An infrared and visible image fusion method based on multi-scale transformation and norm optimization
- 引言
- 方法論
- 預融合影像的生成
- 基于MDLatLRR的影像分解
- 基礎層與細節層的影像融合
- 基礎層
- 細節層
- 逆變換
- 總結
- 對于紅外可見光影像融合的思考
論文:
An infrared and visible image fusion method based on multi-scale transformation and norm optimization
代碼:(如果覺得論文的思想對你們有幫助,請幫我點亮小星星哈哈哈):
LYJ/IVFusion
以下分為三大部分介紹這篇論文:
研究背景以及現存問題:論文的引言部分對當前紅外可見光影像融合研究現狀進行了詳細總結,相信對于剛接觸該方向的同學也可以起到綜述的作用,篇幅有限,在這里就不展開了,
方法論:介紹該融合演算法的步驟,就單純介紹,這一步不做討論,
總結:結合論文實驗部分討論其創新性,
引言
可見影像可以為計算機視覺任務提供最直觀的細節, 但是,由于資料收集環境的影響,可見影像可能無法突出顯示重要目標, 與可見影像不同,紅外影像可以根據熱輻射差異將目標與背景區分開,而不受照明和天氣條件的影響, 但是,紅外影像的局限性在于它們無法提供紋理細節, 因此,僅使用可見影像或紅外影像不能提供足夠的資訊來促進計算機視覺應用,例如各種環境中的目標檢測,識別和跟蹤, 為了解決這個問題,多種紅外和可見光影像融合方法被提出,
文章提出的演算法屬于多尺度變換與范數優化結合的混合演算法,多尺度變換將影像分解為基礎層與細節層,其中基礎層控制著影像目標背景整體對比度,細節層控制著影像中細節資訊,當前融合演算法在基礎層與細節層融合中存在以下問題:
第一:傳統的基礎層“權重分配”融合規則通常使融合影像在源影像中保留高像素強度的特征,而忽略全域對比度,導致融合影像無法在復雜場景(例如,汽車或路燈的夜間情況)中突出目標,
第二:對于細節層的常規融合策略旨在保留更多的源影像細節, 然而,并非所有可見光影像中的細節資訊都是有效的,特別是在復雜的場景中, 因此,通過從可見影像中包含更多細節來提高融合影像的質量并不總是有幫助的,
方法論
這張圖三個紅色部位分別是下面三個標題,
首先對紅外可見影像進行預處理得到預融合影像,接著將紅外影像、可見光影像與預融合影像經影像分解演算法MDLatLRR分解出基礎層與細節層,其中,來自預融合影像的基礎層作為最終融合影像的基礎層,來自紅外可見影像的細節層在預融合影像的協助下融合得到最終融合影像的細節層,
預融合影像的生成
預融合影像有兩個作用:
A:提高最終融合影像中目標與背景的對比度,
B:作為細節層融合中消除可見光影像無效細節資訊的參考,
具體來說,預融合處理可視作一個優化問題:由對比度保真項與梯度稀疏約束項構成:
對比度保真項:f表示預融合圖,Ir是紅外影像,
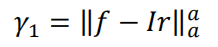
我們希望最終融合影像保留紅外影像的目標背景對比度,而不是直接跟紅外影像每個像素值一模一樣 (畢竟紅外影像并不符合人眼視覺感知嘛) ,也就是(f-Ir)大部磁區域不為0,但接近0,即我們認為(f-Ir)應當是高斯分布,采用的是L2范數,
梯度稀疏約束:
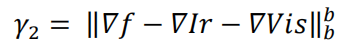
這一項是預融合影像梯度項,既考慮了紅外影像,也考慮了可見光影像,顯然,在νf-梯度分布上,我們當然希望是梯度可以一模一樣轉移到預融合影像中,也就是大部分值為0,本來用L0范數最直白了,但是L0范數是一個NP問題,所以采用L1范數來作為近似,
綜合起來:
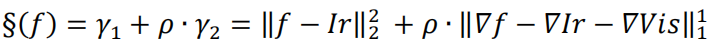
