本文記錄個人對EM演算法的理解
首先為什么要使用EM演算法,他適用于哪些場景呢?
大家都知道EM演算法是聚類演算法的一種, 這個演算法是在資料已知的前提下討論引數的合理性,
換一句話說, 他是可以用似然函式建模的,等下會記錄如何用數學語言描述這個演算法,但是首先先使用經典的投硬幣的問題將這個抽象的演算法形象化,
什么情況下我們要使用 EM演算法呢
假設我們現在有2枚硬幣,分別記為硬幣A 和硬幣B,如果我拿起硬幣A 投了5次得到了以下的結果:A:[+,+,-,-,+] ,這里“+”表示硬幣正面朝上,“-”表示反面朝上,之后我拿起硬幣B我也投5次得到了以下的結果B:[-,-,+,+,+], 那么現在想要求到A出現正面的概率和B出現正面的概率是很簡單的,
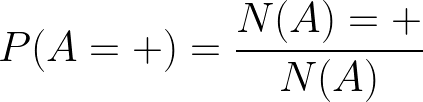
上述公式中N(A)所表示的是A拋的總次數,N(A)=+ 意思是在這些次數中出現正面的次數,
同理B出現正面的概率也可以用同樣的方式表示,可以記為:
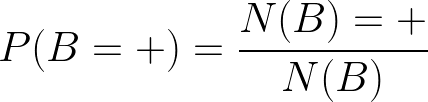
上述兩個式子相對比較好理解,但是現在請設想這樣一個情況,
我從AB兩枚硬幣中隨機取一枚來投擲,并記錄下投擲結果,經過N次這樣的投擲之后,我也可以得到一組記錄著正反面的資料,但是如果只給你這樣一組資料,告訴你這一組資料是隨機投擲AB兩枚硬幣產生的,有沒有可能求出硬幣A出現正面的概率和硬幣B出現正面的概率呢??這個時候就可以考慮使用EM演算法了!
EM 演算法的一般思路
這個問題和最開始的那一個投硬幣的問題不同在哪里?
其實我們仔細的看看,會發現這一個問題中,我們不知道每一次投擲硬幣的結果到底是A產生的還是B產生的,要是知道了就和最開始的那一個投硬幣問題一樣了,但是問題是我們不知道,而且它潛移默化地影響著我們最后的計算結果, 這種我們無法從資料中直接觀測到的,但是又影響著最后模型輸出的變數,我們叫它 ‘隱變數 / 潛變數’(Latent variable)
那這個時候我們就應該想方設法的把這個隱變數給表示出來呀!
假設我們現在有一個由投擲AB兩枚硬幣產生的一組結果 T:[+,+,-,-+,-]. 我們可以用另一個概率分布Q 來表示每一個結果是由A或者B產生的概率,用 Z 來表示那個隱藏變數(那么我們先明確隱藏變數 Z 其實就只有兩個值呀!除了A就是B,不可能有C的情況出現,對吧!),那么現在,我們就可以假設在 T 這一組結果中由A產生的概率是 Q(Z=A) ,同理也可以假設由B產生的概率是 Q(Z=B).那么這個時候求得A和B出現正面的概率也就不是難事了呀~
假如,我初始化Q(Z=A)=0.4, Q(Z=B)=0.6,那么在T中出現的3個正面朝上的結果中,就有
3 x 0.4 = 1.2 個是由硬幣A產生的,3 x 0.6 = 1.8個是硬幣B產生的,那同樣的,在T中所有反面結果中,由A這個硬幣產生的概率就是 3 x 0.4 = 1.2, 由B產生的概率是 3 x 0.6 = 1.8
那么這樣一來 這個問題是不是就變成了最開始的那個最簡單的投硬幣問題了呢?
所以A出現正面和B出現正面的概率就可以這樣來計算了(我們在這里把這兩個概率用θ來表示吧~):
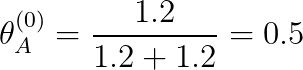
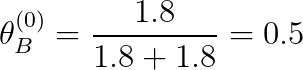
(這個概率看上去好像很符合我們得到的資料,但是這是因為為了方便計算我舉了一個很簡單的例子啦~,真實情況比這個要復雜哦!)
