什么是ElasticSearch
ElasticSearch是一個基于Lucene的搜索服務器,它提供了一個分布式多用戶能力的全文搜索引擎,提供基于Restful標準的API介面,
ElasticSearch基于Java實作,是當前最流行的企業級搜索引擎,設計用于云計算中,能夠達到實時搜索,穩定,可靠,快速,安裝使用方便,
ElasticSearch不僅能對海量規模的資料完成分布式索引與檢索,還能提供資料聚合分析功能,
優點
- 速度快,近實時查詢
- 索引和檢索資料量大,支持TB級資料
- 高擴展,高可用
基本概念
| 關系資料庫 | ES |
| 資料庫Database | 索引Index |
| 表Table | 型別Type |
| 資料行Row | 檔案Document |
| 資料列Column | 欄位Field |
| 表結構Schema | 映射Mapping |
接近實時(NRT)
ES是一個接近實時的搜索平臺,這意味著從索引一個檔案到這個檔案能夠被搜索到有一個很小的延遲(通常不到1s),
索引(index)
ES將它的資料存盤在一個或多個索引(index)中,索引就像資料庫,可以向索引寫入檔案或者從索引讀取檔案,并通過ES內部使用Lucene寫入索引或檢索索引,
檔案(document)
檔案(document)是ES中的主要物體,ES的搜索最終可以歸結為對檔案的搜索,檔案由欄位構成,
映射(mapping)
所有檔案寫入索引之前都會進行分析,如何將輸入的文本分割為詞條,哪些詞潭訓被過濾,這種行為叫做映射(mapping),一般由用戶自定義規則,
型別(type)
每個檔案都有與之對應的型別(type)定義,這允許用戶在一個索引中存盤多種檔案型別,并為不同檔案提供不同的映射,
資料源(river)
代表ES的一個資料源,也是其他存盤方式(如資料庫)同步資料到ES的一個方法,它是以插件方式存在的一個服務,通過讀取river中的資料并將它索引到ES中,官方提供的River有couchDB、RabbitMQ等等,
網關(gateway)
代表ES索引的持久化存盤方式,ES默認是先把索引寫入記憶體,當記憶體滿了再持久化到硬碟,當這個ES集群關閉再重啟時,就會從網關中讀取索引資料,ES支持多種型別的Gateway,有本地檔案系統(默認)、分布式檔案系統、Hadoop的HDFS、amazon的s3服務等,
自動發現(discovery.zen)
代表ES的自動發現節點機制,ES是一個基于p2p的系統,它先通過廣播尋找存在的節點,再通過多播協議來進行節點之間的通訊,同時也支持點對點的互動,
通信(transport)
代表ES內部節點或集群與客戶端的互動方式,默認內部是使用tcp協議互動,同時也支持http協議(json格式)、thrift、servlet、memcached、zeroMQ等傳輸協議(通過插件集成),
節點見通信埠默認:9300-9400
集群(cluster)
代表一個集群,集群中有多個節點(node),其中一個為主節點,這個主節點是可以通過選舉產生的,主從節點是對于集群內部來說的,
ES的一個概念就是去中心化,字面理解就是無中心節點,這是對于集群外部來說的,從外部來看ES集群,在邏輯上是一個整體,任何一個節點的通信都是等價的,
分片(shards)
代表索引分片,ES可以把一個完整的索引分為多個分片,這樣的好處是可以把一個大的索引拆分成多個,分布到不同的節點上,構成分布式索引,分片的數量只能在索引創建前指定,并且索引創建后不能更改,
副本(replicas)
代表索引副本,ES可以設定多個索引的副本,副本可以提供系統的容錯性,當某個節點某個分片損壞或丟失時可以從副本中恢復,副本也可以提高ES的查詢效率,ES會自動對搜索請求進行負載均衡,
資料恢復(recovery)
也叫資料重新分布,ES在有節點加入或退出時會根據機器的負載對索引分片進行重新分配,掛掉的節點重新啟動也會進行資料恢復,
GET /_cat/health?v #可以看到集群狀態
分片和復制(shards and replicas)
一個索引可以存盤超過單個節點硬體限制的大量資料,為了解決這個問題,ES提供了將索引劃分成多片的能力,這些片叫分片,當你創建一個索引時,你可以指定想要的分片數量,每個分片本身也是一個功能完善且獨立的索引,這個索引可以被放置到集群中的任何節點上,
分片的出現允許水平分割/擴展內容容量,允許在分片之上進行分布式的并行的操作,進而提高系統的性能吞吐量,
ES允許創建分片的一份或多份拷貝,作為故障轉移機制的一部分,這些拷貝叫做復制分片,或者直接叫復制,
復制提高了系統的可用性,同時搜索也可以在復制上進行,可以擴展系統的搜索量/吞吐量,
每個索引可以被分成多個分片,一個索引也可以被復制多份,
分片和復制的數量可以在索引創建時指定,在索引創建之后,可以動態地改變復制的數量,但是不能改變分片的數量,
安裝配置
解壓,進入bin目錄,可以看到啟動腳本
運行啟動

可以看到系結了兩個埠:
- 9300:Java程式訪問的埠
- 9200:瀏覽器、postman訪問的埠
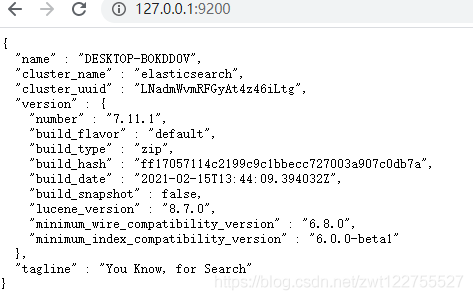
訪問:http://127.0.0.1:9200
安裝ik分詞器
下載插件:https://github.com/medcl/elasticsearch-analysis-ik/releases ,Elasticsearch和IK分詞器必須版本一致,
直接解壓放到\plugins目錄,
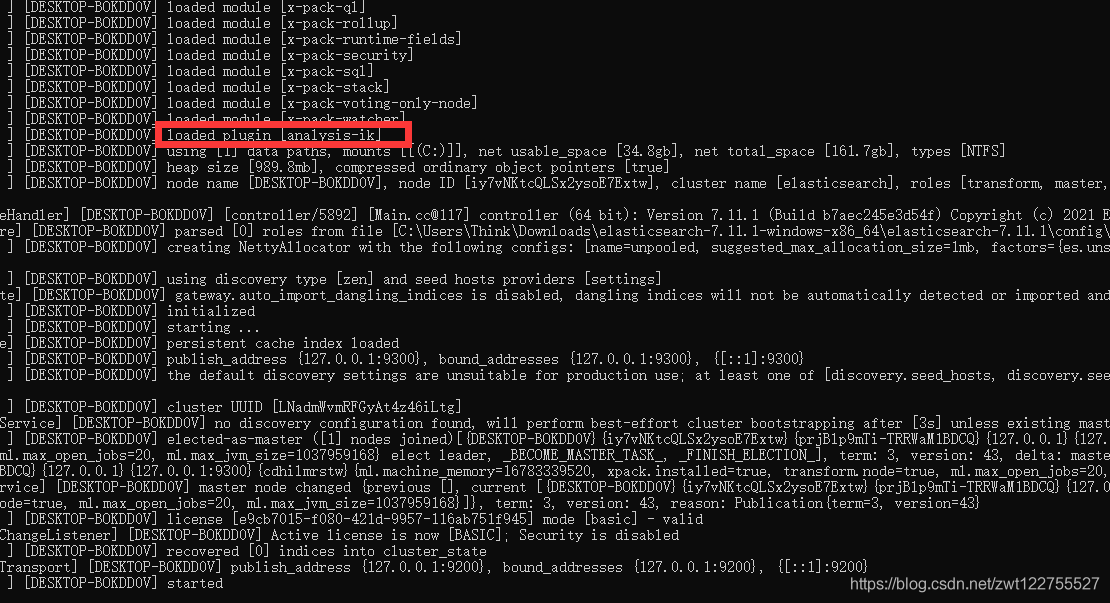
啟動ES,可以看到加載的插件
elasticsearch.yml檔案
# 集群名稱
cluster.name: es-demo
# 節點名稱
node.name: node-1
# 既可以選舉為主節點,也可以存盤資料,也可作為負載器
node.master: true
node.data: true
# 資料存盤地址
path.data: /opt/apps/es/data
# 日志
path.logs: /opt/apps/es/logs
# 臨時檔案
path.work: /opt/apps/es/tmp
# 索引分片數,默認5片
index.number_of_shards: 3
# 索引副本數,默認1個
index.number_of_replicas: 2
# 啟動時鎖住記憶體,保證不會swap
bootstrap.memory_lock: true
bootstrap.system_call_filter: false
# 系結的ip地址
network.host: 0.0.0.0
# 參與集群的埠
transport.tcp.port: 9300
