獨家思維導圖!讓你秒懂李宏毅2020深度學習(三)——深度學習基礎(神經網路和反向傳播部分)
長文預警!!!前面兩篇文章主要介紹了李宏毅視頻中的機器學習部分,從這篇文章開始,我將介紹李宏毅視頻中的深度學習部分,難度又將提升一個檔次,大家一起加油鴨!本篇內容融合了李宏毅深度學習基礎部分的多項知識,順序根據博主的理解進行了些許調整,旨在能讓大家更清晰的理解,有啥理解不對的地方歡迎大家批評指正!
系列文章傳送門:
獨家思維導圖!讓你秒懂李宏毅2020機器學習(一)—— Regression回歸
獨家思維導圖!讓你秒懂李宏毅2020機器學習(二)—— Classification分類
獨家思維導圖!讓你秒懂李宏毅2020深度學習(三)—— 深度學習基礎(神經網路和反向傳播部分)
獨家思維導圖!讓你秒懂李宏毅2020深度學習(四)—— CNN(Convolutional Neural network)
文章目錄
- 獨家思維導圖!讓你秒懂李宏毅2020深度學習(三)——深度學習基礎(神經網路和反向傳播部分)
- Up and downs of Deep Learning
- Neural Network
- M-P神經元模型
- 結構
- 效果
- 影響
- 單層感知機模型(單層神經網路)
- 結構
- 效果
- 影響
- 兩層神經網路(多層感知器)
- 結構
- 效果
- 訓練
- 影響
- 多層神經網路(深度學習)
- 結構
- 效果
- 訓練
- 影響
- 總結
- 李宏毅老師定義
- Fully Connect Feedforward Network(全連接前饋?絡)
- 激勵函式
- 無激勵函式的神經網路
- 有激勵函式的神經網路
- Activation Function Mindmap(干貨!!!)
- Matrix Operation
- Backpropagation(反向傳播)
- Chain Rule
- 1 復合函式
- 2 鏈式法則
- 2.1 單變數函式鏈式法則
- 2.2 多變數函式鏈式法則
