獨家思維導圖!讓你秒懂李宏毅2020機器學習(二)—— Classification分類
在上一篇文章我總結了李老師Introduction和regression的具體內容,即1-4課的內容,這篇我將會總結classification的內容(包括Generative Model和Discriminative Model),即5-6課的內容(第6課Logistic Regression雖然名字叫regression實際上也是classification的內容),這兩課的內容有點難懂,博主花了好長時間才理出頭緒,當然,說的有不準確的地方還請各位大佬批評指正!
上一篇文章傳送門獨家思維導圖!讓你秒懂李宏毅2020機器學習(一)—— Regression回歸
文章目錄
- 獨家思維導圖!讓你秒懂李宏毅2020機器學習(二)—— Classification分類
- Classification
- 概念描述
- 特征數值化
- How to classification
- Why not apply Regression?
- Prepositional knowledge
- Generative model
- Binary Classification
- Logistic Regression(Discriminative)
- Step 1: Function set
- Step 2: Goodness of a function
- Step 3: Find the best function
- Logistic Regression VS Linear Regression
- Why not apply Square error?
- Multi-class Classification
- Limitation of Logistic Regression
- Powerful Cascading Logistic Regression
Classification
概念描述
分類(classification),即找一個函式判斷輸入資料所屬的類別,可以是二類別問題(是/不是),也可以是多類別問題(在多個類別中判斷輸入資料具體屬于哪一個類別),與回歸問題(regression)相比,分類問題的輸出不再是連續值,而是離散值,用來指定其屬于哪個類別,分類問題在現實中應用非常廣泛,比如垃圾郵件識別,手寫數字識別,人臉識別,語音識別等,
簡單來說就是找一個function,它的input是一個object,它的輸出是這個object屬于哪一個class
特征數值化
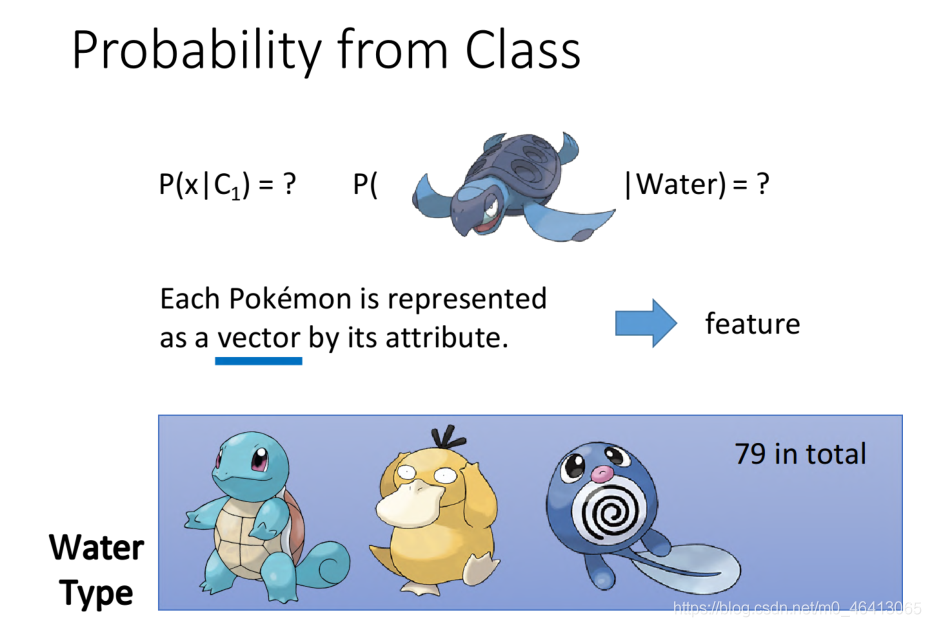
上面說到classification的input是一個object,但object怎么輸入呢?
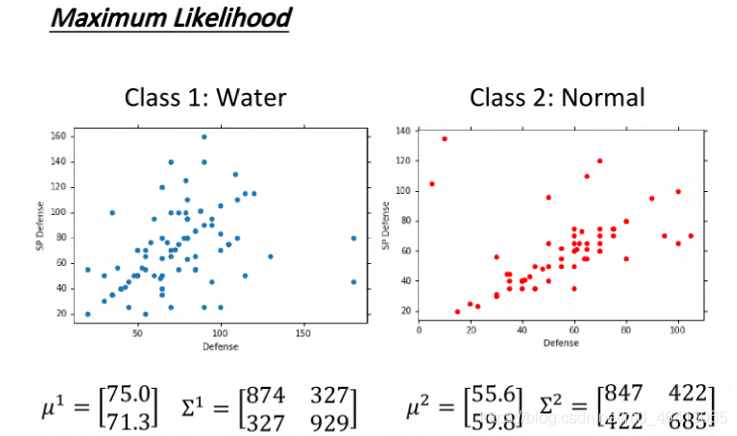
我們需要用數字來表示這個object的特征,李老師寶可夢的例子是
用?命值(HP)、攻擊?(Attack)、防御?(Defense)、特殊攻擊?(Special Attack)、特殊防御?(Special defend)、速度(Speed)七種特性的數值所組成的vector來描述一只皮卡丘,

How to classification
好了,解決了input的問題,就需要找分類的方法了,一個直觀的想法就是看能不能套用前面回歸的做法,
Why not apply Regression?
