文章目錄
- 第 1 章 Kafka 概述
- 1.1 定義
- 1.2 訊息佇列
- 1.2.1 傳統訊息佇列的應用場景
- 1.2.2 訊息佇列的兩種模式
- 1.3 Kafka 基礎架構
- 第 2 章 Kafka 快速入門
- 2.1 安裝部署
- 2.1.1 集群規劃
- 2.1.2 jar 包下載
- 2.1.3 集群部署
- 2.2 Kafka 命令列操作
- 第 3 章 Kafka 架構深入
- 3.1 Kafka 作業流程及檔案存盤機制
- 3.2 Kafka 生產者
- 3.2.1 磁區策略
- 3.2.2 資料可靠性保證
- 1)副本資料同步策略
- 2)ISR
- 3)ack 應答機制
- 4)故障處理細節
- 3.2.3 Exactly Once 語意
- 3.3 Kafka 消費者
- 3.3.1 消費方式
- 3.3.2 磁區分配策略
- 3.3.3 offset 的維護
- 3.3.4 消費者組案例
- 3.4 Kafka 高效讀寫
- 3.5 Zookeeper 在 Kafka 中的作用
- 3.6 Kafka 事務
- 3.6.1 Producer 事務
- 3.6.2 Consumer 事務
第 1 章 Kafka 概述
1.1 定義
Kafka 是一個分布式的基于發布/訂閱模式的訊息佇列(Message Queue),主要應用于大資料實時處理領域,
1.2 訊息佇列
1.2.1 傳統訊息佇列的應用場景
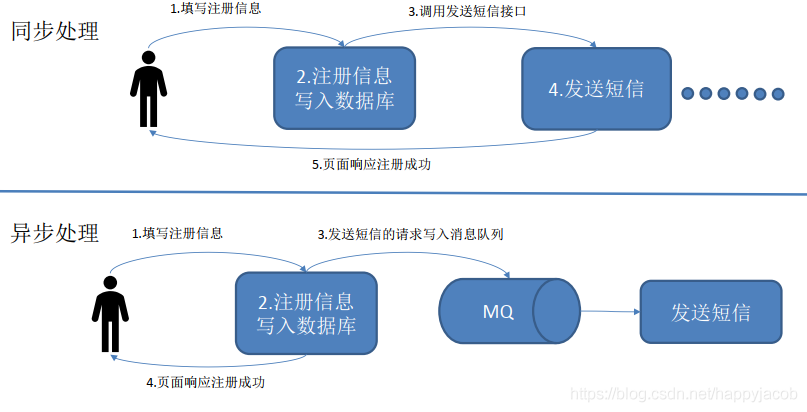
同步處理時步驟 5 可能較長時間未進行,用戶長時間得不到相應,采用異步的方式,訊息注冊到資料庫中之后,馬上給用戶回應,發送訊息的請求寫入訊息佇列中,等待發送訊息,這樣發送短信的時效性就沒這么重要了,
使用訊息佇列的好處
- 解耦:允許你獨立的擴展或修改兩邊的處理程序,只要確保它們遵守同樣的介面約束,
- 可恢復性:系統的一部分組件失效時,不會影響到整個系統,訊息佇列降低了行程間的耦合度,所以即使一個處理訊息的行程掛掉,加入佇列中的訊息仍然可以在系統恢復后被處理,
- 緩沖:有助于控制和優化資料流經過系統的速度,解決生產訊息和消費訊息的處理速度不一致
的情況, - 靈活性 & 峰值處理能力:在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量并不常見,如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費,使用訊息佇列能夠使關鍵組件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰,
- 異步通信:很多時候,用戶不想也不需要立即處理訊息,訊息佇列提供了異步處理機制,允許用戶把一個訊息放入佇列,但并不立即處理它,想向佇列中放入多少訊息就放多少,然后在需要的時候再去處理它們,
1.2.2 訊息佇列的兩種模式
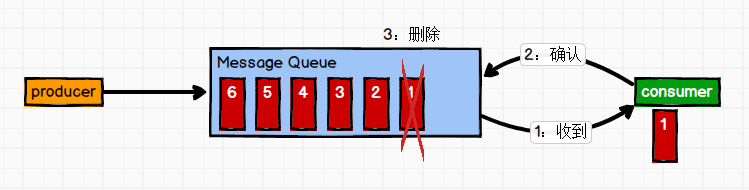
(1)點對點模式(一對一,消費者主動拉取資料,訊息收到后訊息清除)
訊息生產者生產訊息發送到 Queue 中,然后訊息消費者從 Queue 中取出并且消費訊息,訊息被消費以后,queue 中不再有存盤,所以訊息消費者不可能消費到已經被消費的訊息,Queue 支持存在多個消費者,但是對一個訊息而言,只會有一個消費者可以消費,
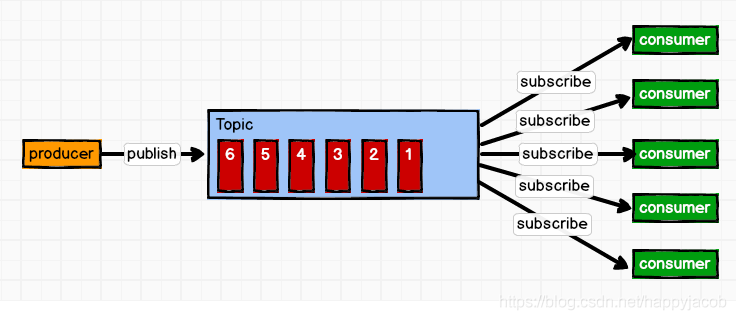
(2)發布/訂閱模式(一對多,消費者消費資料之后不會清除訊息)
訊息生產者(發布)將訊息發布到 topic 中,同時有多個訊息消費者(訂閱)消費該訊息,和點對點方式不同,發布到 topic 的訊息會被所有訂閱者消費,
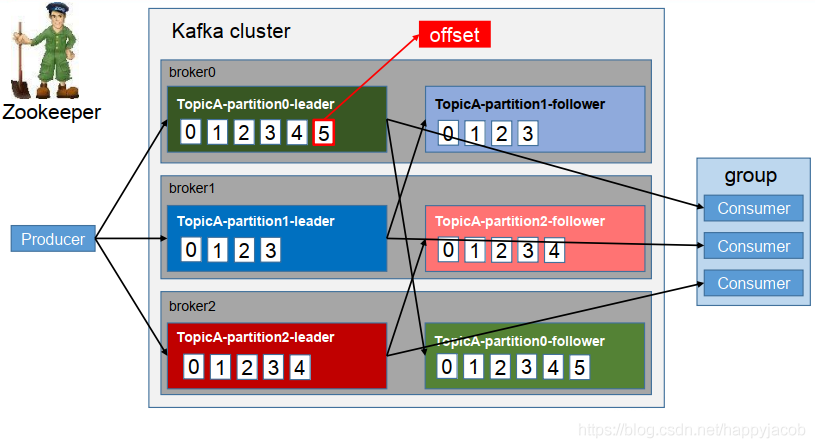
1.3 Kafka 基礎架構
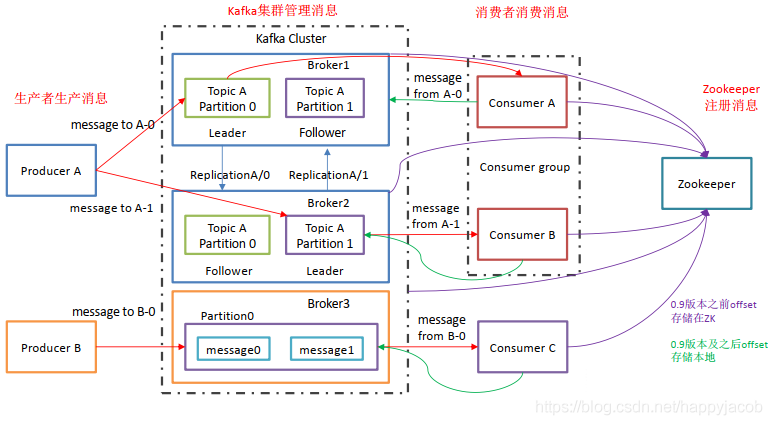
- Producer:訊息生產者,就是向 kafka broker 發訊息的客戶端;
- Consumer:訊息消費者,向 kafka broker 取訊息的客戶端;
- Consumer Group(CG):消費者組,由多個 consumer 組成, 消費者組內每個消費者負責消費不同磁區的資料,一個磁區只能由一個組內消費者消費;消費者組之間互不影響,所有的消費者都屬于某個消費者組,即消費者組是邏輯上的一個訂閱者,同一個組的消費者之間時競爭關系,一個 partition 被一個消費者消費了,就不會被組內另一個消費者消費;
