目錄
一、語意分割概述
二、演算法原理
2.1 BiSeNetV2演算法簡述
2.1.1 細節分支
2.1.2 語意分支
2.1.3 雙邊特征指導聚合(BGA)
2.1.4 分割頭設計和增強訓練策略
2.2 BiSeNetV2完整模型
三、訓練
3.1 準備開發環境
3.2 資料集
3.2.1 資料集介紹
3.2.2 標簽掩碼圖轉換
3.2.3生成訓練、驗證串列檔案
3.3 訓練
四、推理部署
4.1 Python腳本推理
4.1.1 單樣本測驗
4.1.2 基于視頻的實時背景替換
4.2基于Django的線上Web部署
4.2.1 簡單部署
4.2.2 高并發部署
五、總結
六、參考文獻
一、語意分割概述
影像語意分割是一種將影像分割成一系列具有特定語意類別屬性區域的方法,目前已成為當前影像理解分析和計算機視覺 等領 域的熱點研究內容,簡單舉個例子,下圖為例:


上邊是一張自然街景拍攝的圖片,下邊是對應的語意分割圖,可以看到,分割的結果就是將同類的物體全都用一種顏色標注出來,每一類物體就是一種“語意”,例如圖中人是一類語意,馬路是一類語意,樹是一類語意,電線桿是一類語意,等等,語意分割就是要按照語意類別進行分割,如果兩個像素靠的很近,例如圖中的人和樹,但是它們不屬于同一個語意類別,那么語意分割演算法就需要將他們分割開來,可以看到,語意分割相比傳統的分割添加了語意的概念,它需要演算法具備一定的先驗知識,大體上“知道”人是什么樣子、樹是什么樣子、馬路是什么樣子,有了這種先驗知識,才能準確的對影像每個像素進行分割(標注),
如果從分類的角度來看這個問題,那么語意分割可以理解為為影像中的每個像素進行分類,類別就是影像中所有的語意種類(個數),相比計算機視覺中一般的分類問題,語意分割的難度更大,因為其精度需要精確至像素級別,
語意分割方法按照時間可以大致分為兩類:傳統方法和深度學習方法,
- 傳統方法:主要采用馬爾科夫隨機場(MRF)和條件隨機場(CRF)等方法進行數學建模,方法相對簡單,運行速度快,缺點就是缺乏有效的先驗知識,分割精度低;
- 深度學習方法:目前主流的語意分割演算法都是采用深度學習來實作,較傳統演算法來說,深度學習方法可以充分利用大樣本資料的先驗知識得到更佳的分割性能;
語意分割技術可以對整幅影像進行像素級的分析,目前,語意分割已經被廣泛應用于自動駕駛、無人機落點判定、地質檢測、面部分析、精準農業等場景中,本文將從語意分割角度切入,以人像分割任務為例,詳細講解如何利用語意分割技術實作一款實時視頻去背景產品,其核心在于利用語意分割技術實作復雜背景下的人像分割,
本文采用百度開源的Paddle深度學習框架,安裝和使用方式可以參照官網執行,之所以采用百度Paddle框架是因為paddle有眾多官方維護的CV代碼套件,涵蓋影像分類、目標檢測、語意分割、OCR文字識別、GAN等,這些現成的代碼套件可以開箱即用,有比較好的維護,幾乎包含當前一系列主流深度學習演算法,同時,最新的paddle動態圖框架可以讓我們像Pytorch一樣非常容易的了解演算法代碼并且能夠除錯、改動代碼,另外,我們訓練出來的模型可以方便的使用動態圖轉靜態圖功能完成多平臺部署,同時,如果部署環境資源受限(例如移動端),paddle也提供了相應的量化裁減工具和輕量級模型轉換工具paddle lite,可以方便我們對這些模型進行生產級部署,整體來說,Paddle在國產框架中目前使用量第一,整個生態環境較好,相對其它國產框架更加成熟,即使和tensorflow和pytorch相比也有一定的優勢,選擇Paddle開發人工智能產品是一個不錯的選擇,
二、演算法原理
目前,很多人像分割模型為了盡可能的提高分割精度,在模型選擇上都選擇了重量級模型,盡管精度較高,但是不能滿足實時性分割要求,例如面向視頻的實時背景替換,為了能夠達到實時的分割速度,同時保證一定的分割精度,本文實作時以實時語意分割演算法為主,借鑒論文BiSeNetV2實作人像分割任務,從而能夠從相對復雜背景中分割出人像區域,
2.1 BiSeNetV2演算法簡述
本文采用BiSeNetV2來實作,考慮到實時性和精度雙重要求,BiSeNetV2是一個性價比較高的折中方案,具體速度和精度指標如下圖所示:
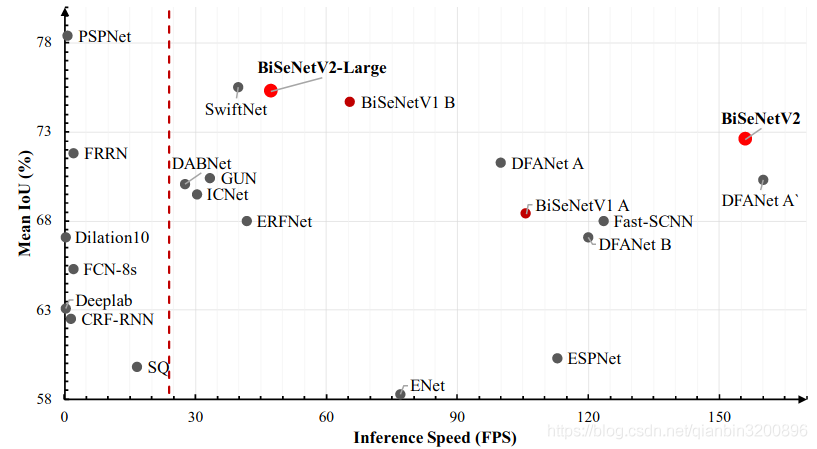
從BiSeNetV2論文中給出的資料來看,對于2048x1024解析度的影像,其速度在1張GTX1080Ti上可以達到156FPS,當然這個速度需要借助tensorrt框架,但是其強勁的性能還是非常吸引人的,
BiSeNet演算法基本原理如下:
(1) 整個網路分成兩個分支,分別為語意分支和細節分支,其中語意分支網路層深、通道數窄,這樣可以快速實作下采樣,獲得更多的背景關系語意資訊,而通道數窄則利于速度的提升,細節分支與之相反,網路層淺、通道數寬,這樣可以將注意力集中于區域細節,減少細節的損失,從感性角度分析,這個模型在設計上是非常合理的,即對于語意部分,更應關注背景關系語意資訊,更應該準確的從宏觀上進行類別區分,當然為了提高速度其通道數可以窄一些,對于細節部分,如果使用較深的層數勢必會降低特征解析度,進而丟失細節資訊,因此,對于細節部分只需要使用遷層模型即可,在論文中,語意分支的通道數設定為細節分支的倍,
可以設定為1/4,基本結構如下圖所示,
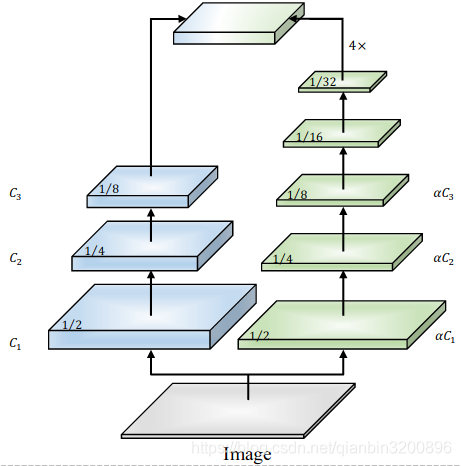
這里需要說明的是上述兩個分支中間并沒有鏈接,這個與典型的編解碼網路是不同的,這樣可以減少記憶體消耗,
(2)兩個分支網路最后通過精心設計的聚合模塊進行特征聚合,實作特征互補
BiSeNetV2完整的網路結構如下圖所示:
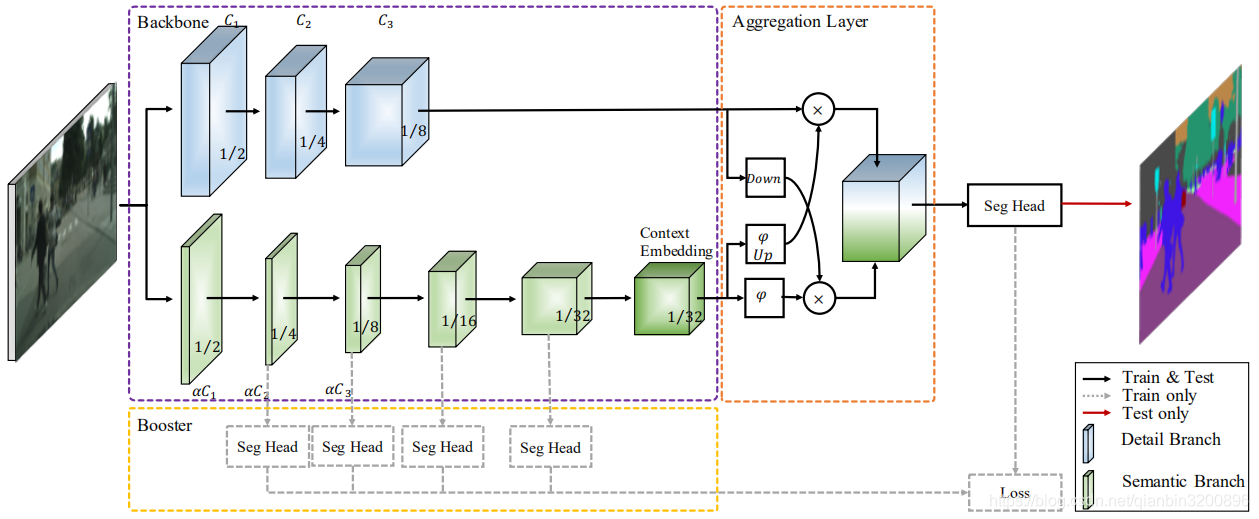
紫色虛框中的是對應的兩個分支網路,然后橙色框中的是最后的特征聚合網路,最后通過一個Seg Head分割頭得到最終的分割結果,為了進一步提高分割精度,作者額外設計了幾個分割頭,在黃色框中給出,這些額外的分割頭只有在訓練的時候會使用,在推理測驗的時候是不需要這些分割頭的,因此這種操作可以提高最終的推理精度但是又不會降低推理速度,是一個比較好的trick,上圖中Down表示下采樣,Up表示上采樣,表示Sigmoid激活函式,
2.1.1 細節分支
細節分支一共包含3個階段,每個階段含有兩個或3卷積,其中第一個卷積的滑動步長stride=2,其余卷積滑動步長stride=1,因此,每個階段都會對影像特征縮小一倍,最后,三階段結束后輸出特征解析度變為原始影像的1/8,詳細的結構引數如下表所示:
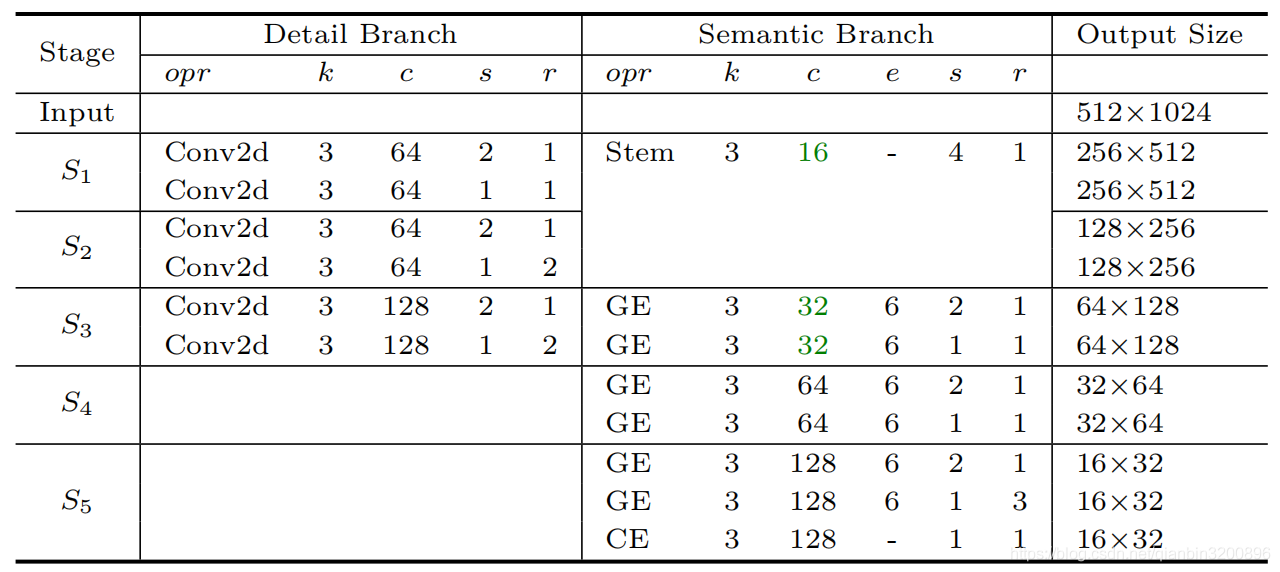
其中k表示核尺寸,c表示輸出通道數,s表示滑動步長,r表示重復次數,e表示通道擴展倍數,下面對照動態圖代碼具體看一下細節分支的實作方式:
class DetailBranch(nn.Layer):
def __init__(self, in_channels):
super().__init__()
C1, C2, C3 = 64, 64, 128
