一、前言
1.1、資料集介紹
? CIFAR-10資料集由10個類的60000個32x32彩色影像組成,每個類有6000個影像,有50000個訓練影像和10000個測驗影像,
? 資料集分為五個訓練批次和一個測驗批次,每個批次有10000個影像,測驗批次包含來自每個類別的恰好1000個隨機選擇的影像,訓練批次以隨機順序包含剩余影像,但一些訓練批次可能包含來自一個類別的影像比另一個更多,總體來說,五個訓練集之和包含來自每個類的正好5000張影像,
? 以下是資料集中的類,以及來自每個類的10個隨機影像:

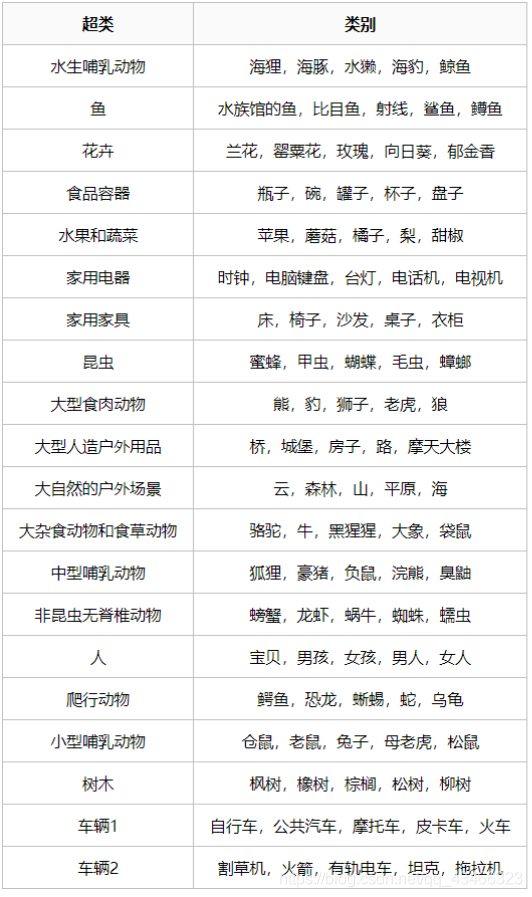
? CIFAR-100 資料集就像CIFAR-10,除了它有100個類,每個類包含600個影像,,每類各有500個訓練影像和100個測驗影像,CIFAR-100 中的100個類被分成20個超類,每個影像都帶有一個“精細”標簽(它所屬的類)和一個“粗糙”標簽(它所屬的超類),以下是 CIFAR-100 中的類別串列:
1.2、本次網路介紹
? 本次共搭建18個網路層:10個卷積層、5個最大池化層以及3個全連接層,其中2個卷積層+1個最大池化層為1個單元,具體網路引數如下圖所示:

二、匯入庫
? 本次使用的Tensorflow版本為2.0.0,為方便搭建網路,利用 kears 構建網路,因此,匯入 kears 的 layers、Sequential、optimizers、datasets,
import tensorflow as tf
from tensorflow.keras import layers,Sequential,optimizers,datasets
三、匯入Cifar-100資料集并查看資料集格式
? 利用 kearas.datasets 函式直接匯入資料集,并分為訓練集與測驗集,并查看資料集形狀:
(x,y),(x_test,y_test) = datasets.cifar100.load_data() # 加載資料集
print('x:',x.shape,'y:',y.shape,'x_test:',x_test.shape,"y_test:",y_test.shape)
? 得到的資料格式如下:

? 因為 y 與 y_test 都是標簽集,因此,其維度均應為1維,而加載后的卻是二維張量,所以要進行資料處理,
y = tf.reshape(y,[50000])
y_test = tf.reshape(y_test,[10000])
print('y:',y.shape,'y_test:',y_test.shape)

四、資料處理
4.1、資料預處理函式
? 通過資料與處理函式,將 numpy 型別資料變為 tensorflow 型別資料,
def preprocess(x,y): # 預處理函式
# [0-1]
x = tf.cast(x,dtype=tf.float32) / 255 # 歸一化處理
y = tf.cast(y,dtype=tf.int64) # y必須是整數型,因為onehot里輸入不能為float
return x,y
? 通過資料預處理函式便可以將別的型別的資料變為 tensorflow 型別,因為像素均為 0 -255 值,所以進行歸一化處理,將資料值分布變為 0 -1,由后面要進行 one_hot 編碼,所以標簽集資料必須為 tfint64型別,
4.2、進行資料處理
train_db = tf.data.Dataset.from_tensor_slices((x,y)) # 將輸入的張量的第一個維度看做樣本的個數,沿其第一個維度將tensor切片,得到的每個切片是一個樣本資料,實作了輸入張量的自動切片,
train_db = train_db.shuffle(10000).map(preprocess).batch(64) # 64個樣本為一個 batch
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(64)
? 首先對于訓練集,對變數進行切片處理,然后利用 shuffle 函式打亂資料,利用與處理函式進行資料轉換,并64個樣本為一個batch;而對于測驗集,并不需要來打亂樣本順序,
五、搭建網路層
? 為便于區分,本次搭建分為兩步:一是卷積層——包括卷積與池化兩個操作,選擇最大池化操作;二是全連接層,最后一層輸出神經元為100(本次分類的類數)且最后一層不添加激活函式,
5.1、卷積層搭建
? 卷積層共 5 個單元,每個單元都是“2+1”組合:2個卷積層,一個池化層,具體形式如下:
conv_layers = [
# unit 1
layers.Conv2D(64,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(64,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
# unit 2
layers.Conv2D(128,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(128,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
# unit 3
layers.Conv2D(256,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(256,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
# unit 4
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
# unit 5
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same')
