目錄
Environment 環境
Reference 參考鏈接
Video Datasets 視頻資料集 & 加載
加載 UCF101 資料集
加載 HMDB51 資料集
加載 Kinetics 400 資料集
Video I/O 視頻 I/O 操作
torchvision.io.read_video()
torchvision.io.read_video_timestamps()
torchvision.io.write_video()
class torchvision.io.VideoReader(path, stream='video')
Video Transform 視頻變換操作
ToTensorVideo()
NormalizeVideo()
RandomHorizontalFlipVideo()
CenterCropVideo()
RandomCropVideo()
RandomResizedCropVideo()
Example
Video Classification Model 視頻動作分類模型
Example
Environment 環境
- Win 10
- Anaconda Navigator
- PyCharm
- cuda 10.1
- torch 1.7.1
- torchvision 0.8.2
- Python 3.8
Reference 參考鏈接
- Anaconda Navigator 版本的升級:https://www.cnblogs.com/developerchen/p/8879516.html
打開 Anaconda Prompt,輸入以下命令:
conda install -c continuumcrew anaconda-navigator=1.5.1
conda update --all
- torch 1.7.1 的安裝:https://pytorch.org/get-started/locally/
打開 Anaconda Prompt,切換到相應環境,輸入以下命令:
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
- Pytorch 1.7.1 官方檔案:https://pytorch.org/docs/stable/index.html
Video Datasets 視頻資料集 & 加載
- UCF101:https://pytorch.org/docs/stable/torchvision/datasets.html#ucf101
- HMDB51:https://pytorch.org/docs/stable/torchvision/datasets.html#hmdb51
- Kinetics400:https://pytorch.org/docs/stable/torchvision/datasets.html#kinetics-400
- ......
加載 UCF101 資料集
import torchvision.datasets as datasets
data = datasets.UCF101(
root='path/UCF-101',
annotation_path='path/UCF101TrainTestSplits-RecognitionTask/ucfTrainTestlist',
frames_per_clip=16,
num_workers=0
)
print(data)回傳值:
- video (Tensor[T, H, W, C]): the `T` video frames
- audio(Tensor[K, L]): the audio frames, where `K` is the number of channels and `L` is the number of points
- label (int): class of the video clip
注意:
- win 10 系統下運行該代碼一定要加上 num_workers=0,不然會報出如下錯誤
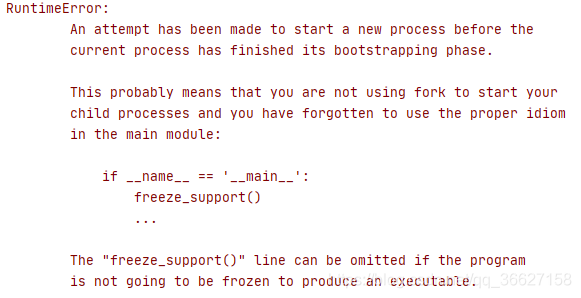
- 還需要安裝 PyAV 這個庫,安裝命令:pip install av

- 在匯入 UCF101 資料時,由于 windows 路徑用的是“\”,所以在加載資料集時會報出如下錯誤:
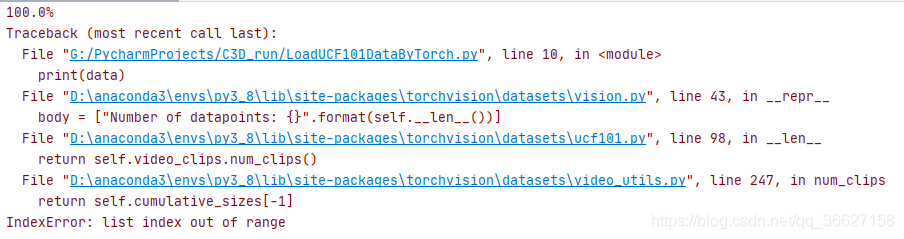
原因 & 解決方案:https://stackoverflow.com/questions/61522539/i-cant-import-the-ucf-101-dataset-torchvision-list-index-out-of-range-error
原因:trainlist01/02/03.txt 和 testlist01/02/03.txt 中的 video path 長這樣:ApplyEyeMakeup/v_ApplyEyeMakeup_g01_c01.avi 和 windows 系統路徑要求的斜杠( \ )不一樣
我用的是其中的第一種解決方案:把 trainlist01/02/03.txt 和 testlist01/02/03.txt 中的 / 全部替換為 \
加載 HMDB51 資料集
引數:
root (string) – Root directory of the HMDB51 Dataset.