self.convs = nn.Sequential(
# stage 1
layers.ConvBNReLU(3, C1, 3, stride=2),
layers.ConvBNReLU(C1, C1, 3),
# stage 2
layers.ConvBNReLU(C1, C2, 3, stride=2),
layers.ConvBNReLU(C2, C2, 3),
layers.ConvBNReLU(C2, C2, 3),
# stage 3
layers.ConvBNReLU(C2, C3, 3, stride=2),
layers.ConvBNReLU(C3, C3, 3),
layers.ConvBNReLU(C3, C3, 3),
)
def forward(self, x):
return self.convs(x)其中ConvBNReLU表示卷積、BN歸一化和Relu激活三個操作,
2.1.2 語意分支
BiSeNetV2在設計語意分支的時候使用了很多特殊的子模塊,具體包括3種:Stem Block(Stem)、Gather and Expansion Block(GE)、Context Embedding Block(CE),下面逐步進行講解,
(1)Stem Block(Stem)
參考前面的表格,Stem Block跨越兩個階段S1和S2,影像解析度最終降低為原來的1/4,其基本結構如下圖所示:
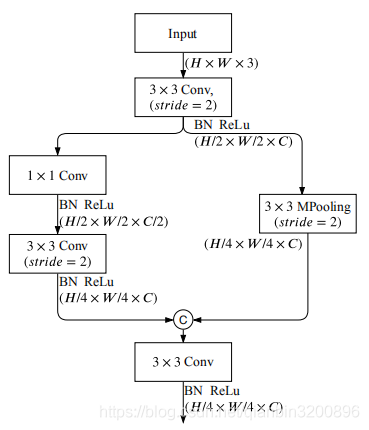
其結構思路是比較清晰的,也是分成兩個短分支,一路分支正常的走兩個卷積操作,另一路分支走一個最大池化操作,最后兩路按通道級聯(通道數擴大一倍)再經過一個卷積作為輸出,模型代碼如下所示:
class StemBlock(nn.Layer):
def __init__(self, in_dim, out_dim):
super(StemBlock, self).__init__()
self.conv = layers.ConvBNReLU(in_dim, out_dim, 3, stride=2)
self.left = nn.Sequential(
layers.ConvBNReLU(out_dim, out_dim // 2, 1),
layers.ConvBNReLU(out_dim // 2, out_dim, 3, stride=2))
self.right = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.fuse = layers.ConvBNReLU(out_dim * 2, out_dim, 3)
def forward(self, x):
x = self.conv(x)
left = self.left(x)
right = self.right(x)
concat = paddle.concat([left, right], axis=1)
return self.fuse(concat)(2)Gather and Expansion Block(GE)
在S3、S4、S5階段主要使用Gather and Expansion Block(GE)來提取語意特征,影像解析度進一步降低,這個GE操作主要借鑒MobileNet中的深度可分離卷積depth-wise convolution(關于深度可分離卷積的概念可以參考另一篇博客),相比普通cnn卷積其運算量大幅下降,而模型精度卻可以得到有效保證,這里GE模塊一共設計了兩種結構,一種是針對stride=1的情況,還有一種是針對stride=2的情況,兩種結構如下圖所示:
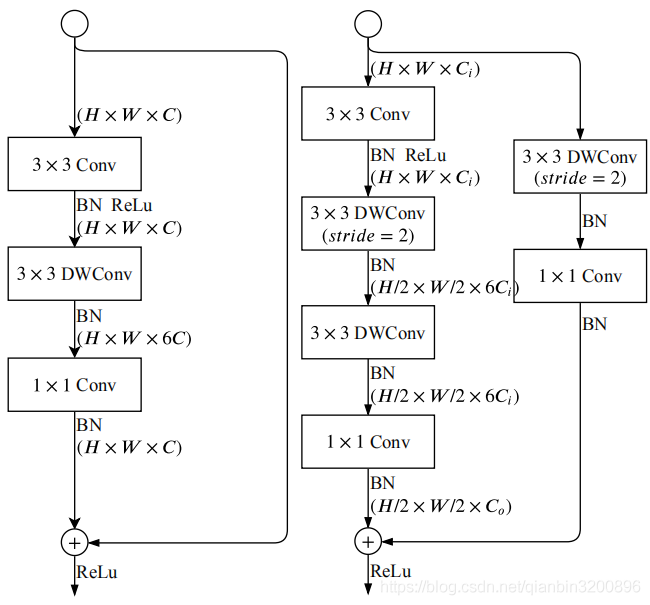
基本思路就是通過3x3卷積來聚合特征,然后使用3x3深度可分離卷積來擴展影像通道,最后再使用1x1卷積進行降維,因此這個子模型名稱翻譯過來就叫"聚合-擴展"模型,
第一種結構代碼如下:
class GatherAndExpansionLayer1(nn.Layer):
"""Gather And Expansion Layer with stride 1"""
def __init__(self, in_dim, out_dim, expand):
super().__init__()
expand_dim = expand * in_dim
self.conv = nn.Sequential(
layers.ConvBNReLU(in_dim, in_dim, 3),
layers.DepthwiseConvBN(in_dim, expand_dim, 3),
layers.ConvBN(expand_dim, out_dim, 1))
def forward(self, x):
return F.relu(self.conv(x) + x)需要注意的是這里并沒有像MobileNetV2那樣使用ReLu6作為激活函式,這樣也方便未來模型的靜態匯出和轉化,
第二種結構代碼如下:
class GatherAndExpansionLayer2(nn.Layer):
"""Gather And Expansion Layer with stride 2"""
def __init__(self, in_dim, out_dim, expand):
super().__init__()
expand_dim = expand * in_dim
self.branch_1 = nn.Sequential(
layers.ConvBNReLU(in_dim, in_dim, 3),
layers.DepthwiseConvBN(in_dim, expand_dim, 3, stride=2),
layers.DepthwiseConvBN(expand_dim, expand_dim, 3),
layers.ConvBN(expand_dim, out_dim, 1))
self.branch_2 = nn.Sequential(
layers.DepthwiseConvBN(in_dim, in_dim, 3, stride=2),
layers.ConvBN(in_dim, out_dim, 1))
def forward(self, x):
return F.relu(self.branch_1(x) + self.branch_2(x))(3)Context Embedding Block(CE)
在S5階段的最后一個部分,使用了Context Embedding Block(CE),該模塊主要是為了進一步獲取背景關系語意資訊,因此采用全域平均池化操作來提取特征,基本結構如下圖所示:
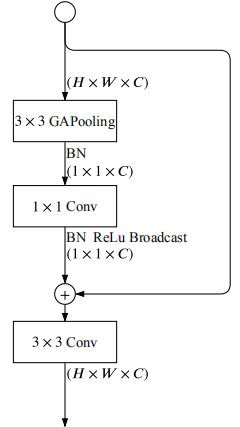
值得注意的是該模塊并沒有改變原特征大小和通道數,模型代碼如下:
class ContextEmbeddingBlock(nn.Layer):
def __init__(self, in_dim, out_dim):
