目錄
- 一、集群使用場景
- 二、集群搭建
- 1.ZooKeeper集群搭建
- 2.Kafka集群搭建
- 三、多集群同步
- 1.配置
- 2.調優
- 總結
集群是一種計算機系統, 它通過一組松散集成的計算機軟體和/或硬體連接起來高度緊密地協作完成計算作業,在某種意義上,他們可以被看作是一臺計算機,集群系統中的單個計算機通常稱為節點,通常通過局域網連接,但也有其它的可能連接方式,集群計算機通常用來改進單個計算機的計算速度和/或可靠性,一般情況下集群計算機比單個計算機,比如作業站或超級計算機性能價格比要高得多,
集群的特點
集群擁有以下兩個特點:
- 可擴展性:集群的性能不限制于單一的服務物體,新的服務物體可以動態的添加到集群,從而增強集群的性能,
- 高可用性:集群當其中一個節點發生故障時,這臺節點上面所運行的應用程式將在另一臺節點被自動接管,消除單點故障對于增強資料可用性、可達性和可靠性是非常重要的,
集群的能力
- 負載均衡:負載均衡把任務比較均勻的分布到集群環境下的計算和網路資源,以提高資料吞吐量,
- 錯誤恢復:如果集群中的某一臺服務器由于故障或者維護需要無法使用,資源和應用程式將轉移到可用的集群節點上,這種由于某個節點的資源不能作業,另一個可用節點中的資源能夠透明的接管并繼續完成任務的程序,叫做錯誤恢復,
負載均衡和錯誤恢復要求各服務物體中有執行同一任務的資源存在,而且對于同一任務的各個資源來說,執行任務所需的資訊視圖必須是相同的,
一、集群使用場景
Kafka 是一個分布式訊息系統,具有高水平擴展和高吞吐量的特點,在Kafka 集群中,沒有 “中心主節點” 的概念,集群中所有的節點都是對等的,
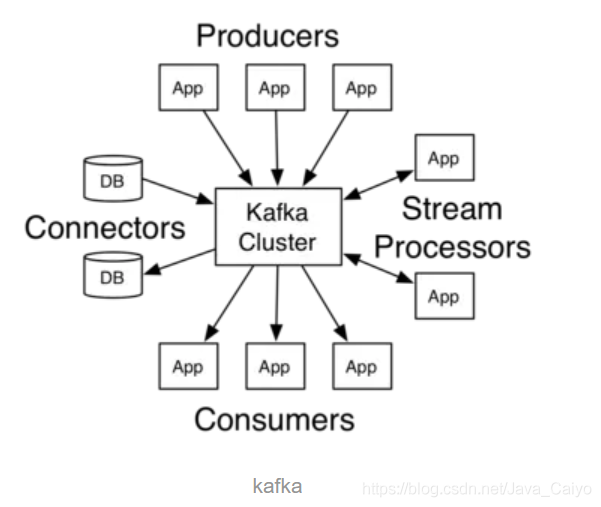
Broker(代理)
每個 Broker 即一個 Kafka 服務實體,多個 Broker 構成一個 Kafka 集群,生產者發布的訊息將保存在 Broker 中,消費者將從 Broker 中拉取訊息進行消費,
Kafka集群架構圖
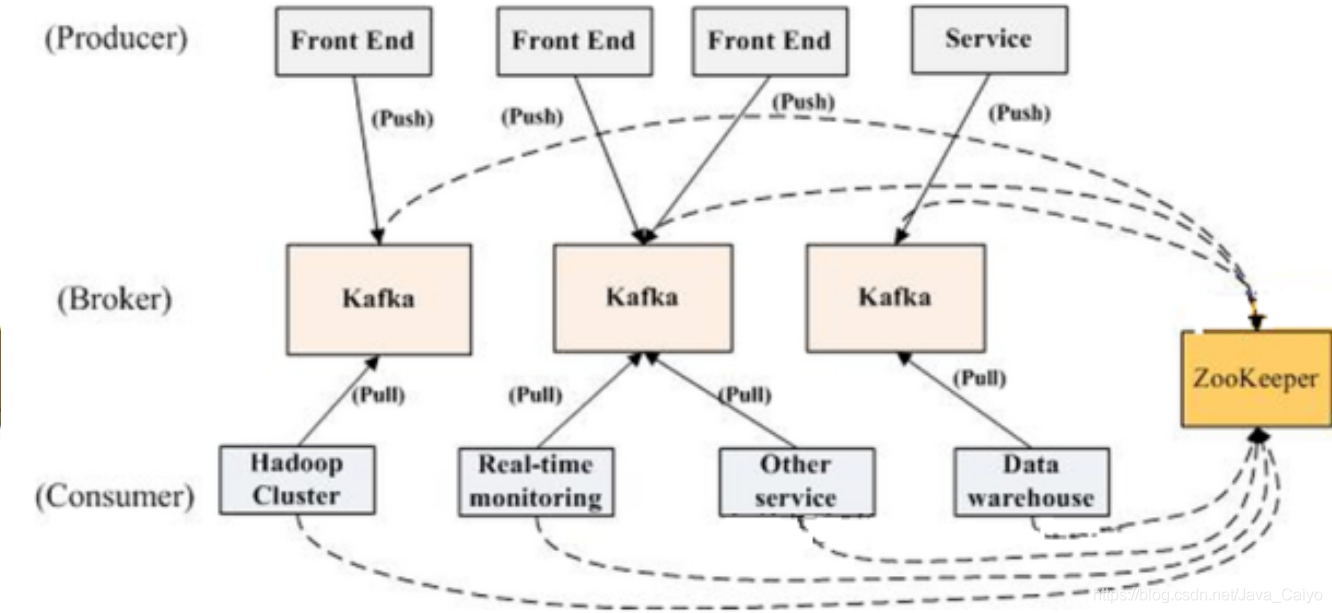
從圖中可以看出 Kafka 強依賴于 ZooKeeper ,通過 ZooKeeper 管理自身集群,如:Broker 串列管理、Partition 與 Broker 的關系、Partition 與 Consumer 的關系、Producer 與 Consumer 負載均衡、消費進度 Offset 記錄、消費者注冊 等,所以為了達到高可用,ZooKeeper 自身也必須是集群,
二、集群搭建
1.ZooKeeper集群搭建
場景
真實的集群是需要部署在不同的服務器上的,但是在我們測驗時同時啟動十幾個虛擬機記憶體會吃不消,所以這里我們搭建偽集群,也就是把所有的服務都搭建在一臺虛擬機上,用埠進行區分,
我們這里要求搭建一個三個節點的Zookeeper集群(偽集群),
安裝JDK
集群目錄
創建zookeeper-cluster目錄,將解壓后的Zookeeper復制到以下三個目錄
itcast@Server-node:/mnt/d/zookeeper-cluster$ ll
total 0
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 ./
drwxrwxrwx 1 dayuan dayuan 512 Aug 19 18:42 ../
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-1/
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-2/
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 10:02 zookeeper-3/
itcast@Server-node:/mnt/d/zookeeper-cluster$
ClientPort設定
配置每一個Zookeeper 的dataDir(zoo.cfg) clientPort 分別為2181 2182 2183
# the port at which the clients will connect
clientPort=2181
myid配置
在每個zookeeper的 data 目錄下創建一個 myid 檔案,內容分別是0、1、2 ,這個檔案就是記錄每個服務器的ID
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$ cat
temp/zookeeper/data/myid
0