annotation_path (str) – Path to the folder containing the split files.
frames_per_clip (int) – Number of frames in a clip.
step_between_clips (int) – Number of frames between each clip.
fold (int, optional) – Which fold to use. Should be between 1 and 3.
train (bool, optional) – If
True, creates a dataset from the train split, otherwise from thetestsplit.transform (callable, optional) – A function/transform that takes in a TxHxWxC video and returns a transformed version.
回傳值:
- video (Tensor[T, H, W, C]): the `T` video frames
- audio(Tensor[K, L]): the audio frames, where `K` is the number of channels and `L` is the number of points
- label (int): class of the video clip
加載 Kinetics 400 資料集
引數:
root (string) – Root directory of the Kinetics-400 Dataset.
frames_per_clip (int) – number of frames in a clip
step_between_clips (int) – number of frames between each clip
transform (callable, optional) – A function/transform that takes in a TxHxWxC video and returns a transformed version.
回傳值:
- video (Tensor[T, H, W, C]): the `T` video frames
- audio(Tensor[K, L]): the audio frames, where `K` is the number of channels and `L` is the number of points
- label (int): class of the video clip
Video I/O 視頻 I/O 操作
官方檔案:
- https://pytorch.org/docs/stable/torchvision/io.html?highlight=video
- https://pytorch.org/docs/stable/torchvision/io.html#fine-grained-video-api
torchvision.io.read_video()
原始碼:https://pytorch.org/docs/stable/_modules/torchvision/io/video.html#read_video
Parameters
filename (str) – path to the video file
start_pts (int if pts_unit = 'pts', optional) – float / Fraction if pts_unit = ‘sec’, optional the start presentation time of the video
end_pts (int if pts_unit = 'pts', optional) – float / Fraction if pts_unit = ‘sec’, optional the end presentation time
pts_unit (str, optional) – unit in which start_pts and end_pts values will be interpreted, either ‘pts’ or ‘sec’. Defaults to ‘pts’.
Returns
vframes (Tensor[T, H, W, C]) – the T video frames
aframes (Tensor[K, L]) – the audio frames, where K is the number of channels and L is the number of points
info (Dict) – metadata for the video and audio. Can contain the fields video_fps (float) and audio_fps (int)
補充知識:什么是時間戳?什么是 pts?
https://blog.csdn.net/tanningzhong/article/details/105564589
時間戳單位
前面我們提到采樣率,感覺到采樣率是個很大的單位,一般標準的音頻AAC采樣率達到了44kHz,視頻采樣率也規定在90000Hz.所以我們衡量時間的單位不能再是秒,毫秒這種真實的時間單位,我們的單位應該轉換為采樣率,也就是一個采樣的時間為音視頻的時間單位,這就是時間戳的真實值,當我們要播放和控制時,我們再將時間戳根據采樣率轉換為真實的時間即可,
一句話,時間戳不是真實的時間是采樣次數,比如時間戳是160,我們不能認為是160秒或者160毫秒,應該是160個采樣,要換算真實時間,我們必須知道采樣率,比如8000,那么說明1秒被劃分成8000分之一,如果你要明確160個采樣占用的時間,則160*(1/8000)即可,即20毫秒,
時間戳增量
就是一幀影像和另外一幀影像之間的時間戳差值,或者一幀音頻和一幀音頻的時間戳差值,同理時間戳增量也是采樣個數的差值不是真實時間差值,還是要根據采樣率才能換算成真實時間,
所以對于視頻和音頻的時間戳計算要一定明確幀率是多少,采樣率是多少,
比如視頻而言,幀率25,那么對于90000的采樣率來說,一幀占用的采樣數就是90000/25也就是3600,說明每幀影像的時間戳增量應該是3600,換算成實際時間就是3600*(1/90000)=0.04秒=40毫秒,這也和1/25=0.04秒=40毫秒一致,
對于AAC音頻,一幀1024個采樣,采樣頻率是44kHz,所以一幀的播放時間應該是1024*(1/44100)=0.0232秒=23.22毫秒,
用個 Example 更直觀的理解這兩個概念:
import torchvision.io as io
vframes, aframes, info = io.read_video(
filename='path/v_ApplyEyeMakeup_g01_c01.avi',
