文章目錄
- 神經網路訓練細節與注意點
- 梯度檢查
- 使用雙精度浮點數
- 使用少量資料點
- 不要讓正則化項蓋過資料項
- 訓練程序中的監控
- 訓練集/驗證集上的準確度
- 我們用標準差為0.01均值為0的高斯分布值來初始化權重(這不合理)
- 重新正確設定權重:
- 隨機梯度下降與引數更新
- 普通更新
- 物理動量角度啟發的引數更新
- Nesterov Momentum
- 計算dx_ahead(在x_ahead處的梯度,而不是在x處的梯度)
- 學習率退火
- 二階方法
- Adam
- 歡迎關注公眾號~ 你可以獲取這篇文章的詳細講解視頻和相關實作代碼~
- 想獲取視頻和實作代碼(巨大學習價值)~可以在公眾號回復:動手擼第二期
神經網路訓練細節與注意點
本文主要包括以下內容:
梯度檢查
合理性(Sanity)檢查
檢查學習程序
損失函式
訓練集與驗證集準確率
權重:更新比例
每層的激活資料與梯度分布
可視化
引數更新
一階(隨機梯度下降)方法,動量方法,Nesterov動量方法
學習率退火
二階方法
逐引數適應學習率方法(Adagrad,RMSProp)
超引數調優
評價
模型集成
總結
拓展參考

梯度檢查
理論上將進行梯度檢查很簡單,就是簡單地把決議梯度和數值計算梯度進行比較,然而從實際操作層面上來說,這個程序更加復雜且容易出錯,下面是一些提示、技巧和需要仔細注意的事情:
加max項的原因很簡單:整體形式變得簡單和對稱,再提個小醒,別忘了避開分母中兩項都為0的情況,OK,對于相對誤差而言
相對誤差>1e-2意味著你的實作肯定是有問題的
1e-2>相對誤差>1e-4,你會有點擔心
1e-4>相對誤差,基本是OK的,但是要注意極端情況(使用tanh或者softmax時候出現kinks)那還是太大
1e-7>相對誤差,放心大膽使用
使用雙精度浮點數
如果你使用單精度浮點數計算,那你的實作可能一點問題都沒有,但是相對誤差卻很大,實際工程中出現過,從單精度切到雙精度,相對誤差立馬從1e-2降到1e-8的情況,
要留意浮點數的范圍
一篇很好的文章是What Every Computer Scientist Should Know About Floating-Point Arithmetic,我們得保證計算時,所有的數都在浮點數的可計算范圍內,太小的值(通常絕對值小于1e-10就絕對讓人擔心)會帶來計算上的問題,如果確實過小,可以使用一個常數暫時將損失函式的數值范圍擴展到一個更“好”的范圍,在這個范圍中浮點數變得更加致密,比較理想的是1.0的數量級上,即當浮點數指數為0時,
目標函式的不可導點(kinks)
在進行梯度檢查時,一個導致不準確的原因是不可導點問題,不可導點是指目標函式不可導的部分,它指的是一種會導致數值梯度和決議梯度不一致的情況,會出現在使用ReLU或者類似的神經單元上時,對于很小的負數,比如x=-1e-6,因為x<0,所以決議梯度是絕對為0的,但是對于數值梯度而言,加入你計算f(x+h),取的h>1e-6,那就跳到大于0的部分了,這樣數值梯度就一定和決議梯度不一樣了,而且這個并不是極端情況哦,對于一個像CIFAR-10這樣級別的資料集,因為有50000個樣本,會有450000個max(0,x),會出現很多的kinks,
不過我們可以監控max里的2項,比較大的那項如果存在躍過0的情況,那就要注意了,
使用少量資料點
解決上面的不可導點問題的一個辦法是使用更少的資料點,因為含有不可導點的損失函式(例如:因為使用了ReLU或者邊緣損失等函式)的資料點越少,不可導點就越少,所以在計算有限差值近似時越過不可導點的幾率就越小,還有,如果你的梯度檢查對2-3個資料點都有效,那么基本上對整個批量資料進行梯度檢查也是沒問題的,所以使用很少量的資料點,能讓梯度檢查更迅速高效,
設定步長h要小心
h肯定不能特別大,這個大家都知道對吧,但我并不是說h要設定的非常小,其實h設定的非常小也會有問題,因為h太小程式可能會有精度問題,很有意思的是,有時候在實際情況中h如果從非常小調為1e-4或者1e-6反倒會突然計算變得正常,
