B題——汽油辛烷值優化
作者序言
B題當時比賽時選的人非常多,可以說占據了近一般的參賽隊伍,但是這題蘊含很多小問題,諸多選手也是叫苦連天,
我們隊伍利用3天的時間完成這道賽題,最侄訓得全國一等獎(1.3%),也是全校唯一 一等獎,在此將整體思路整理,供大家參考,也歡迎一起交流、批評、指正,
在本科時期參加的美國大學生數學建模比賽也獲得M獎,后續會出一片數學建模經驗的blog,有問題或備賽疑惑的同學可以私信我,
背景
- 汽油是小型車輛的主要燃料,汽油燃燒產生的尾氣排放對大氣環境有重要影響,為此,
世界各國都制定了日益嚴格的汽油質量標準,汽油清潔化重點是降低汽油中的硫、烯烴含
量,同時盡量保持其辛烷值, - 辛烷值(以 RON 表示)是反映汽油燃燒性能的最重要指標,并作為汽油的商品牌號,
現有技術在對催化裂化汽油進行脫硫和降烯烴程序中,普遍降低了汽油辛烷值, - 化工程序的建模一般是通過資料關聯或機理建模的方法來實作的,取得了一定的成果,
但是由于煉油工藝的復雜性以及操作變數的高度非線性及相互強耦聯,傳統資料關聯模型
難以對程序優化作出及時回應,效果不佳, - 現有某石化企業運行 4 年的催化裂化汽油精制脫硫裝置并積累了大量歷史資料,其汽
油產品辛烷值損失平均為 1.37 個單位相較于同類裝置的最小損失值 0.6 個單位有較大的優
化空間,現通過資料挖掘技術來解決該場景化工程序建模問題,
資料
具體資料源參見數學建模B題資料
