目錄
- 目的
- 背景
- 個人配置
- 賽題要求
- 本機跑通Baseline
- pytorch配置
- 準備環節
- 添加transformers和sklearn
- 資料檔案及bert配置
- 模型訓練程序
- 資料準備
- 訓練
- 更改batch_size適配主機
- 生成結果
- 打包預測結果
- Docker提交
- Docker安裝
- 本機Docker推送
- 走通的路
- 比賽提交
- 致謝
- 參考
目的
??根據Datawhale大佬們提供的baseline訓練模型,并通過docker的方式提交到天池比賽,獲得自己的分數,對于新手來說,并沒有看起來那么輕松,特此記錄踩坑歷程,感謝老師們的指點!
背景
個人配置
- 作業系統:windows10專業版(Tipis:家庭版裝docker會有區別)
- 顯卡:RTX3070
- 環境:pytorch1.7.1(GPU版)+ CUDA11.1 + Pycharm + windows版Docker
賽題要求
- 賽事資訊:天池->全球人工智能技術創新大賽【熱身賽二】
- Datawhale提供的baseline(特別感謝~):地址
??Tips:之后將基于該baseline教程,詳細敘述我的配置歷程,
本機跑通Baseline
pytorch配置
- 關于windows版的Anaconda+Pytorch+Pycharm+Cuda配置可以看我之前總結的博客:地址
- 關于CuDNN的配置可以看我另一篇總結:地址
??踩了許多坑的總結~
準備環節
??git clone模型檔案到本機,專案命名為tianchi-multi-task-nlp,運行環境為pytorch虛擬環境,編譯器為Pycharm,
