文章目錄
- 國外
- 1.加州大學伯克利分校和 Google 研究院合作發布文章,推出 BoTNet,模型在ImageNet基準測驗中具有84.7%top-1精度,
- 2.哈佛大學利用傳感器和區域相互作用實作 3D 魚群控制
- 3.谷歌提出生命組織框架
- 4.微軟、加州大學莫塞德分校提出 ZoRO-Offload 可以在單個 GPU 訓練 130 億引數的深度學習模型
- 5.DeepMind 專家總結 2020 機器學習和自然語言處理亮點
- 1).大規模、高效率模型
- 2).增強檢索
- 3).少樣本學習
- 4).對比學習
- 5).超越準確率進行評估
- 6).大型語言模型的實踐落地問題
- 7).多語言NLP
- 8).Image Transformer
- 9).機器學習在科學當中的應用
- 10).強化學習,
- 國內
- 1.在Google 等設定的大規模跨語言泛化的多語言多任務基準 XTREME 當中,百度 1 月 1 日 提交的 ERNIE-M 排名第一,
- 2.美團、上交大等:魯棒的可微分神經網路搜索 DARTS-
- 3.北大教授朱松純創立暗物智能公司獲5億融資
- 4.依圖科技開源 T2T-ViT 首次全面超過 ResNet
- 5.類腦智能芯片研究中心黃如院士團隊多篇學術論文入選第66屆IEDM
國外
1.加州大學伯克利分校和 Google 研究院合作發布文章,推出 BoTNet,模型在ImageNet基準測驗中具有84.7%top-1精度,
【標題】Bottleneck Transformers for Visual Recognition
【時間】2021-1-27
【來源】伯克利大學、Google 研究院
【鏈接】https://arxiv.org/abs/2101.11605
【內容摘要】
團隊推出的 BoTNet 是一種功能但概念簡單的架構,將自注意力納入了多種計算機視覺任務,僅在 ResNet 三個瓶頸模塊當中使用了全注意力替換空間卷積,該方法在市里分割和物件檢測上取得了良好實作,改善了基線,減少了引數,同時具有低延遲成本的特點,在使用 Mask-CNN 框架情況下,BoTNet 在 COCO 實體分段基準上實作了 44.4% 的 MASK AP 和 49.7% 的 Box AP,超過了先前在 COCO 驗證集上的模型結構,在 ImageNet 基準測驗中,該設計具有 84.7% 精度的強大性能,
2.哈佛大學利用傳感器和區域相互作用實作 3D 魚群控制
【標題】Implicit coordination for 3D underwater collective behaviors in a fish-inspired robot swarm
【時間】2021-1-13
【來源】Florian Berlinger,Melvin Gauci, ProfileRadhika Nagpal
【鏈接】https://robotics.sciencemag.org/content/6/50/eabd8668?rss=1
【內容摘要】
魚群可成千上萬和諧地聚集游動,不管是遷移還是躲避捕食者,規避動態動作,都表現出令人印象深刻的集體行為,這種復雜的三維行為來自對鄰近個體的觀察,相比之下,許多水下機器人使用的是集中的水上通信,協調復雜度有限,本文僅使用產生和感測藍光介導的隱式通信,展示了復雜而動態的三維聚集行為,
3.谷歌提出生命組織框架
【標題】SELF-ORGANIZING INTELLIGENT MATTER: A BLUEPRINT FOR AN AI GENERATING ALGORITHM
【時間】2021-1-14