- Backpropagation Mindmap(干貨!!!)
- 參考文章
Up and downs of Deep Learning
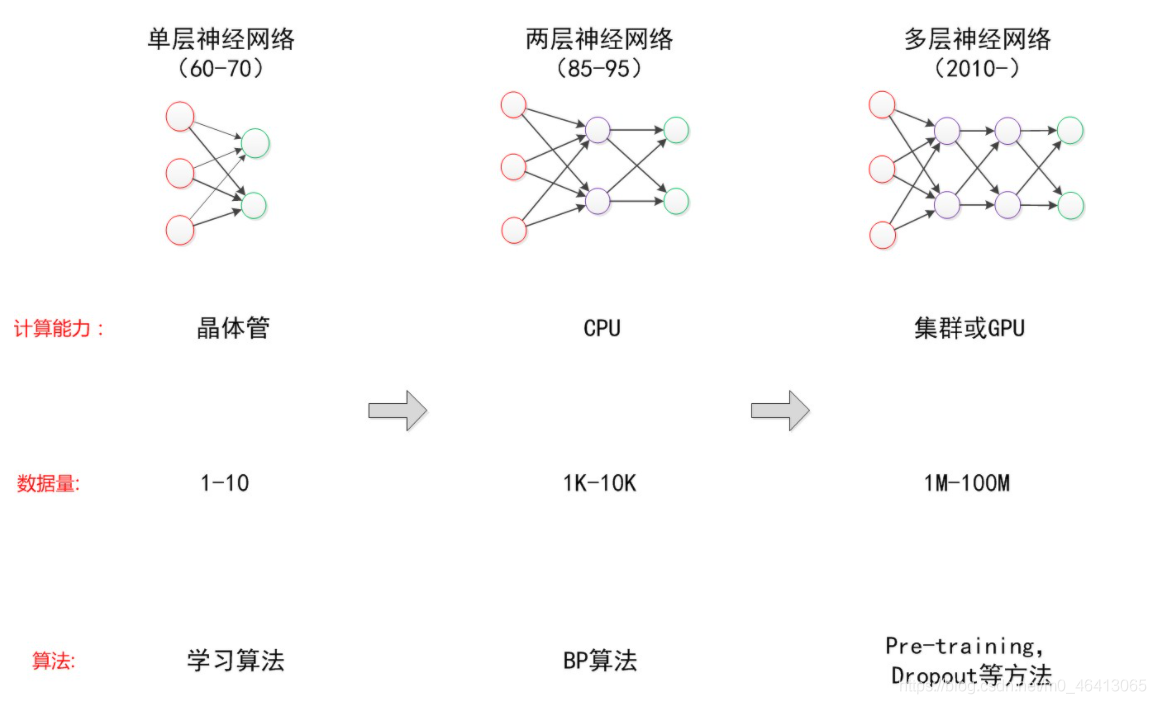
李老師首先給我們介紹了深度學習的起起伏伏(發展史)這里參考網上的一張圖片:
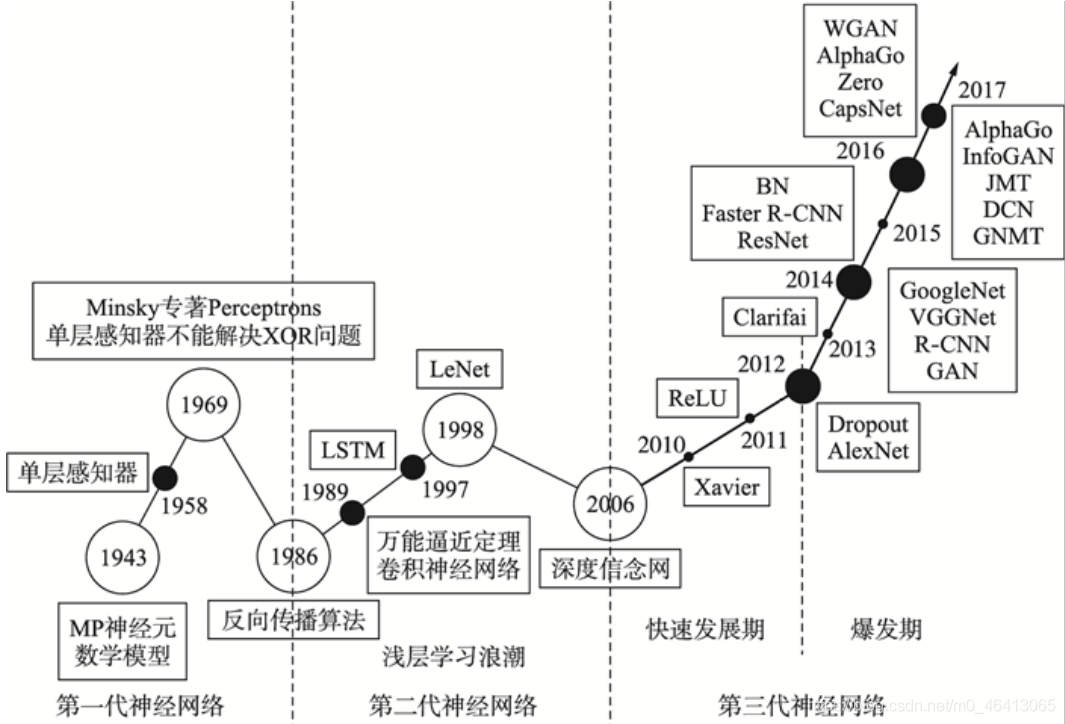
- 1958:Perceptron(linear model),感知機的提出和Logistic Regression類似,只是少了sigmoid的部分1969:Perceptron has limitation,from MIT
- 1980s:Multi-layer Perceptron,多層感知機和今天的DNN很像
- 1986:Backpropagation,反向傳播Hinton propose的Backpropagation 存在problem:通常超過3個layer的neural network,就train不出好的結果
- 1989: 1 hidden layer is “good enough”,why deep? 有?提出?個理論:只要neural network有?個hidden layer,它就可以model出任何的function,所以根本沒有必要疊加很多個hidden layer,所以Multi-layer Perceptron的?法?壞掉了,這段時間Multi-layer Perceptron這個東西是受到抵制的
- 2006:RBM initialization(breakthrough):Restricted Boltzmann Machine,受限玻爾茲曼機 Deep learning -> another Multi-layer Perceptron
在當時看來,它們的不同之處在于在做gradient descent的時候選取初始值的?法如果是?RBM,那就是Deep
