有些網頁我們請求的html代碼并沒有我們在瀏覽器里看到的內容,
因為有些資訊是通過Ajax加載并通過JavaScript渲染生成的,
一.目標站點分析
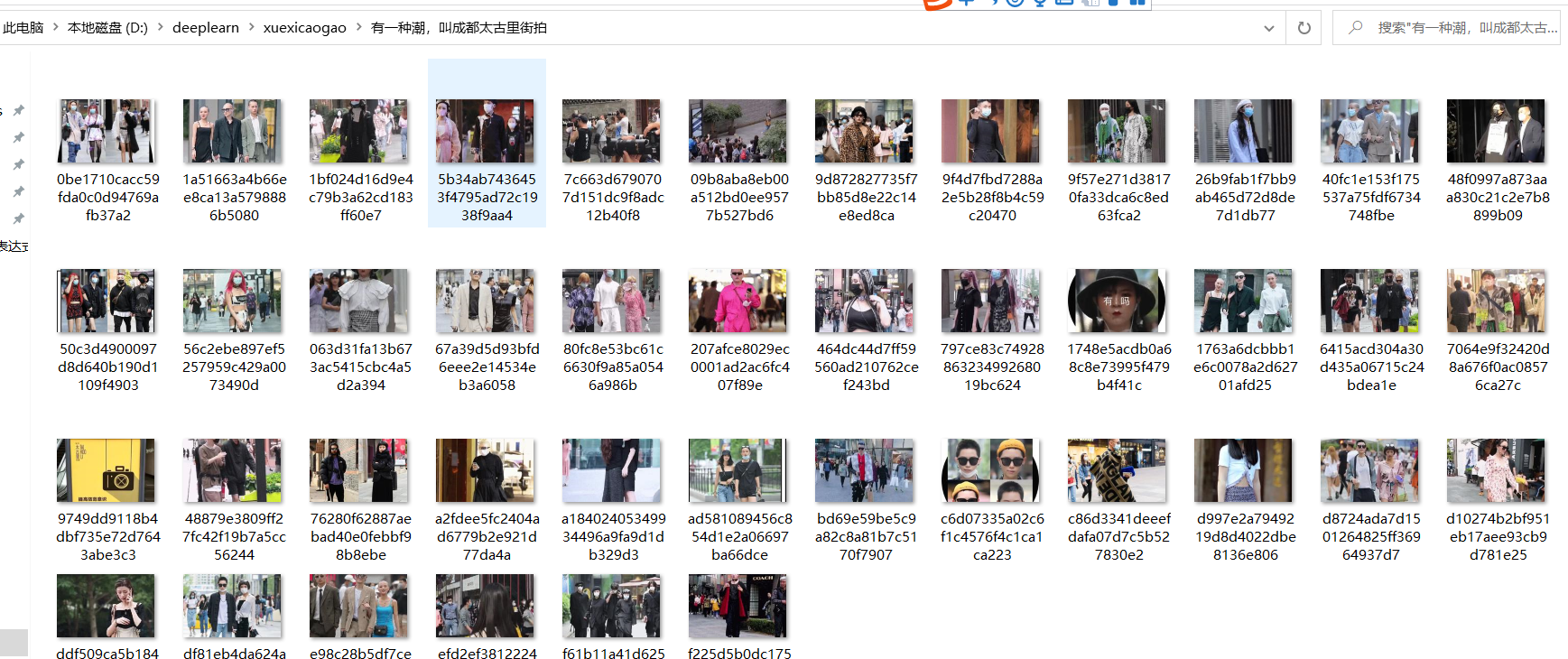
頭條街拍
查看的Ajax請求
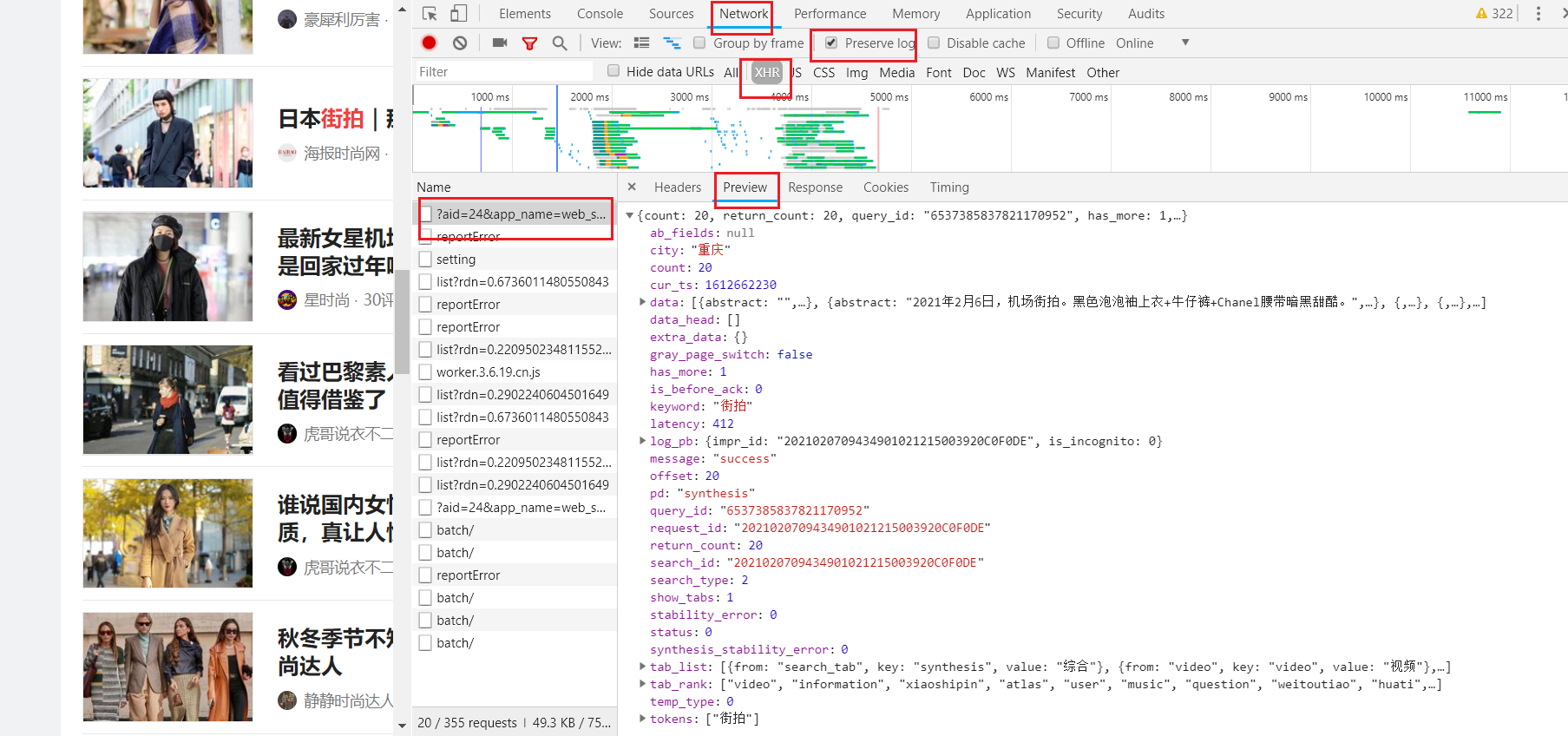
選擇network 勾選preserve log 再勾選XHR ,資料鏈接如左側aid格式
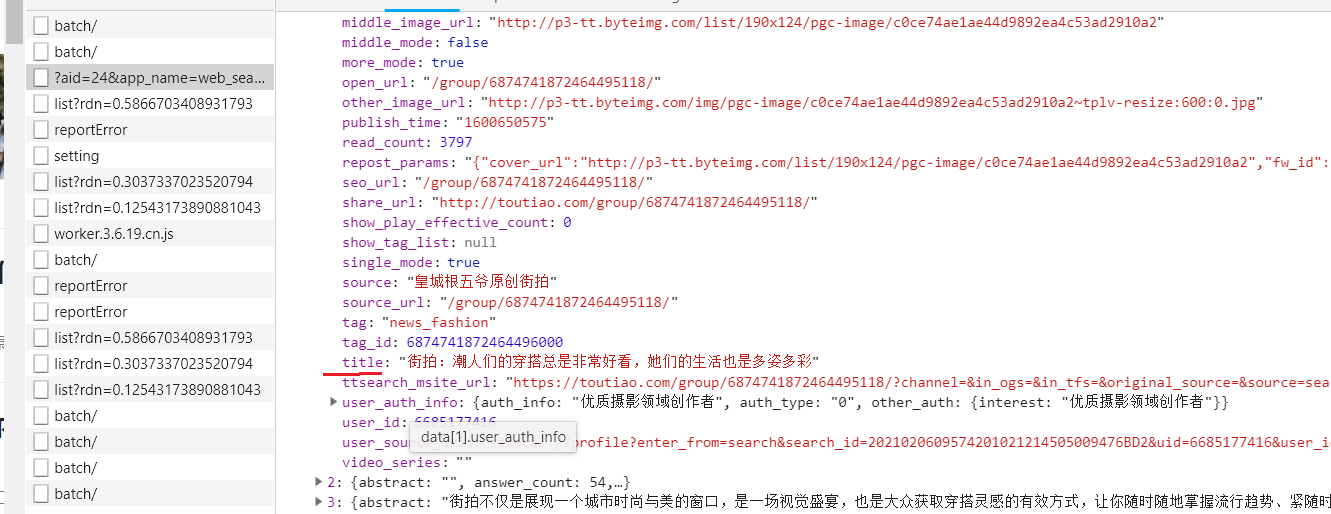
在data下面能夠找到title
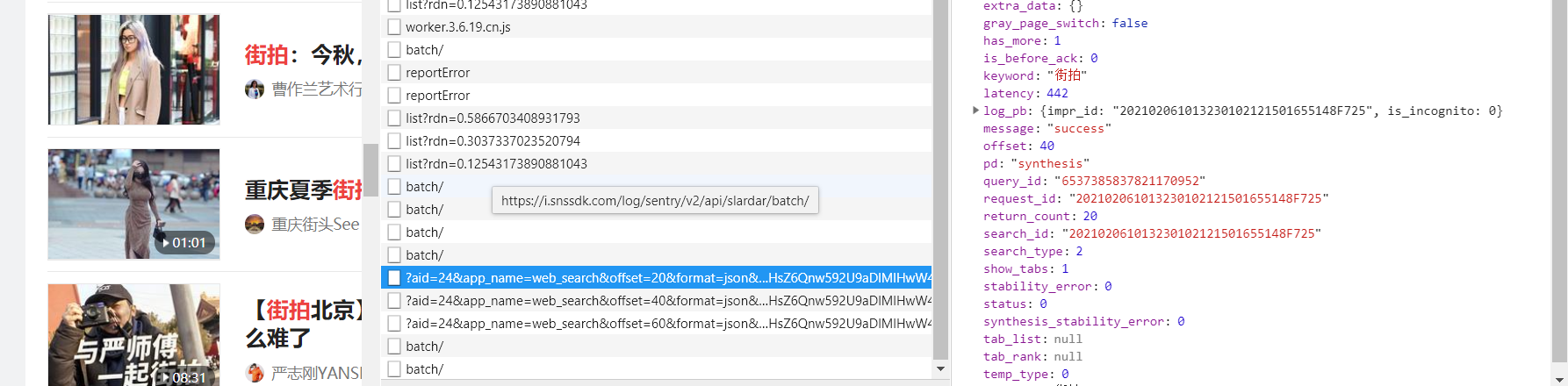
我們網頁不斷下滑,發現請求有offset有20,40,60變化,如圖,
我們可以認為改變offset的值就能拿到不同資料,
通過觀察data,發現資料是json資料,

實戰
一.抓取索引頁內容
1.查看URL
藍色為基本url,其他為引數
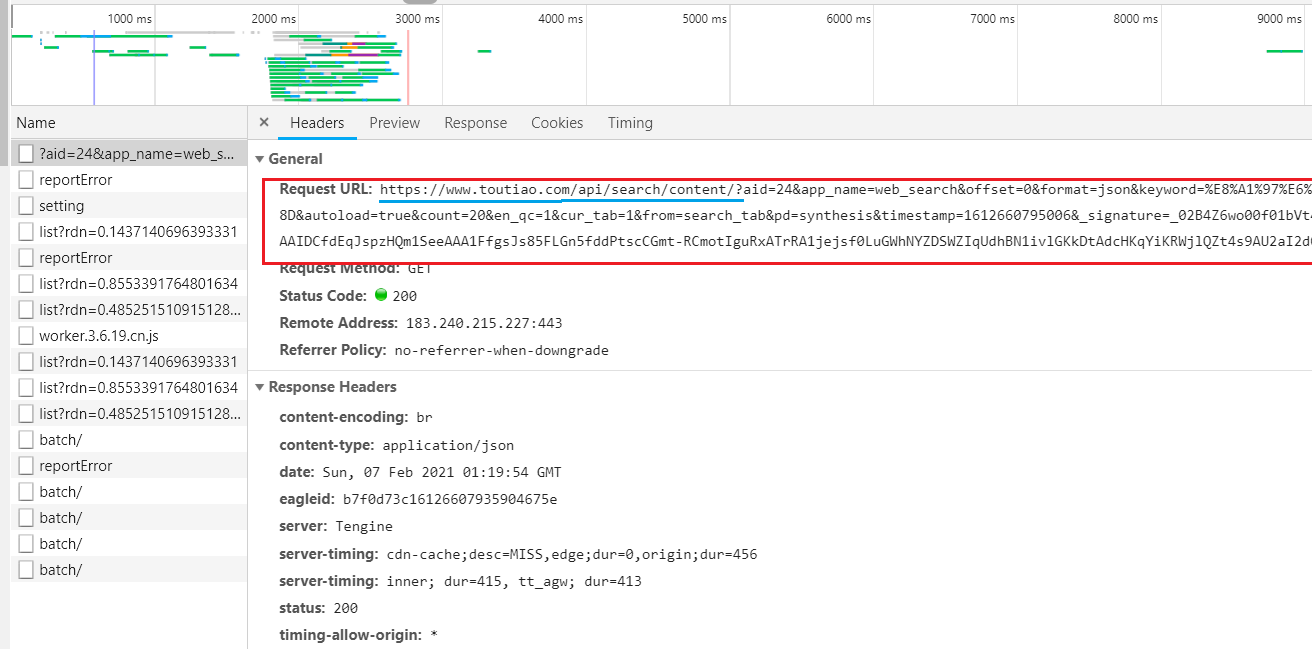
這些引數在下圖
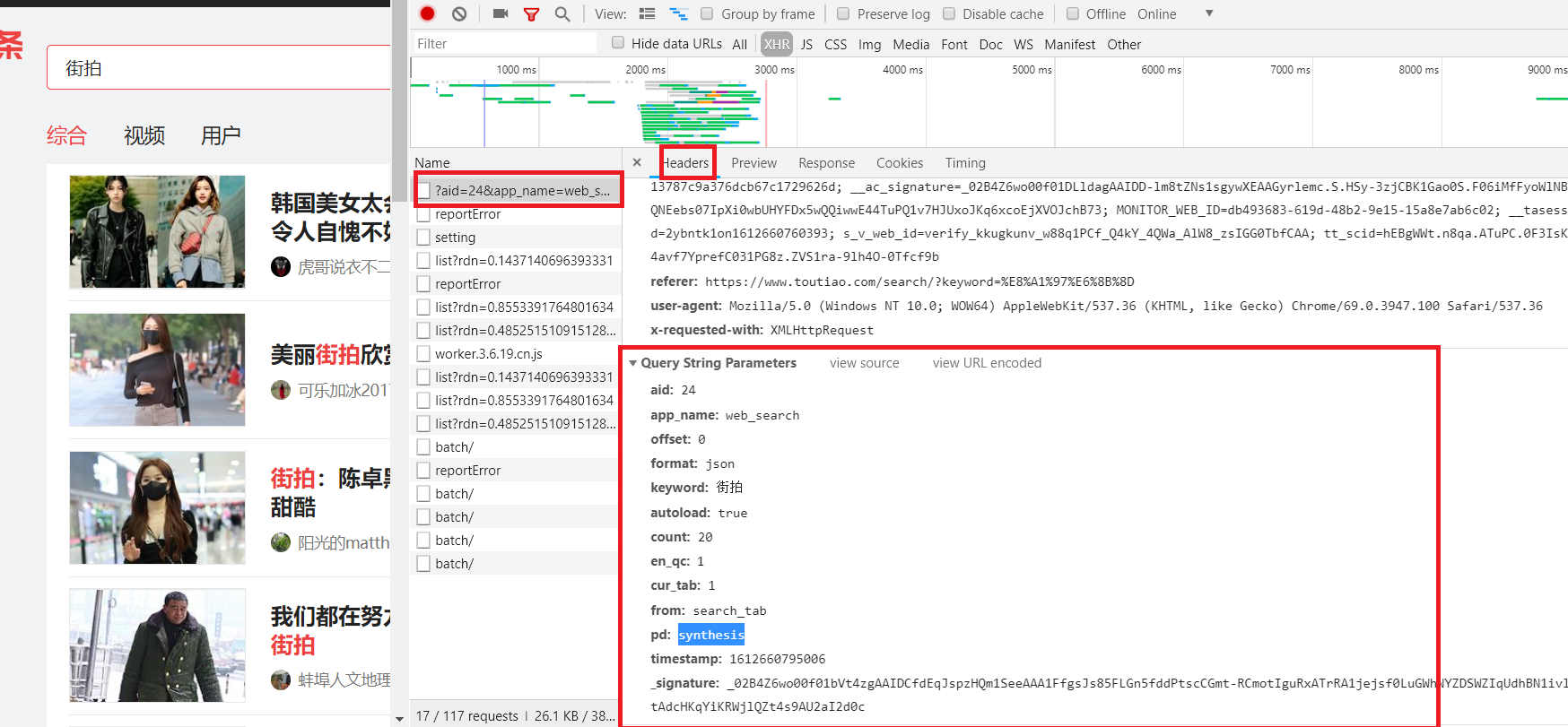
急需下拉網頁,只有offset在變化,每次變化20
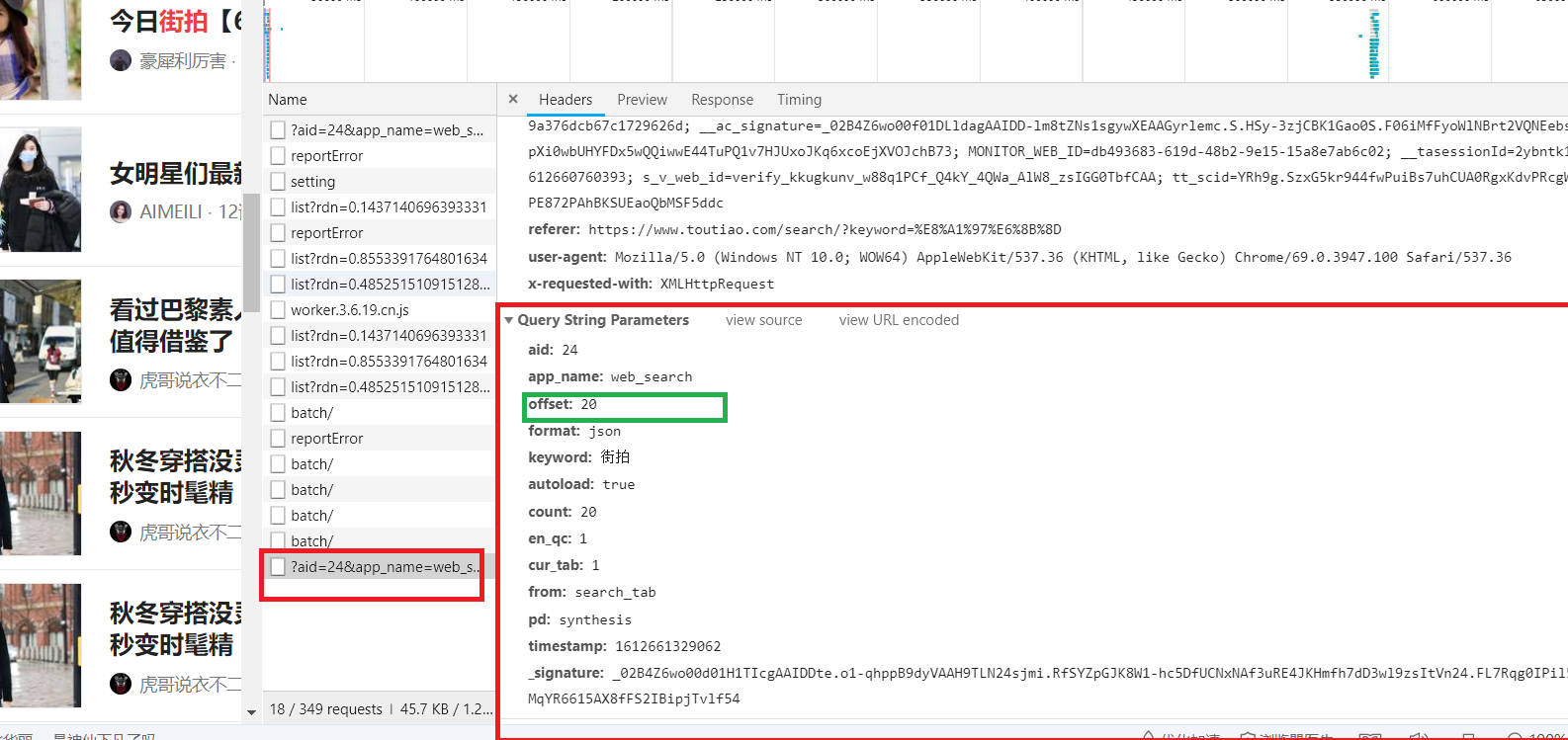
獲取html代碼如下
from urllib.parse import urlencode
import requests
from requests.exceptions import ConnectionError
def get_page(offest,keyword):#獲取請求并回傳決議頁面,offest,keyword為可變引數
