回圈鏈表、雙向鏈表、靜態鏈表
三遍定律:
理解了單鏈表本文的理解易如反掌,單鏈表請點擊這里
理解了單鏈表本文的理解易如反掌,單鏈表請點擊這里
理解了單鏈表本文的理解易如反掌,單鏈表請點擊這里
1.回圈鏈表
將單鏈表中終端結點的指標端由空指標改為指向頭結點,就使整個單鏈表形成一個環,這種頭尾相接的單鏈表稱為單回圈鏈表,簡稱回圈鏈表(circular linked list),
回圈鏈表可以從任意一個結點出發,訪問到鏈表的全部結點,
為了使空鏈表與非空鏈表處理一致,我們通常設一個頭結點,當然,這并不是說,回圈鏈表一定要頭結點,這需要注意,回圈鏈表帶有頭結點的空鏈表如圖:
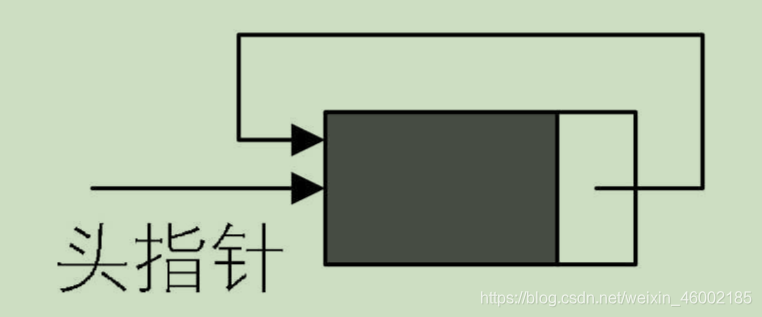
對于非空的回圈鏈表就如圖:

回圈鏈表和單鏈表的主要差異就在于回圈的判斷條件上,原來是判斷 p->next 是否為空,現在則是
p->next 不等于頭結點,則回圈未結束,
在單鏈表中,我們有了頭結點時,我們可以用O(1)的時間訪問第一個結點,但對于要訪問到最后一個結點,卻需要O(n)時間,因為我們需要將單鏈表全部掃描一遍,
有沒有可能用O(1)的時間由鏈表指標訪問到最后一個結點呢?當然可以,
不過我們需要改造一下這個回圈鏈表,不用頭指標,而是用指向終端結點的尾指標來表示回圈鏈表,此時查找開始結點和終端結點都很方便了,如圖:

從上圖中可以看到,終端結點用尾指標 rear 指示,則查找終端結點是 O(1),而開始結點,其實就是rear->next->next,其時間復雜也為 O(1),
舉個程式的例子,要將兩個回圈鏈表合并成一個表時,有了尾指標就非常簡單了,比如下面的這兩個回圈鏈表,它們的尾指標分別是rearA和rearB,如圖:
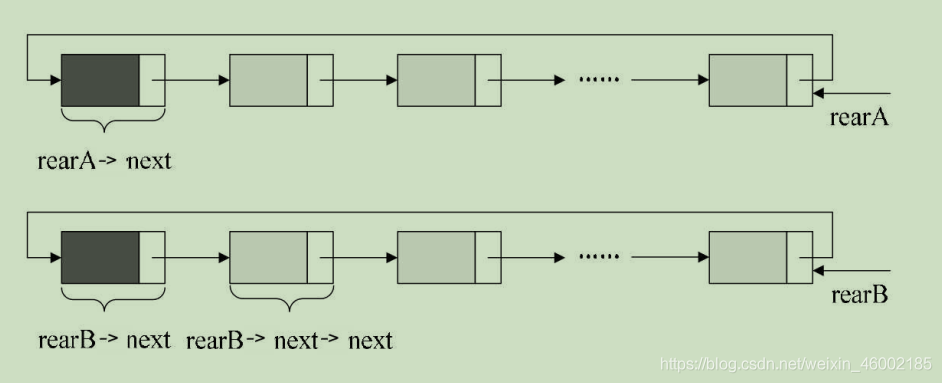
要想把它們合并,只需要如下的操作即可,如圖:
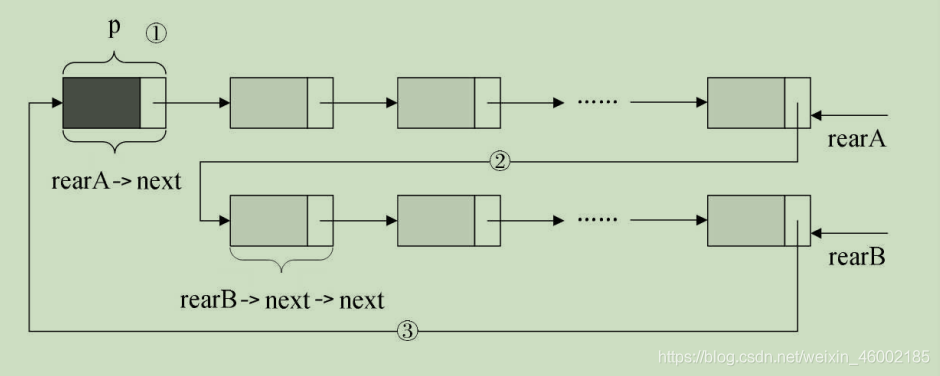
光說不寫假把式,代碼如下:
/* 保存 A 表的頭結點,即 ① */
p = rearA->next;
/* 將本是指向 B 表的第一個結點(不是頭結點)賦值給 RearA->next,即 ② */
rearA->next = rearB->next->next;
q = rearB->next;
/* 將原 A 表的頭結點賦值給 rearB->next,即 ③ */
rearB->next = p;
/* 釋放 q */
free(q);