問題提出
- 根據從催化裂化汽油精制裝置采集的 325 個資料樣本(每個資料樣本都有 354 個操作
變數),通過資料挖掘技術來建立汽油辛烷值(RON)損失的預測模型,并給出每個樣本
的優化操作條件,在保證汽油產品脫硫效果(歐六和國六標準均為不大于 10μg/g,但為了
給企業裝置操作留有空間,本次建模要求產品硫含量不大于 5μg/g)的前提下,最終完成
降低汽油辛烷含量損失降幅在 30% 以上,
現根據以上背景以及所提供資料完成以下任務:
- 參考近四年的工業資料的資料樣本,對 285 號和 313 號樣本原始資料根據給定的
樣本處理方法對資料樣本進行預處理,填入樣本資料集中對應的資料樣本編號中,以便進
一步分析, - 資料樣本提供了 325 個樣本資料,以及建立辛烷損失值模型所需要的 367 個操作
變數,通過降維的方法篩選出建模的主要變數,并給出詳盡的分析, - 采用(1)(2)中完成的資料樣本以及建模變數,使用資料挖掘技術建立辛烷值
(RON)損失預測模型,并驗證, - 在保證產品硫含量不大于 5μg/g 的前提下,利用(3)中的模型對應的 325 個資料
樣本可操作變數進行優化,并給出辛烷值(RON)損失降幅大于 30% 的主要變數優化后的
操作條件, - 對 133 號樣本,圖形展示(2)中選定的主要操作變數在優化調整程序中對應辛烷
值和硫含量的變化軌跡,
問題一分析
本題要求對 285 號和 313 號原始資料根據指定的資料處理規范進行預處理并填入相應
