進入干貨之前,先簡單自我介紹一下吧,筆者主要從事深度學習CV領域,近一年,由于作業需要,再加上個人興趣,在目標檢測、實體分割任務方面,花了不少時間調研和閱讀論文,
對此,筆者也跑過了無數實驗,參加過大大小小的比賽,emmm,有最侄訓得第一的,有遺憾獲得第二的,有初賽就被淘汰無緣復賽的,也有做到一半由于各種原因放棄的,有機會以后可以和大家嘮一嘮...
言歸正傳,今天想和大家分享的獨家干貨是,MMDetectionV2 + ResNeSt + RTX3090的訓練實錄,CVer會比較熟悉,這三款分別來自框架、演算法、硬體領域的產品,都是2020年新推出的爆款,目前還沒有看過三者結合的公開實驗分享,
正好,筆者最近注冊了 gpushare.com 免費租用了一臺雙卡24G的GeForce RTX 3090設備,就順便升級了一下MMDetection至V2.7.0(2020年11月底發布,之前由于其更新速度太快,下半年一直停留在V2.2.0版本),并發現此次更新,增加了對ResNeSt作為backbone的支持,立刻決定跑個實驗測驗一下性能,希望能給大家一些參考,
接下來,分別簡單介紹一下:
-MMDetection
這是港中大OpenMMLab及商湯科技開源的基于PyTorch的檢測分割框架,該團隊在參加2018 MS COCO Detection Challenge后開源,于2018年10月首次發布V0.5.1版本,2020年1月發布V1.0.0版本,2020年6月推出全新升級的V2.0.0版本,
相比于其他類似的開源框架,例如Facebook的maskrcnn-benchmark及Detectron2或百度的PaddleDetection,MMDetection是目前最受歡迎、關注度最高的框架,主要原因在于,其功能全覆寫面廣、性能高、以及更新速度快等特點,
-ResNeSt