2.雙向鏈表
我們的單鏈表,總是從頭到尾找結點,難道就不可以正反遍歷都可以嗎?當然可以,只不過需要加點東西而已,
我們在單鏈表中,有了next指標,這就使得我們要查找下一結點的時間復雜度為O(1),可是如果我們要查找的是上一結點的話,那最壞的時間復雜度就是O(n)了,因為我們每次都要從頭開始遍歷查找,
為了克服單向性這一缺點,我們的老科學家們,設計出了雙向鏈表,雙向鏈表(double linkedlist)是在單鏈表的每個結點中,再設定一個指向其前驅結點的指標域,所以在雙向鏈表中的結點都有兩個指標域,一個指向直接后繼,另一個指向直接前驅,
/* 線性表的雙向鏈表存盤結構 */
typedef struct DulNode{
ElemType data;
struct DuLNode *prior; /* 直接前驅指標 */
struct DuLNode *next; /* 直接后繼指標 */
} DulNode, *DuLinkList;
既然單鏈表也可以有回圈鏈表,那么雙向鏈表當然也可以是回圈表,雙向鏈表的回圈帶頭結點的空鏈表如圖:
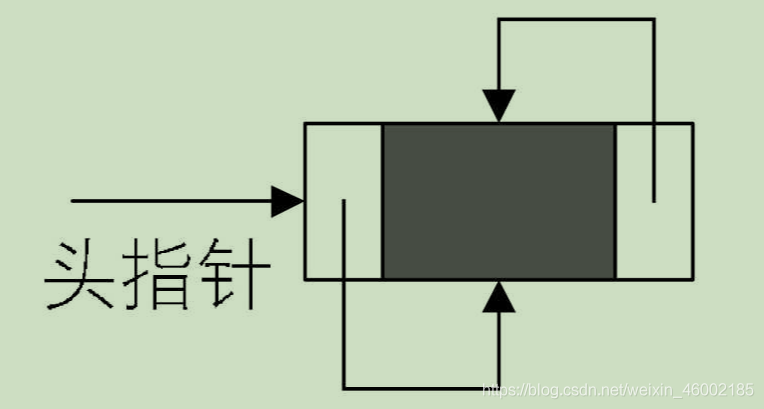
非空的回圈的帶頭結點的雙向鏈表如圖:
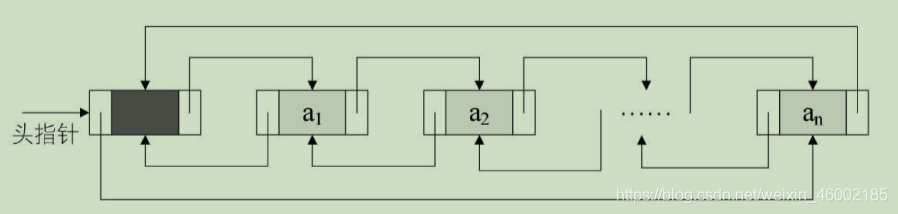
由于這是雙向鏈表,那么對于鏈表中的某一個結點p,它的 后繼的前驅 和 它的 前驅的后繼 自然也是它自己,即:
p->next->prior = p = p->prior->next
雙向鏈表是單鏈表中擴展出來的結構,所以它的很多操作是和單鏈表相同的,比如求長度的ListLength,查找元素的 GetElem,獲得元素位置的 LocateElem 等,這些操作都只要涉及一個方向的指標即可,另一指標多了也不能提供什么幫助,
就像人生一樣,想享樂就得先努力,欲識訓就得付代價,雙向鏈表既然是比單鏈表多了如可以反向遍歷查找等資料結構,那么也就需要付出一些小的代價:在插入和洗掉時,需要更改兩個指標變數,
插入操作時,其實并不復雜,不過順序很重要,千萬不能寫反了,
我們現在假設存盤元素e的結點為s,要實作將結點s插入到結點p和p->next之間需要下面幾步,如圖:
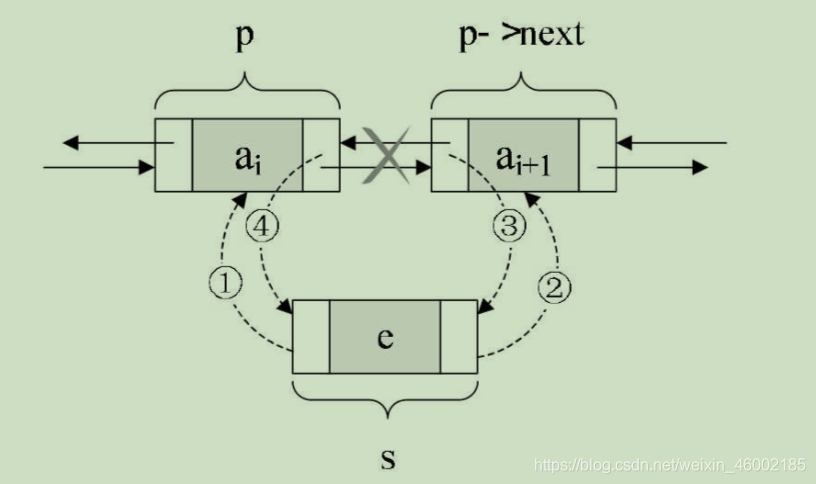
步驟如下:
/* 把 p 賦值給 s 的前驅,如圖中 ① */
s->prior = p;
/* 把p->next賦值給s的后繼,如圖中 ② */
s->next = p->next;
