作者:小小明
非常擅長解決各類復雜資料處理的邏輯,各類結構化與非結構化資料互轉,字串決議匹配等等,
至今已經幫助至少百名資料從業者解決作業中的實際問題,如果你在資料處理上遇到什么困難,歡迎評論區與我交流,
求每個學生分數最接近的10個學生
需求背景
某MOOC課程網站的老師需要統計每個學生成績最相近的10個學生,距離計算公式是每門課程的成績之差的絕對值求和,
例如,學生1的成績為(83,84,86,99,87),學生2的成績為(83,84,86,99,87)
兩個學生的距離為|83-83|+|84-84|+|86-86|+|99-99|+|87-87|=0則判定為這兩個學生成績距離完全相同,這個距離越大說明兩個學生的成績差異越大,
下面僅使用模擬資料展示,
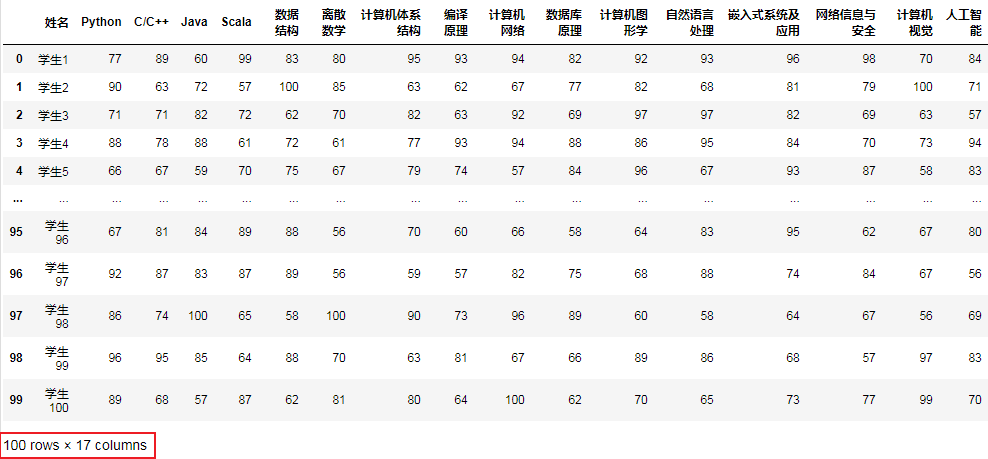
首先讀取資料:
import pandas as pd
import numpy as np
import heapq
df = pd.read_csv("學生成績.csv", encoding="gbk")
df.head()
結果:
這位老師管理的小班,僅100個學生,
采用雙重for回圈遍歷每個學生與所有學生進行匹配計算,也僅1萬次回圈的計算量,下面我將遍歷每個學生,然后內層回圈再遍歷每個學生進行笛卡爾積計算,最終計算出每個學生分數最接近的10個學生,
雙重for回圈+最小堆解決需求
data = df.values
length = data.shape[0]
names = data[:, 0]
scores = data[:, 1:]
result = []
# 遍歷取出每一行的資料
for i in range(length):
# 分別取出當前遍歷出來的姓名和成績串列
name, score = names[i], scores[i]
# 用一個最小堆保存最接近的10學生
min_similar_10 = []
for j in range(length):
if i == j:
# 跳過對自己的比較
continue
# 被比較的學生姓名和成績
find_name, find_scores = names[j], scores[j]
# 計算兩個學生成績的距離
sim_value = np.abs(score-find_scores).sum()
# 將被比較的學生和對應距離保存到最小堆中
heapq.heappush(min_similar_10, (find_name, sim_value))
# 取出10個距離最小的學生
min_similar_10 = heapq.nsmallest(10, min_similar_10, key=lambda x: x[1])
name_distance_dict = dict(min_similar_10)
name_similars, distances = list(
name_distance_dict.keys()), list(name_distance_dict.values())
result.append((name, name_similars, distances))
result = pd.DataFrame(result, columns=["姓名", "分數最接近的10個學生", "距離"])
result
最終結果:
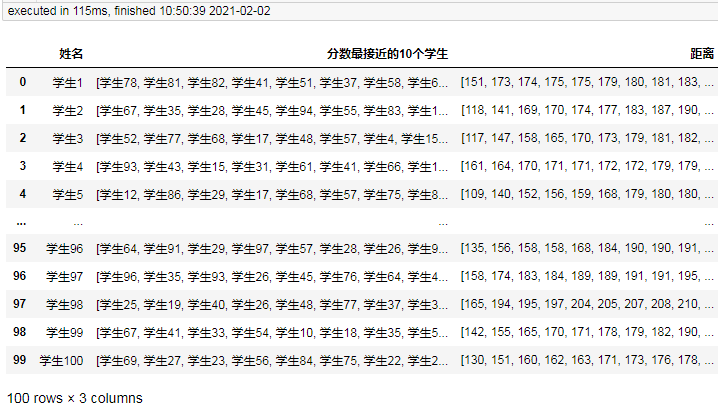
僅耗時120毫秒以內,說明雙重for回圈的演算法在100資料量時,可以順利解決這個問題的,
下面簡單介紹一下最小堆:
堆是資料結構中最常見的一種資料結構,是一個完全二叉樹,最小堆中每一個節點的值都小于等于其子樹中每個節點的值,
具體的原理,學過資料結構的讀者都懂,沒有學過的也不用深究,
上面的代碼中使用最小堆的目的是為了避免排序,采用堆化方式查找N個最小值,基于最小堆的查找,時間復雜度在O(logN)~O(N)之間,
