目錄
- 一、對數幾率和對數幾率回歸
- 二、Sigmoid函式
- 三、極大似然法
- 四、梯度下降法
- 四、Python實作
一、對數幾率和對數幾率回歸
??在對數幾率回歸中,我們將樣本的模型輸出\(y^*\)定義為樣本為正例的概率,將\(\frac{y^*}{1-y^*}\)定義為幾率(odds),幾率表示的是樣本作為正例的相對可能性,將幾率取對便可以得到對數幾率(log odds,logit),
\[logit=\log\frac{y^*}{1-y^*} \]??而對數幾率回歸(Logistic Regression)則試圖從樣本集中學得模型\(w^Tx\)并使其逼近該樣本的對數幾率,從而可以得到:
\[condition1:w^Tx=\log\frac{y^*}{1-y^*} \]二、Sigmoid函式
??通過求解\(conditoin1\)可以得到:
\[y^*=\frac{e^{w^Tx}}{1+e^{w^Tx}}=\frac{1}{1+e^{-w^Tx}} \]??由此我們可以知道樣本\(x_i\)為正例的概率可以通過函式\(h(w^Tx_i)=\frac{1}{1+e^{-w^Tx_i}}\)來表示,而其中的函式\(h(z)\)便被稱為Sigmoid函式,其影像如下:
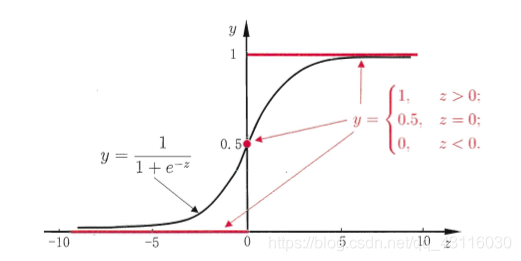
??求其導數:
\[h'(z)=\frac{-e^{-z}}{(1+e^{-z})^2}=\frac{1}{1+e^{-z}}(1-\frac{1}{1+e^{-z}})=h(z)(1-h(z)) \]這是一個很好的性質,有利于簡化后面優化模型時的計算,
三、極大似然法
??通過前面的推導,可以得到:
\[P(y=1|x)=y^*=h(w^Tx)\,\,\,\,\,\,\,\,P(y=0|x)=1-y^*=1-h(w^Tx) \]合并兩個式子,則有:
\[P(y|x)=h(w^Tx)^y(1-h(w^Tx))^{1-y} \]??求出了樣本標記的分布律,便可以通過極大似然法來估計分布律中的引數\(w\),先寫出極大似然函式:
\[L(y_i|x_i,w)=\prod^{m}_{i=1}h(w^Tx_i)^{y_i}(1-h(w^Tx_i))^{1-{y_i}} \]??對極大似然函式取對可以得到對數似然函式:
\[l(y_i|x_i,w)=log(L)=\sum^{m}_{i=1}{(y_i\log h(w^Tx_i)+(1-y_i)log(1-h(w^Tx_i)))} \]??在前面乘上負數因子便可以得到對數幾率回歸的代價函式:
\[J(w)=-\frac{1}{m}\sum^{m}_{i=1}{(y_i\log h(w^Tx_i)+(1-y_i)log(1-h(w^Tx_i)))} \]通過最小化上述代價函式便可以估計出引數\(w\)的值,
四、梯度下降法
??通過上述步驟,優化對數幾率回歸模型的關鍵變成了求解:
\[w=\arg\min J(w)=\arg\min -\frac{1}{m}\sum^{m}_{i=1}{(y_i\log h(w^Tx_i)+(1-y_i)log(1-h(w^Tx_i)))} \]??在《線性回歸:梯度下降法優化》中,我已經詳細介紹了梯度下降法的數學原理,這里直接使用梯度下降法來對對數幾率回歸模型進行優化,
??對\(J(w)\)進行求導:
??將\(\frac{\partial J}{\partial w}\)帶入引數\(w\)的更新公式\(w^*=w-\eta\frac{\partial J}{\partial w}\),最終得到\(w\)的更新公式如下:
\[w^*=w+\frac{\eta}{m}\sum^{m}_{i=1}{(y_i-h(w^Tx_i))x_i} \]四、Python實作
??梯度下降優化演算法:
def fit(self, X, y):
self.W = np.zeros(X.shape[1] + 1)
for i in range(self.max_iter):
delta = self._activation(self._linear_func(X)) - y
self.W[0] -= self.eta * delta.sum()
self.W[1:] -= self.eta * (delta @ X)
return self
??匯入鳶尾花資料集進行測驗:
if __name__ == "__main__":
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
irirs = datasets.load_iris()
X = irirs["data"][:100]
y = irirs["target"][:100]
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, test_size=0.3)
classifier = LRClassifier().fit(X_train, y_train)
y_pred = classifier.predict(X_test)
print(classification_report(y_test, y_pred))
??分類報告如下:
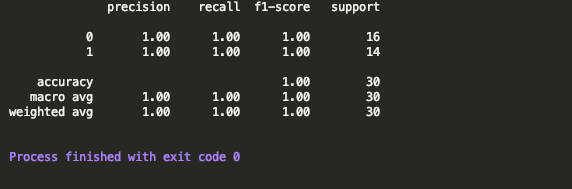
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247104.html
標籤:其他
上一篇:線性回歸:梯度下降法原理與實作
下一篇:神經網路模型與誤差逆傳播演算法