Video Question Answering: a Survey of Models and Datasets
長文預警!!!
p.s.此篇文章于2021年1月25日新鮮出爐,在Springer需要付費觀看,博主免費分享給大家,希望與大家共同學習!
Abstract
視頻問答(VideoQA)根據視頻內容自動回答自然語言問題,它促進了在線教育、情景分析、視頻內容檢索等方面的發展,VideoQA是一項具有挑戰性的任務,因為它需要一個模型來理解視頻的語意資訊和生成答案的問題,首先,我們提出了一個視頻特征提取模塊、文本特征提取模塊、集成模塊和答案生成模塊組成的視頻質量保證系統的總體框架,集成模塊是核心模塊,包括核心處理模型、遞回神經網路(RNNs)編碼器和特征融合,這三個子模塊協作生成背景關系表示,答案生成模塊在此基礎上生成答案, 然后,總結了核心處理模型的方法,并詳細介紹了編碼器解碼器、注意模型、記憶網路等方法的思想和應用,此外,我們還介紹了廣泛使用的資料集和評價標準,以及在基準資料集上的實驗結果分析,最后,我們討論了視頻qa領域所面臨的挑戰,并為未來的作業提供了一些可能的方向,
Keywords
Video question answering
Feature extraction
Encoder-decoder
Attention model
Memory network
Recurrent neural networks
Feature fusion
1 Introduction
近年來,視覺和語言理解任務因其包含了真實世界的動態場景資訊而受到越來越多的關注,它有助于有效聚合海量資料,為在線學習提供教育資源,VideoQA在深度視覺和語言理解方面起著至關重要的作用,VideoQA的主要目標是學習一個模型,這需要理解視頻和問題中的語意資訊,以及它們的語意關聯,以預測給定問題的正確答案,在視頻質量檢測中應用了多種人工智能技術,包括物件檢測[1]和分割[2]、特征提取[3]、內容理解[4]、分類[5]等,綜合表現的評估指標是答對問題的百分比,VideoQA可以應用于許多實際應用中,如用戶自由提問的視頻內容檢索,視障人士的視頻內容理解等,VideoQA打破了視覺和語言的語意鴻溝,從而促進了視覺理解和人機互動,
即使VideoQA是ImageQA[6]的自然擴展,它們之間仍然有許多不同之處,因此,簡單地將ImageQA方法擴展到視頻是不夠的,也是最優的,主要區別在于兩個方面:
(1)VideoQA處理具有豐富外觀和運動資訊的長序列影像,而不是單一的靜態影像,
(2)由于視頻中存在大量的時間線索,VideoQA需要更多的時間推理來回答問題,如動作過渡和計數,
在此基礎上,本研究對視頻質量控制的研究框架、核心處理模型的方法、資料集以及未來的發展方向進行了全面的綜述,
在VideoQA框架中,
(1)視頻特征提取模塊分別使用Faster-RCNN[7]提取區域級特征,使用CNN[8-10]提取幀級特征,使用C3D[11]提取影像級別特征,
(2)文本特征提取模塊分別使用預先訓練的詞嵌入模型[12,13]和句子嵌入模型[14-16]提取詞級特征,
(3)集成模塊以視覺和文本資訊為重要線索,生成具有多模態語意的背景關系表示,
(4)答案生成模塊根據語境表征,通過判別模型生成答案,
集成模塊包括核心處理模型、rns編碼器和特征融合,這三個子模塊協作獲得背景關系表示,核心處理模型是進行推理和生成答案的核心部分,它由多種模型組成,如編碼器-解碼器[17]、注意模型[18]、記憶網路[19]和其他方法[20],編碼器-解碼器模型有兩個組件:一個編碼器和一個解碼器,編碼器從變長輸入序列中提取定長表示,然后解碼器從該表示中生成答案,注意模型有選擇地將注意力集中在源中相關度最高的部分,并收集加權表示生成答案,具體來說,它根據問題選擇重要的視頻,獲得問題引導的視頻表示,記憶體網路模型包含一個記憶體陣列,它存盤整個視頻內容以保存其長期記憶,并結合注意模型根據問題閱讀相關資訊,得到問題引導的視頻表示用于回答問題,其余的方法大致可以歸類為其他方法,例如,使用生成對抗網路(GAN)的思想來解決VideoQA任務,此外,RNNs編碼器對視頻和問題的時間結構進行建模,特征融合融合了多模態特征(視覺和語言),提高了回答性能,
根據不同的視頻源,我們引入了一些基準資料集,如MovieQA[19]、TGIFQA[21]、TVQA[22]、PororoQA[23]和Activity-QA[24],針對資料集設計了不同型別的問題,如多項選擇題、填空題和開放式問題,與影像相比,視頻具有更豐富和高質量的時間維度的視覺資訊,這決定了VideoQA需要對視頻進行更深層次的語意分析,此外,有兩種常用的評價標準來評價生成答案的質量,即準確性和waps[25],
值得注意的是,視頻qa研究作業已經引起了極大的關注,然而,調查[26-29]只關注VisualQA任務,一些VideoQA作品在[30]中被回顧,這還不夠,因此,我們的調查對VideoQA任務進行了全面和集中的描述,并對近年來的作業進行了回顧,總結了尚未解決的問題,為今后的作業提供了很有前景的方向,
這項調查的結構如下,第2節給出了VideoQA的形式化定義和總體架構,并以圖表的形式說明了不同模塊的處理,第三節總結了近期的視頻qa論文中關于預測答案的核心處理模型,并對核心處理模型進行了全面的文獻綜述,以及如何利用這些思想解決視頻qa任務,第4節介紹了應用于視頻qa的典型資料集和評估指標,第五部分總結并討論了未來可能的發展,最后,第六章進行了總結,提出了一些思考,并為今后的作業提供了研究方向,
2 Framework of video QA
2.1 Video QA task and terminology
以往的研究使用無監督[20]、半監督[31]或監督學習模型[18]來解決VideoQA任務,在大多數情況下,監督學習仍然是最常見的,因此,解決VideoQA任務的監督學習的正式定義如下,在描述模型之前,我們首先解釋表1中列出的一些基本概念和術語,模型f(v,q, a;θ)的輸入:模型輸出的視頻v∈v,問題q∈q,答案a∈a,因此,我們學習程序中的目標函式為:

其中θ為模型系數,l θ為損失函式,λ為訓練損失與正則化之間的權衡引數,顯然,如何訓練模型引數θ來回答問題是解決視頻qa任務的關鍵,

為便于描述,圖1給出了VideoQA任務的總體框架,該任務由以下四個部分組成:視頻特征提取模塊、文本特征提取模塊、集成模塊和答案生成模塊,視頻特征包括區域級特征、幀級特征和剪輯級特征,詳細的分析將在2.2節中描述,
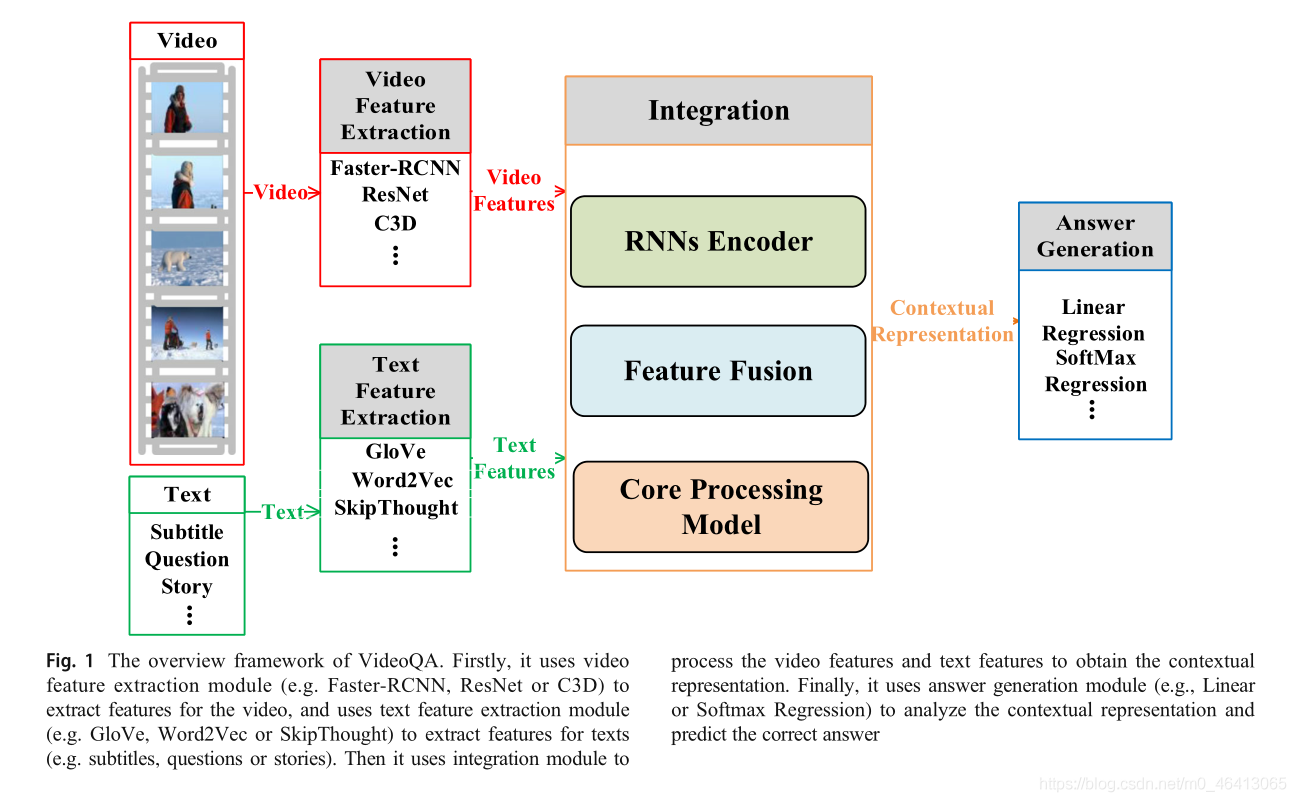
文本特征包括詞層特征和句子層特征,這兩層特征既表示粗粒度的問題特征,也表示細粒度的詞特征,詳細分析將在2.3節中討論,
提取的視頻特征和文本特征輸入到集成模塊中,然后輸出背景關系表示,這是問題回答的關鍵線索,集成模塊的定義和分析將在2.4節中討論,答案生成模塊使用背景關系表示來生成答案,模塊的詳細分析將在2.4.1節中介紹,
2.2 Video feature extraction
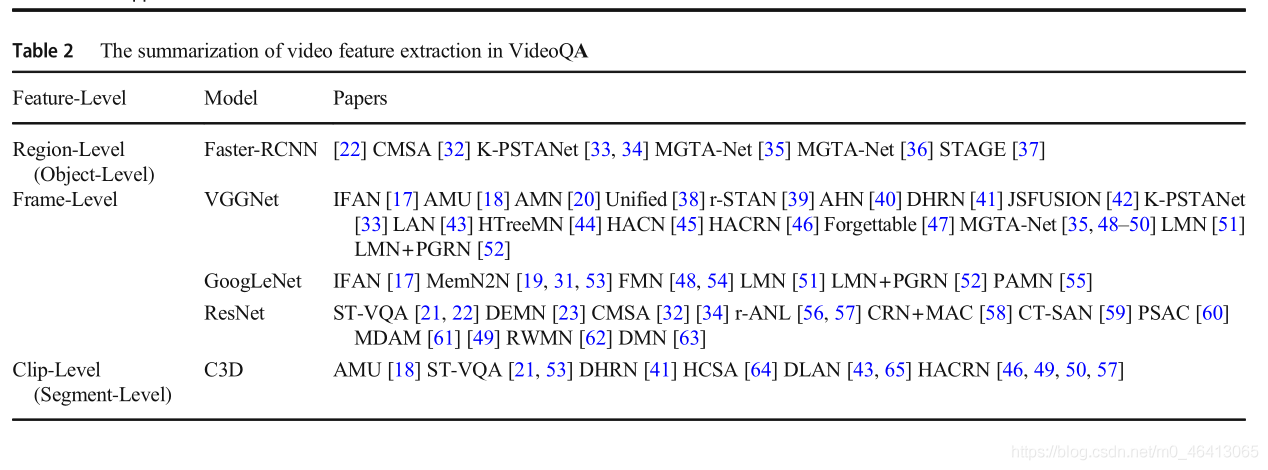
與影像相比,視頻不僅包含靜態的區域(物件)級和幀級特征,還包含動態的片段(段)級特征,區域級視頻特征是對區域視覺資訊的細粒度表示,提取的區域特征可以表示為區域級的視頻特征和預測的檢測標簽,兩者都可以作為集成模塊的輸入,由于現有的基于region proposal network (RPN)的作業在許多測驗中都取得了很高的精度,大多數作業都使用Faster-RCNN檢測感興趣的區域部分,以識別視頻的區域屬性,
幀級視頻特征是對全域視覺資訊的粗粒度表示,它比區域級視頻特征捕獲更多型別的資訊,(例如:人物和場景),隨著深度神經網路的發展,人們提出了更深入、性能更高的神經網路,如VGGNet、GoogLeNet和ResNet,VGGNet被廣泛用于提取每一幀的幀級特征,每幀大小為224 × 224,然后提取第一個全連通層的4096維特征向量作為幀級視頻特征,類似地,GoogLeNet被用于提取幀級特征,這些特征來自于Concat層的最后一個初始5b,特征尺寸為2 × 7 × 1024,利用ResNet,從pool5層提取2048維的特征向量,
剪輯級視頻特征是順序的和動態的特征表示(例如,行為),C3D網路在動作識別任務和捕捉視頻動態資訊的能力方面顯示了很有前途的結果,在Sport-1 M資料集[11]t o e x tra c t the c l i p水平特征上預先訓練C3D,C3D的fc7層和C3D的conv5b層的輸出特征作為連續16幀的剪輯特征,特性大小分別為4096和1024,我們將基于上述模型的作業總結在表2中,
2.3 Text feature extraction
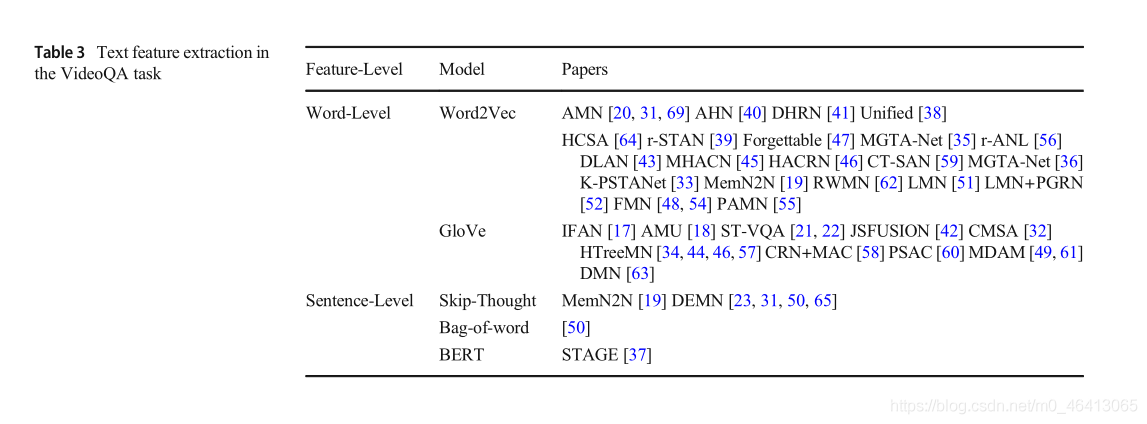
在自然語言處理任務中,預先訓練好的語言模型是提取文本特征的有效方法[66,67],句子級模型通過分析句子的順序資料來預測句子之間的關系,單詞級模型在單詞級[16]上實作細粒度表示,VideoQA中有大量的文本資料,即字幕、故事、對話和問題,這些文本資料被認為是一個單詞序列,因此,文本特征提取可分為單詞級和句子級,
采用Word2Vec[12]和GloVe[13]的詞嵌入提取詞級特征,詞向量是詞匯表中所有詞的向量表示的特征矩陣,該演算法將所有的詞轉化為低維嵌入空間,計算詞間的語意相似度,采用預先訓練的word2vec模型[68]提取題、答案的語意資訊,其維數為256,預訓練的300維手套模型也在許多研究作業中得到應用,該手套是根據維基百科2014和Gigaword 5(包括400k的詞匯量)訓練的,對于不出現在手套中的詞,使用現有詞的嵌入值的平均值,
通常使用Skip-Thought[14]、Bag-of-word[15]和BERT[16]來提取句子級文本特征,受詞向量學習的啟發,Skip-Thought是一種學習高質量句子向量的模型,它將skip-gram模型抽象到句子級別,在VideoQA中,使用SkipThought學習RNN模型中的句子語意和句法屬性,以捕獲問題語意資訊之間的相似性,word袋模型使用一個固定長度的單詞計數向量來表示文本,雖然該模型不考慮詞級資訊,但它已被證明能夠成功地捕捉到長距離詞匯相關資訊和主題資訊,BERT是一種經過微調的基于transformer的語言模型,它捕捉雙向背景關系資訊,以在不同的句子級別任務中預測句子,我們在表3中總結了常用的預先訓練過的語言模型,
2.4 Integration
集成模塊的目的是建立多模態語意資訊之間的相關表示,作為問答的關鍵線索,為了學習背景關系表示,集成模塊中需要核心處理模型、rns編碼器和特征融合三個模塊進行協作,核心處理模型作為集成模塊的重要組成部分,是解決VideoQA任務的核心,主要分為四類方法:編譯碼法、注意模型法、記憶網路法等,由于視頻和文本都是不同長度的連續資料,所以選擇RNNs編碼器是很自然的,現有的方法表明,結合不同層次的特征也可以提高性能[70],特征融合也分為三類:線性池化、模型融合、雙線性池化[30],
為了更清楚地說明,圖2給出了集成模塊的示例,集成模塊將注意模型集成到解碼器的語言模型中,實作利用語言模型解碼視頻資訊的方法,它在問題和視頻之間建立了緊密的聯系,具體來說,詞嵌入向量{x1,…,xt?1,xt,…,xn}被輸入語言模型[71],該語言模型在t?1時間步長輸出隱藏狀態ht?1,注意模型基于隱藏狀態ht?1對視頻特征進行注意,得到注意結果為,由此可見,注意力模型被整合到LSTM的程序中,整合模塊不僅使用了核心處理模型中的方法,還使用了RNNs編碼器對問題序列進行編碼,通過連接的方法將最后一個隱藏狀態hn和記憶單元狀態cnn融合,生成帶有問題視頻語意資訊的背景關系表示,是回答問題的重要線索,
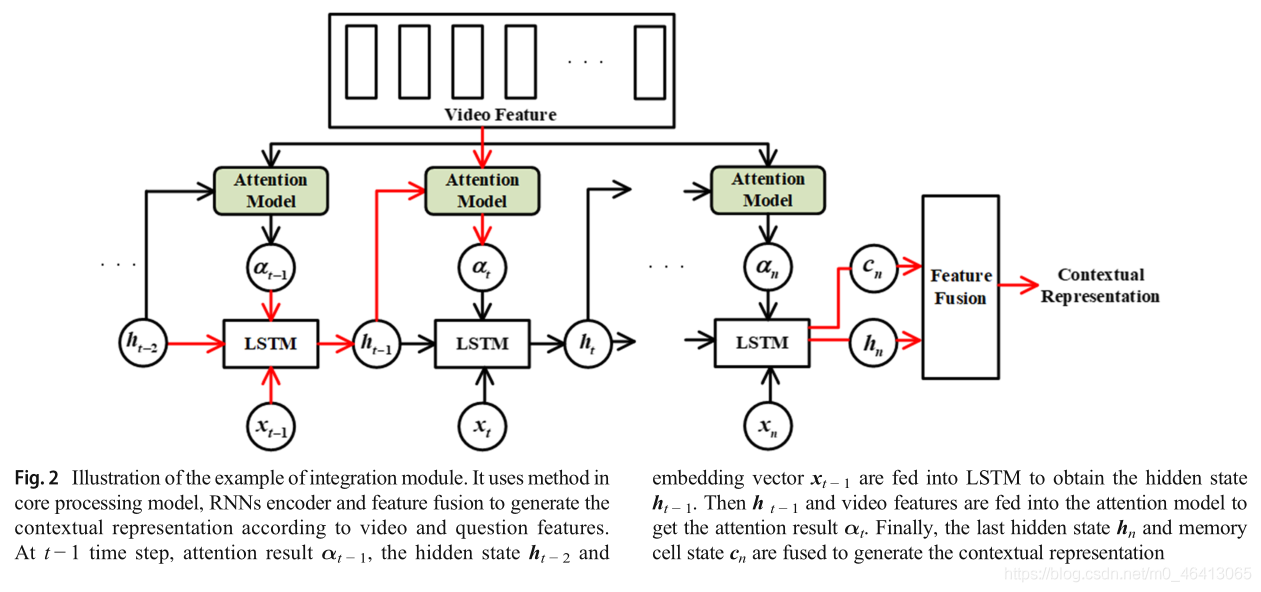
2.4.1 Core processing model
本研究將核心處理模型的方法分為四類:編碼器-解碼器、注意模型、記憶網路等,編碼器-解碼器框架由編碼器和解碼器組成,編碼器對來自變長輸入句子的定長表示進行編碼,解碼器生成與問題相關的變長序列,注意力模型的思想是計算視頻上的權重分布,并賦予與問題相關的元素更高的值,記憶網路是一種具有遞回注意力模型的神經網路,與遞回神經網路相比具有較大的外存盤器,它包含一個存盤陣列,為多個周期編碼輸入源,以及一個注意力模型,允許閱讀程序在每個周期關注不同的內容,其余的方法大致歸類為其他方法,表4總結了現有的作業,第三章將詳細介紹在核心處理模型中的方法分析,

