【編者按】『四個引數畫大象,五個引數鼻子晃』 著名實驗和理論物理學家、諾獎得主費米曾經這樣參考馮諾依曼的話:“四個引數,我就能擬合出一個大象出來,用五個引數我就能讓他的鼻子擺動”,看似是個玩笑,實際上真的有一篇論文研究繪制大象,只是時間是在 2010 年,機器學習當中,引數越多,理論上的精度越高(也極易產生過擬合),當然需要的算力也更多,GPT-3 使用了驚人的 1750 億引數,堪稱史上最大 AI 模型,沒想到這才多久,Google Brain 團隊就搞了一個大新聞,他們使用了 1.6 萬億引數推出了語言模型 Switch Transformer,比 T5 模型當中的 T5-XXL 模型還要快 4 倍,比基本的 T5 模型快了 7 倍,
作者 | 八寶粥
出品 | CSDN (id:CSDNnews)
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-TCpaC3ft-1610539820570)(image/20210113_164325_86.png)]](https://img.uj5u.com/2021/01/15/215547151155581.png)
近日,Google Brain 團隊在預印本發布論文《SWITCH TRANSFORMERS: SCALING TO TRILLION PARAMETER MODELS WITH SIMPLE AND EFFICIENT SPARSITY》,宣布利用萬億級引數進行預訓練的稀疏模型 SWITCH TRANSFORMERS 的誕生,該方法可以在控制通信和計算資源的情況下提升訓練的穩定性,同等計算資源條件下比 T5-XXL 模型快 4 倍,
來自 Google Brain 的三位科學家 William Fedus、Barret Zoph 以及 Noam Shazeer 使用了 Switch Transformer 模型,簡化了 MOE 的路由演算法、設計了直觀的改進模型,從而實作了通信和計算成本的降低,值得期待的是,這種訓練方法修復了不穩定性,并且首次展示了大型稀疏模型在低精度(bfloat 16)格式下進行訓練,將模型和 T5 模型進行對比,基于 101 種語言的設定和 C4 語料庫(Colossal Clean Crawled Corpus,從網路上抓取的數百 GB 干凈英語文本) 訓練效果實作了對 T5 模型的超越,甚至是 7 倍速碾壓,
模型原理
深度學習模型通常對于所有的輸入重復使用相同的引數,而專家混合模型(Mixture-of-Experts)則不是這樣,它采用的模式是對輸入實力選擇不同的引數,這樣的結果就是可以在計算成本不變的情況下得到一個稀疏激活模型,它的引數可以是無比巨大的,然而 MOE 具有較大的通信成本,且訓練不穩定,因而難以推廣,
簡單來說,Google Brain 基于 MOE 推出了一種方案,利用稀疏模型增加速度,對于需要稠密模型的時候也可以將稀疏模型蒸餾成稠密模型,同時進行微調,調整 dropout 系數避免引數過大的過擬合,
