前言
任何一個服務,如果僅僅是單機部署,那么性能總是有上限的,RabbitMQ 也不例外,當單臺 RabbitMQ 服務處理訊息的能力到達瓶頸時,可以通過集群來實作高可用和負載均衡,
RabbitMQ 集群知多少
通常情況下,在集群中我們把每一個服務稱之為一個節點,在 RabbitMQ 集群中,節點型別可以分為兩種:
- 記憶體節點:元資料存放于記憶體中,為了重啟后能同步資料,記憶體節點會將磁盤節點的地址存放于磁盤之中,除此之外,如果訊息被持久化了也會存放于磁盤之中,因為記憶體節點讀寫速度快,一般客戶端會連接記憶體節點,
- 磁盤節點:元資料存放于磁盤中(默認節點型別),需要保證至少一個磁盤節點,否則一旦宕機,無法恢復資料,從而也就無法達到集群的高可用目的,
PS:元資料,指的是包括佇列名字屬性、交換機的型別名字屬性、系結資訊、vhost等基礎資訊,不包括佇列中的訊息資料,
RabbitMQ 中的集群主要有兩種模式:普通集群模式和鏡像佇列模式,
普通集群模式
在普通集群模式下,集群中各個節點之間只會相互同步元資料,也就是說,訊息資料不會被同步,那么問題就來了,假如我們連接到 A 節點,但是訊息又存盤在 B 節點又怎么辦呢?
不論是生產者還是消費者,假如連接到的節點上沒有存盤佇列資料,那么內部會將其轉發到存盤佇列資料的節點上進行存盤,雖然說內部可以實作轉發,但是因為訊息僅僅只是存盤在一個節點,那么假如這節點掛了,訊息是不是就沒有了?這個問題確實存在,所以這種普通集群模式并沒有達到高可用的目的,
鏡像佇列模式
鏡像佇列模式下,節點之間不僅僅會同步元資料,訊息內容也會在鏡像節點間同步,可用性更高,這種方案提升了可用性的同時,因為同步資料之間也會帶來網路開銷從而在一定程度上會影響到性能,
RabbitMQ 集群搭建
接下來讓我們一起嘗試搭建一個 RabbitMQ 集群:
-
假如之前啟動過單機版,那么先洗掉舊資料
rm -rf /var/lib/rabbitmq/mnesia或者洗掉安裝目錄內的var/lib/rabbitmq/mnesia,我本機是安裝在安裝目錄下,所以執行的是命令rm -rf /usr/local/rabbitmq_server-3.8.4/var/lib/rabbitmq/mnesia/, -
接下來需要啟動以下三個命令來啟動三個不同埠號的
RabbitMQ服務,除了指定RabbitMQ服務埠之后還需要額外指定后臺管理系統的埠,而且必須指定node名的前綴,因為集群中是以節點名來進行通信的,所以節點名必須唯一,默認的節點名是rabbit@hostname,下面的命令表示指定了前綴:
RABBITMQ_NODE_PORT=5672 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15672}]" RABBITMQ_NODENAME=rabbit1 rabbitmq-server -detached
RABBITMQ_NODE_PORT=5673 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15673}]" RABBITMQ_NODENAME=rabbit2 rabbitmq-server -detached
RABBITMQ_NODE_PORT=5674 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [{port,15674}]" RABBITMQ_NODENAME=rabbit3 rabbitmq-server -detached
啟動之后進入 /usr/local/rabbitmq_server-3.8.4/var/lib/rabbitmq/mnesia/ 目錄查看,發現創建了 3 個節點資訊:
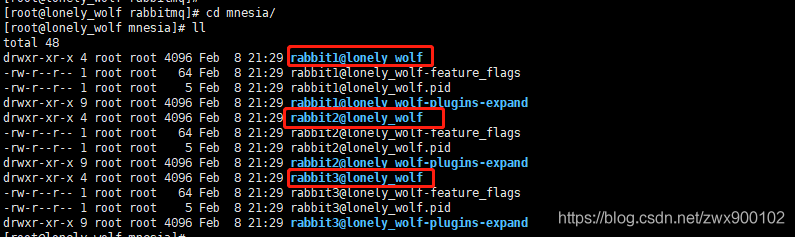
另外通過 ps -ef | grep rabbit 也可以發現三個服務行程被啟動,
- 現在啟動的三個服務彼此之間還沒有聯系,現在我們需要以其中一個節點為主節點,然后其余兩個節點需要加入主節點,形成一個集群服務,需要注意的是加入集群之前,需要重置節點資訊,即不允許帶有資料的節點加入集群,
//rabbit2 節點重置后加入集群
rabbitmqctl -n rabbit2 stop_app
rabbitmqctl -n rabbit2 reset
rabbitmqctl -n rabbit2 join_cluster --ram rabbit1@`hostname -s` //--ram 表示這是一個記憶體節點
