本文原創首發于極市平臺公眾號,如需轉載請私信作者
2020年,在深度學習目標檢測領域誕生了yolov4,yolov5和nanodet這些優秀的檢測模型,有許多的微信公眾號報道這些演算法模型,深度學習目標檢測方法可劃分為 Anchor-base 和 Anchor-free 兩大類,nanodet是一個速度超快和輕量級的移動端 Anchor-free 目標檢測模型,并且它的精度不亞于yolo系列的,
nanodet通過一些論文里的trick組合起來得到了一個兼顧精度、速度和體積的檢測模型,作者用到的一些trick,主要參考自:
- 參考FCOS 式的單階段 anchor-free 目標檢測模型,FCOS特點是讓模型學習feature map中每個位置到檢測框的四條邊的距離,如下圖所示,

- 使用 ATSS 進行目標采樣,該方法提出了自適應訓練樣本選擇方法,該方法根據目標的統計特征(方差和均值)自動劃分正訓練樣本和負訓練樣本,彌合了基于錨的探測器與無錨探測器之間的差距,
- 使用 Generalized Focal Loss 損失函式執行分類和邊框回歸(box regression),該函式能夠去掉 FCOS 的 Centerness 分支,省去這一分支上的大量卷積,從而減少檢測頭的計算開銷,
為了達到輕量化的目的,作者在設計網路結構時,使用 ShuffleNetV2 1.0x 作為骨干網路,他去掉了該網路的最后一層卷積,并且抽取 8、16、32 倍下采樣的特征輸入到 PAN 中做多尺度的特征融合,
在FPN模塊里,去掉所有卷積,只保留從骨干網路特征提取后的 1x1 卷積來進行特征通道維度的對齊,上采樣和下采樣均使用插值來完成,與 YOLO 使用的 concat操作不同,專案作者選擇將多尺度的 Feature Map 直接相加,使整個特征融合模塊的計算量變得非常小,
在檢測頭模塊里,使用了共享權重的檢測頭,即對 FPN 出來的多尺度 Feature Map 使用同一組卷積預測檢測框,然后每一層使用一個可學習的 Scale 值作為系數,對預測出來的框進行縮放,與此同時,使用了 Group Normalization(GN)作為歸一化方式.FCOS 的檢測頭使用了 4 個 256 通道的卷積作為一個分支,也就是說在邊框回歸和分類兩個分支上一共有 8 個 c=256 的卷積,計算量非常大,為了將其輕量化,專案作者首先選擇用深度可分離卷積替換普通卷積,并且將卷積堆疊的數量從 4 個減少為 2 組,在通道數上,將 256 維壓縮至 96 維,之所以選擇 96,是因為需要將通道數保持為 8 或 16 的倍數,能夠享受到大部分推理框架的并行加速,
最后,專案作者借鑒了 YOLO 系列的做法,將邊框回歸和分類使用同一組卷積進行計算,然后 split 成兩份,最后,專案作者借鑒了 YOLO 系列的做法,將邊框回歸和分類使用同一組卷積進行計算,然后 split 成兩份,這樣就組成了nanodet網路,