不要讓正則化項蓋過資料項
通常損失函式是資料損失和正則化損失的和(例如L2對權重的懲罰),需要注意的危險是正則化損失可能吞沒掉資料損失,在這種情況下梯度主要來源于正則化部分(正則化部分的梯度運算式通常簡單很多),這樣就會掩蓋掉資料損失梯度的不正確實作,因此,推薦先關掉正則化對資料損失做單獨檢查,然后對正則化做單獨檢查,對于正則化的單獨檢查可以是修改代碼,去掉其中資料損失的部分,也可以提高正則化強度,確認其效果在梯度檢查中是無法忽略的,這樣不正確的實作就會被觀察到了,
記得關閉隨機失活(dropout)和資料擴張(augmentation)
在進行梯度檢查時,記得關閉網路中任何不確定的效果的操作,比如隨機失活,隨機資料擴展等,不然它們會在計算數值梯度的時候導致巨大誤差,關閉這些操作不好的一點是無法對它們進行梯度檢查(例如隨機失活的反向傳播實作可能有錯誤),因此,一個更好的解決方案就是在計算f(x+h)和f(x-h)前強制增加一個特定的隨機種子,在計算決議梯度時也同樣如此,
檢查少量的維度
在實際中,梯度可以有上百萬的引數,在這種情況下只能檢查其中一些維度然后假設其他維度是正確的,注意:確認在所有不同的引數實際情況中,梯度可能有上百萬維引數,因此每個維度都檢查一遍就不太現實了,一般都是只檢查一些維度,然后假定其他的維度也都正確,要小心一點:要保證這些維度的每個引數都檢查對比過了,
訓練前的檢查作業
在開始訓練之前,我們還得做一些檢查,來確保不會運行了好一陣子,才發現計算代價這么大的訓練其實并不正確,
在初始化之后看一眼loss,其實我們在用很小的亂數初始化神經網路后,第一遍計算loss可以做一次檢查(當然要記得把正則化系數設為0),以CIFAR-10為例,如果使用Softmax分類器,我們預測應該可以拿到值為2.302左右的初始loss(因為10個類別,初始概率應該都為0.1,Softmax損失是-log(正確類別的概率):-ln(0.1)=2.302),對于Weston Watkins SVM,假設所有的邊界都被越過(因為所有的分值都近似為零),所以損失值是9(因為對于每個錯誤分類,邊界值是1),如果沒看到這些損失值,那么初始化中就可能有問題,
加回正則項,接著我們把正則化系數設為正常的小值,加回正則化項,這時候再算損失/loss,應該比剛才要大一些,
試著去擬合一個小的資料集,最后一步,也是很重要的一步,在對大資料集做訓練之前,我們可以先訓練一個小的資料集(比如20張圖片),然后看看你的神經網路能夠做到0損失/loss(當然,是指的正則化系數為0的情況下),因為如果神經網路實作是正確的,在無正則化項的情況下,完全能夠過擬合這一小部分的資料,但是注意,能對小資料集進行過擬合并不代表萬事大吉,依然有可能存在不正確的實作,比如,因為某些錯誤,資料點的特征是隨機的,這樣演算法也可能對小資料進行過擬合,但是在整個資料集上跑演算法的時候,就沒有任何泛化能力,
訓練程序中的監控
開始訓練之后,我們可以通過監控一些指標來了解訓練的狀態,我們還記得有一些引數是我們認為敲定的,比如學習率,比如正則化系數,
損失/loss隨每輪完整迭代后的變化
合適的學習率可以保證每輪完整訓練之后,loss都減小,且能在一段時間后降到一個較小的程度,太小的學習率下loss減小的速度很慢,如果太激進,設定太高的學習率,開始的loss減小速度非常可觀,可是到了某個程度之后就不再下降了,在離最低點一段距離的地方反復,無法下降了,下圖是實際訓練CIFAR-10的時候,loss的變化情況:
大家可能會注意到上圖的曲線有一些上下跳動,不穩定,這和隨機梯度下降時候設定的batch size有關系,batch size非常小的情況下,會出現很大程度的不穩定,如果batch size設定大一些,會相對穩定一點,
訓練集/驗證集上的準確度
然后我們需要跟蹤一下訓練集和驗證集上的準確度狀況,以判斷分類器所處的狀態(過擬合程度如何):