learning;如果沒有?RBM,就是傳統的Multi-layer Perceptron那實際上呢,RBM?的不是neural network base的?法,?是graphical model,后來?家試驗得多了發現RBM并沒有什么太?的幫助,因此現在基本上沒有?使?RBM做initialization了
RBM最?的貢獻是,它讓?家重新對Deep learning這個model有了興趣(?頭湯的故事)- 2009:GPU加速的發現
- 2011:start to be popular in speech recognition,語?識別領域
- 2012:win ILSVRC image competition,Deep learning開始在影像領域流?開來
聯系前面的機器學習,深度學習的三個步驟跟機器學習基本一致,只不過第一步找Function變成了找Neural Network
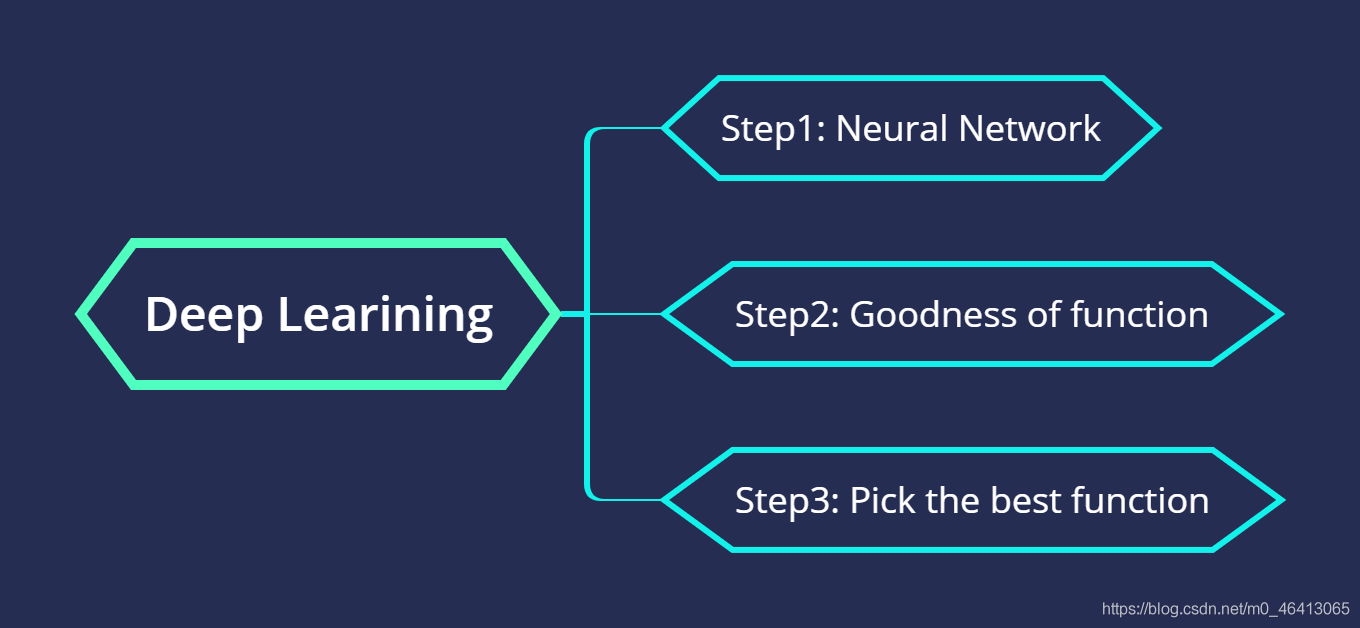
因此,理解Deep Learning在Mechine Learning 上的一大改進就從理解Deep Learning的fuction——Neural Network開始吧!
Neural Network
在這里我們先不按照李老師的講課內容普及一些東西:
縱觀神經網路的發展:(是不是發現跟深度學習的發展神似呢)
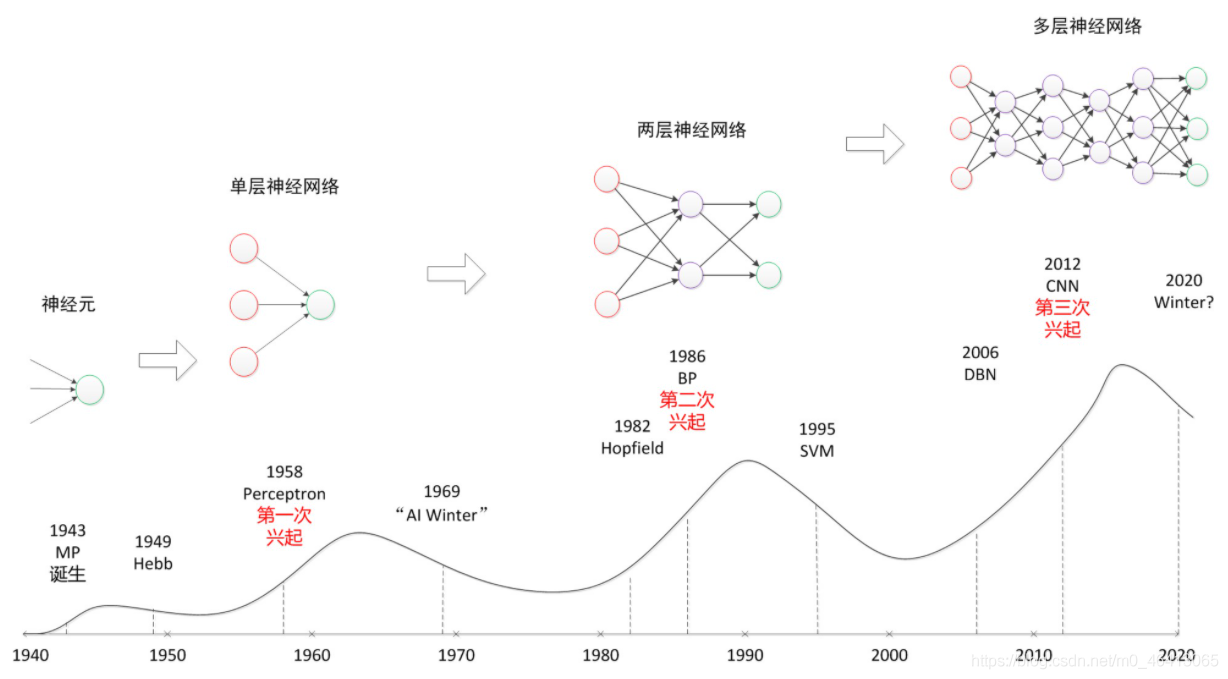
可見,神經網路是深度學習不可缺少的一部分,
在按歷史行程介紹神經網路之前,我們先來熟悉下常見的幾種激活函式
我總結為思維導圖如下:
M-P神經元模型
結構
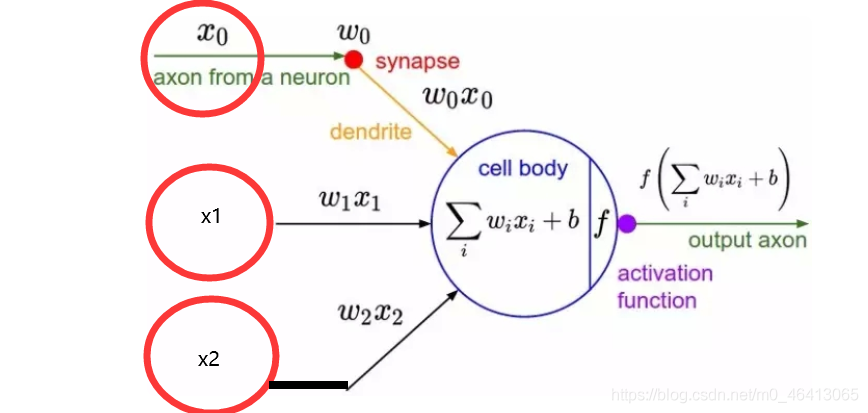
1943年,McCulloch和Pitts構成了一種人工神經元模型,也就是我們現在經常用到的“M-P神經元模型”,如下圖所示:
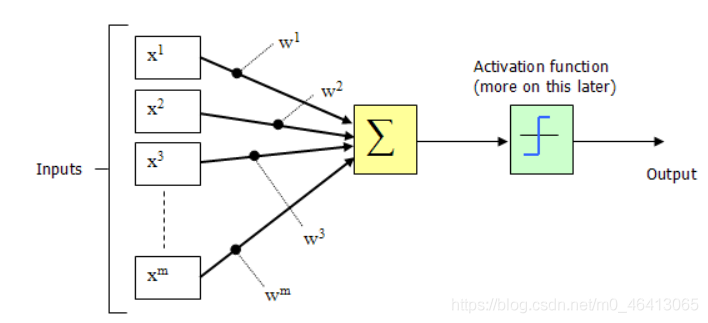
從上圖M-P神經元模型可以看出,神經元的輸出:
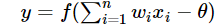
也可以寫成這樣:
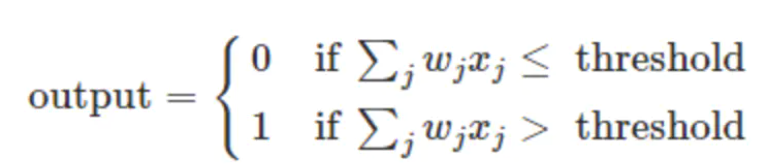
其中θ為我們之前提到的神經元的激活閾值,函式f(?)也被稱為是激活函式,如上圖所示,函式f(?)可以用一個階躍方程表示,大于閾值激活;否則則抑制,但是這樣有點太粗暴,因為階躍函式不光滑,不連續,不可導,因此在后面的探索中我們進化出了幾種較好的常用激活函式,我們在之后會詳細介紹,
以下內容大部分來自博客
下圖是一個典型的神經元模型:包含有3個輸入,1個輸出,以及2個計算功能,
注意中間的箭頭線,這些線稱為“連接”,每個上有一個“權值”,
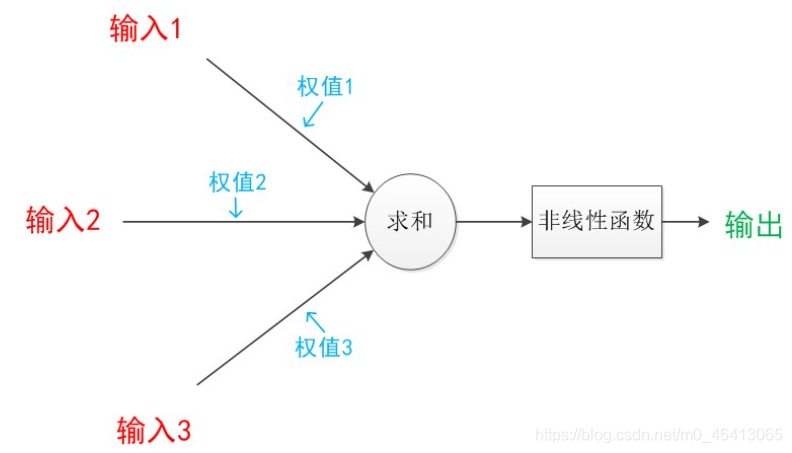
連接是神經元中最重要的東西,每一個連接上都有一個權重,
一個神經網路的訓練演算法就是讓權重的值調整到最佳,以使得整個網路的預測效果最好,
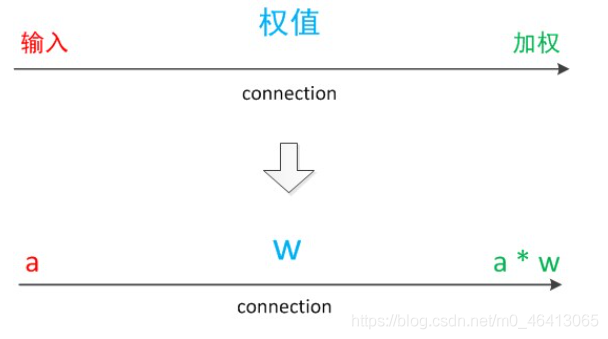
我們使用a來表示輸入,用w來表示權值,一個表示連接的有向箭頭可以這樣理解:在初端,傳遞的信號大小仍然是a,端中間有加權引數w,經過這個加權后的信號會變成aw,因此在連接的末端,信號的大小就變成了aw,
在其他繪圖模型里,有向箭頭可能表示的是值的不變傳遞,而在神經元模型里,每個有向箭頭表示的是值的加權傳遞,
如果我們將神經元圖中的所有變數用符號表示,并且寫出輸出的計算公式的話,就是下圖,
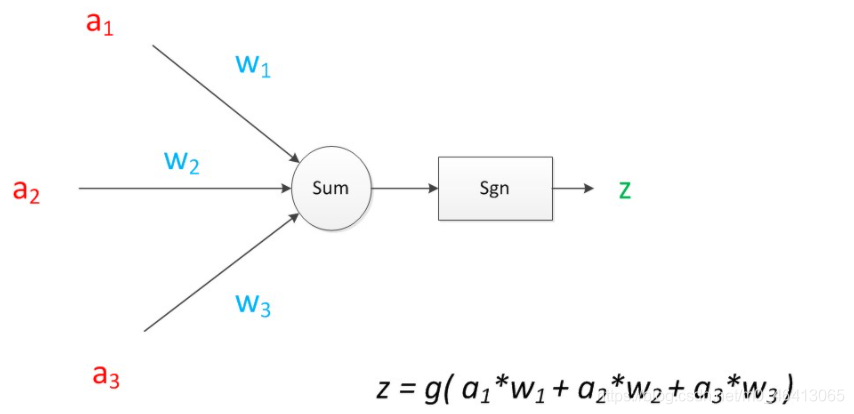
可見z是在輸入和權值的線性加權和疊加了一個函式g的值,在MP模型里,函式g是sgn函式,也就是取符號函式,這個函式當輸入大于0時,輸出1,否則輸出0,
下面對神經元模型的圖進行一些擴展,首先將sum函式與sgn函式合并到一個圓圈里,代表神經元的內部計算,其次,把輸入a與輸出z寫到連接線的左上方,便于后面畫復雜的網路,最后說明,一個神經元可以引出多個代表輸出的有向箭頭,但值都是一樣的,