總結一下,就是:
1.Regression的output是連續性質的數值,?classification要求的output是離散性質的點,我們很難找到?個Regression的function使?部分樣本點的output都集中在某?個離散的點附近,
2. 線性回歸用來解決分類問題時,穩定性差,當樣本分布比較復雜時,線性回歸無法做到準確的分類,
過于抽象?用李老師的例子來解釋一下:
以binary classification為例,我們在Training時讓輸?為class 1的輸出為1,輸?為class 2的輸出為-1;那么在testing的時候,regression的output是?個數值,它接近1則說明它是class 1,它接近-1則說明它是class 2
假設現在我們的model是 y=b+w1x1+w2x2,input是兩個feature(x1,x2)
有兩個class,藍?的是class 1,紅?的是class 2,
我們希望
藍?的屬于class 1的寶可夢,input到Regression的model,output越接近1越好;
紅?的屬于class 2的寶可夢,input到Regression的model,output越接近-1越好,
假設我們真的找到了這個function,如圖所?,綠?的線表?b+w1x1+w2x2=0,也就是class 1和class 2的分界線,這種情況下,值接近-1的寶可夢都集中在綠線的左上?,值接近1的寶可夢都集中在綠線的右下?,這是合理的,
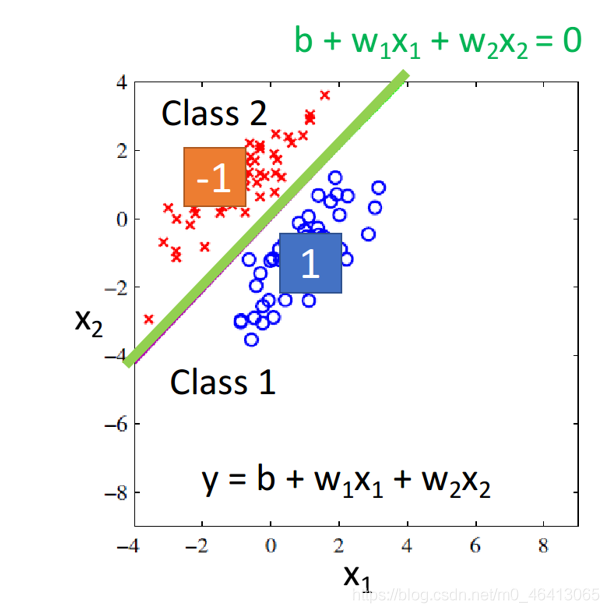
但是上述現象只會出現在樣本點?較集中地分布在output為-1和1的情況,如果像下圖所?,顯然綠線為最好的那個model的分界線
但如果將所有樣本點通過Regression訓練出來的model,會是紫?這條分界線對應的model
因為相對于綠線,它“減?”了由右下?這些點所帶來的error,也就是說,regression會考慮相距分界線較遠的點
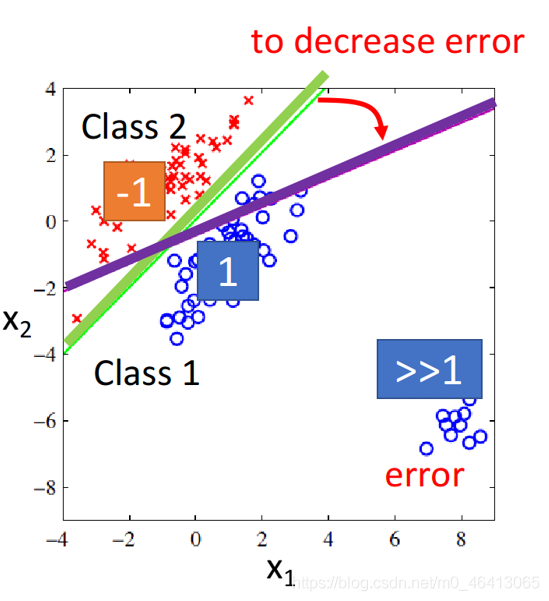
也就是說,
Regression對樣本分布太敏感了
假如現在負樣本比較多,那么回歸線將會更靠近負樣本,使得正樣本的預測值下降,
為了使損失函式(均方差)最小化,回歸線要朝著負樣本的方向移動;
即上面的的function會為了使損失函式(均方差)最小化,由綠線的位置向右下角距離較遠的藍色樣本點偏移,變成紫色部分,
所以,Regression定義model好壞的定義?式對classification來說是不適?的
再簡單點說,兩點pass掉了regression:
1.線性回歸的預測值是連續值的形式,不是概率的形式
2.對資料分布比較敏感
好的,接下來我們終于可以進入正題了!
Wait!還需要一點概率論的前置知識,當然,熟練掌握概率論的大佬請跳過
Prepositional knowledge
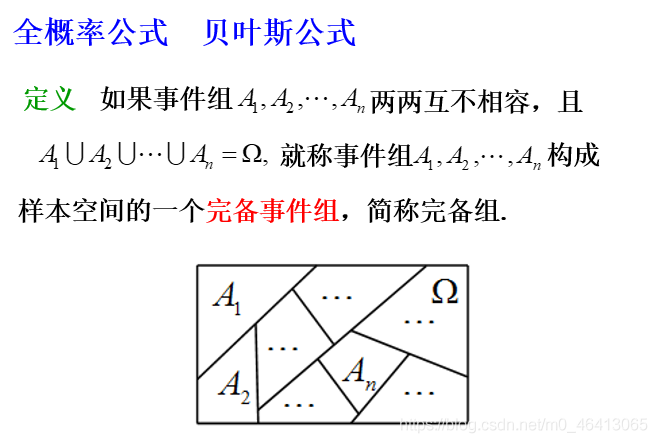
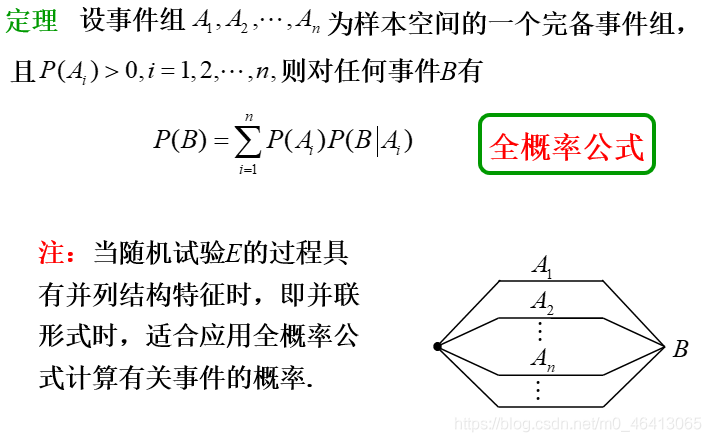



Generative model
終于步入正題了!