隨著時間推進,訓練集和驗證集上的準確度都會上升,如果訓練集上的準確度到達一定程度后,兩者之間的差值比較大,那就要注意一下,可能是過擬合現象,如果差值不大,那說明模型狀況良好,
權重:權重更新部分 的比例
最后一個應該跟蹤的量是權重中更新值的數量和全部值的數量之間的比例,注意:是更新的,而不是原始梯度(比如,在普通sgd中就是梯度乘以學習率),需要對每個引數集的更新比例進行單獨的計算和跟蹤,一個經驗性的結論是這個比例應該在1e-3左右,如果更低,說明學習率可能太小,如果更高,說明學習率可能太高,下面是具體例子:
相較于跟蹤最大和最小值,有研究者更喜歡計算和跟蹤梯度的范式及其更新,這些矩陣通常是相關的,也能得到近似的結果,
每層的激活資料及梯度分布
如果初始化不正確,那整個訓練程序會越來越慢,甚至直接停掉,不過我們可以很容易發現這個問題,體現最明顯的資料是每一層的激勵和梯度的方差(波動狀況),舉個例子說,如果初始化不正確,很有可能從前到后逐層的激勵(激勵函式的輸入部分)方差變化是如下的狀況:
我們用標準差為0.01均值為0的高斯分布值來初始化權重(這不合理)
Layer 0: Variance: 1.005315e+00
Layer 1: Variance: 3.123429e-04
Layer 2: Variance: 1.159213e-06
Layer 3: Variance: 5.467721e-10
Layer 4: Variance: 2.757210e-13
Layer 5: Variance: 3.316570e-16
Layer 6: Variance: 3.123025e-19
Layer 7: Variance: 6.199031e-22
Layer 8: Variance: 6.623673e-25
大家看一眼上述的數值,就會發現,從前往后,激勵值波動逐層降得非常厲害,這也就意味著反向演算法中,計算回傳梯度的時候,梯度都要接近0了,因此引數的迭代更新幾乎就要衰減沒了,顯然不太靠譜,我們按照上一講中提到的方式正確初始化權重,再逐層看激勵/梯度值的方差,會發現它們的方差衰減沒那么厲害,近似在一個級別:
重新正確設定權重:
Layer 0: Variance: 1.002860e+00
Layer 1: Variance: 7.015103e-01
Layer 2: Variance: 6.048625e-01
Layer 3: Variance: 8.517882e-01
Layer 4: Variance: 6.362898e-01
Layer 5: Variance: 4.329555e-01
Layer 6: Variance: 3.539950e-01
Layer 7: Variance: 3.809120e-01
Layer 8: Variance: 2.497737e-01
再看逐層的激勵波動情況,你會發現即使到最后一層,網路也還是『活躍』的,意味著反向傳播中回傳的梯度值也是夠的,神經網路是一個積極learning的狀態,
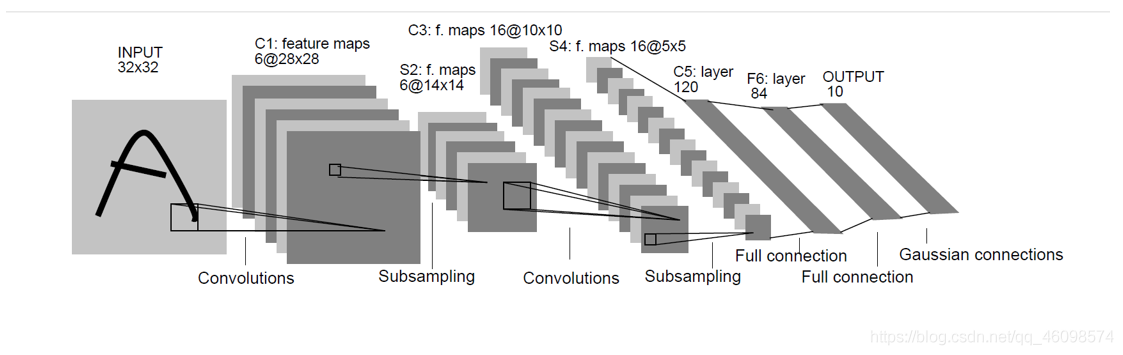
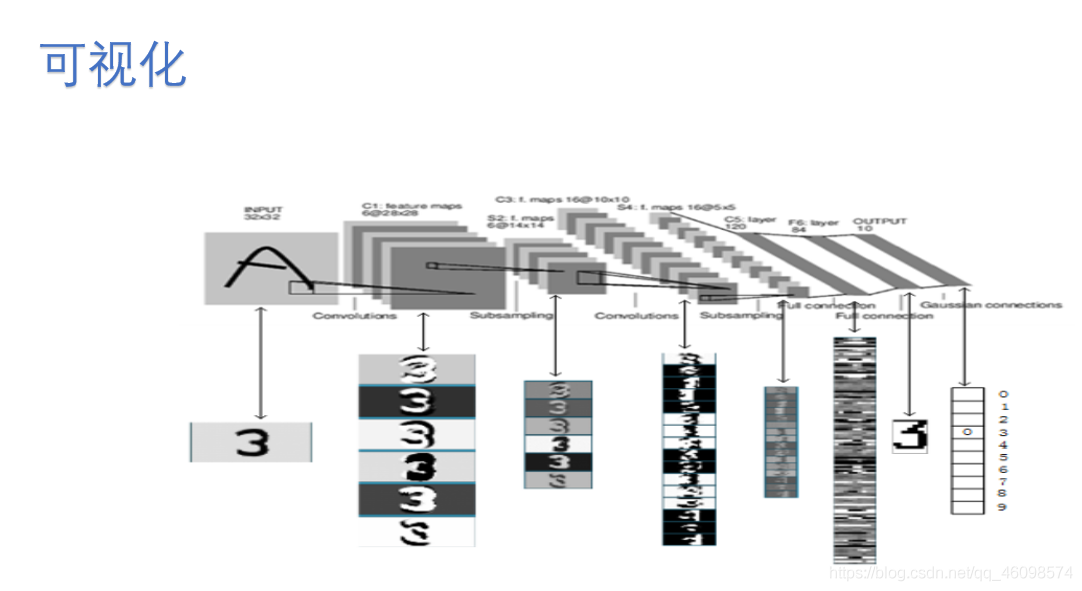
第一層可視化
最后再提一句,如果神經網路是用在影像相關的問題上,那么把首層的特征和資料畫出來(可視化)可以幫助我們了解訓練是否正常:上圖的左右是一個正常和不正常情況下首層特征的可視化對比,左邊的圖中特征噪點較多,影像很『渾濁』,預示著可能訓練處于『病態』程序:也許是學習率設定不正常,或者正則化系數設定太低了,或者是別的原因,可能神經網路不會收斂,右邊的圖中,特征很平滑和干凈,同時相互間的區分度較大,這表明訓練程序比較正常,
引數更新
當我們確信決議梯度實作正確后,那就該在后向傳播演算法中使用它更新權重引數了,就單引數更新這個部分,也是有講究的:
說起來,神經網路的最優化這個子話題在深度學習研究領域還真是很熱,下面提一下大神們的論文中提到的方法,很多在實際應用中還真是很有效也很常用,