添加transformers和sklearn
??pytorch虛擬環境中并沒有這兩項,我們需要使用pip安裝一下,不過要注意一點,我們需要將這兩個包安裝到pytorch虛擬環境下,而不是直接在cmd中全域安裝,
??打開Anaconda->powershell prompt,我們通過powershell prompt進入pytorch虛擬環境,
conda activate <pytorch環境名稱(自己命名)> #激活虛擬環境
pip install transformers #安裝transformers
pip install sklearn #安裝sklearn
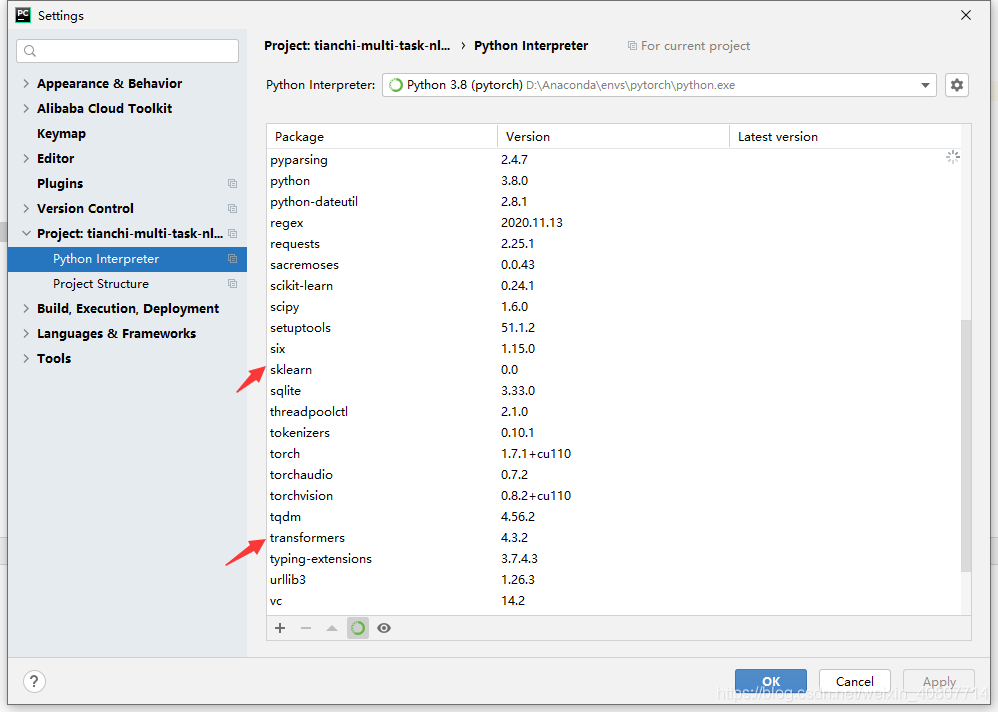
??安裝結果如圖:
資料檔案及bert配置
??下載中文預訓練BERT模型bert-base-chinese,地址:https://huggingface.co/bert-base-chinese/tree/main
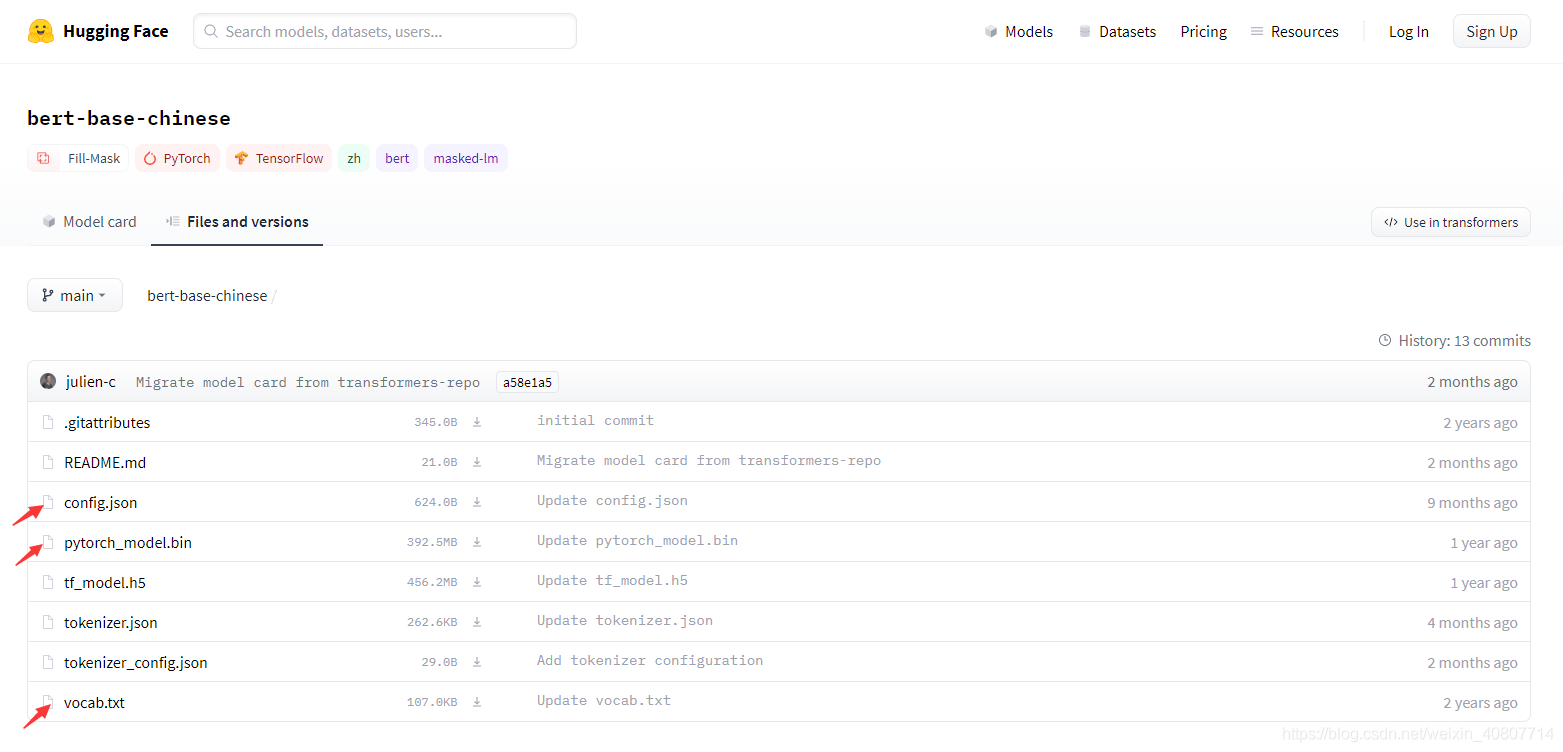
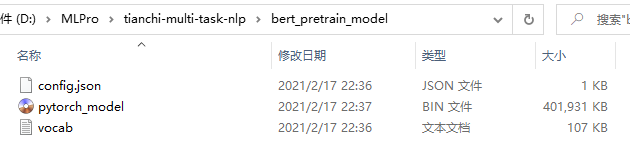
??只需下載config.json、vocab.txt和pytorch_model.bin,把這三個檔案放進tianchi-multi-task-nlp/bert_pretrain_model檔案夾下,
??下載比賽資料集,把三個資料集分別放進tianchi-multi-task-nlp/tianchi_datasets/資料集名字/下面:
- OCEMOTION/total.csv:http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/OCEMOTION_train1128.csv
- OCEMOTION/test.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/ocemotion_test_B.csv
- TNEWS/total.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/TNEWS_train1128.csv
- TNEWS/test.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/tnews_test_B.csv
- OCNLI/total.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/OCNLI_train1128.csv
- OCNLI/test.csv: http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531841/b/ocnli_test_B.csv
??檔案目錄樣例:
tianchi-multi-task-nlp/tianchi_datasets/OCNLI/total.csv
tianchi-multi-task-nlp/tianchi_datasets/OCNLI/test.csv
??分別建立檔案夾并重命名資料集即可~
模型訓練程序
資料準備
??分開訓練集和驗證集,默認驗證集是各3000條資料,引數可以自己修改,
運行
generate_data.py檔案
??這里windows10系統可能會遇到一個問題:

??可能是編碼問題,解決方法就是在定位處添加:
,encoding='utf-8'
并且在所有.csv后綴(資料集檔案)的后面都要添加該引數,

訓練
更改batch_size適配主機
??運行train.py檔案來訓練模型,初始設定:
train(epochs=20,batchSize=16, device='cuda:0', lr=0.0001, use_dtp=True, pretrained_model=pretrained_model, tokenizer_model=tokenizer_model, weighted_loss=True)
這里主要關注batchSize和epochs,因為bert很吃顯存,所以我們要根據本機的配置對應調整模型引數,我的顯卡是RTX3070 顯存8G,結果遇到了問題:
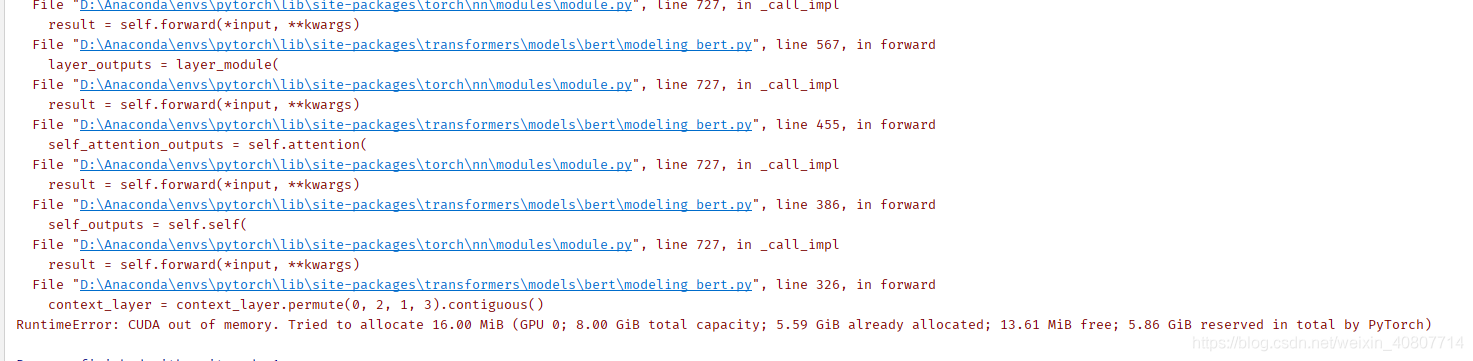
??經過查閱,我發現Stack Overflow上有一個問題比較有參考意義,結合目前情況,我選擇只調小batchSize,
batchSize=8
結果一覺醒來,跑通模型~
??此外,會保存驗證集上平均f1分數最高的模型到./saved_best.pt,
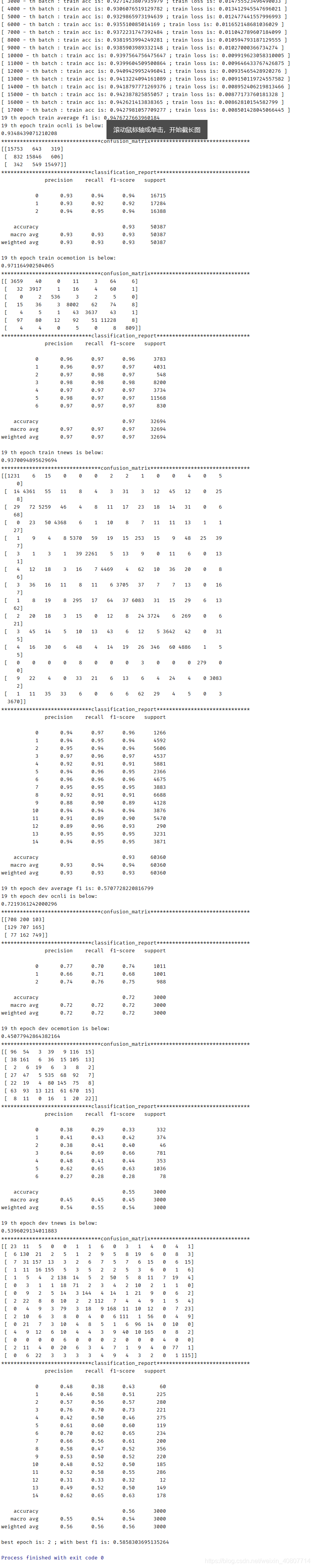
生成結果
??用訓練好的模型./saved_best.pt生成結果:
運行
inference.py檔案
打包預測結果
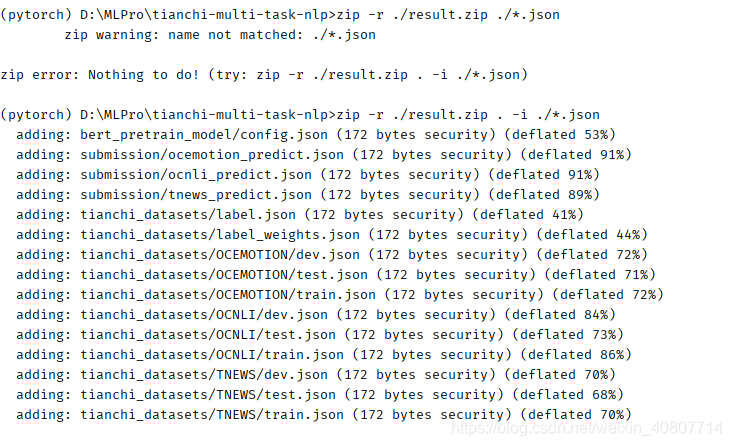