/* 把s賦值給p->next的前驅,如圖中③ */
p->next->prior = s;
/* 把s賦值給p的后繼,如圖中④ */
p->next = s;
關鍵在于它們的順序,由于第2步和第3步都用到了p->next,如果第4步先執行,則會使得p->next提前變成了s,使得插入的作業完不成,所以我們不妨把上面這張圖在理解的基礎上記憶,順序是先搞定s的前驅和后繼,再搞定后結點的前驅,最后解決前結點的后繼,
如果插入操作理解了,那么洗掉操作,就比較簡單了,
若要洗掉結點p,只需要下面兩步驟,如圖:
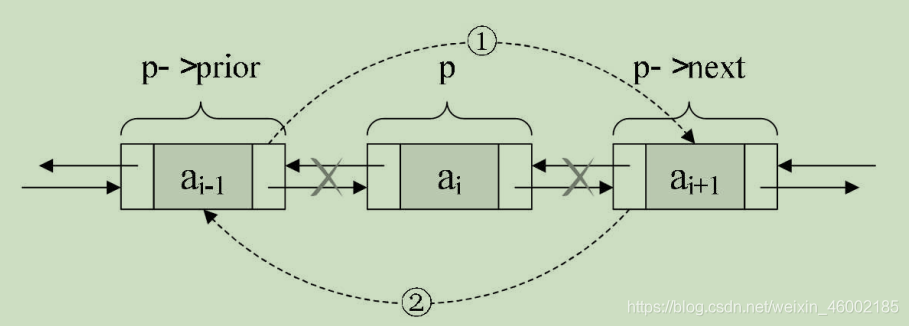
步驟如下:
/* 把p->next賦值給p->prior的后繼,如圖中① */
p->prior->next = p->next;
/* 把p->prior賦值給p->next的前驅,如圖中② */
p->next->prior = p->prior;
/* 釋放結點 */
free(p);
雙向鏈表相對于單鏈表來說,要更復雜一些,畢竟它多了prior指標,對于插入和洗掉時,需要格外小心,另外它由于每個結點都需要記錄兩份指標,所以在空間上是要占用略多一些的,不過,由于它良好的對稱性,使得對某個結點的前后結點的操作,帶來了方便,可以有效提高演算法的時間性能,說白了,就是用空間來換時間,
3.靜態鏈表
C語言具有指標這一強大的功能,也是眾多計算機領域的人用來描述資料結構首選C語言的原因之一,指標可以使C非常容易的操作記憶體中的地址和資料,這比其他高級語言更加靈活方便,Java、C#等面向物件語言,雖然不使用指標,但因為啟用了物件參考機制,從某種角度也間接實作了指標的某些作用,但對于其他一些語言,如Basic、Fortran等早期的編程語言對于一些資料結構的操作就沒有那么方便了,
有前輩想出來用陣列來代替指標,描述單鏈表:首先讓陣列的元素都是由兩個資料域組成,data和cur,也就是說,陣列的每個下標都對應一個data和一個cur,資料域data,用來存放資料元素,也就是通常我們要處理的資料;而cur相當于單鏈表中的next指標,存放該元素的后繼在陣列中的下標,我們把cur叫做游標,
我們把這種用陣列描述的鏈表叫做靜態鏈表,這種描述方法還有起名叫做游標實作法,
為了我們方便插入資料,通常會把陣列建立得大一些,以便有一些空閑空間可以便于插入時不至于溢位,
用代碼描述一下:
/* 線性表的靜態鏈表存盤結構 */
/* 假設鏈表的最大長度是1000 */