關于MOE
混合專家系統屬于一種集成的神經網路,每一個專家就是一種神經網路,我們查看特定案例的輸入資料來幫助選擇要依賴的模型,于是模型就可以選擇訓練案例而無需考慮未被選中的例子,因此他們可以忽略不擅長的建模內容,它的主要思想就是讓每位專家專注于自己比其他專家更優的內容,這樣一來,整體的模型就趨于專業化,如果當中的每個專家都對預測變數求平均,那么每個模型就都要去補償其他模型產生的綜合誤差,所謂“術業有專攻”,專家就讓他去搞專業的事情,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-lxQutr3F-1610539820580)(image/20210113_193924_16.png)]](https://img.uj5u.com/2021/01/15/215547151155582.png)
在這個模型當中,每個專家處理固定的批量 token 容量系數,每個 token 被路由到具有最高路由概率的專家,但是每個專家的批處理量大小是(token 總數/專家總數)×容量因子,如果 token 分配不均,某些專家就會超載,大的容量系數可以緩解流量問題,也會增加通信成本,
權重分配與近水樓臺
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-HaDLzADc-1610539820607)(image/20210113_200605_67.png)]](https://img.uj5u.com/2021/01/15/215547151155583.png)
每個 4×4 的虛線網格表示 16 個核,陰影正方形是該核上包含的資料(模型權重或令牌批次),我們說明了如何為每種策略拆分模型權重和資料張量,第一行:說明模型權重如何在核心之間分配,此行中不同大小的形狀表示前饋網路(FFN)層中較大的權重矩陣,陰影正方形的每種顏色標識唯一的權重矩陣,每個核心的引數數量是固定的,但是較大的權重矩陣將對每個令牌應用更多的計算,第二行:說明如何在內核之間拆分資料批, 每個內核持有相同數量的令牌,從而在所有策略中保持固定的記憶體使用率,磁區策略具有不同的屬性,允許每個內核在內核之間具有相同的令牌或不同的令牌,這是不同顏色所象征的,
同時,該模型對于稠密矩陣乘法適應硬體進行了有效利用,比如 GPU 和 Google 自家的 TPU,早在 2019 年,Google AI 就模擬了果蠅東岸從的神經圖,由于掃描后重建影像高達 40 億像素,為了處理這些圖片,Google AI 使用數千塊 TPU 進行計算處理,可以說是下了血本,而此次推出的模型,它需要最低的硬體標準只是滿足兩個專家模型的需要就夠了,
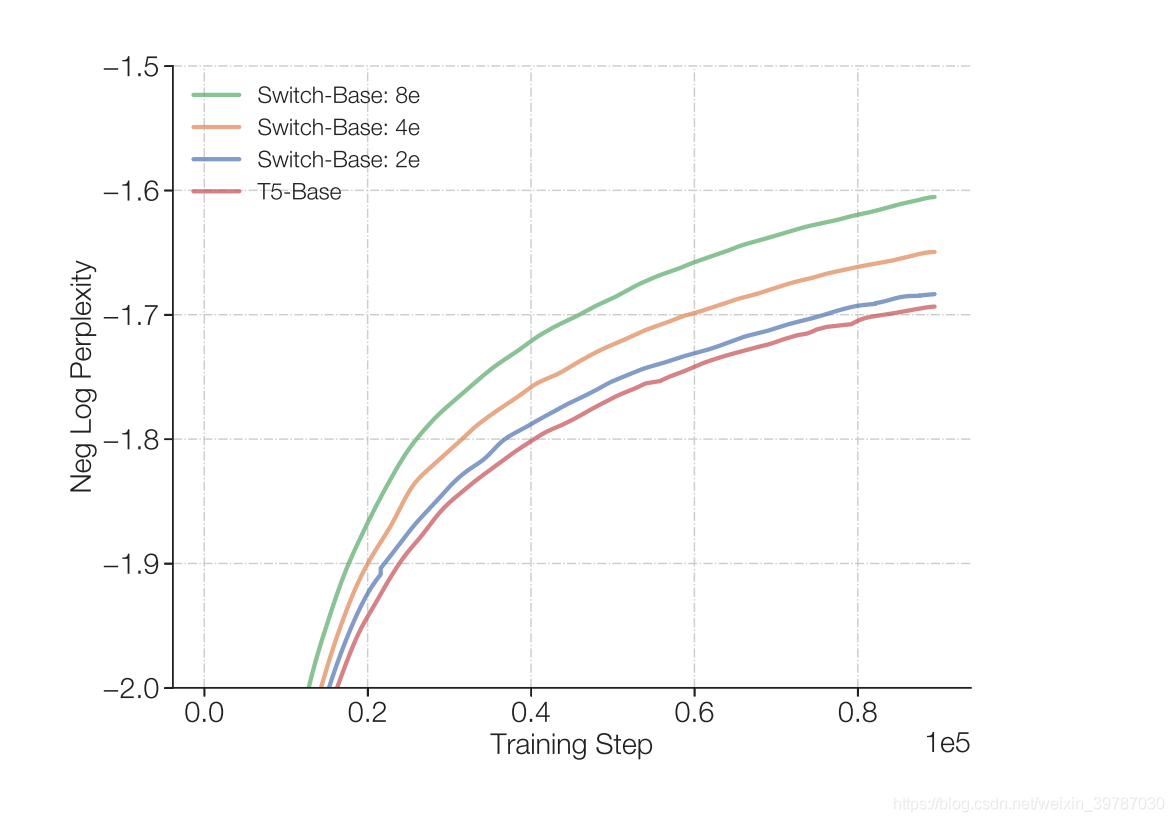
如上,滿足兩個專家的模型,仍然能夠對 T5-Base 模型有所提升,
跑個分~
