“據不完全統計,90%的程式員在作業中使用Redis的時候只會用到string的資料型別”
上面的話當然是一句玩笑話,大家不必當真哈! (。?ˇ?ˇ?)
Redis目前在我們的作業當中已經是一個必不可少的工具了,面試的時候也已經成為面試官們的必考題,
接下來我會從Redis的資料型別出發,舉例講解每種資料型別在實際作業當中能具體都有哪些使用場景,也包含了一些騷操作,
觀前提醒:閱讀本文需要有一定的Redis基礎知識哦!
Redis的使用場景
- String
- Hash
- List
- Set
- sorted set
- bitmap
- BitMap是什么?
- 命令介紹
- 使用場景
- HyperLogLog
- 介紹
- 什么是基數?
- 使用場景:網頁的UV(Unique Visitor:獨立訪客)
- GEO
- 介紹
- 使用場景
- 總結
String
- 商品編號、訂單號使用incr命令自增
> set key 1
OK
> incr key
(integer) 2
> incr key
(integer) 3
> get key
"3"
- 文章瀏覽量
同上也可以使用incr命令 - 限流
實作限流功能,主要需要使用set key value ex 200 nx這個命令,這里value需要設定為整數,每次介面請求時,對value進行校驗,只要沒有達到限流閾值,那就對key進行incr,然后執行具體的業務代碼,命令如下:
#假設200秒內,只允許5次請求
#首先每次請求過來,先去獲取key
> get ratelimit
(nil)
#發現key不存在,則進行設定,value設定為1,代表請求了一次,ttl設定為100秒,本次請求通過,
> set ratelimit 1 ex 200 nx
OK
#又來了一個請求,同樣是先獲取key
> get ratelimit
"1"
#發現key存在,且value等于1,未達到5次限流閾值,然后對key操作自增,本次請求通過,
> incr ratelimit
(integer) 2
#后續操作原理同上,,,,
> get ratelimit
"2"
> incr ratelimit
(integer) 3
> get ratelimit
"3"
> incr ratelimit
(integer) 4
> get ratelimit
"4"
> incr ratelimit
(integer) 5
#這個時候,在200秒時間范圍內又來了一個請求,獲取key,發現value已經等于5,達到了限流閾值,本次請求攔截,
> get ratelimit
"5"
Hash
- 首先需要明確Redis中的hash就相當于是Java中的Map,并且是 Map<String,Map<Object,Object>> 這種形式的,因此可以用來物件
- 簡單版購物車功能
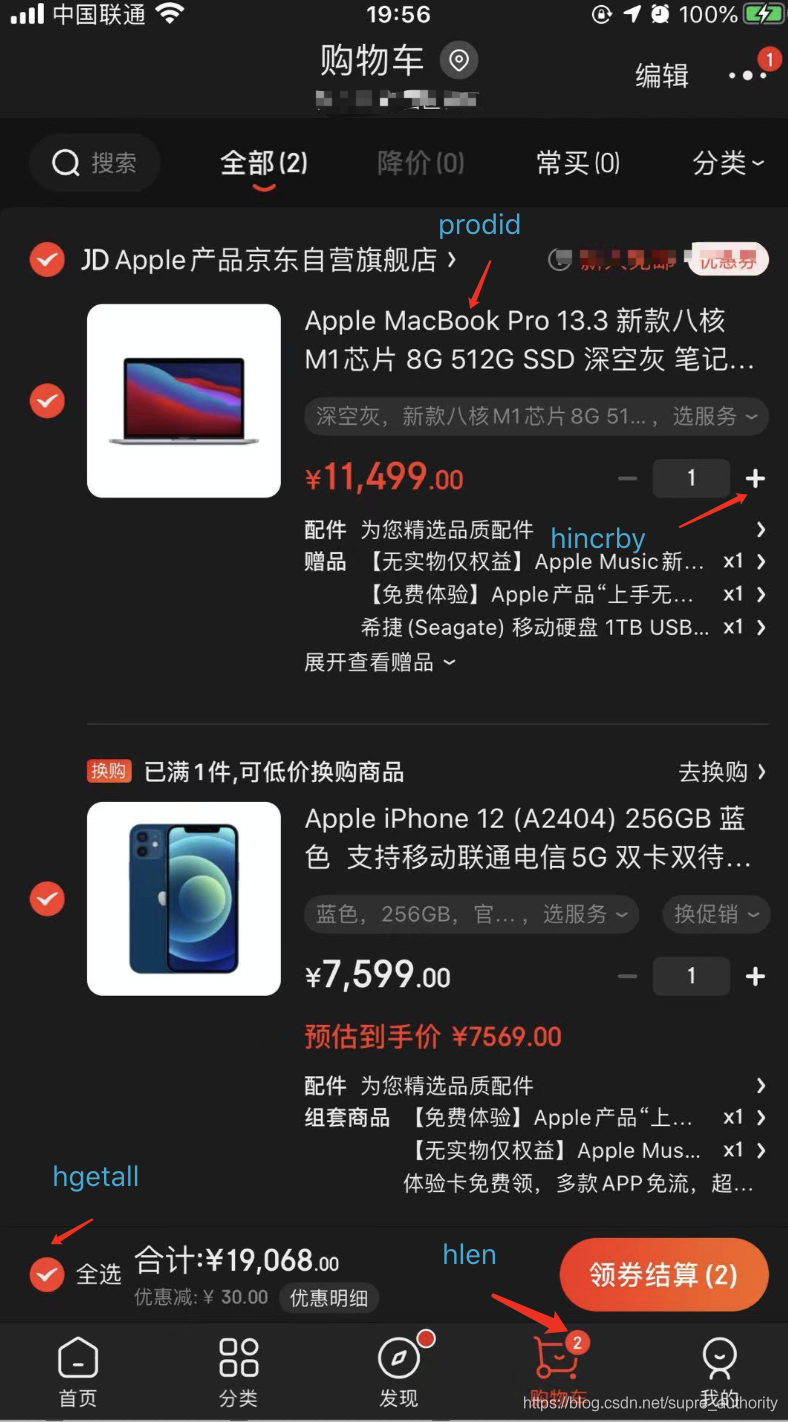
通過上圖,可以發現,通過幾個命令,就可以基本實作購物車的常用功能了,命令如下:
#給uid為9527的用戶添加商品1,數量為1件
> hset shopcar_uid9527 prodid_1 1