- Broker:一臺 kafka 服務器就是一個 broker,一個集群由多個 broker 組成,一個 broker 可以容納多個 topic,
- Topic:可以理解為一個佇列, 生產者和消費者面向的都是一個 topic;
- Partition:為了實作擴展性,一個非常大的 topic 可以分布到多個 broker(即服務器)上,一個 topic 可以分為多個 partition,每個 partition 是一個有序的佇列;磁區提高 topic 并發,提高負載均衡能力;
- Replica:副本,為保證集群中的某個節點發生故障時,該節點上的 partition 資料不丟失,且 kafka 仍然能夠繼續作業,kafka 提供了副本機制,一個 topic 的每個磁區都有若干個副本,一個 leader 和若干個 follower,
- leader:每個磁區多個副本的“主”,生產者發送資料的物件,以及消費者消費資料的物件都是 leader,
- follower:每個磁區多個副本中的“從”,實時從 leader 中同步資料,保持和 leader 資料的同步,leader 發生故障時,某個 follower 會成為新的 follower,
第 2 章 Kafka 快速入門
2.1 安裝部署
2.1.1 集群規劃
這里再本地 ubuntu 安裝,就只裝了一個節點
安裝 zookeeper-3.4.10,kafka-0.11.0
2.1.2 jar 包下載
http://kafka.apache.org/downloads.html
2.1.3 集群部署
1)解壓安裝包
$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
2)修改解壓后的檔案名稱
$ mv kafka_2.11-0.11.0.0/ kafka
3)在/opt/module/kafka 目錄下創建 logs 檔案夾
$ mkdir logs
4)修改組態檔
$ cd config/
$ vim server.properties
#broker 的全域唯一編號,不能重復
broker.id=0
#洗掉 topic 功能使能
delete.topic.enable=true
#處理網路請求的執行緒數量
num.network.threads=3
#用來處理磁盤 IO 的現成數量
num.io.threads=8
#發送套接字的緩沖區大小
socket.send.buffer.bytes=102400
#接收套接字的緩沖區大小
socket.receive.buffer.bytes=102400
#請求套接字的緩沖區大小
socket.request.max.bytes=104857600
#kafka 運行日志存放的路徑
log.dirs=/opt/module/kafka/logs
#topic 在當前 broker 上的磁區個數
num.partitions=1
#用來恢復和清理 data 下資料的執行緒數量
num.recovery.threads.per.data.dir=1
#segment 檔案保留的最長時間,超時將被洗掉
log.retention.hours=168
#配置連接 Zookeeper 集群地址
zookeeper.connect=localhost:2181
該檔案中需要修改的有這幾個配置項,broker.id、delete.topic.enable、log.dirs、zookeeper.connect
注意:這里的配置項 log.dirs 對應的目錄下存放的并不是 kafka 的日志,而是 kafka 的訊息資料,
如果是以集群方式部署的,還需要再其他節點修改組態檔 config/server.properties,broker.id 不能重復,可以是 0,1,2 這種
5)啟動 zookeeper
bin/zkServer.sh start
6)啟動kafka
bin/kafka-server-start.sh -daemon config/server.properties
-daemon:以守護行程的方式啟動,不以阻塞
7)關閉 kafka 行程
bin/kafka-server-stop.sh
8)關閉zookeeper行程