params = {
'aid': '24',
'app_name': 'web_search',
'offset': offest,#頁數
'format': 'json',
'keyword': keyword,#關鍵詞,本例子為街拍
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': '1612660795006',
'_signature': '_02B4Z6wo00f01bVt4zgAAIDCfdEqJspzHQm1SeeAAA1FfgsJs85FLGn5fddPtscCGmt-RCmotIguRxATrRA1jejsf0LuGWhNYZDSWZIqUdhBN1ivlGKkDtAdcHKqYiKRWjlQZt4s9AU2aI2d0c'
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
base_url = 'https://www.toutiao.com/api/search/content/?'
url = base_url + urlencode(params)
try:
response = requests.get(url,headers = headers)
if response.status_code == 200 :
return response.text
except ConnectionError:
print('程式錯誤')
return None
def main():
base_url = 'https://www.toutiao.com/api/search/content/?'
html=get_page(0,'街拍')
print(html)
if __name__ =='__main__':
main()
 可以發現結果中有很多超鏈接
可以發現結果中有很多超鏈接

二.資料決議
回到瀏覽器,查看回傳結果Respnse回應,資料格式為json格式
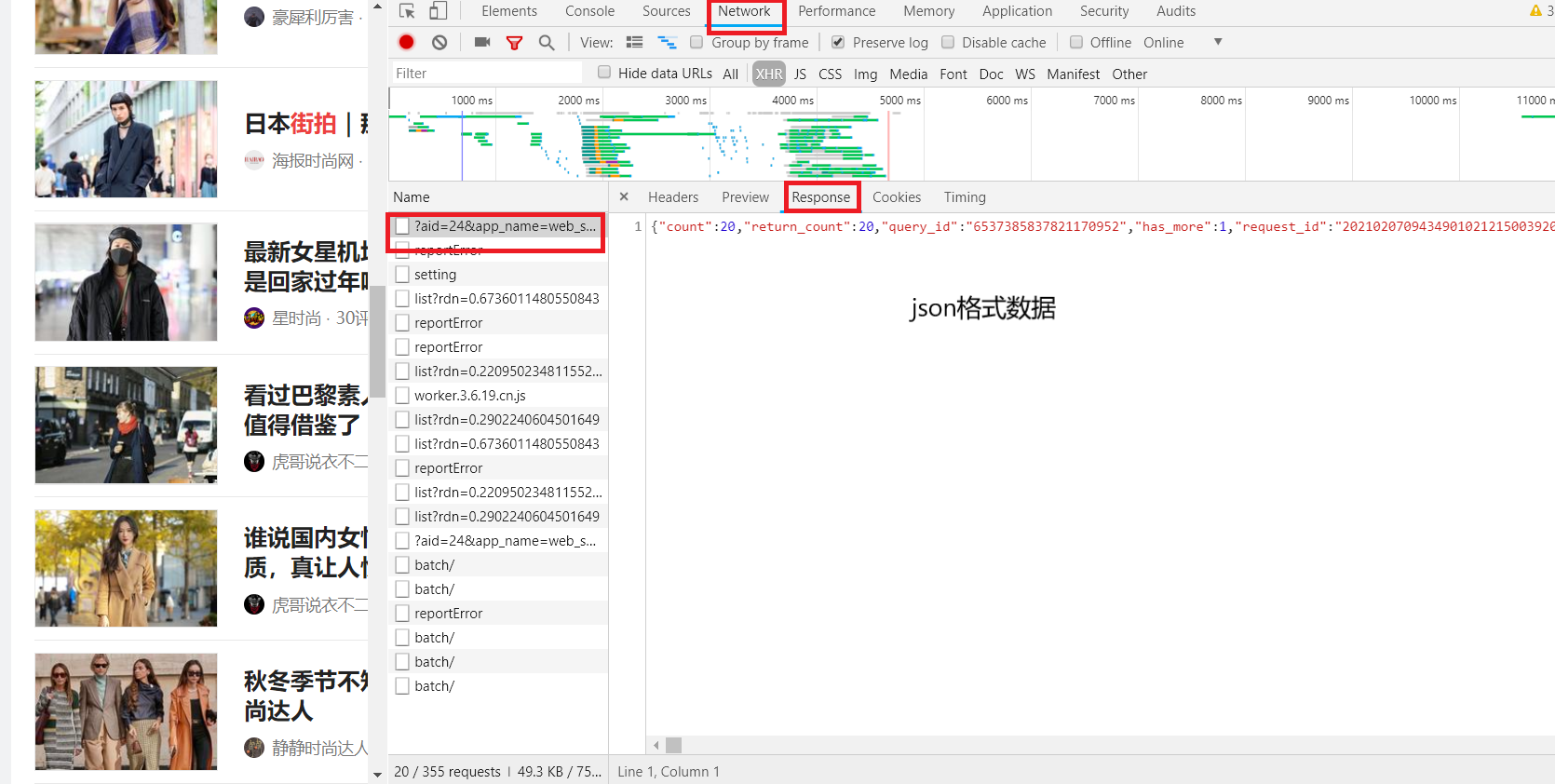
在Preview找到data
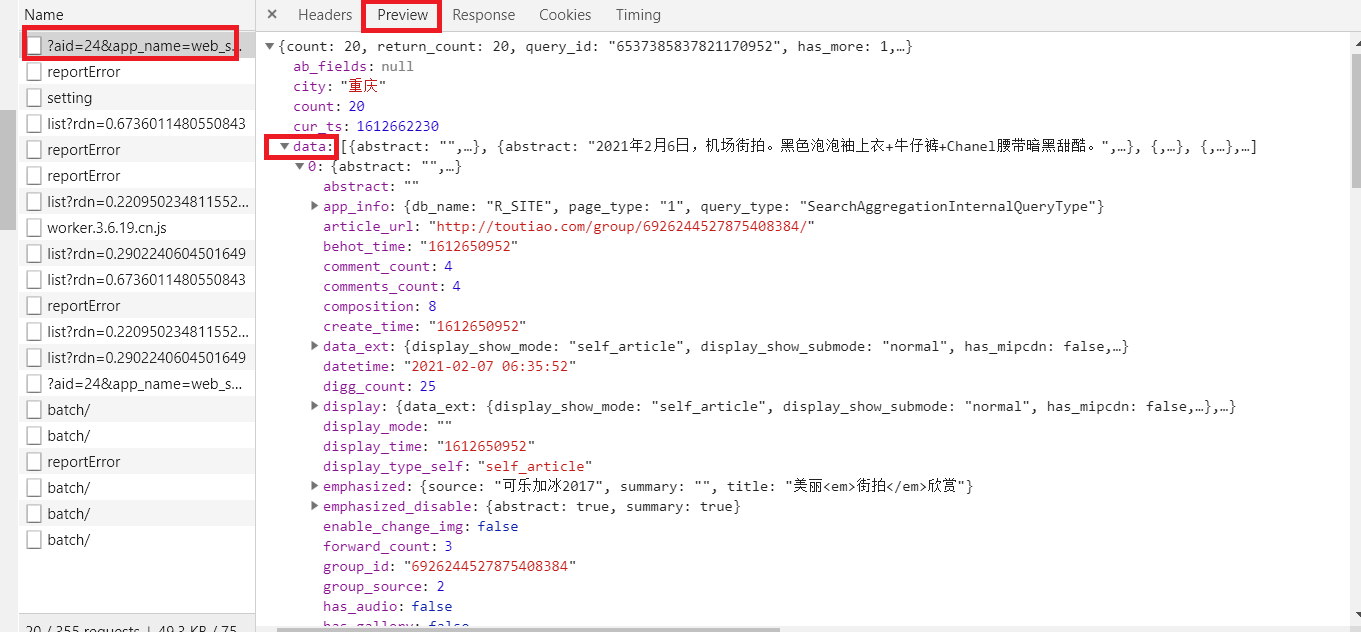
對data進行展開,其中的0,1,2.,均為一組街拍
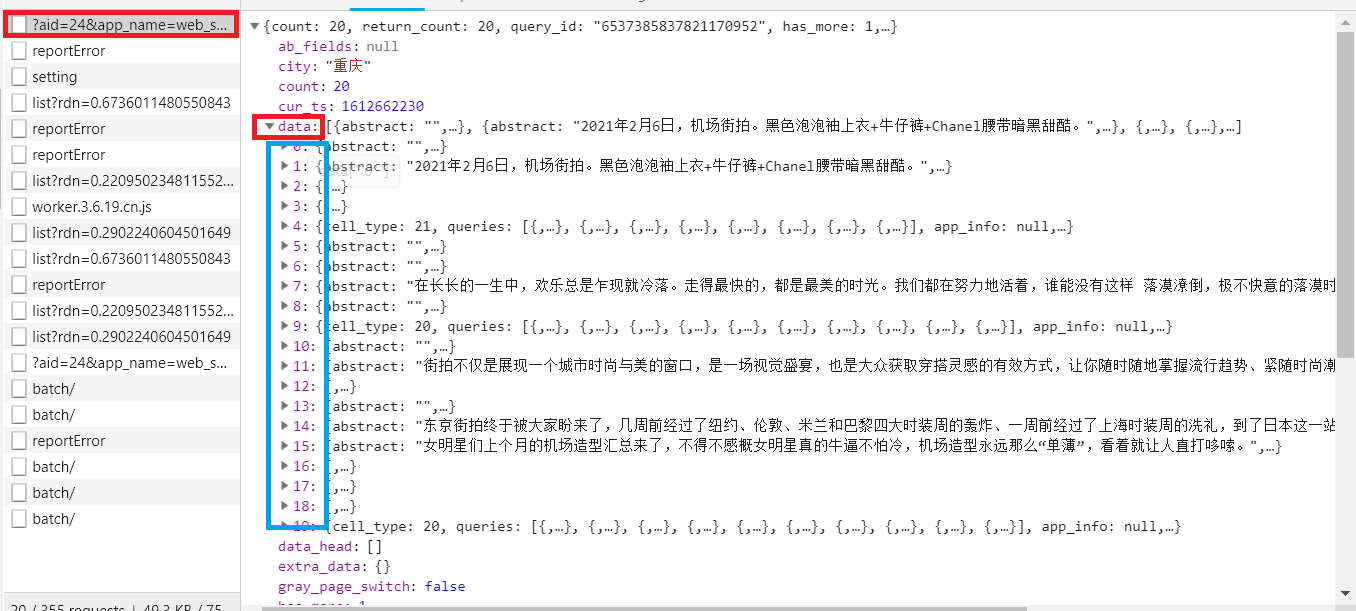
展開0
圖片url在image_list里
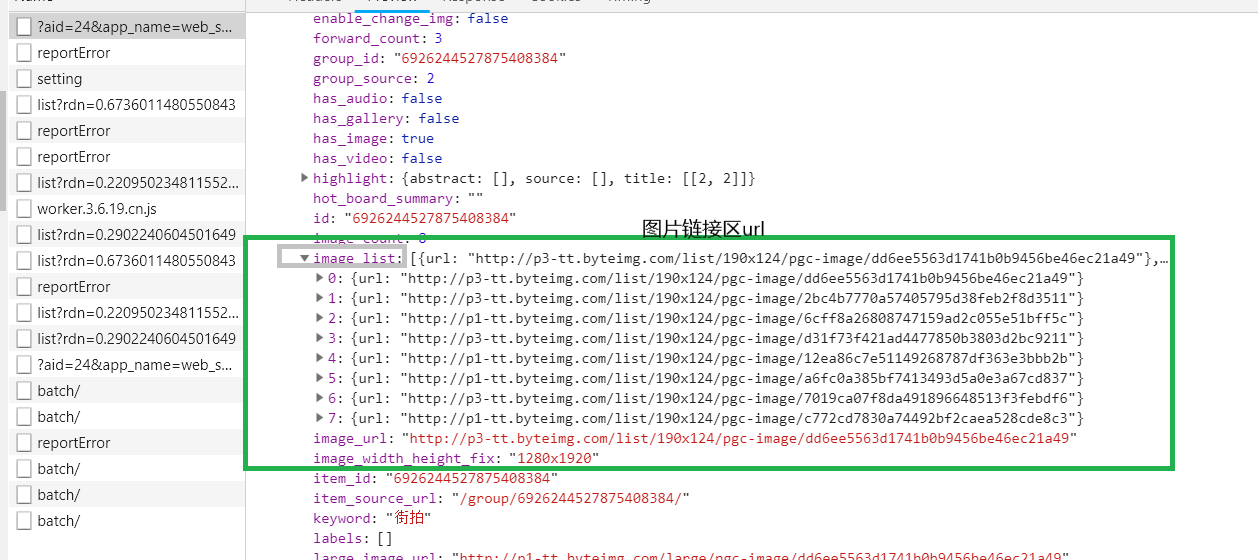
圖片名titlie
#資料決議
import json
def parse_page_index(html):
data=json.loads(html)#轉換為json物件
if data and 'data'in data.keys():#判斷回應里的data是否存在
for item in data.get('data'): # 用item回圈每一條,即0,1,2...
# 這里需要判斷image_list是否為空
title = item.get('title')
if 'image_list' in item and item['image_list'] != []:
images = item['image_list']
for image in images:
yield {
'image': image.get('url'),
'title': title
} # 回傳的一個字典