令 k = f - Ir - Vis,r = -Vis,u = 2·ρ,可得:f = k+Ir+Vis,如下形式: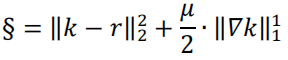
梯度可拆分為水平方向與垂直方向:
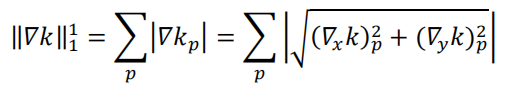
最后優化函式為:
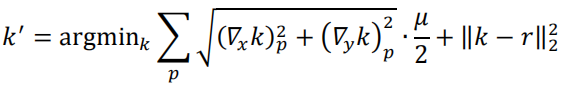
最后應用Split Bregman求該式子最小值k,可得到預融合影像f,
基于MDLatLRR的影像分解
論文中的影像分解演算法參考自論文:MDLatLRR、代碼來自:MDLatLRR
事實上,所謂將影像分解為高頻與低頻、基礎層與細節層的演算法,其實本質上都是拿濾波演算法來進行改造的,比如:導向濾波、最小二乘法濾波、雙邊濾波,
基于MDLatLRR的演算法本質上是利用影像的低秩性來分解影像,
秩的通俗理解:秩就是秩序,看到過別人舉的一個例子:一群人排隊,如果里面的人互相不認識,那么就不會讓對方插隊,此時該隊伍就井然有序 (秩序),這時我們就稱該隊伍的秩序比較好 (高秩),但是如果里面互相認識的人比較多,那么待會就會出現走后門、插隊的現象發生,此時的隊伍就亂成一鍋粥,秩序差,也就是低秩,
線性代數中的秩:表示矩陣行列之間的相關性,行列之間的相關性越高,秩越低,矩陣行或列之間就可以互相表示,引申到影像中,就是在說影像里面的像素結構彼此的相關程度,一幅影像往往是低秩或者近似低秩的,這是因為其中的影像資訊具有很大的相關性,所以一幅自然影像往往可以由其內部少部分資料表示 (這就是影像壓縮),但如果影像存在噪聲,那么存在隨機幅值任意大但是分布稀疏的誤差就會破壞了原有資料的低秩性,
下面的圖片來源于:低秩恢復演算法(影像去噪)