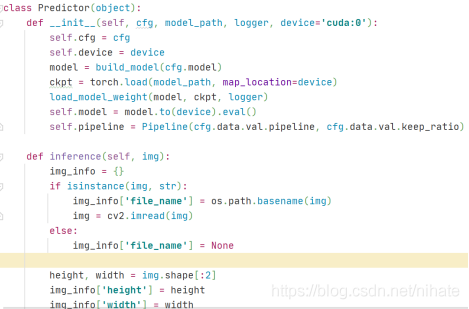
作者把nanodet發布在github上,專案地址: https://github.com/RangiLyu/nanodet,下載代碼和模型檔案到本地,按照README檔案運行一個前向推理程式,接下來,我閱讀前向推理主程式demo.py檔案,嘗試理解在運行這個主程式時需要呼叫哪些函式和.py檔案,在前向推理主程式demo.py檔案,對一幅圖片做目標檢測是在Predictor類的成員函式inference里實作的,它里面包含了對輸入圖片做預處理preprocess,前向計算forward和后處理postprocess這三個步驟,Predictor類的定義如下圖所示
對輸入原圖做預處理,預處理模塊是使用Pipeline類實作,對應的代碼是
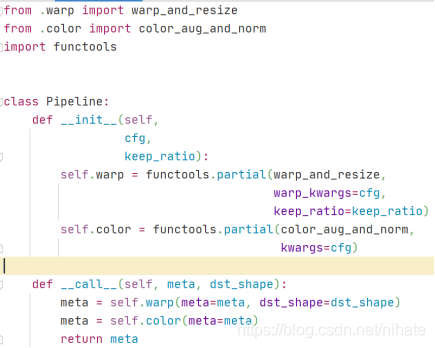
看到這段代碼時,我有些懵逼了,第一次見到functools.partial這個模塊,我百度查了一下它的作用是包裝函式,接著看warp_resize函式,這個函式對應的代碼很復雜,里面有多個if條件判斷,呼叫了多個自定義函式,限于篇幅,在這里展示部分截圖代碼,如下圖所示
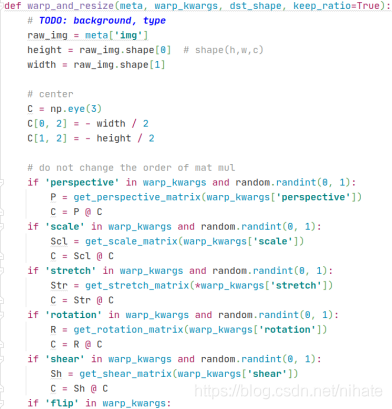
從代碼不難猜測出warp_resize函式的作用是對原圖做resize,于是我把warp_resize函式回傳的影像做可視化并列印出影像的尺寸是高寬:320x320,可視化結果如下圖所示,
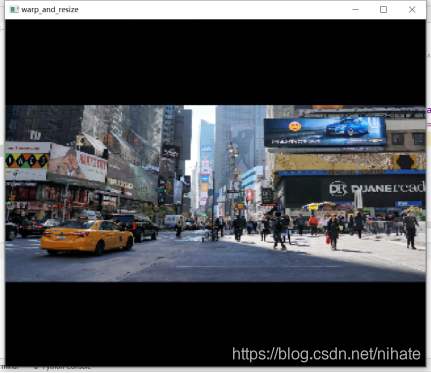
從圖中可以看到,warp_resize函式是保持原圖高寬比的resize,短邊剩下的部分用黑色像素填充,這種功能在ultralytics的yolov3和yolov5代碼倉庫里有一個letterbox函式實作的,在letterbox函式使用opencv庫里的resize和copyMakeBorder就可以實作保持高寬比的resize,這種方法簡潔明了,接著我對warp_resize函式和letterbox函式對同一幅圖片做保持原圖高寬比的resize的結果比較,可視化結果如下,從視覺上看不出它們有何差異,把這兩幅圖的像素矩陣做減法比較,發現它們并不等于0,也是是說它們的像素值還是有差異的,
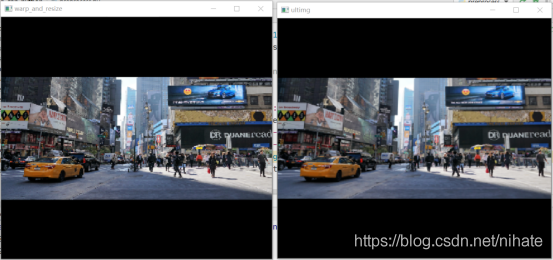
接著看預處理模塊Pipeline類里的第二個函式color_aug_and_norm,代碼截圖如下,可以看出,這個函式的作用是對輸入圖片的RGB三通道分別做減均值除以標準差的操作,不過在最開始對img除以255,在最后對均值和標準差分別除以255,這三次除以255是完全沒必要的,因為在最后一步 (img - mean) / std,分子分母可以約掉1/255,這和img,mean,std不做除以255這一步計算,直接(img - mean) / std是等價的,