隨機梯度下降與引數更新
普通更新,最簡單的更新形式是沿著負梯度方向改變引數(因為梯度指向的是上升方向,但是我們通常希望最小化損失函式),假設有一個引數向量x及其梯度dx,那么最簡單的更新的形式是:
普通更新
x += - learning_rate * dx
其中learning_rate是一個超引數,它是一個固定的常量,當在整個資料集上進行計算時,只要學習率足夠低,總是能在損失函式上得到非負的進展,
Momentum update
這是上面引數更新方法的一種小小的優化,通常說來,在深層次的神經網路中,收斂效率更高一些(速度更快),這種引數更新方式源于物理學角度的優化,
物理動量角度啟發的引數更新
v = mu * v - learning_rate * dx # 合入一部分附加速度
x += v # 更新引數
這里v是初始化為0的一個值,mu是我們敲定的另外一個超變數(最常見的設定值為0.9,物理含義和摩擦力系數相關),一個比較粗糙的理解是,(隨機)梯度下降可以看做從山上下山到山底的程序,這種方式,相當于在下山的程序中,加上了一定的摩擦阻力,消耗掉一小部分動力系統的能量,這樣會比較高效地在山底停住,而不是持續震蕩,對了,其實我們也可以用交叉驗證來選擇最合適的mu值,一般我們會從[0.5, 0.9, 0.95, 0.99]里面選出最合適的,
Nesterov Momentum
Nesterov動量與普通動量有些許不同,最近變得比較流行,在理論上對于凸函式它能得到更好的收斂,在實踐中也確實比標準動量表現更好一些,
它的思想對應著如下的代碼:
x_ahead = x + mu * v
計算dx_ahead(在x_ahead處的梯度,而不是在x處的梯度)
v = mu * v - learning_rate * dx_ahead
x += v
然而在實踐中,人們更喜歡和普通SGD或上面的動量方法一樣簡單的運算式,通過對x_ahead = x + mu * v使用變數變換進行改寫是可以做到的,然后用x_ahead而不是x來表示上面的更新,也就是說,實際存盤的引數向量總是向前一步的那個版本,x_ahead的公式(將其重新命名為x)就變成了:
v_prev = v # 存盤備份
v = mu * v - learning_rate * dx # 速度更新保持不變
x += -mu * v_prev + (1 + mu) * v # 位置更新變了形式
學習率退火
在實際訓練程序中,隨著訓練程序推進,逐漸衰減學習率是很有必要的,我們繼續回到下山的場景中,剛下山的時候,可能離最低點很遠,那我步子邁大一點也沒什么關系,可是快到山腳了,我還激進地大步飛奔,一不小心可能就邁過去了,所以還不如隨著下山程序推進,逐步級訓一點點步伐,不過這個『火候』確實要好好把握,衰減太慢的話,最低段震蕩的情況依舊;衰減太快的話,整個系統下降的『動力』衰減太快,很快就下降不動了,下面提一些常見的學習率衰減方式:
步伐衰減:這是很常見的一個衰減模式,每進行幾個周期就根據一些因素降低學習率,典型的值是每過5個周期就將學習率減少一半,或者每20個周期減少到之前的0.1,這些數值的設定是嚴重依賴具體問題和模型的選擇的,在實踐中可能看見這么一種經驗做法:使用一個固定的學習率來進行訓練的同時觀察驗證集錯誤率,每當驗證集錯誤率停止下降,就乘以一個常數(比如0.5)來降低學習率,
指數級別衰減:數學形式為α=α0e?ktα=α0e?kt,其中α0α0,k是需要自己敲定的超引數,t是迭代輪數,
1/t衰減:有著數學形式為α=α0/(1+kt)α=α0/(1+kt)的衰減模式,其中α0α0,k是需要自己敲定的超引數,t是迭代輪數,
實際工程實踐中,大家還是更傾向于使用步伐衰減,因為它包含的超引數少一些,計算簡單一些,可解釋性稍微高一點,
二階方法
逐引數適應學習率方法