bin/zkServer.sh stop
2.2 Kafka 命令列操作
1)查看當前服務器中的所有 topic
bin/kafka-topics.sh --zookeeper localhost:2181 --list
bin/kafka-topics.sh --zookeeper localhost:2181 --describe

2)創建 topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic first --partitions 2 --replication-factor 1
選項說明:
--topic 定義 topic 名
--partitions 指定磁區數量
--replication-factor 指定副本數量,副本數量不能大于broker的數量

3)洗掉 topic
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic first

我們已經將配置項 delete.topic.enable 設為 True,這條洗掉陳述句會將 first topic 洗掉,否則將不會生效,
4)發送訊息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic first
5)消費訊息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first --from-beginning
6)查看某個 topic 的詳情
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic first

7)修改磁區數
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic first --partitions 3
將 partitions 數量改為 3 個
第 3 章 Kafka 架構深入
3.1 Kafka 作業流程及檔案存盤機制
Kafka 中訊息是以 topic 進行分類的,生產者生產訊息,消費者消費訊息,都是面向 topic 的,
topic 是邏輯上的概念,而 partition 是物理上的概念,每個 partition 對應于一個 log 檔案,該 log 檔案中存盤的就是 producer 生產的資料,Producer 生產的資料會被不斷追加到該log 檔案末端,且每條資料都有自己的 offset,消費者組中的每個消費者,都會實時記錄自己消費到了哪個 offset,以便出錯恢復時,從上次的位置繼續消費,
檔案目錄中每個 partition 對應一個檔案夾,沒有 topic 對應的檔案夾,如下圖所示,
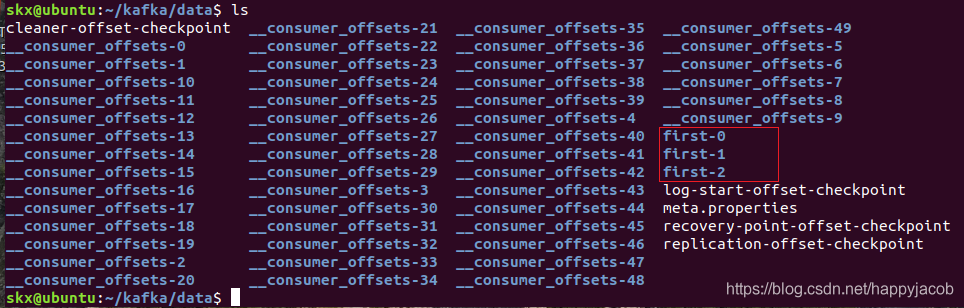
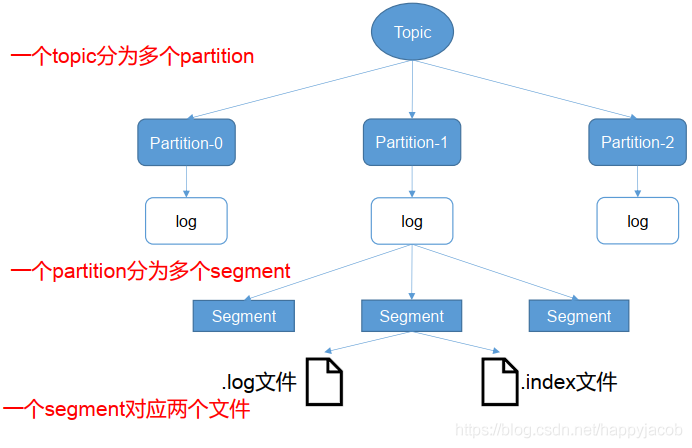
由于生產者生產的訊息會不斷追加到 log 檔案末尾,為防止 log 檔案過大導致資料定位效率低下,Kafka 采取了分片和索引機制,將每個 partition 分為多個 segment,每個 segment 對應兩個檔案——“.index”檔案和“.log”檔案,這些檔案位于一個檔案夾下,該檔案夾的命名規則為:topic 名稱+磁區序號,例如,first 這個 topic 有三個磁區,則其對應的檔案夾為 first-0,first-1,first-2,
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
index 和 log 檔案以當前 segment 的第一條訊息的 offset 命名,下圖為 index 檔案和 log 檔案的結構示意圖,
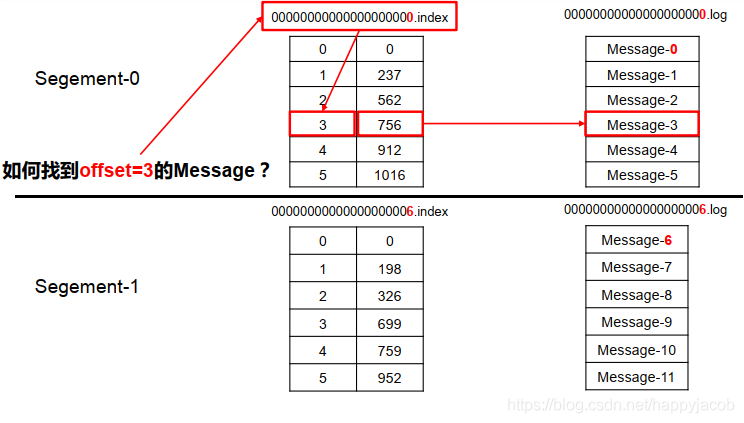
“.index”檔案存盤大量的索引資訊,“.log”檔案存盤大量的資料,索引檔案中的元資料指向對應資料檔案中 message 的物理偏移地址,
手動模擬一遍如果索引訊息:
指定一個偏移量,如果在該 partition 中快速找到改偏移量 offset 對應的訊息內容呢,假設找 offset = 3 的訊息,首先需要找到該訊息在哪個 .log 檔案中,這個簡單,.log 和 .index 檔案是以該檔案中第一條訊息的偏移量進行命令的,二分法可以快速定位到在對應的 .log 和 .index 檔案,假設該檔案夾下檔案為 00000000000000000000.index,00000000000000000000.log,00000000000000000006.index,00000000000000000006.log,可以得到訊息在 00000000000000000000.log 中,索引資訊在 00000000000000000000.index 中,Message-0,Message-1等每條訊息的大小雖然不是固定的,但是在 .index 檔案中,訊息編號和訊息的地址大小的固定的,根據第一條訊息編號為1,找編號為 3 的訊息,可以在 .index 檔案中快速跳轉到編號為 3 的位置,從而取出 offset = 3 的訊息的地址為 756,直接在檔案 00000000000000000000.log 中找地址為 756 的位置就找到了offset = 3 的訊息,
3.2 Kafka 生產者
3.2.1 磁區策略
1) 磁區的原因
- 方便在集群中擴展,每個 Partition 可以通過調整以適應它所在的機器,而一個 topic又可以有多個 Partition 組成,因此整個集群就可以適應任意大小的資料了;
- 可以提高并發,因為可以以 Partition 為單位讀寫了,
2) 磁區的原則
我們需要將 producer 發送的資料封裝成一個 ProducerRecord 物件,
- 指明 partition 的情況下,直接將指明的值直接作為 partiton 值;
- 沒有指明 partition 值但有 key 的情況下,將 key 的 hash 值與 topic 的 partition 數進行取余得到 partition 值;
- 既沒有 partition 值又沒有 key 值的情況下,第一次呼叫時隨機生成一個整數(后面每次呼叫在這個整數上自增),將這個值與 topic 可用的 partition 總數取余得到 partition 值,也就是常說的 round-robin 演算法,
3.2.2 資料可靠性保證
為保證 producer 發送的資料,能可靠的發送到指定的 topic,topic 的每個 partition 收到 producer 發送的資料后,都需要向 producer 發送 ack(acknowledgement 確認收到),如果 producer 收到 ack,就會進行下一輪的發送,否則重新發送資料,
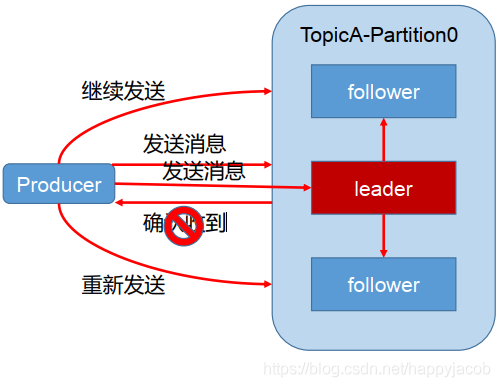
何時發送 ack?
- 確保有 follower 與 leader 同步完成,leader 再發送 ack,這樣才能保證 leader 掛掉之后,能在 follower 中選舉出新的 leader,
多少個 follower 同步完成之后發送 ack?
- 方案 1:半數以上的 follower 同步完成,即可發送 ack 繼續發送重新發送
- 方案 2:全部的 follower 同步完成,才可以發送 ack
1)副本資料同步策略
| 方案 | 優點 | 缺點 |
|---|---|---|
| 半數以上完成同步, 就發送 ack | 延遲低 | 選舉新的 leader 時,容忍 n 臺節點的故障,需要 2n+1 個副本 |
| 全部完成同步,才發送ack | 選舉新的 leader 時, 容忍 n 臺節點的故障,需要 n+1 個副本 | 延遲高 |
為了保證資料可靠,則至少要保證由一臺機器上的資料是完整的,所以
方案1:一共 2n+1 個節點,半數以上完成同步,則至少 n+1 個節點完成同步,掛了 n 個節點,至少有 1 個節點的資料是完整的
方案2:全部同步完成,一個 n+1 個節點,掛了 n 個,還有 1 個節點資料是完整的
Kafka 選擇了第二種方案,原因如下:
- 同樣為了容忍 n 臺節點的故障,第一種方案需要 2n+1 個副本,而第二種方案只需要 n+1 個副本,而 Kafka 的每個磁區都有大量的資料,第一種方案會造成大量資料的冗余,
- 雖然第二種方案的網路延遲會比較高,但網路延遲對 Kafka 的影響較小,
2)ISR
采用第二種方案之后,設想以下情景:leader 收到資料,所有 follower 都開始同步資料,但有一個 follower,因為某種故障,遲遲不能與 leader 進行同步,那 leader 就要一直等下去,直到它完成同步,才能發送 ack,這個問題怎么解決呢?