【來源】DeepMind Karol Gregor, Frederic Besse
【鏈接】https://arxiv.org/pdf/2101.07627.pdf
【內容摘要】
來自 DeepMind 的研究者提出了一種人工生命框架,旨在促進智能生物出現,沒有明確的代理概念,存在由原子元素組成的環境,這些元素包含神經操作,通過資訊交換和環境進行類似物理的規則互動,
文章討論了進化程序如何使得多原子元素組成新的生物體的機制,同時討論如何構成通用AI 生成演算法的基礎,目前已經創建了系統的一個版本,總結了系統的核心屬性,有包含神經網路的元素,這些元素可以互動、通信、形成更大單元,從而有效地實作更大的網路,這里有機體和機器之間沒有區別,元素可以寫入其他元素,可以復制,可以寫入其他資訊來創造有用的機器,或者創造出全新的機器,這些機器既可以創造新的“個體”也可以是新的大腦創造出更好的演算法,
4.微軟、加州大學莫塞德分校提出 ZoRO-Offload 可以在單個 GPU 訓練 130 億引數的深度學習模型
【標題】ZeRO-Of?oad: Democratizing Billion-Scale Model Training
【時間】2021-1-18
【來源】Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He
【鏈接】https://arxiv.org/pdf/2101.06840.pdf
【內容摘要】
大規模模型訓練往往需要昂貴的 GPU 集群等,ZeRO-Offload 在單個 GPU 上就可以實作 130 億引數模型的訓練,和 PyTorch 之類的框架相比,它的大小增加了 10 倍,而無需進行模型更改和犧牲效率,她通過將資料卸載到 CPU 上進行大型訓練,只在最大程度減少 GPU 網站的資料移動同時降低 CPU 計算時間,最大程度上節省 GPU 的記憶體,結果可以在單個 N 卡 V100 GPU 上針對 10B 引數是模型實作 40 TFlops/GPU ,而對 1.4B 引數模型,僅使用 PyTorch 可以實作 30Tf,在記憶體沒有用完的情況即可進行最大的訓練,ZeRO-Offload 還只在可用多個 GPU 上擴展,在 128 個 GPU 上提供接近線性的加速,
5.DeepMind 專家總結 2020 機器學習和自然語言處理亮點
【標題】ML and NLP Research Highlights of 2020
【時間】2021-1-19
【來源】Sebastian Ruder
【鏈接】https://ruder.io/research-highlights-2020/
【內容摘要】
來自 DeepMind 的專家 Ruder 針對自己興趣總結了在 2020 年機器學習和自然語言處理作業中的亮點,有以下十項:
1).大規模、高效率模型
發生了什么?2020 年我們見證了更大的語言和對話模型,例如 Turing-NLG、BST、GPT-3 等等,而研究人員也越來越注意到這些模型的價格和能耗并致力于縮小模型的作業,例如通過修剪、量化和蒸餾壓縮等方式,它為什么重要?因為擴大模型規模能夠突破當前模型的功能范圍,而它也必須搞笑,通過壓縮大模型會導致更加強大和高效的模型出現,下一步是什么呢?基于人們對于增長效率的興趣,不光是模型的性能和引數數量的報告,未來報告能效也會越來越普遍,這對于全面評估模型具有重要意義,
2).增強檢索