遠比排序的時間復雜度O(nlogN)快,
關于heapq的官方檔案:https://docs.python.org/zh-cn/3/library/heapq.html?highlight=heapq#module-heapq
heapq的實作原始碼:https://github.com/python/cpython/blob/3.9/Lib/heapq.py
如果你對堆的實作原理感興趣,可以參考資料結構學習筆記:
https://datastructure.xiaoxiaoming.xyz/#/16.%E5%A0%86
好景不長,該MOOC網站的管理員后面又希望把歷史班級所有學生的分數最接近的10個學生都找出來,大概有1W以上的學生,用上面的代碼跑了一下,10分鐘左右也跑出了結果,感覺我的代碼處理效果還不錯,
我自己也測驗了一下1萬條測驗資料:
df = pd.read_csv("學生成績_10000.csv", encoding="gbk")
data = df.values
length = data.shape[0]
names = data[:, 0]
scores = data[:, 1:]
result = []
# 遍歷取出每一行的資料
for i in range(length):
# 分別取出當前遍歷出來的姓名和成績串列
name, score = names[i], scores[i]
# 用一個最小堆保存最接近的10學生
min_similar_10 = []
for j in range(length):
if i == j:
# 跳過對自己的比較
continue
# 被比較的學生姓名和成績
find_name, find_scores = names[j], scores[j]
# 計算兩個學生成績的距離
sim_value = np.abs(score-find_scores).sum()
# 將被比較的學生和對應距離保存到最小堆中
heapq.heappush(min_similar_10, (find_name, sim_value))
# 取出10個距離最小的學生
min_similar_10 = heapq.nsmallest(10, min_similar_10, key=lambda x: x[1])
name_distance_dict = dict(min_similar_10)
name_similars, distances = list(
name_distance_dict.keys()), list(name_distance_dict.values())
result.append((name, name_similars, distances))
result = pd.DataFrame(result, columns=["姓名", "分數最接近的10個學生", "距離"])
result
結果:
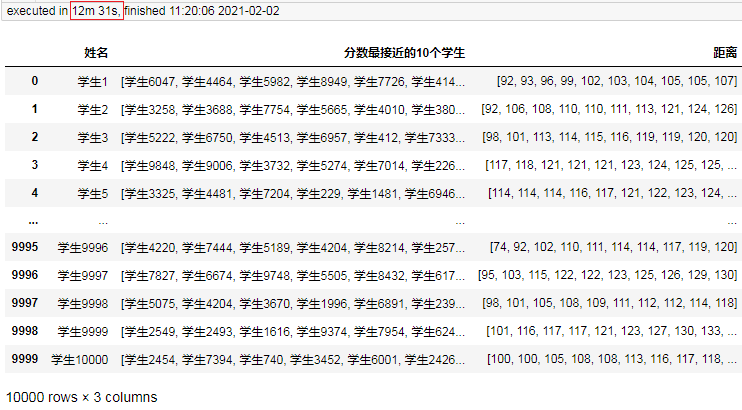
耗時是12.5分鐘,
雖然網站管理員對這個代碼已經滿意,但對于我來說速度還是太慢,要跑這么大的資料量,代碼還是優化一下比較好,于是我使用numpy向量化操作,使程式在2分鐘內對1萬條資料跑出了結果,下面是處理代碼:
使用numpy向量化操作解決需求
考慮到部分讀者沒有看懂最小堆的操作,這次我將分步拆解下面這套代碼的處理邏輯,
首先對本文開頭的100條資料進行測驗,獲取源資料的姓名和分數陣列:
import pandas as pd
import numpy as np
import heapq
df = pd.read_csv("學生成績.csv", encoding="gbk")
data = df.values
length = data.shape[0]
names = data[:, 0]
scores = data[:, 1:]