??直接運行:
zip -r ./result.zip ./*.json
會遇到‘zip‘ 不是內部或外部命令,也不是可運行的程式 或批處理檔案的報錯,這是由于windows系統下并沒有zip命令(Linux),不過我們可以下載GnuWin32中exe檔案,默認安裝即可,注意,要記住安裝路徑,方便我們添加環境變數,
??右鍵此電腦->屬性->高級系統設定->環境變數,在系統變數中的Path添加GnuWin32\bin路徑,
重啟電腦,即可使用zip命令,
??到此,在本機訓練baseline的程序完畢,
Docker提交
??再次強調,win10專業版和家庭版在安裝Docker程序中區別很大,我的主機為win10專業版,此外,docker的命令列操作均在windows powershell運行,必要時以管理員身份運行,
Docker安裝
??直接去官網安裝windows桌面版即可,在第一次運行Docker時,Hyper-V始終加載失敗,我發現是由于我新配的主機未開虛擬化(到任務管理器的性能頁面即可查詢)由于本機是華碩主板,我需要在開機時按F2進入BIOS界面打開虛擬化,再次進入Docker之后,沒有再遇到該問題,
??第一次運行Docker,在測驗hello-world鏡像時候,windows powershell報錯unable to find image,意思是Docker在本地沒有找到hello-world鏡像,也沒有從docker倉庫中拉取鏡像,由于Docker服務器在國外(需要翻墻),因此我們在國內無法正常拉取鏡像,所以需要我們為Docker設定國內阿里云的鏡像加速器,
{