上面的LRR將影像中的噪聲E與低秩矩陣DZ分離,低秩矩陣DZ就是經過去噪的影像,基于MDLatLRR的影像分解演算法將上圖中式(13)改造成:多出來的L是顯著系數投影矩陣,即上圖的影像低秩矩陣DZ進一步被拆分為基礎部分和顯著部分,
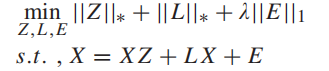
以上是對影像單個尺度進行分解,引申到多尺度變換中即分解多次,每一次以上一次尺度分解得到的基礎層為輸入,如下圖所示:
基礎層與細節層的影像融合
基礎層
基礎層來自預融合影像經MDLatLRR影像分解演算法所得的基礎層,
細節層
細節層的融合程序如下:
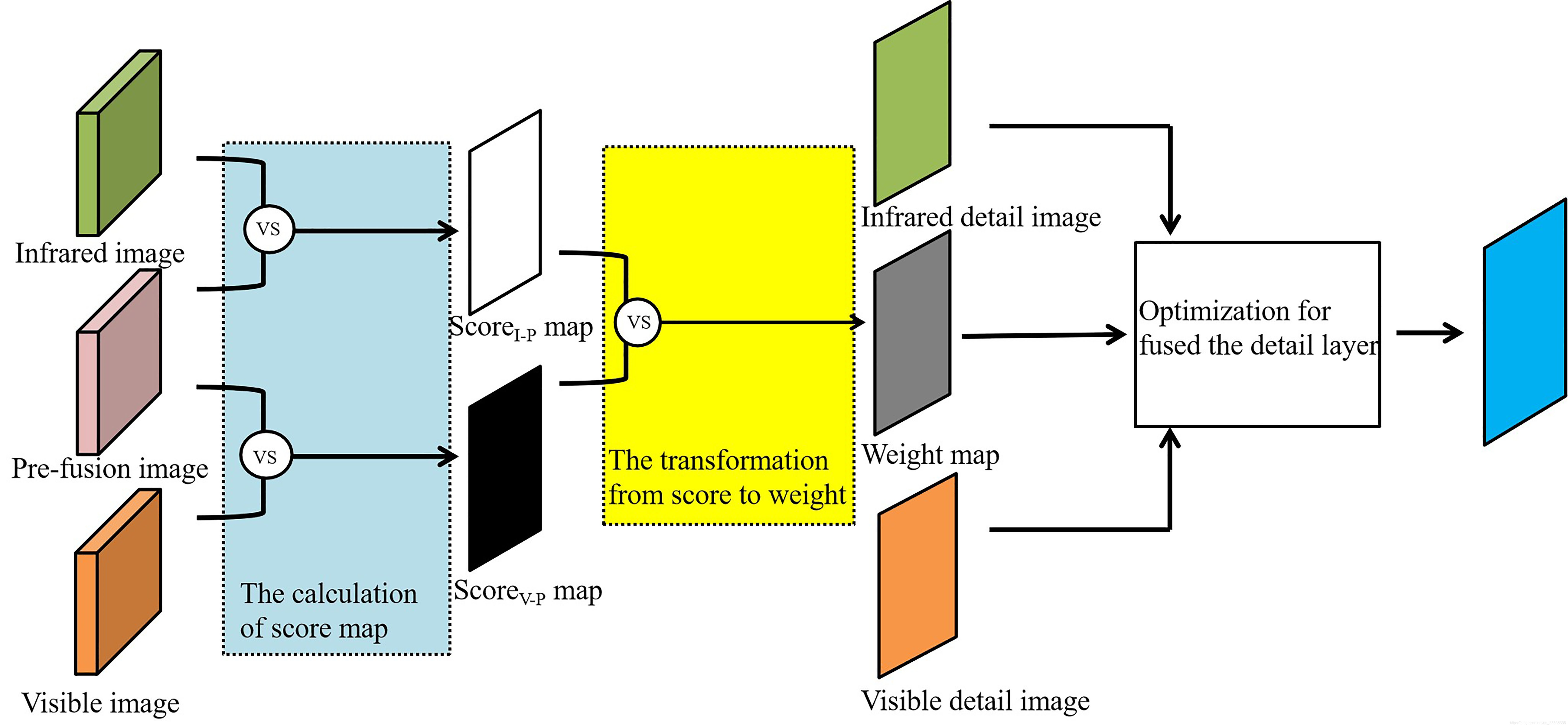
得分圖的生成:
對預融合影像與紅外影像、預融合影像與可見影像分別使用滑動視窗計算區域SSIM,得到Score(V-P) Map (可見與預融合影像)與Score(I-P) Map (紅外與預融合影像),
得分圖到權重圖的轉換:
得到的兩個得分圖再經由如下式子:
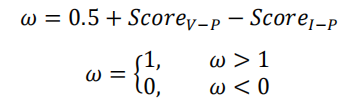
轉換為以下權重圖:

由于最終權重圖作用于可見影像細節層中,所以權重圖亮度越暗的位置代表著對應位置的可見影像細節資訊權重越低,可以明顯看到,不利于最終融合結果的可見光資訊權重被降低了,
用于細節層融合的優化演算法:
該優化程序旨在使可見光影像資訊有效的地方對應在融合細節層中傾向于可見光資訊,在紅外影像資訊有效的地方傾向紅外光資訊,設計出如下優化等式:
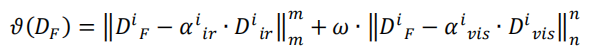
DF代表最終優化得到的融合細節層、Dir表示來自紅外影像的細節層、Dvis表示來自可見影像的細節層,既然對可見光影像細節層進行了過濾,難免會影響到有效的資訊,所以分別對紅外可見的細節資訊進行了增強,即加入增強系數αir與αvis,增強的思想是自適應區域均方差(公式見論文),ω為上一步得到的權重圖,同樣的,我們希望融合細節層在紅外與可見影像細節中取得一個平衡,即接近0,但不等于0,故采用的還是L2范數,