得到這個之后我們繼續!現在這個問題已經和最開始的那個投硬幣的問題一樣的,知道資料,知道兩枚硬幣出現正反面的概率了!但是這個值不一定準確!!! 因為所有的前提都是我們隨機初始化的,現在我們要做的就是要來優化我們的θ,爭取找到最好的那一個θ,可以想想爬山的例子來幫助理解,你想去山頂,將你隨機置于山上一個地方,然后一點一點向上爬的感覺,具體怎么做其實很簡單,
既然現在我們已經知道了AB出現正反面的概率了,那么我們可以用這個概率去更新我們的Q,然后再用新的Q又更新θ,一直執行這個程序直到收斂!這里畫個圖可能會更加的直觀一點兒~,這個更新的程序就類似圖中所示 (圖有點佛系,,,,)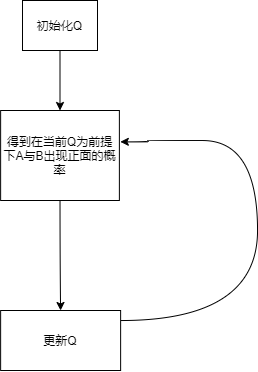
這個程序一直進行直到收斂,收斂的條件可以是我們已經找到了最好的那個θ了,自然可以退出回圈了,或者是達到了最大的迭代次數,也可以作為收斂條件,