Leader 維護了一個動態的 in-sync replica set (ISR),意為和 leader 保持同步的 follower 集合,當 ISR 中的 follower 完成資料的同步之后,leader 就會給 follower 發送 ack,如果 follower 長時間未向 leader 同步資料 , 則該 follower 將被踢出 ISR , 該時間閾值由 replica.lag.time.max.ms 引數設定,Leader 發生故障之后,就會從 ISR 中選舉新的 leader,
舊版本的 kafka 選擇哪個 follower 進入 ISR 取決于兩個條件,同步資料的延遲時間、follower 和 leader 相差的資料條數,新版本 kafka 移除了訊息條數這個條件,因為訊息可能一次發送一批訊息,導致短時間訊息條數 leader 和 follower 差距較大,這時所有的 follower 被移除 ISR,同步完又加入 ISR,這個資訊放在 zookeeper 中,會頻繁操作 ISR,頻繁寫 zk,
3)ack 應答機制
對于某些不太重要的資料,對資料的可靠性要求不是很高,能夠容忍資料的少量丟失,所以沒必要等 ISR 中的 follower 全部接收成功,
所以 Kafka 為用戶提供了三種可靠性級別,用戶根據對可靠性和延遲的要求進行權衡,選擇以下的配置,
acks 引數配置:
- acks = 0:producer 不等待 broker 的 ack,這一操作提供了一個最低的延遲,broker 一接收到還沒有寫入磁盤就已經回傳,當 broker 故障時有可能 丟失資料;
- acks = 1:producer 等待 broker 的 ack,partition 的 leader 落盤成功后回傳 ack,如果在 follower,同步成功之前 leader 故障,那么將會丟失資料;
- acks = -1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盤成功后才回傳 ack,但是如果在 follower 同步完成后,broker 發送 ack 之前,leader 發生故障,那么會造成資料重復,
acks = 1 資料丟失案例:leader 已經寫資料了,回傳 ack 了,follower 還沒寫資料,leader 掛了,生產者不會重新發送,follower 也沒有資料
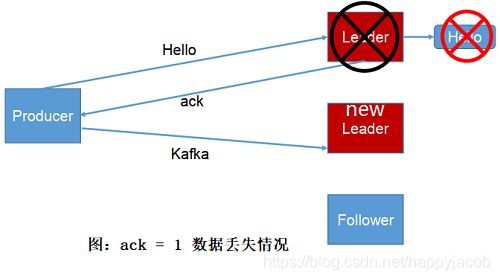
acks = -1 資料丟失情況:ISR中 的所有的 follower 都被移除了,退化到 acks=1 的情況了,這種情況很少出現,更多的情況是 acks = -1 導致資料重復,
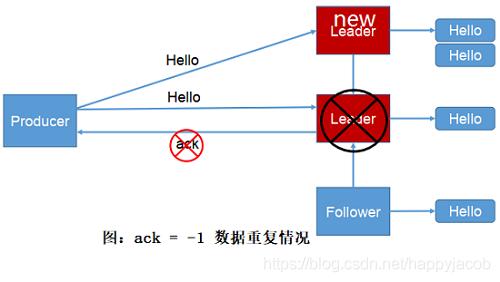
acks = -1 資料重復情況:ISR 中的 follower 已經同步了資料,leader 還沒發送 ack,leader 掛掉了,已經寫資料看 follower 變成 leader,生產者已經沒有寫入資料,重發,導致又寫了一份
4)故障處理細節
背景:如果 leader 已經同步資料了,follower 還沒同步資料或者尚未同步完成,leader 掛了,某一個follower 變成 leader,此時原來的 leader 又活了,出現 follower 比 leader 資料多的情況,資料不一致了,如何處理?
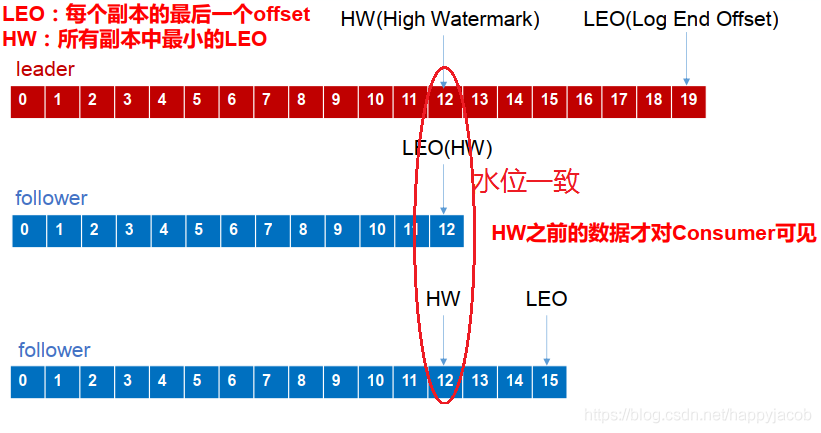
LEO :指的是每個副本最大的 offset;
HW :指的是消費者能見到的最大的 offset ,ISR 佇列中最小的 LEO,
(1)follower 故障
follower 發生故障后會被臨時踢出 ISR,待該 follower 恢復后,follower 會讀取本地磁盤記錄的上次的 HW,并將 log 檔案高于 HW 的部分截取掉,從 HW 開始向 leader 進行同步,等該 follower 的 LEO 大于等于該 Partition 的 的 HW,即 follower 追上 leader 之后,就可以重新加入 ISR 了,