super(ContextEmbeddingBlock, self).__init__()
self.gap = nn.AdaptiveAvgPool2D(1)
self.bn = layers.SyncBatchNorm(in_dim)
self.conv_1x1 = layers.ConvBNReLU(in_dim, out_dim, 1)
self.conv_3x3 = nn.Conv2D(out_dim, out_dim, 3, 1, 1)
def forward(self, x):
gap = self.gap(x)
bn = self.bn(gap)
conv1 = self.conv_1x1(bn) + x
return self.conv_3x3(conv1)整體實作還是比較簡單的,
從上述語意分支可以看到,該分支整體上使用了多種模塊結構,其必要性還需要后期實驗驗證,如果客戶對模型速度非常苛刻的話,那么可以嘗試洗掉其中一部分結構,讓整體速度再快一點,
2.1.3 雙邊特征指導聚合(BGA)
前面介紹了BiSeNet的語意分支和細節分支,最后,需要設計一種結構模型將這兩路分支的特征進行合并,實作特征互補融合,BiSeNetV2設計了名為BGA的融合模型,其模型結構如下:
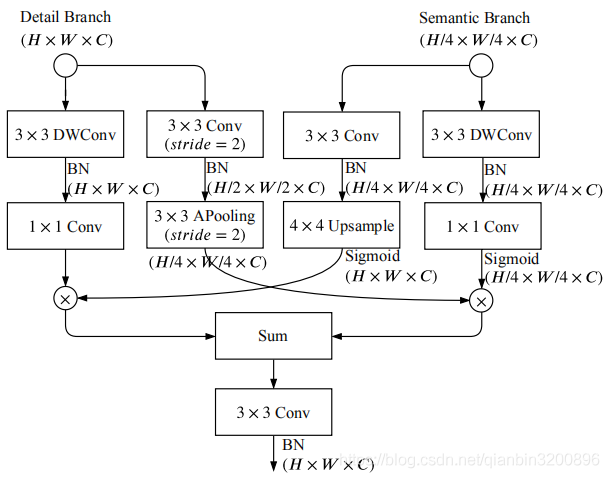
主要思想就是在兩個尺度層面實作特征融合,由語意分割特征來指導細節特征,該模型代碼如下:
class BGA(nn.Layer):
"""The Bilateral Guided Aggregation Layer, used to fuse the semantic features and spatial features."""
def __init__(self, out_dim, align_corners):
super().__init__()
self.align_corners = align_corners
self.db_branch_keep = nn.Sequential(
layers.DepthwiseConvBN(out_dim, out_dim, 3),
nn.Conv2D(out_dim, out_dim, 1))
self.db_branch_down = nn.Sequential(
layers.ConvBN(out_dim, out_dim, 3, stride=2),
nn.AvgPool2D(kernel_size=3, stride=2, padding=1))
self.sb_branch_keep = nn.Sequential(
layers.DepthwiseConvBN(out_dim, out_dim, 3),
nn.Conv2D(out_dim, out_dim, 1), layers.Activation(act='sigmoid'))
self.sb_branch_up = layers.ConvBN(out_dim, out_dim, 3)
self.conv = layers.ConvBN(out_dim, out_dim, 3)
def forward(self, dfm, sfm):
db_feat_keep = self.db_branch_keep(dfm)
db_feat_down = self.db_branch_down(dfm)
sb_feat_keep = self.sb_branch_keep(sfm)
sb_feat_up = self.sb_branch_up(sfm)
sb_feat_up = F.interpolate(
sb_feat_up,
db_feat_keep.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
sb_feat_up = F.sigmoid(sb_feat_up)
db_feat = db_feat_keep * sb_feat_up
sb_feat = db_feat_down * sb_feat_keep
sb_feat = F.interpolate(
sb_feat,
db_feat.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
return self.conv(db_feat + sb_feat)
2.1.4 分割頭設計和增強訓練策略
分割頭主要是為了輸出最后的分割結果,其模型結構比較簡單,如下圖所示:
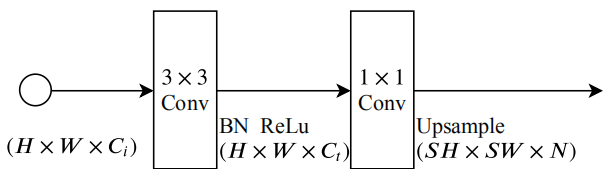
通過兩個卷積完成特征的調整,最后再通過上采樣還原成原始的特征大小,代碼如下所示:
class SegHead(nn.Layer):
def __init__(self, in_dim, mid_dim, num_classes):
super().__init__()
self.conv_3x3 = nn.Sequential(
layers.ConvBNReLU(in_dim, mid_dim, 3), nn.Dropout(0.1))
self.conv_1x1 = nn.Conv2D(mid_dim, num_classes, 1, 1)
def forward(self, x):
conv1 = self.conv_3x3(x)
conv2 = self.conv_1x1(conv1)
return conv2需要注意,在BiSeNetV2的訓練階段,作者提出了利用多個分割頭嵌入在語意分支的不同層來增強訓練,各個分割頭的輸出結果一起作為損失函式來指導訓練,在推理時則去除這些多余的分割頭,這樣可以在訓練的時候更多的利用語意分割資訊指導訓練向更優的結果靠攏,同時在推理時幾乎不降低推理速度,這種增強trick在實際使用時往往會有一定的精度提升,
2.2 BiSeNetV2完整模型
匯總前面講述的各個子模型結構,下面給出BiSeNetV2完整的模型代碼:
class BiSeNetV2(nn.Layer):
"""
The BiSeNet V2 implementation based on PaddlePaddle.
The original article refers to
Yu, Changqian, et al. "BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation"
(https://arxiv.org/abs/2004.02147)
Args:
num_classes (int): The unique number of target classes.
lambd (float, optional): A factor for controlling the size of semantic branch channels. Default: 0.25.
pretrained (str, optional): The path or url of pretrained model. Default: None.