]
5.2、全連接層搭建
? 全連接層共三層,其引數如下:
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu), # 輸出為 256
layers.Dense(128, activation=tf.nn.relu), # 輸出為 128
layers.Dense(100, activation=None), # 輸出為 100,且不加激活函式
])
六、設立各部分網路輸入形式、優化器以及定義所有變數
? 因為照片是 32 × 32 × 3 32\times32\times3 32×32×3 的,因此第一部分的輸入是 [ N o n e , 32 , 32 , 3 ] [None,32,32,3] [None,32,32,3] ,其中None 代表樣本數;第二部分全連接層輸入為 [ N o n e , 512 ] [None,512] [None,512] ,因此,為保證輸入格式正確,需要對第一部分網路的輸出進行 r e s h a p e reshape reshape 操作,
? 選擇 A d a m Adam Adam 優化器,學習率設定為 1 e ? 4 1e-4 1e?4 ,網路的總變數 = 第一部分變數 + 第二部分變數,
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None,512])
optimizer = optimizers.Adam(lr=1e-4)
variables = conv_net.variables + fc_net.variables
七、前向傳播與誤差計算
? 訓練 50 次, b a t c h s i z e = 64 batchsize = 64 batchsize=64 ,每訓練 100 個批次,輸出列印準確率與損失函式值,
for epoch in range(50):
for step,(x,y) in enumerate(train_db): # enumerate() 函式用于將一個可遍歷的資料物件(如串列、元組或字串)組合為一個索引序列,同時列出資料和資料下標,一般用在 for 回圈當中
with tf.GradientTape() as tape:
# [b,32,32,3] => [b,1,1,512]
out = conv_net(x)
# flaten
out = tf.reshape(out,[-1,512])
# [b,512] => [b,100]
logits = fc_net(out)
# onehot編碼:[b] => [b,100]
y_onehotcode = tf.one_hot(y,100) # y不能為float
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehotcode,logits,from_logits=True)
loss = tf.reduce_mean(loss)
八、梯度求解與權重更新
grads = tape.gradient(loss,variables) # 求解梯度
optimizer.apply_gradients(zip(grads,variables)) # 梯度更新
if step % 100 ==0:
print(epoch,step,'loss:',float(loss))
九、測驗訓練集
for x,y in test_deb:
out = conv_net(x)
out = tf.reshape(out,[-1,512]) # 保證全連接層輸入正確
logits = fc_net(out)
prob = tf.nn.softmax(logits,axis=1)
pred = tf.argmax(prob,axis= 1) # 把全連接層的輸出進行分類
# 求解準確率
correct = tf.cast(tf.equal(pred,y),dtype=tf.int32)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch,'acc:',acc)
十、附錄
10.1、注意事項
- 資料集的形狀十分重要,無論是加載后資料集還是要預處理的資料集,都應確保其 s h a p e shape shape 準確,否則無法代入網路進行訓練;
- 利用 tf.one_hot() 函式進行編碼時,要確保資料為 tf.int64
10.2、完整代碼
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" # 屏蔽tensorflow的輸出日志資訊,必須放在匯入TF庫前
import tensorflow as tf
from tensorflow.keras import layers,Sequential,optimizers,datasets
conv_layers = [
# unit 1
layers.Conv2D(64,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(64,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
# unit 2
layers.Conv2D(128,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(128,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
# unit 3
layers.Conv2D(256,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(256,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