Binary Classification
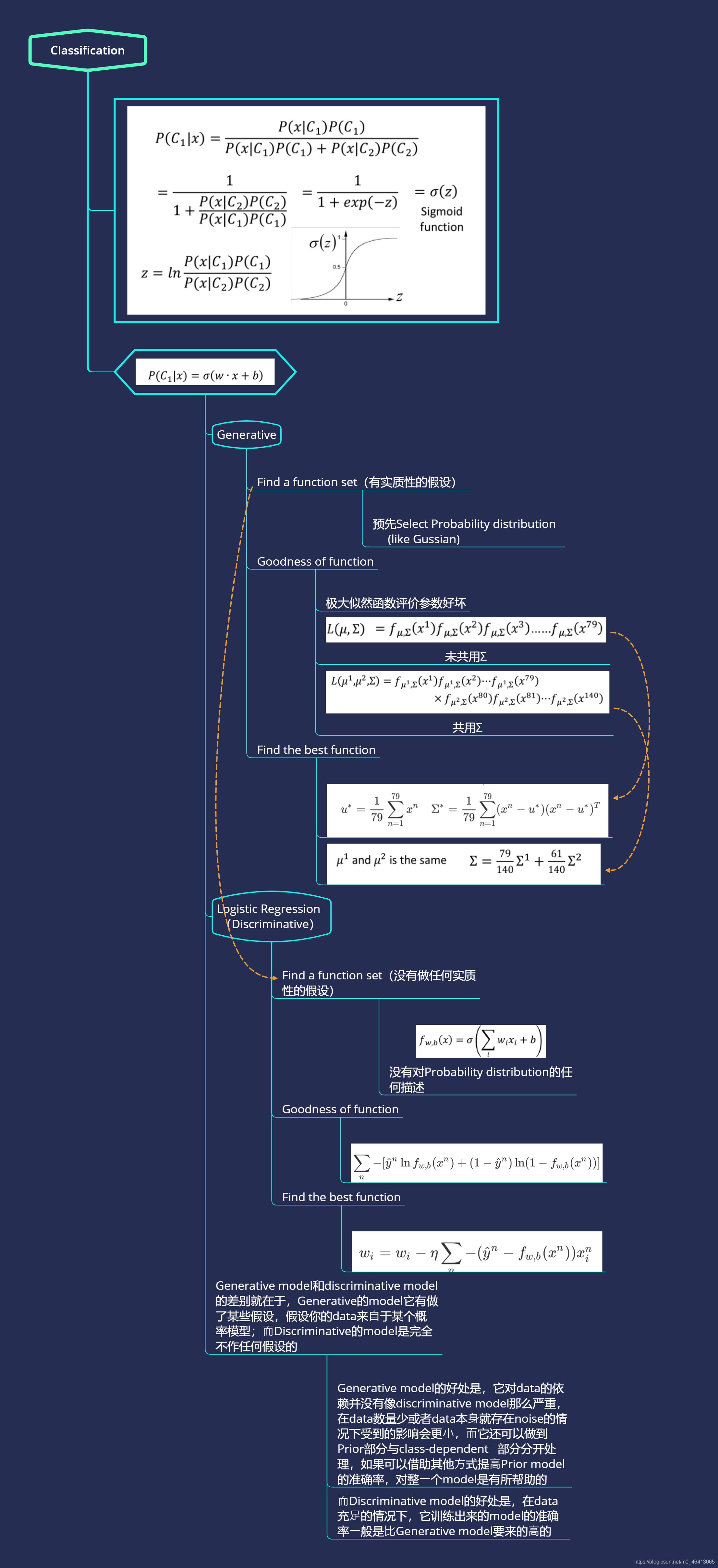
首先考慮?元分類的問題,我們拿到?個input x,想要知道這個x來自于class 1或class 2的概率
這不就是我上文講的貝葉斯公式嘛!
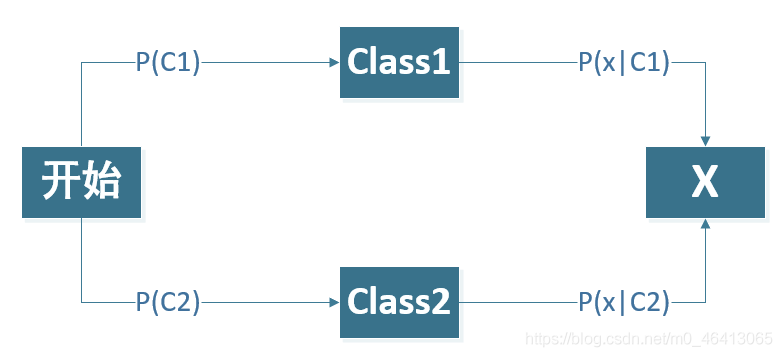
由圖我們可以得到以下兩個公式
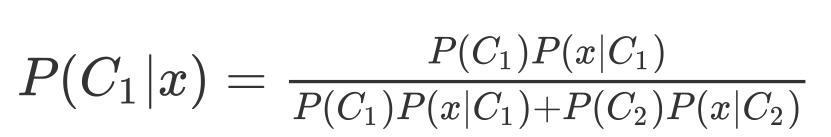
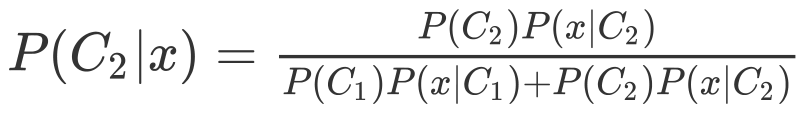
先提一點,在這里P(C1|x)+P(C2|x)=1喲,也就是說,我們只需求一即可,
當P(C1|x)>0.5 我們就說x是屬于C1的
其中P(C1),P(C2)這兩個值還是比較好求的
在Training data??,有79只?系,61只?般系
P(C1)=79/(79+61)=0.56
P(C2)=61/(79+61)=0.44
關鍵在于如何得到P(x|C1)和P(x|C2)
錯誤的想法:
假設我們的x是?只新來的海?,但是在我們79只?系的寶可夢training data??根本就沒有海?,所以挑?只海?出來的可能性根本就是0啊!
實際上,這這已有的79只?系寶可夢的data其實只是冰???,這些只是從一個概率密度函式中挑出來的樣本,設這個概率密度函式為f(x),則
P(x|C1)=f(x)
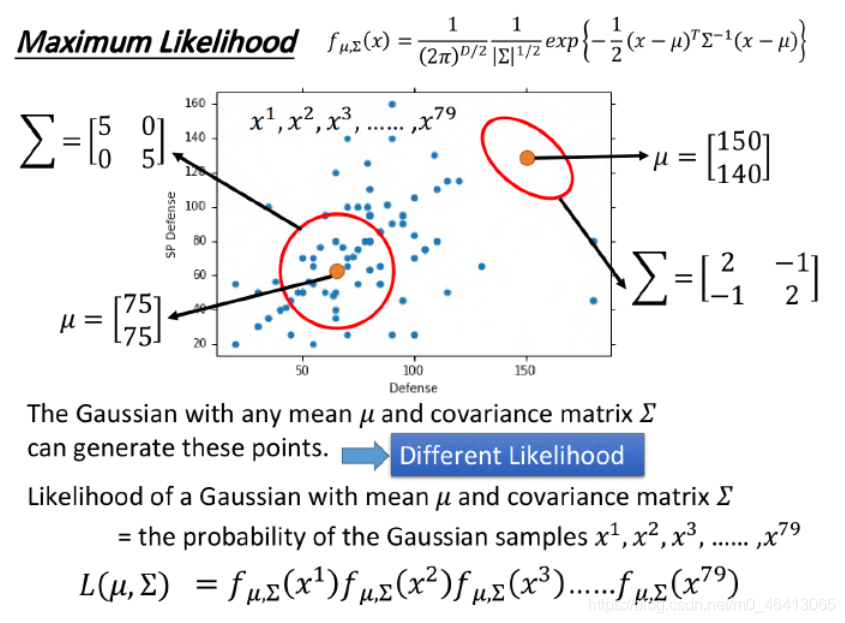
在這里,李老師設這個概率密度函式為Gaussian,我們要通過這79個已知的樣本點來找出生成這些樣本點可能性最大的Gaussian,即由冰山一角推算整個冰山,
很自然的想到用極大似然估計法來估測這個Gaussian(實際上就是求μ和Σ)做法是
找出最特殊的那對μ和Σ,從它們共同決定的?斯函式中再次采樣出79個點,使”得到的分布情況與當前已知79點的分布情況相同“這件事情發?的可能性最?