"registry-mirrors": ["https://alzgoonw.mirror.aliyuncs.com"]
}
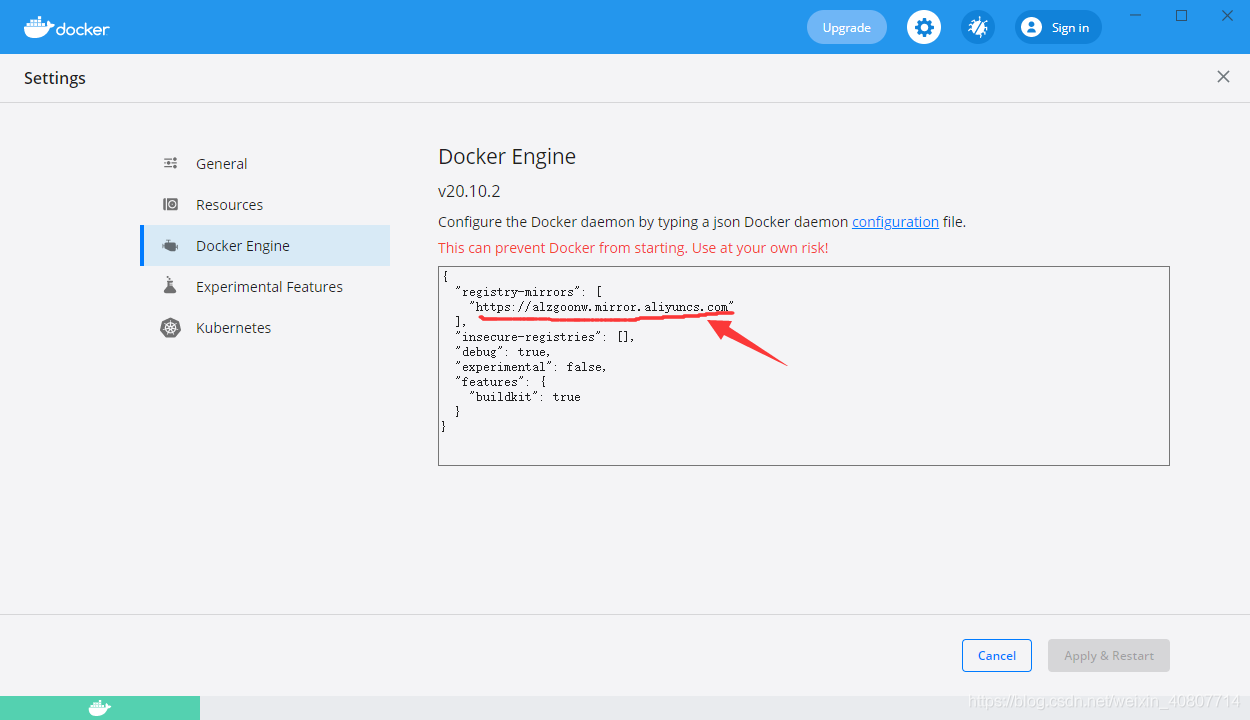
重啟后即可正常拉取hello-world鏡像,
本機Docker推送
??給出我使用的參考教程,仔細研讀,會有識訓,我也會給出我自己走通的路~
- 基本盤:Docker推送到阿里云教程
- 云端鏡像倉庫中的操作指南
- 比賽的容器鏡像提交說明
??注:涉及到一些個人倉庫id的截圖暫時不便放出,請諒解,可參考 基本盤:Docker推送到阿里云教程內的運行結果圖,
走通的路
??進入云端鏡像倉庫創建自己的鏡像倉庫和命名空間,進入自己創建的倉庫,找到操作指南,里面有你想要的~
??現在開始準備提交的檔案夾(submission):
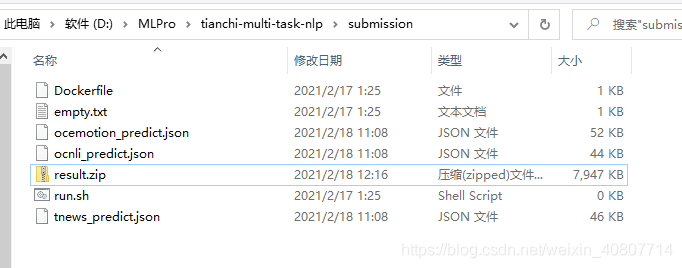
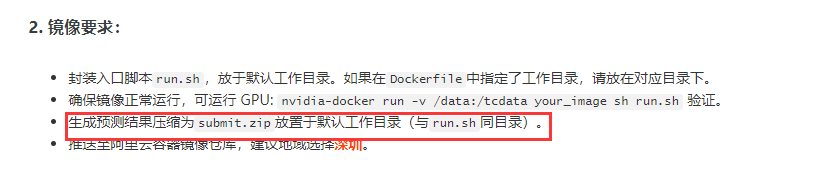
這里注意要把打包好的result.zip放到submission內,不然你可能會浪費一次比賽提交機會,這是由于比賽要求:
??之后在windows powershell中進入(cd)到submission檔案夾內,進行如下操作:\
- 登錄
docker login --username=用戶名 registry.cn-shenzhen.aliyuncs.com
注意:用戶名在自創倉庫的詳情頁下方的操作指南里有說明,
- 構建鏡像
docker build -t registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0 .