print(names[:5])
print(scores[:5])
結果:
['學生1' '學生2' '學生3' '學生4' '學生5']
[[71 82 81 84 73 95 62 96 96 87 61 78 79 89 98 80]
[57 91 99 74 93 93 58 74 89 84 63 62 78 57 94 74]
[72 59 76 60 99 71 73 74 72 74 85 79 100 88 80 91]
[71 62 81 80 57 84 92 95 63 59 84 64 90 58 60 75]
[83 62 95 76 57 75 97 57 65 63 84 73 74 59 62 93]]
遍歷第一次就break結束,取出第一個學生用于測驗:
for i in range(length):
name, score = names[i], scores[i]
print(name, score)
break
結果:
學生1 [77 89 60 99 83 80 95 93 94 82 92 93 96 98 70 84]
利用numpy廣播變數的特性一次性求出該學生與所有學生(含自己)的距離:
score_diff = np.abs(scores-score).sum(axis=1)
score_diff
結果:
array([0, 322, 248, 203, 215, 366, 198, 224, 299, 229, 274, 240, 253, 238,
183, 239, 223, 344, 320, 221, 291, 264, 273, 309, 307, 243, 258,
231, 225, 185, 234, 324, 315, 247, 247, 232, 179, 210, 238, 261,
175, 252, 259, 254, 330, 270, 193, 248, 252, 214, 175, 219, 262,
256, 265, 249, 263, 180, 270, 294, 260, 195, 272, 240, 213, 181,
252, 292, 261, 233, 238, 205, 237, 241, 244, 234, 255, 151, 228,
241, 173, 174, 221, 248, 191, 249, 243, 224, 252, 266, 229, 231,
228, 346, 232, 273, 269, 336, 294, 277], dtype=object)
由于上面的距離包含自身,所以先取出距離最短的11個學生的索引,再洗掉自身的索引:
min_similar_index = np.argpartition(score_diff, 11)[:11].tolist()
min_similar_index.remove(i)
min_similar_index
結果:
[77, 80, 81, 40, 50, 36, 57, 65, 14, 29]
根據這10個學生的索引讀取所需要的資料:
name_similars = names[min_similar_index]
distances = score_diff[min_similar_index]
print(name_similars)
print(distances)
結果:
['學生78' '學生81' '學生82' '學生41' '學生51' '學生37' '學生58' '學生66' '學生15' '學生30']
[151 173 174 175 175 179 180 181 183 185]
這樣我們就已經計算出該學生成績最接近的10個學生的姓名和距離,
然后整理一下完整處理代碼:
import pandas as pd
import numpy as np
import heapq