之前介紹到,Google Brain 當時的 T5 組合模型霸榜過 SuperGLUE,該模型在語言模型基準測驗榜 GLUE 和 SuperGLUE 上得分均不同程度地超過 T5 的基礎水平,也算是正常發揮,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-FPE79nUm-1610539820594)(image/20210113_195800_30.png)]](https://img.uj5u.com/2021/01/15/215547151155585.png)
雖然模型距離目前榜首的 DeBERTa 組合模型還有較長的一段路要走,該專案最大的意義在于實作了超大型引數和稀疏模型結合的高效使用,
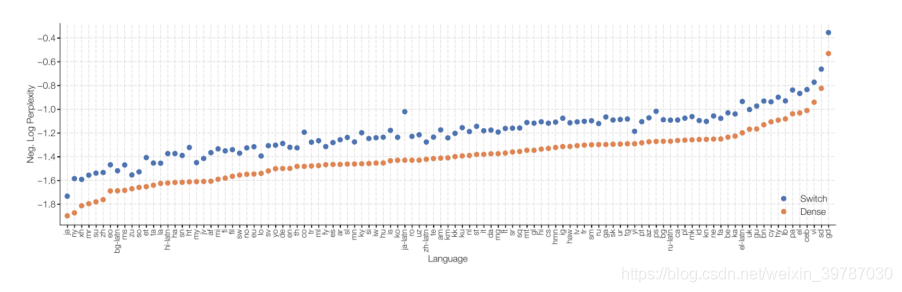
下游實驗中,我們進行了 101 種語言的測驗,可以看到該模型相比稠密模型,在所有的任務上均有明顯提升,
當場答疑
31 頁的論文,難免有讀者看完之后有好奇或不解,作者想到了這個問題,直接寫了出來,作者強調,在稀疏專家模型當中,“稀疏” 指的是權重,而不是關注模式,
1.純粹的引數技識訓讓 Switch Transformer 更好嗎?
是的,看怎么設計!引數和總的 FLOPs 是獨立衡量神經語言模型的標準,大型模型已經被證實具有良好的表現,不過基于相同計算資源的情況下,我們的模型具有更加簡潔、有效且快速的特點,
2.我沒有超算——模型對我來說依然有用嗎?
雖然這項作業集中在大型模型上,我們發現只要有兩個專家模型就能實作,模型需要的最低限制在附錄當中有講,所以這項技術在小規模環境當中也非常有用,
3.在速度-精度曲線上,稀疏模型相比稠密模型有優勢嗎?
當然,在各種不同規模的模型當中,稀疏模型的速度和每一步的表現均優于稠密模型,
4.我無法部署一個萬億引數的模型-我們可以縮小這些模型嗎?
這個我們無法完全保證,但是通過 10 倍或者 100 倍蒸餾,可以使模型變成稠密模型,同時實作專家模型 30%的增益效果,
5.為什么使用 Switch Transformer 而不是模型并行密集模型?
從時間角度看,稀疏模型效果要優越很多,不過這里并不是非黑即白,我們可以在 Switch Transformer 使用模型并行,增加每個 token 的 FLOPs,但是這可能導致并行變慢,
6.為什么稀疏模型尚未廣泛使用?
擴展密集模型的巨大成功減弱了人們使用稀疏模型的動力,此外,稀疏模型還面臨一些問題,例如模型復雜性、訓練難度和通信成本,不過,這些問題在 Switch Transformer 上也已經得到了有效的緩解,
論文很長,深入了解,還需閱讀全文,
【參考資料】
1.2010 年4引數擬合大象論文
1.文章鏈接
2.MOE模型代碼
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/249037.html
標籤:其他
上一篇:關于你看得懂看不懂的羅永浩