假設這79個樣本獨立同分布(極大似然法條件)可得到李老師如下極大似然函式
極大似然函式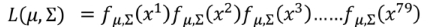
實際上就是該事件發?的概率就等于每 個點都發?的概率之積,我們只需要把79個點中每?個點的data代進去,就可以得到?個關于μ和Σ的函式,分別求偏導,解出微分是0的點,即使L最?的那組引數,便是最終的估測值,通過微分得到的?斯函式的 μ和Σ的最優解如下:
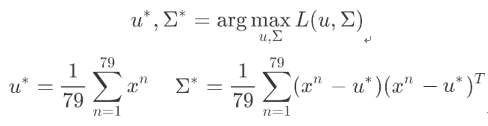
即μ剛好是數學期望,Σ剛好是協?差(這個可以當作公式來記憶)
李老師最終算的值如下:
然后其實就可以算概率進行分類了
當P(C1|x)>0.5 —— x->C1
當P(C1|x)<0.5 —— x->C2

老師把testing data上得到的結果可視化出來
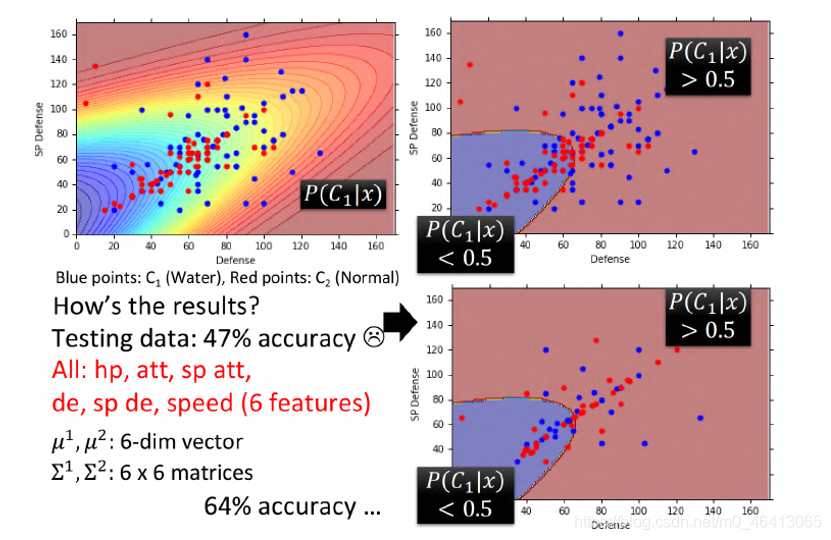
注意,劃重點,由剛剛兩個樣本分別求出來的自己的μ和Σ得到的boundary是曲線
同時,這個準確率也不好
Why?
->還記得之前的兩個Error嗎?
其實variance是跟input的feature size的平?成正?的,所以當feature的數量很?的時候,Σ??的增?是可以?常快的,在這種情況下,給不同的Gaussian以不同的Σ(covariance matrix),會造成model的引數太多,?引數多會導致該model的variance過?,出現overfitting的現象,因此對不同的class使?同?個Σ(covariance matrix),可以有效減少引數
于是,常見的做法是:不同的 class可以share同?個Σ(covariance matrix),注意不同class自己的概率密度函式的μ還是不同的
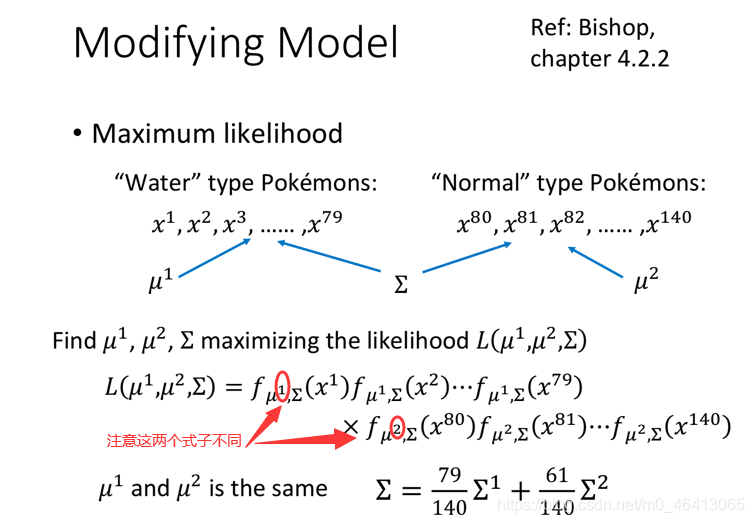
此時就把μ1、μ2和共同的Σ?起去合成?個極?似然函式,此時可以發現,得到的 μ1、μ2和原來?樣,還是各?的均值,?Σ則是原先兩個Σ1和Σ2的加權
然后像上面那樣對結果進行可視化:
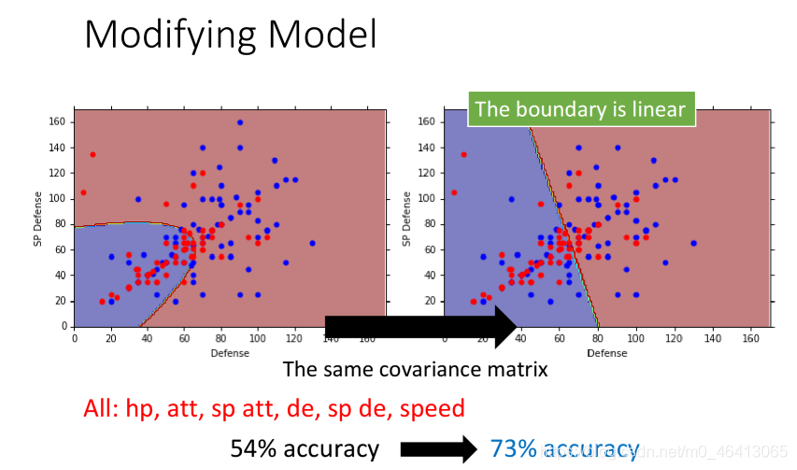
驚訝的發現,不僅共用后正確率提高了而且:
沒有共?covariance matrix——分界線:?條曲線;
如果共?covariance matrix——分界線:?條直線;
奇怪,這直線怎么解釋呢?