到目前為止大家看到的學習率更新方式,都是全域使用同樣的學習率,調整學習率是一件很費時同時也容易出錯的事情,因此大家一直希望有一種學習率自更新的方式,甚至可以細化到逐引數更新,現在確實有一些這種方法,其中大多數還需要額外的超引數設定,優勢是在大多數超引數設定下,效果都比使用寫死的學習率要好,在本小節我們會介紹一些在實踐中可能會遇到的常用適應演算法:
Adagrad是一個由Duchi等提出的適應性學習率演算法
假設有梯度和引數向量x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
注意,變數cache的尺寸和梯度矩陣的尺寸是一樣的,還跟蹤了每個引數的梯度的平方和,這個一會兒將用來歸一化引數更新步長,歸一化是逐元素進行的,注意,接收到高梯度值的權重更新的效果被減弱,而接收到低梯度值的權重的更新效果將會增強,有趣的是平方根的操作非常重要,如果去掉,演算法的表現將會糟糕很多,用于平滑的式子eps(一般設為1e-4到1e-8之間)是防止出現除以0的情況,Adagrad的一個缺點是,在深度學習中單調的學習率被證明通常過于激進且過早停止學習,
RMSprop
是一個非常高效,但沒有公開發表的適應性學習率方法,有趣的是,每個使用這個方法的人在他們的論文中都參考自Geoff Hinton的Coursera課程的第六課的第29頁PPT,這個方法用一種很簡單的方式修改了Adagrad方法,讓它不那么激進,單調地降低了學習率,具體說來,就是它使用了一個梯度平方的滑動平均:
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
在上面的代碼中,decay_rate是一個超引數,常用的值是[0.9,0.99,0.999],其中x+=和Adagrad中是一樣的,但是cache變數是不同的,因此,RMSProp仍然是基于梯度的大小來對每個權重的學習率進行修改,這同樣效果不錯,但是和Adagrad不同,其更新不會讓學習率單調變小,
Adam
Adam是最近才提出的一種更新方法,它看起來像是RMSProp的動量版,簡化的代碼是下面這樣:
m = beta1m + (1-beta1)dx
v = beta2v + (1-beta2)(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)
注意這個更新方法看起來真的和RMSProp很像,除了使用的是平滑版的梯度m,而不是用的原始梯度向量dx,論文中推薦的引數值eps=1e-8, beta1=0.9, beta2=0.999,在實際操作中,我們推薦Adam作為默認的演算法,一般而言跑起來比RMSProp要好一點,但是也可以試試SGD+Nesterov動量,完整的Adam更新演算法也包含了一個偏置(bias)矯正機制,因為m,v兩個矩陣初始為0,在沒有完全熱身之前存在偏差,需要采取一些補償措施,建議讀者可以閱讀論文查看細節,或者課程的PPT,
下圖是上述提到的多種引數更新方法下,損失函式最優化的示意圖:
超引數調優
我們已經看到,訓練一個神經網路會遇到很多超引數設定,神經網路最常用的設定有:
初始學習率,
學習率衰減方式(例如一個衰減常量),
正則化強度(L2懲罰,隨機失活強度),
但是也可以看到,還有很多相對不那么敏感的超引數,比如在逐引數適應學習方法中,對于動量及其時間表的設定等,在本節中將介紹一些額外的調參要點和技巧:
對于大的深層次神經網路而言,我們需要很多的時間去訓練,因此在此之前我們花一些時間去做超引數搜索,以確定最佳設定是非常有必要的,最直接的方式就是在框架實作的程序中,設計一個會持續變換超引數實施優化,并記錄每個超引數下每一輪完整訓練迭代下的驗證集狀態和效果,實際工程中,神經網路里確定這些超引數,我們一般很少使用n折交叉驗證,一般使用一份固定的交叉驗證集就可以了,
超引數范圍