所以正如演算法的名字所述,整個演算法的步驟就只有兩步Expectation(E-step) 和 maximization(M-step),從上文的描述中,可以我們在更新Q的那個程序其實就是在做Expectation,更新θ的那一步就是maximization,因為我們想要最好的θ,
用稍微數學一點的語言描述一下這個程序
在前文的時候我提到,類似這種知道資料討論引數的情況,我們可以用最大似然函式對其進行建模,假設是針對引數θ的最大似然函式影像:
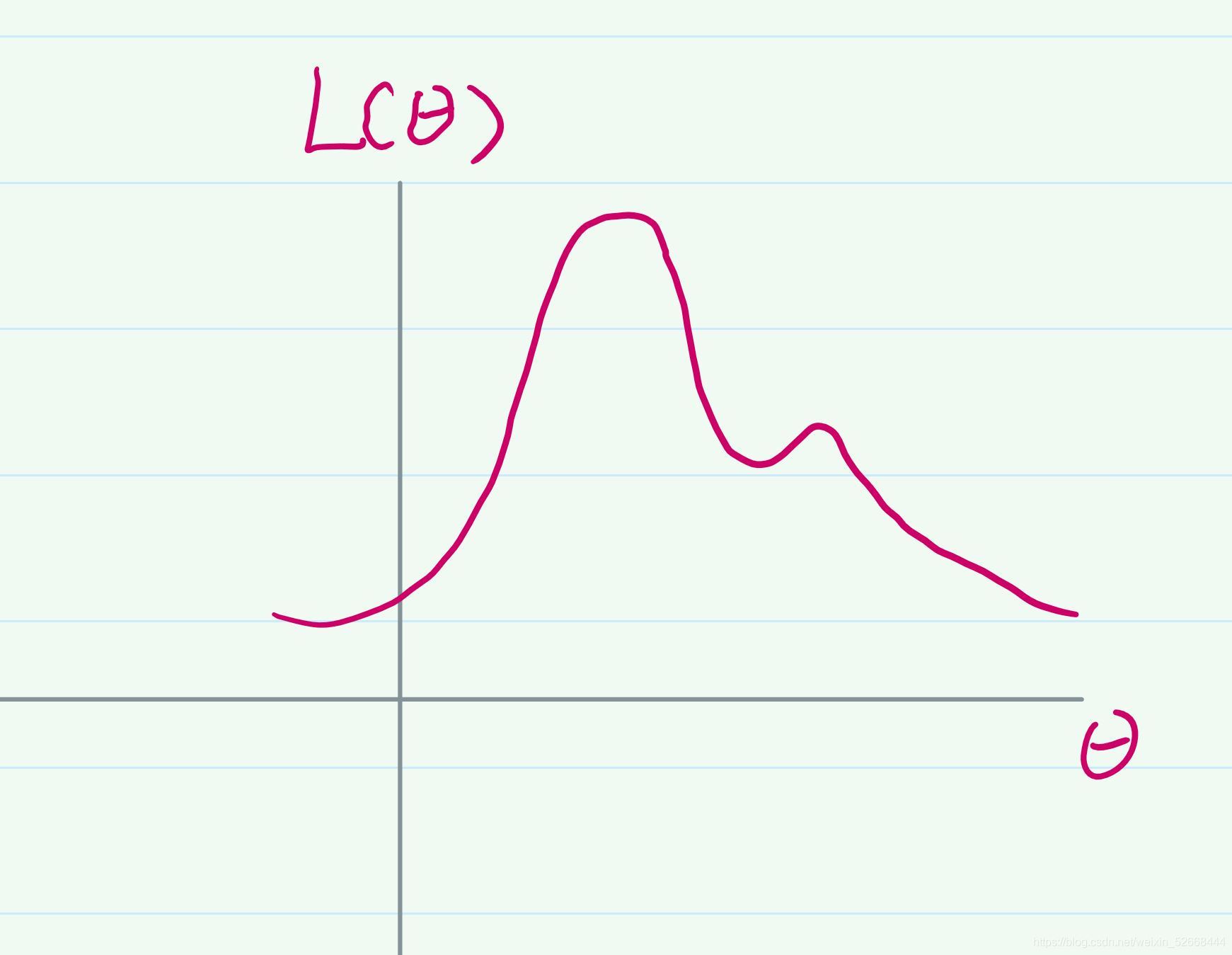
因為我們是在討論引數θ的合理性,想要找到一個最佳的θ,所以這個最大似然函式的一定是關于θ的,這樣的函式存在一個問題,他可能不是凸函式,在優化問題上,我們知道凸函式它一定是有一個全域最優解的,但是如果是非凸,那么可能存在多個區域最優解,不是很好進行優化,對于圖中的這個函式如何來找到最佳的θ呢? 還是以爬山的那個場景來類比,我既然不知道哪個θ是最好的,我可以隨機的初始化一個θ呀,就像隨機把人放在山的某個位置一樣,就像下圖所示,我隨機的初始化了一個θ1: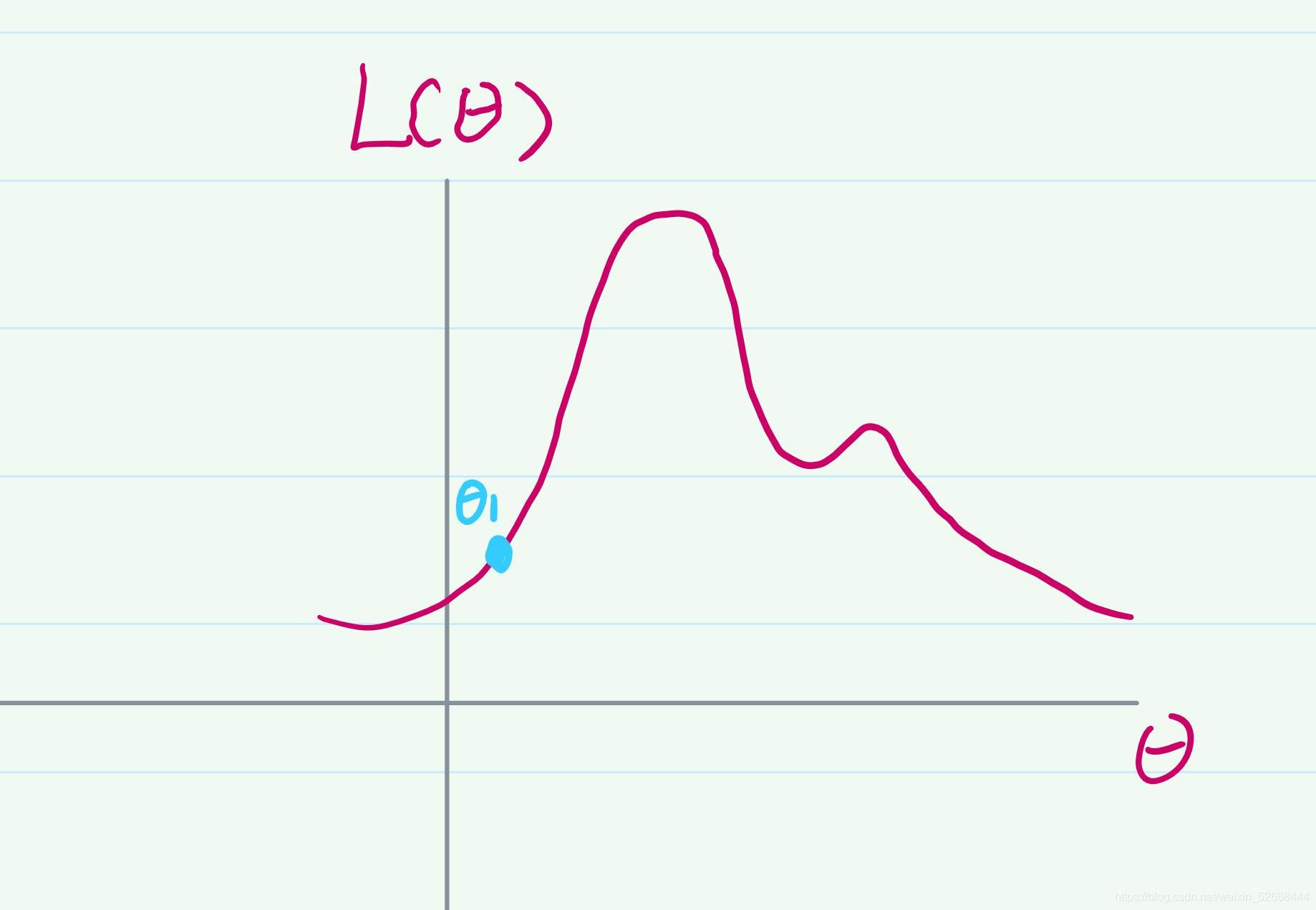