1
#給uid為9527的用戶添加商品2,數量為1件
> hset shopcar_uid9527 prodid_2 1
1
#用戶對商品2增加了購買數量
> hincrby shopcar_uid9527 prodid_2 3
(integer) 4
#用戶的購物車此時含有2種商品
> hlen shopcar_uid9527
2
#全選購物車中的所有商品,可以得到商品id及其對應的購買數量
> hgetall shopcar_uid9527
1) "prodid_1"
2) "1"
3) "prodid_2"
4) "4"
List
- 微信訂閱號文章
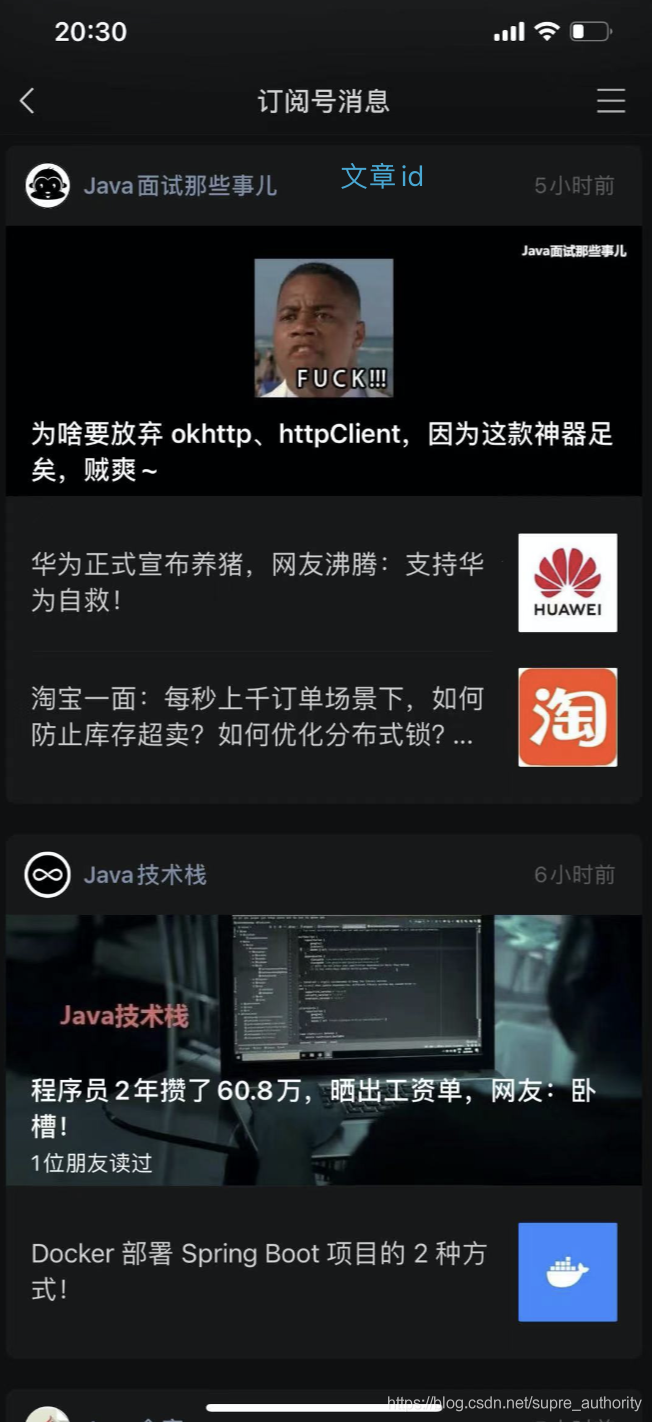
#給用戶推送一篇文章,id為789
> lpush uid_9527_likearticle 789
(integer) 1
#同上
> lpush uid_9527_likearticle 666
(integer) 2
#同上
> lpush uid_9527_likearticle 999
(integer) 3
#同上
> lpush uid_9527_likearticle 234234
(integer) 4
#同上
> lpush uid_9527_likearticle 888
(integer) 5
#展示用戶收到最新的3篇文章
> lrange uid_9527_likearticle 0 2
1) "888"
2) "234234"
3) "999"
- 限流
list實作可以實作類似令牌桶模式的限流功能,主要需要以下幾個步驟:
1) 定時任務:一直往list中push值,直到list的length達到設定的閾值
2)每次處理請求時,先使用pop命令彈出,如果成功則處理請求,否則就是觸發了限流
具體命令如下:
#統計一下目前桶中有多少令牌
> llen key
(integer) 0
#未達到桶的最大值,定時任務往桶中放入令牌
> lpush key 1
(integer) 1
> lpush key 1
(integer) 2
> lpush key 1
(integer) 3
#達到桶的最大值,定時任務停止放令牌
> llen key
(integer) 3
#每次請求,從桶中pop,成功則處理該請求
> rpop key
"1"
> rpop key
"1"
> rpop key
"1"
#pop失敗,達到限流閾值
> rpop key
(nil)
Set
- 抽獎
#往獎池中添加參與活動的用戶id
> sadd users1 111 222 333 444 555 666 777 888 999 12312 234 9527
(integer) 12
#抽取5名幸運用戶
> srandmember users1 5
1) "444"
2) "999"
3) "333"
4) "234"
5) "666"
srandmember命令用于回傳集合中的一個或多個隨機元素,但是不會移除其中的元素,如果要實作那種階梯式抽獎,已中獎的用戶不再參與抽獎的功能,可以使用spop命令