(2)leader 故障
leader 發生故障之后,會從 ISR 中選出一個新的 leader,之后,為保證多個副本之間的資料一致性,其余的 follower 會先將各自的 log 檔案高于 HW 的部分截掉,然后從新的 leader 同步資料,
注意:這只能保證副本之間的資料一致性,并不能保證資料不丟失或者不重復
資料重復 eg:
假設生產者發訊息 13-19,ISR 中有兩個 follower,leader 掛了,第二 follower 同步了 13-15,然后變成 leader,由于 ISR 沒同同步完生產者沒收到 ack,重新發送了13-19,follower 已經同步的 13-15 就重復了
3.2.3 Exactly Once 語意
將服務器的 ACK 級別設定為 -1,可以保證 Producer 到 Server 之間不會丟失資料,即 At Least Once 語意,相對的,將服務器 ACK 級別設定為 0,可以保證生產者每條訊息只會被發送一次,即 At Most Once 語意,
At Least Once 可以保證資料不丟失,但是不能保證資料不重復;相對的,At Least Once 可以保證資料不重復,但是不能保證資料不丟失,但是,對于一些非常重要的資訊,比如說交易資料,下游資料消費者要求資料既不重復也不丟失,即 Exactly Once 語意,在 0.11 版本以前的 Kafka,對此是無能為力的,只能保證資料不丟失,再在下游消費者對資料做全域去重,對于多個下游應用的情況,每個都需要單獨做全域去重,這就對性能造成了很大影響,
0.11 版本的 Kafka,引入了一項重大特性:冪等性,所謂的冪等性就是指 Producer 不論向 Server 發送多少次重復資料,Server 端都只會持久化一條,冪等性結合 At Least Once 語意,就構成了 Kafka 的 Exactly Once 語意,即:
要啟用冪等性,只需要將 Producer 的引數中 enable.idompotence 設定為 true 即可,Kafka 的冪等性實作其實就是將原來下游需要做的去重放在了資料上游,開啟冪等性的 Producer 在初始化的時候會被分配一個 PID,發往同一 Partition 的訊息會附帶 Sequence Number,而 Broker 端會對 <PID, Partition, SeqNumber>做快取,當具有相同主鍵的訊息提交時,Broker 只會持久化一條,
但是 PID 重啟就會變化,同時不同的 Partition 也具有不同主鍵,所以冪等性無法保證跨磁區跨會話的 Exactly Once,
3.3 Kafka 消費者
3.3.1 消費方式
consumer 采用 pull(拉)模式從 broker 中讀取資料,
push(推)模式很難適應消費速率不同的消費者,因為訊息發送速率是由 broker 決定的,它的目標是盡可能以最快速度傳遞訊息,但是這樣很容易造成 consumer 來不及處理訊息,典型的表現就是拒絕服務以及網路擁塞,而 pull 模式則可以根據 consumer 的消費能力以適當的速率消費訊息,
pull 模式不足之處是,如果 kafka 沒有資料,消費者可能會陷入回圈中,一直回傳空資料,針對這一點,Kafka 的消費者在消費資料時會傳入一個時長引數 timeout,如果當前沒有資料可供消費,consumer 會等待一段時間之后再回傳,這段時長即為 timeout,
3.3.2 磁區分配策略
一個 consumer group 中有多個 consumer,一個 topic 有多個 partition,所以必然會涉及到 partition 的分配問題,即確定那個 partition 由哪個 consumer 來消費,