"""
def __init__(self,
num_classes,
lambd=0.25,
align_corners=False,
pretrained=None):
super().__init__()
C1, C2, C3 = 64, 64, 128
db_channels = (C1, C2, C3)
C1, C3, C4, C5 = int(C1 * lambd), int(C3 * lambd), 64, 128
sb_channels = (C1, C3, C4, C5)
mid_channels = 128
self.db = DetailBranch(db_channels)
self.sb = SemanticBranch(sb_channels)
self.bga = BGA(mid_channels, align_corners)
self.aux_head1 = SegHead(C1, C1, num_classes)
self.aux_head2 = SegHead(C3, C3, num_classes)
self.aux_head3 = SegHead(C4, C4, num_classes)
self.aux_head4 = SegHead(C5, C5, num_classes)
self.head = SegHead(mid_channels, mid_channels, num_classes)
self.align_corners = align_corners
self.pretrained = pretrained
self.init_weight()
def forward(self, x):
dfm = self.db(x)
feat1, feat2, feat3, feat4, sfm = self.sb(x)
logit1 = self.aux_head1(feat1)
logit2 = self.aux_head2(feat2)
logit3 = self.aux_head3(feat3)
logit4 = self.aux_head4(feat4)
logit = self.head(self.bga(dfm, sfm))
logit_list = [logit, logit1, logit2, logit3, logit4]
logit_list = [
F.interpolate(
logit,
x.shape[2:],
mode='bilinear',
align_corners=self.align_corners) for logit in logit_list
]
return logit_list上述模型在輸出時輸出了5個分割頭的結果,組成了一個分割影像串列,在訓練的時候會全部用到這5個結果,在推理的時候只取第一個,
三、訓練
3.1 準備開發環境
本文訓練部分全部采用Python代碼,Python版本為3.6.9,作業系統為Ubuntu 18.04,使用兩塊英偉達顯卡GeForce GTX 1080 Ti進行分布式訓練,為了方便后續PC端C++集成,cuda版本為10.0,cudnn版本為7.6(這個版本Paddle官方有提供對應的編譯好的C++預測庫),如果讀者想要運行本文代碼,請按照上述配置安裝python、cuda和cudnn,
本文訓練代碼采用百度Paddle框架,版本為最新的動態圖版本PaddlePaddle2.0.0-rc1,安裝方式可以參照官網執行,模塊代碼主要基于paddleseg語意分割庫,為了使用該語意分割庫,需要使用下述命令安裝一下:
pip install paddleseg然后再把本文提供的代碼下載下來即可開始下面的訓練和推理,
3.2 資料集
3.2.1 資料集介紹
本文采用愛分割提供的人像分割資料集來訓練和測驗,該資料集總共包含34425張影像,每張影像尺寸均已調整為600x800,并且同時提供對應的groundtruth,部分樣例如下圖所示:
原圖:

groundtruth:

從實際觀測效果來看,該資料集的alpha圖示注并不精確,盡管如此,我們還是可以用它來訓練一個較好的人像語意分割模型,需要注意的是該資料集的標注形式并不是以常見的alpha通道圖給出,而是直接給出了摳圖前景,我們實際的任務是需要將資料集的label影像制作成只有0和1兩個值圖,因此在處理該資料集時需要先將alpha通道提取出來,然后進行二值分割即可,分割閾值可以設定為50,本文為了方便各位讀者,已經將資料集二值分割完畢,效果如下所示:
原圖:

label圖:

這里需要注意的是,為了能夠直觀的看到人像前景分割效果,在資料處理時將灰度大于50的值全部設定為255,而小于50的全部設定為0,即整個影像只有0和255兩種值,這與paddleseg需要的只有0、1兩種標簽的資料集不一致,因此還要對資料標簽進行轉化,
3.2.2 標簽掩碼圖轉換
首先在data目錄下新建ai_fen_ge檔案夾用于存放愛分割資料集,然后在該檔案夾下存放img和gt子檔案夾,分別存放原始png影像和對應的真值掩碼圖,下面要做的第一件事就是將gt中的真值掩碼圖進行轉換,轉換結果存放在同目錄下名為label的子檔案夾中,轉換腳本如下:
import os
import cv2
import random
img_folder='img'
gt_folder='gt'
label_folder='label'
fileNameLst=os.listdir(img_folder)
random.shuffle(fileNameLst)
img_index=1
for i in range(len(fileNameLst)):
if(os.path.splitext(fileNameLst[i])[1]=='.png'):
# 讀取gt影像
label = cv2.imread(os.path.join(gt_folder,fileNameLst[i]),cv2.IMREAD_GRAYSCALE)
label[label<50]=0
label[label>=50]=1
num0=sum(sum(label==0))
num1=sum(sum(label==1))
if (num0+num1) != label.shape[0]*label.shape[1]:
print('當前轉化出錯')
break
# 影像保存
labelpath=os.path.join(label_folder,fileNameLst[i])
cv2.imwrite(labelpath,label)
print('當前完成第 '+str(img_index)+' 張圖片')
img_index=img_index+1轉換完成以后再看轉化的資料標簽,會有一個問題出現,因為標簽圖中只有0和1兩個值,在灰度呈現上因值太小無法直觀的觀察轉換結果,這里我們可以采用paddle之前提供的一個腳本,將這些標簽影像再轉化成可以直接觀看的彩色標簽圖,而這些彩色標簽圖也是可以直接被paddleseg正確讀取的,
在當前檔案夾下再創建1個檔案夾名為colorlabel,然后使用腳本gray2pseudo_color.py來進行轉換,輸入命令如下:
python gray2pseudo_color.py label colorlabel轉換結果如下圖所示:

通過上圖可以比較直觀的觀察標簽結果,
3.2.3生成訓練、驗證串列檔案
paddle動態圖和pytorch很類似,在讀取檔案時為了方便后面分布式訓練,可以先將圖片路徑和對應的標簽路徑分別寫入txt檔案中,后面讀取時根據這個txt檔案來定位影像位置,在生成txt時即可指明訓練集和驗證集,
因為愛分割資料集樣本比較多,共34425張,這里將其中的30000張取出用于訓練,余下的4425張用于驗證,完整轉換腳本如下:
import os
import cv2
import random
img_folder = 'img'
label_folder = 'colorlabel'
trainlst = 'train_list.txt'
vallst = 'val_list.txt'
# 獲取檔案夾內檔案名
filenamelst = os.listdir(img_folder)
random.shuffle (filenamelst)
trainnamelst = filenamelst[0:30000]
valnamelst = filenamelst[30000:]
index = 1
# 寫入訓練樣本檔案
f=open(trainlst, 'a', encoding='utf-8')
for i in range(len(trainnamelst)):
# 判斷當前檔案
imgname = trainnamelst[i]
imgpath = img_folder + '/' + imgname
img = cv2.imread(imgpath, cv2.IMREAD_COLOR)
if img is None:
print("當前影像出錯")
print(imgpath)
break
name = imgname[15:]
labelpath = label_folder + '/' + imgname
label = cv2.imread(labelpath, cv2.IMREAD_GRAYSCALE)
if label is None:
print("當前影像出錯")
print(labelpath)
break
#寫入lst檔案
text = imgpath + ' ' + labelpath + '\n'
f.write(text)
print('寫完第 '+str(index)+' 張圖片')
index=index+1
f.close()
# 寫入驗證樣本檔案
f=open(vallst, 'a', encoding='utf-8')
for i in range(len(valnamelst)):
# 判斷當前檔案
imgname = valnamelst[i]
imgpath = img_folder + '/' + imgname
img = cv2.imread(imgpath, cv2.IMREAD_COLOR)
if img is None:
print("當前影像出錯")
print(imgpath)
break
name = imgname[15:]
labelpath = label_folder + '/' + imgname
label = cv2.imread(labelpath, cv2.IMREAD_GRAYSCALE)
if label is None:
print("當前影像出錯")
print(labelpath)
break
#寫入lst檔案
text = imgpath + ' ' + labelpath + '\n'
f.write(text)
print('寫完第 '+str(index)+' 張圖片')
index=index+1
f.close()
print('全部完成')最終在ai_fen_ge目錄下生成了train_list.txt和val_list.txt,其中每個txt的每一行同時指明了影像路徑和對應的標簽路徑(中間用空格隔開),最終的目錄結構如下圖所示:

最后說明以下,之所以采用上面的資料集格式是因為paddleseg套件對于每個資料集都是按照這個格式來存盤和讀取的,以后有類似需求的時候可以按照上面資料集的處理方法簡單修改就可以無縫銜接后面的訓練步驟了,
3.3 訓練
paddleseg套件對每個資料集的加載處理都放在了一個單獨的檔案中,具體可以查看paddleseg/datasets目錄下,如下所示:

所以為了能夠正常的訓練,我們也需要仿照其中的opti_disc_seg.py檔案,創建一個單獨的ai_fen_ge.py檔案,內容如下:
import os
from .dataset import Dataset
from paddleseg.utils import seg_env
from paddleseg.cvlibs import manager
from paddleseg.transforms import Compose
@manager.DATASETS.add_component
class AiFenGe(Dataset):
"""
愛分割資料集
Args:
transforms (list): Transforms for image.
dataset_root (str): The dataset directory. Default: None
mode (str, optional): Which part of dataset to use. it is one of ('train', 'val', 'test'). Default: 'train'.
edge (bool, optional): Whether to compute edge while training. Default: False
"""
def __init__(self,
dataset_root=None,
transforms=None,
mode='train',
edge=False):
self.dataset_root = dataset_root
self.transforms = Compose(transforms)
mode = mode.lower()
self.mode = mode
self.file_list = list()
self.num_classes = 2
self.ignore_index = 255
self.edge = edge
if mode not in ['train', 'val', 'test']:
raise ValueError(
"`mode` should be 'train', 'val' or 'test', but got {}.".format(
mode))
if self.transforms is None:
raise ValueError("`transforms` is necessary, but it is None.")