rabbitmqctl -n rabbit2 start_app
rabbitmqctl -n rabbit3 stop_app
rabbitmqctl -n rabbit3 reset
rabbitmqctl -n rabbit3 join_cluster --disc rabbit1@`hostname -s` //--disc表示磁盤節點(默認也是磁盤節點)
rabbitmqctl -n rabbit3 start_app
- 成功之后,執行命令
rabbitmqctl cluster_status查詢節點rabbit1的狀態,可以看到下圖所示,兩個磁盤節點一個記憶體節點:
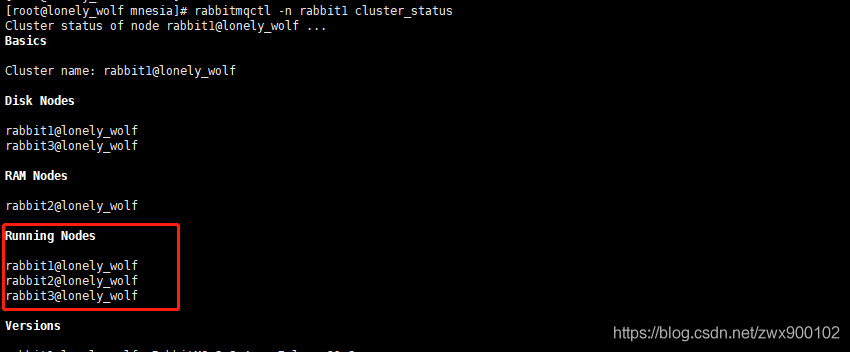
- 需要注意的是,到這里啟動的集群只是默認的普通集群,如果想要配置成鏡像集群,則需要執行以下命令:
rabbitmqctl -n rabbit1 set_policy ha-all "^" '{"ha-mode":"all"}'
到這里 RabbitMQ 集群就算搭建完成了,不過需要注意的是,這里因為是單機版本,所以沒有考慮 .erlang.cookie 檔案保持一致,
基于 HAProxy + Keepalived 高可用集群
假如一個 RabbitMQ 集群中,有多個記憶體節點,我們應該連接到哪一個節點呢?這個選擇的策略如果放在客戶端做,那么會有很大的弊端,最嚴重的的就是每次擴展集群都要修改客戶端代碼,所以這種方式并不是很可取,所以我們在部署集群的時候就需要一個中間代理組件,這個組件要能夠實作服務監控和轉發,比如 Redis 中的 Sentinel(哨兵)集群模式,哨兵就可以監聽 Redis 節點并實作故障轉移,
在 RabbitMQ 集群中,通過 Keepalived 和 HAProxy 兩個組件實作了集群的高可用性和負載均衡功能,
HAProxy
HAProxy 是一個開源的、高性能的負載均衡軟體,同樣可以作為負載均衡軟體的還有 nginx,lvs 等, HAproxy 支持 7 層負載均衡和 4 層負載均衡,
負載均衡
所謂的 7 層負載均衡和 4 層負載均衡針對的是 OSI 模型而言,如下圖所示就是一個 OSI 通信模型:

上圖中看到,第 7 層對應了應用層,第 4 層對應了傳輸層,常用的負載均衡軟體如 nginx 一般作業在第 7 層,lvs(Linux Virtual Server)一般作業在第 4 層,
4層負載:
4 層負載使用了 NAT (Network Address Translation)技術,即:網路地址轉換,收到客戶端請求時,可以通過修改資料包里的源 IP 和埠,然后把資料包轉發到對應的目標服務器,4 層負載均衡只能根據報文中目標地址和源地址對請求進行轉發,無法判斷或者修改請求資源的具體型別,
7層負載:
根據客戶端請求的資源路徑,轉發到不同的目標服務器,
高可用 HAProxy
HAProxy 雖然實作了負載均衡,但是假如只是部署一個 HAProxy,那么其本身也存在宕機的風險,一旦 HAProxy 宕機,那么就會導致整個集群不可用,所以我們也需要對 HAProxy 也實作集群,那么假如 HAProxy 也實作了集群,客戶端應該連接哪一臺服務呢?問題似乎又回到了起點,陷入了無限回圈中…
Keepalived
為了實作 HAProxy 的高可用,需要再引入一個 Keepalived 組件,Keepalived 組件主要有以下特性:
- 具有負載功能,可以監控集群中的節點狀態,如果集群中某一個節點宕機,可以實作故障轉移,
- 其本身也可以實作集群,但是只能有一個
master節點, master節點會對外提供一個虛擬IP,應用端只需要連接這一個IP就行了,可以理解為集群中的HAProxy節點會同時爭搶這個虛擬IP,哪個節點爭搶到,就由哪個節點來提供服務,
VRRP 協議
VRRP 協議即虛擬路由冗余協議(Virtual Router Redundancy Protocol),Keepalived 中提供的虛擬 IP 機制就屬于 VRRP,它是為了避免路由器出現單點故障的一種容錯協議,
總結
本文主要介紹了 RaabbitMQ 集群的相關知識,并對比了普通集群和鏡像集群的區別,最后通過實踐搭建了一個 RabbitMQ 集群,同時也介紹了普通的集群存在一些不足,可以結合 HAProxy 和 Keepalived 組件來實作真正的高可用分布式集群服務,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/258915.html
標籤:其他
上一篇:什么是 BPM?