#往獎池中添加參與活動的用戶id,一共12名用戶
> sadd users2 111 222 333 444 555 666 777 888 999 12312 234 9527
(integer) 12
#抽取三等獎3名
> spop users2 3
1) "555"
2) "999"
3) "888"
#獎池里還剩9名用戶
> scard users2
9
#抽取二等獎2名
> spop users2 2
1) "12312"
2) "444"
#獎池里還剩7名用戶
> scard users2
7
#抽取一等獎1名
> spop users2 1
1) "111"
#獎池里還剩6名用戶
> scard users2
6
- 朋友圈點贊
#用戶22、33點贊了朋友圈
> sadd WechatMoments 22 33
(integer) 2
#用戶666點贊了朋友圈
> sadd WechatMoments 666
(integer) 1
#用戶33取消了點贊
> srem WechatMoments 33
1
#展示所有點贊的用戶
> smembers WechatMoments
1) "22"
2) "666"
#統計朋友圈點贊的數量
> scard WechatMoments
2
#判斷用戶22是否點贊了該朋友圈
> sismember WechatMoments 22
(integer) 1
#判斷用戶33是否點贊了該朋友圈
> sismember WechatMoments 33
(integer) 0
- 共同關注的人
#用戶u1關注了這些大V
> sadd u1 1 2 3 4 5 6
(integer) 6
#用戶u2關注了這些大V
> sadd u2 5 6 7 8 9
(integer) 5
#用戶u1、u2共同關注了如下大V
> sinter u1 u2
1) "5"
2) "6"
- 可能認識的人
#用戶u1有如下好友
> sadd u1 1 2 3 4 5 6
(integer) 6
#用戶u2有如下好友
> sadd u2 1 4 5 6 9 11
(integer) 6
#用戶u1、u2存在共同的好友
> sinter u1 u2
1) "1"
2) "4"
3) "5"
4) "6"
#那么用戶u1、u2可能有認識對方的一些好友
> sdiff u1 u2
1) "2"
2) "3"
> sdiff u2 u1
1) "9"
2) "11"
sorted set
- 排行榜(熱搜、VIP充值)
#用戶A、B、C等用戶分別充值了如下的金額
> zadd ranklist 100 A 200 B 300 C 444 D 234 E 35 F 534 G
(integer) 7
#此時充值排行榜的前三名分別是如下幾個用戶
> zrevrange ranklist 0 2 withscores
1) "G"
2) 534.0
3) "D"
4) 444.0
5) "C"
6) 300.0
#用戶B又充值了999.99元
> zincrby ranklist 999.99 B
1199.99
#充值排行榜的前三名就發生了變化