if not os.path.exists(self.dataset_root):
raise Exception("當前資料集目錄不存在\\n")
if mode == 'train':
file_path = os.path.join(self.dataset_root, 'train_list.txt')
elif mode == 'val':
file_path = os.path.join(self.dataset_root, 'val_list.txt')
else:
file_path = os.path.join(self.dataset_root, 'test_list.txt')
with open(file_path, 'r') as f:
for line in f:
items = line.strip().split()
if len(items) != 2:
if mode == 'train' or mode == 'val':
raise Exception(
"File list format incorrect! It should be"
" image_name label_name\\n")
image_path = os.path.join(self.dataset_root, items[0])
grt_path = None
else:
image_path = os.path.join(self.dataset_root, items[0])
grt_path = os.path.join(self.dataset_root, items[1])
self.file_list.append([image_path, grt_path])
上述檔案基本上只需要參照optic_disc_seg.py檔案即可,修改對應的類名就好了,paddleseg套件擁有一套比較完善的資料訓練、處理框架,按照它的框架修改對應的關鍵代碼就可以實作自己資料集的訓練,有興趣的讀者可以自行完整的閱讀paddleseg的代碼,由于采用了動態圖框架,因此可以方便的斷點除錯代碼,理解整體的資料處理流程,
接下來定義一份組態檔,具體的在configs/quick_start目錄下面創建1個名為bisenet_aifenge_320x320_3k.yml的組態檔,具體內容如下:
batch_size: 16
iters: 100000
train_dataset:
type: AiFenGe
dataset_root: data/ai_fen_ge
transforms:
- type: Resize
target_size: [320, 320]
- type: RandomHorizontalFlip
- type: Normalize
mode: train
val_dataset:
type: AiFenGe
dataset_root: data/ai_fen_ge
transforms:
- type: Resize
target_size: [320, 320]
- type: Normalize
mode: val
optimizer:
type: sgd
momentum: 0.9
weight_decay: 4.0e-5
learning_rate:
value: 0.01
decay:
type: poly
power: 0.9
end_lr: 0
loss:
types:
- type: CrossEntropyLoss
coef: [1, 1, 1, 1, 1]
model:
type: BiSeNetV2
num_classes: 2
pretrained: Null
上述組態檔有些關鍵引數需要說明,其中所有的影像大小統一到320x320進行訓練和評估,目標類別是2類
最后在paddleseg/datasets目錄下,修改__init__.py檔案,匯入AiFenGe資料處理類:
from .ai_fen_ge import AiFenGe本文使用2塊Nvidia 1080Ti顯卡進行訓練,具體執行命令如下所示:
export CUDA_VISIBLE_DEVICES=0,1
python -m paddle.distributed.launch train.py \
--config configs/quick_start/bisenet_aifenge_320x320_3k.yml \
--do_eval \
--use_vdl \
--save_interval 5000 \
--save_dir output總共耗時約8小時,訓練程序如下所示:
由于在訓練程序中開啟了VDL,因此可以使用VDL工具查看訓練曲線等,在終端中輸入命令:
visualdl --logdir output/效果如下圖所示:

接下來就可以在瀏覽器中輸入http://localhost:8040來查看曲線圖:
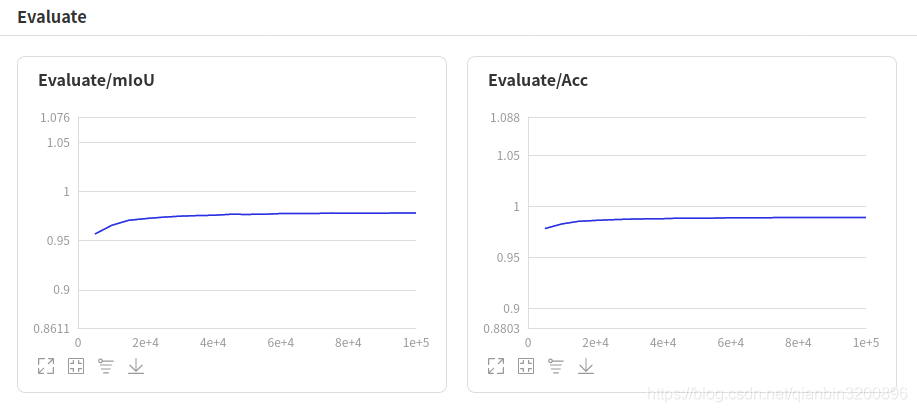
根據上述曲線圖,可以看到在接近于60000次迭代的時候已經接近收斂,mIoU漲幅不大了,最終迭代100000次,最好的mIoU=0.9781,訓練出來的動態圖模型大小為15.2M,
四、推理部署
本節開始闡述演算法推理部署環節,通過深度學習訓練出來的模型最終只有結合實際產品需要進行推理部署才能真正發揮人工智能的作用,目前,深度學習推理部署的方式大致有5種:
(1) Python腳本推理部署:使用單一python腳本進行推理,在腳本里面開個for回圈不斷處理圖片即可,這種部署方式是最簡單的,不需要對模型進行轉換,只需要按照訓練環境要求進行配置即可開始模型推理,
(2) 基于http的Web服務器推理部署:將模型呼叫腳本嵌入于web服務器中,所有請求都用http的形式將影像上傳到web服務器,服務器處理完每個請求再回傳結果,這種方式對用戶客戶端要求最低,基本不需要改動用戶客戶端即可實作人工智能應用,所有的環境配置、計算資源全部在web服務器上實作,部署簡單,呼叫方便,訓練完成后基本就可以直接進行推理,不需要對模型進行轉換操作,但是這種方式也有個很明顯的弊端,就是對服務器的計算資源要求較高,并發訪問請求比較多時容易造成服務器卡頓甚至奔潰,并且以http網路訪問的形式本身有一定的延遲,不適合在線實時任務,
(3) PC客戶端推理部署:基于深度學習的PC客戶端程式開發一般在工業質檢領域用的比較多,給一臺工控機配上一塊顯卡即可進行深度學習推理,利用深度學習進行賦能,可以很大程度上改善傳統演算法的精度問題,一般情況下為了效率和脫離python環境需要,PC桌面程式開發(C#、MFC或者QT界面框架)會采用C++語言,因此需要對訓練出來的模型進行動轉靜操作,同時要使用C++來加載和推理模型,這種部署模型好處就在于方便程式移植,并且由于演算法采用C++進行推理,速度快并且安全性高(Python是明碼可見的,C++是要先編譯成二進制語言的,因此C++程式更不容易被破譯),前提是對C++要比較了解,
(4) 移動端推理部署:現在智能手機非常普及,而且成本很低,很自然的,可以在移動手機上運行一些輕量級的深度學習演算法來獲得較好的用戶體驗,例如手機端美顏、基于人臉關鍵點檢測的特效等,一般情況下我們訓練出來的深度學習模型都比較重,往往需要對模型進行量化、裁減、剪枝等操作才能獲得適合手機端部署的模型,當然,很多深度學習框架配備了自動模型輕量化工具,例如tensorflow lite或者paddle lite等,基于移動端的深度學習部署也是當前一大熱點和難點,要有一定的安卓或者iOS開發基礎,
(5) 嵌入式推理部署(邊緣計算):考慮到實際生產部署的成本問題(畢竟GPU顯卡比較貴),以及各種場景的小型化、低功耗需求,基于嵌入式的深度學習邊緣部署方案相繼被提出,這也是現在最熱門的深度學習應用方向:邊緣計算,通過邊緣計算設備,你就可以在小型機器人上部署高精尖的深度學習模型,可以在工業質檢領域用最節省的成本運行高精度的質檢模型,當然,由于嵌入式設備資源有限,其開發有一定的難度,在所有部署方案中也是最考驗開發者能力的,現在比較流行的邊緣設備包括英偉達Jetson系列、百度Edgeboard系列、樹莓派等,其中如果想在樹莓派上運行深度學習模型可能還需要再配備類似USB的神經計算棒,邊緣計算是目前所有部署方案中難度最高的,需要掌握多種框架和語言,需要較好的模型修改能力(有些算子在邊緣設備上不支持),
本節內容以前面訓練出來的人像分割模型為例子,詳細闡述各個部署方案,使用的是paddle2 rc版本,cuda10.0,cudnn7.6,其它配置具體參見每節部署內容,
4.1 Python腳本推理
4.1.1 單樣本測驗
paddleseg套件提供了方便的predit.py檔案用于執行預測,具體使用下面的命令即可:
python predict.py \
--config configs/quick_start/bisenet_aifenge_320x320_3k.yml \
--model_path output/iter_100000/model.pdparams \
--image_path data/ai_fen_ge/test_img \
--save_dir output/result其中test_img是從網上下載的部分個人自拍照,都是上半身照片,背景不一致,預測結果存放在output/result目錄下面,并且為了能夠方便的看出分割效果,paddleseg已經將預測掩碼圖與原圖進行了合成,偏綠色部分即為預測區域,偏紫色部分即為背景區域,部分測驗效果如下所示:
















從上圖中可以看到,整體分割效果還可以,沒有出現大面積的誤判,僅僅在區域細節處例如發絲部分處理的不好,但是這個效果是可以說的通的,畢竟我們使用的愛分割訓練資料集精度不高,并且我們采用的是語意分割模型,并不是徹底的摳圖模型,對于實時語意分割模型來說,這個效果本身已經比較好了,后續如果想更進一步,那么可以級聯一個MNet模型用于精細摳圖,后面我會再開博文針對這個問題繼續改進,
根據測驗,每張影像平均耗時約40ms,能夠滿足實時分割的要求,
由于predit.py檔案封裝的比較厲害,下面我們對其進行簡化,使得后面我們能夠更加自由的使用Python進行動態圖模型預測,具體的,在專案根目錄下(即和train.py同一目錄)新建一個腳本檔案test.py,內容如下:
#匯入第三方庫
import cv2
import numpy as np
import paddle
import paddle.nn.functional as F
#匯入自定義庫
from paddleseg.models import BiSeNetV2
#引數設定
im_path='data/ai_fen_ge/test_img/1.jpg'
model_path='output/iter_100000/model.pdparams'
crop_size=(320,320)
mean=(0.5, 0.5, 0.5)
std=(0.5, 0.5, 0.5)
num_class=2
#加載模型
model = BiSeNetV2(num_class)
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
model.eval()
#開始推理
with paddle.no_grad():
#讀取影像
im = cv2.imread(im_path)
ori_shape = im.shape[:2]
#影像預處理
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, crop_size, cv2.INTER_LINEAR)
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
#轉換成4通道張量格式
im = np.transpose(im, (2, 0, 1))
im = im[np.newaxis, ...]
im = paddle.to_tensor(im)
#模型推理
logits = model(im)
logit = logits[0]
pred = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
pred = F.interpolate(pred, ori_shape, mode='nearest')
#二值掩碼影像保存
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')*255
cv2.imwrite('output/result/result.jpg', pred)
#與新背景合成
im = cv2.imread(im_path)
bg=cv2.imread('data/ai_fen_ge/bg.png')
bg=cv2.resize(bg, (ori_shape[1],ori_shape[0]), cv2.INTER_LINEAR)
alpha=cv2.cvtColor(pred,cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
comp = im * alpha_f + bg * (1. - alpha_f)
cv2.imwrite('output/result/comp.jpg', comp.astype(np.uint8))上述代碼比較干凈,已經將各個封裝的關鍵代碼抽取了出來,其中需要注意引數設定部分,需要根據具體的任務組態檔來修改這些引數,上述代碼結構比較簡單,只對一張影像進行推理,由于是兩分類任務,因此推理結果用二值化的掩碼圖來表示,最后,做了一下拓展,將分割出來的前景人物和新背景圖進行合成,最終效果如下圖所示:




從左到右依次為:原始圖、二值掩碼圖、新背景圖、新合成圖
從整體效果上看,分割效果還是相對可以的,下面就可以根據這個簡單的python腳本展開一些應用,比如視頻實時替換,具體見下一小節,
4.1.2 基于視頻的實時背景替換
目前,視頻會議在人們的作業和個人生活中變得越來越重要,在視頻會議里通過人像分割實時背景替換,可以有效保護視頻會議者的隱私,同時,也是一項有趣的體驗,本小節我們就來實作一下這個功能,具體執行比較簡單,只需要通過opencv實時的捕獲USB攝像頭,然后將每張影像用前面的人像分割模型進行分割再完成新背景合成即可,
完整代碼如下:
#匯入第三方庫
import cv2
import numpy as np
import paddle
import paddle.nn.functional as F
#匯入自定義庫
from paddleseg.models import BiSeNetV2
#引數設定
im_path='data/ai_fen_ge/test_img/1.jpg'
model_path='output/iter_100000/model.pdparams'
crop_size=(320,320)
mean=(0.5, 0.5, 0.5)
std=(0.5, 0.5, 0.5)
num_class=2
#加載模型
model = BiSeNetV2(num_class)
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
model.eval()
#開始捕獲攝像頭
cap = cv2.VideoCapture(0)
with paddle.no_grad():
while(1):
# 獲取影像
ret, orgimg = cap.read()
im=orgimg.copy()
ori_shape = im.shape[:2]
#影像預處理
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, crop_size, cv2.INTER_LINEAR)
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
#轉換成4通道張量格式
im = np.transpose(im, (2, 0, 1))
im = im[np.newaxis, ...]