注意:registry.~~~用自己倉庫地址替換(到自創倉庫的詳情頁查詢),地址后面的1.0為自己指定的版本號,用于區分每次build的鏡像,最后的.是構建鏡像的路徑,不可以省掉,
- 推送鏡像到倉庫
docker tag [ImageId] registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
docker push registry.cn-shenzhen.aliyuncs.com/test_for_tianchi/test_for_tianchi_submit:1.0
注意:ImageId在Docker桌面->左側Images欄->鏡像名串列-> <registry.~~~:1.0> -> IMAGE ID中;registry.~~~用自己倉庫地址替換(到自創倉庫的詳情頁查詢),與上面的操作一致,
??至此,Docker推送完成,接下來可以提交了,
比賽提交
??提交界面如圖:
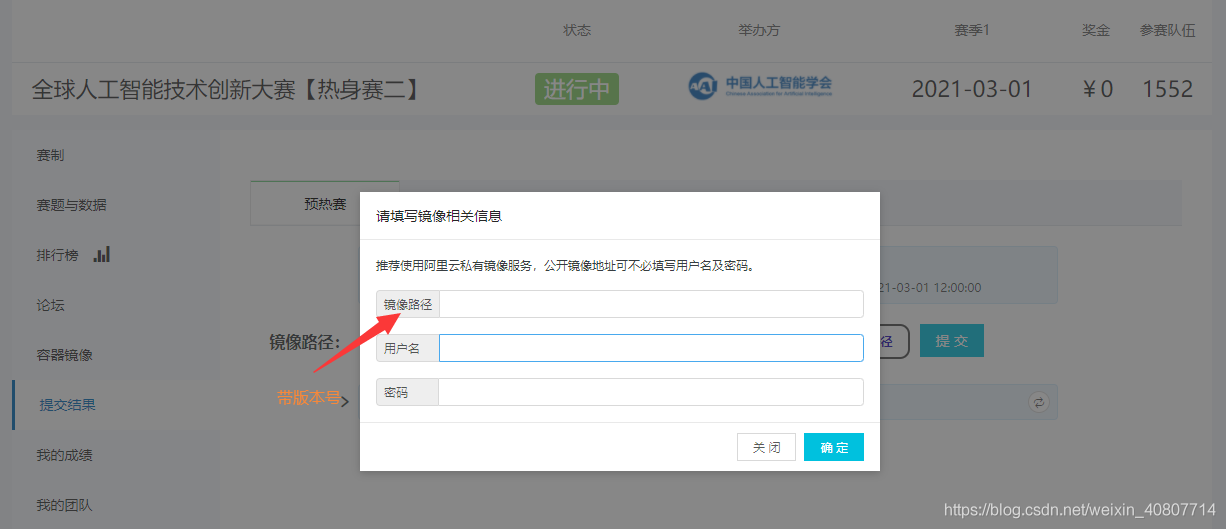
??剛才我提到要將要把打包好的result.zip放到submission內,即與run.sh同目錄,第一次提交我并沒有這樣做,于是提交之后無結果,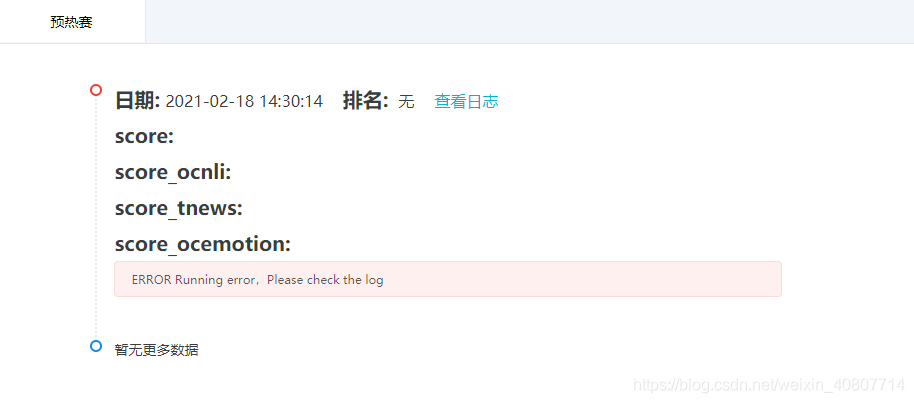