的樣本編號,樣本的原始資料每編號各 40 組,我們將每組的資料用給定的資料處理規范
進行驗證,得到最終的資料,最后對每一列求期望補充相應的樣本編號,
問題二分析
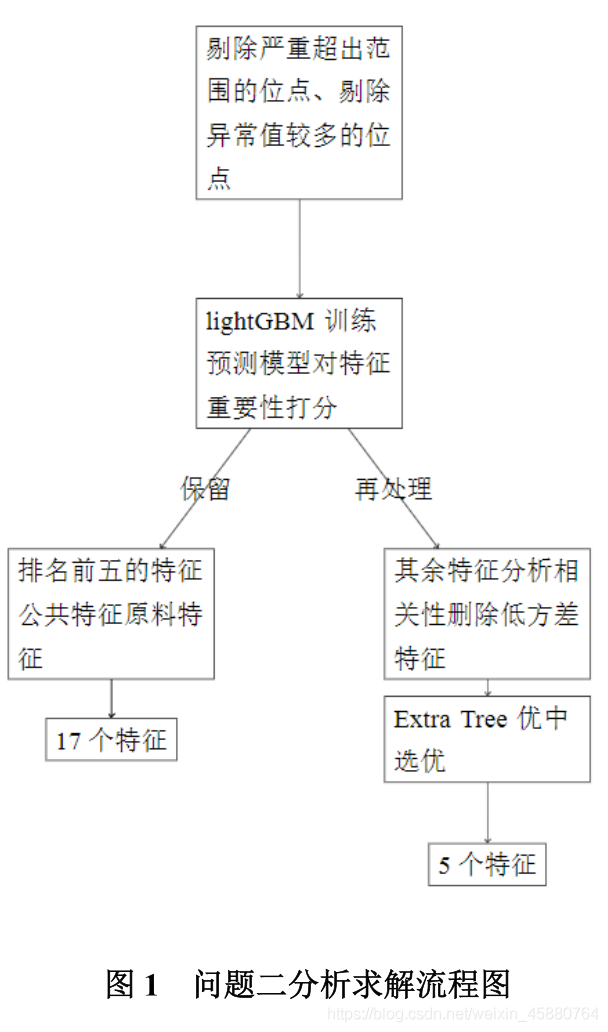
本題首先對資料樣本按照最大最小限幅以及拉依達法則進行列變數清洗,
- 第一輪篩選,將處理后的資料針對產品中硫含量、RON 損失值用 lightGBM 做特征權
重打分并以一定規則篩選出權重排名較前以及原料性質附帶待生吸附劑、再生吸附劑等 17
個變數, - 第二輪篩選,針對排名較低且獨立出現的 57 個變數進行相關性分析,針對相關性 >0.8
的兩兩變數避免同時出現,之后基于決策樹模型再做特征,選擇選出最終 5 個變數并整合
第一輪 17 個變數,得到建模所需要的 22 個主要變數,具體流程如圖1所示,
問題三分析
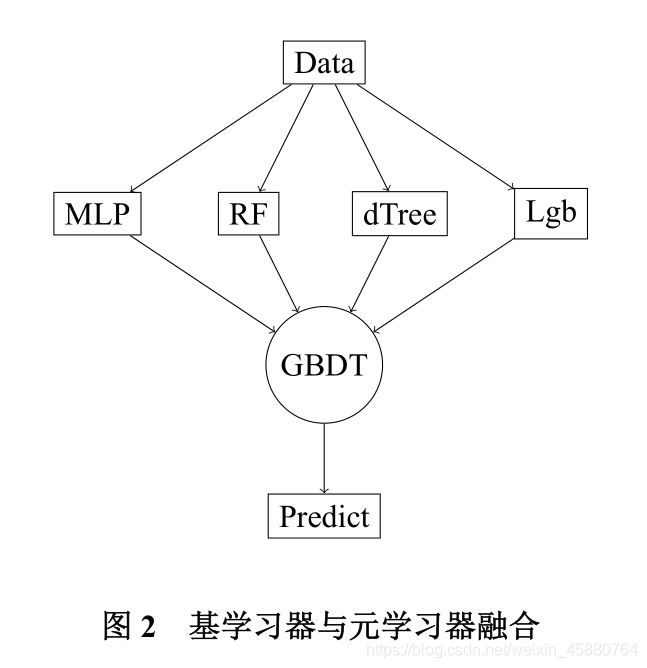
本題利用模型融合的方法,構建集成學習模型,分別建立產品硫含量、RON 損失值預
測的集成學習模型,
- 首先分別訓練 4 個基學習器:多層感知機、隨機森林、決策樹、梯度提升決策樹,構
建 4 個相關性較低的弱學習器, - 再將 4 個基學習器進行模型融合,集成到梯度下降樹(GBDT)中,實作 2 層的集成
