Module原始碼介紹
本篇是nn.Module原始碼系列文章介紹第二篇,建議讀者在閱讀第一篇之后,在來閱讀本篇,當然,也可以直接閱讀本文,因為提供了大量的實體,
第一篇地址
文章目錄
- Module原始碼介紹
- 前置知識:Module中train/eval模塊狀態切換
- 實戰:隨意進行train/eval狀態切換
- 實戰:凍結網路中所有BN層
- nn.Module中指定梯度和梯度清0函式
- 實戰:凍結BN層梯度引數
- 總結
前置知識:Module中train/eval模塊狀態切換
? 在上篇文章中,介紹了nn.Module是如何完成自定義網路的初始化的,比如現在我新建了一個如下的 conv+bn+conv 的簡單網路,
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.leconv1 = nn.Conv2d(1, 1, 1, 1, 0)
self.lebn = nn.BatchNorm2d(1)
self.leconv2 = nn.Conv2d(1, 1, 1, 1, 0)
def forward(self,x):
pass
if __name__ == '__main__':
input = torch.ones(1,1,2,2) # 偽造資料
net = Net()
for module in net.children():
print('net包含的模塊為:\n',module)
for p in module.parameters():
print('當前module需要學習的引數為:\n',p)
? 為了方便,我把卷積核維度定義為1*1大小,通過運行上述代碼可以發現:卷積核的引數僅有兩個weight和bias,且其維度大小為1,BN層需要學習的引數也為兩個:平移引數和形變引數,維度也為1,Okay,運行的結果圖如下:
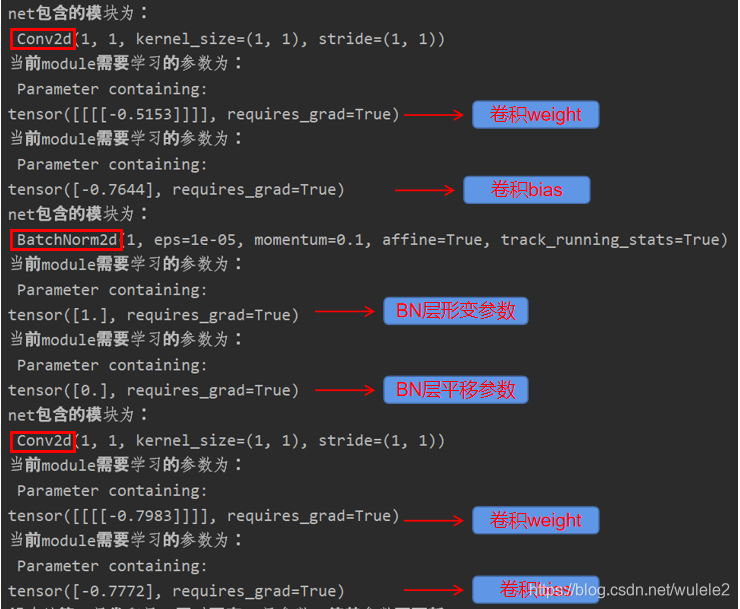
? 從上圖可以看出,總共需要學習6個引數,為啥是“要學習”?,因為每個引數后面均是 requires_grad=True,我們知道,模型有train狀態和eval狀態,簡單來說就是訓練時候讓網路所有module(leconv1+lebn+leconv2)處于 train 狀態,而測驗時候讓網路的所有module處于 eval 狀態,那么nn.Module是如何區分這兩種狀態的呢?這里貼下nn.Module的原始碼:
def train(self: T, mode: bool = True) -> T:
self.training = mode
for module in self.children():
module.train(mode)
return self
def eval(self: T) -> T:
return self.train(False)
? 函式特別簡單:即若是train狀態下:讓net中所有module指定為True;而在eval狀態下,則直接給train傳入False即可,這樣就修改了模型的狀態,
實戰:隨意進行train/eval狀態切換
? 上述介紹僅僅是介紹了將一個網路中所有module要么全部轉成train,要么全部轉成eval,比較死板,那么,若僅想讓leconv1處于eval狀態,而讓lebn和leconv2處于train狀態呢(這種方式經常遇到,尤其在遷移學習程序中)?