#define MAXSIZE 1000
typedef struct
{
ElemType data;
/* 游標(Cursor),為0時表示無指向 */
int cur;
} Component,
StaticLinkList[MAXSIZE];
對陣列第一個和最后一個元素作為特殊元素處理,不存資料,我們通常把未被使用的陣列元素稱為備用鏈表,而陣列第一個元素,即下標為0的元素的cur就存放備用鏈表的第一個結點的下標;而陣列的最后一個元素的cur則存放第一個有數值的元素的下標,相當于單鏈表中的頭結點作用,當整個鏈表為空時,則為0,如圖:
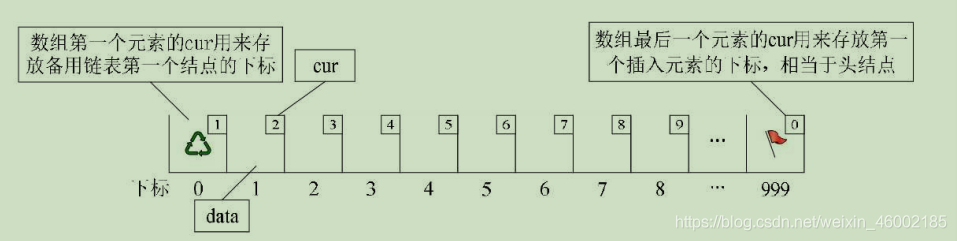
假設我們已經將資料存入靜態鏈表,比如分別存放著“甲”、“乙”、“丁”、“戊”、“己”、“庚”等資料,則它的狀態如圖所示:
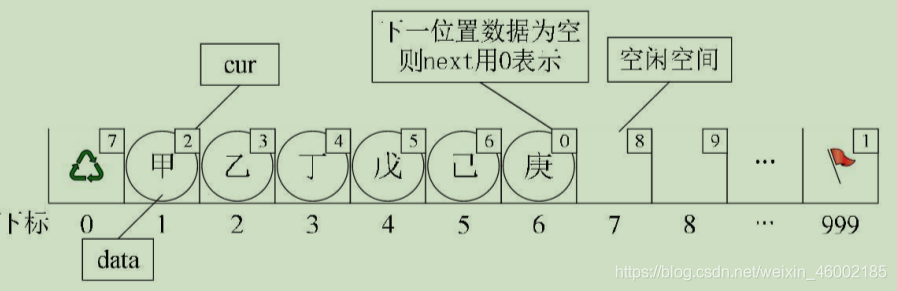
此時“甲”這里就存有下一元素“乙”的游標2,“乙”則存有下一元素“丁”的下標3,而“庚”是最后一個有值元素,所以它的cur設定為0,而最后一個元素的cur則因“甲”是第一有值元素而存有它的下標為1,而第一個元素則因空閑空間的第一個元素下標為7,所以它的cur存有7,
(1)靜態鏈表的插入操作
靜態鏈表中解決的是:如何用靜態模擬動態鏈表結構的存盤空間的分配,需要時申請,無用時釋放,
在動態鏈表中,結點的申請和釋放分別借用 malloc() 和 free() 兩個函式實作,在靜態鏈表中,操作的是陣列,不存在像動態鏈表的結點申請和釋放問題,所以我們需要自己實作這兩個函式,才可以做插入和洗掉操作,
為了辨明陣列中哪些分量未被使用,解決辦法是將所有未被使用過的及被洗掉的分量用游標鏈成一個備用的鏈表,每當進行插入時,便可以從備用鏈表上取的第一個結點作為待插入的新結點,
/* 若備用空間鏈表非空,則回傳分配的結點下標,否則回傳 0 */
int Malloc_SLL(StaticLinkList space)
{
/* 當前陣列第一個元素的 cur 存的值,就是要回傳的第一個備用的空閑的下標 */
int i = space[0].cur;
/* 由于要拿出一個分量來使用了,所以我們就得把它的下一個分量用來做備用 */
if (space[0].cur)
space[0].cur = space[i].cur;
return i;
}
這段代碼,一方面它的作用就是回傳一個下標值,這個值就是陣列頭元素的cur存的第一個空閑的下標,從上面的圖示例子來看,其實就是回傳7,