一般對超引數的嘗試和搜索都是在log域進行的,例如,一個典型的學習率搜索序列就是learning_rate = 10 ** uniform(-6, 1),我們先生成均勻分布的序列,再以10為底做指數運算,其實我們在正則化系數中也做了一樣的策略,比如常見的搜索序列為[0.5, 0.9, 0.95, 0.99],另外還得注意一點,如果交叉驗證取得的最佳超引數結果在分布邊緣,要特別注意,也許取的均勻分布范圍本身就是不合理的,也許擴充一下這個搜索范圍會有更好的引數,
模型融合與優化
實際工程中,一個能有效提高最后神經網路效果的方式是,訓練出多個獨立的模型,在預測階段選結果中的眾數,模型融合能在一定程度上緩解過擬合的現象,對最后的結果有一定幫助,我們有一些方式可以得到同一個問題的不同獨立模型:
使用不同的初始化引數,先用交叉驗證確定最佳的超引數,然后選取不同的初始值進行訓練,結果模型能有一定程度的差別,
在交叉驗證中發現最好的模型,使用交叉驗證來得到最好的超引數,然后取其中最好的幾個(比如10個)模型來進行集成,這樣就提高了集成的多樣性,但風險在于可能會包含不夠理想的模型,在實際操作中,這樣操作起來比較簡單,在交叉驗證后就不需要額外的訓練了,
一個模型設定多個記錄點,如果訓練非常耗時,那就在不同的訓練時間對網路留下記錄點(比如每個周期結束),然后用它們來進行模型集成,很顯然,這樣做多樣性不足,但是在實踐中效果還是不錯的,這種方法的優勢是代價比較小,
還有一種常用的有效改善模型效果的方式是,對于訓練后期,保留幾份中間模型權重和最后的模型權重,對它們求一個平均,再在交叉驗證集上測驗結果,通常都會比直接訓練的模型結果高出一兩個百分點,直觀的理解是,對于碗狀的結構,有很多時候我們的權重都是在最低點附近跳來跳去,而沒法真正到達最低點,而兩個最低點附近的位置求平均,會有更高的概率落在離最低點更近的位置,
總結
訓練一個神經網路需要:
利用小批量資料對實作進行梯度檢查,還要注意各種錯誤,
進行合理性檢查,確認初始損失值是合理的,在小資料集上能得到100%的準確率,
在訓練時,跟蹤損失函式值,訓練集和驗證集準確率,如果愿意,還可以跟蹤更新的引數量相對于總引數量的比例(一般在1e-3左右),然后如果是對于卷積神經網路,可以將第一層的權重可視化,
推薦的兩個更新方法是SGD+Nesterov動量方法,或者Adam方法,
隨著訓練進行學習率衰減,比如,在固定多少個周期后讓學習率減半,或者當驗證集準確率下降的時候,
使用隨機搜索(不要用網格搜索)來搜索最優的超引數,分階段從粗(比較寬的超引數范圍訓練1-5個周期)到細(窄范圍訓練很多個周期)地來搜索,
進行模型集成來獲得額外的性能提高,
文章參考于博客園: 良有以也,我已詳細分析并發布于公眾號:
歡迎關注公眾號~ 你可以獲取這篇文章的詳細講解視頻和相關實作代碼~
結合全文,我在mnist資料集上實作了訓練集100%準確率和驗證集99.2準確率,歡迎來看~ 代碼在這了:
import cv2
import torch
import torch.nn as nn
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import numpy
import argparse
from tqdm import tqdm
import torch.nn.functional as F
from torch.autograd import Variable
class Cnn_Mnist(nn.Module):
def __init__(self):
"""
super(Cnn_Mnist, self).__init__()
self.conv = nn.Conv2d(1, 4, 3)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(1, 4, 3)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(13*13*4, 30)
self.fc2 = nn.Linear(30, 10)
self.softmax = nn.Softmax()
def forward(self, x):