神經元可以看作一個計算與存盤單元,計算是神經元對其的輸入進行計算功能,存盤是神經元會暫存計算結果,并傳遞到下一層,
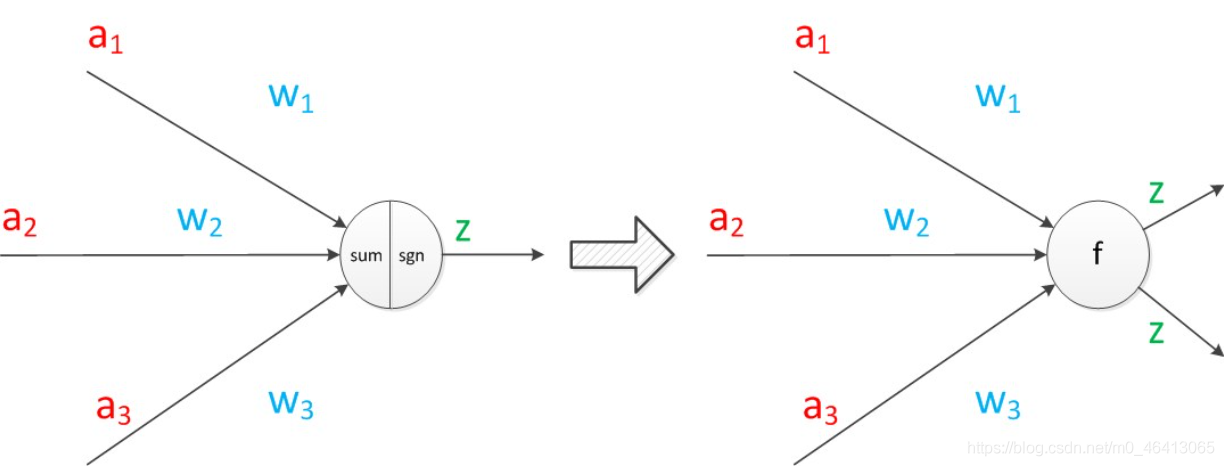
神經元擴展
當我們用“神經元”組成網路以后,描述網路中的某個“神經元”時,我們更多地會用“單元”(unit)來指代,同時由于神經網路的表現形式是一個有向圖,有時也會用“節點”(node)來表達同樣的意思,
效果
神經元模型的使用可以這樣理解:
我們有一個資料,稱之為樣本,樣本有四個屬性,其中三個屬性已知,一個屬性未知,我們需要做的就是通過三個已知屬性預測未知屬性,
具體辦法就是使用神經元的公式進行計算,三個已知屬性的值是a1,a2,a3,未知屬性的值是z,z可以通過公式計算出來,
這里,已知的屬性稱之為特征,未知的屬性稱之為目標,假設特征與目標之間確實是線性關系,并且我們已經得到表示這個關系的權值w1,w2,w3,那么,我們就可以通過神經元模型預測新樣本的目標,
影響
1943年發布的MP模型,雖然簡單,但已經建立了神經網路大廈的地基,但是,MP模型中,權重的值都是預先設定的,因此不能學習,
1949年心理學家Hebb提出了Hebb學習率,認為人腦神經細胞的突觸(也就是連接)上的強度上可以變化的,于是計算科學家們開始考慮用調整權值的方法來讓機器學習,這為后面的學習演算法奠定了基礎,
單層感知機模型(單層神經網路)
結構
從激活函式跳回來,剛剛說到1943年提出了神經元(MP模型)
在原來MP模型的“輸入”位置添加神經元節點,標志其為“輸入單元”,其余不變,于是就得到了1958年的單層感知機模型,這就是單層神經網路,
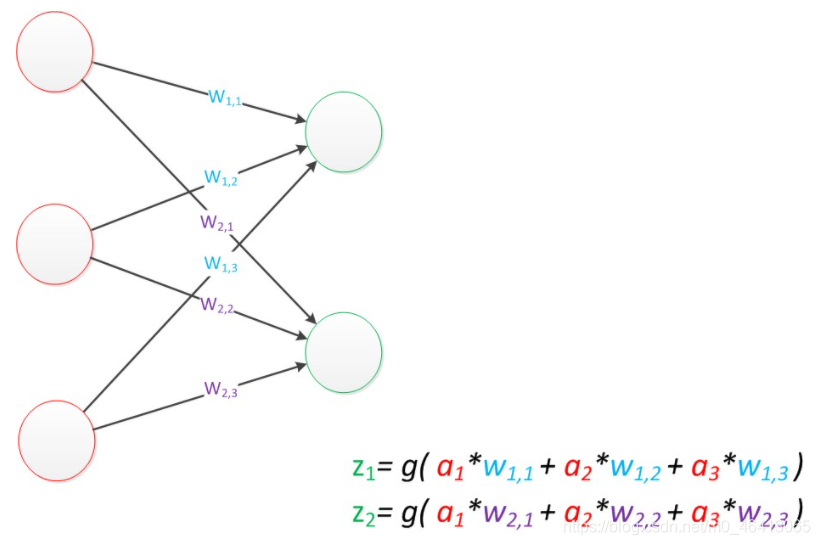
在“感知器”中,有兩個層次,分別是輸入層和輸出層,輸入層里的“輸入單元”只負責傳輸資料,不做計算,輸出層里的“輸出單元”則需要對前面一層的輸入進行計算,