號稱最強ResNet改進版,“ResNeSt: Split-Attention Networks”這篇論文出自亞馬遜李沐,張航團隊,于2020年4月上傳至arXiv(截止目前還未在會議或期刊上發表,不出意外,2021年的CVPR或ICCV等頂會應該會有它的身影),
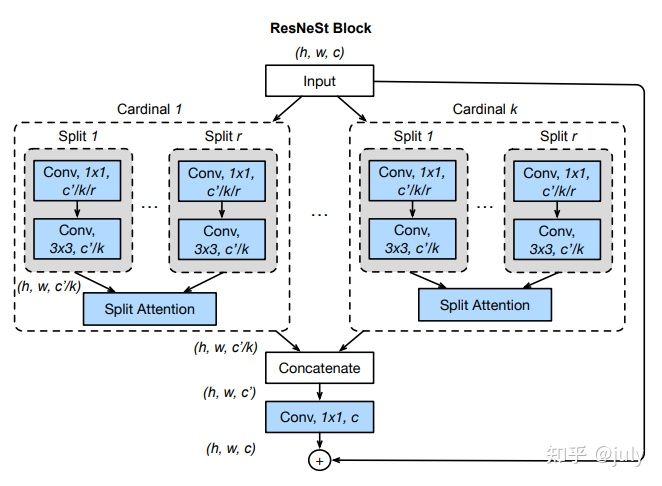
此文一出反響熱烈,一方面,由于其在影像分類、目標檢測、實體分割、語意分割等多項任務中都有顯著提升,
另一方面,一些質疑聲也隨之而來,主要來源于其對比實驗,例如ResNeSt-50 vs. ResNet-50,采用了大量最新發表的訓練及資料增強策略,而在ResNet-50于2015年提出時,這些技術并不存在,因此其公平性受到挑戰,
無論如何,ResNeSt在最近各大比賽中頻繁登場并大放光彩,可見其泛化能力極強,
-RTX 3090
英偉達GeForce RTX 30系列,于2020年9月正式發布,其中的3090版本對比上一任“老大哥”GeForce RTX 2080 Ti,不論是性能還是價格都完全碾壓,
再加上疫情原因,以至于推出后很長時間,在國內市場都處于缺貨、搶購、價格抬高等現象,即便在美國也是一卡難求,這無疑讓深度學習愛好者對其充滿向往,
介紹完背景后,現在進入正題,本次實驗的相關配置如下:
- Python 3.8.7
- PyTorch 1.7.1
- torchvision 0.8.2
- CUDA 11.0
- cuDNN 8.0.5
- GCC 7.3
- MMDetection 2.7.0
- MMCV 1.2.4
資料方面,采用了經典的MS COCO 2017,其中訓練集train、驗證集val以及測驗集test-dev的數量分別約為118K、5K、20K,
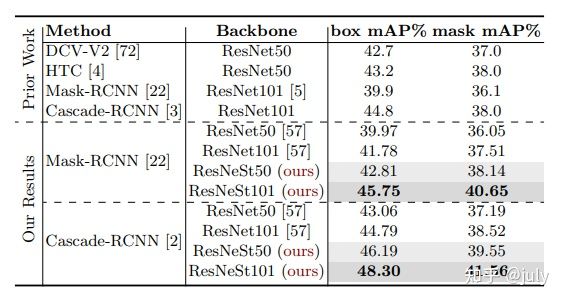
