模型的檢驗
1.用留出法(80%訓練集,20%測驗集)拆分資料,用訓練集訓練邏輯回歸模型,并在測驗集資料上驗證模型的效果(以AUC為標準),
一個模型很重要的是其在新樣本的預測能力,因此只在原資料集上回測檢驗模型評估其擬合能力往往是不夠的,還需要評估模型的泛化能力,就是評估模型對新樣本(測驗集)的預測能力,這里使用留出法將資料分為訓練集和測驗集,將800條資料用來訓練模型,并將得到的模型在200條資料的測驗集上進行預測,進行模型精度的評價,得到對應的ROC曲線和AUC值,
#繪制測驗集的ROC曲線
lw = 2
plt.figure(figsize=(5,5),dpi=200)
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_prob, pos_label=1)
auc=round(metrics.roc_auc_score(y_test, y_prob),3)
plt.plot(fpr, tpr, color='steelblue',lw=lw, label='ROC curve (Area & Auc = %0.2f)' % auc) ###假正率為橫坐標,真正率為縱坐標做曲線
plt.plot([0, 1], [0, 1], color='#8b8b8b', lw=lw, linestyle='--')
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC_Curve')#Receiver operating characteristic example
plt.legend(loc="lower right")
plt.show()
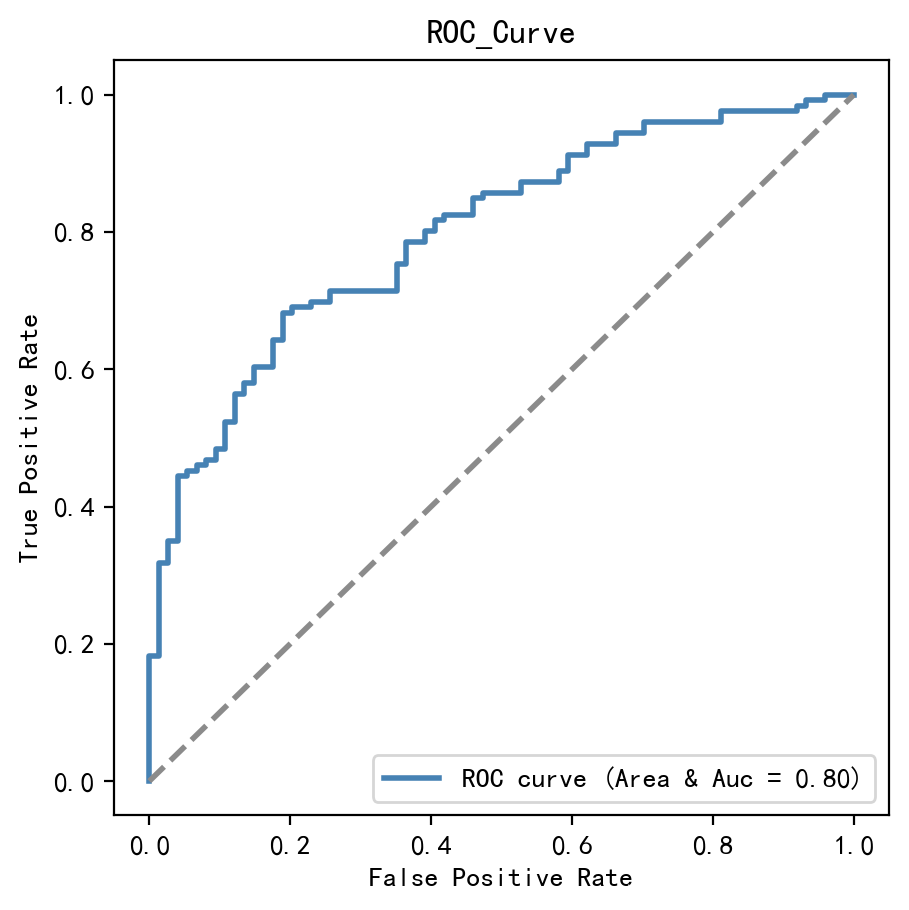
如圖ROC曲線圖,ROC曲線橫軸為正確預測的比率(TPR),縱軸為錯誤預測的比率(FPR),根據該模型ROC曲線上下的面積,計算模型的AUC值約為0.80,又因在測驗集預測得出的結果,可以初步說明該模型在新樣本(預測)的預測能力較強,模型的泛化能力較強,但經過多次單獨建立模型,發現相同資料得到AUC值并不完全一樣,有時0.7有時0.8,可見使用留出法建立模型的AUC值不是特別穩定,使用留出法建立模型的ROC曲線沒有在原資料回測模型光滑,一個得到200個預測結果,一個得到1000條預測結果,ROC曲線變得不光滑的原因很可能是測驗集樣本量變少且模型特征分布不均勻,導致TPR和FPR在不同區間變化不穩定,
2.用15折交叉驗證法拆分資料,每次用訓練集訓練邏輯回歸模型,并在測驗集資料上驗證模型模型的效果(以AUC為標準)
在檢驗模型對新樣本(測驗集)預測能力的程序中,可以使用n折交叉驗證的方法檢驗模型的過擬合和欠擬合現象,在資料和模型其他變數保持不變的情況下,按照資料的索引劃分了十五次訓練集和測驗集,并單獨用各份資料的訓練集訓練模型并在測驗集上進行預測,完成了對該資料集的15折交叉驗證,計算每次試驗的AUC值后得到下表:
15折交叉驗證AUC: 0.862 0.85 0.846 0.804 0.776 0.774 0.745 0.739 0.731 0.719 0.705 0.659 0.645 0.628
在該資料集的15折交叉驗證中,十五個模型AUC值的均值約為0.7521,模型AUC值的最大值約為0.862,最小值約為0.628,極差為0.234,由于AUC均值和最值有較大出入,可以初步預估AUC值約為0.862的模型很可能存在一定的過擬合現象,AUC值約為0.628的模型很可能存在一定的欠擬合現象,模型經過15折交叉驗證所產生AUC值的極差較大,可見該資料集的資料的特征分布不是十分均勻,其訓練集和測驗集的劃分在一定程度上影響該模型的精度AUC值,影響模型對新樣本的預測能力,因此需要根據15折交叉驗證的結果進行模型的選擇或優化,最大程度減少模型的過擬合或欠擬合現象,
3.將題1和2的結果與TASK5的結果對比并說明,
使用留出法對資料集進行一次劃分得到模型的AUC值約為0.80,而15折交叉驗證15次劃分資料集得到模型的AUC均值為0.752,15折交叉驗證的模型精度低于留出法的模型精度,可以預估題1留出法得到的模型存在一定的過擬合現象,如果以題1資料集劃分所建立的模型為后續模型優化和業務結論的基礎,就需要處理模型的過擬合現象,使用懲罰項降低模型的復雜程度,降低模型過擬合的可能性,
為了更好的讓留出法所建立模型和15折交叉驗證進行對比,在模型的建立上進行進一步分析,在資料和其他變數保持不變的情況下,進一步繪制出15折交叉驗證的ROC曲線:
from sklearn.model_selection import KFold
k_fold=KFold(n_splits=15)
i=1
AUC= []
plt.figure(figsize=(17,17),dpi=200)
for train_index, test_index in k_fold.split(data_new):
logit=sm.Logit(data_new.loc[train_index,'是否按期還款_1'], data_new.loc[train_index,train_cols])
result=logit.fit()
y_prob=result.predict(data_new.loc[test_index,train_cols])
auc=metrics.roc_auc_score(data_new.loc[test_index,'是否按期還款_1'], y_prob)
plt.subplot(5,5,i)
fpr, tpr, thresholds = metrics.roc_curve(data_new.loc[test_index,'是否按期還款_1'], y_prob, pos_label=1)
auc1='AUC:'+str(round(auc,3))
plt.plot(fpr, tpr,linewidth=2.5) #繪制ROC曲線圖
plt.plot([0, 1], [0, 1], color='#8b8b8b', lw=2, linestyle='--')