# http埠號
http.port: 9200
# 內容的最大容量
http.max_content_length: 100mb
# Discovery配置
discovery.zen.ping_timeout: 30s
# 防止集群發生腦裂
discovery.zen.minimun_master_nodes: 2
discovery.zen.fd.ping_timeout: 30s
# 單播發現地址
discovery.zen.ping.unicast.hosts: ["192.168.1.100:9300", "192.168.1.101:9300", "192.168.1.102:9300"]
# discovery.zen.ping.multicast.enabled: false
# 最多等待5分鐘,如果沒有上線就重新rebalance
gateway.recover_after_time: 5m
# 3個節點上線后,才會進行shard recovery
gateway.recover_after_nodes: 3
# 最小節點數量
gateway.expected_nodes: 3
# 洗掉索引庫必須顯示指定,禁止洗掉所有索引,推薦生產環境使用
action.destructive_requires_name: true
# cors配置
http.cors.enabled: true
http.cors.allow-origin: "*"
集群原理
ES集群包括三種角色,
master節點
整個集群只會有一個master節點,負責維護集群狀態資訊(元資料metadata),可以存盤資料,但是不建議用master節點來存盤索引資料,master節點需要從眾多可以成為master的節點中選舉產生一個,
- 負責集群節點的上下線,shard分配的重新分配,
- 創建、洗掉索引,
- 負責接收集群狀態的變化,并推送給所有節點,每個節點都有一份完整的cluster state,只是master節點負責維護,
- 利用自身空閑資源,協調創建索引的請求或查詢請求,并分發到其他節點,
配置
node.master: true
node.data: falsedata節點
負責索引資料的存盤和讀寫,data節點消耗記憶體和磁盤IO的性能較大,
配置
node.master: false
node.data: trueclient節點(負載均衡節點)
不會被選為master節點,也不會存盤索引資料,主要用于查詢負載均衡,將請求分發給多個node節點,并對結果進行匯總,
配置
node.master: false
node.data: false集群搭建規劃
記憶體
ES很占記憶體,JVM占用的比較小,主要是Lucene,Lucene基于OS檔案系統快取,將頻繁的讀寫磁盤檔案到記憶體進行快取以提高性能,所以需要足夠的記憶體支持,
資料量:上億建議每臺機器64G記憶體,
CPU
ES集群對CPU要求比較低,核心數可以提高并發能力,一般多核即可,
磁盤
需要頻繁讀寫磁盤,推薦SSD或RAID,
網路
ES集群是p2p模式的分布式架構,所有node都是相當的,任意兩個node之間的互相通信都會很頻繁,因此要避免異地多機房,保證低延遲+高速,
JVM
保證所有環境JDK版本一致,防止client和server由于版本不一致,出現序列化問題,盡量使用最新版本,
容量規劃
建議資料在10億以內,資料量最好恒定,
先計算資料硬碟容量,總記憶體數,ES會用一半給到JVM,剩下的一半,硬碟容量 * 1.5 就足夠了,一般10億數量,5臺左右8核64G足夠,如何查詢太復雜,則需要加記憶體,
Java實戰
搜索操作Demo
public class SearchDemo {
private TransportClient client;
@Before
public void init() throws Exception {
// 1. 指定ES集群
Settings settings = Settings.builder().put("cluster.name", "es—demo").build();
// 2. 創建訪問ES服務器的客戶端
client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.1.100"), 9300));
}
@Test
public void testSearchIndex() {
try {
// 3. 資料查詢展示
GetResponse response = client.prepareGet("index1", "blog", "10").execute().actionGet();
String sourceAsString = response.getSourceAsString();
System.out.println(sourceAsString);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 批量MultiGet
*/
@Test
public void testMultiGet() {
try {
// 3. 查詢 按索引 型別和id 回傳的是陣列
MultiGetResponse response = client.prepareMultiGet().add("index", "blog", "8", "10")
.add("lib", "user", "1", "2", "3").get();
// 4. 遍歷輸出一下
for (MultiGetItemResponse item : response) {
GetResponse gr = item.getResponse();
if (gr != null && gr.isExists()) {
System.out.println(gr.getSourceAsString());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 批量 - bulk
*/
@Test
public void testBulk() {
try {
BulkRequestBuilder builder = client.prepareBulk();
// 批量添加
builder.add(client.prepareIndex("lib2", "books", "8").setSource(XContentFactory.jsonBuilder().startObject()
.field("title", "python").field("price", 99).endObject()));