演算法方面,本次實驗選擇了ResNeSt-101 + FPN + SyncBN + Cascade Mask RCN作為檢測器,這里并沒有使用最新的HTC或DetectoRS,主要是想和ResNeSt論文中給出的實驗結果做直接對比,
訓練及測驗細節如下:
- 訓練時長采用“2x schedule”,即24周期,step=[16,22]
- 多尺度訓練1600x[400,1200],這里參考了HTC論文里的尺度,而非ResNeSt論文中的1333x[640,800]
- 單尺度測驗1600x1000,同上,未選擇傳統的1333x800
- 雙卡訓練,每卡2張圖片,即batch size為4
- 初始學習率設定為0.01,這里稍高于傳統目標檢測linear scaling rule定義的0.005
- 根據ResNeSt論文推薦,backbone及head都采用SyncBN
- 其余設定及超引數不變
訓練一個周期大約11.5小時,訓練時顯存幾乎占滿,如下圖所示,由于是雙卡跑“2x schedule”,如果按照一般論文中的8卡跑“1x schedule”配置來算的話,整個訓練程序大約需要34.5小時,算是比較快的,這里順便提一下,經親測,同樣的配置8卡2080 Ti跑“1x schedule”一般需要2天多一些(49至50小時),
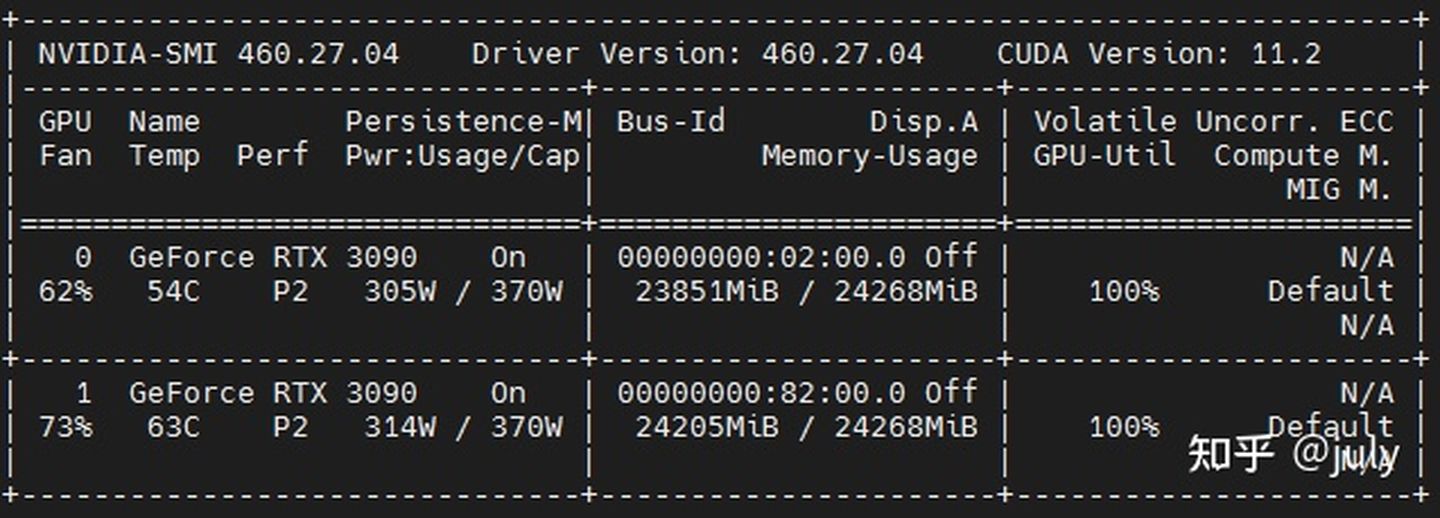
受資源限制,多尺度訓練并未采用HTC的1600x[400,1400],同樣的,backbone并沒加入最近比較流行的DCNv2,加入后mAP一般可以提升1至2個百分點左右,如下圖所示(來自于ResNeSt原文中的Table 12),

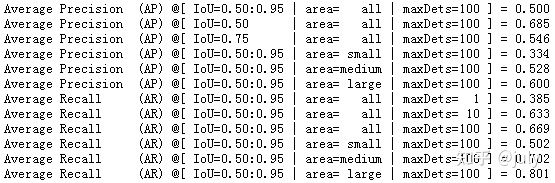