# 卷積層,分別是二維卷積->sigmoid激勵->池化
out = self.conv(x) # [batch_size, 4, 28 - 9 - 1=20, 28 - 9 - 1=20]
out = torch.sigmoid(out)
out = self.pool(out)
# 將特征的維度進行變化(batchSize*filterDim*featureDim*featureDim->batchSize*flat_features)
out = out.view(-1, self.num_flat_features(out))
out = self.fc(out)
out = torch.sigmoid(out)
out = self.fc2(out)
out = self.softmax(out)
return out"""
super(Cnn_Mnist, self).__init__()
self.conv1 = nn.Sequential( # input_size=(1*28*28)
nn.Conv2d(1, 6, 5, 1, 2), # padding=2保證輸入輸出尺寸相同
nn.ReLU(), # input_size=(6*28*28)
nn.MaxPool2d(kernel_size=2, stride=2), # output_size=(6*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.ReLU(), # input_size=(16*10*10)
nn.MaxPool2d(2, 2) # output_size=(16*5*5)
)
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10)
# 定義前向傳播程序,輸入為x
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# nn.Linear()的輸入輸出都是維度為一的值,所以要把多維度的tensor展平成一維
x = x.view(x.size()[0], -1) # [batch_size, 400]
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
x = F.softmax(x, dim=1)
return x # F.softmax(x, dim=1)
def num_flat_features(self, out):
size = out.size()[1:]
num_feature = 1
for i in size:
num_feature *=i
return num_feature
class Train_Test():
def __int__(self):
pass
def get_data(self):
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
self.trainset = datasets.MNIST('./data', download=True, train=True, transform=transform)
self.trainsetloader = torch.utils.data.DataLoader(self.trainset, batch_size=args.batch_size, shuffle=True, pin_memory=True)
self.testset = datasets.MNIST('./data', download=True, train=False, transform=transform)
self.testset_loader = torch.utils.data.DataLoader(self.testset,batch_size=1, shuffle=True)
def train(self):
best = 0.