那么既然下標為7的分量準備要使用了,就得有接替者,所以就把分量7的cur值賦值給頭元素,也就是把8給space[0].cur,之后就可以繼續分配新的空閑分量,實作類似malloc()函式的作用,
現在我們如果需要在“乙”和“丁”之間,插入一個值為“丙”的元素,按照以前順序存盤結構的做法,應該要把“丁”、“戊”、“己”、“庚”這些元素都往后移一位,但目前不需要,因為我們有了新的手段,
新元素“丙”,想插隊是吧?可以,你先悄悄地在隊伍最后一排第7個游標位置待著,我一會就能幫你搞定,我接著找到了“乙”,告訴他,你的cur不是游標為3的“丁”了,這點小錢,意思意思,你把你的下一位的游標改為7就可以了,“乙”嘆了口氣,收了錢把cur值改了,此時再回到“丙”那里,說你把你的cur改為3,就這樣,在絕大多數人都不知道的情況下,整個排隊的次序發生了改變,如圖:
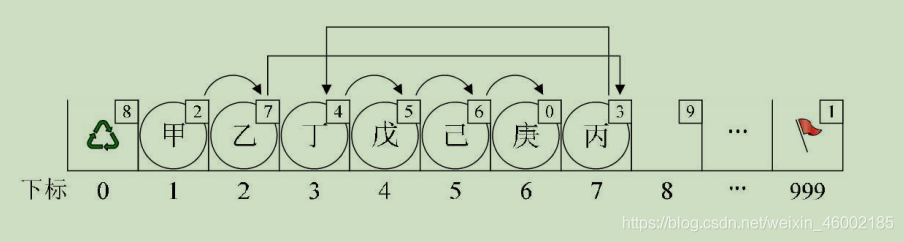
上圖實作代碼如下:
/* 在 L 中第 i 個元素之前插入新的資料元素 e */
Status ListInsert(StaticLinkList L, int i, ElemType e)
{
int j, k, l;
/* 注意 k 首先是最后一個元素的下標 */
k = MAX_SIZE - 1;
if (i < 1 || i > ListLength(L) + 1)
return ERROR;
/* 獲得空閑分量的下標 */
j = Malloc_SLL(L);
if (j)
{
/* 將資料賦值給此分量的data */
L[j].data = e;
/* 找到第i個元素之前的位置 */
for (l = 1; l <= i - 1; l++)
k = L[k].cur;
/* 把第i個元素之前的cur賦值給新元素的cur */
L[j].cur = L[k].cur;
/* 把新元素的下標賦值給第i個元素之前元素的cur */
L[k].cur = j;
return OK;
}
return ERROR;
}
當我們執行插入陳述句時,我們的目的是要在“乙”和“丁”之間插入“丙”,呼叫代碼時,輸入 i 值為 3,
讓 k = MAX_SIZE-1=999,
j = Malloc_SSL(L) = 7,此時下標為 0 的 cur 也因為 7 要被占用而更改備用鏈表的值為 8,
