今天整好是大年三十,這里先給各位讀者拜個早年,我發現之前的疑難雜癥系列較為受到歡迎,因此就總結一下近些年作業中遇到的一些精典案例,總結一下并去掉涉及敏感資訊分享給大家,同時我也突然發現這次生產+災備這對歡喜冤家的話題,好像和情人節還有點關系,因此也就順便參加情人節征文了,這里祝各位讀者牛年行大運,牛氣沖天,情場職場雙豐收,
兩地三中心-幸福的一家三口
在開展下的介紹之前這里我們先來介紹一下災備體系的主要技術指標:
RTO(Recovery Time Objective):RTO是指災難發生后,從IT系統崩潰導致業務停頓開始,到IT系統完全恢復,業務恢復運營為止的這段時間長度,RTO用于衡量業務從停頓到恢復的所需時間,
RPO(Recovery Point Objective):IT系統崩潰后,可以恢復到某個歷史時間點,從歷史時間點到災難發生的時間點的這段時間長度就稱為RPO,RPO用于衡量業務恢復所允許丟失的資料量,
簡單來講RTO就是災難發生后業務中斷的時間,RPO就是災難發生后資料丟失的數量,比如這次微盟的刪庫事件業務歷時8天完全恢復,而資料全部找回,那么其RTO就是8天,RPO就是0,
一般來說目前比較流行的災備體系是至少建設三個資料中心,而這三中心的關系有點像一家三口的關系,具體說明如下:
主中心:正常情況下全面提供業務服務
同城中心:一般使用同步復制的方式來向同城災備中心傳輸資料,保證同城中心資料復本為最新,隨時可以接管業務,以保證RTO的指標,但是同城中心無法應對此類刪庫事件,
異地中心:一般使用延時異步復制(延時時間一般為30分鐘左右)的方式向異地災備中心傳輸資料,其中同步復制的好處是一旦主中心被人工破壞,那么不會立刻涉及異地中心,以保證RPO的指標,
總結災備體系的最佳實踐就是兩地三中心,其中生產與同城中心像一對夫妻共同保證業務連續性,優先負責用戶體驗;異地中心則像是個寶寶,保證資料連續性,確保在爸媽都出問題的情況下,家庭還有延續的火種,
心連心vs 心貼心,這是個問題
之前DNS域名尋址技術沒有推廣應用的時候,很多企業的災備中心與生產中心全部是使用二層打通的技術來搭建的,也就是說災備中心與生產中心使用相同的網段,網關在正常情況下活在生產中心,由于這種二層延伸的方案主備中心實際分享同一網路核心,因此也常被稱為心連心方案,如下圖所示,
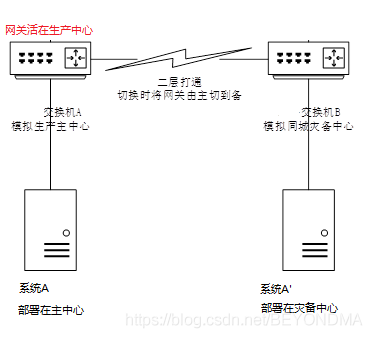
注:圖示中的系統A與其災備節點A’處于同一網段,
對于這種二層延伸的網路結構,在進行單個系統切換時只需要把系統A的服務IP遷移到災備A’即可,也就是將A’的IP地址改為A實際上就完成了切換,這樣基于IP地址的實備切換方案與主備雙機切換幾乎完全一樣,非常的簡單易行,因此在前些年容器等云原生技術未推廣的時候廣為流行,但是這樣的方案也有一個問題就是進行災備中心級切換時需要將網路的活動網關由主中心切換至備中心,此動作會造成網關切換涉及的網路區域服務全部中斷,
與二層延伸的方案相對應,三層連接就是心貼心的方案了,在三層連接的災備體系中主備中心分別使用不同的網段,無論是單系統還是中心級的切換,都是改為DNS的域名決議指向,由于三層連接主備中心不再共享網路核心因此得名心貼心,
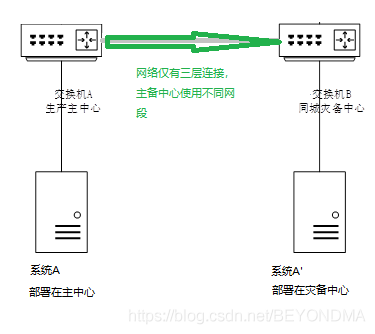
注:圖示中的系統A與其災備節點A’處于不同網段,切換時由DNS改變域名決議指向,
心連心的整體切換方案
考慮到二層延伸方案中中心級整體切換時網關遷移影響較大,而且單系統切換時IP地址飄移也需要較長的時間,這會造成災備中的RTO指標難以保證,并且因此二層延伸的方案逐漸被網路三層連接的方案所取代,
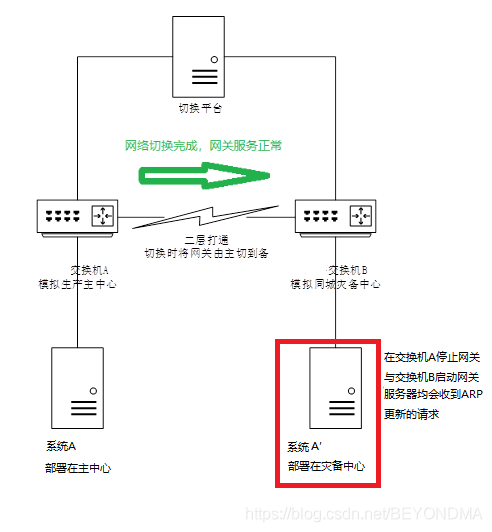
