1.概述:
K-means聚類演算法也稱k均值聚類演算法,是聚類演算法的典型代表,可以說是最簡單的聚類演算法沒有之一,它采用距離作為相似性的評價指標,即認為兩個物件的距離越近,其相似度就越大,該演算法認為類簇是由距離靠近的物件組成的,因此把得到緊湊且獨立的簇作為最終目標,
2.演算法思想:
K-means聚類演算法是一種迭代求解的聚類分析演算法,其步驟是隨機選取K個物件作為初始的聚類中心,然后計算每個物件與各個種子聚類中心之間的距離,把每個物件分配給距離它最近的聚類中心,聚類中心以及分配給它們的物件就代表一個聚類,每分配一個樣本,聚類的聚類中心會根據聚類中現有的物件被重新計算,這個程序將不斷重復直到滿足某個終止條件,終止條件可以是:1)沒有(或最小數目)物件被重新分配給不同的聚類;2)沒有(或最小數目)聚類中心再發生變化;3)誤差平方和區域最小,
3.演算法執行程序:
順序 | 程序 |
| 1 | 隨機抽取K個樣本作為最初的質心 |
| 2 | 開始回圈 |
| 2.1 | 將每個樣本點分配到離他們最近的質心,生成K個簇 |
| 2.2 | 對于每個簇,計算所有被分到該簇的樣本點的平均值作為新的質心 |
| 3 | 當質心的位置不在變化,迭代停止,聚類完成 |
4.模型評估指標:輪廓系數
輪廓系數是最常用的聚類演算法的評價指標,它是對每個樣本來定義的,它能夠同時衡量:
1)樣本與其自身所在的簇中的其他樣本的相似度a,等于樣本與同一簇中所有其它點之間的平均距離,
2)樣本與其它簇中的樣本的相似度b,等于樣本與下一個最近的簇中的所有點之間的平均距離,
根據聚類的要求"簇內差異小,簇外差異大",我們希望b永遠大于a,并且大得越多越好,
單個樣本的輪廓系數計算公式為:
公式可以被決議為:
很容易理解輪廓系數范圍是(-1,1)其中值越接近1表示樣本與自己所在的簇中的樣本很相似,并且與其它簇中的樣本不相似,當樣本與簇外樣本更相似的時候,輪廓系數就為負,如果一個簇中的大多數樣本具有比較高的輪廓系數,則簇會有比較高的總輪廓系數,則整個資料集的平均輪廓系數也高,聚類是合適的,
sklearn中,使用metrics中的類silhouette_score來計算輪廓系數,它回傳所有樣本輪廓系數的均值,silhouette_sample,它回傳資料集中每個樣本自己的輪廓系數,
還有一些其它指標,例如卡林斯基—哈拉巴斯指數,計算起來很快,這里就不詳細介紹了,,,,,,
案例:基于輪廓系數選擇最佳n_clusters
#導包
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples,silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm #colormap