2.4.2 RNNs encoder
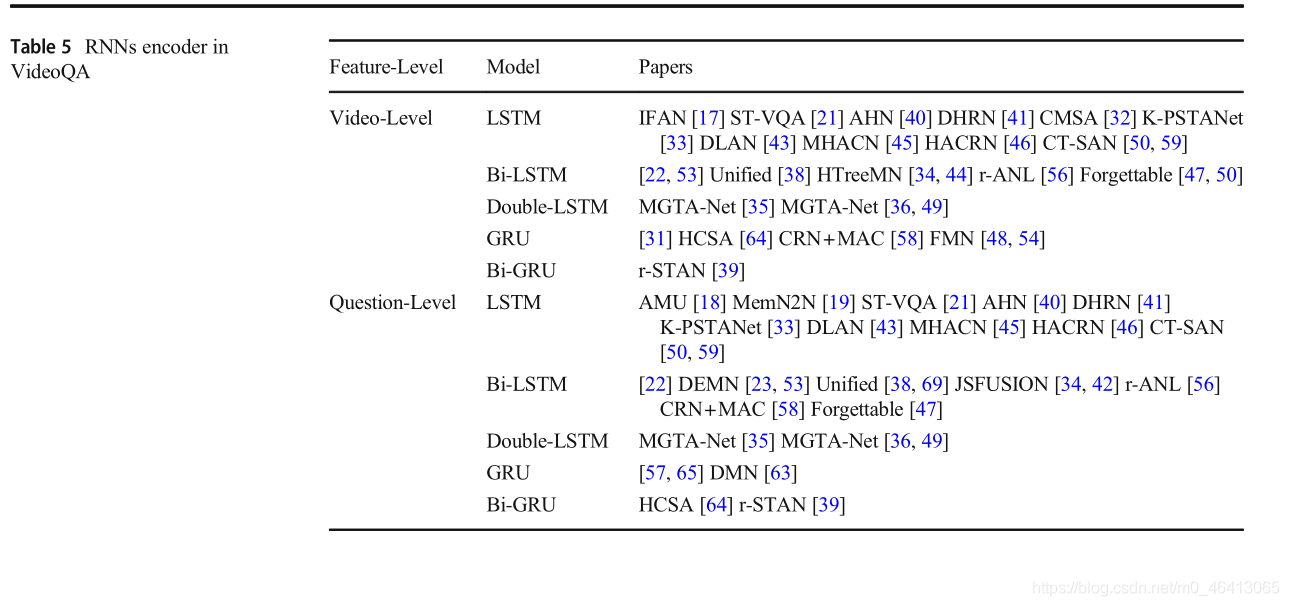
視頻和問題都是順序資料,所以選擇rns網路進行編碼是很自然的,在rns模型的幫助下,通過編碼幀級特征獲得視頻級表示,通過對詞級特征進行編碼,得到問題級表征,RNN族(簡稱RNN)包括LSTM[71]、雙向LSTM (Bi-LSTM)[72]、雙LSTM[73]、門控回圈單元網路(GRU)[74]、雙向GRU(簡稱Bi-GRU)[75],
LSTM是rnn的一種變體,它結合了短期記憶和長期記憶,能夠更好地解決序列相對較長的任務,在基本的LSTM單元結構中,有一個稱為存盤單元的單元,它存盤狀態變化并對順序資料進行編碼,它由輸入門、遺忘門和輸出門三種門機制來調節,對于幀級和詞級特征,輸入門對當前輸入資料和之前隱藏的狀態進行編碼,遺忘門控制是否忘記先前的資訊,以及修改多少資訊的記憶單元狀態,輸出門輸出當前隱藏狀態和存盤單元狀態,這是下一步的輸入,LSTM通常用于編碼這兩個特征,其中最后的隱藏狀態和存盤單元狀態連接作為特征表示,
Bi-LSTM由正向LSTM和反向LSTM組成,它們具有相同的拓撲結構,只是反向輸入序列不同,對于幀級和詞級特征,通常將前向LSTM和后向LSTM的隱藏狀態連接起來作為特征表示,Double-LSTM由一個兩層的LSTM組成,針對上述兩個特征,將第一層的編碼結果傳輸到第二層,最后的隱藏狀態和第二層的存盤單元狀態連接起來作為特征表示,
GRU在概念上比較簡單,但不比LSTM差,GRU只有更新門和重置門,對于框架級和詞級特征,輸出GRU網路的最后隱藏狀態作為特征表示,Bi-GRU由正向GRU和反向GRU組成,它們類似于Bi-LSTM,對上述兩個特征進行編碼,我們在表5中總結了用于編碼視頻特征和問題特征的RNNs方法,
2.4.3 Feature fusion
多模態特征融合是視頻質量保證任務的基礎和意義,特征融合被廣泛應用于多種模態特征的融合,與未融合的特征相比,融合的特征具有更好的性能[76],特征融合方法包括線性池化、模型融合和雙線性池化,
線性池化是多模態特征融合的常用方法,視頻和問題的聯合表示是通過拼接、元素和元素相乘等方法得到的,實驗表明,兩個特征集在不同模態下的分布可能有很大差異,融合特征的表示能力可能不夠,導致預測性能不理想[70],
模型融合采用神經網路學習聯合表示,例如,IFAN [17] u s es LSTM對視頻特征進行編碼,并利用最后的隱藏狀態初始化語言模型,將注意力模型整合到語言模型中,將問題與視頻建立起密切的關系,
與線性池化方法相比,雙線性池化方法[70,76,77]被用來融合不同的模態特征來解決VideoQA任務,多模態緊致雙線性池(MCB)[70]的性能優于線性池方法,然而,MCB通常需要高維特征來保證其魯棒性能,這可能會嚴重限制其能力,因為GPU記憶體的限制,為了解決這一問題,提出了基于兩個特征向量的Hadamard積的多模態低秩雙線性池(MLB)[77],MLB取得了與MCB相同的性能,但其特征維數和模型引數較少,此外,多模態分解雙線性池(MFB)[76]方法是MLB和MCB之間的一種折衷方法,它具有MLB緊湊的輸出特性和MCB健壯的表達能力的雙重優勢,我們將特征融合方法總結在表6中,

2.5 Answer generation
視頻問答題的答案通常分為三種型別:開放式問題、多項選擇題和填空題, 基于監督學習和判別模型解決了答案生成問題,判別模型定義如下:給定一個輸入變數x,該模型直接求解目標變數的類后驗概率P(y|x),定義了一個線性回歸,它將集成模塊中的視頻和問題的背景關系表示作為輸入,并輸出每個候選答案的實值分數,

其中,W?和b為模型引數,通常,訓練模型的方法是最小化成對比較∑p≠nmax(0,1?sp+sn)的hinge loss,其中sn sp 為分別來自錯誤答案和正確答案的分數,
softmax回歸是線性回歸的多類版本,表示為樣本向量x屬于這k個類之一的概率值,因此,我們定義了一個softmax分類器,它以背景關系表示形式O作為輸入,通過計算置信向量s從詞匯表中選擇答案,

其中,W?和b為模型引數,該模型通過最小化softmax損失函式進行訓練,
通過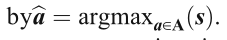
得到預測答案,我們在表格7總結了在表中生成答案的方法,

3 The methods in Core processing model
集成模塊的核心部分是核心處理模型,從視頻和問題特征中提取相關資訊,進行背景關系表示并生成答案,根據思想和方法的不同,core processing model中的方法大致可以分為以下四類: encoder-decoder [17], attention model [18], memory network[19]和其他方法[20] ,詳細介紹了該方法的核心思想,以及如何利用這些思想解決視頻qa任務,
3.1 Encoder-decoder
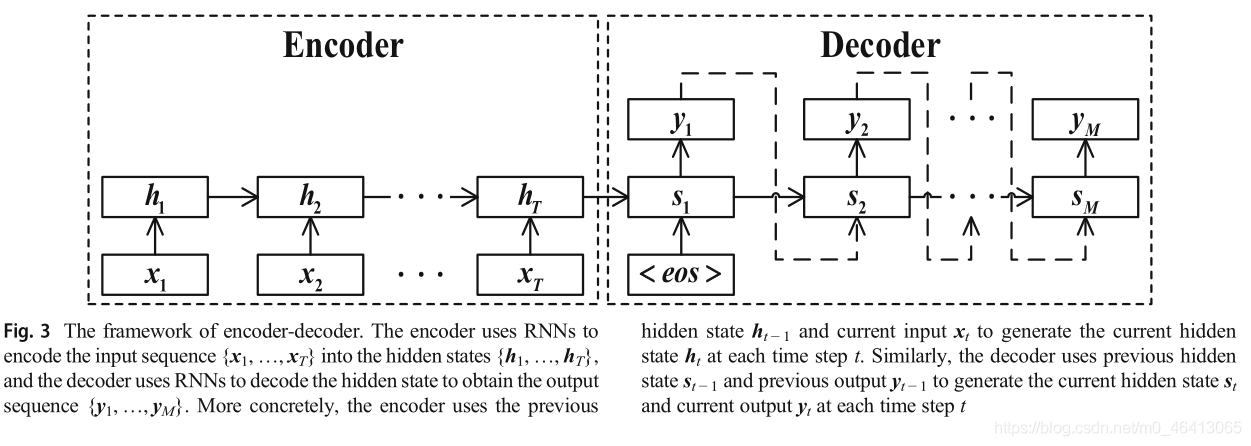
由編碼器和解碼器組成的編譯碼器[78-80]模型在機器翻譯中非常流行,編碼器將變長序列(輸入序列)編碼為中間碼,解碼器使用中間碼生成變長序列(輸出序列)[81],編譯碼器模型的基本框架如圖3所示,首先,輸入序列{x1,…,xT}被送入編碼器,生成t時間步長的隱藏狀態,其中ht=R N N s (xT,ht?1),然后將所有隱藏狀態輸入到一個非線性函式中,生成結果c=q ({h1,…,hT})作為整個輸入序列的輸出,其中是背景關系向量,然后解碼器根據概率函式輸出答案預測yt at t時間步長,如下:
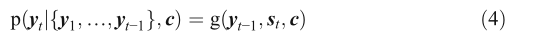
其中g為非線性函式,為隱態st?1產生的解碼器的隱態,輸出yt?1,公式如下:

初始隱藏狀態s1由最后一個隱藏狀態ht和特殊的句子結束標記eos計算,解碼器生成隱藏狀態序列s={s1,…,sM}和輸出序列y=(y1,…,yM),在下面的小節中,我們將討論三種型別的編碼器-解碼器模型:
基本編譯碼、部分改進的編譯碼、完全改進的編譯碼,按編譯碼模型改行程度進行劃分,基本編碼器-解碼器是一個簡單的應用編碼器-解碼器結構的VideoQA,原始的RNN模型,如LSTM和GRU,只是簡單地用于編碼器和解碼器部分,部分改進的編譯碼器只改進了編譯碼器結構的一部分,主要是通過在rns模型中加入注意模型,在上述方法的基礎上,完全改進的編解碼器的編解碼器部分,自然可以與其他模型進行多種組合,在下面的章節中,我們將通過三個類別全面回顧VQA方法,
3.1.1 Basic encoder-decoder
基本編碼器-解碼器是一個簡單的應用編碼器-解碼器結構的VideoQA,本文提出了一種多層GRU編譯碼框架,并提出了一種雙通道排序損耗法來分析過去、描述現在和預測未來,GRU模型編碼幀級特征,以生成隱藏狀態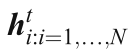
在編碼器的每個時間步,然后這些隱藏狀態的串聯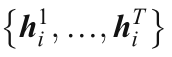
作為中間代碼,對于解碼器,其架構與編碼器相同,解碼器的初始隱藏狀態h0用編碼器最后一步T的隱藏狀態進行初始化,分別學習的三個GRU解碼器分別用于推理過去、描述現在和預測未來,為了產生不同的目標序列,譯碼器在時域中關注不同的資訊,最后,為了評估學習到的視頻對過去、現在和未來的表征,我們采用了雙通道排名損失,以產生比其他干擾因素對正確答案的視覺背景關系和表征向量更高的相似性,本文以時域為研究物件,采用無監督方法對編碼器進行訓練,該方法能夠在較長的時間范圍內對視頻時間結構進行建模,但該方法將時間模型和問答對模型分別訓練,榷訓了視頻內容與文本之間的關系,
在論文[53]中解決的問題型別是帶有填空的VideoQA任務,編碼器使用雙向BN-LSTM (LSTM的批處理規范化變體)對問題進行編碼,前半段LSTM網路對問題進行編碼,輸出表示為ashf,反向LSTM網路在后半部分對問題進行編碼,而輸出表示則記錄為ashb,其中hq ={hf,hb}是整個問題的編碼表示,利用LSTM網路對幀級特征進行編碼得到hV,然后,將hq和hv輸入解碼器,輸出不同候選答案的概率分布,該譯碼器由單層MLP和softmax分類網路組成,采用最大對數似然法對網路引數進行估計,
論文[22]針對多模態VQA任務提出了一種可訓練的多流端到端神經網路,多流包括區域級和概念級特征,以及幀級特征,對于這三個特征,使用基于視徑訓因組訓練的Faster R-CNN來檢測每一幀中的目標和屬性區域,區域特征作為區域級特征,預測的檢測標簽作為概念特征,在ImageNet上訓練ResNet101,提取幀級特征,在編碼器中,使用雙lstm對問題序列和視頻序列進行編碼,以所有時刻步驟的隱藏狀態分別表示問題、答案和視頻,然后,背景關系匹配模塊[82]將背景關系向量和查詢向量作為輸入,產生一組背景關系感知的查詢表示,即每個背景關系查詢對之間的相似度,這些背景關系感知的查詢表示通過連接進行融合,最后,將融合后的表示輸入到另一個雙lstm中進行解碼,它的隱藏狀態被暫時最大池提供給softmax分類器用于答案預測,表8總結了VideoQA中基于基本編碼器解碼器方法的模型,

3.1.2 Partly improved encoder or decoder
部分改進的編譯碼器主要通過增加注意模型來改進編譯碼器的部分結構,IFAN網路在論文[17]中提出,將注意力模型集成到解碼器中,建立了文本和視頻之間的密切關系,首先,利用VGGNet提取幀級特征,然后,在編碼器中,通過LSTM對幀級特征進行編碼,生成以時間結構作為視頻表示的隱藏狀態序列,最后的隱藏狀態和存盤單元狀態用于初始化解碼器的語言模型,然后,為了對視頻資訊進行解碼,在語言模型中引入注意模型來建立問題與視頻之間的關系,特別地,問題被嵌入到生成詞向量xi:i=1,…,n,詞向量xi被用來參加視頻表示,得到γt?1,在下一步中被傳遞到注意狀態γt,可以看出,采用注意模型的LSTM網路傳輸到下一步的狀態包含三個部分:記憶細胞ct?1、隱藏狀態ht?1和注意狀態γt,最后,將最后的隱藏狀態hM和最后的存盤單元狀態cM融合到softmax分類器中,得到最終的答案,
論文[21]提出了ST-VQA網路,將時空注意力模型集成到編碼器中,并根據問題選擇每一幀中的關鍵區域和視頻中的重要幀,首先利用ResNet演算法提取幀級視頻特征,然后利用C3D演算法提取剪輯級視頻特征;它們被連接成整個視頻功能,采用預先訓練的方法提取問題和答案的文本特征,其次,在編碼器中使用雙lstm對幀級視頻特征進行編碼,它的最終隱藏狀態用于初始化第二個double-LSTM,第二個double-LSTM用于對問題進行編碼,并使問題的最終隱藏狀態初始化第三個double-LSTM以生成答案,最后,在解碼器階段,針對多項選擇題、開放式(數)題和開放式(字)題設計三個解碼器生成答案,本文的貢獻在于將問題中的每個單詞分別用于參加視頻中的每一幀,以及每一幀中對應的區域,時空資訊在與問答對相關聯的同時被保留,
論文[38]提出了序列視頻注意力模型和時間問題注意力模型,并將其集成到編碼器中,首先,使用雙lstm分別對問題和視頻進行編碼,編碼器生成的問題表示記作hq={hf q;hb q},同樣,編碼器生成的視頻表示記作hv={ hf v;hb v},其次,提出了兩種注意模型,一種是順序視頻注意模型,它不僅關注視頻的相關幀,而且沿著問題的順序結構反復積累資訊,以獲得問題引導的視頻表示,另一種是時間問題注意模型,它不僅關注每一幀的問題,而且在時間維度上不斷累積以獲得視頻引導的問題表示,第三,將這些模型集成起來,為解碼器生成背景關系表示,該譯碼器由兩個堆疊的單層LSTM組成,其中頂層LSTM用零向量激活,頂層LSTM的輸出直接作為底層LSTM的輸入,直到生成句尾標記eos,最后,底層LSTM對向量進行解碼,通過一個全連通層和一個softmax層生成答案,
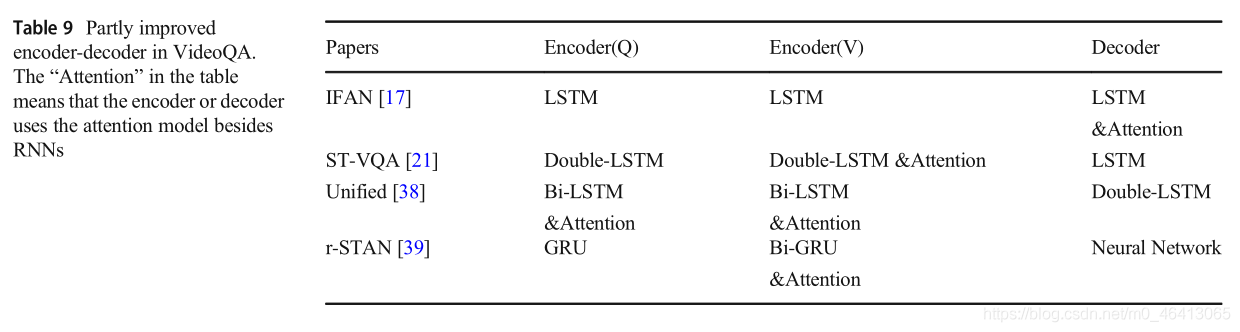
論文[39]提出了將多層次時空注意力網路集成到編碼器中,首先,由于幀級視頻特征不足以捕獲細粒度資訊,自然可以選擇空間注意模型,根據問題自動定位每幀中的目標區域,得到空間參與的幀表示vf,用Bi-GRU對表示vf進行編碼,得到隱藏狀態表示hf,然后,為了減少冗余的視頻幀,顳注意力模型提出了估計視頻幀的相關性問題,并輸出標準化的時間關注分數β∈(0,1),此外,一個與注意力門格勒烏網路是用來學習時空的順序敏感表示出席,與基本GRU模型不同,GRU模型的輸入是hf和βi,當前的估計狀態是基于輸入高頻產生的,然后,GRU網路根據估計狀態和之前的隱藏狀態ht?1更新其隱藏狀態,并將更新門向量設定為標準化得分βi,然后,得到了時空出席的順序敏感表示,記為hT,這是GRU模型的最后一個隱藏狀態,最后,通過引入多步推理程序進一步提高了VideoQA模型的性能,并在第r次更新后獲得時空視頻的聯合表示,以提高泛化性能,在解碼器中,答案由時空視頻的聯合表示生成,僅對VideoQA的編碼器和解碼器部分進行擴展的作業如表9所示,
3.1.3 Fully improved encoder and decoder
充分改進的編碼器-解碼器模型優化了編碼器和解碼器部分,本文研究了多回合視頻質量保證任務,與單回合的VideoQA任務相比,VideoQA資料集包含多回合的問題-答案對,首先,利用I3D網路提取幀級視頻特征;其次,在問題引導的視頻表示模型中,使用雙lstm網路對問題進行編碼,并將前向隱藏狀態和后向隱藏狀態連接起來,得到最終的問題表示,第三,通過測量多模態特征之間的相似度,提出三線性函式來識別與問題最相關的視頻幀,注意模型可以在時間域內剔除不相關的幀,因此,提出了一種選門機制來從每一幀中選擇與問題相關的區域,最后,將問題編碼程序中獲得的隱藏狀態初始化譯碼網路,在t時間步,使用t?1時間步的隱藏狀態對問題中的單詞進行關注,使用最后一個隱藏狀態生成答案,
充分改進的編碼器-解碼器模型優化了編碼器和解碼器部分,本文研究了多回合視頻質量保證任務,與單回合的VideoQA任務相比,VideoQA資料集包含多回合的問題-答案對,首先,利用I3D網路提取幀級視頻特征;其次,在問題引導的視頻表示模型中,使用雙lstm網路對問題進行編碼,并將前向隱藏狀態和后向隱藏狀態連接起來,得到最終的問題表示,第三,通過測量多模態特征之間的相似度,提出三線性函式來識別與問題最相關的視頻幀,注意模型可以在時間域內剔除不相關的幀,因此,提出了一種選門機制來從每一幀中選擇與問題相關的區域,最后,將問題編碼程序中獲得的隱藏狀態初始化譯碼網路,在t時間步,使用t?1時間步的隱藏狀態對問題中的單詞進行關注,使用最后一個隱藏狀態生成答案,
提出了JSFusion[42]來度量視頻質量檢測中任意一對多模態之間的語意相似度,JSFusion由聯合語意張量(joint semantic tensor, JST)和卷積層次譯碼器(convolutional hierarchical decoder, CHD)兩部分組成,JST是一種編碼器網路,它將兩個模的序列壓縮成稠密張量表示,CHD是一個解碼器網路,通過發現隱藏的層次匹配來計算兩種序列模式之間的相似性,這兩個模塊都利用了層次注意模型來提升匹配良好的表示模式,同時以自底向上的方式剔除不匹配的表示,首先,在編碼階段,使用雙lstm對問題進行編碼,融合前向/后向隱藏狀態得到問題表示,使用CNN獲取視頻表示,其次,將問題表示和視頻表示嵌入到同一個特征空間中,將問題用于觀看視頻,獲得問題引導的視頻表示;在解碼時,CHD計算一對多模態序列的兼容性得分,并將JST張量通過一系列卷積層和卷積門控塊進行前一層的匹配嵌入,最后,通過平均池化得到視頻-問題表示,并將其輸入到稠密層中進行預測,
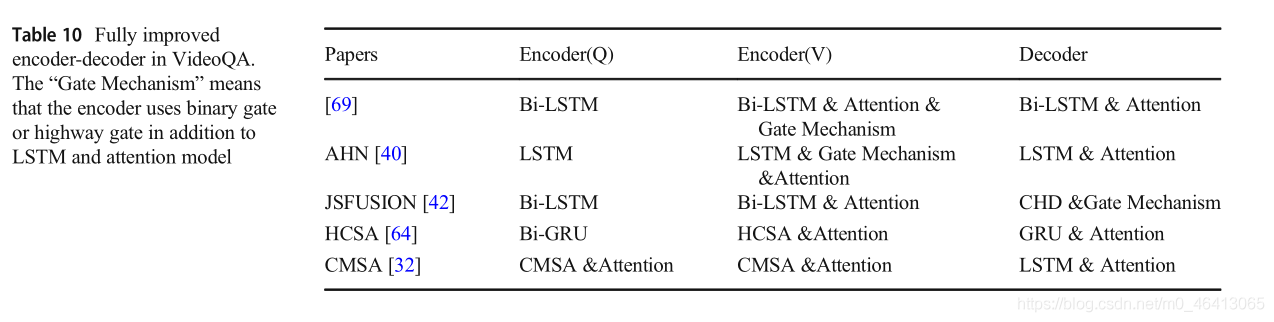
文獻[64]提出了一種分層卷積自注意編譯碼網路(HCSA)來解決長格式的視頻qa任務,首先,利用預先訓練好的3D-ConvNet提取幀級視頻特征,然后輸入線性投影進行降維,利用預先訓練好的word2vec提取問題特征,然后輸入Bi-GRU模型學習問題語意表示,其次,針對表9部分改進的VideoQA編譯碼器,提出了HCSA編碼器,表中的“關注”意味著編碼器和譯碼器使用注意模型除了RNNs論文編碼器(Q)編碼器(V)譯碼器如果[17]LSTM LSTM LSTM注意ST-VQA [21] Double-LSTM Double-LSTM注意LSTM統一[38]B i - L S T M注意Bi-LSTM注意Double-LSTM r-STAN[39]格勒烏Bi-GRU關注神經網路移動Netw:編碼,它由L個卷積的自我注意層組成,每一層由兩個卷積單元、一個注意分割單元和一個問題感知的自我注意單元組成,卷積單元可以有效地建模長格式的視頻內容,注意分割單元將長形式的視頻內容分割成不同的片段,利用問題資訊學習注意的片段級表征,具有問題意識的自我注意單元以問題為引導,捕捉長形式視頻的資訊,HCSA編碼器輸出多層視頻語意表示作為多尺度關注解碼器網路輸入,最后,基于多尺度視覺線索的多尺度細心解碼器對自然語言問題進行了回答,本文的貢獻在于解決了傳統RNN編譯碼框架中由于長期依賴而導致的建模能力不足和計算復雜度高的問題,本文[32]提出了跨模態自我注意(cross-modal self-attention, CMSA)編碼器和LSTM解碼器模型,以解決基于LSTM方法的長期依賴性和局限性問題,首先,提取幀級視頻特征和區域級視頻特征,利用語意豐富嵌入(SRE)模塊將區域級視頻特征和幀級視頻特征嵌入到同一個特征空間中,利用自我注意模型捕獲長視頻之間的時間關系,得到自我注意的SRE表征,其次,將SRE表示作為查詢矩陣,通過不同權重矩陣對字幕特征進行初始化,得到關鍵矩陣和值矩陣;在變壓器編碼器上輸入查詢、鍵和值,通過CMSA得到不同型號vcmsaa的聯合表示,最后,在解碼器中,將平均vcmsaa輸入一個雙層MLP網路,其輸出用于初始化解碼器的隱藏狀態和存盤單元狀態,這個問題被用來參加自我注意的SRE表征,以產生最終的答案,本文的貢獻在于利用不同模態的自我注意模型捕獲模態之間的高級語意資訊,改進VideoQA編碼器和解碼器模型的作業如表10所示,
3.2 Attention model
從自然語言處理領域的著作[83,84]到計算機視覺領域的著作[85,86],注意模型受到了極大的關注,在自然語言處理、統計學習、語音識別和計算機視覺等領域,注意力模型已經成為神經結構的重要組成部分,注意力是由人體生理系統直接驅動的典型例子,人們在觀看狗狗照片時,會選擇性地將注意力集中在照片中的狗身上,而忽略不相關的資訊,如上所述,我們可以把狗當作一個查詢,把照片當作一個來源,注意力模型的主要目標是定位圖片中包含狗的區域,注意模型可以被描述為一個函式,它將一個查詢和一組鍵值對映射到一個輸出[87],其中查詢、鍵、值和輸出都是向量,
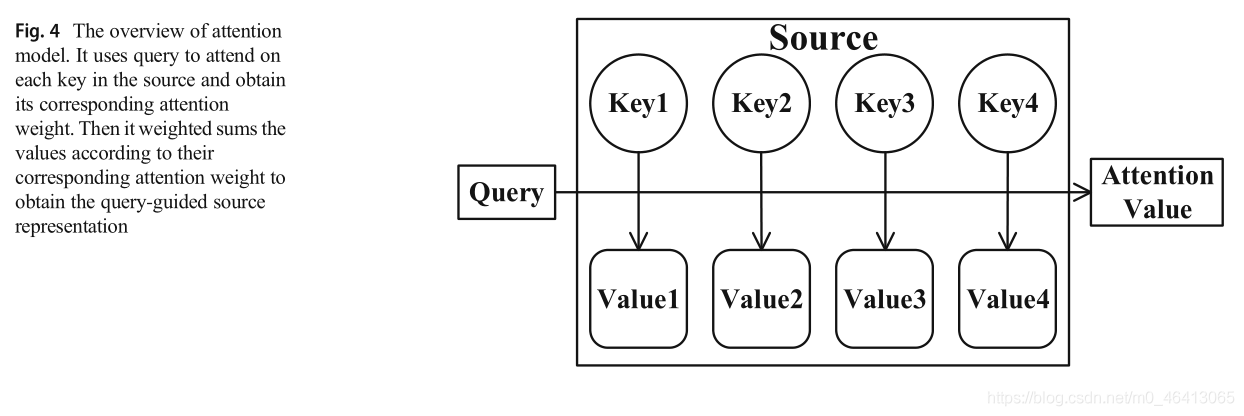
圖4顯示了注意力模型的框架,將查詢和來源輸入注意模型,并輸出注意值,具體來說,在計算注意分布時,查詢作為參考或指南,由鍵-值對組成的源表示為關注物件,其中鍵和值是由不同權重矩陣初始化的源表示,注意力價值是注意力的結果,注意力模型的思想是計算源上的權重分布,將更高的值分配給與查詢相關的元素,因此,查詢引導的源表示由以下方式生成:

分數函式輸出一組標量分數,表示匹配或組合的質量,并實作對查詢和鍵之間的語意資訊的解釋,對齊函式將評分轉換為關注權重αi,α是查詢與源相關的概率,常見的對齊函式是softmax函式,它將所有的分數歸一化為概率值,生成背景關系函式是這些值及其對應的注意權值的加權和,它生成一個查詢引導的源表示,查詢引導的源表示是一種最終表示,它關注與查詢相關聯的源的位置,
由于注意模型給出的結果具有通用性、直觀性和可解釋性,因此在以問題為查詢物件、以視頻為資料源的視頻qa中得到了廣泛的應用,根據注意在視頻問答任務中的應用,我們將注意模型分為:單跳問題引導的注意模型、多跳問題引導的注意模型、視頻問題共同注意模型和自我注意模型,單跳表示源只參與一次,多跳表示不止一次,隨著注意數量的增加,多跳問題引導注意所達到的準確性超過了單跳問題引導注意,在共同注意模型中,問題引導的注意和視頻引導的注意被執行并合并,在自我注意模型中,根據序列的不同位置計算一個表示,
相應的調查[88-90]對注意事項給出了更詳細的說明,為了避免混淆,在進一步討論之前,我們先解釋一些縮寫,Q Guided S是question-guided source的縮寫,根據問題參加視頻的方式為Q→V,根據問題參加背景關系的方式為Q→C
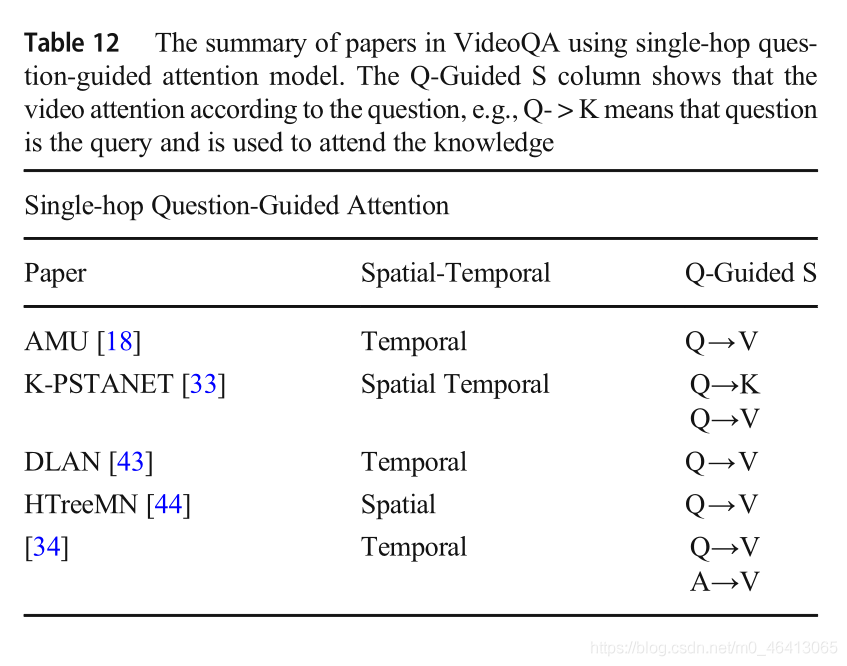
3.2.1 Single-hop question-guided attention model
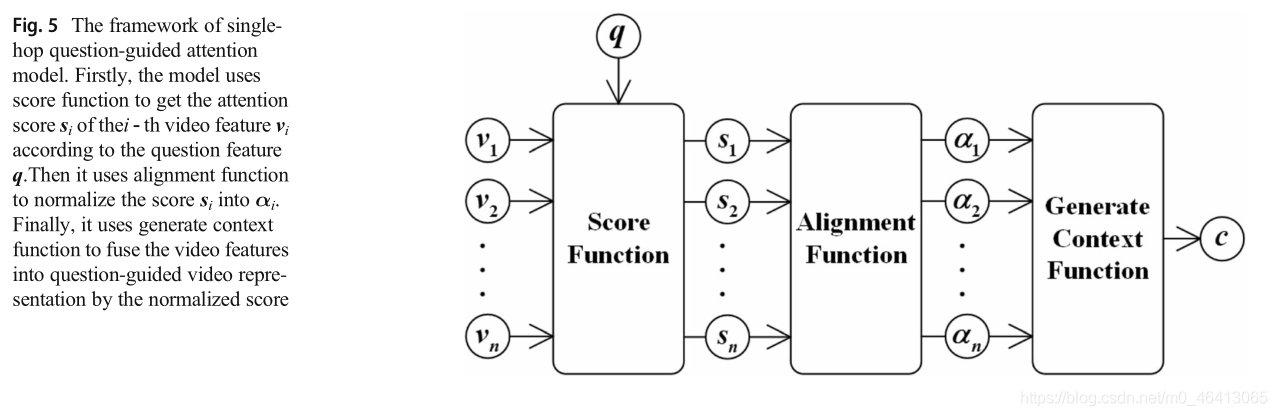
圖5顯示了單跳問題引導注意模型的架構,源是一個包含區域級、幀級和剪輯級特性的視頻特性,Key和value被作為源表示的同等權重的矩陣初始化,利用問題特征q參加幀級視頻特征{v1,v2,…,vn},其中為視頻中采樣的幀級特征個數,問題引導的視頻呈現是注意力的結果,問題引導的注意模型可以表示為:
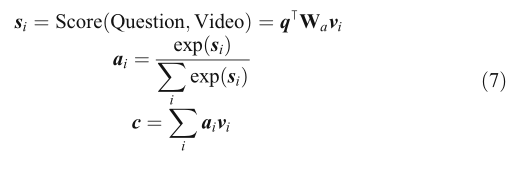
這里我們選擇一般得分函式來計算si, Wa是一個權重矩陣,
表11給出了常用的評分函式

論文[18]提出了一種端到端的視頻qa模型,首先,將VGGNet提取的幀級視頻特征定義為外觀特征;針對運動特征,定義了C3D提取的剪輯級視頻特征,將問題轉換成詞向量,然后輸入到LSTM中,隱藏狀態記住了處理過的單詞的資訊,其次,逐字分析問題,并利用注意記憶單元(AMU)在每個時間步上細化對外觀和運動特征的注意;AMU包括四個步驟:注意、通道融合、記憶和提煉,注意根據問題對外觀和動作特征進行注意,得到問題引導的視頻表示,表示為Q→V,注意程序分兩次進行,信道融合融合特征生成中間視頻表示,記憶是一個LSTM網路,它控制二次注意操作的輸入并記憶注意歷史,在Refine中,在第一和第二注意力權重被細化后,生成視頻表示,將在下一步中使用,第三,在對問題的所有單詞進行處理后,模型生成了一個精煉的問題引導視頻表示,這是回答問題最相關、最重要的資訊,最后,利用問題資訊、注意歷史資訊和優化后的注意表征生成答案,
人們不僅考慮用視覺內容來回答問題,還會在腦海中回顧知識,除了視頻內容外,參考外部知識是必不可少的,論文[33]提出了一種基于知識的漸進時空注意網路(K-PSTANet),該網路不僅考慮了視頻的時空特征,而且利用外部知識來提高問題的回答能力,首先,使用Faster-RCNN模型提取區域級特征,使用VGGNet提取幀級特征,將這兩種特征融合為視頻表示,來自DBpedia[92]的外部知識由Doc2Vec模型編碼[93],將問題轉化為單詞嵌入,逐字輸入LSTM,其次,在每個時間步驟中,分別使用問題感知的知識注意(ATTKnowledge)和時空注意(STA)單元生成問題引導的知識表示和問題引導的視頻表示,atti - knowledge利用問題的隱藏狀態對知識特征進行注意,記為Q→K,然后,將問題引導的知識表示為外部先驗知識來回答問題,第三,在STA單元中,將外部先驗知識和問題隱藏狀態連接為一個查詢來參加視頻表示,記為asQ→V,然后,得到幀級視頻表示,并將其輸入雙lstm得到階敏感表示,最后,在對問題中的所有單詞進行處理后,融合視頻表示、問題和知識生成答案,
許多現有的作品將整個問題作為一個查詢來執行對視頻的注意,這在視頻qa中可能是無效的,論文[43]提出了分層雙層注意網路(DLAN),DLAN模型包含細粒度的詞級注意模型和粗粒度的問題級注意模型,學習問題引導的框架表示和問題引導的片段表示,并將其連接起來回答問題,首先,利用VGGNet網路提取幀級特征,利用C3D網路提取段級特征;其次,為了獲得細粒度的詞引導視頻表示,首先,將問題單詞分別處理幀級和分段級視頻特征,生成詞引導的幀表示和詞引導的段表示;第三,為了獲得粗粒度的問題引導視頻表示,在第二級,對幀級視頻特征和分段級視頻特征對問題進行關注,分別獲得問題引導的幀表示和問題引導的段表示,最后,問題對第二級特征進行注意,以獲得與問題最相關的視頻表示,這些視頻表示用于生成最終答案,
DLAN雖然獲得了一個細粒度的詞級視頻表示,但它忽略了需要不同出席的不同詞和不需要本質出席的無意義詞,論文[44]提出了異構樹形結構記憶網路(HTreeMN),利用問題中的單詞構造語意樹,HTreeMN模型根據單詞型別對樹中的單詞進行處理,與其他型別不同的是,視覺詞在視頻中是與特定區域相關的,所以只有當這些詞屬于視覺詞時,它們才會被關注,HTreeMN的程序如下,首先,將節點分為葉節點、中間節點和根節點三類,葉節點對應于問題中的單詞,由當前節點的單詞參與的視頻輸出一個單詞引導的視頻表示,其次,中間節點對應著NP、VP、NN等句子中間表示,其注意結果是所有子節點注意的累積,根節點的計算方法與此相同,HTreeMN模型利用語法樹結構屬性,將單詞組合成短語,再組合成句子,最后,使用softmax函式根據根節點的注意力生成最終答案,本文的貢獻是通過注意融合的方法將單詞以葉到根的方式傳播,從而理解問題和視頻之間的語意資訊,
論文[34]提出了一種通過多任務學習獲取多模態視頻質量額外監督的方法,該方法由三個主要部分組成:
(1)基于視頻特征、字幕特征、問題和候選答案的多模態視頻qa網路預測答案;
(2)時間定位網路,根據問題定位視頻的開始時間和結束時間;
(3)模態比對網路正確關聯視頻特征和字幕特征,
該多模態視頻問答網路提出了一種背景關系-查詢關注層,將問題和候選答案表示為參與視頻特征的查詢,得到問題引導的視頻表示和答案引導的視頻表示,同時,背景關系-查詢層將問題和候選答案表示為參加字幕的查詢,得到問題引導的字幕表示和答案引導的字幕表示,將問題引導的表示和答案引導的表示融合起來預測最終答案,本文的貢獻是與VideoQA網路的高層共享引數,并提供額外的協作學習信號,以提高回答問題的性能,單跳問題引導注意模型如表12所示,
3.2.2 Multi-hop question-guided attention model
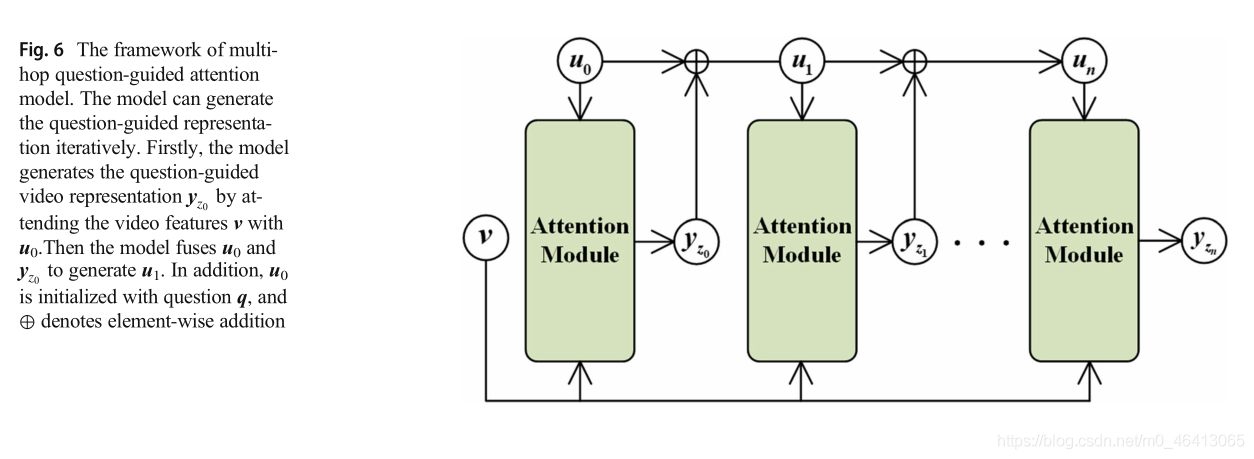
圖6展示了多跳問題引導注意模型的體系結構,該模型以問題q為查詢物件,在視頻v上迭代執行注意,在上述注意程序中,模型使用多跳查詢逐步細化視頻上的注意,多跳模型使答案比單跳模型更準確,隨著跳數的增加,準確性也會提高,已知第k - 1次注意的結果yzk?1(Q;V),一個多跳模型可以表示為:

其中u0用問題q初始化,uk通過匯總uk?1和yzk?1(Q;V)進行更新,更新后的uk用于檢索相關視頻,在處理復雜的時間推理任務時,多跳問題引導注意模型能夠在多次跳后成功定位答案,VideoQA中的多跳問題引導注意模型總結在表13中,我們將在下文中詳細討論每篇論文,
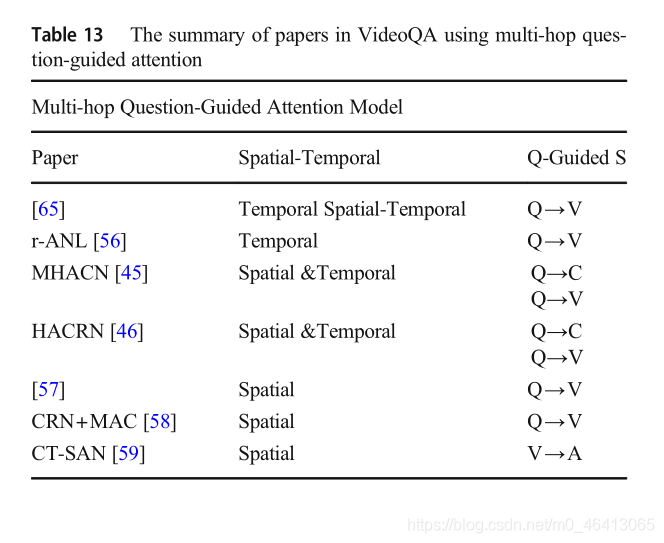
文獻[65]提出了一種解決視頻qa任務的注意框架,該框架由時間注意模型、時空注意模型和全域背景關系嵌入模型三部分組成,時間注意模型將問題視為查詢,在幀級視頻特征上進行單跳注意,得到問題引導的視頻表示,為了更好地定位視頻區域,采用了多跳時間注意模型,時空注意模型將問題作為查詢對視頻區域級特征進行注意,并在每一幀中獲得標記的區域級特征,與通過注意力模型獲得的視頻特征相比,全域背景關系嵌入模型捕獲全域視頻特征,然后將視頻特征輸入到由兩層MLP組成的網路中,論文[56]提出了一種屬性增強注意網路(r-ANL),通過多步推理生成答案,類似于paper[65],不同的是,提取視頻中的屬性標簽來迭代關注視頻,
論文[45]提出了**具有多步推理的多回合層次注意背景關系網路(MHACN)**來解決多回合視頻問答任務,MHACN模型根據視頻生成答案,與給定的問題和對話語境相關聯,會話背景關系包含多組問答對,首先,利用問題對對話語境進行注意,得到問句引導的對話表征,MHACN將問題和問題引導的對話表征進行了歸納,得到了情境感知的問題表征,其次,利用背景關系感知的問題表征對框架中的區域級特征進行空間注意,獲得其問題引導的框架級視頻表征;第三,利用情境感知的問題表征分別對問題引導的幀級視頻特征和分段級視頻特征進行時間注意,以學習上述兩種問題引導的問題表征,最后,為了更好地定位視頻中的目標區域,使用多跳推理程序生成最終的視頻表示來預測答案,論文[46]的思路與[45]相同,不同的是它使用了基于增強解碼器網路的問題引導視頻表示來生成答案,
與以往的多跳推理不同,論文在[57]中提出了ta-GRU網路,它可以隨著時間戳擴展推理,taGRU網路是一種改進的GRU網路,其隱藏狀態轉移程序與時間注意相關,首先,利用問題對區域級視頻特征進行注意,以獲得問題引導的視頻表示,然后,將區域和問題引導的視頻表示連接到ta-GRU網路中,第三,利用問題生成當前狀態和之前所有升級后的隱藏狀態的注意權重,得到最終的隱藏狀態,最后,用ta-GRU的最終隱藏狀態來預測最終答案,
論文[58]提出了一個端到端層次結構的視頻qa模型,該模型由一個基于剪輯的關系網路(CRN)和一個記憶-注意組合網路(MAC)組成,用于預測答案,首先,對于視頻表示,CRN將問題作為查詢,對剪輯級特征進行注意,獲得問題引導的視頻表示,同時,它也適用于物件、動作和時空資訊中的關系,然后,將問題引導的視頻表示作為知識庫輸入MAC,MAC協同控制單元、讀單元和寫單元對知識庫進行迭代操作推理,從而計算出中間推理結果,最后,利用MAC的最終輸出表示來生成答案,
論文[59]提出了一種新的高級概念詞檢測器,該檢測器以視頻和相關問題作為輸入,為每個視頻生成高級概念詞串列,采用軟注意模型的LSTM網路檢測跨幀區域一致出現的概念詞,概念追蹤語意注意網路(CT-SAN)是一個具有多步推理能力的語意注意模型,由兩種語意注意功能組成,將t - 1時間步的預測標簽作為輸入語意注意功能的輸入,對概念詞進行注意,得到了t時間步的標簽引導的概念詞表征,將隱藏狀態的atttime步長和視頻作為輸出語意注意函式的輸入,對概念詞進行注意,得到視頻引導的概念詞表征,輸入和輸出語意注意函式協同作業,通過多跳迭代推理得到最終預測詞,
3.2.3 Video-question co-attention model
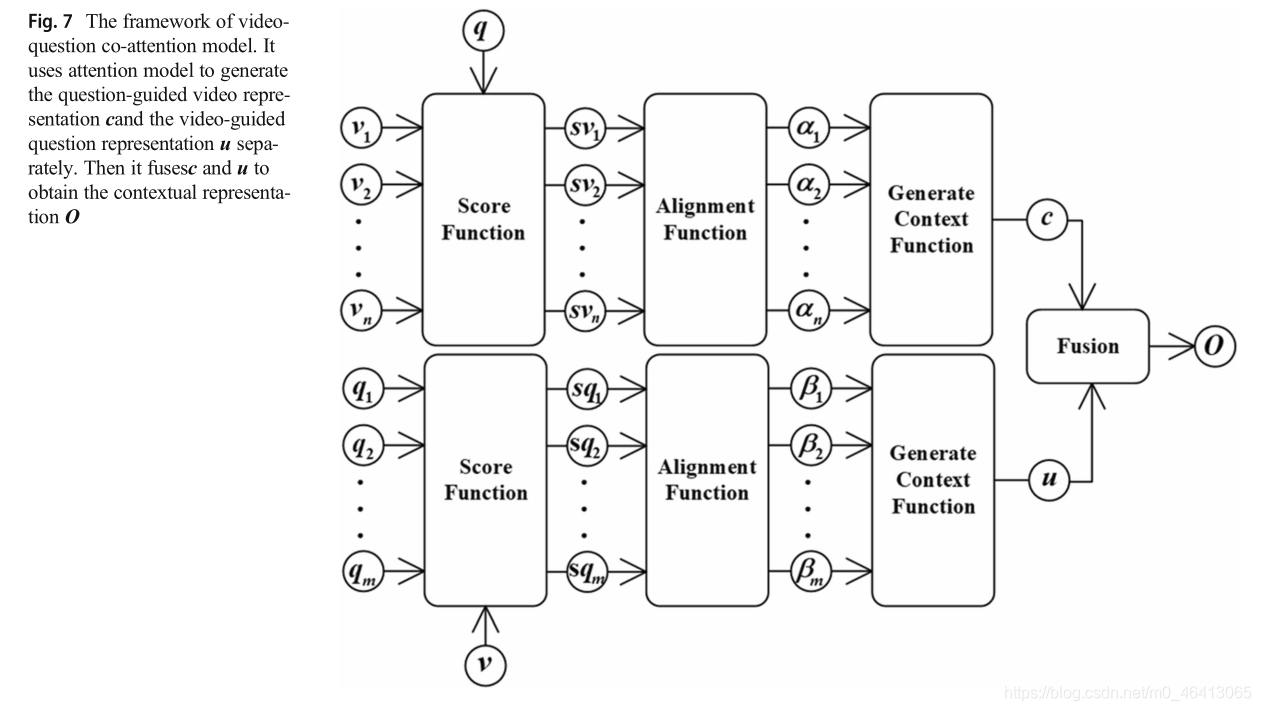
視頻-問題共同注意模型同時處理視頻和問題,通過共同學習兩者的注意權重來捕獲視頻和問題之間的互動,視頻-問題共同注意模型是一個對稱模型,其結構如圖7所示,問題引導的視頻注意模型將問題作為查詢表示,對視頻特征{v1,v2,…,vn}進行注意,其中n為幀數,與此同時,視頻引導的問題注意模型使用視頻作為查詢的表示來對問題特征{q1,q2,…,qm}(其中m為單詞數)進行注意,問題引導的視頻注意可以減少視頻中與問題無關的冗余資訊,獲得的視頻顯示了“往哪里看”,視頻引導的問題注意還可以減少問題中與視頻無關的冗余資訊:
所以它揭示了“該聽哪些詞”,然后融合問題引導的視頻表示c和視頻引導的問題表示u作為回答問題的重要表示,視頻-問題共同注意模型表示為:
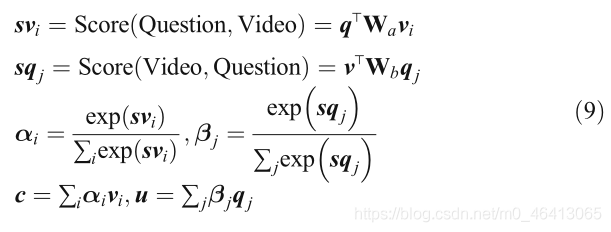
其中Wa和Wb是權矩陣,VideoQA中的視頻-問題共同注意模型如表14所示,下面我們將對每篇論文進行詳細討論,
[47]論文提出了re-watcher模型和re-reader模型,并將其結合到遺忘-watcher模型中,以更好地利用視頻的時間資訊和答案的短語資訊,首先,該模型將問題與其對應的候選答案連接成一個QA句子,使用兩種獨立的雙lstm將QA陳述句和視頻編碼到聯合特征空間中,然后,將QA陳述句和視頻資訊輸入到再觀看模型中,輸出問題引導的視頻表示,重看模式模仿了一個人,這個人需要反復閱讀問題來記住視頻內容,再次,將QA陳述句和視頻資訊輸入到再讀模型中,輸出視頻引導的問題表征,重復閱讀模式模仿了一個需要反復觀看視頻來記住問題的人,最后,將rewatcher模型和rereader模型結合到遺忘-觀察者模型中,得到當前候選答案的得分,
論文[35]提出了一種多粒度時間注意網路(MGTA-Net),該網路通過共同注意模型學習多粒度視頻和問題特征,獲得與答案相關的全域和部分視頻資訊,基于物件級視頻特征、幀級視頻特征和問題特征,構建了細粒度物件協同注意模型和粗粒度視頻協同注意模型,細粒度物件共同注意模型同時處理物件級視頻特征和問題,并共同學習它們的注意權值,以捕獲它們之間的互動,粗粒度視頻協同注意模型同時處理幀級視頻特征和問題,并共同學習它們的注意權值來捕獲它們之間的互動,最后,將細粒度和粗粒度的物件表示融合在一起來預測答案,
3.2.4 Self-attention model
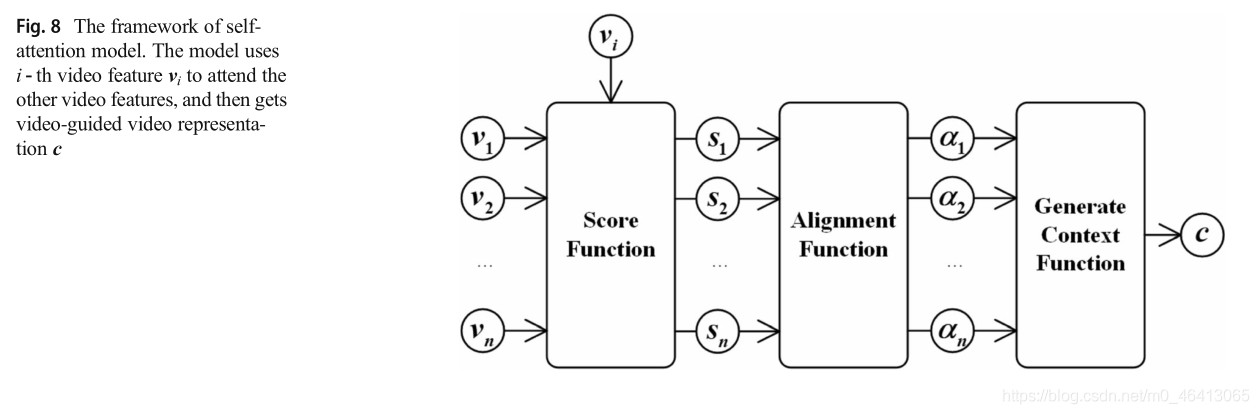
自我注意模型已經成功地應用于機器翻譯、語言理解、影像生成和問題回答等多種任務中[94-99],自我注意模型不同于前面提到的其他注意模型,它通過以相同的順序參與所有位置來計算每個位置的權重分布,在自我注意模型中,鍵、值和查詢來自相同的序列,即query = key = value,圖8顯示了自我注意模型的體系結構,視頻特征vi .參加視頻特征v.自我注意的表征為:
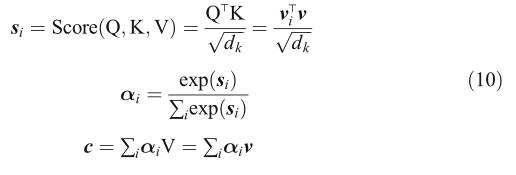
其中1/√dk 為比例因子,Q、K、V分別表示查詢、鍵、值,自我注意應用規模化的點積注意,多頭自我注意應用規模化的點積注意并行運行,多頭自我注意的表示形式為:

其中投影為引數矩陣WO;WQ i;WK i;WV i.多頭自我注意模型將查詢、鍵和值投影h次,以捕捉遠距離依賴關系和位置資訊,因此,它提高了理解相同序列中位置相關性的能力,VideoQA中的自我注意模型總結在表15中,我們將在下文中詳細討論每一篇論文,