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$
zoo.cfg
在每一個zookeeper 的 zoo.cfg配置客戶端訪問埠(clientPort)和集群服務器IP串列,
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$ cat conf/zoo.cfg
# The number of milliseconds of each tick
# zk服務器的心跳時間
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper
dataDir=temp/zookeeper/data
dataLogDir=temp/zookeeper/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.0=127.0.0.1:2888:3888
server.1=127.0.0.1:2889:3889
server.2=127.0.0.1:2890:3890
dayuan@MY-20190430BUDR:/mnt/d/zookeeper-cluster/zookeeper-1$
解釋:server.服務器ID=服務器IP地址:服務器之間通信埠:服務器之間投票選舉埠
啟動集群
啟動集群就是分別啟動每個實體,啟動后我們查詢一下每個實體的運行狀態
itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-1$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /mnt/d/zookeeper-cluster/zookeeper-1/bin/../conf/zoo.cfg
Mode: leader
itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-2$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /mnt/d/zookeeper-cluster/zookeeper-2/bin/../conf/zoo.cfg
Mode: follower
itcast@Server-node:/mnt/d/zookeeper-cluster/zookeeper-3$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /mnt/d/zookeeper-cluster/zookeeper-3/bin/../conf/zoo.cfg
Mode: follower
2.Kafka集群搭建
集群目錄
itcast@Server-node:/mnt/d/kafka-cluster$ ll
total 0
drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:15 ./
drwxrwxrwx 1 dayuan dayuan 512 Aug 19 18:42 ../
drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:39 kafka-1/
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 14:02 kafka-2/
drwxrwxrwx 1 dayuan dayuan 512 Jul 24 14:02 kafka-3/
drwxrwxrwx 1 dayuan dayuan 512 Aug 28 18:15 kafka-4/
itcast@Server-node:/mnt/d/kafka-cluster$
server.properties
# broker 編號,集群內必須唯一
broker.id=1
# host 地址
host.name=127.0.0.1
# 埠
port=9092
# 訊息日志存放地址
log.dirs=/tmp/kafka/log/cluster/log3
# ZooKeeper 地址,多個用,分隔
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
啟動集群
分別通過 cmd 進入每個 Kafka 實體,輸入命令啟動
...............................
[2019-07-24 06:18:19,793] INFO [Transaction Marker Channel Manager 2]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager)