Kafka 有兩種分配策略,一是 RoundRobin,一是 Range,
- 1)RoundRobin
按照組類劃分,將所有的 topic 的 partition 輪詢分給 consumer
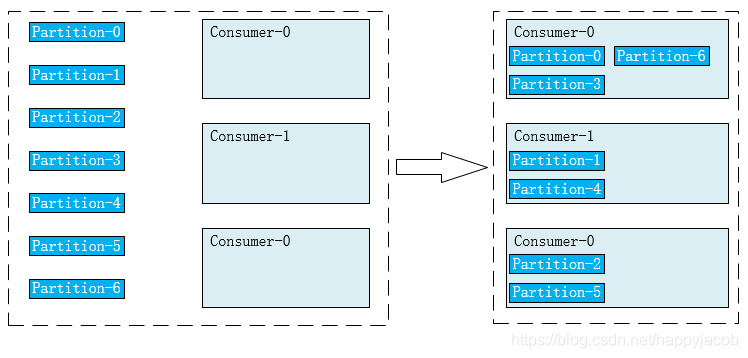
RoundRobin 將所有 topic 的 Partition 放在一起,輪詢分給消費者,
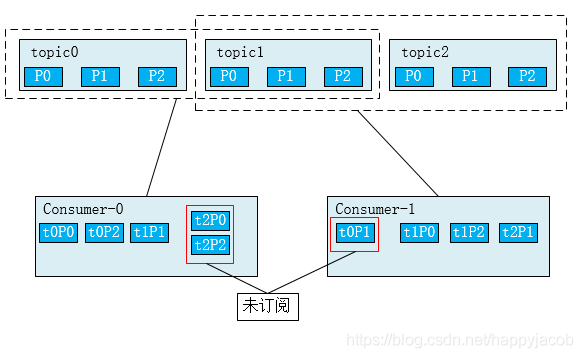
缺點:可能會將訊息發給給未訂閱 topic 的消費者,如下所示,consumer0 訂閱了 topic0、topic1,consumer1訂閱了topic1、topic2;t0P0 代表 topic0 的 Partition0;RoundRobin 會將三個 topic 的 partition 放在一起進行排序,然后輪詢發給 consumer,這樣會導致 consumer0 會接收 topic2 的訊息,consumer1 會接收 topic0 的訊息,
- 2)Range
按照 topic 進行劃分,將該 topic 的 partition 平均分給 consumer
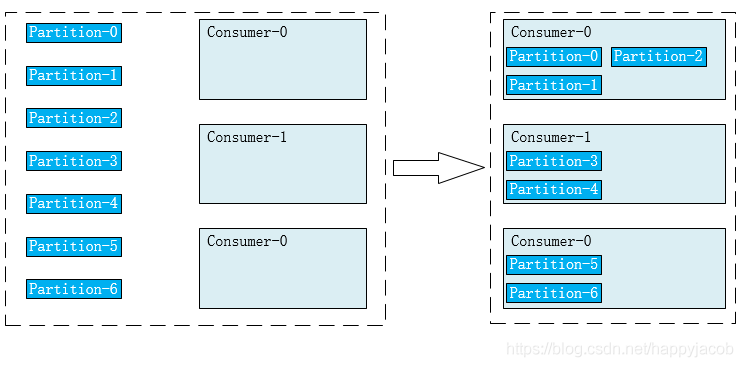
Range 按照 topic 的將 partition 分給 consumer,將一個 topic 中的 partition 分給訂閱的 consumer,假設有 partition0-partition6 7個磁區,將 0-2 磁區分給 consumer0,3-4 磁區分給 consumer1,5-6 磁區分給 consumer2
缺點:可能會導致不同的 consumer 分配不均衡,如下所示,topic0 有三個 partition,topic1 有三個 partition;consumer0 和, consumer1 都訂閱了topic0 和 topic1,Range 會導致 consumer0 分到 4 個 partition,consumer1 分到 2 個 partition,隨著 topic 的增加,分配不均衡的問題會更加嚴重,
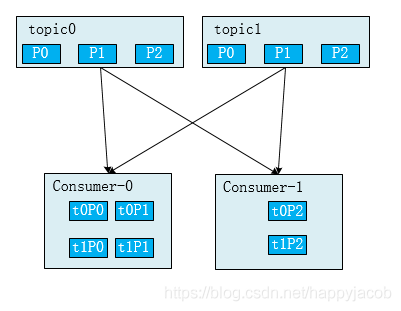
kafka 默認使用 Range 的方式對磁區進行分配,
磁區分配策略觸發時機:當消費者組中的消費者數量發生變化時,就會觸發磁區分配策略
3.3.3 offset 的維護
由于 consumer 在消費程序中可能會出現斷電宕機等故障,consumer 恢復后,需要從故障前的位置的繼續消費,所以 consumer 需要實時記錄自己消費到了哪個 offset,以便故障恢復后繼續消費,
group + topc + partition 唯一確定一個 offset,這樣一個消費者組中一個消費者掛了,其他消費者可以接著消費,或者有新的消費者加入消費者組,可以從還沒消費的位置接著消費
Kafka 0.9 版本之前,consumer 默認將 offset 保存在 Zookeeper 中,從 0.9 版本開始,consumer 默認將 offset 保存在 Kafka 一個內置的 topic 中,該 topic 為__consumer_offsets,
1)修改組態檔 consumer.properties,在檔案末尾加一行
exclude.internal.topics=false
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper localhost:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning
如果再次消費,需要更改 consumer.properties 檔案中的 group.id,同一個 group.id 不能再次消費
3.3.4 消費者組案例
1)需求:測驗同一個消費者組中的消費者,同一時刻只能有一個消費者消費,
2)案例實操