import numpy as np
import pandas as pd
from sklearn.datasets import make_blobs
#自己創建資料集
X,y=make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
fig,ax1=plt.subplots(1)
ax1.scatter(X[:,0],X[:,1]
,marker='o'#點的形狀
,s=8)#點的大小
plt.show()
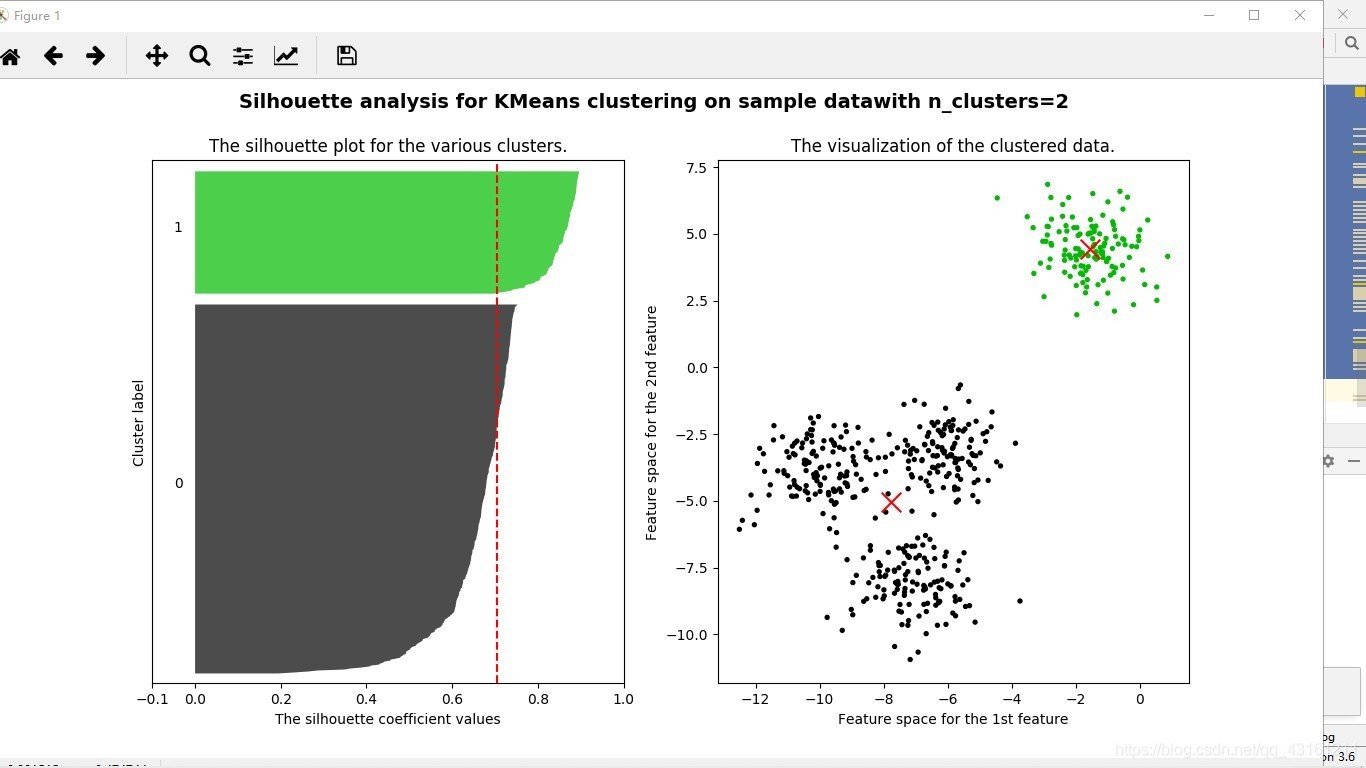
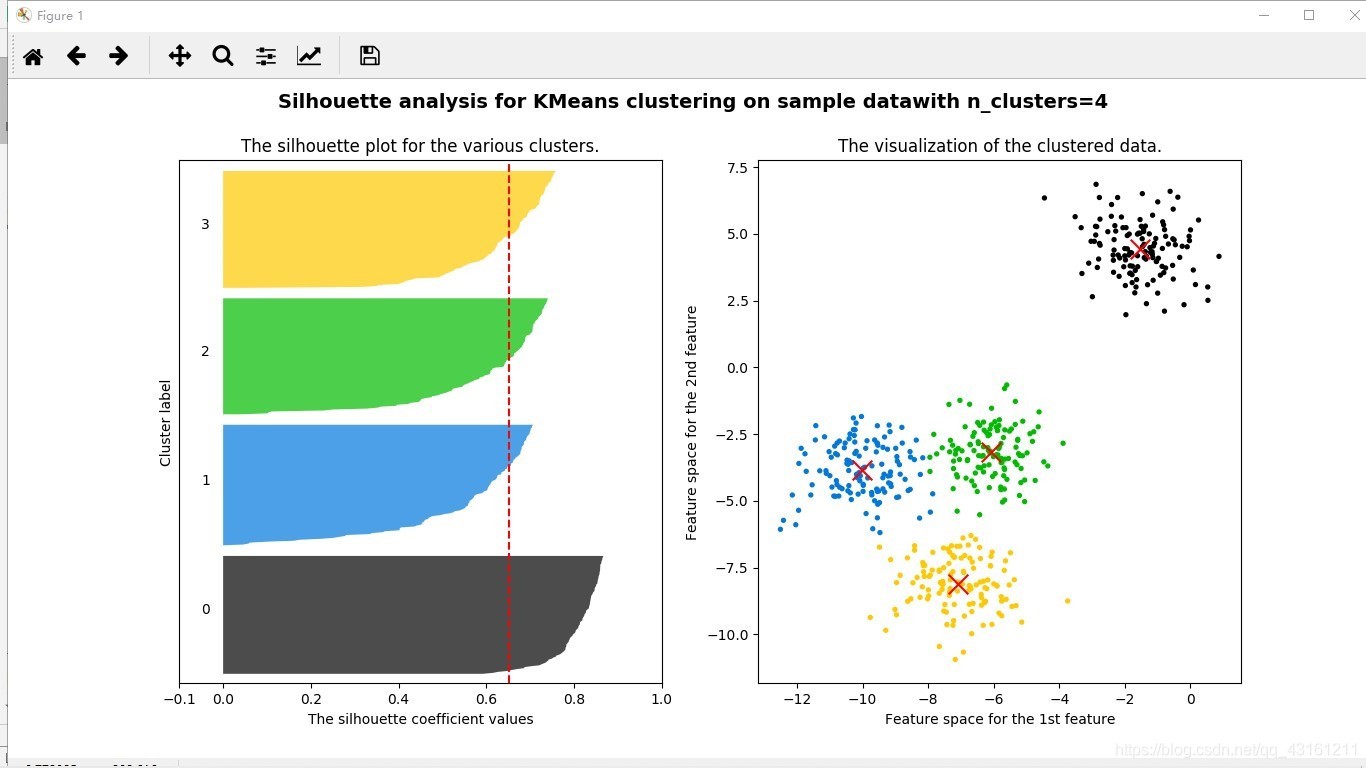
for n_clusters in [2,3,4,5,6,7]:
n_clusters=n_clusters
fig,(ax1,ax2)=plt.subplots(1,2)#一個畫布,兩個子圖
fig.set_size_inches(18,7)
ax1.set_xlim([-0.1,1])#設定x軸取值
ax1.set_ylim([0,X.shape[0]+(n_clusters+1)*10])#設定y軸取值
#開始建模
cluster=KMeans(n_clusters=n_clusters,random_state=0).fit(X)
cluster_labels=cluster.labels_
silhouette_avg=silhouette_score(X,cluster_labels)#所有樣本輪廓系數的均值
print('For n_clusters=',n_clusters,'The average silhouette_score is:',silhouette_avg)
sample_silhouette_values=silhouette_samples(X,cluster_labels)
y_lower=10#設定y軸初始取值
#對每一個簇進行回圈
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]#每一個樣本的輪廓系數
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]#這一個簇中樣本個數
y_upper = y_lower + size_cluster_i#簇的y軸上限
color = cm.nipy_spectral(float(i) / n_clusters)#每次回圈生成不同顏色
ax1.fill_betweenx(np.arange(y_lower, y_upper)