net = Cnn_Mnist().to(args.device)
self.get_data()
self.loss_fn = torch.nn.CrossEntropyLoss()
self.optimizer = torch.optim.Adam(net.parameters(), lr=args.learning_rate)
tq = tqdm(range(args.epochs))
for epoch in tq:
running_loss = 0.
running_acc = 0.
for (images, labels) in self.trainsetloader:
image = Variable(images.to(args.device))
label = Variable(labels.to(args.device))
output = net(image.to(args.device))
loss = self.loss_fn(output, labels.to(args.device))
self.optimizer.zero_grad()
# backward
loss.backward()
# optimizer
self.optimizer.step()
running_loss += loss.item()
_, predict = torch.max(output, 1)
running_acc += (predict == label).sum().item()
running_acc /= len(self.trainset)
running_loss /= len(self.trainset)
print(" Loss: %.5f, Acc: %.5f" % (running_loss, 100 * running_acc))
if running_acc >= best:
# 保存下訓練好的模型,省得下次再重新訓練
best = running_acc
# torch.save(net.state_dict(), args.weights)
print(' Best model saved! Epoch:', epoch)
def val(self):
net = Cnn_Mnist().to(args.device)
net.load_state_dict(torch.load(args.weights))
self.get_data()
self.loss_fn = torch.nn.CrossEntropyLoss()
self.optimizer = torch.optim.Adam(net.parameters(), lr=args.learning_rate)
net.eval()
test_loss = 0.
testacc = 0.
bad_case_num = 0
print(len(self.trainset), len(self.testset))
for (images, labels) in tqdm(self.testset_loader):
image = Variable(images.to(args.device))
label = Variable(labels.to(args.device))
outputs = net(image)
loss = self.loss_fn(outputs, label)
self.optimizer.step()
test_loss += loss.item()
nothing, predict = torch.max(outputs, 1)
testacc += (predict == label).sum().item()
if predict != label:
bad_case_num += 1
# print(predict, '****', label)
testacc /= len(self.testset)
test_loss /= len(self.testset)
print("Val Loss: %.5f, Acc: %.2f Bad_case_num %d" % (test_loss, 100 * testacc, bad_case_num))
def test(self):
self.get_data()
net = Cnn_Mnist().to(args.device)
net.load_state_dict(torch.load(args.weights))
testsetloader = iter(self.testset_loader)
images, labels = testsetloader.next()
plt.imshow(images[0].numpy().squeeze())
plt.show()
print(images.shape)
# plt.imshow(images.numpy().squeeze())
output = net(images.to(args.device))
nothing, predict = torch.max(output, 1)
print(predict)
# cv2.imshow()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', default=300, help='training epochs')
parser.add_argument('--method', default='val', help='train to run, test or val')
parser.add_argument('--weights', default='models/cnn_mnist.pt', help='save the weight')
parser.add_argument('--device', default='cuda', help='cuda or cpu')
parser.add_argument('--learning_rate', default=1.5e-4, help='cuda or cpu')
parser.add_argument('--batch_size', default=1, help='batch_size')
args = parser.parse_args()
mnist = Train_Test()
if 'train' in args.method:
mnist.train()
elif 'val' in args.method:
mnist.val()
elif 'test' in args.method:
mnist.test()
else:
print('please check the argparse!')
想獲取視頻和實作代碼(巨大學習價值)~可以在公眾號回復:動手擼第二期

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255633.html
標籤:AI
上一篇:原器件集合