df = pd.read_csv("學生成績.csv", encoding="gbk")
data = df.values
length = data.shape[0]
names = data[:, 0]
scores = data[:, 1:]
result = []
for i in range(length):
name, score = names[i], scores[i]
score_diff = np.abs(scores-score).sum(axis=1)
min_similar_index = np.argpartition(score_diff, 11)[:11].tolist()
min_similar_index.remove(i)
name_similars = names[min_similar_index]
distances = score_diff[min_similar_index]
result.append((name, name_similars, distances))
result = pd.DataFrame(result, columns=["姓名", "分數最接近的10個學生", "距離"])
result
結果:

下面再針對一萬條資料跑一跑:
df = pd.read_csv("學生成績_10000.csv", encoding="gbk")
data = df.values
length = data.shape[0]
names = data[:, 0]
scores = data[:, 1:]
result = []
for i in range(length):
name, score = names[i], scores[i]
score_diff = np.abs(scores-score).sum(axis=1)
min_similar_index = np.argpartition(score_diff, 11)[:11].tolist()
min_similar_index.remove(i)
name_similars = names[min_similar_index]
distances = score_diff[min_similar_index]
result.append((name, name_similars, distances))
result = pd.DataFrame(result, columns=["姓名", "分數最接近的10個學生", "距離"])
result
結果:
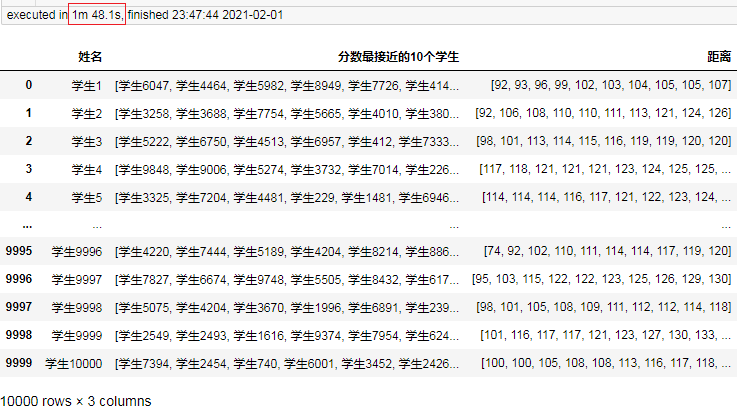
可以看到耗時為1分48秒,相對直接使用笛卡爾積快了很多倍,
使用ball_tree解決需求
雖然上面的優化已經大幅度提升了程式性能,但畢竟仍然需要雙重遍歷O(n^2)時間復雜度的方法,萬一哪天網站要求對10萬個學生進行計算呢?時間又要多翻了幾十倍,耗時要達到好幾個小時,我轉而一想直接用KNN內部的ball_tree來解決這個問題吧,
(關于使用KNN查找最近點的問題可參考很早之前的一篇文章:https://blog.csdn.net/as604049322/article/details/112385553)
先使用10000條學生成績的資料進行測驗,讀取這10000條學生成績資料:
df = pd.read_csv("學生成績_10000.csv", encoding="gbk")
df
結果:
然后取出需要被訓練的資料:
# 取出用于被KNN訓練的資料
data = df.iloc[:, 1:].values
# y本身用于標注每條資料屬于哪個類別,但我們并不使用KNN的分類功能,所以統一全部標注為類別0
y = np.zeros(data.shape[0], dtype='int8')
print(data[:5])
print(y[:5])
結果:
[[ 77 89 60 99 83 80 95 93 94 82 92 93 96 98 70 84]
[ 90 63 72 57 100 85 63 62 67 77 82 68 81 79 100 71]
[ 71 71 82 72 62 70 82 63 92 69 97 97 82 69 63 57]
[ 88 78 88 61 72 61 77 93 94 88 86 95 84 70 73 94]
[ 66 67 59 70 75 67 79 74 57 84 96 67 93 87 58 83]]
[0 0 0 0 0]
創建KNN訓練器,并進行訓練:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1, algorithm='ball_tree', p=1)
knn.fit(data, y)
distance, similar_points = knn.kneighbors(
data, n_neighbors=11, return_distance=True)
distance = distance.astype("int", copy=False)
print(distance[:5])
print(similar_points[:5])
結果:
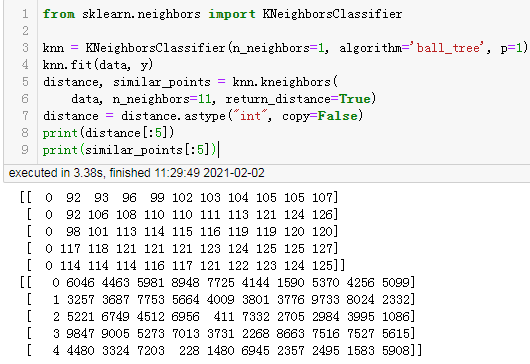
訓練耗時為3.4秒,
n_neighbors是KNN用來分類的引數,我們并不使用分類,將其指定的越小,越能減少無用的計算量,但是這個引數必須比0大,所以我指定為1,
而需求方要求的距離計算公式顯然就等價于曼哈頓距離,所以我將p指定為1,
knn.kneighbors則用來計算最近的點,n_neighbors指定為11是因為結果會包含自身,后面去除自身后結果是10,
由于sklearn最終計算出來的距離是float浮點數型別,而這個需求只可能產生整數距離,所以將其轉換為整數,
上面訓練完就相當于已經計算出了結果,下面我再將結果整理成需要的格式:
names = df['姓名']
result = []
for i, name in names.iteritems():
name_similar_indexs = similar_points[i].tolist()
self_index = name_similar_indexs.index(i)
name_similar_indexs.pop(self_index)
name_similars = names[name_similar_indexs].tolist()
distances = distance[i].tolist()
distances.pop(self_index)
result.append((name, name_similars, distances))
result = pd.DataFrame(result, columns=["姓名", "分數最接近的10個學生", "距離"])
result
結果:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-eYVdNiTA-1612241715190)(求分數最接近的10個學生.assets/image-20210202113318583.png)]
對于10000條資料ball_tree的計算總耗時為5秒左右,可見相對于前面的雙重遍歷的方法速度已經提高了N倍,
關于KD-tree演算法和Ball-tree演算法的原理可參考:
https://www.cnblogs.com/eyeszjwang/articles/2429382.html
https://www.cnblogs.com/lesleysbw/p/6074662.html
https://www.zhihu.com/question/30957691
對4萬條學生模擬資料進行測驗