大型模型已經顯示出從預訓練的資料中獲得令人驚訝的知識,這給他們回答問題帶來了方便,不過這些知識隱式存盤在模型引數中效率很低,并且需要更大的模型來保留資訊,最近的方法聯合訓練和檢索和大型語言模型,從而在知識密集型 NLP 任務和語言建模當中有良好表現,這些方法的優點是將檢索直接繼承到語言模型預訓練當中,從而減輕事實回憶,專注 NLP 當中更具挑戰性的方面,它為什么重要呢?檢索可以將事實正確性和真實性、生成文本的相關性和構成兩方面的優點結合起來,下一步將通過直接提供預測資料幫助系統更容易解釋,
3).少樣本學習
目前我們處于可以用幾十個實體演示給定任務的階段,快速學習的一個非常自然的范例就是將任務重構成語言建模,代表性的就是 GPT-3 的背景關系學習方法,不過這種設定還有局限性,需要龐大的模型+模型無需現有知識進行更新+模型可使用知識量受到背景關系視窗限制,且需要手工制作,近期的作業和可控神經文本生成的廣泛領域相關,快速學習可以讓模型快速適應多任務,不過每次更新所有引數是一種浪費,最好進行區域更新,少樣本學習僅僅通過幾個示例就能像模型講授任務,減輕了機器學習和自然語言處理的入門障礙,也增加了資料收集的空間,未來將在提高一次性性能領域進行改進,
4).對比學習
對比學習,從否定樣本當中學習區分優劣樣本的能力,例如從否定采樣和噪聲當中對比估計是表示學習和子監督學習的主要內容,近期,對比學習在計算機視覺和語音的子監督表示學習當中越來越受歡迎,資料增強對于對比學習來說至關重要,這也可以解釋為什么資料增項不普遍的自然語言處理當中進行無監督對比學習并不成功,它不會嘗試使類中的所有特征相似,但會保留實體資訊,語言建模當中的但標簽和模型輸出對數之間的交叉熵目標存在局限性,而對比學習則可以幫助完善這一不足,下一步,對比學習和隱蔽語言建模將是我們學習更加豐富和強大的表示形式,
5).超越準確率進行評估
自然語言處理很多模型已經實作了超人的性能,但是我們任務的簡單性能指標并不能包含模型的局限性,該領域有兩個關鍵的主題:1.精選當前模型難以實作的示例;2.超越諸如準確性之類的簡單指標,進行更加細分的評估,對前者的方法是在資料集創建之時使用對抗過濾,過濾掉當前模型正確的實體,關于第二點的方法在本質上相同,不過不是針對特定示例,而是用示例來探查感興趣的任務共有的現象,機器學習模型取得有意義的進步的同時,我們也要了解它是否會導致某些錯誤和無法捕獲的現象,通過對模型進行細粒度診斷,將更容易識別模型的確行并提出解決方案,
6).大型語言模型的實踐落地問題
和 2019 年相比,語言模型分子側重于此類模型捕獲的語法、語意和世界知識,但是微調的程序中發現容易受到后門攻擊,攻擊者可以操縱模型,眾所周知,經過預訓練的模型可以捕獲有關受保護屬性(例如性別)的偏見,大型預訓練模型受到了很多機構的訓練,并在實際場景當中得到積極部署,這里我們不僅要意識到他們的偏見,還要了解可能帶來的不良后果,下一步應該從開發程序中就將偏見與公平等問題納入考慮問題當中,
7).多語言NLP
世界各地開發者們采用不同的語言構建大規模模型,出現了越來越多的語言通用基準,其中有兩份檔案給了很大的啟發,它們強調了使用英語之外語言的緊迫性,同時警告不要將語言社區及資料視為商品,對多語言進行自然語言處理是一種很好的挑戰,并且能夠給社會帶來巨大的影響,下一步應該確立最具挑戰設定的模型并確定哪些情況下構成當前模型的失敗,
8).Image Transformer
Transformer 在自然語言處理當中取得了極大的成功,但是在計算機視覺領域成就不高,卷積神經網路依然占據主導,與卷積神經網路和回圈神經網路相比 transformer 的偏置更小,盡管在理論上不如回圈神經網路,但是基于足夠的資料和鉤摹將會勝過其他對手,它們將特別適用于有足夠的計算和資料用于無人監管的預訓練的情況,在小規模的設定當中,卷積神經網路依然是首選,
9).機器學習在科學當中的應用