builder.add(client.prepareIndex("lib2", "books", "8").setSource(
XContentFactory.jsonBuilder().startObject().field("title", "VR").field("price", 199).endObject()));
// 執行操作
BulkResponse response = builder.get();
// 查看狀態
System.out.println(response.status());
// 查看是否有失敗情況
if (response.hasFailures()) {
System.out.println("error");
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 查詢全部 matchAllQuery
*/
@Test
public void testMatchAllQuery() {
try {
QueryBuilder qb = QueryBuilders.matchAllQuery();
SearchResponse sr = client.prepareSearch("index1").setQuery(qb).setSize(3).get();
SearchHits hits = sr.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Map<String, Object> map = hit.getSourceAsMap();
for (Object key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 查詢 match
*/
@Test
public void testMatchQuery() {
try {
QueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "搜索");
SearchResponse response = client.prepareSearch("index1").setQuery(queryBuilder).setSize(3).get();
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Map<String, Object> map = hit.getSourceAsMap();
for (Object key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 查詢 multiMatch
*/
@Test
public void testMultiMatchQuery() {
try {
QueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("搜索", "title", "content");
SearchResponse response = client.prepareSearch("index1").setQuery(queryBuilder).setSize(3).get();
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Map<String, Object> map = hit.getSourceAsMap();
for (Object key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* term查詢
*/
@Test
public void testTermQuery() {
try {
QueryBuilder queryBuilder = QueryBuilders.termQuery("content", "搜索");
SearchResponse response = client.prepareSearch("index1").setQuery(queryBuilder).setSize(3).get();
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Map<String, Object> map = hit.getSourceAsMap();
for (Object key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* terms 查詢
*/
@Test
public void testTermsQuery() {
try {
QueryBuilder queryBuilder = QueryBuilders.termsQuery("content", "搜索", "功能");
SearchResponse response = client.prepareSearch("index1").setQuery(queryBuilder).setSize(3).get();
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Map<String, Object> map = hit.getSourceAsMap();
for (Object key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* range prefix wildcard fuzzy ids 查詢
*/
@Test
public void test14() {
try {
// range 查詢
// QueryBuilder queryBuilder=
// QueryBuilders.rangeQuery("postdate").from("2021-01-01").to("2021-03-01").format("yyyy-MM-dd");
// prefix 查詢
// QueryBuilder queryBuilder= QueryBuilders.prefixQuery("title", "搜索");
// whildcard 查詢
// QueryBuilder queryBuilder= QueryBuilders.wildcardQuery("content", "在*");
// fuzzy 查詢
// QueryBuilder queryBuilder= QueryBuilders.fuzzyQuery("content", "solr");
// ids 查詢
QueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("8", "10");
SearchResponse response = client.prepareSearch("index1").setQuery(queryBuilder).setSize(3).get();
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Map<String, Object> map = hit.getSourceAsMap();
for (Object key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 聚合查詢
*/
@Test
public void test15() {
try {
// 最大值
// AggregationBuilder agg = AggregationBuilders.max("aggMax").field("postdate");
// SearchResponse response =
// client.prepareSearch("index1").addAggregation(agg).get();
// Max max = response.getAggregations().get("aggMax");
// System.out.println(max.getValue());
// 最小值
// AggregationBuilder agg = AggregationBuilders.min("aggMin").field("postdate");
// SearchResponse response =
// client.prepareSearch("index1").addAggregation(agg).get();
// Min min = response.getAggregations().get("aggMin");
// System.out.println(min.getValue());
// 平均值
// AggregationBuilder agg = AggregationBuilders.avg("aggAvg").field("postdate");
// SearchResponse response =
// client.prepareSearch("index1").addAggregation(agg).get();
// Avg avg = response.getAggregations().get("aggAvg");
// System.out.println(avg.getValue());
// 基數
AggregationBuilder agg = AggregationBuilders.cardinality("aggCardinality").field("postdate");
SearchResponse response = client.prepareSearch("index1").addAggregation(agg).get();
Cardinality cardinality = response.getAggregations().get("aggCardinality");
System.out.println(cardinality.getValue());
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* query string
*
*/
@Test
public void test16() {
try {
// 全文檢索(部分條件都滿足即可) + 必須有 - 必須沒有
QueryBuilder queryBuilder = QueryBuilders.simpleQueryStringQuery("+搜索 -ES");
SearchResponse response = client.prepareSearch("index1").setQuery(queryBuilder).setSize(3).get();
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Map<String, Object> map = hit.getSourceAsMap();
for (Object key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 組合查詢
*
* boolQuery must 必須有 mustNot 必須沒有 should 或者 filter 過濾 constantscore
*
*/
@Test
public void test17() {
try {
// constantscore
QueryBuilder queryBuilder = QueryBuilders.constantScoreQuery(QueryBuilders.termQuery("name", "hah"));
SearchResponse response = client.prepareSearch("index1").setQuery(queryBuilder).setSize(3).get();
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Map<String, Object> map = hit.getSourceAsMap();
for (Object key : map.keySet()) {
System.out.println(key + " = " + map.get(key));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 分組聚合
*/
@Test
public void testterms() {
try {
AggregationBuilder agg = AggregationBuilders.terms("terms").field("age");
SearchResponse response = client.prepareSearch("index1").addAggregation(agg).execute().get();
Terms terms = response.getAggregations().get("terms");
for (Terms.Bucket entry : terms.getBuckets()) {
System.out.println(entry.getKey() + ": " + entry.getDocCount());