我們把需要計算的層次稱之為“計算層”,并把擁有一個計算層的網路稱之為“單層神經網路”,
假如我們要預測的目標不再是一個值,而是一個向量,那么可以在輸出層再增加一個“輸出單元”,
如果我們仔細看輸出的計算公式,會發現這兩個公式就是線性代數方程組,因此可以用矩陣乘法來表達這兩個公式,
例如,輸入的變數是[a1,a2,a3]T(代表由a1,a2,a3組成的列向量),用向量a來表示,方程的左邊是[z1,z2]T,用向量z來表示,
系數則是矩陣W(2行3列的矩陣,排列形式與公式中的一樣),
于是,輸出公式可以改寫成:g(W * a) = z
這個公式就是神經網路中從前一層計算后一層的矩陣運算,
效果
與神經元模型不同,感知器中的權值是通過訓練得到的,因此,根據以前的知識我們知道,感知器類似一個邏輯回歸模型,可以做線性分類任務,
我們可以用決策分界來形象的表達分類的效果,決策分界就是在二維的資料平面中劃出一條直線,當資料的維度是3維的時候,就是劃出一個平面,當資料的維度是n維時,就是劃出一個n-1維的超平面,
下圖顯示了在二維平面中劃出決策分界的效果,也就是感知器的分類效果,
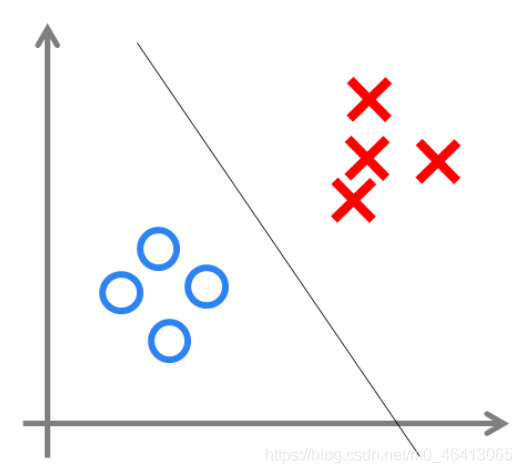
影響
感知器只能做簡單的線性分類任務,但是當時的人們熱情太過于高漲,并沒有人清醒的認識到這點,于是,當人工智能領域的巨擘Minsky指出這點時,事態就發生了變化,

Minsky在1969年出版了一本叫《Perceptron》的書,里面用詳細的數學證明了感知器的弱點,尤其是感知器對XOR(異或)這樣的簡單分類任務都無法解決,
Minsky認為,如果將計算層增加到兩層,計算量則過大,而且沒有有效的學習演算法,所以,他認為研究更深層的網路是沒有價值的,
由于Minsky的巨大影響力以及書中呈現的悲觀態度,讓很多學者和實驗室紛紛放棄了神經網路的研究,神經網路的研究陷入了冰河期,這個時期又被稱為“AI winter”,
接近10年以后,對于兩層神經網路的研究才帶來神經網路的復蘇,
兩層神經網路(多層感知器)