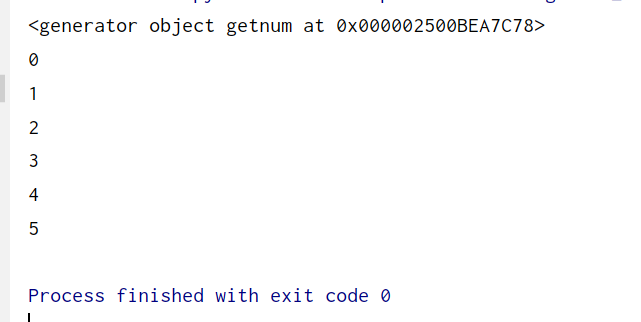
yield用法見例子
回傳的是一個可以迭代的物件
def getnum(n):
i = 0
while i <= n:
yield i
i += 1
a = getnum(5)
print(a)
for i in a:
print(i)
三.圖片保存
import os
from hashlib import md5
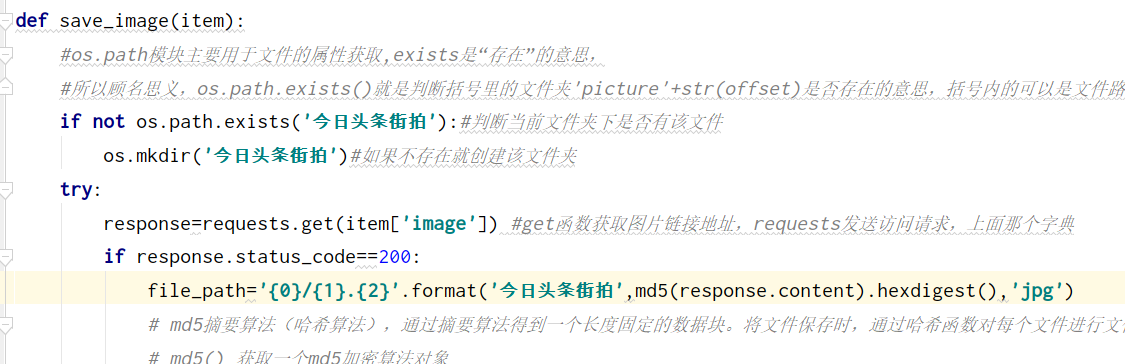
def save_image(item):
#os.path模塊主要用于檔案的屬性獲取,exists是“存在”的意思,
#所以顧名思義,os.path.exists()就是判斷括號里的檔案夾'picture'+str(offset)是否存在的意思,括號內的可以是檔案路徑,
if not os.path.exists(item.get('title')):#判斷當前檔案夾下是否有該檔案
os.mkdir(item.get('title'))#如果不存在就創建該檔案夾
try:
response=requests.get(item['image']) #get函式獲取圖片鏈接地址,requests發送訪問請求,上面那個字典
if response.status_code==200:
file_path='{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
# md5摘要演算法(哈希演算法),通過摘要演算法得到一個長度固定的資料塊,將檔案保存時,通過哈希函式對每個檔案進行檔案名的自動生成,
# md5() 獲取一個md5加密演算法物件
# hexdigest() 獲取加密后的16進制字串
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