pts_unit='pts',
end_pts=3
)
print(vframes.shape)
print(info)
# output:
# torch.Size([3, 240, 320, 3])
# {'video_fps': 25.0, 'audio_fps': 44100}
# --------------------------------------------------------------------
import torchvision.io as io
vframes, aframes, info = io.read_video(
filename='path/v_ApplyEyeMakeup_g01_c01.avi',
pts_unit='sec',
end_pts=3
)
print(vframes.shape)
print(info)
# output:
# torch.Size([75, 240, 320, 3])
# {'video_fps': 25.0, 'audio_fps': 44100}
torchvision.io.read_video_timestamps()
原始碼:https://pytorch.org/docs/stable/_modules/torchvision/io/video.html#read_video_timestamps
Parameters
filename (str) – path to the video file
pts_unit (str, optional) – unit in which timestamp values will be returned either ‘pts’ or ‘sec’. Defaults to ‘pts’.
Returns
pts (List[int] if pts_unit = ‘pts’) – List[Fraction] if pts_unit = ‘sec’ presentation timestamps for each one of the frames in the video.
video_fps (float, optional) – the frame rate for the video
Example:
import torchvision.io as io
v_pts, v_fps = io.read_video_timestamps(
filename='path/v_ApplyEyeMakeup_g01_c01.avi',
pts_unit='pts'
)
print(v_pts)
print(v_fps)
# output
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164]
# 25.0
# ---------------------------------------------------------------------------
import torchvision.io as io
v_pts, v_fps = io.read_video_timestamps(
filename='path/v_ApplyEyeMakeup_g01_c01.avi',
pts_unit='sec'
)
print(v_pts)
print(v_fps)
# output
# [Fraction(1, 25), Fraction(2, 25), Fraction(3, 25), Fraction(4, 25), Fraction(1, 5), Fraction(6, 25), Fraction(7, 25), Fraction(8, 25), Fraction(9, 25), Fraction(2, 5), Fraction(11, 25), Fraction(12, 25), Fraction(13, 25), Fraction(14, 25), Fraction(3, 5), Fraction(16, 25), Fraction(17, 25), Fraction(18, 25), Fraction(19, 25), Fraction(4, 5), Fraction(21, 25), Fraction(22, 25), Fraction(23, 25), Fraction(24, 25), Fraction(1, 1), Fraction(26, 25), Fraction(27, 25), Fraction(28, 25), Fraction(29, 25), Fraction(6, 5), Fraction(31, 25), Fraction(32, 25), Fraction(33, 25), Fraction(34, 25), Fraction(7, 5), Fraction(36, 25), Fraction(37, 25), Fraction(38, 25), Fraction(39, 25), Fraction(8, 5), Fraction(41, 25), Fraction(42, 25), Fraction(43, 25), Fraction(44, 25), Fraction(9, 5), Fraction(46, 25), Fraction(47, 25), Fraction(48, 25), Fraction(49, 25), Fraction(2, 1), Fraction(51, 25), Fraction(52, 25), Fraction(53, 25), Fraction(54, 25), Fraction(11, 5), Fraction(56, 25), Fraction(57, 25), Fraction(58, 25), Fraction(59, 25), Fraction(12, 5), Fraction(61, 25), Fraction(62, 25), Fraction(63, 25), Fraction(64, 25), Fraction(13, 5), Fraction(66, 25), Fraction(67, 25), Fraction(68, 25), Fraction(69, 25), Fraction(14, 5), Fraction(71, 25), Fraction(72, 25), Fraction(73, 25), Fraction(74, 25), Fraction(3, 1), Fraction(76, 25), Fraction(77, 25), Fraction(78, 25), Fraction(79, 25), Fraction(16, 5), Fraction(81, 25), Fraction(82, 25), Fraction(83, 25), Fraction(84, 25), Fraction(17, 5), Fraction(86, 25), Fraction(87, 25), Fraction(88, 25), Fraction(89, 25), Fraction(18, 5), Fraction(91, 