Minsky說過單層神經網路無法解決異或問題,但是當增加一個計算層以后,兩層神經網路不僅可以解決異或問題,而且具有非常好的非線性分類效果,不過兩層神經網路的計算是一個問題,沒有一個較好的解法,
1986年,Rumelhar和Hinton等人提出了反向傳播(Backpropagation,BP)演算法,解決了兩層神經網路所需要的復雜計算量問題,從而帶動了業界使用兩層神經網路研究的熱潮,
結構
兩層神經網路除了包含一個輸入層,一個輸出層以外,還增加了一個中間層,此時,中間層和輸出層都是計算層,我們擴展上節的單層神經網路,在右邊新加一個層次(只含有一個節點),
現在,我們的權值矩陣增加到了兩個,我們用上標來區分不同層次之間的變數,
例如ax(y)代表第y層的第x個節點,z1,z2變成了a1(2),a2(2),下圖給出了a1(2),a2(2)的計算公式,
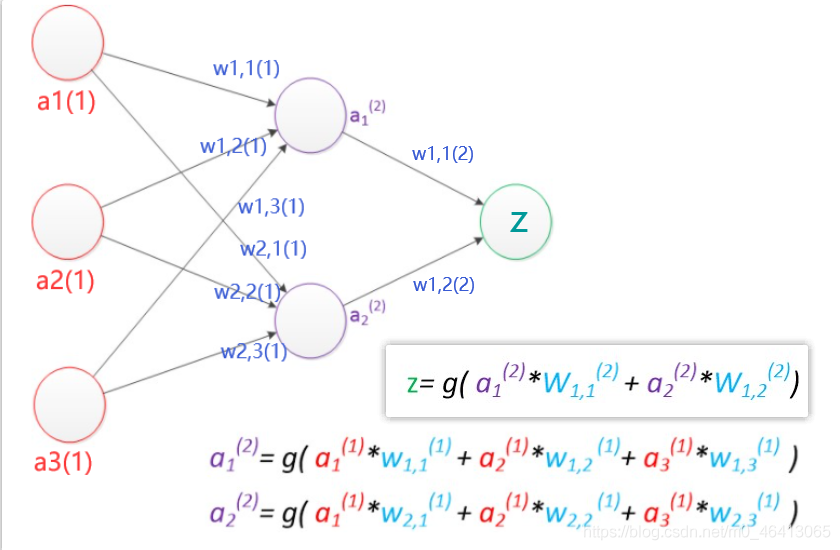
計算最終輸出z的方式是利用了中間層的a1(2),a2(2)和第二個權值矩陣計算得到的.
假設我們的預測目標是一個向量,那么與前面類似,只需要在“輸出層”再增加節點即可,
我們使用向量和矩陣來表示層次中的變數,a(1),a(2),z是網路中傳輸的向量資料,W(1)和W(2)是網路的矩陣引數,如下圖,
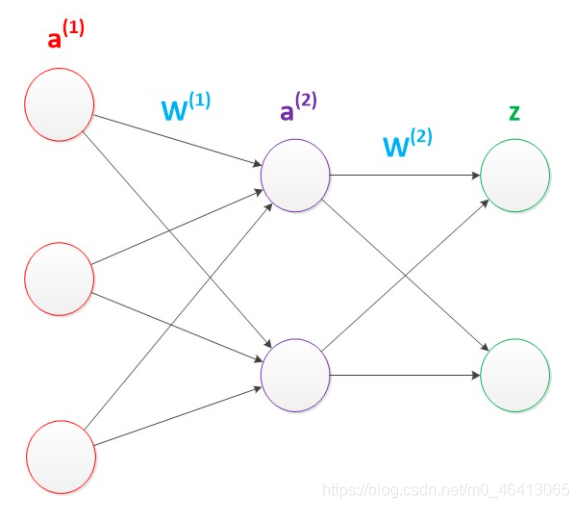
使用矩陣運算來表達整個計算公式的話如下:
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = z;
由此可見,使用矩陣運算來表達是很簡潔的,而且也不會受到節點數增多的影響(無論有多少節點參與運算,乘法兩端都只有一個變數),因此神經網路的教程中大量使用矩陣運算來描述,
需要說明的是,至今為止,我們對神經網路的結構圖的討論中都沒有提到偏置節點(bias unit),事實上,這些節點是默認存在的,它本質上是一個只含有存盤功能,且存盤值永遠為1的單元,在神經網路的每個層次中,除了輸出層以外,都會含有這樣一個偏置單元,正如線性回歸模型與邏輯回歸模型中的一樣,