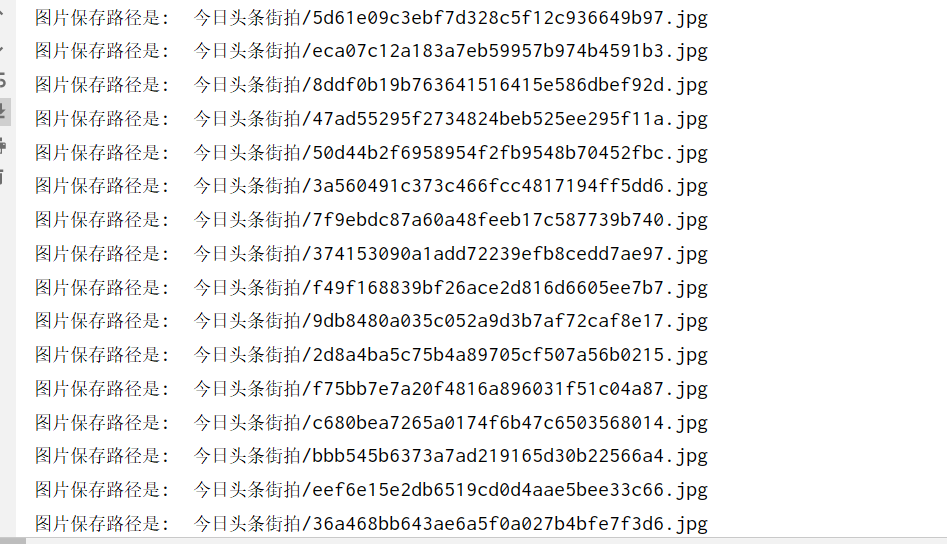
print('圖片保存路徑是: ', file_path)
else:
print('圖片已經下載',file_path)
except requests.ConnectionError:
print('圖片保存失敗')
md5(response.content).hexdigest()摘要演算法(哈希演算法),通過摘要演算法得到一個長度固定的資料塊,將檔案保存時,通過哈希函式對每個檔案進行檔案名的自動生成,
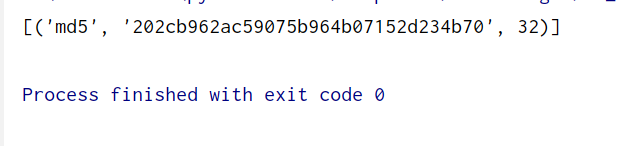
示例
from hashlib import md5
hash_functions = [md5]
def get_hash_code(s):
result = []
hash_obj = md5(s)
hash_hex = hash_obj.hexdigest()
result.append((hash_obj.name, hash_hex, len(hash_hex)))
return result
if __name__ == '__main__':
s = "123"
result = get_hash_code(s.encode("utf-8"))
print(result)
總的代碼
from urllib.parse import urlencode
import requests
from requests.exceptions import ConnectionError
import json