[2019-07-24 06:18:19,793] INFO [TransactionCoordinator id=2] Startup complete. (kafka.coordinator.transaction.TransactionCoordinator)
[2019-07-24 06:18:19,846] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread)
[2019-07-24 06:18:19,869] INFO [SocketServer brokerId=2] Started data-plane processors for 1 acceptors (kafka.network.SocketServer)
[2019-07-24 06:18:19,879] INFO Kafka version: 2.2.1 (org.apache.kafka.common.utils.AppInfoParser)
[2019-07-24 06:18:19,879] INFO Kafka commitId: 55783d3133a5a49a (org.apache.kafka.common.utils.AppInfoParser)
[2019-07-24 06:18:19,883] INFO [KafkaServer id=2] started (kafka.server.KafkaServer)
三、多集群同步
MirrorMaker是為解決Kafka跨集群同步、創建鏡像集群而存在的;下圖展示了其作業原理,該工具消費源集群訊息然后將資料重新推送到目標集群,
1.配置
創建鏡像
使用MirrorMaker創建鏡像是比較簡單的,搭建好目標Kafka集群后,只需要啟動mirror-maker程式即可,其中,一個或多個consumer組態檔、一個producer組態檔是必須的,whitelist、blacklist是可選的,在consumer的配置中指定源Kafka集群的Zookeeper,在producer的配置中指定目標集群的 Zookeeper(或者broker.list),
kafka-run-class.sh kafka.tools.MirrorMaker –
consumer.config sourceCluster1Consumer.config –
consumer.config sourceCluster2Consumer.config –num.streams 2 –
producer.config targetClusterProducer.config –whitelist=“.*”
consumer組態檔:
# format: host1:port1,host2:port2 ...
bootstrap.servers=localhost:9092
# consumer group id
group.id=test-consumer-group
# What to do when there is no initial offset in Kafka or if the current
# offset does not exist any more on the server: latest, earliest, none
#auto.offset.reset=
producer組態檔:
# format: host1:port1,host2:port2 ...
bootstrap.servers=localhost:9092
# specify the compression codec for all data generated: none, gzip, snappy, lz4, zstd
compression.type=none
2.調優
同步資料如何做到不丟失 首先發送到目標集群時需要確認:request.required.acks=1 發送時采用阻塞模式,否則緩沖區滿了資料丟棄:queue.enqueue.timeout.ms=-1
總結
本章主要對Kafka集群展開講解,介紹了集群使用場景,Zookeeper和Kafka多借點集群的搭建,以及多集群的同步操作,
參考文章《Kafka技術手冊》
需要的同學可加助理VX:C18173184271 備注:CSDN Java_Caiyo 免費獲取Java資料!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/249038.html
標籤:其他