??查看日志之后發現無法打開result檔案:

這樣浪費了兩次機會,
??此時,我發現賽題要求將result.zip與run.sh放于同一目錄,盡管今天只剩下最后一次機會,我仍然選擇相信自己的判斷,于是重新構建了2.0版本,再次推送到鏡像倉庫,結果提交成功,有了baseline成績,趕緊截圖保存~
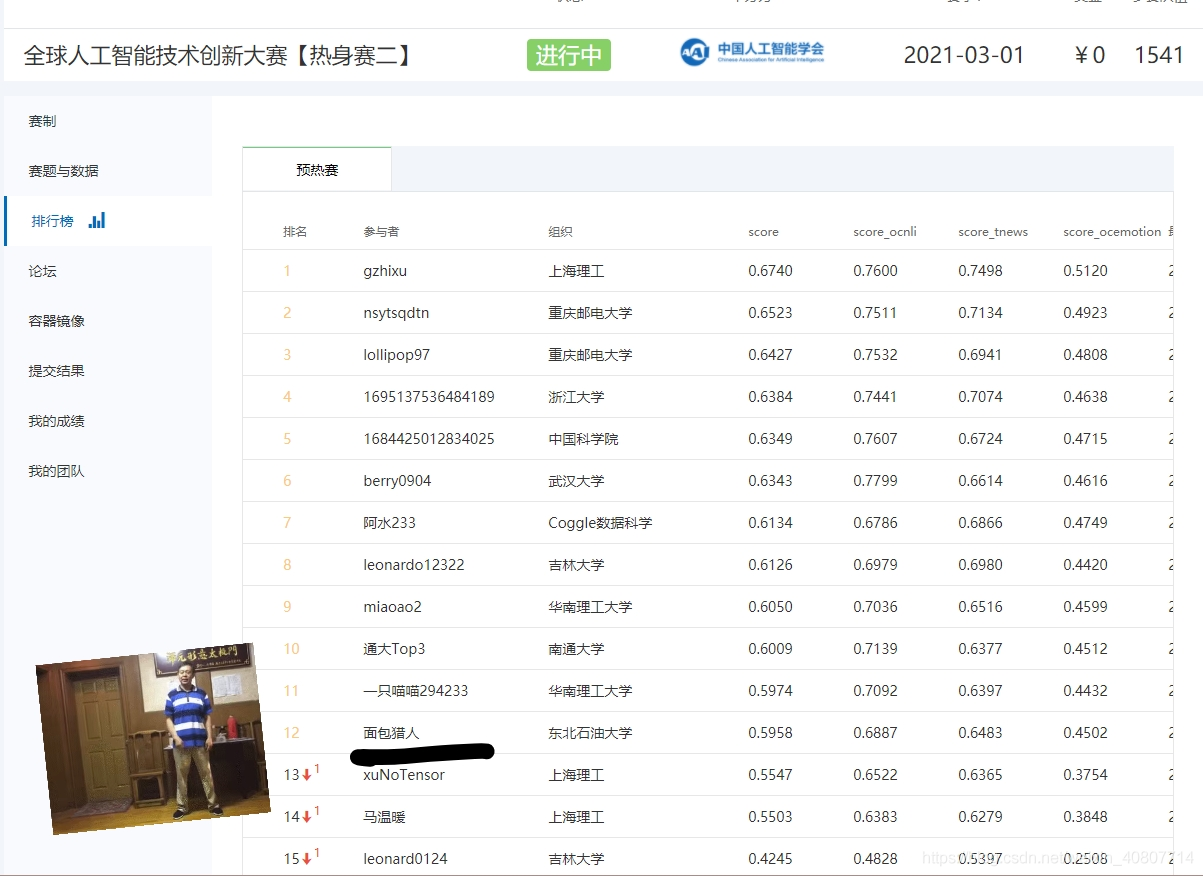
當然,優化之路才剛剛開始!
致謝
??萬分感謝Datawhale提供這次機會!
參考
- baseline
- 全球人工智能技術創新大賽【熱身賽二】
- UnicodeDecodeError解決方案
- windows zip命令
- docker測驗問題
- 基本盤:Docker推送到阿里云教程
- 云端鏡像倉庫中的操作指南
- 比賽的容器鏡像提交說明
- windows版的Anaconda+Pytorch+Pycharm+Cuda配置
- CuDNN的配置
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261848.html
標籤:AI