學習模型,如圖2所示, - 根據評價指標均方誤差(MSE)、平均絕對誤差(MAE), 集成的模型對硫含量、RON
損失值的預測準確度遠高于單一基學習器,且誤差都較小,模型有較好的預測效果,
問題四分析
問題要求給出操作變數的優化方案,使得依據優化操作變數生成的 RON loss 和 CP S
滿足給定要求,
將此問題建模為多目標優化問題,目標函式即為第三問建立的兩個模型,
由遺傳演算法計算得到 325 個樣本的操作變數的帕累托最優取值,再在其中進行篩選,刪去
不滿足題設要求的帕累托最優解,即可找到完全滿足題設要求的優化操作變數取值,
問題五分析
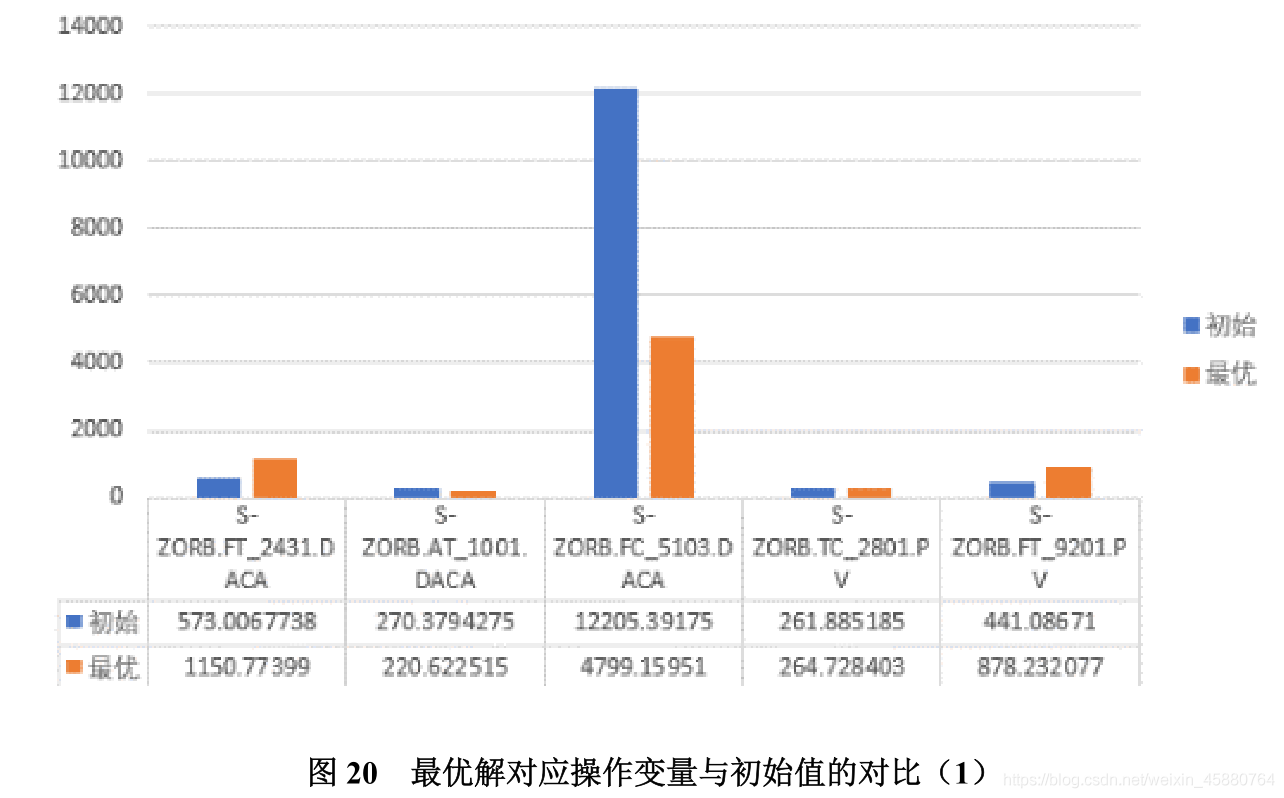
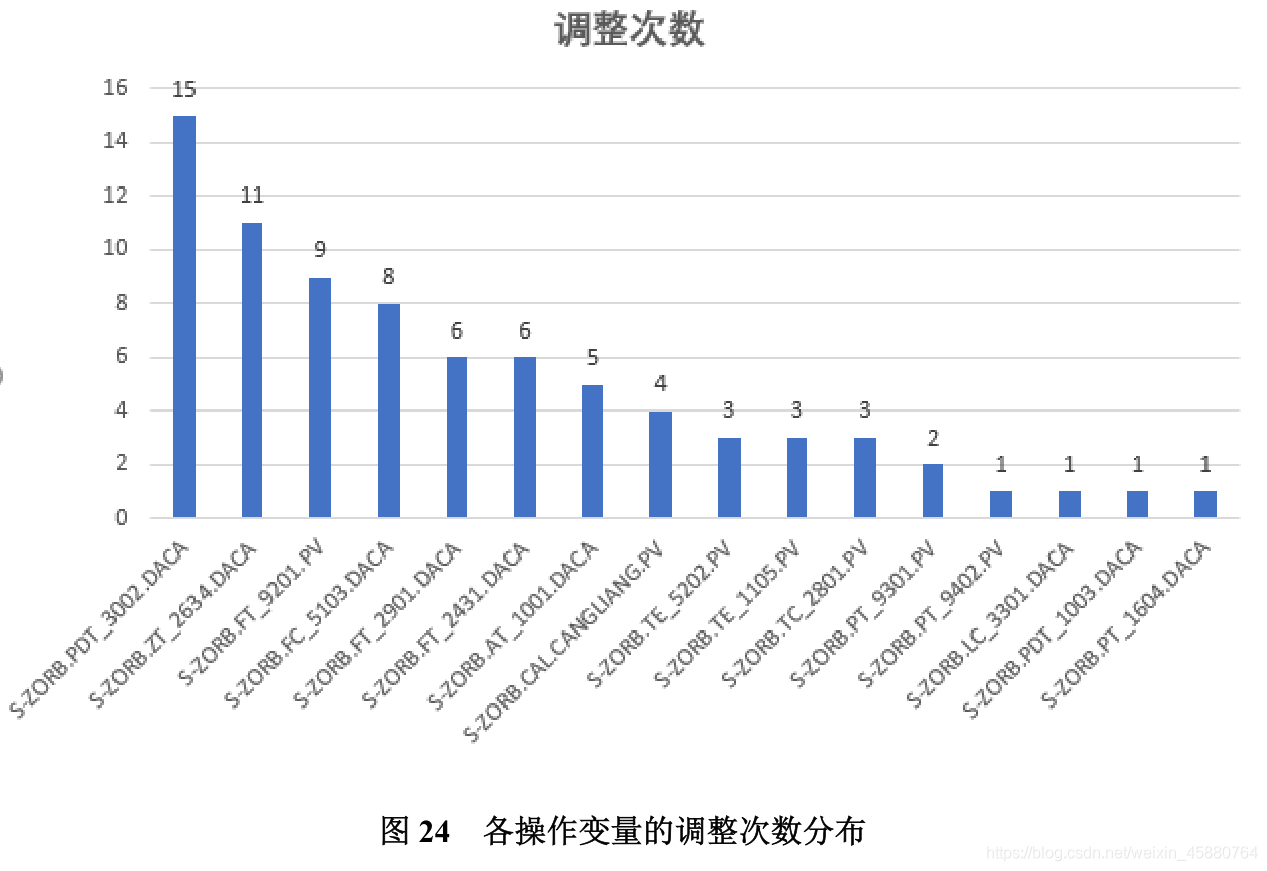
根據問題四中構建的優化策略,在保證優化目標的前提下,尋找 133 號樣本點的帕累
托最優解對應的最優操作變數,結合操作變數范圍,將初始操作變數逐步調整至最優數值,
每一步調整都會產生 133 號新的樣本,利用預測模型對其預測,得到操作變數優化調整過
程中對應的汽油辛烷值和硫含量的變化
論文架構
論文主要由以下幾個部分組成

論文重要圖片
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/264807.html
標籤:其他
上一篇:Kafka學習筆記--kafka 概述、快速入門,架構深入
下一篇:5.2 原生JDBC增刪改查