25), Fraction(92, 25), Fraction(93, 25), Fraction(94, 25), Fraction(19, 5), Fraction(96, 25), Fraction(97, 25), Fraction(98, 25), Fraction(99, 25), Fraction(4, 1), Fraction(101, 25), Fraction(102, 25), Fraction(103, 25), Fraction(104, 25), Fraction(21, 5), Fraction(106, 25), Fraction(107, 25), Fraction(108, 25), Fraction(109, 25), Fraction(22, 5), Fraction(111, 25), Fraction(112, 25), Fraction(113, 25), Fraction(114, 25), Fraction(23, 5), Fraction(116, 25), Fraction(117, 25), Fraction(118, 25), Fraction(119, 25), Fraction(24, 5), Fraction(121, 25), Fraction(122, 25), Fraction(123, 25), Fraction(124, 25), Fraction(5, 1), Fraction(126, 25), Fraction(127, 25), Fraction(128, 25), Fraction(129, 25), Fraction(26, 5), Fraction(131, 25), Fraction(132, 25), Fraction(133, 25), Fraction(134, 25), Fraction(27, 5), Fraction(136, 25), Fraction(137, 25), Fraction(138, 25), Fraction(139, 25), Fraction(28, 5), Fraction(141, 25), Fraction(142, 25), Fraction(143, 25), Fraction(144, 25), Fraction(29, 5), Fraction(146, 25), Fraction(147, 25), Fraction(148, 25), Fraction(149, 25), Fraction(6, 1), Fraction(151, 25), Fraction(152, 25), Fraction(153, 25), Fraction(154, 25), Fraction(31, 5), Fraction(156, 25), Fraction(157, 25), Fraction(158, 25), Fraction(159, 25), Fraction(32, 5), Fraction(161, 25), Fraction(162, 25), Fraction(163, 25), Fraction(164, 25)]
# 25.0
torchvision.io.write_video()
原始碼:https://pytorch.org/docs/stable/_modules/torchvision/io/video.html#write_video
Parameters
filename (str) – path where the video will be saved
video_array (Tensor[T, H, W, C]) – tensor containing the individual frames, as a uint8 tensor in [T, H, W, C] format
fps (Number) – frames per second
class torchvision.io.VideoReader(path, stream='video')
官方檔案:https://pytorch.org/docs/stable/torchvision/io.html#fine-grained-video-api
Fine-grained video-reading API. Supports frame-by-frame reading of various streams from a single video container.
Parameters
path (string) – Path to the video file in supported format
stream (string, optional) – descriptor of the required stream, followed by the stream id, in the format
{stream_type}:{stream_id}. Defaults to"video:0". Currently available options include['video', 'audio']
注意:我使用的時候報出了如下錯誤,原因是 VideoReader 還在測驗【Beta】中,網上有人說安裝 ffmpeg 后就可以了,但是我試了不管是在系統還是在 conda 下安裝都沒有用,還是等正式推出之后再說吧,,,

參考:
- "RuntimeError: Not compiled with video_reader support" raises when I use the new fine-grained VideoReader API. https://github.com/pytorch/vision/issues/2934#issuecomment-718834813
- 官方解釋報錯鏈接(還在測驗【Beta】中):https://github.com/pytorch/vision/releases/tag/v0.8.0
- ffmpeg 的 conda 下載與安裝:conda install ffmpeg
- ffmpeg 的 windows 下載與安裝:https://www.zhihu.com/question/288655694/answer/1605692761
常用函式:
- __next__() :Decodes and returns the next frame of the current stream
Returns:
a dictionary with fields
dataandptscontaining decoded frame and corresponding timestamp
- get_metadata():Returns video metadata
Returns:
dictionary containing duration and frame rate for every stream
- seek(time_s: float):Seek within current stream.
