣中易于識別的模式
Pivot Graph(透視圖,資料透視圖)
為多元圖形設計的,即每個節點都與多個屬性相關聯
PivotGraph的設計是為了突出圖形的各個維度之間的互動作用,比較容易看出各個組之間的關系
點的大小是匯合的結點的數量,邊的粗細是匯合的邊的多少
treemap RT演算法(Node-Link Diagrams)
RT:使空間更有效,最大化空間密度,以及最好對稱
treemap:每個子樹都由一個矩形表示,該矩形被劃分成與其子樹相對應的較小矩形
大小都差不多的時候不容易看出區別,而且會出現比較細長的矩形,極端的寬高比
該演算法從左至右或自上而下地對矩形進行填充,填充時只考慮子節點順序和權值所代表的面積,
Draw()
{Change orientation from parent (horiz/vert)
Read all files and directories at this level
Make rectangle for each, scaled to size
Draw rectangles using appropriate size and color
For each directory
Make recursive call using its rectangle as focus
}
Draw()
{
從父級更改方向(水平、垂直)
讀取此級別的所有目錄和檔案
為每個檔案和目錄制作矩形,按比例縮放
用適當的大小和顏色繪制矩陣
對于每個目錄:
使用矩陣作為焦點進行遞回呼叫
}
Squarified treemap:使得寬高比基本為1,若不是就放棄當前位置,轉換位置插入矩陣,極端的寬高比或者非常接近正方形的寬高比都不好
將子節點從大到小進行排列;
從權值最大的節點開始,按照沿最短邊優先開始,緊靠左邊或者下邊的原則,從左到右或者從下到上開始填充,
當填充第i個子節點時,采用同行同列插入或者新建一行/列的方式,對比第1到i-1個矩形的平均長寬比,選擇平均長寬比低的填充結果作為第i個子節點的填充方式,
PipeLine
原始檔案 ->自然語言處理,檔案處理 ->對檔案關鍵字進行計數 ->進行分析,找到相關檔案進行比較 ->所需資訊的幾何表示 ->進行可視化
outline
元資料:關于資料的資料
兩個層面:
宏觀:搜索更大的資料集,非結構化:無元資料 結構化:顯示元資料
微觀:小型檔案集合的檔案間關系,檢測到的檔案如何與查詢相關,檢測到檔案如何互相關聯,檔案內方法,
themescape:用高度/顏色來表示檔案密度
TopicLens:大型檔案集合的高效多級可視主題探索,當滑鼠放到一個點的時候會顯示更底層,更微觀的檔案
themeriver: 主題河流圖是一種特殊的流圖,它主要用來表示事件或主題等在一段時間內的變化
sparkclouds:用大小表示權重,每個詞下面都有一個折線圖用來表示隨時間的使用頻率,
Parallel Wordclouds:用大小表示權重,用一條折線連接相同的詞語,折線的粗細表示詞的頻率,一列一列的,最下面有時間刻度,在每個時間刻度上使用頻率最高的詞
Oview+detail
Fcous+Context
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/246838.html
標籤:其他
下一篇:LTE物理層