im = paddle.to_tensor(im)
#模型推理
logits = model(im)
logit = logits[0]
pred = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
pred = F.interpolate(pred, ori_shape, mode='nearest')
#二值掩碼影像保存
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')*255
#與新背景合成
im=orgimg.copy()
bg=cv2.imread('data/ai_fen_ge/video_bg.png')
bg=cv2.resize(bg, (ori_shape[1],ori_shape[0]), cv2.INTER_LINEAR)
alpha=cv2.cvtColor(pred,cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
im = im * alpha_f + bg * (1. - alpha_f)
# 顯示
cv2.imshow("capture", im.astype(np.uint8))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 結束釋放資源
cap.release()
cv2.destroyAllWindows() 我的攝像頭輸出解析度是480X640,因此找了1張基本同樣長寬比的影像作為背景圖,
原始背景影像如下所示:
與新背景合成視頻如下所示:
視頻合成
在背景相對比較簡單的場景下,這種實時替換效果還是可以的,另外,從幀率上來看,還是比較快的,因此這也留下了改進空間,如果要開發實際的產品,那么一方面可以降低GPU性能(成本就可以下降),另一方面可以對BiSeNetV2演算法進一步減少通道,降低模型運算量,
4.2基于Django的線上Web部署
使用Web方式部署深度學習模型也是比較常見的一種部署方式,一般情況下,我們可以自由的對Web服務器進行環境配置,在上面搭建完整的paddle動態圖推理環境并開啟http api服務,然后所有的終端都通過http api將需要推理的影像發送至服務器進行推理,推理結果再由web回傳給各個終端,因此,這種方式對于終端來說是最方便的,它不要做任何的軟硬體改造,
本小節我們并不采用paddle現成的web部署方案paddle serving,主要原因在于如果當預測模型需要對影像進行一些預處理操作的時候,paddle serving需要用戶額外安裝一個客戶端來實作這些預處理操作,這在很多實際應用場景中是不合適、不夠用的,另一方面,完全使用paddle serving也不利于我們對整個的部署環境進行把控,真正產品級部署的時候我們還是希望能夠全方位的把握當前web運行狀態,即使出問題了也能夠快速定位和尋找解決方案,
本小節我們采用純python語言開發的web框架django來實作,這里需要注意,一般網上教程更多采用flask來講解,其本質是一樣的,flask更精煉、更適合微服務部署,而django現成的web輪子多,如果是構建一個完整的web專案的話建議還是用django更好,當然,不管是django還是flask,其核心都是用python開發的,對python具有天然的支持性,
這里也給自己不久前剛上市的一本書打個call《Python Web開發從入門到實戰》,想要快速掌握Python Web技術的讀者可以支持一下,兩者結合一方面可以使用Django快速搭建完整Web專案(例如賬戶管理,后臺管理,資料庫管理,頁面設計等),同時由于Django框架原生使用Python語言,因此可以在Django中方便的嵌入我們的深度學習模型,進行線上部署,實作AI落地,
本節內容使用windows 10系統,Web框架使用django 2.2.4,paddle還是使用最新的2.0.0版本,需要注意,前面的內容都是在Ubuntu上訓練和實作的,從本小節開始,都在Windows平臺上操作,
4.2.1 簡單部署
4.2.1.1 環境安裝
首先安裝python3.7,然后安裝英偉達cuda和cudnn,版本為cuda10.0和cudnn7.6.5,這里cuda版本強烈建議使用cuda10.0,這是為了后面能夠和嵌入式設備統一(在jetson上只提供了cuda10.0對應的預測庫),
接下來在windows上安裝paddle2.0.0,具體安裝方式可以參考官網教程,選擇好版本后就可以使用它的推薦命令進行安裝:
由于需要使用opencv進行影像加載、保存等操作,因此安裝opencv:
pip install opencv_python為了在windows系統上使用paddleseg,還需要安裝pip install filelock:
pip install filelock最后安裝django:
pip install django==2.2.44.2.1.2 創建Django專案
首先定位到PaddleSeg-release-v2.0.0-rc目錄下面,然后使用命令創建一個django專案:
django-admin startproject djangoSeg這樣在專案根目錄下創建了一個名為djangoSeg的專案,接下來切換到djangoSeg下面,然后創建一個應用:
python manage.py startapp app在djangoSeg子目錄下的settings.py檔案中添加應用,具體修改兩處地方:
ALLOWED_HOSTS = ['*',] #放開訪問權限INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app',# 添加參考
]接下來在urls.py檔案中定義一個路由:
from django.contrib import admin
from django.urls import path
from app.views import seg
urlpatterns = [
path('admin/', admin.site.urls),
path('seg/', seg, name='seg'), #定義人像分割api
]通過上述路由設定我們就定義好了分割介面的api,如果是在本地運行,那么對應的網址就是:http://127.0.0.1:8000/seg ,
到這里我們先來梳理一下具體的執行流程:
(1)啟動django服務器,啟動時加載1次深度學習模型,該模型是全域變數,這樣后面推理的時候就不需要再加載了,可以有效節省時間;
(2)服務器啟動并且加載模型后進入等待狀態,直到有請求到達;
(3)客戶端(使用python腳本或者網頁)將本地的一張影像加載并以二進制流stream的形式發送至http://127.0.0.1:8000/seg進行處理,然后開始等待服務器回傳;
(4)服務器收到請求,呼叫對應的視圖處理函式seg進行處理,首先從流中恢復出影像資料然后呼叫深度學習模型進行人像分割,然后從服務器本地加載一張固定背景圖進行合成,合成出新圖先jpg壓縮再采用base64編碼轉json回傳給客戶端;
(5)客戶端收到服務器的回傳結果,首先base64解碼再jpg解壓碩訓得回傳的影像資料,最后展示影像;
首先在manage.py同目錄下定義一個load_model.py檔案,該檔案用于加載paddle模型,代碼如下:
#匯入paddle庫
import paddle
import paddle.nn.functional as F
#匯入自定義庫
import sys
sys.path.append("..")
from paddleseg.models import BiSeNetV2
#引數設定
model_path='model.pdparams'
crop_size=(320,320)
mean=(0.5, 0.5, 0.5)
std=(0.5, 0.5, 0.5)
num_class=2
#cuda環境設定
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
#加載模型
segmodel = BiSeNetV2(num_class)
para_state_dict = paddle.load(model_path)
segmodel.set_dict(para_state_dict)
segmodel.eval()
paddle.no_grad()然后在settings.py檔案最后添加該檔案:
import load_model這樣在django程式啟動的時候就會加載1次模型了,
接下來在app/views檔案中進行視圖處理函式的撰寫:
# 匯入django庫
from django.shortcuts import render
from django.views.decorators.csrf import csrf_exempt
from django.http import JsonResponse
#匯入第三方庫
import numpy as np
import json
import cv2
import base64
#匯入paddle庫
import paddle
import paddle.nn.functional as F
#匯入全域模型和相關引數
from load_model import crop_size,mean,std,segmodel
def read_image(stream=None):
"""
從資料流中讀取影像
"""
data_temp = stream.read()
im = np.asarray(bytearray(data_temp), dtype="uint8")
im = cv2.imdecode(im, cv2.IMREAD_COLOR)
return im
@csrf_exempt
def seg(request):
result = {}
if request.method == "POST":
if request.FILES.get('image') is not None:
im = read_image(stream=request.FILES["image"])
else:
result["img64"] = ""
return JsonResponse(result)
#讀取影像
ori_shape = im.shape[:2]
org_img=im.copy()
#影像預處理
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, crop_size, cv2.INTER_LINEAR)
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
#轉換成4通道張量格式
im = np.transpose(im, (2, 0, 1))
im = im[np.newaxis, ...]