為了測驗方便,不再用excel來生成資料,而是直接使用python,
python直接生成測驗資料的方法,以生成10條資料為例:
size = 100000
data = np.c_[np.arange(1, size+1).reshape((-1, 1)),
np.random.randint(56, 101, size=(size, 16))]
df = pd.DataFrame(data, columns=["姓名", "Python", "C/C++", "Java", "Scala", "資料結構", "離散數學",
"計算機體系結構", "編譯原理", "計算機網路", "資料庫原理", "計算機圖形學",
"自然語言處理", "嵌入式系統及應用", "網路資訊與安全", "計算機視覺", "人工智能"])
df["姓名"] = "學生"+df["姓名"].astype(str)
df
結果:
然后使用上面相同的代碼分別測驗1w條、2w條、3w條、…、10w條:

1萬條耗時5.3秒,
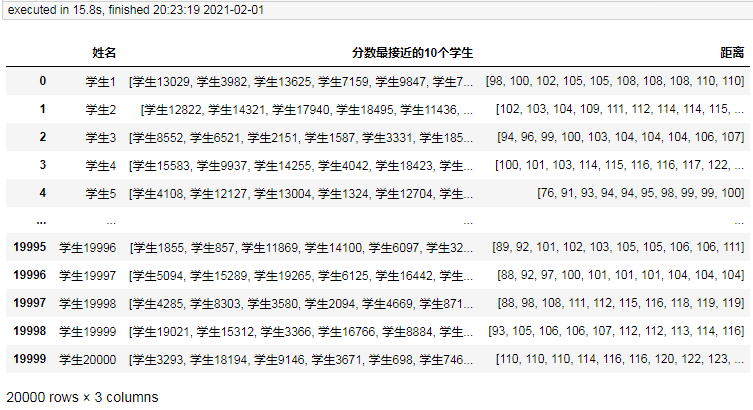
2萬條耗時15.8秒,
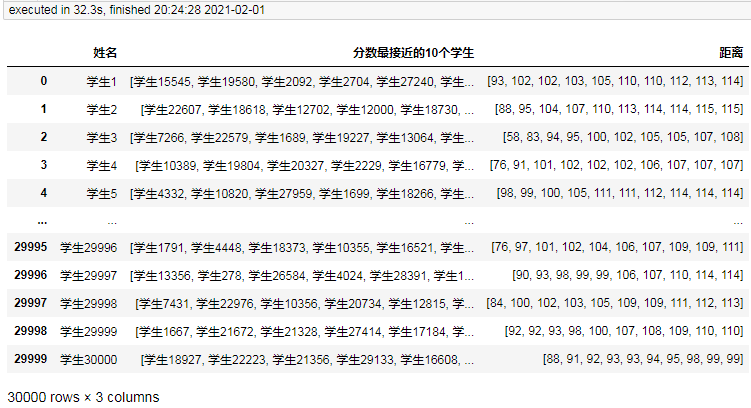
3萬條耗時32.3秒,
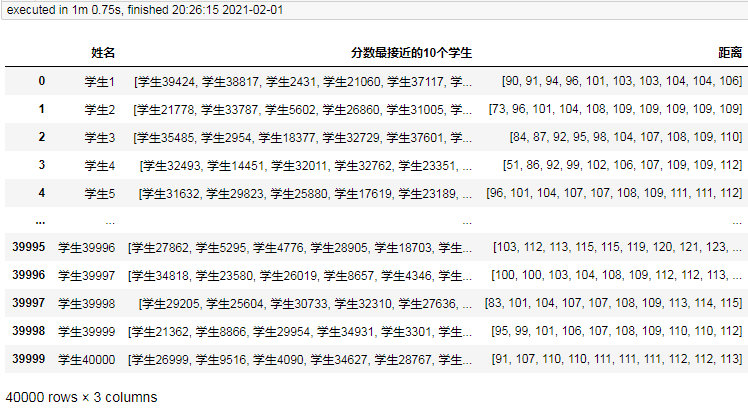
4萬條耗時60.75秒,
預估10萬條資料的耗時
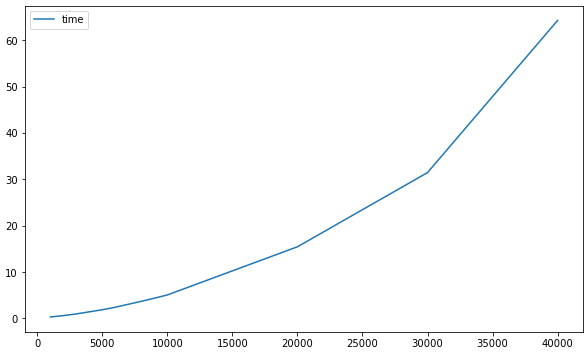
這時間增長趨勢好像也不是線性增長而是指數增長,下面先就記錄一下多少條記錄時耗時多久吧:
import pandas as pd
import numpy as np
import time
from sklearn.neighbors import KNeighborsClassifier
times = {}
for size in np.r_[np.arange(1000, 10001, 1000), np.arange(20000, 60001, 10000)]:
data = np.c_[np.arange(1, size+1).reshape((-1, 1)),
np.random.randint(56, 101, size=(size, 16))]
df = pd.DataFrame(data, columns=["姓名", "Python", "C/C++", "Java", "Scala", "資料結構", "離散數學",
"計算機體系結構", "編譯原理", "計算機網路", "資料庫原理", "計算機圖形學",
"自然語言處理", "嵌入式系統及應用", "網路資訊與安全", "計算機視覺", "人工智能"])
df["姓名"] = "學生"+df["姓名"].astype(str)
start_time = time.perf_counter()
# 取出用于被KNN訓練的資料
data = df.iloc[:, 1:].values
# y本身用于標注每條資料屬于哪個類別,但我并不使用KNN的分類功能,所以統一全部標注為類別0
y = np.zeros(data.shape[0], dtype='int8')
knn = KNeighborsClassifier(n_neighbors=1, algorithm='ball_tree', p=1)
knn.fit(data, y)
distance, similar_points = knn.kneighbors(
data, n_neighbors=11, return_distance=True)
distance = distance.astype("int", copy=False)
names = df['姓名']
result = []
for i, name in names.iteritems():