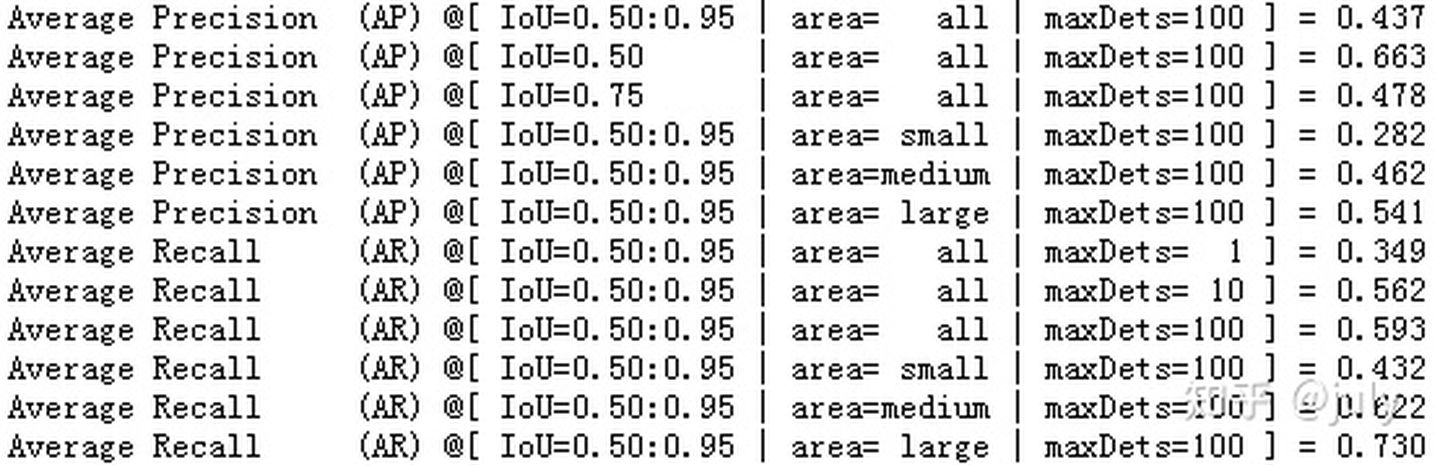
根據以往經驗,多尺度測驗一般mAP可提升1.5至2.5個百分點左右,由于本次實驗并非為了比賽或刷榜,為節省時間測驗階段采用單尺度,結果如下:
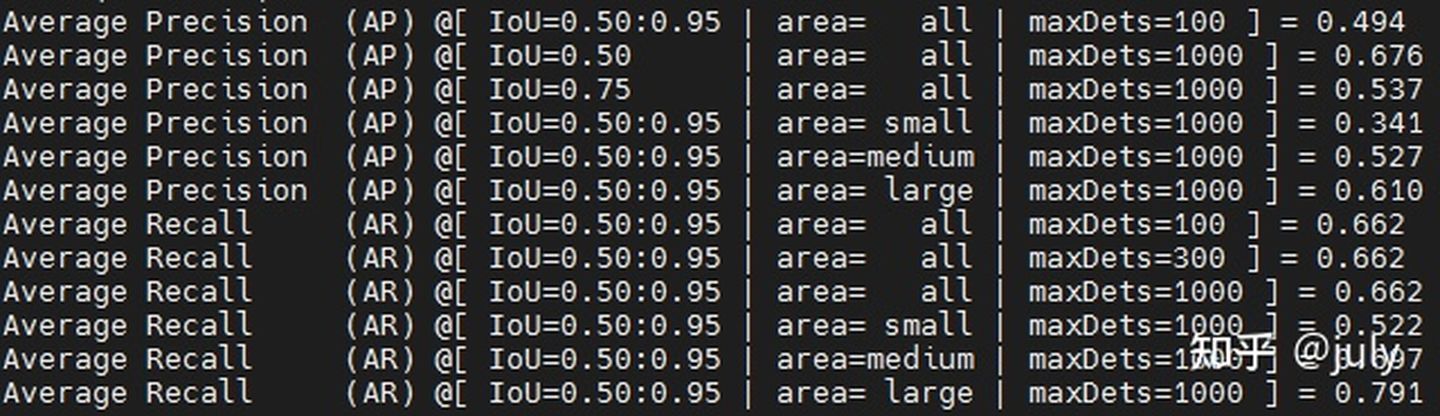
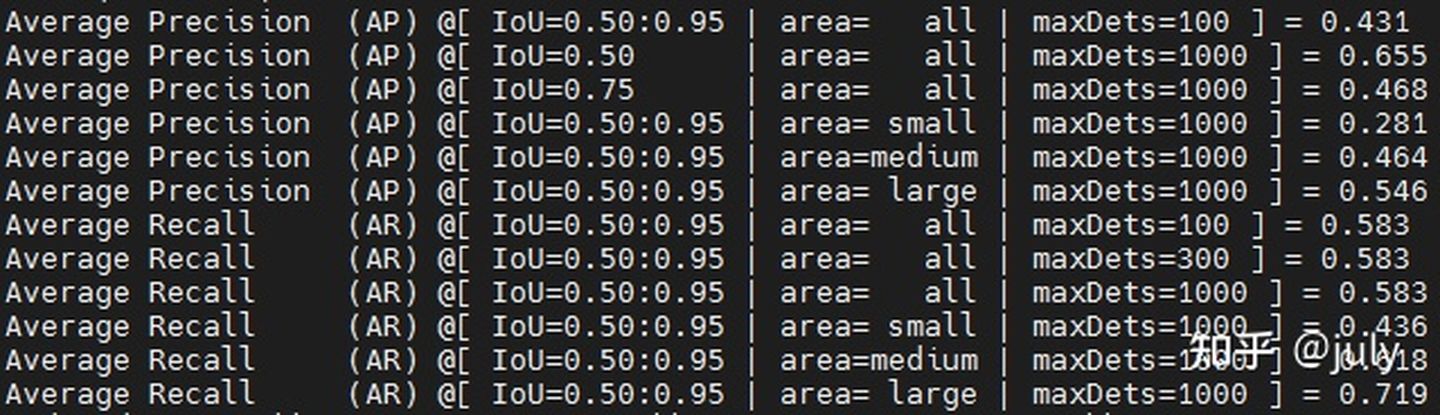
上面兩張圖,分別為模型在驗證集上的檢測bbox mAP以及分割segm mAP結果,對比下圖中的結果(來自于ResNeSt原文中的Table 6),本次實驗效果稍微好一些(bbox 49.4% vs. 48.3%,segm 43.1% vs. 41.6%),可能得益于較大的尺度及較長的訓練時長,但不論如何,雙卡的RTX 3090可以復現作者的8卡結果還是令人比較滿意的,
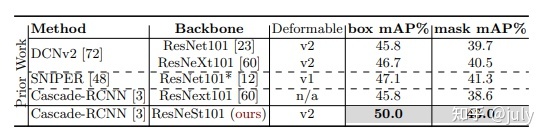
下面三張圖分別為測驗集test-dev上的bbox mAP、segm mAP(需要將json檔案上傳至COCO的官方網站)以及原文中的Table 10,需要注意的是原文中的結果使用了DCNv2, 而本次實驗并未對backbone欄位外的增強操作,也達到了一樣的效果(bbox 50.0% vs. 50.0%,segm 43.7% vs. 43.0%),
綜上,通過測驗“新一代卡皇”GeForce RTX 3090的性能,最終結果還是比較令人滿意的,gpushare.com??????? 平臺的穩定性也有加分,整體的訓練體驗也比較友好,現在新人注冊有百元代金券,可以直接下單白嫖,沒有使用門檻,需要的鵝們可以蹭一蹭~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261321.html
標籤:AI