- 修改config/consumer.properties 組態檔中的 group.id 屬性為任意組名,
- 開啟兩個消費者 1,2 在同一個組內
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first --consumer.config config/consumer.properties
- 開啟兩個消費者 3 在采用隨機組號
bin/kafka-console-producer.sh --broklist localhost:9092 --topic first
- 開啟生產者
bin/kafka-console-producer.sh --broklist localhost:9092 --topic first
查看訊息接收情況
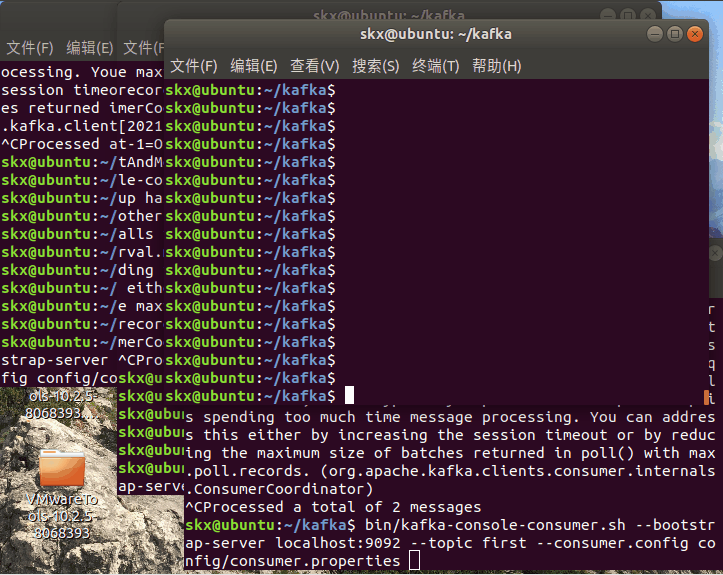
結論:看到消費者1,2在同一組內,采用輪詢的方式接受訊息,同一時刻只有一個消費者接收到訊息,消費者 3 單獨在一個組中,可以接收所有訊息
3.4 Kafka 高效讀寫
1)順序寫磁盤
Kafka 的 producer 生產資料,要寫入到 log 檔案中,寫的程序是一直追加到檔案末端,為順序寫,官網有資料表明,同樣的磁盤,順序寫能到 600M/s,而隨機寫只有 100K/s,這與磁盤的機械機構有關,順序寫之所以快,是因為其省去了大量磁頭尋址的時間,
2)零復制技術,零拷貝
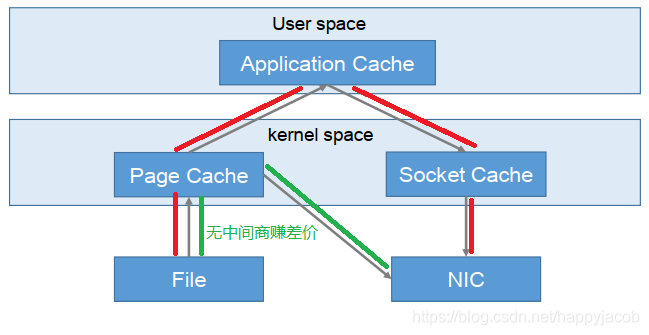
資料不會經過用戶態
3.5 Zookeeper 在 Kafka 中的作用
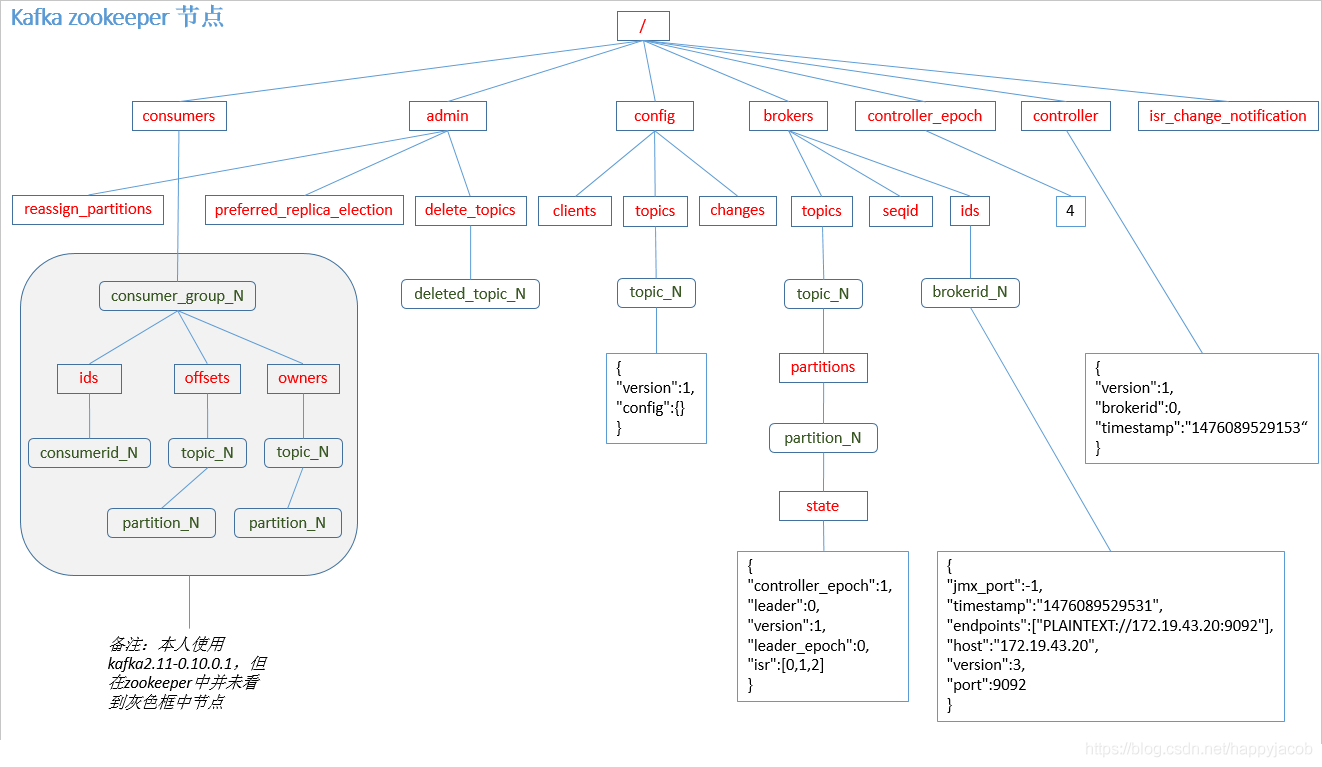
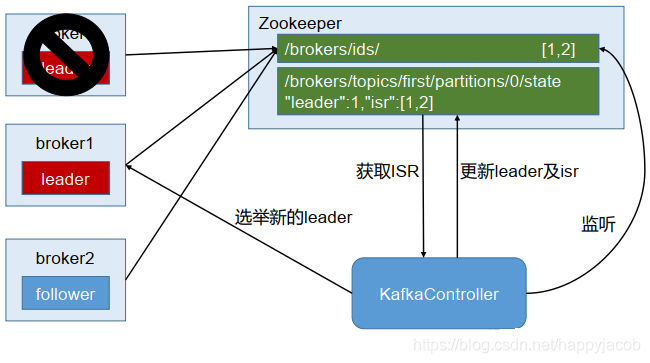
Kafka 集群中有一個 broker 會被選舉為 Controller,負責管理集群 broker 的上下線,所有 topic 的磁區副本分配和 leader 選舉等作業,
Controller 的管理作業都是依賴于 Zookeeper 的,
以下為 partition 的 leader 選舉程序:
3.6 Kafka 事務
3.6.1 Producer 事務
冪等性可以在 Producer 行程不掛的情況下保證 Exactly Once,<PID, Partition, SeqNumber> 可以確定訊息是否重復,但是當 Producer 行程重啟,PID 發生改變,就不能保證 Exactly Once,
為了實作跨磁區跨會話的事務,需要引入一個全域唯一的 Transaction ID,并將 Producer 獲得的 PID 和 Transaction ID 系結,這樣當 Producer 重啟后就可以通過正在進行的 Transaction ID 獲得原來的 PID,
為了管理 Transaction,Kafka 引入了一個新的組件 Transaction oordinator,Producer 就是通過和 Transaction Coordinator 互動獲得 Transaction ID 對應的任務狀態,Transaction Coordinator 還負責將事務所有寫入 Kafka 的一個內部 Topic,這樣即使整個服務重啟,由于事務狀態得到保存,進行中的事務狀態可以得到恢復,從而繼續進行,
3.6.2 Consumer 事務
上述事務機制主要是從 Producer 方面考慮,對于 Consumer 而言,事務的保證就會相對較弱,尤其時無法保證 Commit 的資訊被精確消費,這是由于 Consumer 可以通過 offset 訪問任意資訊,而且不同的 Segment File 生命周期不同,同一事務的訊息可能會出現重啟后被洗掉的情況,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/264806.html
標籤:其他