我們可以把原來要求的概率形式化簡一下:
運算式上下同除以分?,有沒有覺得形式很像一個常用函式(劃重點)
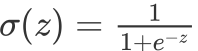
sigmoid function(S函式),我們把該式設成這個函式

引入引數z,再反解z,再化簡z
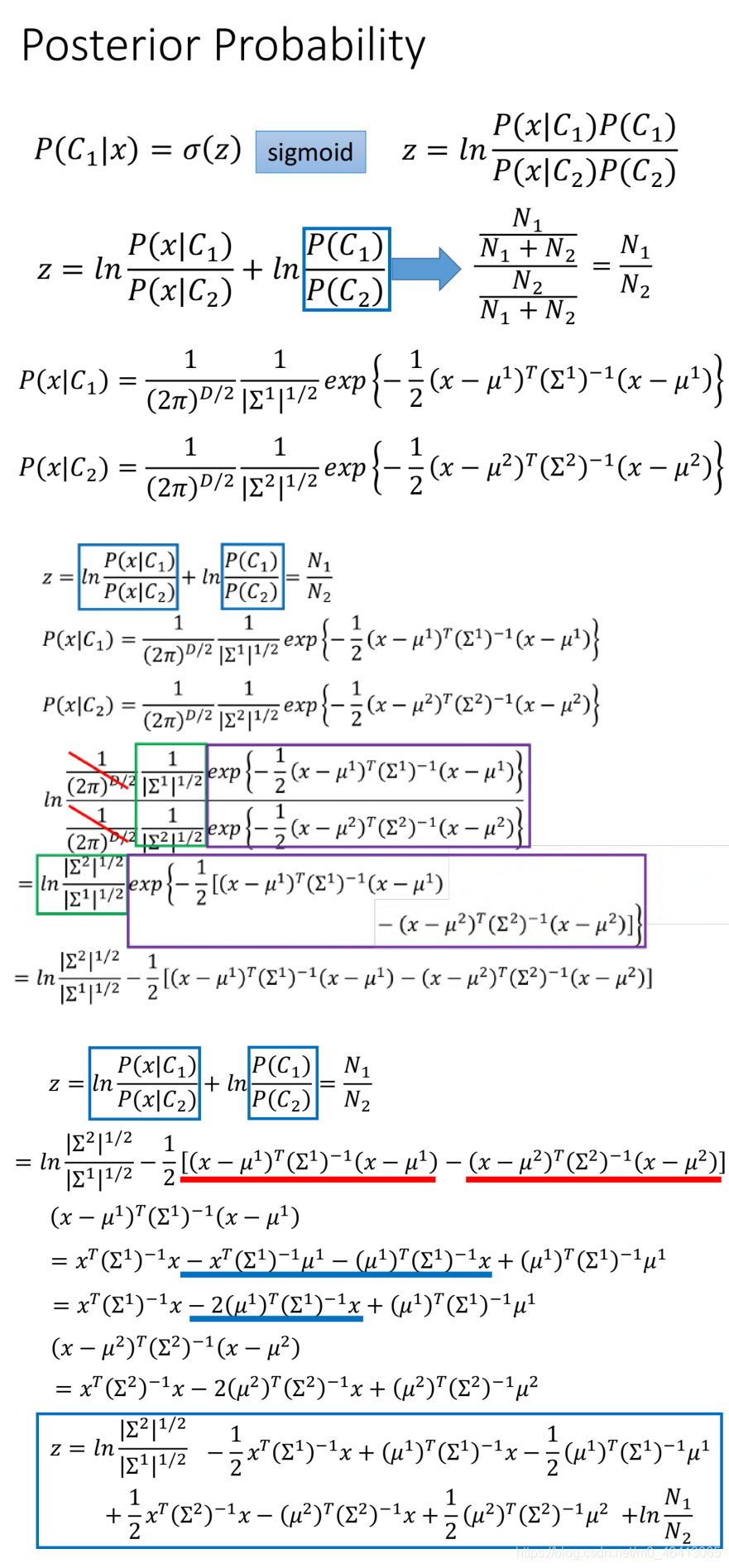
可以看出,當Σ1和Σ2不相等時z是一大堆復雜的式子時:
boundary(分界線)為P(x|C1)=0.5的那條線,即z=0的那條線
此時z=0顯然為曲線,
但當Σ1和Σ2相等時

此時分界線z=0為一條直線,
以上就是Generative Model的分類方法,可以看出,這個方法我們先有一個預設的概率密度函式模型,然后再用極大似然法來尋找預設概率密度函式模型的引數,求出我們基于貝葉斯公式的那個概率來判斷分類,那能不能我們不預設概率密度函式模型呢?能不能我們不算,自動把那個概率密度函式找出來呢?于是我們就有了分類的第二個處理手段Logistic Regression
Logistic Regression(Discriminative)
還記得上節在Gaussian的distribution下考慮class 1和class 2共?Σ,可以得到?個線性的z嗎?
其實很多其他的Probability model經過化簡以后也都可以得到同樣的結果,這節我們就基于z為線性來展開
即用上面的貝葉斯模型,可以將求P(C1|x)的問題轉化為求sigmoid(z)的問題,即轉換為求z的問題,也就是求線性z函式的w和b,于是我們節的任務說白了就是找w和b
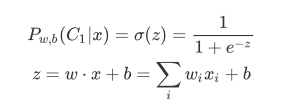
還記得我上篇提到的機器學習的三個步驟嗎?