論文[60]提出了一個帶有注意的位置自我注意模型,位置自我注意模型計算同一序列內所有位置的注意力在每個位置上的權重分布,然后加入絕對位置的表示,共同注意模型同時對視頻和問題進行注意,首先,PSAC對視頻進行位置自我注意,得到位置自我注意的視覺特征;其次,PSAC對問題進行了位置自我注意,獲得了位置自我出席問題的特征,為了共同注意來自不同位置不同子空間的資訊,位置自我注意采用了l尺度的點積注意,然后,基于視頻特征和問題特征構建相似矩陣,生成問題引導和視頻引導的問題表示,最后,將位置自出席視覺特征與兩種表征相結合,預測最終答案,
文獻[61]提出了一種多模態雙注意記憶(MDAM)模型,該模型利用自我注意學習框架和字幕中的潛在概念,首先,自我注意模型利用一個多頭自我注意來獲取潛在變數,使每個幀和字幕關注包括自己在內的所有幀和字幕,其次,將這些潛在變陣列合起來生成輸出張量,將輸出張量輸入到多點問題引導的注意模型中,得到視頻表示和標題表示,然后,利用該問題對視頻和字幕表示進行融合,得到一種多模態融合表示,最后,利用多模態融合表示和候選答案計算得分,得到最終預測答案,
3.3 Memory network
在長序列學習中,模型通常需要記住視頻的內容,并在很長一段時間內準確地找到與給定問題相關的內容,從而推斷出答案,因此,建立一個能夠描述視頻內容長期依賴性的模型是非常重要的,但也是具有挑戰性的,現有的大多數機器學習模型都缺乏能夠容易讀寫的長期記憶組件,并且可以與推理無縫結合,雖然rnn可以根據輸入序列進行預測,但其記憶體(由隱藏狀態和權值編碼)通常太小,無法準確記住視頻內容,
為了解決上述問題,論文[100]提出了一種新的學習模型,稱為記憶網路(memory networks, MemNN),其核心思想是構建一個可以讀寫的記憶組件,然后,將MemNN與成功的機器學習推理模型相結合,在那之后,這個模型被訓練來學習如何有效地利用記憶組件,MemNN在每次迭代時都需要由相應的支持事實進行監督,而大多數資料集僅由問答對的形式組成,
因此,論文[101]提出了端到端記憶網路(MemN2N),該網路可以從輸入-輸出對進行端到端的訓練,因此,該模型需要較少的監督培訓,更適合實際環境,此外,MemN2N也被擴展來處理多跳操作,隨著跳數的增加,模型的泛化性能有所提高,
文獻[102]提出了動態記憶網路(DMN),DMN包括情景記憶模塊,情景記憶模塊由注意模型和回圈網路組成,它可以通過多次迭代進行更新,該模塊將問題、之前的記憶和客觀事實作為當前迭代的輸入,然后在每次迭代中更新情景記憶單元,獲得當前的記憶,存盤網路在VideoQA中的應用總結在表16中,我們將在下文中詳細討論每一篇論文,
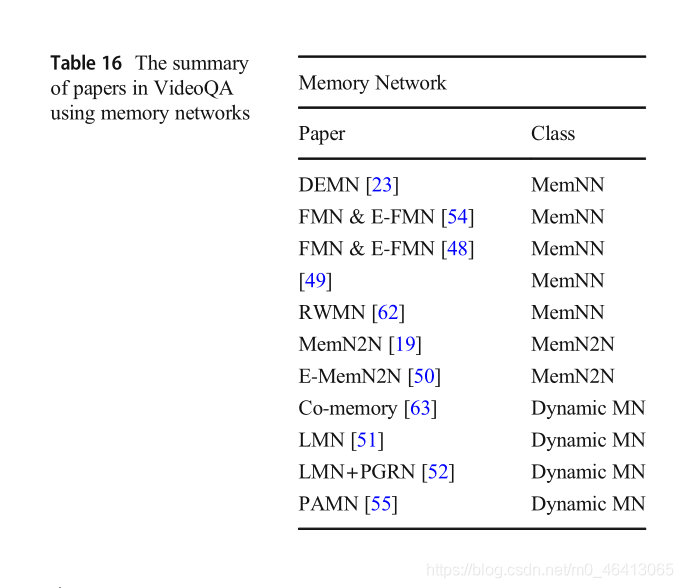
3.3.1 Memory networks
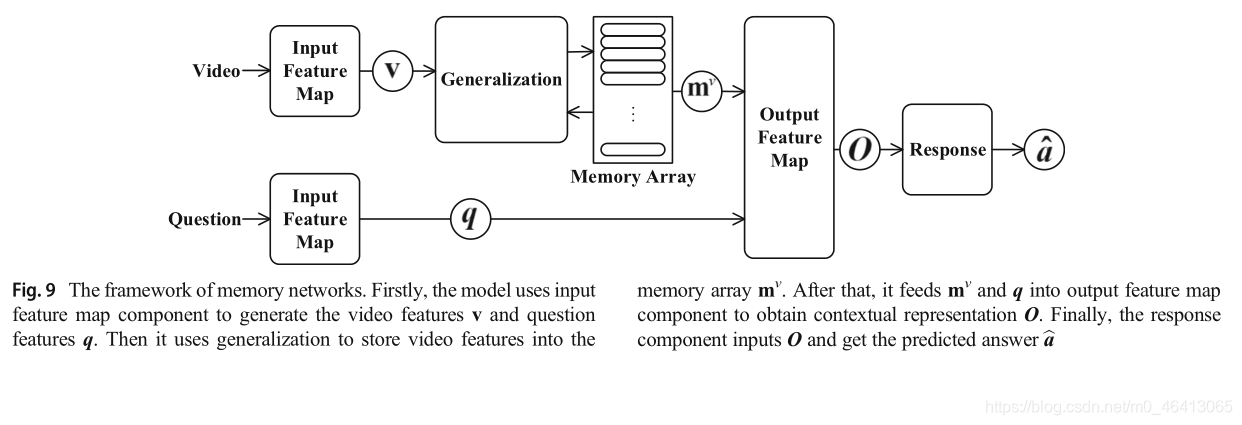
MemNN由一個記憶陣列M和四個可學習的成分組成:輸入特征映射、泛化、輸出特征映射和回應,記憶陣列M是用來存盤整個視頻內容的陣列,它可以保留視頻序列的長期記憶作為知識庫,然后,記憶可以用來推斷一個給定問題的答案,輸入特征映射組件提取視頻特征和問題特征,這在前面2.2節和2.3節中提到過,泛化組件接受將存盤在記憶體陣列中的內容作為輸入,并根據它更新記憶體陣列,在這個程序中,存盤陣列可以按順序更新,也可以通過復雜的操作進行廣義化,如通過非線性映射更新,輸出特征映射組件根據查詢結果和當前記憶體陣列狀態進行推理,得到特征空間中的背景關系表示,回應組件將背景關系表示轉換為預期的答案,具體程序見2.4.1節,存盤網路的總體結構如圖9所示,然后,介紹了在視頻qa研究中起著重要作用的記憶網路,
論文[23]提出了一種深度嵌入式存盤網路(DEMN)模型,該模型對存盤網路的泛化成分進行了改進,它使該組件能夠根據視頻特征和與視頻相對應的字幕特征生成故事描述,然后,泛化組件將故事描述按順序存盤到記憶體陣列M中,記憶體陣列被定義為一個故事集,它代表整個視頻內容,之后,輸出特征映射組件使用問題引導的注意模型來尋找與問題最相關的故事的?,最后,將s?與問題連接起來,得到sa作為回應組件的輸入,反應成分使用注意模型對sa與每個候選答案句子ai的匹配進行評分,然后選擇得分最高的候選答案作為最終預測答案,
論文[54]提出了遺忘記憶網路(FMN)模型,FMN修改記憶體網路的輸出特征映射組件,根據輸入的問題,修改后的組件可以專注于視頻中與問題相關的部分,而忽略其他不相關的部分,FMN在記憶體陣列中按順序存盤區域級特性,輸出特征映射組件首先計算存盤陣列的內積和獲取區域級特征權重的問題,然后,該分量通過計算top-k區域特征的加權和得到問題引導的視頻表示,最后,融合視頻特征和問題特征作為回應分量的輸入來預測答案,之后,[54]又提出了一種基于FMN的擴展遺忘記憶網路(e -FMN)模型,E-FMN利用GRU模型對視頻幀進行編碼,而不是簡單地求和,從而有效地捕捉視頻中的時間資訊,論文[48]pro對FMN模型和E-FMN模型提出了兩個改進,一方面,與僅使用視頻剪輯來解決VideoQA任務相比,將視頻剪輯和文本特征融合在一起可以獲得更好的性能,另一方面,選擇權重的中位數來忽略無用或不相關的資訊,
不同于以往將視頻特征按順序存盤在存盤陣列中的模型,論文[49]利用注意模型將每個輸入特征分配給所有的存盤單元,這些輸入特征被視為背景關系感知的視頻特征和問題特征,由于簡單的異構資料組合不能有效地表示視頻內容,提出異構視頻記憶學習運動和外觀的共同注意,從而獲得視頻表示,增強推理能力,異構視頻存盤器的存盤器結構包括用于存盤視頻內容的存盤器陣列,以及用于確定如何將視頻內容寫入存盤器的三種隱藏狀態,此外,還設計了寫操作、讀操作和隱藏狀態更新操作來有效地讀寫記憶體陣列的內容,寫操作分別輸入外觀和運動,根據隱藏狀態分別計算外觀、運動和記憶陣列的權值,然后根據權值更新記憶陣列的內容,讀取操作根據所述隱藏狀態和所述外觀和動作內容,確定每個存盤單元的權重,然后,它根據權重從記憶體陣列中讀取并融合內容,以獲得背景關系表示,隱藏狀態更新操作根據當前隱藏狀態和背景關系表示更新隱藏狀態,在此基礎上,外部問題記憶采用與問題相似的處理方法來獲得其表征,然后通過時間注意和LSTM的多步推理實作背景關系和問題的多模態融合,最后,根據問題生成答案,
文獻[62]提出了一種讀寫記憶體網路(RWMN)模型,RWMN將記憶體網路的泛化部分修改為寫網路和讀網路,首先,RWMN將視頻特性按順序存盤到存盤器陣列中,然后,RWMN設計了一個由多個卷積層組成的寫網路,使每個存盤單元與相鄰的視頻特征相關聯,然后RWMN設計了一個讀入問題的網路,提高了存盤陣列和問題之間的相關性,使后續的推理更加準確,讀網路首先通過微型斷路器將問題的特性集成到存盤器陣列中,然后,read網路通過多個卷積層對一系列場景進行連接和關聯,以改善對問題的理解,提高預測精度,最后,讀取網路得到一個重構的存盤陣列,用來推斷正確的答案,RWMN的輸入與[23]相似,推理和回答預測部分與MemNN相似,RWMN與其他記憶體網路模型的不同之處在于,RWMN的記憶體陣列的維數在更新程序中會變小,而其他模型的記憶體陣列的維數是靜態的,
3.3.2 End-to-end memory networks
MemN2N的架構與MemNN相似,而MemN2N改變了存盤陣列的結構和推理程序,增強了模型的連續性,因此,MemN2N可以從輸入-輸出對端到端的訓練,并顯著減少了訓練程序中必要的監督,以適用于現實應用,
MemN2N的特點是它使用兩個記憶體陣列來轉換輸入序列,一個是用于記憶內容資訊的存盤器陣列mv,另一個是用于推理生成輸出的輸出存盤器,具體來說,MemN2N可分為輸入記憶體表示、輸出記憶體表示和最終預測生成三個模塊,輸入存盤表示模塊首先使用嵌入矩陣A將輸入序列轉換為存盤陣列mvat,該模塊還使用嵌入矩陣B將問題嵌入得到內部狀態u,然后計算問題內部狀態與記憶體mv之間的匹配權值p,如下所示:
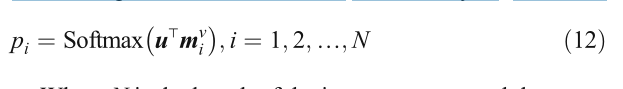
其中N是輸入序列和存盤陣列的長度,輸出存盤表示模塊首先利用嵌入矩陣c將輸入序列轉換成輸出存盤陣列mo,然后將輸出存盤陣列mo與匹配權值p加權求和得到回應向量c,如下所示:

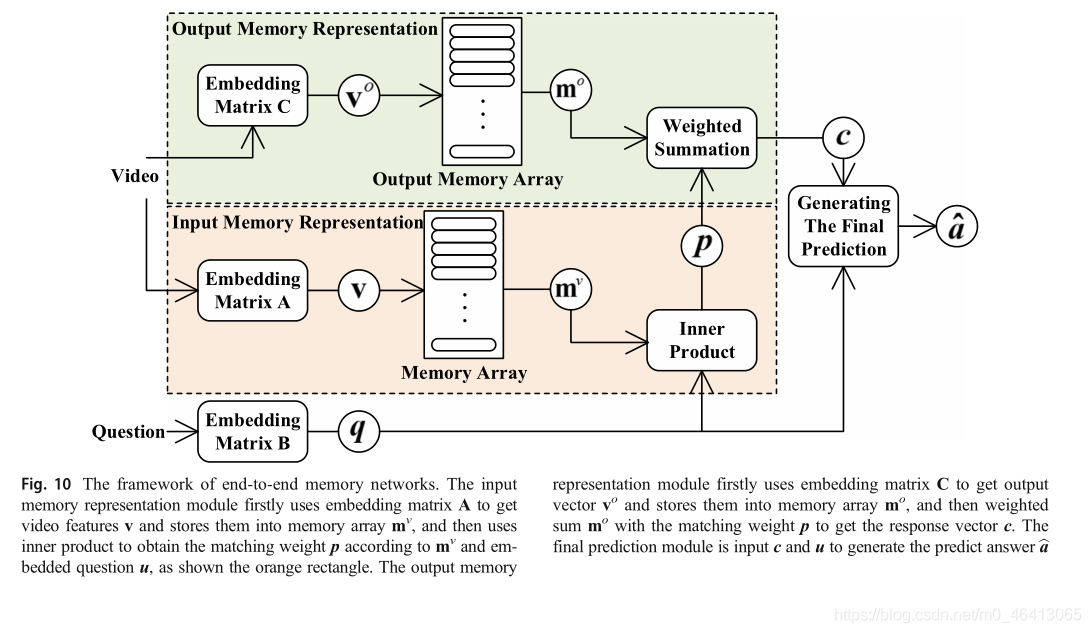
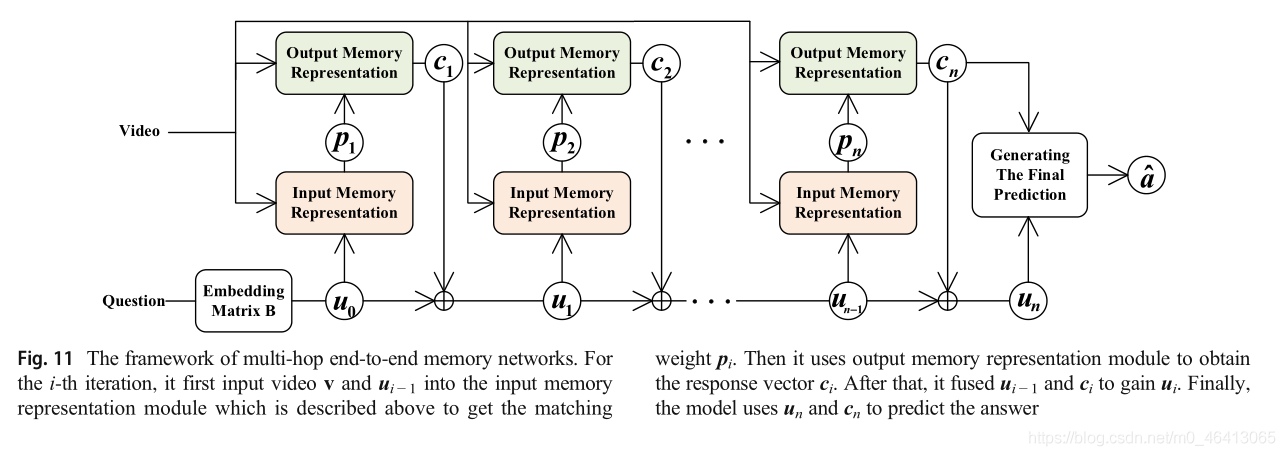
論文[19]將原有的MemN2N模型應用于VideoQA任務的MovieQA資料集,并根據MovieQA的特點,提出了MemN2N的兩個關鍵修改,第一個關鍵修改是增加了額外的嵌入層F來映射多個選項,使MemN2N模型能夠從多個選項中預測出正確的選項,然后,該模型計算候選答案、問題u和輸出結果之間的相似度來預測答案,由于VideoQA中的資料非常大,像原來的MemN2N那樣直接學習不同的嵌入矩陣會導致整個網路中有大量的引數,雖然共享所有不同嵌入矩陣的引數是可行的,但引數的數量仍然很大,因此,提出了第二種關鍵修改方法,即使用Word2Vec預先訓練的嵌入矩陣Z替換原始網路中的所有嵌入矩陣,使用共享的線性投影T將視頻和問題映射到同一個低維空間,這種改進有效地減少了需要訓練的引數數量,提高了學習效率,
論文[50]采用了多跳MemN2N模型,并對模型的輸入進行了修改,得到了擴展端到端存盤網路(E-MN)模型,該模型能夠捕捉連續幀中動作之間的時間關系,利用一組幀序列作為輸入,采用雙lstm對序列進行編碼,然后將編碼后的序列輸入到模型中,提高了模型對時間資訊的分析能力,以適應視頻質量保證的要求,
3.3.3 Dynamic memory networks
與MemNN和MemN2N不同,DMN在情景記憶模塊中修改泛化、輸出特征映射和記憶陣列,使記憶陣列可以由問題動態更新,DMN由四個模塊組成,輸入模塊、問題模塊、情景記憶模塊輸入特征圖輸入特征圖綜合輸出特征圖反應記憶陣列···視頻問題圖9記憶網路框架該模型首先使用輸入特征映射組件生成視頻特征v和問題特征q,然后使用泛化方法將視頻特征存盤到存盤陣列mv中,然后,將mv和q輸入到輸出特征映射組件中,得到背景關系表示O,最后,回應組件輸入O,得到預測答案b,像MemNN的輸入特性映射組件,輸入模塊使用格勒烏編碼輸入序列{x1, x2,…,xn}到事實表示{c1, c2,…,cn},問問題模塊編碼問題表示,迭代更新記憶程序是由q在情景記憶模塊,將事實表征{c1,c2,…,cn}和問題表征q輸入情景記憶模塊,情景記憶模塊使用q初始化情景記憶m0=q,在第i次迭代中,情景記憶模塊使用GRU來更新情景記憶:

其中⊙是元素的乘積,“;”是連接操作,使用情景記憶來預測答案的答案模塊與MemNN的反應模塊相似,答案模塊在情景記憶模塊的末尾或每次更新操作之后被觸發,綜上所述,DMN的記憶體陣列在推理程序中是動態的,而MemNN和MemN2N的記憶體陣列是靜態的,論文[35]相信動態記憶可以檢索一些資訊,被認為是不相關的在以前的迭代,以實作更好的推理,視頻QA DMN框架如圖12所示,接下來,我們將通過論文闡述如何將DMN的思想應用到視頻qa中,
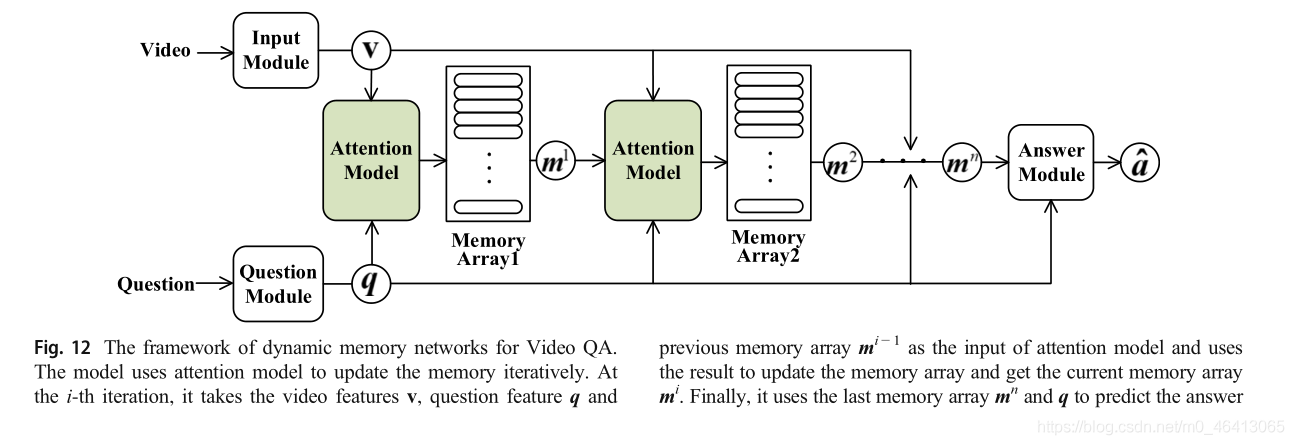
論文[63]建立了一種適用于視頻qa的DMN網路,它對輸入模塊進行了修改,將情景記憶模塊變為動作表象共同記憶模塊,改進后的輸入模塊包含多個時間卷積層,用于建模時間背景關系資訊,以及多個反卷積層,用于恢復時間解析度,該模型可以建立多層次的時態表示,每一層表示不同的背景關系資訊,輸入模塊分別應用于運動和外觀,以獲得運動的背景關系事實和外觀的co textual facts,運動-外觀共同記憶模塊包含兩個單獨的記憶陣列,一個用于運動,另一個用于外觀,運動-外觀共同記憶模塊的每次迭代包括三個步驟,共同記憶注意力、動態事實集成和記憶更新,共同記憶注意分別利用先前的運動記憶、先前的外表記憶和疑問對運動事實和外表事實進行注意,得到運動注意門和外表注意門,動態事實集成根據相應的關注門獲取事實的權重,然后對事實進行加權求和,得到整體事實,記憶更新使用基于注意的GRU將集成事實和相應的注意門編碼為當前的背景關系事實,通過這些事實來更新記憶陣列,最后,運動-表象共記憶模塊將運動記憶和表象記憶連接起來,得到共同記憶,然后,回答模塊使用記憶體來預測答案,通過上述修改,模型不僅可以關注問題所涉及的不同時間特征,還可以根據需要關注外觀或運動資訊,
論文[51]提出了一種分層記憶網路(LMN)模型,該模型結合了視頻內容和字幕,提高了答案預測的性能,LMN的存盤模塊由靜態字存盤和動態字幕存盤兩部分組成,可以學習分層視頻表示,LMN有兩個版本,單跳和多跳,在單跳演算法中,靜態詞存盤器的詞存盤陣列存盤了整個資料集中的所有詞,用于學習區域的語意表示,該方法利用一幀內的所有區域,計算每個區域特征與單詞存盤陣列中每個單詞的相似度,得到每個單詞的權重,然后,LMN對所有詞進行加權求和,更新區域特征,然后,將每一幀的區域特征相加得到幀的表示,動態字幕存盤器中的字幕存盤陣列以句子的形式存盤字幕,用于表示剪輯,動態字幕存盤器以幀的表示作為輸入,計算存盤陣列中每一幀與每句話的相似度,得到每個字幕的權重,然后,該模塊對字幕進行加權求和來更新幀表示,對幀表示進行加權求和得到剪輯表示,最后,單跳LMN使用片段表示、問題和候選答案來預測正確答案,在多跳中,靜態詞存盤模塊只計算前一跳的區域表示與當前詞的相似度來得到當前的區域表示,而詞存盤陣列沒有更新,在完成最后一跳后,通過區域特征的加權和得到幀的表示,與單跳不同的是,多跳動態字幕存盤模塊利用當前的字幕存盤和視頻表示生成下一跳的字幕存盤,通過這樣做,模塊消除了不相關的字幕資訊,提高了推理能力,一般來說,單跳LMN的單詞記憶和字幕記憶對于視頻來說都是靜態的,所以我們認為單跳LMN模型是MemNN的一種變體,雖然多跳LMN的詞存盤是靜態的,但字幕存盤是通過視頻的幀表示動態更新的,因此多跳LMN模型被認為是DMN的變體,
論文[52]在[51]的LMN模型的基礎上,增加了一個plot graph representation network (PGRN),并引入了一個新的資料集PlotGraphs作為外部知識,PGRN用圖形表示視頻內容(如人物、情節等)之間的語意資訊和關系,認為結合LMN和PGRN可以更充分地表達視頻內容,并用于推理,PGRN包含多個節點,表示情節、角色、屬性、位置、時間、運動和原因,由于屬性節點只與人物相關,位置、時間、運動、原因等節點與情節相關,因此PGRN將它們分別進行融合,得到人物表示和情節表示,此外,角色往往與許多其他情節節點有關系,所以PGRN將情節作為圖的中心,然后,PGRN得到了包含節點語意資訊和節點之間關系的整個圖的表示,由于圖的描述可能包含與問題無關的冗余資訊,PGRN需要根據問題計算圖的權重,并根據權重更新圖的表示,最后,將LMN得到的視頻內容與PGRN得到的圖形表示進行融合,并用于預測答案,
論文[55]提出了漸進注意記憶網路(PAMN)模型,該系統包含四個模塊:雙記憶嵌入、漸進注意、動態模態融合和信念修正回答方案,雙存盤嵌入模塊利用前饋神經網路(FFN)將視頻和字幕分別嵌入到相應的存盤陣列中,漸進注意模塊以視頻記憶、字幕記憶、問題表征和答案為輸入,通過基于問題和答案的注意模型對視頻記憶和字幕記憶進行迭代更新,這個模塊通過積累線索來定位回答問題的相關時間點,并從記憶中過濾出對問題不必要的資訊,在注意模型對每個存盤陣列進行每個更新周期后,動態模態融合模塊根據兩個存盤陣列與問題之間的相關性,對兩個存盤陣列進行權重賦值,然后通過權重對視頻和字幕進行融合,得到視頻的融合記憶體,信念修正答疑方案利用信念來衡量每個考生答案的信度,對信念進行等概率初始化,并根據問題與候選答案之間的相關性進行第一次修正,然后,在迭代程序中利用融合記憶對信念進行動態修正,信念修正回答方案可以通過每次迭代連續預測答案,而不是在其他模型中只預測一次答案,使推理結果更加準確可靠,
3.4 Other methods

在以上三節中,根據核心處理模型的特點,詳細介紹了核心處理模型的三種型別,但也有一些模型有自己獨特的想法,一般不能將其劃分為以上幾類,這些論文的摘要見表17,
受生成式對抗網路[103]的啟發,論文[20]提出了一種對抗式多模態網路(AMN)模型,并將自我注意模型引入其中,AMN為視頻特征和相應的文本特征找到一個一致的子空間來獲得多模態特征表示,并保持多模態表示與原始視頻之間的自相關性,AMN由三部分組成:對抗性多模態表征學習、基于自我注意的一致性約束和答案推理,對抗多模態表示學習是基于生成式對抗網路的思想設計的,生成式對抗網路由一個生成器和一個鑒別器組成,該演算法用于尋找視頻特征與相應文本特征之間具有高相關性的子空間,該生成器由兩個不同的注意模型組成,用于學習視頻的多模態表示,第一個注意模型將視頻的區域特征映射到一個單詞空間中,并將所有區域特征相加得到幀特征,第二種注意模型將幀特征映射到字幕空間,得到視頻特征,訓練識別器將視頻的文本特征與生成器學習到的多模態表示區分開來,針對多模態表示產生時可能丟失資訊的問題,提出了基于自我注意的一致性約束,由于原始視頻和多模態表示的維數不同,AMN引入了自我注意模型將兩個表示映射到一個固定的空間中,答案推理采用多模態表示、問題和候選答案來預測答案,并更新字幕來洗掉字幕中的不相關資訊,
論文[37]提出了一種基于基礎證據的時慷訓答者(STAGE)模型,該模型利用時空域來回答問題,STAGE的核心思想是生成一個與問題和答案最相關的跨度提案,并用它來預測答案,這可以過濾掉無關的資訊輸入模塊問題模塊注意力模型記憶力Array1???注意力模型記憶力Array2???回答模塊???視頻問題圖12的框架動態記憶體網路視頻質量,該模型采用注意模型對記憶進行迭代更新,在第i個迭代,視頻功能v,問問題特性和之前的記憶體陣列mi?1作為輸入的注意模型,并使用結果來更新記憶體陣列并獲取當前記憶體陣列mi,最后,它使用最后一個記憶體陣列mnand問移動Netw預測答案:問題,并改善預測性能,首先,STAGE通過RCNN獲得視頻特征,通過BERT獲得文本特征,并使用卷積編碼器對視頻特征和文本特征進行編碼,其次,STAGE利用qa引導的注意生成視頻和字幕的qa引導表示,并將其融合得到融合后的視頻文本表示,第三,STAGE利用線性層、卷積編碼器和最大池化層得到輸出特征矩陣,然后,STAGE根據輸出的特征矩陣,實作一個跨度預測器,預測每個時間位置的開始和結束概率,然后應用動態規劃,根據開始和結束概率生成跨度建議,最后,STAGE用輸出特征矩陣生成一個全域假設表示,用span建議生成一個區域假設表示,并將它們連接起來預測正確答案,
4 Datasets