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* filter聚合
*/
@Test
public void testfilter() {
try {
QueryBuilder query = QueryBuilders.termQuery("filter", "搜索");
AggregationBuilder agg = AggregationBuilders.filter("filter", query);
SearchResponse response = client.prepareSearch("index1").addAggregation(agg).execute().get();
Filter filter = response.getAggregations().get("filter");
System.out.println(filter.getDocCount());
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* filters聚合
*/
@Test
public void testfilters() {
try {
// QueryBuilder query = QueryBuilders.termQuery("filters", "搜索");
AggregationBuilder agg = AggregationBuilders.filters("filters",
new FiltersAggregator.KeyedFilter("changge", QueryBuilders.termQuery("content", "change")),
new FiltersAggregator.KeyedFilter("hejiu", QueryBuilders.termQuery("content", "hejiu")));
SearchResponse response = client.prepareSearch("index1").addAggregation(agg).execute().get();
Filters filters = response.getAggregations().get("filters");
for (Filters.Bucket entry : filters.getBuckets()) {
System.out.println(entry.getKey() + ": " + entry.getDocCount());
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* range聚合
*/
@Test
public void testrange() {
try {
AggregationBuilder agg = AggregationBuilders.range("range").field("age").addUnboundedTo(50)// (,to)
.addRange(20, 50)// [form,)
.addUnboundedFrom(25);
SearchResponse response = client.prepareSearch("index1").addAggregation(agg).execute().get();
Range range = response.getAggregations().get("range");
for (Range.Bucket entry : range.getBuckets()) {
System.out.println(entry.getKey() + ": " + entry.getDocCount());
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* missing聚合
*/
@Test
public void testmissing() {
try {
AggregationBuilder agg = AggregationBuilders.missing("missing").field("age");
SearchResponse response = client.prepareSearch("index1").addAggregation(agg).execute().get();
Aggregation aggregation = response.getAggregations().get("missing");
System.out.println(aggregation.toString());
} catch (Exception e) {
e.printStackTrace();
}
}
}索引操作Demo
public class IndexDemo {
private TransportClient client;
@Before
public void init() throws Exception {
// 1. 指定ES集群
Settings settings = Settings.builder().put("cluster.name", "es—demo").build();
// 2. 創建訪問ES服務器的客戶端
client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.1.100"), 9300));
}
@Test
public void testCreateIndex() throws Exception {
// 3. 指定要添加的檔案
XContentBuilder doc = XContentFactory.jsonBuilder().startObject().field("id", "1")
.field("title", "玩轉搜索(二)-- Solr實戰").field("content", "Solr是一個獨立的企業級搜索應用服務器,它對外提供API介面,")
.field("postdate", "2021-02-06").field("url", "https://blog.csdn.net/zwt122755527/article/details/113553242").endObject();
// 4. 添加資料,添加到es服務器中
IndexResponse response = client.prepareIndex("index1", "blog", "10").setSource(doc).get();