Step 1: Function set
Step 2: Goodness of a function
Step 3: Find the best function
Step 1: Function set
這?的function set就是Logistic Regression——邏輯回歸
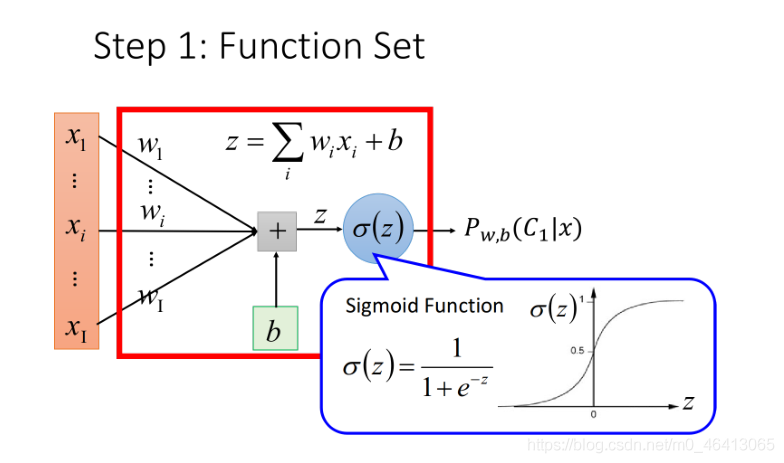
Step 2: Goodness of a function
像剛剛一樣,我們還是要找一個最有可能生成我們這些樣本點的概率密度函式概率密度函式
但這次,我們不做預設,只是簡簡單單的把它看作f(x)=sigmoid(z)=P(C1|x)
于是我們表示出生成這些樣本點的概率(就是極大似然估計函式)

并作如下化簡:
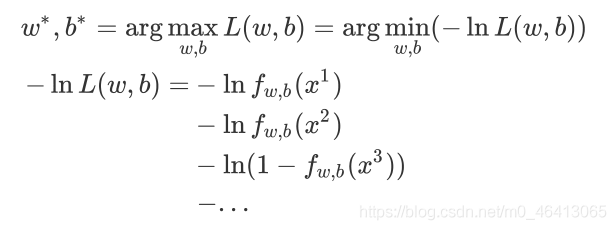
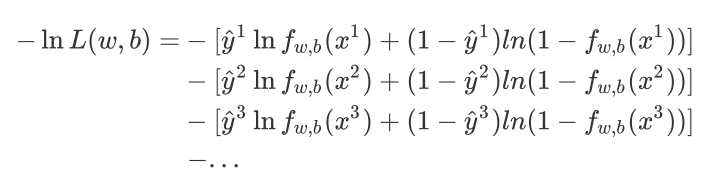
(由于class 1和class 2的概率運算式不統?,上?的式??法寫成統?的形式,為了統?格式,這?將Logistic Regression?的所有Training data都打上0和1的標簽,即output y^=1 代表class 1,output y=2 代表class 2)

即我們要找的引數實際上就是:
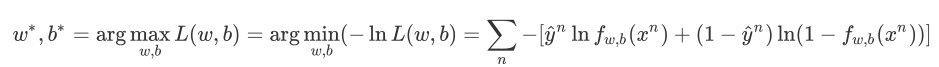
這?xn表?第n個樣本點,yn表?第n個樣本點的class標簽(1表?class 1,0表?class 2),最終這個summation的形式,??其實是兩個Bernouli distribution(兩點分布)的cross entropy(交叉熵)
交叉熵實際上表達的是希望這個function的output和它的target越接近越好
不過這個argmin你們有沒有覺得眼熟呢?
還記得上文的Loss函式嗎,博主感覺,這里的交叉熵就可以看作Loss函式
Step 3: Find the best function
那既然可以看作Loss函式,Find the best function的方法就直接照搬了——gradient descent
還記得上一篇的gradient descent嗎?回顧一下:
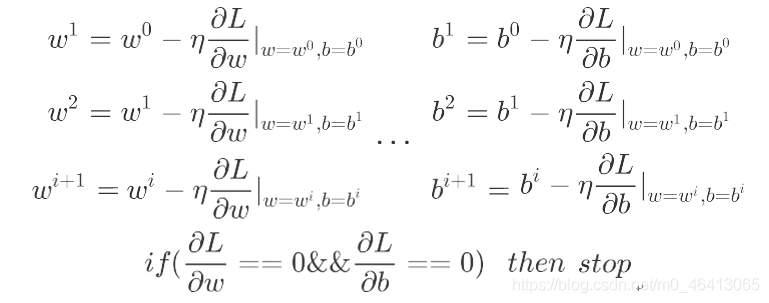
因此,我們要求偏導了
Tip:sigmoid function的微分: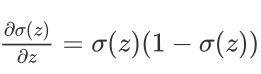
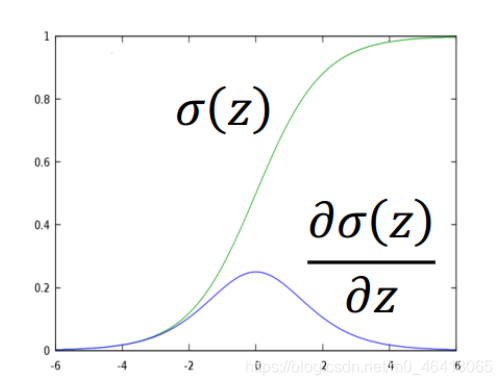


得到最終的結果:
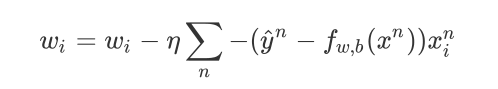
首先分析下,原來update取決于三件事:
- ??設定的 learning rate
- 來?于data的 xi
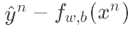 代表function的output跟理想target的差距有多?,如果離?標越遠,update的步伐就要越?
代表function的output跟理想target的差距有多?,如果離?標越遠,update的步伐就要越?
其次,有沒有發現這個式子有點眼熟?
我們直接放出Logistic Regression與Linear Regression的對比圖
Logistic Regression VS Linear Regression

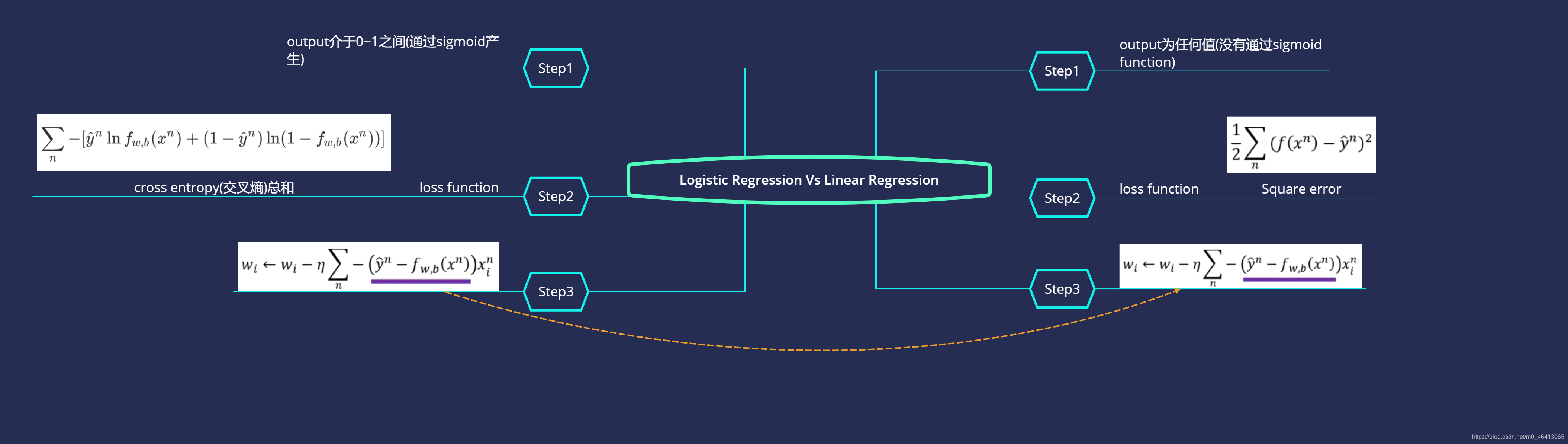
Logistic Regression和linear Regression的 update的?式是?模?樣的!