Parameters
time_s (float) – seek time in seconds
Video Transform 視頻變換操作
官方原始碼:
- https://github.com/pytorch/vision/blob/master/torchvision/transforms/_functional_video.py(比下一個鏈接更底層一點)
- https://github.com/pytorch/vision/blob/master/torchvision/transforms/_transforms_video.py(上一個鏈接包裝了一下)
我暫時沒有找到官方檔案,不過從原始碼里的注釋里也能明白,
第二個鏈接里官方給出的 video 相關的 Transform 函式如下:
- RandomCropVideo
- RandomResizedCropVideo
- CenterCropVideo
- NormalizeVideo
- ToTensorVideo
- RandomHorizontalFlipVideo
ToTensorVideo()
Convert tensor data type from uint8 to float, divide value by 255.0 and permute the dimensions of clip tensor.
和圖片的 ToTensor() 操作類似,但要注意維度的順序!
Args:
clip (torch.tensor, dtype=torch.uint8): Size is (T, H, W, C)
Return:
clip (torch.tensor, dtype=torch.float): Size is (C, T, H, W)
NormalizeVideo()
Normalize the video clip by mean subtraction and division by standard deviation.
和圖片的 Normalize() 函式是一致的,不過圖片通常使用 ImageNet 的 mean 和 std,視頻用的是 Kinetics-400 的 mean = [0.43216, 0.394666, 0.37645] and std = [0.22803, 0.22145, 0.216989](來源:https://pytorch.org/docs/stable/torchvision/models.html#video-classification) ,
Args:
mean (3-tuple): pixel RGB mean
std (3-tuple): pixel RGB standard deviation
inplace (boolean): whether do in-place normalization
RandomHorizontalFlipVideo()
Flip the video clip along the horizonal direction with a given probability.
沒有 Video Vertically Flip 也能理解吧
Args:
p (float): probability of the clip being flipped. Default value is 0.5
CenterCropVideo()
Args:
clip (torch.tensor): Video clip to be cropped. Size is (C, T, H, W)crop_size: int / tuple
Returns:
torch.tensor: central cropping of video clip. Size is (C, T, crop_size, crop_size)
RandomCropVideo()
Args:
clip (torch.tensor): Video clip to be cropped. Size is (C, T, H, W)size: int / tuple
Returns:
torch.tensor: randomly cropped/resized video clip.
RandomResizedCropVideo()
Args:
clip (torch.tensor): Video clip to be cropped. Size is (C, T, H, W)scale:【Default】(0.08, 1.0)
ratio:【Default】(3.0 / 4.0, 4.0 / 3.0)
interpolation_mode:【Default】"bilinear"
Returns:
torch.tensor: randomly cropped/resized video clip.
Example
import torchvision.transforms as transform
import torchvision.transforms._transforms_video as v_transform
import torchvision.io as io
vframes, aframes, info = io.read_video(
filename='path/v_ApplyEyeMakeup_g01_c01.avi',
pts_unit='pts',
)
trans = transform.Compose([
v_transform.ToTensorVideo(),
v_transform.RandomHorizontalFlipVideo(),
v_transform.RandomResizedCropVideo(112),
])
print(vframes.shape)
print(trans(vframes))
print(trans(vframes).shape)
# output:
# 原來的 video clip tensor's shape:torch.Size([164, 240, 320, 3])
# Transform 后的 video clip tensor's shape:torch.Size([3, 164, 112, 112])
Video Classification Model 視頻動作分類模型
官方檔案:https://pytorch.org/docs/stable/torchvision/models.html#video-classification
原始碼:https://pytorch.org/docs/stable/_modules/torchvision/models/video/resnet.html
模型:
-
ResNet 3D 18
-
ResNet MC 18
-
ResNet (2+1)D
這些模型我沒太詳細接觸過,檔案里已經非常貼心的給出了相應的論文:https://arxiv.org/abs/1711.11248,
Parameters
pretrained (bool) – If True, returns a model pre-trained on Kinetics-400
progress (bool) – If True, displays a progress bar of the download to stderr
Returns
Network
Example
import torchvision.models.video as v_model
model = v_model.r3d_18(pretrained=True)
print(model)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259568.html
標籤:其他