目錄
- 寫在前面
- 關于可持久化
- 可持久化陣列 & 可持久化線段樹
- 暴力做法
- 一個小優化
- 進一步優化
- 練習
- 主席樹
寫在前面
這是 CSP-S2 2020 考完后 5ab 寫的第一篇文章,學的第一個新演算法,
CSP-S2 考完后,5ab 就要朝著省選演算法進發,學習省選內容嘍,
關于可持久化
可持久化是一種思想,一種通過修改區域,拷貝區域資料的方法來達到多版本訪問的目的,
這樣說確實不太清楚,難道你就是這么學的?我們來看一個例子,
可持久化陣列 & 可持久化線段樹
給你一個序列,每一次基于一個歷史版本單點修改某個數,或者詢問某個數,
暴力做法
我們可以先考慮暴力:
- 先將陣列存下來;
- 每一次操作,拷貝陣列然后進行修改或者詢問,
顯而易見,這個操作的復雜度是 \(\mathcal{O}(nq)\),不夠優秀,我們得考慮一個更好的做法,
一個小優化
眾所周知,遇事不決就分塊,我們不妨將這個陣列分塊,
每一次操作,我們只要記錄塊內的修改即可,可以有 \(\mathcal{O}(q\sqrt{n})\) 的優秀復雜度,可以通過不小的資料,
進一步優化
我們考慮用線段樹維護,這是一個很簡單的推進——從分塊到線段樹,
注意到如果是線段樹,每一次要拷貝的資料僅僅為一條鏈,如圖:
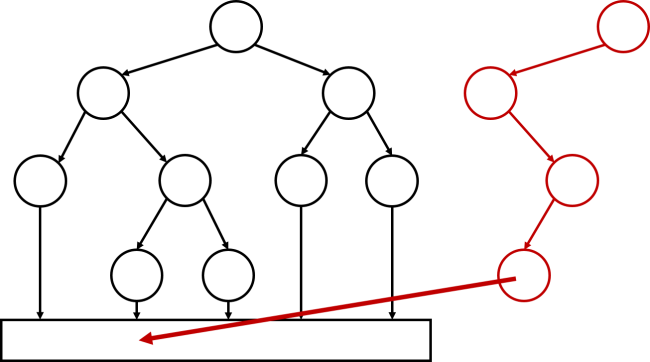
這個性質極其優美,但是,怎么樣維持線段樹的形態呢?
我們有一個極其暴力的做法:直接動態開點,然后將沒有修改的部分直接指向原部分!
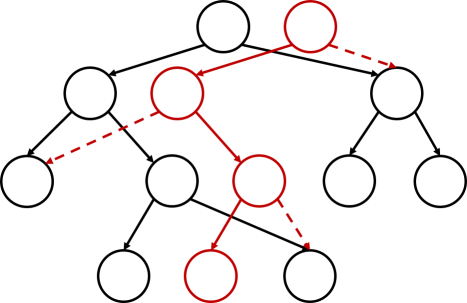
注意到這樣的改進使單次修改的復雜度(無論是時間還是空間)都降到了 \(\mathcal{O}(\log n)\),實際上,這就是可持久化陣列,
當然,我們已經搭建了線段樹結構,所以我們也實作了可持久化線段樹,
練習
【模板】可持久化線段樹 1(可持久化陣列)
裸模板,直接用可持久化線段樹即可,代碼
主席樹
get 到了可持久化線段樹,我們就能夠搞定許多以前做不出來的問題,如臭名昭著的區間第 \(k\) 大,
問題是,給定一個數列 \(a\),每一次詢問 \([l_i,r_i]\),要求出該區間中的第 \(k\) 大,
形式地說,即若 \(\left<p_{l_i},p_{l_i+1},\cdots,p_{r_i}\right>=\left<l_i,l_i+1,\cdots,r_i\right>\) 且滿足 \(a_{p_{l_i}}\le a_{p_{l_i+1}}\le\cdots\le a_{p_{r_i}}\),給定 \(k\),求 \(a_{p_{l_i+k-1}}\),
當然,在資料比較小的時候可以使用排序法,但那實在是太慢了,我們考慮一種新思路,
注意到區間第 \(k\) 大就是有 \(k-1\) 比這個數小,那么我們只要可以快速詢問有多少個數比自己小,那么不就能二分了嗎?而詢問恰恰好是線段樹擅長的,
接下來我們引入一個概念,那就是權值線段樹,
眾所周知,線段樹擅長處理區間問題,那么數的區間就是值域,所以權值線段樹就是建立在值域上的線段樹,當然得離散化,
接下來,我們建一棵權值線段樹 \(T\) 在 \([L,R]\) 上,對于節點 \(i\) 所對應的區間為 \([l_i,r_i]\),
考慮如下操作:
- 對于 \([L,R]\) 中的每一個數 \(x\),在 \(T\) 的對應位置加上 \(1\);
- 查詢 \([l_i,r_i]\) 的區間和,
那么,操作 \(2\) 的結果就是 \([L,R]\) 的數在 \([l_i,r_i]\) 的數量,這樣我們就可以愉快地二分了,
說了這么多,好像也并沒有什么卵用,這和快排有什么區別呢?
注意到,每一次插入一個數,原序列就只有一個數被改動,那么我們就可以愉快地使用可持久化線段樹來維護,
但是,這樣我們也只能做到 \([1,r]\) 的區間第 \(k\) 大,距離真正的區間第 \(k\) 大還有一點距離,
但同時,我們又注意到這些線段樹結構相同,而且每一次操作都是加法,那么我們就可以做前綴和!即,讓 \(T_R\) 的每一個節點減去 \(T_{L-1}\) 的對應節點,那么得到的就是 \(T_{[L,R]}\),
這就是主席樹,(關于為什么要叫主席樹,好像是因為發明者 HJT 與當年主席的相同)
\[\href{https://paste.ubuntu.com/p/CPWsPQD6Yh/}{\large\texttt{Code}} \]不妨試一下模板題?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/247521.html
標籤:其他