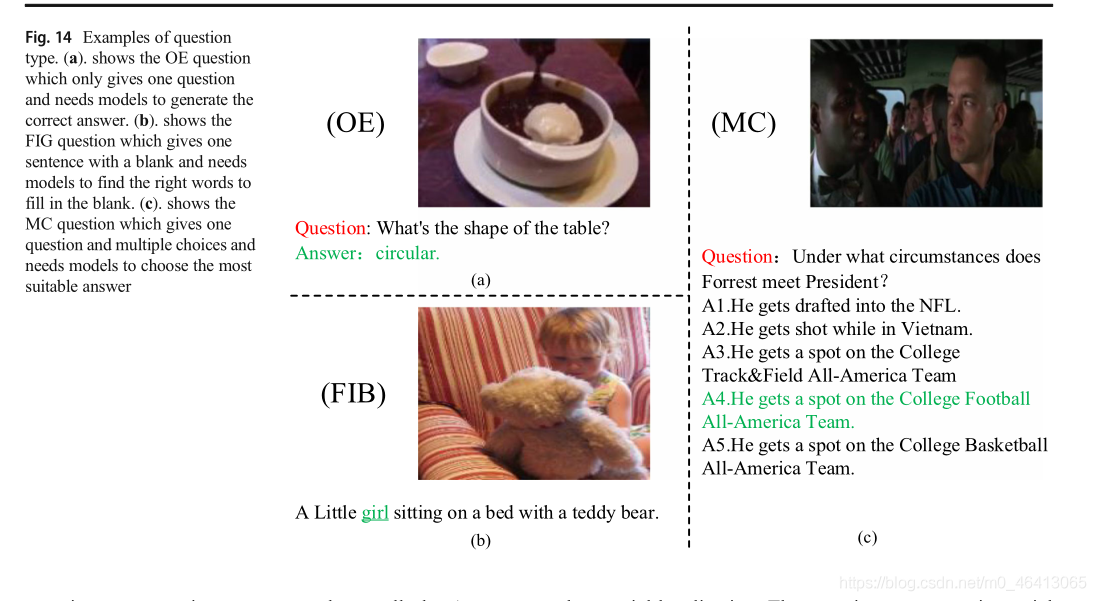
在VideoQA的大量研究作業中,已經專門為它收集了大量的資料集,我們根據視頻源對現有的典型VideoQA資料集進行了廣泛的分類,分為以下幾類:電影型別、電視型別、TGIF型別、幾何型別、游戲和卡通型別,此外,還有一些非特異性的資料集值得關注,這些資料集沒有包括在本次調查中,資料集樣本由一個視頻剪輯、一個問題和最少正確答案組成的三部分組成,在圖13中,資料集中各個類別的視頻內容顯示如下,以MovieQA資料集屬于電影型別為例,如圖13中的紅框所示,它的問題和答案分別用紅色和綠色標記,根據視頻剪輯的長度,可以分為短視頻和長視頻,長視頻包含了復雜而深刻的事件、動作和學習物件,其長度比短視頻要長,問題通常是自然語言描述句,即文本資料,一些特殊的資料集還提供額外的文本資料,如對話、說明、故事等等,目前的題型分為開放式(OE)、多項選擇(MC)和填空(FIB),OE問題是根據視頻剪輯的內容,在完整的句子系統的基礎上,自動生成正確的答案,具體的例子見圖14a,MC題是在對一題和多個備選答案(一般為1對4錯)的情況下,選擇一個準確的答案,如圖14b所示,F I B問題是根據給定的視頻和一個不完整的問題,從整個詞匯集中找到適合空白的單詞或短語,如圖14c所示,為了便于讀者比較和查看不同資料集之間的差異,列出了S om e di S t in ci v e資料集,如表18所示,最后,VideoQA的兩個主要評估標準Acc和wops在4.7節中介紹,
4.1 Movie Types
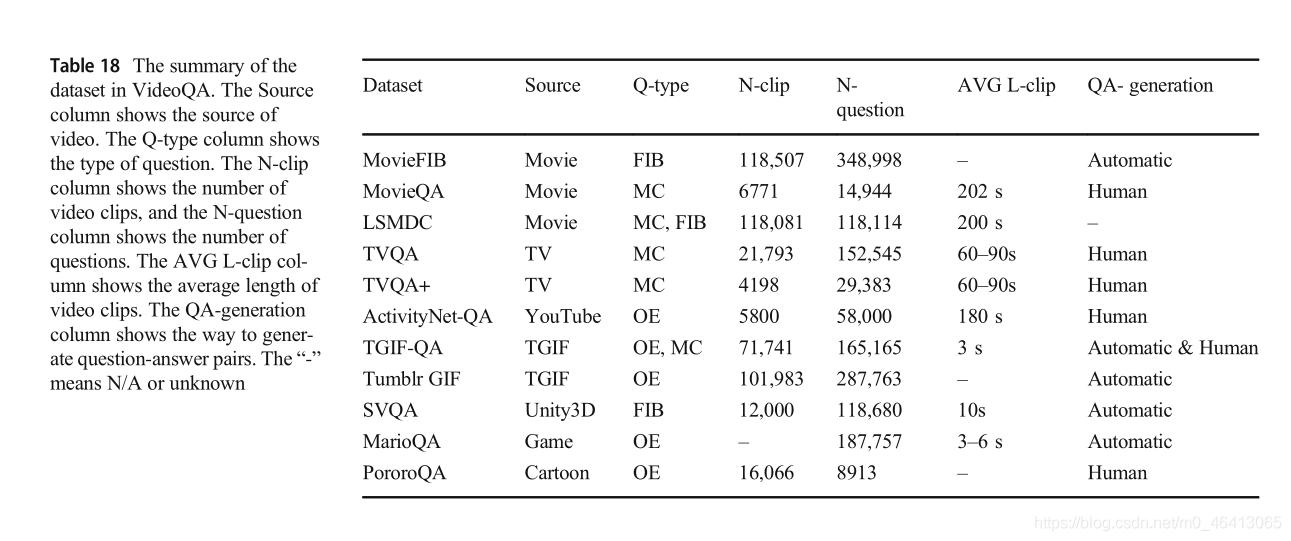
來自LSMDC 2016資料集的 MovieFIB[53] 是針對視障人士的基于描述性視頻標注修改的FIB資料集,該型別的問題是由自然語言工具包(NLTK)工具針對原始LSMDC 2016資料集提供的標注生成的,其中以名詞、動詞、形容詞和副詞詞性標注的詞作為空題的候選答案,問答資料集包含348998雙,其中有296960在訓練集,驗證集,21689和30349年在測驗集,由于問題生成基于注釋的原始LSMDC資料集,只有淺一些視頻資訊,資料集需要高級的語意推理,
MovieQA[19] 是應用最廣泛的資料集之一,旨在評估從視頻和問題中對長篇故事的理解,該資料集包含408部電影和14944個MC問題-答案對,每個問題-答案對由五個選項組成,只有一個正確答案,此外,每個問答對都是根據模板手工生成的,為了更好地理解視頻內容,該資料集還提供了與電影視頻、字幕、分布式交換機、腳本和情節梗概相關的五種故事源,基于這些來源的不同組合,該資料集涉及6個子任務:(i)視頻+字幕,(ii)僅字幕,(iii)僅分布式,(iv)僅腳本,(v)僅情節概要,和(vi)開放式的,在這些子任務中,第一個任務更值得注意,因為它是唯一一個需要理解視頻和文本的VQA任務,而其他任務都是純文本的,6462個問答對分別被分為4318、886和1258,分別用于訓練、驗證和測驗集,140個電影(共6771個剪輯)被分成4385個、1098個和1288個剪輯,分別用于訓練、驗證和測驗集,每個剪輯的長度非常長,平均長度為202秒,由于電影片段的長度,不斷變化的背景和故事情節,MovieQA更注重以抽象和高層次的資訊來理解故事,
LSMDC2016[104] 資料集來源于大規模電影描述挑戰,基于M-VAD和MPII-MD資料集的融合,提出了電影和字幕理解的三個任務:MC、視頻檢索和FIB,MC任務中的正確答案來自ground truth標題,其他五個候選答案是從其他標題中隨機抽取的,視頻檢索任務是根據給定的查詢活動短語從1000個測驗視頻中找到相應的視頻,FIB任務與上述描述相同,LSMDC資料集的訓練集、驗證集和組合測驗集中的視頻數量分別為91,908、6542和19,631,同時,組合測驗集由10053個公開測驗資料和9778個盲測驗資料組成,盲測驗集僅用于評價,與其他資料集相比,LSMDC具有更多的視頻片段,更關注電影本身,
4.2 TV types
TVQA[22]資料集是一個以電視節目為視頻源的大型資料集,同時,這則視頻來自三種型別的6部長期播放的電視劇:(1)情景喜劇:《生活大爆炸》,《老爸老媽浪漫史》,《老友記》,醫療類劇集:《實習醫生格蕾》、《豪斯醫生》;(3)犯罪劇:卡塞爾,共有925集,涵蓋461個小時,21793個視頻剪輯產生了152545對問題,多模態問答對由Amazon Mechanical Turk作業人員根據視頻和字幕,根據模板自然生成,問題模板首先使用開始時間戳和結束時間戳,根據“when / before / after”來定位與問題相關的視頻片段中的相關時刻,然后構成與視頻和問題理解相關的“what / how / where / why /”問題,這個問題是MC問題,平均長度為13.5個單詞,它明顯大于其他資料集,總共有461.2 h的視頻,視頻剪輯的長度平均為60 - 90秒,包含了大量關于人們活動和場景的自然資訊,它還具有豐富的動態和現實的社會互動,TVQA的一個關鍵特性是,每個視頻剪輯都有開始和結束的時間戳,以便根據問題準確定位視頻剪輯的關鍵部分,
TVQA+[37]資料集在TVQA的基礎上增加了接地邊界盒,具有更多的時空關系,該演算法從TVQA資料集《生活大爆炸》中選擇一個電視節目作為視頻源,并根據問題和正確答案逐幀添加邊框,邊界框是在Amazon Mechanical Turk平臺上手動添加的,資料集包含4198個視頻剪輯,29383個問答對,148468張影像,有310826個包圍框,平均每幅圖示注2.09條,每道題標注10.58條,標注種類2527種,它的獨特之處在于它的問答對不僅包含時間定位,而且包含空間定位,其中最重要的是空間定位,因為它對每個視頻幀中的目標區域進行了標注,VideoQA任務可以使用目標區域和屬性標簽特性進行訓練,這樣他們可以更準確地回答問題,
4.3 Open types
ActivityNet-qa[105]資料集來源于ActivityNet視頻資料集,基于人們的日常生活視頻,它從ActivityNet資料集的20000個視頻中采樣5800個視頻,考慮到班級的多樣性和視頻數量的平衡,它包括14,429個視頻剪輯,71,961個自然語言描述和130,161個問答對,主要有五種型別的問題:什么,誰,如何,在哪里,和其他,資料集的問答對是根據給定的問題模板使用現成的演算法手工生成的,問題涉及三種型別:運動型問題主要要求對粗時間動作的理解;空間關系問題主要基于靜態框架進行空間推理;時間關系問題驗證了從一系列幀中推理物件時間關系的能力,資料集限制問題和答案的長度,以確保質量,題目最多20個字,答案最多5個字,ActivityNet-QA資料集的視頻源于人們的日常生活,更加真實,因此對VideoQA有重要的影響,
4.4 TGIF types
TGIF-qa[106]資料集是一個公開的短格式TGIF資料集,它使用gif作為視頻源,該資料集基于TGIF資料集提出了四種型別的任務:重復計數、重復動作、狀態轉換和幀QA,重復計數任務是一個關于計算一個動作的重復次數的OE問題,其答案主要在2到10之間,重復動作任務定義為識別視頻中重復的動作的MC問題,狀態轉換任務是一個MC問題,是關于識別另一種狀態之前(或之后)的狀態,包括面部表情(如從悲傷到快樂)、動作(如從站立到坐)、位置(如從臥室到客廳)、物體屬性(如從空到滿),這三個任務都是由模板生成的,Frame QA task是一個OE問題,主要是基于視頻中的某一幀,比如ImageQA,該任務由原始TGIF資料集的描述資訊自動生成,問題的型別包括型別、數量、顏色和位置,TGIF-QA資料集基于71,741個gif生成了共165,165個問題回答對,與其他資料集相比,TGIF-QA資料集是唯一的,因為它包含了更多的動詞形式,理解視頻片段的內容需要豐富的時空推理,
Tumblr的GIF[38]資料集與TGIFQA具有相同的來源,但問答對生成的方式不同,該資料集包括101983個視頻剪輯(gif)和287,763個問答對,它分為三個部分:訓練、驗證和測驗集,訓練集包含79325個視頻中的230,689個問題-答案對,驗證和測驗集分別有來自10,038和12,620個視頻的24,696和32,378個問答對,QA對是自動生成的,問題的型別主要分為what、when、where、who、whose、how many六類,該資料集最重要的特征是在生成問答對時保證不偏倚,生成的答案的相似性非常低,此外,Tumblr GIF資料集包含單個事件,比MovieQA資料集簡單,因此不需要高級別的推理,
4.5 Geometry types
SVQA[57]資料集使用關于幾何變化的合成視頻作為視頻源,由Unity 3D生成,每個視頻剪輯有3 - 8個不同形狀、大小和顏色的靜態或動態幾何物件,其中動態幾何物件有額外的動作型別和動作方向屬性,基于這些屬性,它可以根據物件之間特定的時空關系、相對位置和動作順序來構造推理問題,構造的SVQA擁有12000個合成視頻,并自動生成約120k個帶有固定模板的問答對,為了保證生成的問題的質量,首先將少量的幾何屬性整合到所有候選描述中,其次,每個描述都會被檢查和更正,最后,利用均衡機制使答案分布具有一定的均勻性,設計原則是解決邏輯結構的組合問題,這需要多步的推理程序,雖然SVQA資料集的視頻內容與其他資料集相比還不夠充分,但回答這個問題需要對時空關系有更強的推斷,
MarioQA[65]資料集使用名為《無限馬里奧兄弟》(Infinite Mario Bros)的游戲視頻作為其視頻源,《無限馬里奧兄弟》是《超級馬里奧兄弟》的變體,它收集了13小時的超級馬里奧游戲,生成帶有事件日志的視頻片段,并根據手工構建的模板,從抽取的事件中自動生成187,757個問答對,每個視頻剪輯平均包含11.3個事件,問答組合是基于不同的事件生成的,包括E = {kill, die, jump, hit, break, appear, shoot, throw, kick, hold, eat},生成的問題仍然分為三種型別——以事件為中心的問題、計數問題和狀態問題,根據時間關系將MarioQA資料集構造為三個子集,沒有時間關系(NT):在整個視頻中有78297個NT的例子,它們更關心沒有任何時間關系短語的獨特事件,簡單時間關系(ET):有64,619個ET例子包含關于全球獨特事件的問題,以上兩種型別很容易回答,硬時間關系(HT):有44,841個HT的例子涉及干擾事件,使VQA系統根據時間推理從多個相同的事件中找到正確答案,為了保證問題的推理性和答案的清晰度,洗掉了一些需要額外資訊推理的問題,以保證資料集的質量,MarioQA資料集的特征是具有多個事件和時間依賴性的大量視頻,游戲視頻中事件的發生是清晰的,不會讓人感到曖昧,所以很容易在游戲視頻中學習完整的語意資訊,
**PororoQA[23]**視頻來源于廣受歡迎的兒童卡通系列視頻,該資料集包含20.5 h視頻的16066對場景-對話,27328個細粒度場景描述句子和8913個故事相關的問答對,描述句和問答對是在Amazon Mechanical Turk (AMT)平臺上手工收集的,在場景描述中,移動網路應用的平均句數和單詞數分別為1.7和13.6,它擁有大量的支持事實標簽,表明在每個視頻剪輯中鏈接框架和標題,以更正答案資訊和描述文本,由于PororoQA使用卡通視頻作為視頻素材,所以視頻內容簡單明了,故事結構連貫,與戲劇或電影相比,環境也很小,此外,由于高質量的場景描述,也涉及到高水平的視頻分析,
4.7 Evaluation criterion
根據題型不同,不同的題型對應不同的評價方法,有兩種流行的方法,精度(Acc)和Wu-Palmer相似度(waps),Acc是答對題數占答對題總數的比例,它是最廣泛的用于衡量分類任務的性能,公式如下:
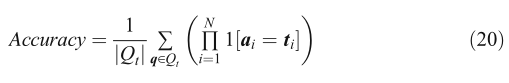
其中qt為問題的數量,N為答案的大小,其中ti代表ground truth答案,ai代表VideoQA模型預測的答案,1[·]是一個指示函式,只有當tiai完全相同時,樣本的精度為1,0 o the r w is e,但是對于OE問題,Acc不能直接用來評價兩個短語之間的相似度,waps用于評估OE問題,它衡量基于語意差異的預測答案與ground truth的差異程度,根據分類樹中兩個詞的最長公共子序列計算相似度,如果預測詞與ground truth答案詞的相似度低于閾值,則候選答案的得分為0,當閾值設定為0.0時,表示為WUPS@0.0,當閾值設定為0.9時,也可以表示為WUPS@0.9,公式如下:
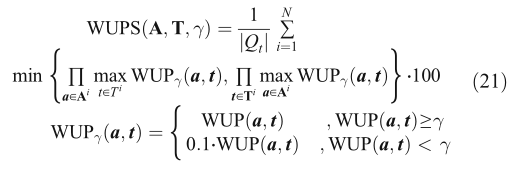
其中WUPγ(任意性)[107]通過WordNet[108]計算單詞相似度,其中N為題數,A= {a1,a2,…,aN}為模型預測的答案,T={t1,t2,…,tN}為ground truth答案,符號ak表示預測句的第k個單詞,tk表示地真句的第k個單詞,
5 Discussions
5.1 Experimental results and analysis
在MovieQA、TGIF-QA和SVQA三個基準資料集上進行了實驗,并對實驗結果進行了分析和描述,MovieQA是一個MC問題資料集,“Video + Subtitle”任務在驗證和測驗集上的實驗結果如表19所示,對實驗結果進行了精度排序,作為競爭基線網路,DEMN在驗證集(44.7%)和測驗集(29.97%)上取得了結果,RWMN明顯優于DEMN的29.97%,RWMN不僅在提高電影理解方面起著至關重要的作用,而且體現了RWMN在處理高級推理問題方面的優越性,LMN采用了更新機制和問題引導注意模型,使字幕記憶與問題更加相關,此外,LMN具有良好的可擴展性,MDAM通過后期融合避免了早期融合的過擬合現象,并利用自我注意模型提高了%5的準確率,A2A模型探索了理解電影的高水平、多模態注意模型,并采用了一種新的詞嵌入方法對詞匯外的詞進行跟蹤,與LMN模型相比,基于動態推理的PAMN模型得到了更準確、更可靠的答案,目前,AMN的測驗準確率達到了45.31%,表明基于GAN和一致性約束的多模態表示學習提高了有效性和泛化能力,我們在表20中顯示了在TGIFQA資料集上的結果比較,TGIF-QA包括以下四項任務,重復動作(action)和狀態轉換(Trans)是多項選擇題,重復計數(count)和框架問答(FrameQA)是開放式問題,實驗采用準確性評價重復動作、狀態轉換和框架QA問題,采用損失值評價重復計數任務,正如所預料的那樣,隨機機會法比其他方法表現最差,因為它是模仿一個人隨機猜答案,在重復計數和重復動作任務方面,論文[49]分別比其他方法獲得了最低的L2平均損耗和最高的準確率,在狀態轉換和幀質量保證任務中,CRN + MAC?移動網路應用的準確率分別為0.787和0.592,顯著優于其他方法,結果表明,多步推理有助于提高視頻質量評價的準確性,
我們總結了SVQA資料集的實驗結果,該資料集具有很強的時空關系推理能力,開放性問題的比較結果見表21,ST-VQA-Tp的性能不如其他演算法,因為它只使用單跳時間注意模型,大量的時間視覺線索丟失了,r-STAN被過度擬合所困擾,統一att的問題是傳統的GRU不能很好地捕捉長期的時間依賴性,此外,E-SA相對于E-VQA的改進證明了注意模型在視頻qa中起著至關重要的作用,SA + TA-GRU的空間注意機制優于E-VQA和Unified-Att,這表明TA-GRU能夠捕獲更完整、更長期的時間視覺線索,CRN + MAC實作了最先進的結果,從44.9%大幅提高到75.8%,由于SVQA資料集中的問題是為多步推理而設計的,因此具有雙處理系統的CRN + MAC在推理程序中是有效的,
5.2 Directions for future work and challenges
VideoQA的研究是推動計算機視覺和自然語言處理研究領域發展的一項重要而具有挑戰性的任務,然而,仍有大量的空間進行進一步的研究和性能改進,因此,本文從視頻qa發展的角度,總結了視頻qa領域尚未解決的問題,并指出了未來作業的方向,
- 實作多模態間的互動 ,VideoQA任務是一個跨模態任務,它支持在不同模式之間進行解釋、對齊和融合,但在以往的研究中,大多只使用視頻和問題來回答問題,很少考慮音頻,因此,利用音頻、視頻和問題的多模態互動,有助于學習魯棒的多模態表示,
- 細粒度和粗粒度特征的分析,為了捕獲視頻的區域屬性(例如,行人的布料型別),細粒度特征在理解視頻內容方面比粗粒度特征表現得更好,相比之下,粗粒度的特征更擅長捕捉視頻的全域屬性(例如,環境),此外,細粒度和粗粒度的特征都需要解決視頻QA任務與合理的融合,
- 轉移學習,由于VideoQA太復雜,無法在有限的資料集中描述,所以學習一個VideoQA資料集中的通用模式非常重要,這些模式可以很好地用于另一個VideoQA資料集,如何將遷移學習應用到VideoQA中是訓練魯棒模型的關鍵問題,
- 建立標準基準資料集,盡管許多論文報告了相對較好的結果,但很難做到比較不同的模型,因為它們在資料資源和問答對生成方面存在差異,因此,可以對標準基準資料集進行進一步的研究,以促進VideoQA的發展,
- VideoQA模型的可視可解釋性,由于缺乏可解釋性,VideoQA模型的結果一直不被信任,因此,利用可視化工具來檢查VideoQA模型的內部作業就顯得尤為重要,
- 用幾個訓練示例訓練一個模型,對于VideoQA來說,一個常見的挑戰是用很少的訓練例子來訓練一個表現良好的深度學習模型,在今后的作業中,建議采用元學習和少鏡頭學習來解決這一問題,
- 優化的培訓,常用的基于最大似然估計訓練的視頻qa網路使網路處于次優狀態,為了提高訓練效率,在今后的作業中可以考慮強化學習框架的研究,
6 Conclusion
VideoQA在計算機視覺和自然語言處理中扮演著重要的角色,它可以根據視頻內容自動回答自然語言問題,視頻質量檢測中運用了許多人工智能技術,如目標檢測與分割、特征提取、內容理解、分類等,VideoQA的研究界在很大程度上促進了人工智能的發展,在這項調查中,對VideoQA進行了系統和全面的回顧,我們提出了一個理解VideoQA的總體框架,并回顧了構建視頻和問題之間的互動表示以回答問題的最流行的方法,我們描述了core processing model中同型別方法的其他改進,并強調了它們在思想和應用上的差異,此外,我們回顧了基準資料集和評價標準,并分析了在這些資料集上的實驗結果,未來的研究作業將需要視頻qa,遷移學習、元學習和視覺工具等有希望的發展方向有望提高視頻qa的性能, 我們相信,未來在這些問題上的作業將有助于VideoQA的更多改進,




轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260356.html
標籤:AI
上一篇:K-Means聚類演算法(一)
下一篇:緒論-演算法【資料結構與演算法】