name_similar_indexs = similar_points[i].tolist()
self_index = name_similar_indexs.index(i)
name_similar_indexs.pop(self_index)
name_similars = names[name_similar_indexs].tolist()
distances = distance[i].tolist()
distances.pop(self_index)
result.append((name, name_similars, distances))
result = pd.DataFrame(result, columns=["姓名", "分數最接近的10個學生", "距離"])
take_time = time.perf_counter()-start_time
print(f"{size}條資料耗時{take_time:.2f}秒")
times[size] = take_time
time_df = pd.DataFrame.from_dict(times, orient='index', columns=["time"])
結果:
1000條資料耗時0.29秒
2000條資料耗時0.59秒
3000條資料耗時0.98秒
4000條資料耗時1.40秒
5000條資料耗時1.97秒
6000條資料耗時2.44秒
7000條資料耗時3.00秒
8000條資料耗時3.74秒
9000條資料耗時4.41秒
10000條資料耗時5.23秒
20000條資料耗時15.92秒
30000條資料耗時31.75秒
40000條資料耗時64.25秒
50000條資料耗時132.26秒
60000條資料耗時220.87秒
從這走勢來看有點像二次函式或冪次函式,我們假設這是一個二次函式然后使用numpy擬合這條曲線,并預估10萬資料的耗時:
from numpy import polyfit, poly1d
import matplotlib.pyplot as plt
%matplotlib inline
x = np.arange(1000, 100001, 1000)
y = poly1d(polyfit(time_df.index, time_df.time, 2))
plt.figure(figsize=(10, 6))
plt.plot(time_df.index, time_df.time, 'rx')
plt.plot(x, y(x), 'b:')
plt.show()
print(f"10萬條資料預計耗時{y(100000):.2f}秒")
結果:
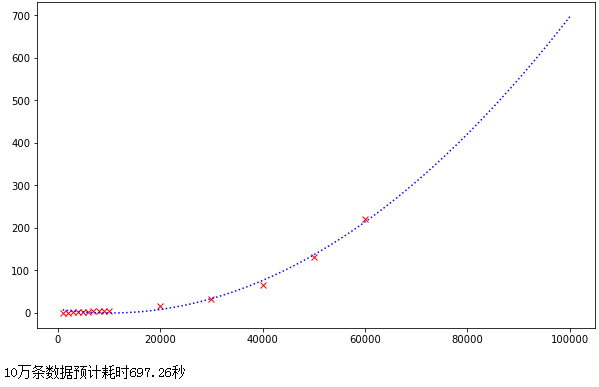
預計耗時11分鐘,
不過實際測驗了一下,12分鐘也并沒有出結果,說明曲線擬合的效果還不是太準,
認真觀察原始資料(紅色點)和擬合曲線(藍色線),可能這個曲線實際并不是二次函式,而是三次以上的函式或冪次函式,下面使用3次函式進行擬合:
from numpy import polyfit, poly1d
import matplotlib.pyplot as plt
%matplotlib inline
x = np.arange(1000, 100001, 1000)
y = poly1d(polyfit(time_df.index, time_df.time, 3))
plt.figure(figsize=(10, 6))
plt.plot(time_df.index, time_df.time, 'rx')
plt.plot(x, y(x), 'b:')
plt.show()
print(f"10萬條資料預計耗時{y(100000):.2f}秒")
結果:
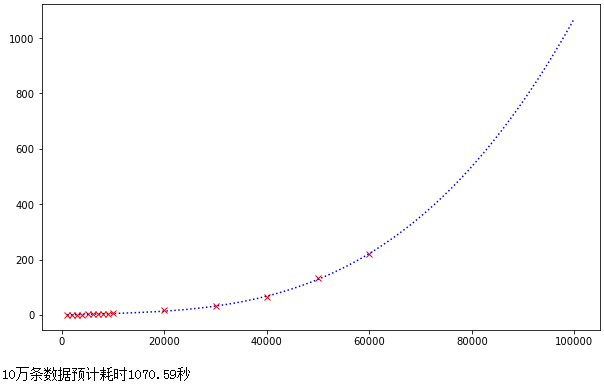
預估耗時為17分鐘,
實際耗時呢?