for 回圈 l 由 1 到 2,執行兩次,代碼 k = L[k].cur ; 使得 k = 999,得到 k = L[999].cur = 1,再得到 k = L[1].cur = 2,
L[j].cur = L[k].cur ; 因 j = 7,而 k = 2 得到L[7].cur=L[2].cur = 3,這就是剛才我說的讓“丙”把它的cur 改為 3的意思,
L[k].cur = j;意思就是L[2].cur = 7,也就是讓“乙”得點好處,把它的 cur 改為指向“丙”的下標 7,
就這樣,我們實作了在陣列中,實作不移動元素,插入了資料的操作,
(2)靜態鏈表的洗掉操作
洗掉元素時,原來是需要釋放結點的函式 free(),現在我們要自己實作它:
/* 洗掉在 L 中第 i 個元素 e */
Status ListDelete(StaticLinkList L, int i)
{
int j, k;
if (i < 1 || i > ListLength(L))
return ERROR;
k = MAX_SIZE - 1;
for (j = 1; j <= i; j++)
k = L[k].cur;
j = L[k].cur;
L[k].cur = L[i].cur;
Free_SSL(L,j); /* 看下文 */
return OK;
}
將下標為k的空閑結點回收到備用鏈表代碼:
/* 將下標為k的空閑結點回收到備用鏈表 */
void Free_SSL(StaticLinkList space, int k)
{
/* 把第一個元素 cur 值賦給要洗掉的分量 cur */
space[k].cur = space[0].cur;
/* 把要洗掉的分量下標賦值給第一個元素的 cur */
space[0].cur = k;
}
甲現在要走,這個位置就空出來了,也就是,未來如果有新人來,最優先考慮這里,所以原來的第一個空位分量,即下標是 8 的分量,它降級了,把 8 給“甲”所在下標為 1 的分量的 cur,也就是 space[1].cur = space[0].cur = 8,而 space[0].cur = k = 1 其實就是讓這個洗掉的位置成為第一個優先空位,把它存入第一個元素的 cur 中,如圖:

(3)靜態鏈表的優缺點
上圖:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/248556.html
標籤:其他
上一篇:做好一個普通人 逐步地悟出自己的規劃 才是可以走的路
下一篇:你不輸出,怎么進步呢。