> zrevrange ranklist 0 2 withscores
1) "B"
2) 1199.99
3) "G"
4) 534.0
5) "D"
6) 444.0
#查看用戶C在排行榜中排名,注意下標從0開始,因此就是排在第四名
> zrank ranklist C
3
- 限流
zset要實作限流的功能,score可以設定成時間戳,然后通過統計一定時間范圍內的數量,來判斷是否達到了限流的閾值,程序比較復雜,我直接用代碼來展示:
/**
* @param redisKey redis限流功能的key
* @param timeLimit 時間限制范圍(毫秒)
* @param countLimit 數量限制
* @return
*/
public boolean tryAcquire(String redisKey, long timeLimit, int countLimit) {
Jedis jedis = new Jedis();
// 獲取當前時間
long nowTime = System.currentTimeMillis();
// 獲取時間限制范圍內的起始時間
long startTime = nowTime - timeLimit;
// 獲取該時間范圍內已經存在的成員數量
Long alreadyExistsCount = jedis.zcount(redisKey, startTime, nowTime);
if (alreadyExistsCount > countLimit) {
// 時間范圍內已經存在了超過限制的成員數量了,說明已經達到限流閾值了,
return false;
}
// 以UUID作為redis的value
String uuid = UUID.randomUUID().toString();
// 向zset中添加新成員
Long zadd = jedis.zadd(redisKey, nowTime, uuid);
if (zadd != 1) {
// 添加失敗
return false;
}
// 移除zset中除了本次時間范圍之外的所有成員資料
Long oldExistsCount = jedis.zcount(redisKey, 0, startTime);
if (oldExistsCount > 0) {
jedis.zremrangeByScore(redisKey, 0, startTime);
}
// 查詢剛才添加的成員在zset中的排名,此時因為已經移除了本次時間范圍之外的所有資料,因此rank不應超過限流數量
Long zrank = jedis.zrank(redisKey, uuid);
if (zrank > countLimit) {
// 排名超過了限流數量,則說明達到限流閾值了
// 主動移除剛才添加的成員
jedis.zrem(redisKey, uuid);
return false;
}
// 未達到限流閾值,回傳成功
return true;
}
以上就是Redis5大基本資料型別的使用場景了,接下來我介紹一下幾個不常見的型別,
bitmap
BitMap是什么?