構建出上述式子后,首先證明其為凸函式,然后利用凸函式的性質: 區域最小值即為全域最小值,
這部分式子推導比較多,下面貼一下論文這部分的程序:

以上證明了優化函式為凸函式,以下求解最終優化結果:
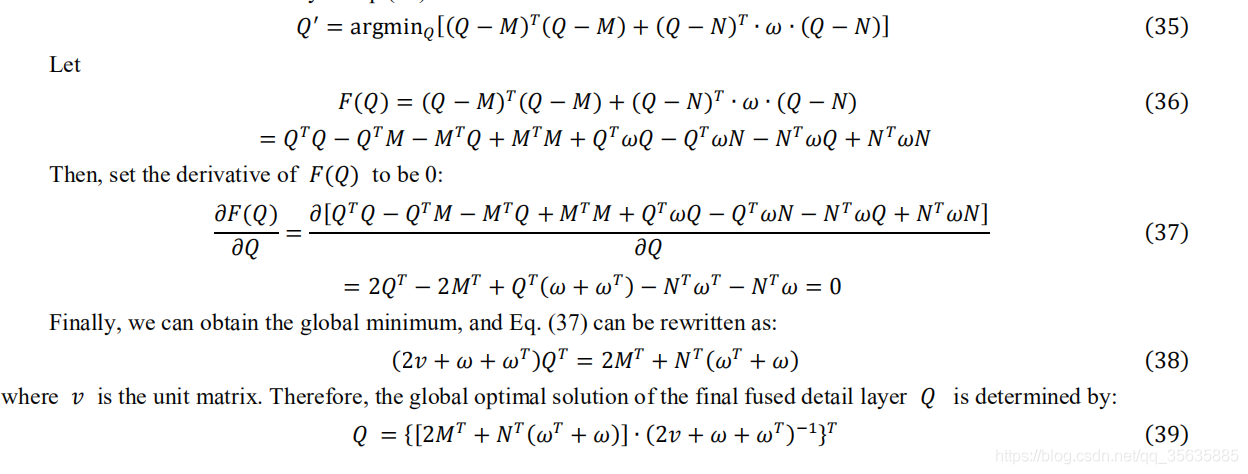
逆變換
與其他基于多尺度變換一樣,該論文的逆變換也只是簡單將細節層與基礎層的影像相加就行了,
B代表最終的融合基礎層base layer,也就是預融合影像經過4次分解所得到的
D代表最終的融合細節層detail layer,
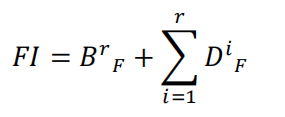
總結
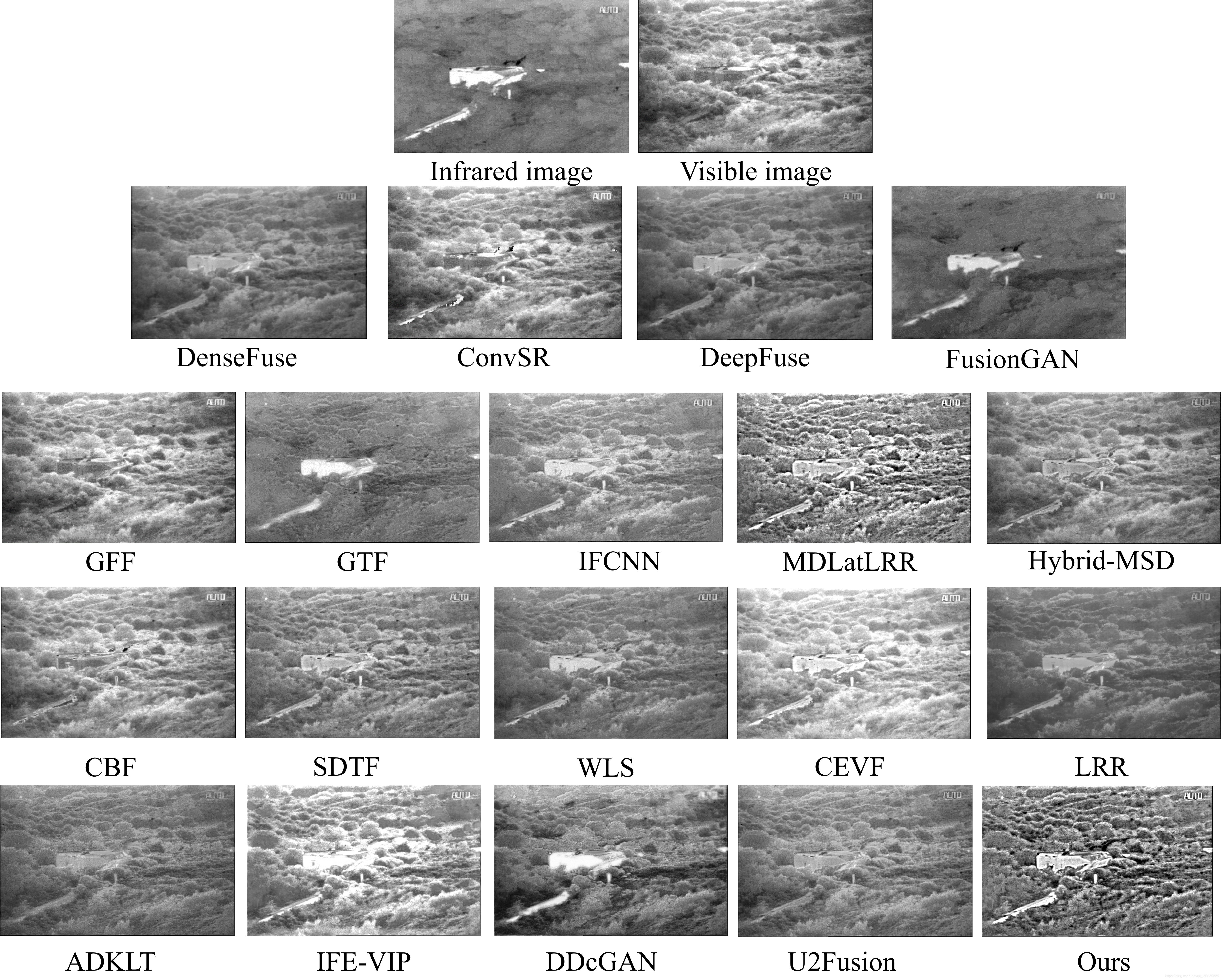
第一:這篇論文與其他論文最大的不同在于融合思想的轉變: 作者認為源影像的資訊并不全是有效資訊,不應該全部放到融合影像中,目前大多數融合論文追求的是融合影像應具有更多源影像的資訊,這可以從其采用的評價指標中看出 ,大多數為有參考影像評價指標(影像結構相似度SSIM、視覺資訊保真度VIF、互資訊MI等),但是紅外可見融合本來就是因為單獨的影像質量不好才需要融合的,我們采用的評價指標大多數為無參考評價指標,從實驗部分可以看出作者的這種思想是有效果的 (尤其對于強光),


第二:當前紅外與可見光影像融合的主流觀點是:
紅外光影像目標突出,但細節資訊不夠豐富,可見光影像細節資訊豐富,但目標不夠突出
對于目標突出
當前許多處理是分解紅外可見光影像得到兩個基礎層,然后通過設計權重分配函式,特別的,影像顯著性被引入到該領域中,但是對于可見光影像,顯著并不等于有效,沒錯,最典型的還是強光資訊,所以,既然紅外光影像能夠突出目標,而且是不受影響,是有效的,那我們直接將紅外影像中目標與背景的亮度比保留下來不就行了嗎???