def get_page(offest,keyword):#獲取請求并回傳決議頁面,offest,keyword為可變引數
params = {
'aid': '24',
'app_name': 'web_search',
'offset': offest,#頁數
'format': 'json',
'keyword': keyword,#關鍵詞,本例子為街拍
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': '1612660795006',
'_signature': '_02B4Z6wo00f01bVt4zgAAIDCfdEqJspzHQm1SeeAAA1FfgsJs85FLGn5fddPtscCGmt-RCmotIguRxATrRA1jejsf0LuGWhNYZDSWZIqUdhBN1ivlGKkDtAdcHKqYiKRWjlQZt4s9AU2aI2d0c'
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
base_url = 'https://www.toutiao.com/api/search/content/?'
url = base_url + urlencode(params)
try:
response = requests.get(url,headers = headers)
if response.status_code == 200 :
return response.text
except ConnectionError:
print('程式錯誤')
return None
#資料決議
import json
def parse_page_index(html):
data=json.loads(html)#轉換為json物件
if data and 'data'in data.keys():#判斷回應里的data是否存在
for item in data.get('data'): # 用item回圈每一條,即0,1,2...
# 這里需要判斷image_list是否為空
title = item.get('title')
if 'image_list' in item and item['image_list'] != []:
images = item['image_list']
for image in images:
yield {
'image': image.get('url'),
'title': title
} # 回傳一個字典
import os
from hashlib import md5
def save_image(item):
#os.path模塊主要用于檔案的屬性獲取,exists是“存在”的意思,
#所以顧名思義,os.path.exists()就是判斷括號里的檔案夾'picture'+str(offset)是否存在的意思,括號內的可以是檔案路徑,
if not os.path.exists(item.get('title')):#判斷當前檔案夾下是否有該檔案
os.mkdir(item.get('title'))#如果不存在就創建該檔案夾
try:
response=requests.get(item['image']) #get函式獲取圖片鏈接地址,requests發送訪問請求,上面那個字典
if response.status_code==200:
file_path='{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
# md5摘要演算法(哈希演算法),通過摘要演算法得到一個長度固定的資料塊,將檔案保存時,通過哈希函式對每個檔案進行檔案名的自動生成,
# md5() 獲取一個md5加密演算法物件
# hexdigest() 獲取加密后的16進制字串
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
print('圖片保存路徑是: ', file_path)
else:
print('圖片已經下載',file_path)
except requests.ConnectionError:
print('圖片保存失敗')
def main():
for offest in range(0, 60, 20):
html = get_page(offest, '街拍')
a = parse_page_index(html)
for item in a:
save_image(item)
if __name__ =='__main__':
main()
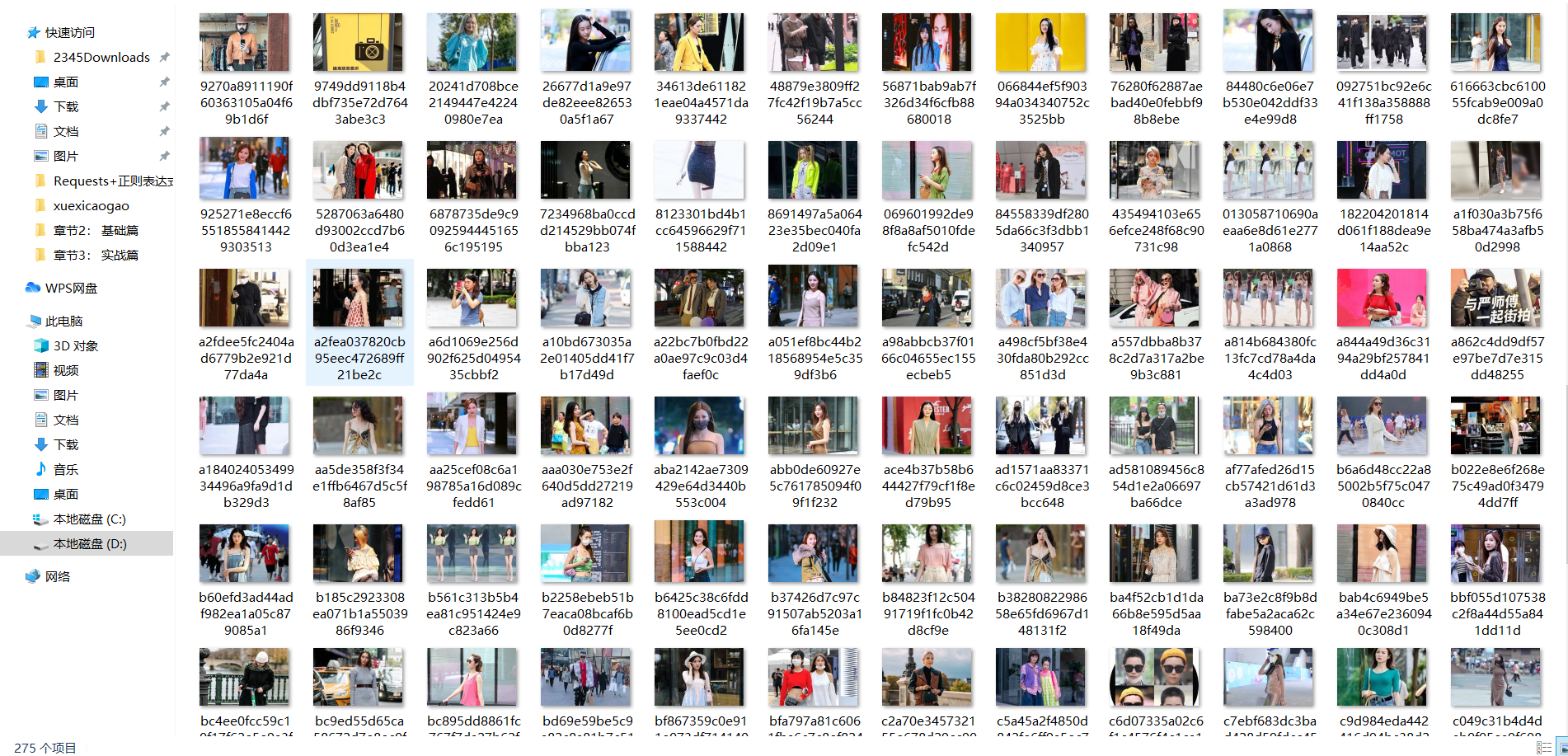
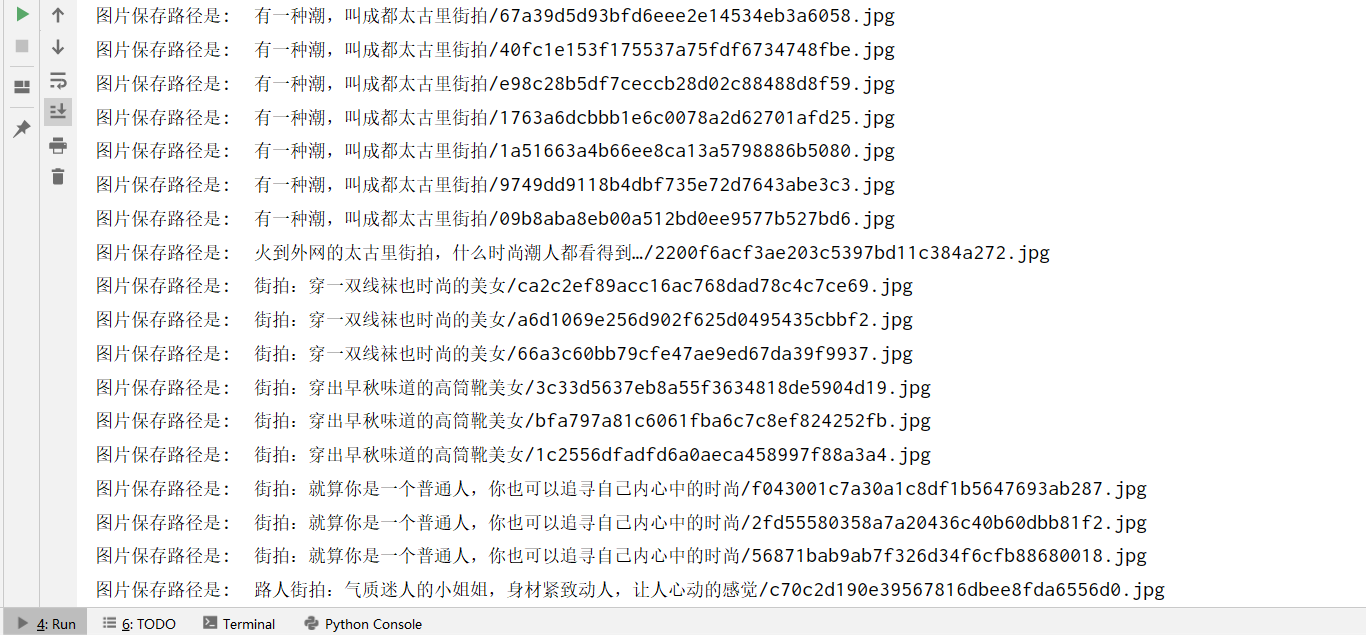 結果檔案夾
結果檔案夾
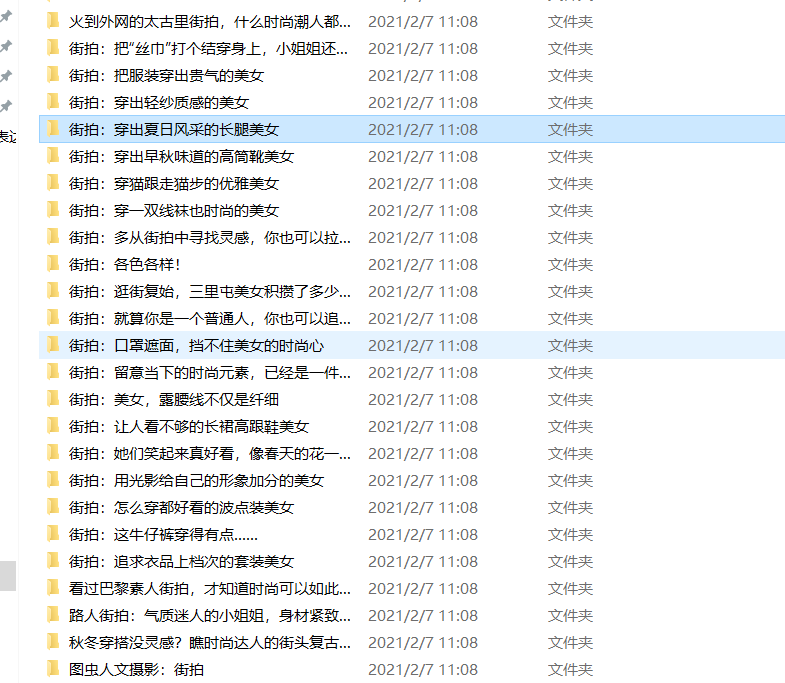 打開一個檔案夾
打開一個檔案夾
檔案夾太多,我們修改為一個檔案夾
結果
結果檔案夾
作者:電氣-余登武,
碼字不易,請點個贊再走,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/258151.html
標籤:其他