# unit 4
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same'),
# unit 5
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.Conv2D(512,kernel_size=[3,3],padding='same',activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2,2],strides=2,padding='same')
]
def preprocess(x,y): # 預處理函式
# [0-1]
x = tf.cast(x,dtype=tf.float32) / 255
y = tf.cast(y,dtype=tf.int64) # y必須是整數型,因為onehot里輸入不能為float
return x,y
(x,y),(x_test,y_test) = datasets.cifar100.load_data() # 加載資料集
y = tf.reshape(y,[50000])
y_test = tf.reshape(y_test,[10000])
train_db = tf.data.Dataset.from_tensor_slices((x,y)) # 將輸入的張量的第一個維度看做樣本的個數,沿其第一個維度將tensor切片,得到的每個切片是一個樣本資料,實作了輸入張量的自動切片,
train_db = train_db.shuffle(10000).map(preprocess).batch(64)
test_db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db = test_db.map(preprocess).batch(64)
def main():
# [b,32,32,3] => [b,1,1,512]
conv_net = Sequential(conv_layers)
# x =tf.random.normal([4,32,32,3])
# out = conv_net(x)
# print(out.shape)
fc_net = Sequential([
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(128,activation=tf.nn.relu),
layers.Dense(100,activation=None) # 最后一個全連接層,因為有100個種類,所以輸出為100
])
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None,512])
optimizer = optimizers.Adam(lr=1e-4)
variables = conv_net.variables + fc_net.variables
for epoch in range(50):
for step,(x,y) in enumerate(train_db): # enumerate() 函式用于將一個可遍歷的資料物件(如串列、元組或字串)組合為一個索引序列,同時列出資料和資料下標,一般用在 for 回圈當中
with tf.GradientTape() as tape:
# [b,32,32,3] => [b,1,1,512]
out = conv_net(x)
# flaten
out = tf.reshape(out,[-1,512])
# [b,512] => [b,100]
logits = fc_net(out)
# onehot編碼:[b] => [b,100]
y_onehotcode = tf.one_hot(y,100) # y不能為float
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehotcode,logits,from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss,variables) # 求解梯度
optimizer.apply_gradients(zip(grads,variables)) # 梯度更新 zip() 函式用于將可迭代的物件作為引數,將物件中對應的元素打包成一個個元組,然后回傳由這些元組組成的串列,
# 如果各個迭代器的元素個數不一致,則回傳串列長度與最短的物件相同,
if step % 100 == 0:
print(epoch,step,'loss:',float(loss))
total_num = 0
total_correct = 0
for x,y in test_db:
out = conv_net(x)
out = tf.reshape(out,[-1,512])
logits = fc_net(out)
prob = tf.nn.softmax(logits,axis=1) # 進行預測
pred = tf.argmax(prob,axis=1)
correct = tf.cast(tf.equal(pred,y),dtype=tf.int32)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch,'acc:',acc)
if __name__ == '__main__':
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/250169.html
標籤:AI
上一篇:【python】在學習用于圖和網路分析的python時遇到的問題和解決方法
下一篇:MySQL常用陳述句