AlphaFold 在蛋白質折疊挑戰賽當中展示了驚人的突破,此外,機器學習在自然可選當中還有其他的顯著發展,例如降水預報、神經網路比商業代數系統更好地了解微分方程,平流層氣球導航等等,對于目前新冠病毒的傳播預測也起到了重要的作用,自然科學可以說是機器學習最有影響力的應用領域,改善和生活相關的方方面面,對世界產生了深遠的影響,
10).強化學習,
單一的強化學習 Agent 首次在 57 個Atari 游戲當中取得了超人性能,該 Agent 的多功能性來自于神經網路,可以使其在探索性策略和剝削策略當中來回轉換;另一個成果就是 MuZero 的發展,它預測了對于準確規劃最重要的環境方面,在沒有任何游戲動態知識的情況下達到了先進的性能,強化學習演算法有許多的實際意義,通過實作更好的環境規劃、建模和動作預測,對領域中基本演算法的改進都會產生很大的影響,
國內
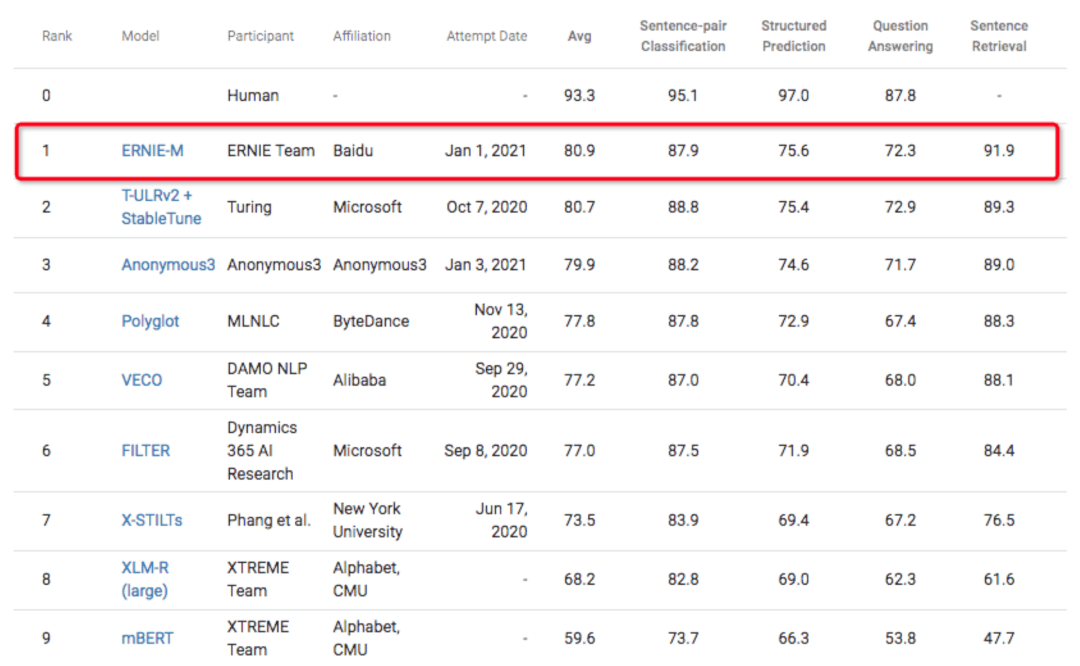
1.在Google 等設定的大規模跨語言泛化的多語言多任務基準 XTREME 當中,百度 1 月 1 日 提交的 ERNIE-M 排名第一,
【時間】2020-1-26
【來源】百度研究院
【鏈接】http://research.baidu.com/Blog/index-view?id=151;https://arxiv.org/pdf/2012.15674.pdf
【內容摘要】
研究表明,經過預訓練的跨語言模型在下游語言任務上表現出色,這種改進源于學習了大量單語言和并行語料庫,團隊提出了一種新的訓練方法 ERNIEM 使得模型將多語言表示和單語言語料庫對齊,打破并行語料庫大小對模型性能的束縛,將反向翻譯的思想整合到預訓練程序當中,實驗表明,該方法優于現有的跨語言模型,在各種跨語言下游任務上提供了最新的結果,
ERNIE-M 可以理解 96 種語言,即使在資料稀疏的語言上也可以提升模型的跨語言傳遞性,
2.美團、上交大等:魯棒的可微分神經網路搜索 DARTS-
【標題】DARTS-: Robustly Stepping out of Performance Collapse Without Indicators
【時間】2021-1-26
【來源】中科院計算所/美團
【鏈接】https://arxiv.org/abs/2009.01027
【內容摘要】
可微分架構搜索(DARTS)是神經網路架構搜索(NAS)中最流行的方法之一,但是它長期存在性能不穩定的問題,為了加固這種方法,需要從惡化的結果中尋找線索,通過使用各種指標作為性能崩潰前的搜索信號,但是對閾值的設定有極高的要求,本文采用了更加直接的方式來解決問題,利用輔助跳過連接對于其他候選操作具有明顯優勢,可以創建公平競爭,在嚴格控制的設定下降低了 3 倍搜索成本,優于最新的 RobustDARTS,大大提升了魯棒性,
3.北大教授朱松純創立暗物智能公司獲5億融資
【時間】2021-1-28
【鏈接】https://www.dm-ai.cn/news/%e9%87%8d%e7%a3%85%ef%bc%81%e6%9a%97%e7%89%a9%e6%99%ba%e8%83%bd%e5%ae%8c%e6%88%905%e4%ba%bf%e5%85%83a%e8%bd%ae%e8%9e%8d%e8%b5%84/
【內容摘要】
暗物智能科技已于2020年年中完成5億元人民幣的A輪融資,本輪融資由賽領資本和吉富創投共同領投,聯想創投、廣州基金、將門創投、花城創投跟投,
暗物智能由全球著名計算機視覺專家、統計與應用數學家、人工智能專家朱松純教授于2017年創辦,公司基于朱松純提出的“小資料、大任務”技術范式,以人機互動與跨領域融合為主攻方向,致力于打造新一代基于強認知的人工智能技術平臺,并通過與教育、新零售等垂直行業深度融合,構建以強認知AI為核心的產業生態,