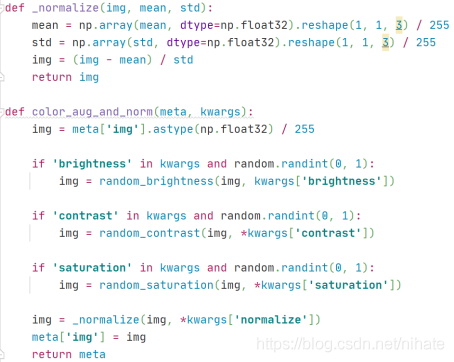
綜上所述,在預處理模塊Pipeline類包含了很多冗余的計算,影像預處理本身是一個簡單問題,但是在官方代碼里卻把簡單問題搞復雜化了,
官方代碼倉庫(https://github.com/RangiLyu/nanodet)里提供了基于 ncnn 推理框架的實作,基于mnn,libtorch,openvino的實作,但是沒有基于Opencv的dnn模塊的實作,于是我就撰寫一套基于Opencv的dnn模塊的實作,程式里包含Python和C++兩個版本的代碼,我把這套程式發布在github上,地址是:
https://github.com/hpc203/nanodet-opncv-dnn-cpp-python
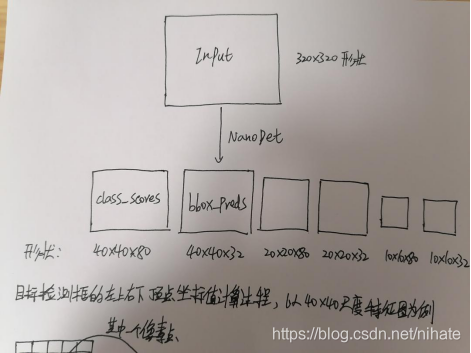
在這套程式里,影像預處理模塊沿用了ultralytics代碼倉庫里的letterbox函式使用opencv庫里的resize和copyMakeBorder就可以實作保持高寬比的resize,此外,在網上有很多介紹nanodet網路結構的文章,但是在文章里沒有對nanodet后處理模塊做詳細介紹的,因此,在撰寫這套程式時,我最關注的是nanodet的后處理模塊,在nanodet網路輸出之后,經過怎樣的矩陣計算之后得到檢測框的左上和右下兩個頂點的坐標(x,y)的值的,接下來,我結合代碼來理解后處理模塊的運行原理,首先,原圖經過預處理之后形成一個320x320的圖片作為nanodet網路的輸入,經過forward前向計算后會得到40x40,20x20,10x10這三種尺度的特征圖(換言之就是原圖縮小8倍,16倍,32倍),在程式代碼里設斷點除錯,查看中間變數,截圖如下:
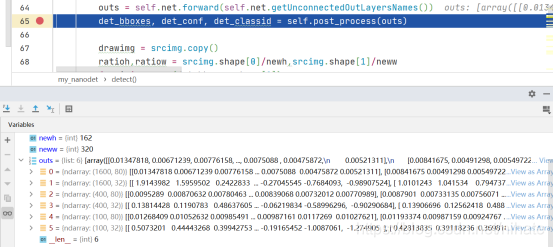
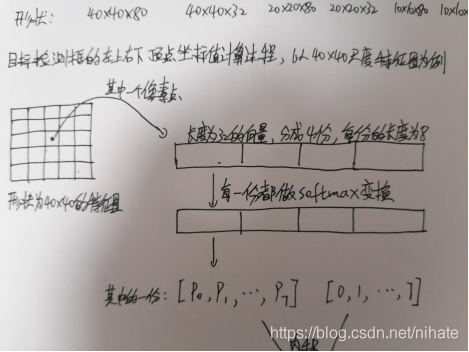
從上圖可以看到,經過forward前向計算后,有6個輸出矩陣,第1個輸出的維度是(1600,80),它對應的是40x40的特征圖(拉平后是長度為1600的向量,也就是說一共有1600個像素點)里的每個像素點在coco資料集的80個類別里的每個類的置信度,第2個輸出的維度是(1600,32),它對應的是40x40的特征圖(拉平后是長度為1600的向量,也就是說一共有1600個像素點)里的每個像素點的檢測框的預測偏移量,可以看到這個預測偏移量是一個長度為32的向量,它可以分成4份,每份向量的長度為8,接下來的第3,4,5,6個輸出矩陣的意義以此類推,
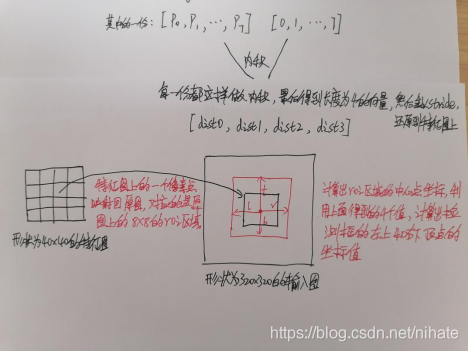
