目錄
- 資料集
- 確定人臉的類別標記
- 劃分訓練集和測驗集與訓練
實驗為基于sklearn的SVM人臉識別,使用 SVM 演算法對戴眼鏡的人臉和不戴眼鏡的人臉進行分類,從而完成 識別戴眼鏡的人臉 的任務;實驗涉及的支持向量機引數計算原理,回顧 第十八課;
資料集
人臉影像資料集 olivetti_py3.pkz,保存在個人資源處,加載資料:
from sklearn.datasets import fetch_olivetti_faces
# 從當前目錄下加載人臉資料集,若沒有則聯網下載到當前目錄下
faces = fetch_olivetti_faces(data_home='./')
該資料集一共有 400 張人臉圖片,每張圖片的大小是:64x64:
faces.images.shape
# (400, 64, 64)
每張圖片作為一個樣本,一共有 400 個樣本,每個樣本的特征維度是:64x64 = 4096:
faces.data.shape
# (400, 4096)
400 張圖片一共包含 40 個不同的人,每個人有 10 張人臉圖片:
from collections import Counter
# 統計 target 中每個取值的數量
count=Counter(faces.target)
count
"""
Counter({0: 10,
1: 10,
2: 10,
3: 10,
4: 10,
...
39: 10})
"""
展示前 4 張人臉圖片:
%matplotlib inline
import matplotlib.pyplot as plt
# 設定子圖數量和畫布大小
plt.figure(num=4,figsize=(20,5))
# 遍歷前 4 張圖片和對應的索引(索引從零開始)
for i,face in enumerate(faces.images[:4]):
# 1行4列的第i+1個子圖
plt.subplot(1,4,i+1)
# 在對應位置顯示子圖
plt.imshow(face)
確定人臉的類別標記
戴眼鏡人臉的圖片索引范圍:
# 下面的每個元組代表索引的起始和結束(閉區間)
segments = [(10, 19), (30, 32), (37, 38), (50, 59), (63, 64),(69, 69), (120, 121), (124, 129),
(130, 139), (160, 161),(164, 169), (180, 182),(185, 185), (189, 189), (190, 192),
(194, 194), (196, 199), (260, 269), (270, 279), (300, 309),(330, 339), (358, 359), (360, 369)]
創建類別標記,戴眼鏡的人臉為 1,沒戴眼鏡的人臉為 0:
import numpy as np
# 先設定所有樣本的標記值為 0
target = np.zeros(faces.target.shape[0])
# 再將戴眼鏡人臉索引位置的標記值設定為 1
for seg in segments:
target[seg[0]:seg[1]+1]=1
target
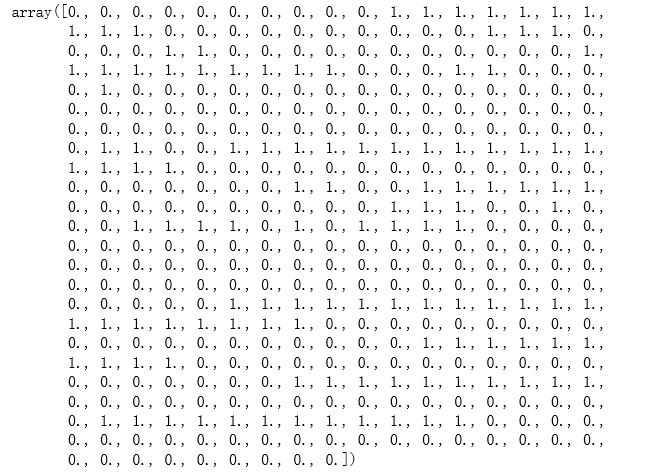
劃分訓練集和測驗集與訓練
劃分資料集:
from sklearn.model_selection import train_test_split
# 設定測驗集的大小為 20%
X_train, X_test, y_train, y_test = train_test_split(faces.data, target, test_size=0.2, random_state=0)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# ((320, 4096), (80, 4096), (320,), (80,))
SVM 模型訓練:
from sklearn.svm import SVC
# 使用線性核函式進行模型訓練
model = SVC(kernel='linear').fit(X_train,y_train)
模型準確率評估:
# 訓練集的準確率
print('train_accuracy =',model.score(X_train,y_train))
# 測驗集的準確率
print('test_accuracy =',model.score(X_test, y_test))
"""
train_accuracy = 1.0
test_accuracy = 0.9875
"""
識別結果可視化:
# 測驗集的預測結果
y_pred = model.predict(X_test)
# 樣本標記值對應的人臉類別
text = {1:'戴眼鏡', 0:'沒戴眼鏡'}
# 設定子圖數量和畫布大小
plt.figure(num=16,figsize=(20,20))
# 設定顯示中文字體(黑體)
plt.rcParams['font.family'] = ['SimHei']
# 遍歷測驗集的 16 張人臉圖片對應的特征向量及其索引
for i,face in enumerate(X_test[:16]):
# 4行4列的第i+1個子圖
plt.subplot(4,4,i+1)
# 將特征向量轉為二維陣列,shape=(64,64)
face = face.reshape(64,64)
# 將二維陣列以圖片的形式展現出來
plt.imshow(face)
# 取出當前人臉的類別標記預測值
label = y_pred[i]
# 在圖片(35,60)的位置標出人臉類別(是否戴眼鏡),字體大小為 24,字體顏色為棕色
plt.text(x=35,y=60,s=text[label],fontdict={'fontsize':24 ,'color':'brown'})

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259969.html
標籤:AI