現在的問題是怎么讓這個θ向上爬呢?既然我們知道凸函式一定有一個全域最優解,那為什么不利用起來呢?現在我創建一個簡單的凸函式g(圖中綠色表示的曲線), 使這個函式g的交于θ1,并且保證g(θ1)的極大值要小于L(θ1)的極小值,其實就是要保證創建的函式g 要在L 下方,上述程序用影像畫出來差不多,如下圖所示:
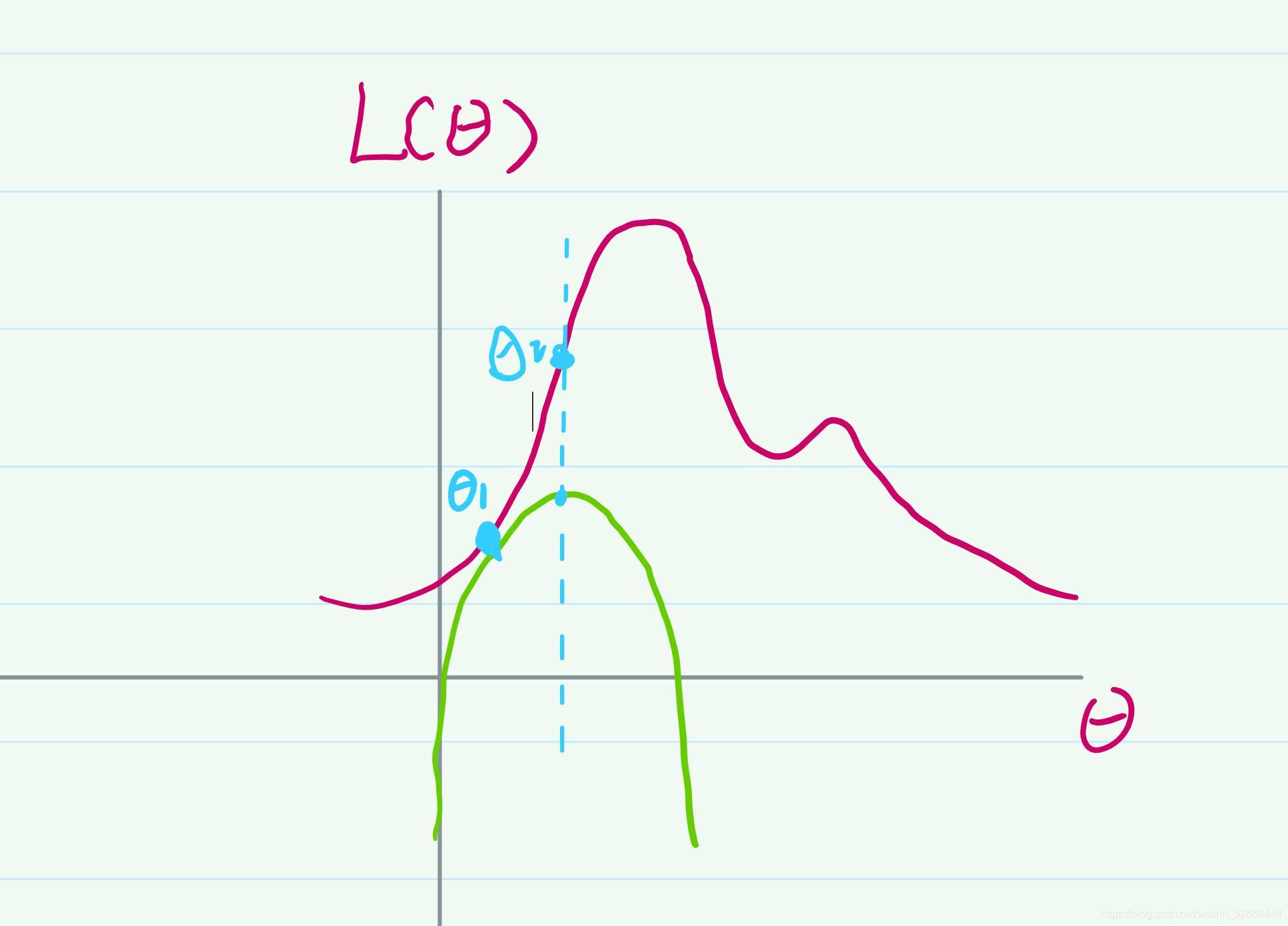
那么凸函式g的最大值是很容易求的,這個時候我們可以把這個凸函式g的全域最優解所對應的那個θ值作為新的θ的值,我將其記為θ2,這個時候可以發現θ已經向上爬了,我們可以對上述步驟進行迭代,在針對θ2創建一個凸函式g2并得到θ3的值,我們可以得到如下影像:
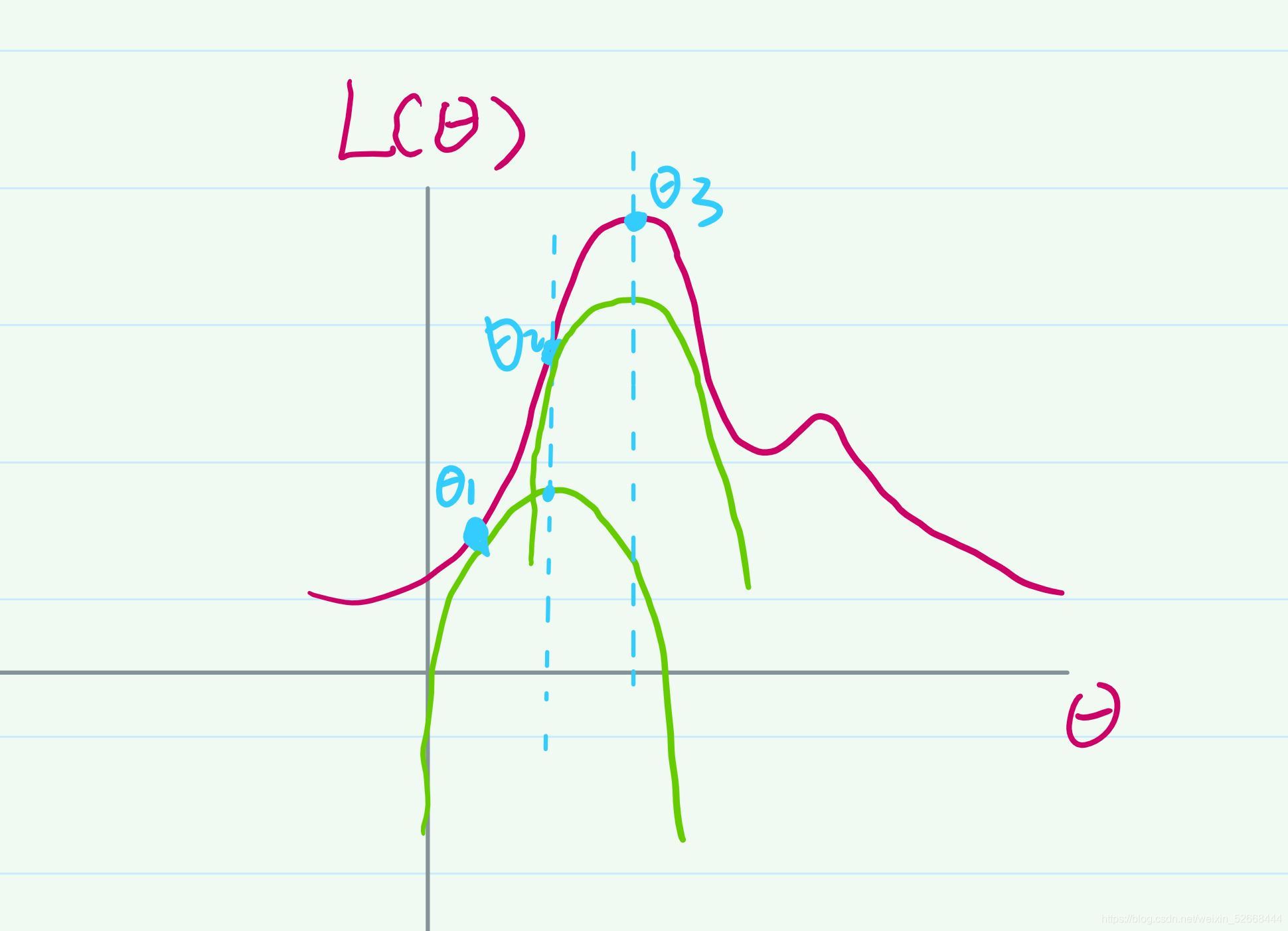
上述步驟一直迭代進行,直到找到一個θ值能最大化這個最大似然函式,也就是找到‘山頂’為止,
數學推導EM演算法