唯?不?樣的是,Logistic Regression的target 和output 都必須是在0和1之間的,
?linear Regression的target和output的范圍可以是任意值,
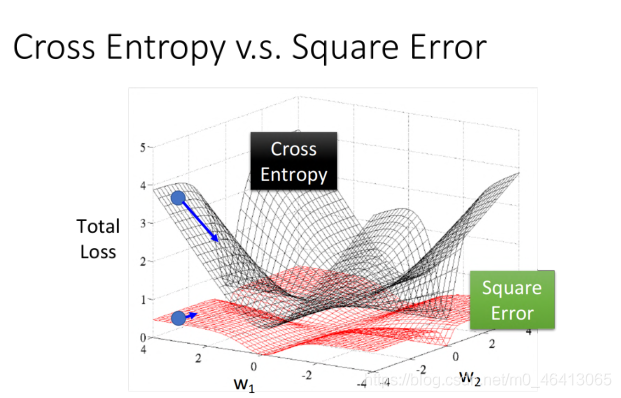
還有一點值得我們注意的是,為什么Logistic Regression的Loss function不用Square error而用交叉熵呢?
Why not apply Square error?
那我們就用Square error來當Loss函式試一下唄!

通過計算可以發現用Square Error在far from target的地方,梯度也接近于0,這樣就會使Loss fuction一直Stuck停滯不前,具體可以可視化如下圖:
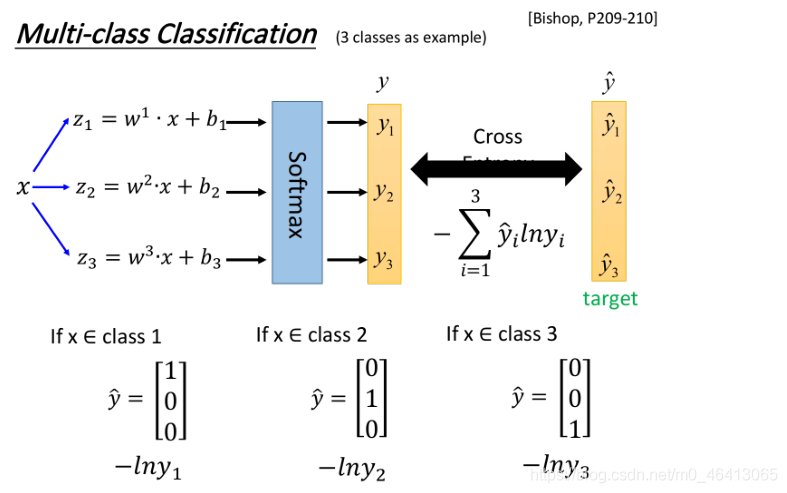
Multi-class Classification
上面無論是Generative model還是Discriminative model都是拿Binary Classification舉例的,對于多元的,其實流程是一樣的,不過有兩個小的改變
上面二元的是采用sigmoid來分類的,三元我們采用softmax來分類:
我們把 丟進?個softmax的function,softmax做的事情是這樣三步:
- 取exponential,得到ez1,ez2, ez3
- 把三個exponential累計求和,得到totalsum=Σezi
- 將total sum分別除去這三項(歸?化),得到 y1,y2,y3
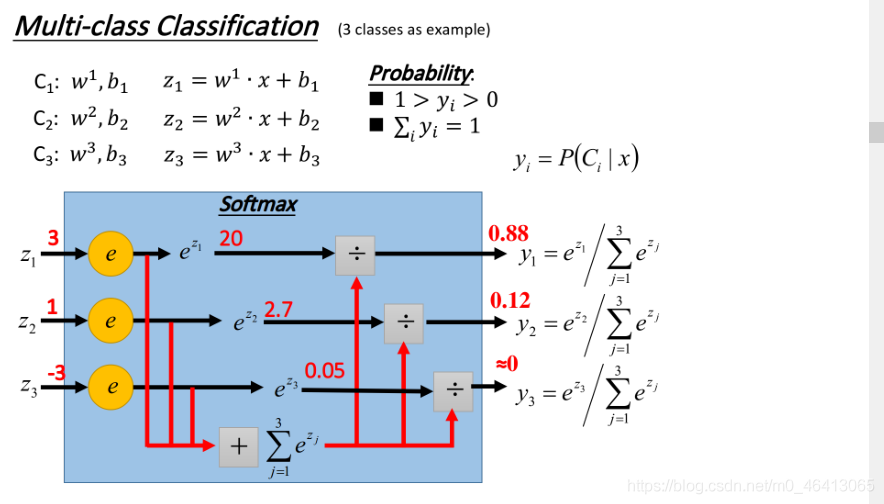
原來的output z可以是任何值,但是做完softmax之后,你的output的值?定是介于0~1之間,并且它們的和?定是1
假設我們?的是Gaussian distribution(共?covariance),經過?般推導以后可以得到softmax的function,?從information theory也可以推匯出softmax function,Maximum entropy本質內容和Logistic Regression是?樣的,這就跟二元是用sigmoid同理,
第二個改變是
我們在訓練的時候還需要有?個target,因為是三個class, output是三維的,對應的target也是三維的,為了滿?交叉熵的條件,target 也必須是probability distribution,這?我們不能使?1,2,3作為class的區分,為了保證所有class之間的關系是?樣的,這?使?類似于one-hot編碼的?式,即
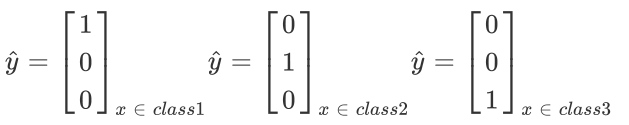