// 5. 查看添加檔案是否成功
System.out.println(response.status());
}
@Test
public void testDeleteIndex() {
// 3. 指定要洗掉的檔案
DeleteResponse response = client.prepareDelete("index1", "blog", "10").get();
// 5. 查看添加檔案是否成功//洗掉成功回傳OK,否則回傳NOT_FOUND
System.out.println(response.status());
}
/**
* 查詢洗掉
*/
@Test
public void testDeleteByQuery() {
try {
MatchQueryBuilder builder = QueryBuilders.matchQuery("title", "搜索");
BulkByScrollResponse response = DeleteByQueryAction.INSTANCE.newRequestBuilder(client).filter(builder)
.source("index1").get();
long count = response.getDeleted();
System.out.println(count);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 更新檔案 - 直接更新
*/
@Test
public void testUpdateIndex() {
try {
// 3. 編輯要修改的doc內容
XContentBuilder doc = XContentFactory.jsonBuilder().startObject().field("title", "Solr").endObject();
// 4. 創建update的請求
UpdateRequest request = new UpdateRequest();
// 5. 指定要修改的索引/型別/id
request.index("index1").type("blog").id("10").doc(doc);
// 6. 提交update請求 更新成功回傳OK,否則回傳NOT_FOUND
UpdateResponse response = client.update(request).get();
// 7. 查看添加檔案是否成功
System.out.println(response.status());
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 更新檔案-upset方式
*/
@Test
public void testUpsertIndex() {
try {
// 3.1 指定要添加的檔案-如果update 失敗的話,沒有這個值 會進行添加操作
XContentBuilder indexdoc = XContentFactory.jsonBuilder().startObject().field("id", "2")
.field("title", "玩轉搜索(一)-- 全文檢索與Lucene實作").field("content", "全文檢索的概念")
.field("postdate", "2021-01-24").field("url", "https://blog.csdn.net/zwt122755527/article/details/112616773").endObject();
// 3.2 指定要修改的檔案
XContentBuilder updatedoc = XContentFactory.jsonBuilder().startObject().field("title", "玩轉搜索").endObject();
// 4.1 編輯要添加的doc的請求
IndexRequest indexRequest = new IndexRequest("index1", "blog", "8").source(indexdoc);
// 4.1 編輯要修改的doc的請求,如果修改失敗會進行upsert操作
UpdateRequest updateRequest = new UpdateRequest("index1", "blog", "8").doc(updatedoc).upsert(indexRequest);
// 5. 提交update請求 操作成功回傳OK,否則回傳NOT_FOUND
UpdateResponse response = client.update(updateRequest).get();
// 6. 查看添加檔案是否成功
System.out.println(response.status());
} catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void test1() {
try {
ClusterHealthResponse healths = client.admin().cluster().prepareHealth().get();
String clusterName = healths.getClusterName();
System.out.println("clusterName = " + clusterName);
int numberOfNodes = healths.getNumberOfNodes();
System.out.println("numberOfNodes = " + numberOfNodes);
for (ClusterIndexHealth health : healths.getIndices().values()) {
String index = health.getIndex();
int numberOfShards = health.getNumberOfShards();
int numberOfReplicas = health.getNumberOfReplicas();
ClusterHealthStatus status = health.getStatus();
System.out.println(status.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/264455.html
標籤:其他
下一篇:第十屆藍橋杯省賽題:把 2019 分解成 3 個各不相同的正整數之和,并且要求每個正整數都不包含數字 2 和 4,一共有多少種不同的分解方法?