雖然二層延伸方案已經是明榷訓花,但是由于存量依舊眾多,因此在前一段時間我專門針對這種二層延伸的方案的中心級整體切換,模擬生產中心發生災難而整體中斷的情況進行了測驗,想看看心連心方案是否還有其它的坑,結果真有驚喜,方案示意圖如下:
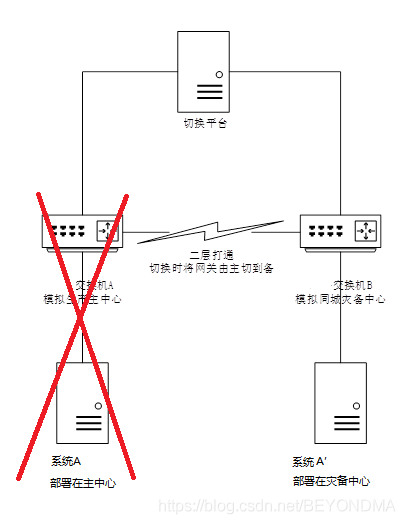
一般來講,中心級整體的災備切換,目前各行業都研發一個切換平臺,統一調度網路設備及系統的切換,當然無此平臺也沒所謂,因此切換平臺只是為了提升切換時間也就是RTO指標的,具體切換動作由手工執行也是一樣,切換主要分為以下三個階段:
系統A主中心服務停止,(主要包括應用服務、節點A卸載服務IP等動作)
網路同城切換(主要包括網關服務主中心停止,備中心啟動)
系統A災備中心服務啟動(主要包括節點A’掛載服務IP,啟動應用服務等動作)
心連心方案中網路中斷的問題
這樣的測驗程序大多數情況下都能成功,但是在切換步驟2網路同城切換后,服務器設備有小概率出現長時間網路中斷的問題,
以我的驗證環境為例(具體硬體型號不便公開),切換40次約出現一次概率約為2.5%,出現系統A’長時間(5分鐘左右)不能聯網的問題,
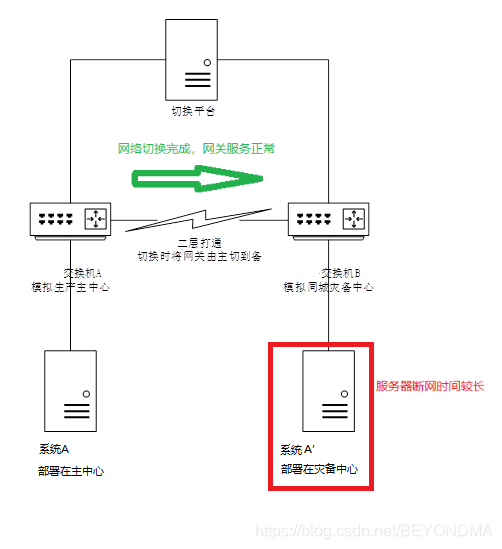
不過與之形成對比的是在正常情況下,網關切換后,服務器可在10秒之內恢復聯網,那么到底是什么引起服務器A’長時間網路不能恢復呢?
斷網原因分析
初步分析的此問題應該是由于網路切換造成網關MAC改變,服務器ARP表的更新超時導致的,因此在A’端進行了抓包檢查,發現在交換機A停止網關與交換機B啟動網關時,服務器A’均會收到ARP更新的報求,
翻閱Linux原始碼發現在arp_process函式中,使用了大量原子操作及作業系統同步原語,以保證arp表的更新不出現沖突,但原子鎖操作的另一結果是在arp表更新的程序,其它arp表更新請求將可能被丟棄,具體關鍵源代碼解讀如下:
static void arp_process(unsigned long arg)
{
...
if (time_after(now, tbl->last_rand + 300 * HZ)) { //內核每5分鐘重新進行一次配置
}
if (atomic_read(&n->refcnt) == 1 &&...){ //使用的原子讀操作
(state == NUD_FAILED || time_after(now, n->used + n->parms->gc_staletime))) {
*np = n->next;
n->dead = 1;
write_unlock(&n->lock);
neigh_release(n);
continue;
}
....
}
斷網問題解決方案
在確定了問題成因是由于兩次arp更新請求時間間隔較近,第一次網關A發布的ARP更新請求其所包含的資訊不是最新的;而第二次由網關B發出ARP更新請求又恰逢上一次請求沒有完成因此被丟棄,那么ARP表就需要等到超時時間(5分鐘)以后才會更新,針對此問題我們確定了兩種解決方案
解決方案一:由于跨廣播域發起的ping操作本身就可以對于本機的arp表進行更新,這樣就可以使arp表不會在5分鐘超時之后才能夠更新,因此我們在服務器A與服務器B上均開啟了長arpping的動作,
解決方案二:加大交換機A停止網關與交換機B啟動網關之間的時間間隔,即使服務器在收到交換機B啟動網關的ARP更新請增長時,已經將之前ARP更新請求處理完成,應該也可以解決此問題,此方案尚待驗證,
生產到災備的切換的程序,是不是像極了小兩口在過日的時候發生的磕磕絆絆呢,希望這個破案的程序可以對各位讀者有一定的啟發與幫助,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261322.html
標籤:AI