im = paddle.to_tensor(im)
#模型推理
logits = segmodel(im)
logit = logits[0]
pred = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
pred = F.interpolate(pred, ori_shape, mode='nearest')
#生成二值掩碼影像
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')*255
#與新背景合成
im = org_img.copy()
bg=cv2.imread('bg.png')
bg=cv2.resize(bg, (ori_shape[1],ori_shape[0]), cv2.INTER_LINEAR)
alpha=cv2.cvtColor(pred,cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
comp = im * alpha_f + bg * (1. - alpha_f)
im=comp.astype(np.uint8)
retval, buffer_img = cv2.imencode('.jpg', im) # 在記憶體中編碼為jpg格式
img64 = base64.b64encode(buffer_img) # base64編碼用于網路傳輸
img64 = str(img64, encoding='utf-8') # bytes轉換為str型別
result["img64"] = img64 # json封裝
return JsonResponse(result)這里注意,需要將之前訓練好的model.pdparams檔案放置在專案manage.py同目錄下面,另外還需準備一張名為bg.png的新的背景圖也放置在這個位置,
最后啟動服務即可:
python manage.py runserver啟動成功后效果如下所示:

接下里我們開始開發客戶端,這里客戶端使用python腳本來實作,具體代碼如下:
import cv2, requests
import numpy as np
import base64
url = "http://localhost:8000/seg/" #訪問介面
# 上傳影像并分割
tracker = None
imgPath = "test.jpg" #影像路徑
files = {
"image": ("filename2", open(imgPath, "rb"), "image/jpeg"),
}
#獲取結果并解碼
req = requests.post(url, data=tracker, files=files).json()
im64=req["img64"]
im64 = bytes(im64, encoding="utf-8")
img = np.frombuffer(base64.decodestring(im64),"float32")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
#結果顯示
cv2.imshow("portrait segmentation", img)
cv2.waitKey(0)從上面的客戶端腳本可以看到,客戶端并不需要paddle等深度學習環境,因此這種web部署方式對客戶端是最友好的,執行上述客戶端腳本,效果如下所示:


左圖是原始影像,右圖是服務器回傳回來的影像,
采用這種部署方式可以快速的搭建產品原型,用于產品演示和低并發情況下部署,以上內容更偏重django,因此這里我不再詳細闡述細節,有興趣的讀者可以參考我的書籍《Python Web開發從入門到實戰》系統的來學習django,
4.2.2 高并發部署
4.2.2.1 架構設計
前面我們使用django自帶的開發服務器進行部署,這個服務器只需要使用命令python manage.py runserver就可以啟動,用來除錯程式非常方便,但是這個開發者服務器本身無法滿足多并發訪問需求,因此,我們還需要把這個專案部署到真正的生產級服務器上,這里我們使用微軟的IIS服務器,另一方面,在架構設計上我們沒有充分考慮GPU本身的性能和穩定性,如果并發訪問比較多的時候,每個視圖處理函式都會呼叫全域深度學習模型變數進行推理,容易造成GPU資源沖突并且容易out of memory,另外,采用前面這種架構雖然理解比較簡單,但是很明顯,GPU是按照請求來的順序一個一個進行推理的,即batch_size永遠等于1,而我們知道,如果將當前需要處理的一部分影像按照batch進行整合然后集中推理,可以充分發揮性能優勢,提高處理速度,因此,我們需要對整體的web架構重新進行設計使得我們能夠充分發揮GPU性能并且服務器運行更加穩定,
為此本文設計了下圖所示的這個架構:
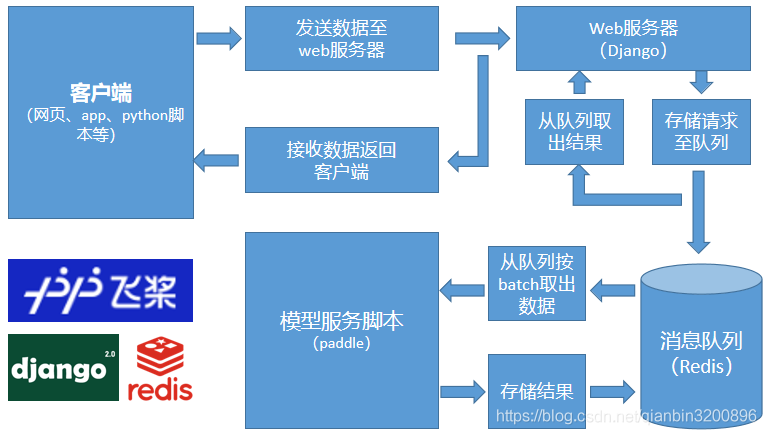
前面客戶端發過來的請求首先交給django web服務器,然后django web服務器呼叫視圖處理函式進行處理,在處理時,不直接使用深度學習模型進行推理,而是把影像推送至Redis訊息佇列,然后等待Redis處理結果,在訊息佇列后面有一個專門的深度學習模型推理腳本,這個腳本定時的從Redis訊息佇列里按照最大batch_size取出影像資料進行集中推理,推理結束后將結果寫入Redis訊息佇列,Web服務器實時的查詢訊息佇列,當發現有結果時就取出結果并回傳給客戶端,
采用上述這種架構可以將web服務器和深度學習推理模塊有效解耦,環境配置更加簡單,可以充分發揮GPU性能進行深度學習批量推理并且能夠保證GPU運行穩定性,同時通過觀察Redis訊息佇列里的當前剩余請求數就可以實時監控當前web系統是否過載,是否需要擴容等問題,
4.2.2.2 生產環境部署
在講解具體部署前,先了解一下Redis資料庫,redis是一個非關系型的快取資料庫,因為是快取所以Redis的速度會非常快(操作都是在記憶體中進行),Redis主要是依靠鍵值對進行存盤,類似于java的map、python的字典,Redis支持許多的語言,如java、C、C++、C#、PHP、JavaScript、Perl、python等,
下面講解具體的Redis安裝方法,首先從github上下載適用于windows的Redis安裝包,本文下載3.2.100版本,將其中的Redis-x64-3.2.100zip壓縮包下載下來,如下圖所示:
下載解壓后將其放置在指定目錄下,然后將該目錄添加到系統環境變數中,接下來在命令列視窗中啟動Redis:
redis-server.exe啟動后如下圖所示:
注意上述的埠號是6379,
安裝并啟動后怎么使用python連接Redis呢?這里我們可以使用現成的python包來實作,首先安裝依賴包:
pip install redis注意,這里使用pip安裝的redis僅僅是一個python橋接工具而已,有了這個工具我們就可以在python中方便的連接并使用Redis了,我們可以使用下面的代碼測驗一下:
import redis
if __name__ == "__main__":
r = redis.Redis(host="localhost",port=6379,decode_responses=True)
r.set("name","a")
print(r.get("name"))運行上述腳本,正常情況下會輸出a,當然也可以使用命令程式驗證:
redis-cli ping正常情況會輸出“PONG”,在Windows系統上有很多工具可以用來管理Redis資料庫,這些工具可以用可視化的方式查看、修改當前鍵值對,使用非常便捷,具體的本文就不再深入介紹,讀者可以自行查閱相關Redis教程,
下面正式開始進入生產級部署環節,
首先修改load_model.py檔案,這里不再需要在django中執行深度學習操作,我們只需要連接redis即可:
import redis
IMAGE_WIDTH = 320
IMAGE_HEIGHT = 320
IMAGE_DTYPE = "float32"
IMAGE_QUEUE = "image_queue"
CLIENT_SLEEP = 0.25
mean=(0.5, 0.5, 0.5)
std=(0.5, 0.5, 0.5)
db = redis.StrictRedis(host="localhost", port=6379, db=0)然后修改views.py檔案,匯入相關的庫和引數:
# 匯入django庫
from django.shortcuts import render
from django.views.decorators.csrf import csrf_exempt
from django.http import JsonResponse
#匯入第三方庫
import numpy as np
import json
import cv2
import base64
import uuid
import time
#匯入引數
from load_model import db, IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_DTYPE, mean, std, IMAGE_QUEUE, CLIENT_SLEEP由于我們需要將影像通過redis進行存盤(中轉),比較好的方式就是將影像先base64轉碼再存盤,具體添加兩個處理函式:
def base64_encode_image(a):
"""
將numpy陣列進行base64編碼
"""
return base64.b64encode(a).decode("utf-8")
def base64_decode_image(a, dtype, shape):
"""
base64轉影像
"""
a = bytes(a, encoding="utf-8")
a = np.frombuffer(base64.decodestring(a), dtype=dtype)
a = a.reshape(shape)
return a接下來修改最重要的視圖處理函式seg,具體如下:
@csrf_exempt
def seg(request):
result = {"success": False}
if request.method == "POST":
if request.FILES.get('img') is not None:
im = read_image(stream=request.FILES["img"])
else:
result["img"] = ""
result["reason"] = "image format is wrong"
return JsonResponse(result)
#讀取影像
ori_shape = im.shape[:2]
org_img = im.copy()
#影像預處理
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, (IMAGE_WIDTH, IMAGE_HEIGHT), cv2.INTER_LINEAR)
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
#轉換成4通道張量格式
im = np.transpose(im, (2, 0, 1))
im = im[np.newaxis, ...]
im = im.copy(order="C")
#影像存盤進redis
k = str(uuid.uuid4())
d = {"id": k, "img": base64_encode_image(im)}
db.rpush(IMAGE_QUEUE, json.dumps(d))
time_out_num = 0
while True:
# 嘗試獲取結果
output = db.get(k)
if output is not None:
#取出結果
output = json.loads(output.decode("utf-8"))
pred = base64_decode_image(output["img"], IMAGE_DTYPE,(1,IMAGE_HEIGHT, IMAGE_WIDTH))
pred = pred.astype('uint8')
pred = pred[0]
#與新背景合成
im = org_img.copy()
bg = cv2.imread('bg.png')
bg = cv2.resize(bg, (ori_shape[1], ori_shape[0]),cv2.INTER_LINEAR)
alpha = cv2.cvtColor(pred, cv2.COLOR_GRAY2BGR)
alpha = cv2.resize(alpha, (ori_shape[1], ori_shape[0]), cv2.INTER_NEAREST)
alpha_f = alpha / 255.