plt.text(x=0.3,y=0.45,s=auc1,fontsize=15)#
plt.title("第"+str(i)+"次實驗的ROC曲線")
i+=1
AUC.append(auc)
plt.show()
print("經過15折交叉驗證,邏輯回歸的AUC的均值為:%0.4f"%(sum(AUC)/len(AUC)))
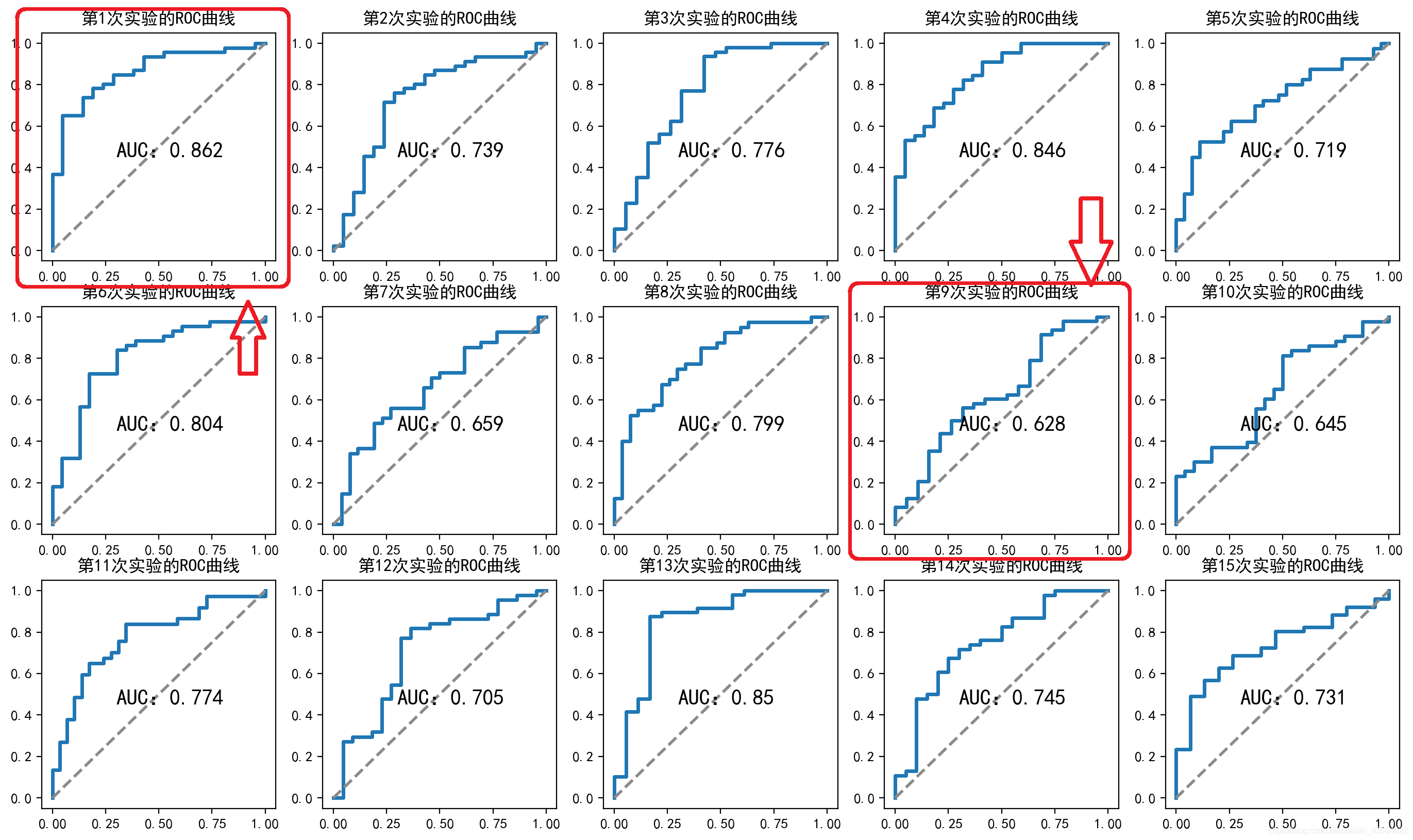
圖2:15折交叉驗證ROC曲線圖
如圖2交叉驗證ROC曲線圖,15折交叉驗證中每次試驗得到的ROC曲線比留出法模型的ROC曲線更不光滑,一是15折試驗是將資料分成了15份每份,每份預測得66個結果少于留出法處理后建模預測得到的200條結果,也因此可以很明顯地看出資料集的特征分布不均勻現象,比如第一個紅框所指模型很有可能存在過擬合現象,第二個紅框很可能存在欠擬合現象,
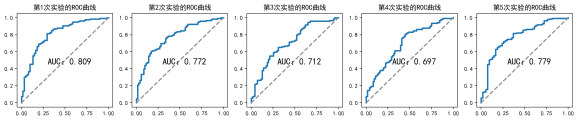
圖3:5折交叉驗證ROC曲線圖
如5折交叉驗證ROC曲線圖,留出法建立的模型是將訓練集和測驗集按照8:2的比例進行分開,也就相當于五折交叉驗證中偶然選擇了隨機的一組資料建模,其AUC值可能是0.8,0.7或0.6,因為資料特征分布不均勻,有的資料訓練出來的模型會產生過擬合現象,有的模型會出現欠擬合的現象,再次說明了在該資料集建模的程序中,訓練集和測驗集的劃分在一定程度上影響該模型的精度AUC值,影響模型對新樣本的預測能力,也再次說明僅僅是劃分一次訓練集和測驗集的模型是不具有強說服力的,需要根據15折交叉驗證的結果對進行模型的選擇或優化,就需要使用懲罰項降低模型的擬合程度,降低模型的復雜程度,
4.模型驗證的總結:
如果所選模型AUC遠高于交叉驗證得到的均值,存在過擬合現象,就需要使用懲罰項降低模型的擬合程度,降低模型的復雜程度,如果所選模型的AUC遠低于交叉驗證得到的均值,可以說明模型存在一定的欠擬合現象,可以通過增加模型的迭代次數等方法,增加模型對資料的描述能力,降低模型的過擬合或欠擬合的可能性,最終使得模型的復雜度和模型對資料的描述能力達到均衡,從而提高模型對客戶是否按期還款的預測能力,進行客戶人群的精準細分,提高模型對互聯網征信相關業務問題的解決能力,比如減少預測失敗所導致客戶流失的可能,降低未按期還款客戶的廣告成本等等,
參考文獻:
[1]王聰,韓志,胥仲橋,王麗莎.基于邏輯回歸的中小微企業信貸策略研究[J].商訊,2021(02):91-92.
- 模型和學習筆記系列2_END
點贊和收藏是周更的動力,真心謝謝!
歡迎交流和討論,有償糾錯,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/256752.html
標籤:其他
上一篇:程式員硬核“年終大掃除”,清理了資料庫 70GB 空間
下一篇:Intel Movidius神經元計算棒加速-Object Detection API訓練MobileNet-SSD模型全流程記錄