然后接下來就是一樣的流程,我就不做過多贅述了
這一章最后還有個有趣的東西,即由Limitation of Logistic Regression引出了Deep Learning
Limitation of Logistic Regression
李老師舉了個例子來說明這個limitation
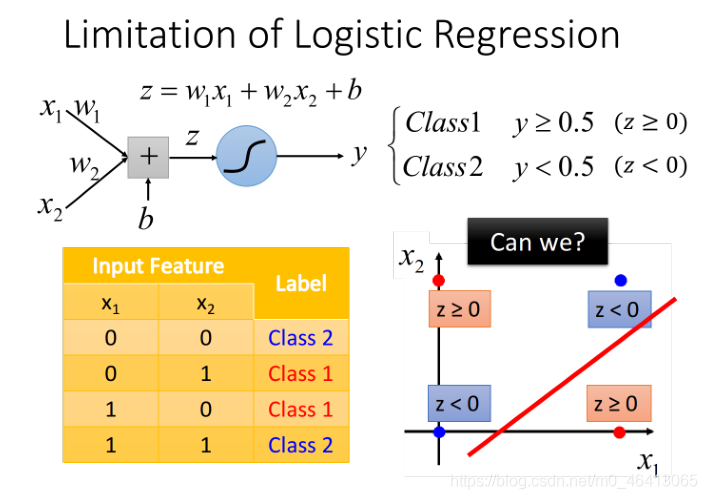
這個例子中,我們無法通過一條直線來分割Class1和Class2
但是,如果變化一下feature space,就能重新分個,例如
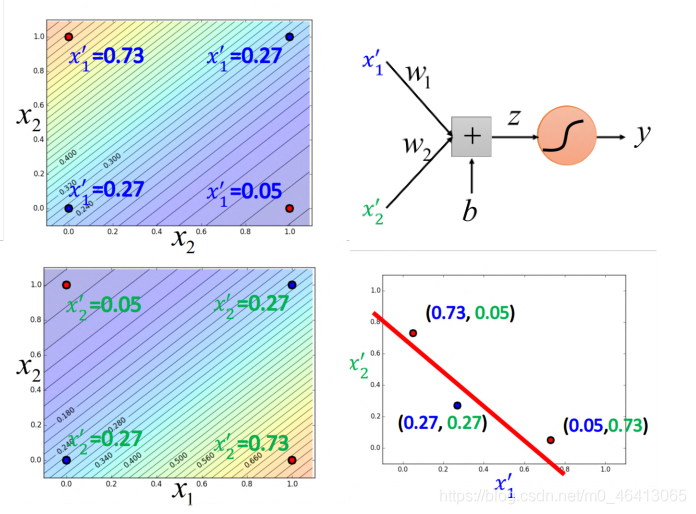
假設這?定義
x1’是原來的點到(0,0)之間的距離,x2’是原來的點到(1,1) 之間的距離,重新映射之后如下
圖右側(紅?兩個點重合),此時Logistic Regression就可以把它們劃分開來
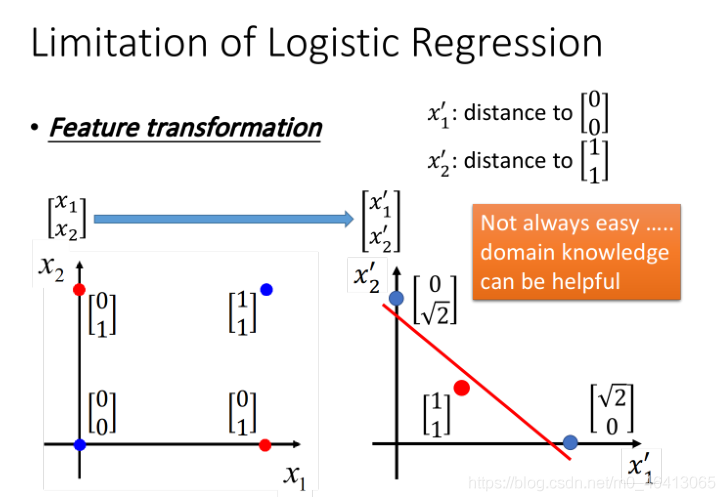
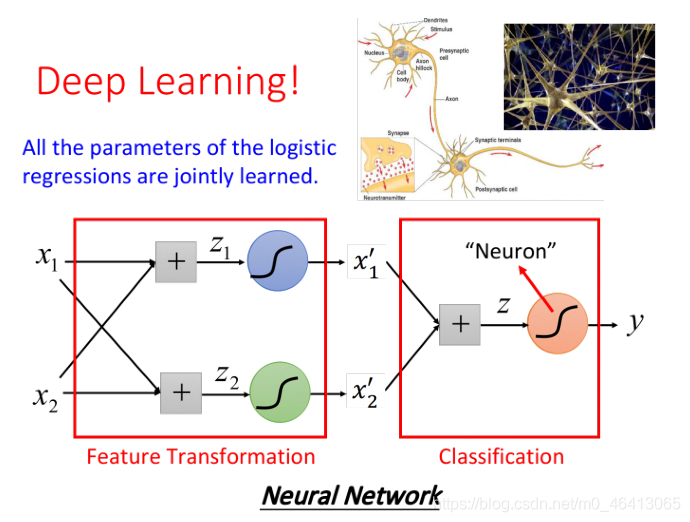
然而,我們人工找這樣的變換是十分困難的,我們需要用機器來找
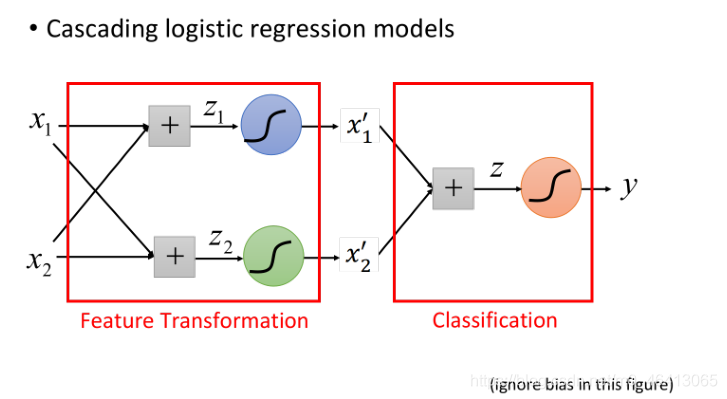
因此著整個流程是,先?n個Logistic Regression做feature Transformation(n為每個樣本點的feature數量),?成n個新的feature,然后再??個Logistic Regression作classifier
Logistic Regression的boundary?定是?條直線,它可以有任何的畫法,但肯定是按照某個?向從? 到低的等?線分布,具體的分布是由Logistic Regression的引數決定的,每?條直線都是由z=b+Σwixi組成的(?維feature的直線畫在?維平?上,多維feature的直線則是畫在多維空間上)
下圖是?維feature的例?,分別表?四個點經過transform之后的x1’和x2’ ,在新的feature space中可以通過最后的Logistic Regression劃分開來
Powerful Cascading Logistic Regression
通過上?的例?,我們發現,多個Logistic Regression連接起來會產?powerful的效果,我們把每?個
Logistic Regression叫做?個neuron(神經元),把這些Logistic Regression串起來所形成的network,就叫做Neural Network,就是類神經?路,這個東西就是Deep Learning!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/261849.html
標籤:AI