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
size = 100000
data = np.c_[np.arange(1, size+1).reshape((-1, 1)),
np.random.randint(56, 101, size=(size, 16))]
df = pd.DataFrame(data, columns=["姓名", "Python", "C/C++", "Java", "Scala", "資料結構", "離散數學",
"計算機體系結構", "編譯原理", "計算機網路", "資料庫原理", "計算機圖形學",
"自然語言處理", "嵌入式系統及應用", "網路資訊與安全", "計算機視覺", "人工智能"])
df["姓名"] = "學生"+df["姓名"].astype(str)
# 取出用于被KNN訓練的資料
data = df.iloc[:, 1:].values
# y本身用于標注每條資料屬于哪個類別,但我并不使用KNN的分類功能,所以統一全部標注為類別0
y = np.zeros(data.shape[0], dtype='int8')
knn = KNeighborsClassifier(n_neighbors=1, algorithm='ball_tree', p=1)
knn.fit(data, y)
distance, similar_points = knn.kneighbors(
data, n_neighbors=11, return_distance=True)
distance = distance.astype("int", copy=False)
names = df['姓名']
結果:
訓練耗時13分鐘,
from tqdm.notebook import tqdm
result = []
pbar = tqdm(total=size)
for i, name in names.items():
pbar.update(1)
name_similar_indexs = similar_points[i].tolist()
self_index = name_similar_indexs.index(i)
name_similar_indexs.pop(self_index)
name_similars = names[name_similar_indexs].tolist()
distances = distance[i].tolist()
distances.pop(self_index)
result.append((name, name_similars, distances))
pbar.close()
result = pd.DataFrame(result, columns=["姓名", "分數最接近的10個學生", "距離"])
result
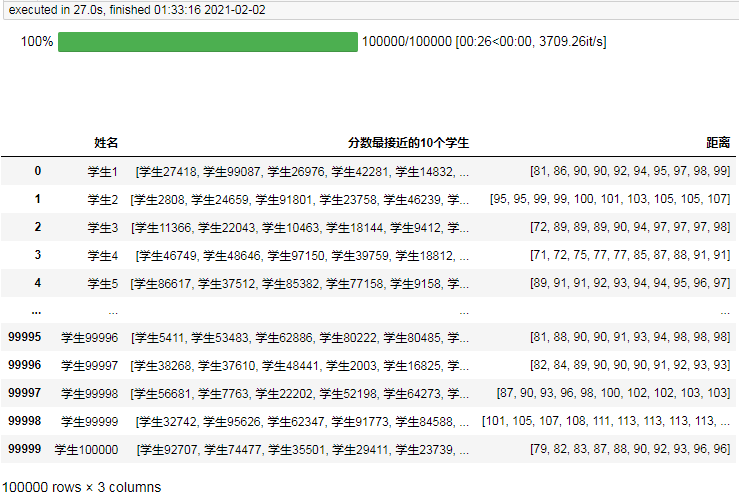
整理結果耗時半分鐘,實際耗時是14分鐘,
雖然14分鐘也比較慢,但相對前面的笛卡爾積的演算法需要耗時好幾小時而言已經大幅度提升程式計算性能,節約了計算時間,
總結
今天我向你演示了如何使用最小堆和numpy來快速計算每個學生分數最接近的10個學生,可以看到在資料量小于一萬時,這種笛卡爾積的演算法還可以接受,但一旦達到2萬以上,基本上就慢的難以忍受了,所以我使用ball_tree來計算這個距離,1W資料量僅耗時5秒,
但是當資料量達到5萬以上時,ball_tree也有點慢了,但也相對笛卡爾積的演算法還是快了很多,
最后,我使用numpy擬合時間曲線,在二次函式的擬合下預估10w資料量時ball_tree的耗時為12分鐘,三次函式的擬合下是17分鐘,而實際測驗的結果是14分鐘,介于2者之間,
歡迎下方留言或評論,分享你的看法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/255634.html
標籤:AI