最近在微信公眾號里看到多篇講解yolov5在openvino部署做目標檢測文章,但是沒看到過用opencv的dnn模塊做yolov5目標檢測的,于是,我就想著撰寫一套用opencv的dnn模塊做yolov5目標檢測的程式,在撰寫這套程式時,遇到的bug和解決辦法,在這篇文章里講述一下,
在yolov5之前的yolov3和yolov4的官方代碼都是基于darknet框架的實作的,因此opencv的dnn模塊做目標檢測時,讀取的是.cfg和.weight檔案,那時候撰寫程式很順暢,沒有遇到bug,但是yolov5的官方代碼(https://github.com/ultralytics/yolov5)是基于pytorch框架實作的,但是opencv的dnn模塊不支持讀取pytorch的訓練模型檔案的,如果想要把pytorch的訓練模型.pth檔案加載到opencv的dnn模塊里,需要先把pytorch的訓練模型.pth檔案轉換到.onnx檔案,然后才能載入到opencv的dnn模塊里,
因此,用opencv的dnn模塊做yolov5目標檢測的程式,包含兩個步驟:(1).把pytorch的訓練模型.pth檔案轉換到.onnx檔案,(2).opencv的dnn模塊讀取.onnx檔案做前向計算,
(1).把pytorch的訓練模型.pth檔案轉換到.onnx檔案
在做這一步時,我得吐槽一下官方代碼:https://github.com/ultralytics/yolov5,這套程式里的代碼混亂,在pytorch里,通常是在.py檔案里定義網路結構的,但是官方代碼是在.yaml檔案定義網路結構,利用pytorch動態圖特性,決議.yaml檔案自動生成網路結構,在.yaml檔案里有depth_multiple和width_multiple,它是控制網路的深度和寬度的引數,這么做的好處是能夠靈活的配置網路結構,但是不利于理解網路結構,假如你想設斷點查看某一層的引數和輸出數值,那就沒辦法了,因此,在我撰寫的轉換到.onnx檔案的程式里,網路結構是在.py檔案里定義的,其次,在官方代碼里,還有一個奇葩的地方,那就是.pth檔案,起初,我下載官方代碼到本地運行時,torch.load讀取.pth檔案總是出錯,后來把pytorch升級到1.7,就讀取成功了,可以看到版本兼容性不好,這是它的一個不足之處,設斷點查看讀取的.pth檔案里的內容,可以看到.pth里既存盤有模型引數,也存盤有網路結構,還儲存了一些超引數,包括anchors,stride等等的,第一次見到有這種操作的,通常情況下,.pth檔案里只存盤了訓練模型引數的,
查看models\yolo.py里的Detect類,在建構式里,有這么兩行代碼:

我嘗試過把這兩行代碼改成self.anchors = a 和 self.anchor_grid = a.clone().view(self.nl, 1, -1, 1, 1, 2),程式依然能正常運行,但是torch.save保存模型檔案后,可以看到.pth檔案里沒有存盤anchors和anchor_grid了,在百度搜索register_buffer,解釋是:pytorch中register_buffer模型保存和加載的時候可以寫入和讀出,
在這兩行代碼的下一行:
![]()
它的作用是做特征圖的輸出通道對齊,通過1x1卷積把三種尺度特征圖的輸出通道都調整到 num_anchors*(num_classes+5),
閱讀Detect類的forward函式代碼,可以看出它的作用是根據偏移公式計算出預測框的中心坐標和高寬,這里需要注意的是,計算高和寬的代碼:
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
沒有采用exp操作,而是直接乘上anchors[i],這是yolov5與yolov3v4的一個最大區別(還有一個區別就是在訓練階段的loss函式里,yolov5采用鄰域的正樣本anchor匹配策略,增加了正樣本,其它的是一些小區別,比如yolov5的第一個模塊采用FOCUS把輸入資料2倍下采樣切分成4份,在channel維度進行拼接,然后進行卷積操作,yolov5的激活函式沒有使用Mish),
現在可以明白Detect類的作用是計算預測框的中心坐標和高寬,簡單來說就是生成proposal,作為后續NMS的輸入,進而輸出最終的檢測框,我覺得在Detect類里定義的1x1卷積是不恰當的,應該把它定義在Detect類的外面,緊鄰著Detect類之前定義1x1卷積,
在官方代碼里,有轉換到onnx檔案的程式: python models/export.py --weights yolov5s.pt --img 640 --batch 1
在pytorch1.7版本里,程式是能正常運行生成onnx檔案的,觀察export.py里的代碼,在執行torch.onnx.export之前,有這么一段代碼:
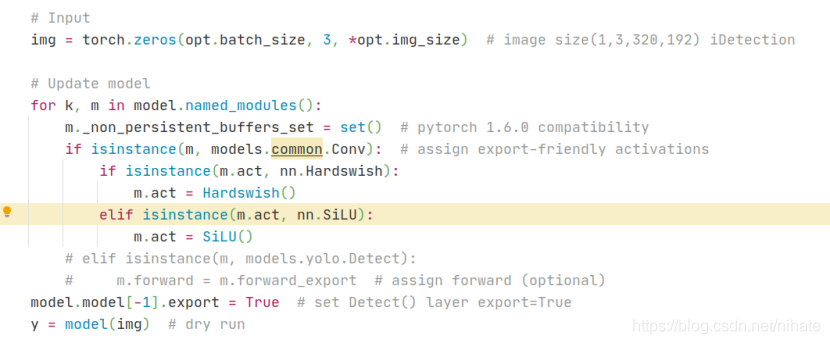
注意其中的for回圈,我試驗過注釋掉它,重新運行就會出錯,列印出的錯誤如下:
![]()
由此可見,這段for回圈代碼是必需的,
(2).opencv的dnn模塊讀取.onnx檔案做前向計算
在生成.onnx檔案后,就可以用opencv的dnn模塊里的cv2.dnn.readNet讀取它,然而,在讀取時,出現了如下錯誤:

我在百度搜索這個問題的解決辦法,看到一篇知乎文章(https://zhuanlan.zhihu.com/p/286298001?utm_source=wechat_timeline),文章里講述的第一條:

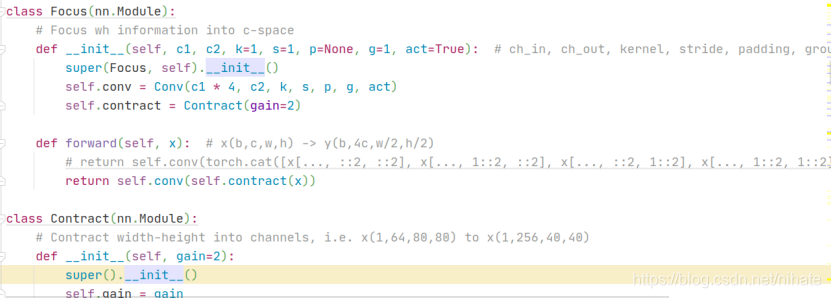
于是查看yolov5的代碼,在common.py檔案的Focus類,torch.cat的輸入里有4次切片操作,代碼如下:

那么現在需要更換索引式的切片操作,觀察到注釋的Contract類,它就是用view和permute函式完成切片操作的,于是修改代碼如下:
其次,在models\yolo.py里的Detect類里,也有切片操作,代碼如下:
![]()
前面說過,Detect類的作用是計算預測框的中心坐標和高寬,生成proposal,這個是屬于后處理的,因此不需要把它寫入到onnx檔案里,
總結一下,按照上面的截圖代碼,修改Focus類,把Detect類里面的1x1卷積定義在緊鄰著Detect類之前的外面,然后去掉Detect類,組成新的model,作為torch.onnx.export的輸入,
torch.onnx.export(model, inputs, output_onnx, verbose=False, opset_version=12, input_names=['images'], output_names=['out0', 'out1', 'out2'])
最后生成的onnx檔案,opencv的dnn模塊就能成功讀取了,接下來對照Detect類里的forward函式,用python或者C++撰寫計算預測框的中心坐標和高寬的功能,
周末這兩天,我在win10+cpu機器里撰寫了用opencv的dnn模塊做yolov5目標檢測的程式,包含Python和C++兩個版本的,程式都除錯通過了,運行結果也是正確的,我把這套代碼發布在github上,地址是 https://github.com/hpc203/yolov5-dnn-cpp-python
后處理模塊,python版本用numpy array實作的,C++版本的用vector和陣列實作的,整套程式只依賴opencv庫(opencv4版本以上的)就能正常運行,徹底擺脫對深度學習框架pytorch,tensorflow,caffe,mxnet等等的依賴,用openvino作目標檢測,需要把onnx檔案轉換到.bin和.xml檔案,相比于用dnn模塊加載onnx檔案做目標檢測是多了一個步驟的,因此,我就想撰寫一套用opencv的dnn模塊做yolov5目標檢測的程式,用opencv的dnn模塊做深度學習目標檢測,在win10和ubuntu,在cpu和gpu上都能運行,可見dnn模塊的通用性更好,很接地氣,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/250167.html
標籤:AI