在理解EM的數學推導程序之前,首先要理解一個很重要的概念那就是Jensen’s inequality(琴生不等式),
他可以被定義成: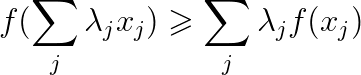
這里的 f 是一個凸函式,
λ
\lambda
λ 是指的一種概率分布,那應該如何來理解這一個不等式呢?我們可以先假設目前就只有兩個
λ
\lambda
λ 和兩個
x
j
x_{j}
xj?的情況就比較好理解了,
我們設
λ
1
=
t
\lambda_{1}=t
λ1?=t,那么就應該是
λ
2
=
1
?
t
\lambda_{2}=1-t
λ2?=1?t,因為一個概率分布中所以的概率相加應該是1嘛, 同時也假設我們有兩個變數
x
1
x_{1}
x1?和
x
2
x_{2}
x2?然后將我們所假設好的變數帶回到上述的不等式中我們可以得到以下式子:
f ( ( 1 ? t ) x 1 + t x 2 ) ? ( 1 ? t ) f ( x 1 ) + t f ( x 2 ) f((1-t)x_{1}+tx_{2}) \geqslant (1-t)f(x_{1})+tf(x_{2}) f((1?t)x1?+tx2?)?(1?t)f(x1?)+tf(x2?)
這樣乍一看還是覺得沒有感覺,但是至少要意識到,不等式的左邊是一條曲線,而右邊是一條直線,那么我們要是把圖畫出來就會清晰很多了,假設這里的這個凸函式是長圖里這個樣子的: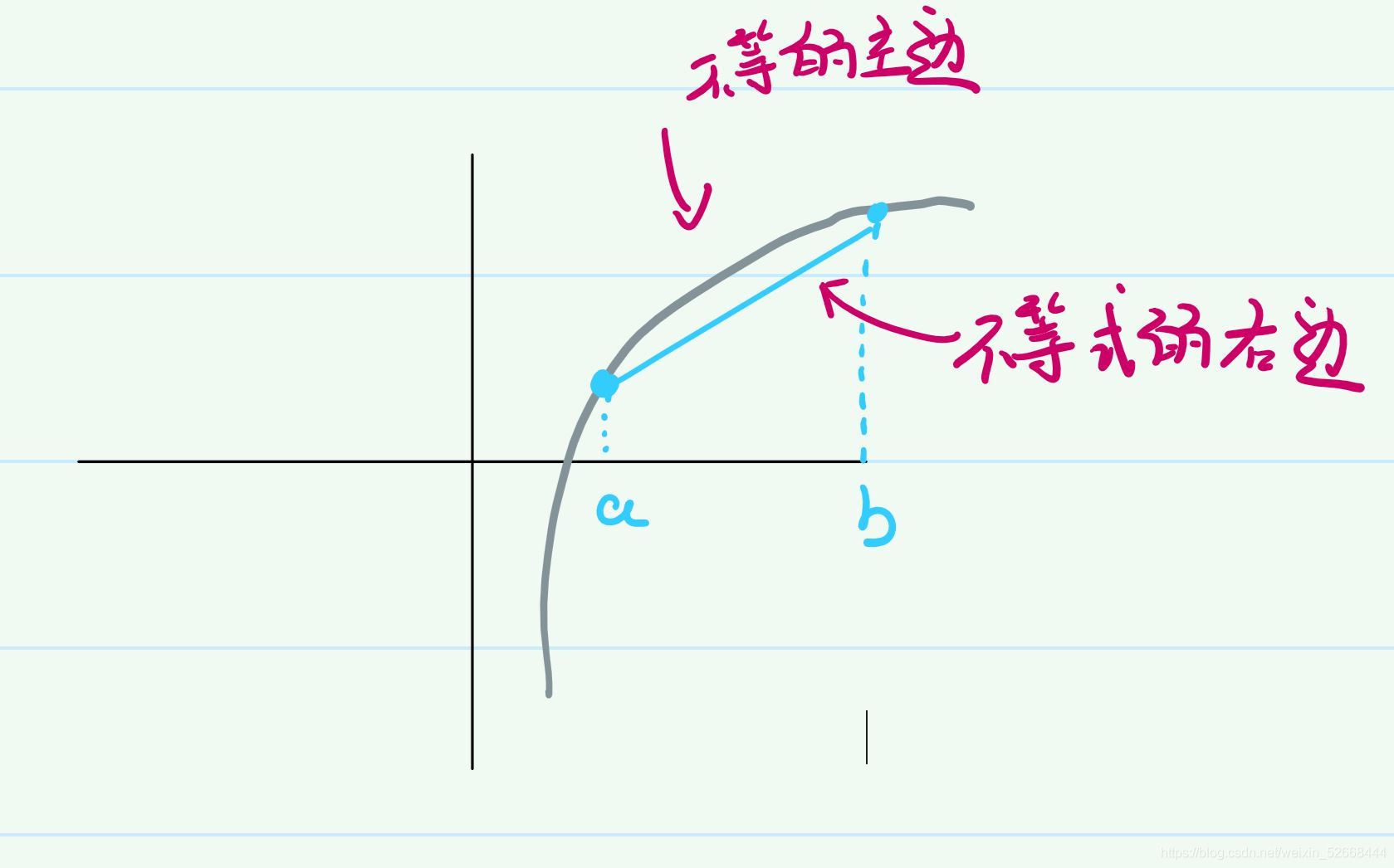
這樣子就很容易理解這個大于等于號是怎么來的了,如果在
x
1
x_{1}
x1?和
x
2
x_{2}
x2?之間隨意取一點
x
T
x_{T}
xT?那么這個點所對應的值永遠小于那個凸函式,取到段直線兩個端點的時候等號成立,正如下圖所示:
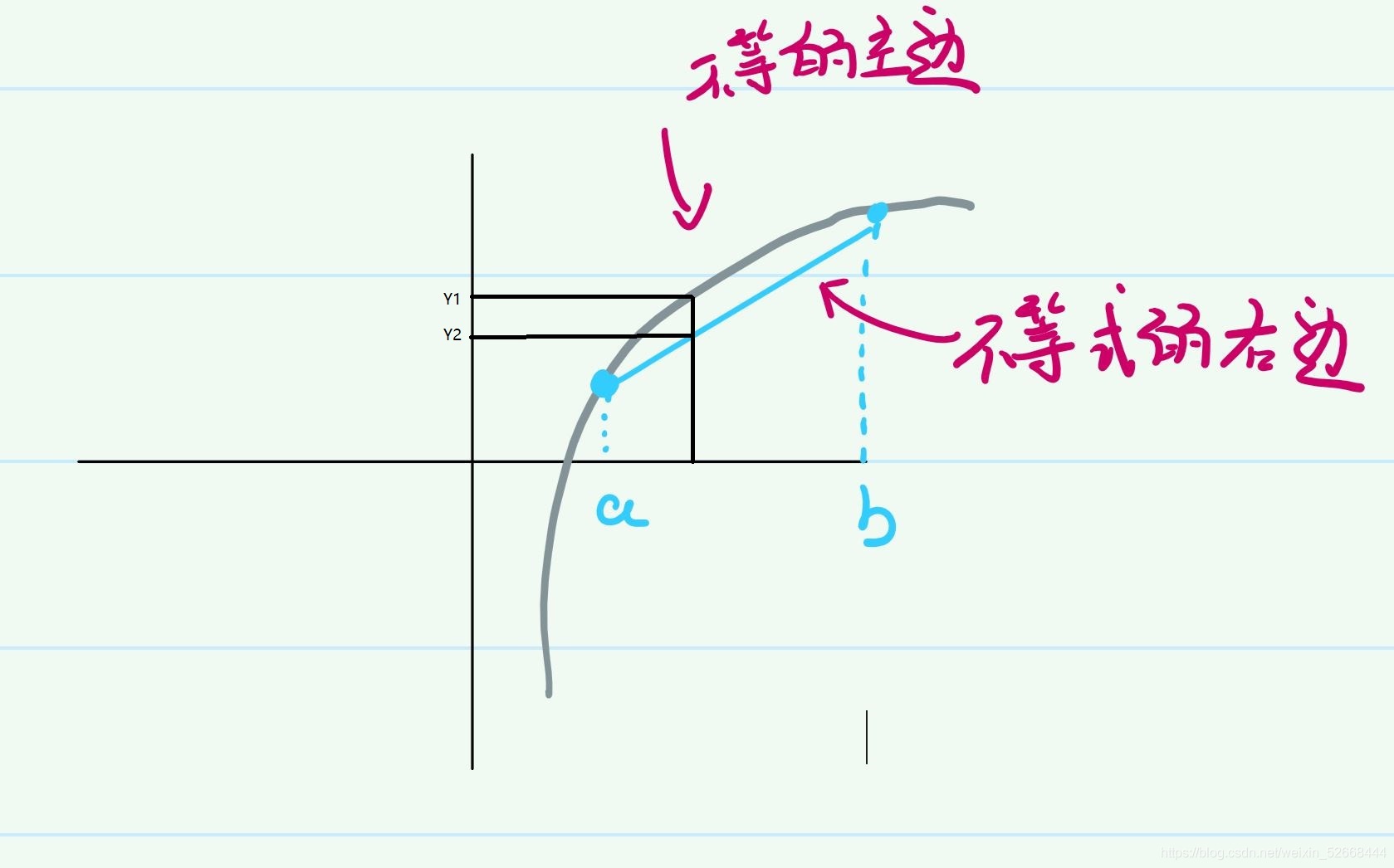
那么上面這一切和EM演算法有什么關系嗎?
假設我們有一組獨立的資料集{x1,x2,…},我們希望使用一個模型來擬合它,我們可以將這個模型寫成下面這個似然函式,這里的 X 就像是我們在第二個投硬幣例子里的投擲結果,θ就像是硬幣A和B 出現正面的概率,