對于細節資訊
可見光影像細節資訊雖然豐富,但由于環境的干擾,并非都是有效資訊,相反,紅外光影像細節資訊雖然不夠豐富,但反映的都是真實資訊,這可以為細節資訊的融合提供幫助,
所以基于上述兩點,作者就提出了兩階段融合策略:
第一階段:預融合,既保留紅外影像目標與背景的亮度比 ( 針對第一點) , 又加入了梯度稀疏約束 (針對第二點,由于紅外影像細節資訊較少,所以適當加入一些可見光影像細節資訊來彌補,引數ρ可用于調節所加入的可見光影像細節資訊的量),
第二階段:細節層融合,以預融合影像為基準,分別與紅外、可見影像進行區域SSIM評分,下圖可明顯看到強光部分在最后參與融合的權重極低,在最終融合結果中可以看到,強光資訊基本被消除,最后,我們再比較一下采用了同種影像分解演算法MDLatLRR,但不同融合規則的方法—MDLatLRR,以證明我們的兩階段融合策略是有效的,

對于紅外可見光影像融合的思考
當前該領域雖然出現了許多基于深度學習的融合方法,但基于深度學習的融合方法并沒有比傳統方法好多少,原因在于這是一個無監督任務,損失函式較難設計,
如若還想在這個方向繼續做下去,
我從個人看法提出如下幾個方向,權當拋磚引玉:
第一:損失函式的設計是一個挑戰,結合感知損失的IFCNN、結合SSIM的DenseFuse(這篇論文挺有趣的,使用COCO資料集訓練了一個可用于影像分解與重建的網路,然后在中間加入人工設計規則進行融合),
第二:從網路結構入手,比如2019年的對抗網路FusionGAN,2020年的雙對抗網路DDcGAN
第三:其實本文存在的缺點就是兩階段融合所使用的時間較長,時間花費主要在于區域SSIM的計算,也就是對可見光影像資訊有效性的評分,不知可否考慮轉化為基于深度學習的方法呢?即自己學習給可見影像資訊打分,在聯想得的遠一些,之前看到過一篇紅外可見融合來進行行人檢測的(Illumination-aware faster R-CNN for robust multispectral pedestrian
detection),其探究了低光跟強光場景下,紅外可見融合中哪個貢獻更大,
第四:模仿傳統演算法中的視覺顯著性,加入注意力模塊CBAM
還可以考慮一下分組卷積,顯著性檢測論文Deep Salient Object Detection With Contextual
Information Guidance中證明了分組卷積有利于突出重要目標,事實上確實是有道理的,傳統卷積將多通道特征組合在一起處理,可能會淹沒掉某些通道的特征,
第四:針對實際應用,紅外可見光融合之后進行分割、檢測,比如融合分割的MFNet與RTFNet
第五:也可以從評價指標入手,由于紅外可見影像融合不存在真實可對比的融合影像,有參考影像評價指標通常只取其中一方影像為參考或兩方取平均,可是我們正是因為源影像質量不好才需要融合的啊,所以也許我們可以改進一下評價指標,設計專門針對紅外可見影像融合的評價指標,
第六:影像分割演算法UNet網路結構采用了是4次下采樣,再上采樣恢復,但是UNet++作者通過做實驗得出結論,4次下采樣并不是對所有分割任務都有效,最后作者抓住這一點,設計了一個基于UNet的新網路,即讓對應網路自己學習對應任務,需要幾次下采樣,最后還可以有的分割任務還可以剪枝,引申到紅外可見融合尺度中,每次基于多尺度變換的傳統融合演算法,分解尺度總是固定的,大部分為4次分解,然后就開始對應融合了,而事實上并沒有誰證明了分解4次再融合就一定是最好的,所以,我們是不是也可以通過一些實驗,甚至可以結合深度學習,加入多種尺度,讓演算法針對不同場景的影像自適應找到一種合適的融合尺度呢?
Emmmm,就先暫時想到這里吧,有什么想法再給大家分享,
最后的最后,如果覺得本文不錯,那就來個:點贊、關注、收藏吧哈哈哈,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/262552.html
標籤:其他
下一篇:什么是金字塔原理?