, ith_cluster_silhouette_values
, facecolor=color
, alpha=0.7
)
ax1.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))#給每一簇輪廓系數顯示編號
y_lower = y_upper + 10#不同簇添加空隙
ax1.set_title('The silhouette plot for the various clusters.')
ax1.set_xlabel('The silhouette coefficient values')
ax1.set_ylabel('Cluster label')
ax1.axvline(x=silhouette_avg,color='red',linestyle='--')#畫輪廓系數均值線
ax1.set_yticks([])
ax1.set_xticks([-0.1,0,0.2,0.4,0.6,0.8,1])
colors=cm.nipy_spectral(cluster_labels.astype(float)/n_clusters)
ax2.scatter(X[:,0],X[:,1]
,marker='o'
,s=8
,c=colors)
centers=cluster.cluster_centers_
ax2.scatter(centers[:,0],centers[:,1],marker='x',c='red',alpha=1,s=200)
ax2.set_title('The visualization of the clustered data.')
ax2.set_xlabel('Feature space for the 1st feature')
ax2.set_ylabel('Feature space for the 2nd feature')
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data"
"with n_clusters=%d" % n_clusters),
fontsize=14,fontweight='bold')#為整個圖設定標題
plt.show()
運行:這里只放了n_clusters=2,4的,到底選哪簇,具體選擇就得看你的業務需求了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/260355.html
標籤:AI
下一篇:【VideoQA最新論文閱讀】第一篇視頻問答綜述Video Question Answering: a Survey of Models and Datasets