comp = im * alpha_f + bg * (1. - alpha_f)
im = comp.astype(np.uint8)
cv2.imwrite("gen.jpg",im)
#壓縮編碼
retval, buffer_img = cv2.imencode('.jpg', im) # 在記憶體中編碼為jpg格式
img64 = base64.b64encode(buffer_img)
img64 = str(img64, encoding='utf-8')
result["img"] = img64 # json封裝
result["success"] = True
result["reason"] = ""
db.delete(k)
break
time.sleep(CLIENT_SLEEP)
#設定超時機制
time_out_num = time_out_num + 1
if (time_out_num > 10):
result["success"] = False
result["img"] = ""
result["reason"] = "time out, the web server is busy now"
db.delete(k)
return JsonResponse(result)
return JsonResponse(result)上述代碼執行時,首先從資料流中取出影像資料,然后對它進行預處理(得到numpy陣列),處理完以后隨機生成一個id號,然后對影像資料進行base64轉碼再和id一起組成json字串,然后保存到redis資料庫中,接下來就是進入while回圈一直等待,直到redis中回傳了處理結果,再進行背景合成回傳結果給客戶端,如果長時間等待無回應,那么就回傳錯誤結果給前端并告知超時,
完成上述修改后就可以啟動django:
python manage.py runserver啟動成功后我們接下來就可以撰寫深度學習推理腳本,具體的創建一個run_model檔案夾(與manage.py同目錄下),然后新建run_model.py檔案和tool.py檔案,其中tool.py檔案用于存放base64編碼和解碼函式,run_model.py檔案則是主要的推理檔案,具體如下:
#匯入第三方庫
import os
import numpy as np
import json
import cv2
import base64
import time
import redis
#匯入paddle庫
import paddle
import paddle.nn.functional as F
#匯入自定義庫
import sys
sys.path.append("../..")
from paddleseg.models import BiSeNetV2
from tool import base64_encode_image,base64_decode_image
#引數設定
model_path='model.pdparams'
IMAGE_WIDTH = 320
IMAGE_HEIGHT = 320
IMAGE_DTYPE = "float32"
num_class=2
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
IMAGE_QUEUE = "image_queue"
SERVER_SLEEP = 0.25
db = redis.StrictRedis(host="localhost", port=6379, db=0)
BATCH_SIZE = 32
#加載模型
segmodel = BiSeNetV2(num_class)
para_state_dict = paddle.load(model_path)
segmodel.set_dict(para_state_dict)
segmodel.eval()
with paddle.no_grad():
while True:
# 批量獲取影像
queue = db.lrange(IMAGE_QUEUE, 0, BATCH_SIZE - 1)
imageIDs = []
batch = None
for q in queue:
# 決議影像
q = json.loads(q.decode("utf-8"))
image = base64_decode_image(q["img"], IMAGE_DTYPE,(1,3, IMAGE_HEIGHT, IMAGE_WIDTH))
if batch is None:
batch = image
else:
batch = np.vstack([batch, image])
# 更新ID
imageIDs.append(q["id"])
if len(imageIDs) > 0:
# 批量推理
print("當前Batch大小: {}".format(batch.shape))
batch = paddle.to_tensor(batch)
logits = segmodel(batch)
logit = logits[0]
preds = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
# 生成二值掩碼影像
preds = preds.numpy().astype('uint8')*255
preds = preds.astype('float32')
# 將結果寫入redis
index = 0
for imageID in imageIDs:
pred = preds[index].copy(order="C")
output = {"img": base64_encode_image(pred)}
db.set(imageID, json.dumps(output))
index = index+1
# 移除影像佇列資料
db.ltrim(IMAGE_QUEUE, len(imageIDs), -1)
time.sleep(SERVER_SLEEP)上述腳本首先載入深度學習模型,然后從redis中批量取出圖片,這里BATCH_SIZE可以根據實際的服務器GPU性能進行設定,通過這種方式可以使得GPU不會產生out of memory現象,另外,由于推理時采用了batch方式,因此相比一張一張影像推理速度更快,
完成上述撰寫后啟動腳本運行服務:
python run_model.py這樣django服務和深度學習服務都已經正常啟動了,
最后,我們寫一個客戶端腳本來測驗一下功能:
import cv2, requests
import numpy as np
import base64
url = "http://localhost:8000/seg/" #訪問介面
# 上傳影像并分割
tracker = None
imgPath = "test.jpg" #影像路徑
files = {
"img": ("filename2", open(imgPath, "rb"), "image/jpeg"),
}
#獲取結果并解碼
req = requests.post(url, data=tracker, files=files).json()
issuccess=req["success"]
if issuccess:
im64=req["img"]
im64 = bytes(im64, encoding="utf-8")
img = np.frombuffer(base64.decodestring(im64),"float32")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
#結果顯示
cv2.imshow("portrait segmentation", img)
cv2.waitKey(0)
else:
print("失敗:")
if req["reason"] is not None:
print(req["reason"])上述代碼正常成功后會顯示替換過背景的人像圖片,
接下來為了應對高并發訪問要求,我們需要將django專案部署到IIS服務器上去,由于這部分內容完全屬于django本身的內容,本文就不再詳細闡述,具體可以參考我的博客或者參考我的書籍《Python Web開發從入門到實戰》,
4.2.2.3 壓力測驗
本小節針對前面設計的高并發架構來進行壓力測驗,只需要修改客戶端代碼即可,具體如下:
# 匯入庫
from threading import Thread
import time
import cv2, requests
import numpy as np
import base64
# 引數設定
url = "http://localhost:80/seg/" # 訪問介面
imgPath = "test.jpg" # 影像路徑
NUM_REQUESTS = 500 # 并發請求數
SLEEP_COUNT = 0.05 # 請求間隔
def call_seg(n):
"""
并行發送執行緒
"""
myfile = {
"img": ("filename2", open(imgPath, "rb"), "image/jpeg"),
}
#提交影像
tracker = None
req = requests.post(url, data=tracker, files=myfile).json()
#顯示并保存結果
if (req["success"]):
print("執行緒 {} 成功".format(n))
im64 = req["img"]
im64 = bytes(im64, encoding="utf-8")
img = np.frombuffer(base64.decodestring(im64), "float32")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
imgpath = 'results/' + str(n) + '.jpg'
cv2.imwrite(imgpath, img)
else:
print("執行緒 {} 失敗".format(n))
if __name__ == '__main__':
for i in range(0, NUM_REQUESTS):
t = Thread(target=call_seg, args=(i, ))
t.daemon = True
t.start()
time.sleep(SLEEP_COUNT)
time.sleep(300)主要是通過python執行緒模擬500個訪問請求,具體執行效果如下圖所示:

同時可以看到當前GPU情況,可以看到性能是比較穩定的:
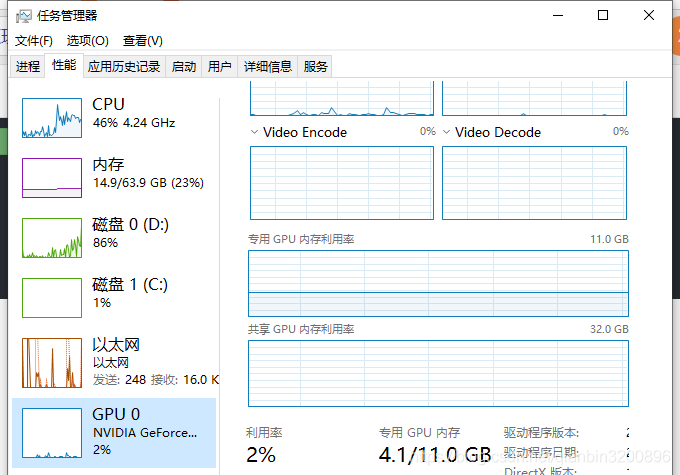
整體來看,搭建生產級的深度學習web平臺是有一定難度的,比較好的方式就是盡量解耦合、模塊化,這樣能夠避免很多環境配置限制,同時也更利于演算法開發人員和Web開發人員協同合作,本文給了一種可行方案,具體落地應用時還需要考慮很多細節和優化問題,例如怎么監控當前負載情況,怎么批量化部署等等,
以上整個web部署方案在我自己的專案中也采用了類似的架構進行了真實的專案落地應用(唯一與本教程不同的是沒有采用django而是采用java web作為web框架),由于水平有限,肯定有不少錯誤或者不當之處,也希望讀者能夠指正,
五、總結
本文將所有代碼和標簽資料集放在了百度網盤里,需要的讀者可以自行下載、訓練和測驗,由于愛分割人像資料集比較大(19G左右),因此分成了gt.rar和img.rar,分別存盤真值標簽和原始影像,下載后將其解壓至工程PaddleSeg-release-v2.0.0-rc/data/ai_fen_ge檔案夾下面即可,
完整代碼下載地址:https://pan.baidu.com/s/1GgbL86s8xVnm2UKs9Hl-YQ 提取碼:o543
愛分割影像資料集img下載地址:https://pan.baidu.com/s/12IlaY1-ZdIZl9ObedDqRIQ 提取碼:o74q
愛分割標簽gt下載地址:https://pan.baidu.com/s/19AUWjq_dj9QikORvPbC4qw 提取碼:yzq0
當然本文還有很多沒有做完的地方,例如我們模型采用的是語意分割模型,因此在人物邊緣處會有背景的殘影(尤其是發絲邊緣),這個需要結合摳圖領域的方法進行二次處理(例如KNN摳圖、Closed form摳圖等),也可以使用端到端的摳圖模型重新修改模型進行訓練,這個任務在后面我會繼續改進并分享教程和代碼,另外,本文還有PC端、移動端和嵌入式端部署方案沒有完成,但是沒辦法春節假期實在太短來不及研究和撰寫了,后面有機會一并補齊,
在paddle使用方面,我也是一個新手,很多內容可能有更好的解決方案,本篇博文如果有錯誤或者可以改進的地方也請讀者指正,大家一起探討一起進步,這里也推薦自己的書友qq群820106877,大家有什么問題(不管是django方面的還是paddle方面的)可以一起交流,
最后,再次給自己剛上市的一本書打個call,《Python Web開發從入門到實戰》,想要快速掌握Python Web技術的讀者可以支持一下,兩者結合一方面可以使用Django快速搭建完整Web專案(例如賬戶管理,后臺管理,資料庫管理,頁面設計等),同時由于Django框架原生使用Python語言,因此可以在Django中方便的使用我們的深度學習模型,進行線上部署,實作AI落地,
六、參考文獻
[1]. Paddle語意分割官網
[2]. Changqian Yu, Changxin Gao, Jingbo Wang, et al. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259970.html
標籤:AI