4.依圖科技開源 T2T-ViT 首次全面超過 ResNet
【標題】Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
【時間】2021-1-28
【來源Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Francis EH Tay, Jiashi Feng, Shuicheng Yan
【鏈接】https://arxiv.org/abs/2101.11986
【內容摘要】
針對ViT的特征多樣性、結構化設計等進行了更深入的思考,提出了一種新穎的Tokens-to-Token機制,用于同時建模影像的區域結構資訊與全域相關性,同時還借鑒了CNN架構設計思想引導ViT的骨干設計,
用于影像分析的 Vit(Vision Transformers)在中型資料集例如ImageNet 上從頭訓練時,性能不如 CNN,分析認為因為輸入影像的簡單標記化無法相對相鄰像素之間的重要區域結構建模,另外 ViT 的冗余注意力骨干網設計導致固計算的功能有限,為了克服這些限制,文章提出了 T2T-ViT 引入了逐層 Tokens 轉換,通過遞回將相鄰的 Tokens 聚合為T2T,由 CNN 架構退隊的具有深窄結構的高校主干用于視覺轉換器,在ImageNet 上訓練時,可以將原始的ViT 引數和mac 減少 200%,實作 2.5% 的性能提升,和 ResNet50 相當大小的 T2T-ViT 在 ImageNet 上也有 80.7% 的精度,
5.類腦智能芯片研究中心黃如院士團隊多篇學術論文入選第66屆IEDM
【來源】北京大學
【鏈接】http://www.ai.pku.edu.cn/info/1086/1772.htm
【內容摘要】
由于新冠病毒疫情的影響,第66屆國際電子器件大會(IEDM)于2020年12月12日至18日首次采取線上會議形式,也為這個歷史悠久的頂級學識訓議帶來不一樣的感受,在本屆IEDM上,北京大學黃如院士團隊發表了4篇高水平學術論文,研究成果覆寫了先進邏輯器件、神經形態器件、神經網路硬體、智能傳感器等多個領域,這也是北京大學微納電子研究院連續14年在IEDM大會上發表論文,
阻變器件是后摩爾時代構建新型存算一體及類腦芯片、突破馮?諾依曼體系結構瓶頸的關鍵電子器件技術之一,但阻變器件的非理想效應以及高密度集成帶來的熱效應會相互耦合,成為阻變器件在存盤及神經形態計算應用中的關鍵挑戰,蔡一茂教授、黃如院士課題組系統研究了阻變器件非理想效應的物理機制,提出了準確描述多種非理想效應的集約模型,建立了能夠綜合評估器件技術、陣列拓撲及演算法設計的跨層次驗證平臺,掌握了非理想效應和熱串擾對存盤及神經形態計算應用的影響,為器件-陣列-演算法的協同優化設計提供了重要指導,蔡一茂教授應邀作了題為《Technology-Array-Algorithm Co-Optimization of RRAM for Storage and Neuromorphic Computing: Device Non-idealities and Thermal Cross-talk》的特邀報告,微納電子學系2017級博士研究生喻志臻為共同第一作者,蔡一茂教授、王宗巍助理研究員和黃如院士為論文的通訊作者,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/256322.html
標籤:AI
上一篇:AI 告別炒作,Java 0 增長,2021 技術路在何方?
下一篇:Hybrid App實作原理