就是通過一個bit位來表示某個元素對應的值或者狀態,其中的key就是對應元素本身,我們知道8個bit可以組成一個Byte,所以bitmap本身會極大的節省儲存空間,
命令介紹
指令 SETBIT key offset value
設定或者清空key的value(字串)在offset處的bit值(只能只0或者1),
使用場景
- 上班打卡、活動簽到
#作業日打卡功能
#第一個數字代表是星期幾,第二個數字代表是否打卡,其中0-未打卡,1-已打卡
> setbit sign 1 1
0
> setbit sign 2 1
0
> setbit sign 3 0
0
> setbit sign 4 0
0
> setbit sign 5 1
0
#查看星期一是否打卡:已打卡
> getbit sign 1
1
#查看星期三是否打卡:未打卡
> getbit sign 3
0
#統計一周打卡天數
> bitcount sign
3
- 統計活躍用戶數
#每天當用戶登錄時就設定一下
> setbit 2021_02_01 22 1
0
> setbit 2021_02_01 33 1
0
> setbit 2021_02_01 9527 1
0
> setbit 2021_02_02 9527 1
0
> setbit 2021_02_02 22 1
0
> setbit 2021_02_03 33 1
0
> setbit 2021_02_03 9527 1
0
#將這3天用戶登錄的資料“整合”
> bitop and ActiveUsers 2021_02_01 2021_02_02 2021_02_03
1191
#統計連續3天都登錄的用戶數量
> bitcount ActiveUsers
1
HyperLogLog
介紹
Redis HyperLogLog 是用來做基數統計的演算法,HyperLogLog 的優點是,在輸入元素的數量或者體積非常非常大時,計算基數所需的空間總是固定 的、并且是很小的,
在 Redis 里面,每個 HyperLogLog 鍵只需要花費 12 KB 記憶體,就可以計算接近 2^64 個不同元素的基 數,這和計算基數時,元素越多耗費記憶體就越多的集合形成鮮明對比,
但是,因為 HyperLogLog 只會根據輸入元素來計算基數,而不會儲存輸入元素本身,所以 HyperLogLog 不能像集合那樣,回傳輸入的各個元素,
什么是基數?
比如資料集 {1, 3, 5, 7, 5, 7, 8}, 那么這個資料集的基數集為 {1, 3, 5 ,7, 8}, 基數(不重復元素)為5,
使用場景:網頁的UV(Unique Visitor:獨立訪客)
傳統的方式,可以使用set保存用戶的id,然后可以統計set中的元素數量作為判斷標準,
但是,這個方式如果保存了大量的用戶id,則會占用大量的記憶體空間,比較浪費,我們的目的就是為了計數,而不是保存用戶的id,
代碼示例:
#用戶每次訪問網頁,記錄一下
> pfadd visit1 a
(integer) true
> pfadd visit1 b
(integer) true
> pfadd visit1 c
(integer) true
> pfadd visit1 d
(integer) true
> pfadd visit1 b
(integer) false
#統計“visit1”網頁總共的UV
> pfcount visit1
(integer) 4
#記錄另一個網頁的訪問資訊
> pfadd visit2 c
(integer) true
> pfadd visit2 a
(integer) true
> pfadd visit2 x
(integer) true
> pfadd visit2 y
(integer) true
> pfadd visit2 z
(integer) true
> pfcount visit2
(integer) 5
#將多個HyperLogLog合并為一個HyperLogLog
> pfmerge total visit1 visit2
(integer) 1
#統計出整個網站的UV
> pfcount total
(integer) 7
注意:如果資料量比較大的話,HyperLogLog統計可能會存在一點誤差,大概是0.81%,但是針對UV統計這種場景的話,完全是可以忽略不計的,
GEO
介紹
GEO 主要用于存盤地理位置資訊,并對存盤的資訊進行操作,該功能在 Redis 3.2 版本新增,
GEO 操作方法有:
- geoadd:添加地理位置的坐標,
- geopos:獲取地理位置的坐標,
- geodist:計算兩個位置之間的距離,
- georadius:根據用戶給定的經緯度坐標來獲取指定范圍內的地理位置集合,
- georadiusbymember:根據儲存在位置集合里面的某個地點獲取指定范圍內的地理位置集合,
- geohash:回傳一個或多個位置物件的 geohash 值,
使用場景
看了上面的介紹,相信很多同學都已經能夠想象出GEO能實作哪些功能了,比如常見的定位、附近的人、兩地之間的距離等等,這些功能都可以使用GEO來實作,
代碼如下:
- 錄入、獲取城市的地理位置資訊(緯度、經度、名稱)
注意:
該命令以采用標準格式的引數x,y,所以經度必須在緯度之前,這些坐標的限制是可以被編入索引的,區域面積可以很接近極點但是不能索引,具體的限制,由EPSG:900913 / EPSG:3785 / OSGEO:41001 規定如下:
- 有效的經度從-180度到180度,
- 有效的緯度從-85.05112878度到85.05112878度,
當坐標位置超出上述指定范圍時,該命令將會回傳一個錯誤,
#添加一些城市的地理位置資訊
127.0.0.1:6379> geoadd city 116.397128 39.916527 beijing
(integer) 1
127.0.0.1:6379> geoadd city 121.48941 31.40527 shanghai
(integer) 1
127.0.0.1:6379> geoadd city 106.54041 29.40268 chongqing
(integer) 1
127.0.0.1:6379> geoadd city 118.8921 31.32751 nanjing
(integer) 1
#獲取城市的地理位置資訊
127.0.0.1:6379> geopos city shanghai
1) 1) "121.48941010236740112"
2) "31.40526993848380499"
- 查看兩地之間的距離
127.0.0.1:6379> geodist city shanghai beijing
"1052105.5643"
#查找上海和北京之間的直線距離,單位:KM,大家可以百度一下,差不多很接近了,
127.0.0.1:6379> geodist city shanghai beijing km
"1052.1056"
- 查看附近的人
#獲得附近人的地址,通過半徑倆查詢,這里就以城市為例了
# 121 31 是我目前大致的經緯度資訊,可以看到100km范圍內的城市只有上海
127.0.0.1:6379> georadius city 121 31 100 km
1) "shanghai"
#把半徑擴大到500km時,城市就包括了上海和南京
127.0.0.1:6379> georadius city 121 31 500 km
1) "nanjing"
2) "shanghai"
#再擴大范圍,查詢出來的城市就更多了
127.0.0.1:6379> georadius city 121 31 50000 km withcoord withdist
1) 1) "chongqing"
2) "1400.2709"
3) 1) "106.54040783643722534"
2) "29.40268053517299762"
2) 1) "nanjing"
2) "203.8973"
3) 1) "118.89209836721420288"
2) "31.32750976275760735"
3) 1) "shanghai"
2) "64.8057"
3) 1) "121.48941010236740112"
2) "31.40526993848380499"
4) 1) "beijing"
2) "1075.4316"
3) 1) "116.39712899923324585"
2) "39.91652647362980844"
#如果說附近的人很多時,可以使用“count”回傳指定數量的結果集
georadius city 121 31 50000 km withcoord withdist count 1
1) 1) "shanghai"
2) "64.8057"
3) 1) "121.48941010236740112"
2) "31.40526993848380499"
- 找出位于指定元素周圍的其他元素
127.0.0.1:6379> georadiusbymember city shanghai 300 km
1) "nanjing"
2) "shanghai"
- 其他
GEO底層其實是由zset實作的,所以也可以使用zset的相關命令
#查看地圖中全部元素
127.0.0.1:6379> zrange city 0 -1
1) "chongqing"
2) "nanjing"
3) "shanghai"
4) "beijing"
#移除某個地址資訊
127.0.0.1:6379> zrem city nanjing
(integer) 1
127.0.0.1:6379> zrange city 0 -1
1) "chongqing"
2) "shanghai"
3) "beijing"
總結
經過上面的講解,相信大家對Redis的使用場景都有了一個更深刻的理解了,回到文章開頭的那句玩笑話,為什么絕大多數人都只是使用string的set key value呢?其實還是了解的少了,光看Redis的那些命令,是蒼白空洞的,只有跟實際業務聯系起來,才能真正發揮Redis的優勢,
當然,你也完全沒有必要把上面的命令全部記住,包括在面試中,面試官并不會過于關心命令的準確性,還是看重你會用來做些什么事情,具體命令隨時查看檔案就可以了,
我列出的這些場景還是一小部分,大家受到啟發后可以擴展,也歡迎在評論區留言,謝謝大家啦!O(∩_∩)O哈哈~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/263422.html
標籤:其他