前面講到過nanodet的特點是讓神經網路學習feature map中每個位置到檢測框的四條邊的距離,接下來我們繼續在程式里設斷點除錯,來理解這4份長度為8的預測偏移量是如何經過一系列的矩陣計算后得到到檢測框的四條邊的距離,代碼截圖如下:
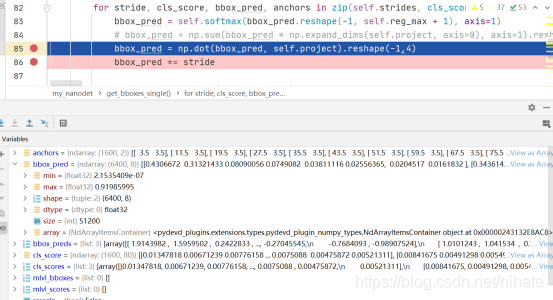
從上圖可以看到,把形狀為(1600,32)的矩陣reshape成(6400,8)的矩陣bbox_pred,其實就等同于把每一行切分成4份組成新的矩陣,然后做softmax變換,把數值歸一化到0至1的區間內,繼續除錯接下來的一步,代碼截圖如下:
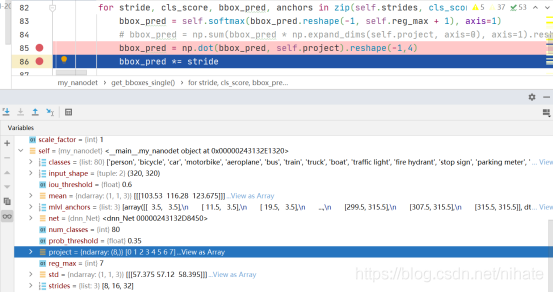
可以看到project是一個長度8的向量,元素值是從0到7,形狀為(6400,8)的矩陣bbox_pred與向量project做乘法得到6400的列向量,然后reshape為(1600,4)的矩陣,接下來乘以縮放步長,這時候就得到的形狀為(1600,4)的矩陣bbox_pred,它的幾何意義就是40x40的特征圖里的每個像素點到檢測框的四條邊的距離,有了這個值之后,接下來的計算就簡單了,在此不做詳細講述,可以參閱我的代碼,簡單來說就是計算特征圖的每個像素點在coco資料集里的80類里的最大score值作為類別置信度,然后把特征圖的所有像素點的類別置信度從高到低排序,取前topk個像素點,然后根據上一步計算出的到檢測框四條邊的距離換算出檢測框的左上和右下兩個頂點的(x,y)值,最后做NMS去除重疊的檢測框,為了更好的理解從nanodet輸出特征圖到最終計算出目標檢測框的左上和右下頂點坐標(x,y)值的這個程序,我在草稿紙上畫圖演示,如下所示:
在撰寫完調用opencv的做nanodet目標檢測的程式后,為了驗證程式的有效性,從COCO資料集里選取幾張圖片測驗并且與官方代碼做比較,官方代碼是用python撰寫的呼叫pytorch框架做目標檢測的,結果如下,左邊的圖是官方代碼的可視化結果,右邊的圖是opencv做nanodet目標檢測的可視化結果,






把官方代碼和我撰寫的代碼做了一個性能比較的實驗,實驗環境是ubuntu系統,8G顯存的gpu機器,在實驗中讀取一個視頻檔案,對視頻里的每一幀做目標檢測,分別運行官方的呼叫pytorch框架做目標檢測的python代碼和我撰寫的呼叫opencv做目標檢測的python代碼,在terminal終端輸入top查看這兩個程式運行時占用的記憶體,截圖如下,第一行是opencv做nanodet目標檢測程式運行時占用的記憶體,第二行是官方代碼運行時占用的記憶體,可以看到使用opencv做nanodet目標檢測對記憶體的消耗明顯要低于官方代碼的pytorch框架做nanodet目標檢測的,
![]()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261323.html
標籤:AI