? 比較簡單:就是找到leconv1然后改變leconv1狀態即可,這里主要復寫一下train方法即可,上代碼:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.leconv1 = nn.Conv2d(1, 1, 1, 1, 0)
self.lebn = nn.BatchNorm2d(1)
self.leconv2 = nn.Conv2d(1, 1, 1, 1, 0)
def train(self, mode = True) :
super(Net, self).train()
for name, module in self.named_children(): # 遍歷模塊
if name == 'leconv1': # 若是 leconv1
module.eval() # 則直接讓其進入eval狀態,
def forward(self,x):
pass
if __name__ == '__main__':
net = Net()
net.train()
? Okay,到目前為止,你可以隨意更改一個網路中任意一層,但是若網路特別深,動輒幾百層,這樣一層一層找,顯然不現實,而且在實際網路中,往往需要凍結所有BN層(此處不做討論,原因可以自行百度),且看第三部分,
實戰:凍結網路中所有BN層
? 此處凍結就是讓所有BN層處于eval狀態:上代碼:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.leconv1 = nn.Conv2d(1, 1, 1, 1, 0)
self.lebn = nn.BatchNorm2d(1)
self.leconv2 = nn.Conv2d(1, 1, 1, 1, 0)
def train(self, mode = True) :
super(Net, self).train()
for module in self.children():
if isinstance(module,nn.BatchNorm2d): # 若當前module為nn.BatchNorm2d
module.eval() # 指定eval狀態
def forward(self,x):
pass
if __name__ == '__main__':
input = torch.ones(1,1,2,2) # 偽造資料
net = Net()
net.train()
? 通過上述就能凍結一個net中所有BN層,
nn.Module中指定梯度和梯度清0函式
? 該節介紹nn.Module梯度處理函式:requires_grad和zero_grad函式:
? 先來看requires_grad_函式:
def requires_grad_(self: T, requires_grad: bool = True) -> T:
for p in self.parameters():
p.requires_grad_(requires_grad)
return self
? 可以看出:回圈網路中所有引數,然后遞回呼叫requires_grad_函式,將所有引數的梯度設定為True,即這些引數需要更新梯度,需要進行學習,
? 在來看看zero_grad_函式:
def zero_grad(self, set_to_none: bool = False) -> None:
for p in self.parameters():
if p.grad is not None:
if set_to_none:
p.grad = None
else:
if p.grad.grad_fn is not None:
p.grad.detach_()
else:
p.grad.requires_grad_(False)
p.grad.zero_()
? 主要借助最后一行代碼,將梯度清0,
實戰:凍結BN層梯度引數
? 上節了解了凍結引數原理,現在假如凍結一個網路中所有BN層的梯度并將BN層內部引數均初始化為1,那么該如何寫呢?
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.leconv1 = nn.Conv2d(1, 1, 1, 1, 0)
self.lebn = nn.BatchNorm2d(1)
self.leconv2 = nn.Conv2d(1, 1, 1, 1, 0)
def train(self, mode = True) :
super(Net, self).train()
for module in self.children():
if isinstance(module,nn.BatchNorm2d): # 若當前module為nn.BatchNorm2d
for p in module.parameters(): # 遍歷module中所有引數
p.data.fill_(1) # 初始化為1
p.requires_grad_(False) # 不更新梯度
def forward(self,x):
pass
if __name__ == '__main__':
input = torch.ones(1,1,2,2) # 偽造資料
net = Net()
net.train()
for name, module in net.named_children():
print('net包含的模塊為:\n',module)
for p in module.parameters():
print('當前module需要學習的引數為:\n',p)
? 現在在來看下輸出結果:
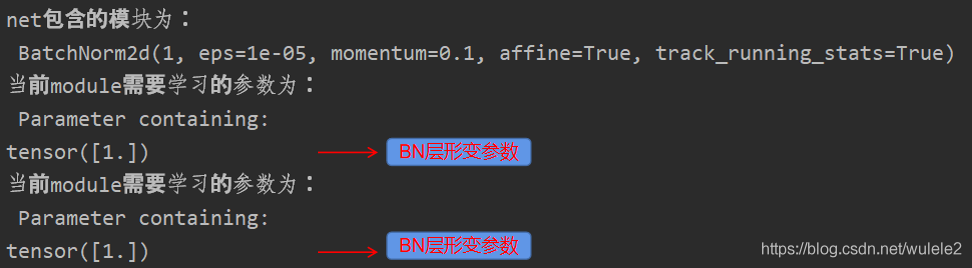
?此時,初始化為1,且沒了requires_grad這項,說明凍結引數成功,
總結
? 讀到這里讀者可能有疑問:eval和requires_grad均能凍結引數,為啥需要兩個呢?
? 我感覺eval凍結的是module層面,而requires_grad可以直接凍結module里面的任意引數,一個寬泛點,一個更加精細點,在實際操作中,往往將二者混合使用(比如凍結resnet的第一階段,同時凍結BN層),
? 下篇會介紹nn.Module中apply函式,用來初始化網路權重,后續還有hook的詳解,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/250166.html
標籤:AI