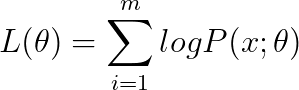
為什么要取log呢?我的理解是為了方便數學運算,而且取log是不會影響尋找最大值的,
但是上述公式沒有把隱變數對結果的影響表達出來,所以我們想辦法把隱變數塞進我們的模型中,為了方便理解我將公式拆開來記錄,正如前文提到,對于一個投擲結果,它可能是硬幣A產生的,也有可能是B產生的,所以我們應該把這個兩種情況的概率加在一起:
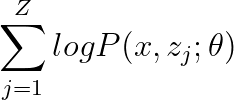
這里的大Z指的就是隱變數有多少種情況,對于投硬幣那個情況而言,就是大Z等于2,所以新的模型可以表達成:
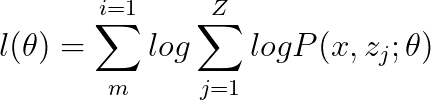
做到這里再來看看當前這個模型離Jensen‘s inequality 還差點啥?? 是不是只差一個概率分布了??那在我們已知的條件中還有什么是概率分布呢??結合拋硬幣的例子來看,只有隱變數z的分布Q了呀!!那為了保持等式的值不變,我在等式的右邊同時除以和乘以一個 Q ( z j ) Q(z_{j}) Q(zj?)得到以下這個等式:
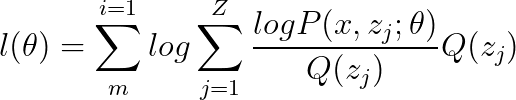
現在上述這個等式就完全和Jensen’s inequality 的形式一致了 (log函式本身就是一個凸函式哦!) ,所以就可以表示成Jensen‘s inequality的形式:
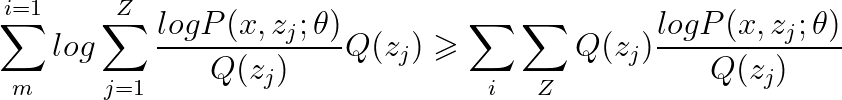
上述不等式在什么情況況下取等號呢?在
l
o
g
x
,
z
j
;
θ
Q
(
z
j
log \frac{x,z_{j};\theta}{Q(z_{j}}
logQ(zj?x,zj?;θ?等于一個常數的時候等號成立,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260353.html
標籤:AI