偏置單元與后一層的所有節點都有連接,我們設這些引數值為向量b,稱之為偏置,如下圖,
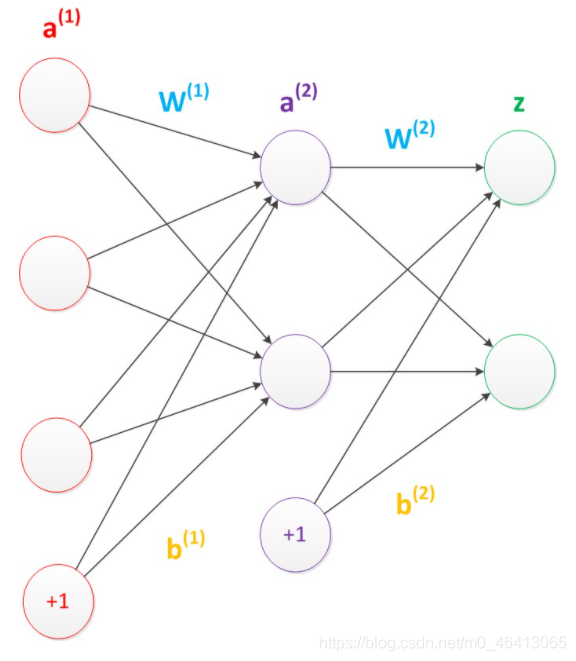
可以看出,偏置節點很好認,因為其沒有輸入(前一層中沒有箭頭指向它),有些神經網路的結構圖中會把偏置節點明顯畫出來,有些不會,一般情況下,我們都不會明確畫出偏置節點,
考慮了偏置以后的一個神經網路的矩陣運算如下:
g(W(1) * a(1) + b(1)) = a(2);
g(W(2) * a(2) + b(2)) = z;
需要說明的是,在兩層神經網路中,我們不再使用sgn函式作為函式g,而是使用平滑函式sigmoid作為函式g,我們把函式g也稱作激活函式(active function),p.s.剛剛介紹了激活函式的思維導圖
事實上,神經網路的本質就是通過引數與激活函式來擬合特征與目標之間的真實函式關系,初學者可能認為畫神經網路的結構圖是為了在程式中實作這些圓圈與線,但在一個神經網路的程式中,既沒有“線”這個物件,也沒有“單元”這個物件,實作一個神經網路最需要的是線性代數庫,
效果
與單層神經網路不同,理論證明,兩層神經網路可以無限逼近任意連續函式,
這是什么意思呢?也就是說,面對復雜的非線性分類任務,兩層(帶一個隱藏層)神經網路可以分類的很好,
下面就是一個例子(此兩圖來自colah的博客),紅色的線與藍色的線代表資料,而紅色區域和藍色區域代表由神經網路劃開的區域,兩者的分界線就是決策分界,
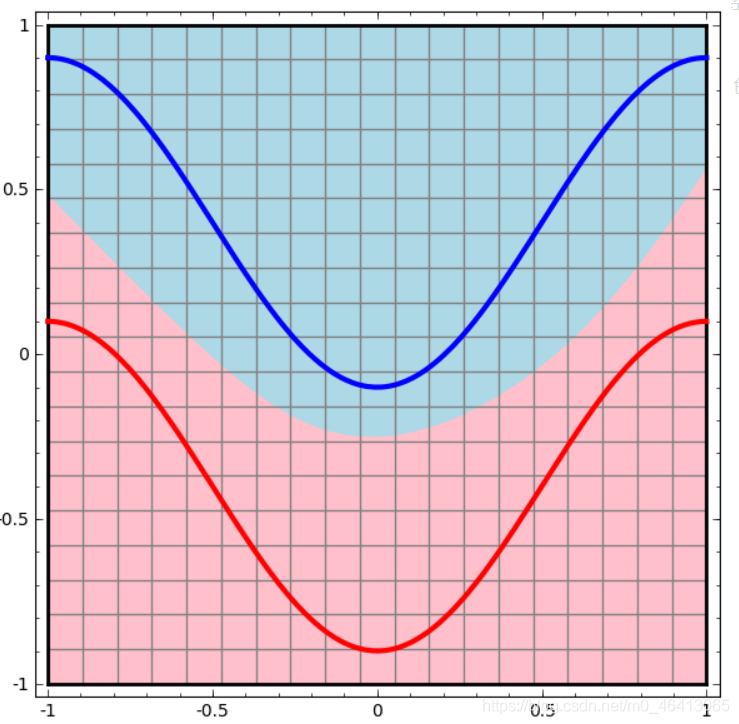
可以看到,這個兩層神經網路的決策分界是非常平滑的曲線,而且分類的很好,有趣的是,前面已經學到過,單層網路只能做線性分類任務,而兩層神經網路中的后一層也是線性分類層,應該只能做線性分類任務,為什么兩個線性分類任務結合就可以做非線性分類任務?
我們可以把輸出層的決策分界單獨拿出來看一下,就是下圖,
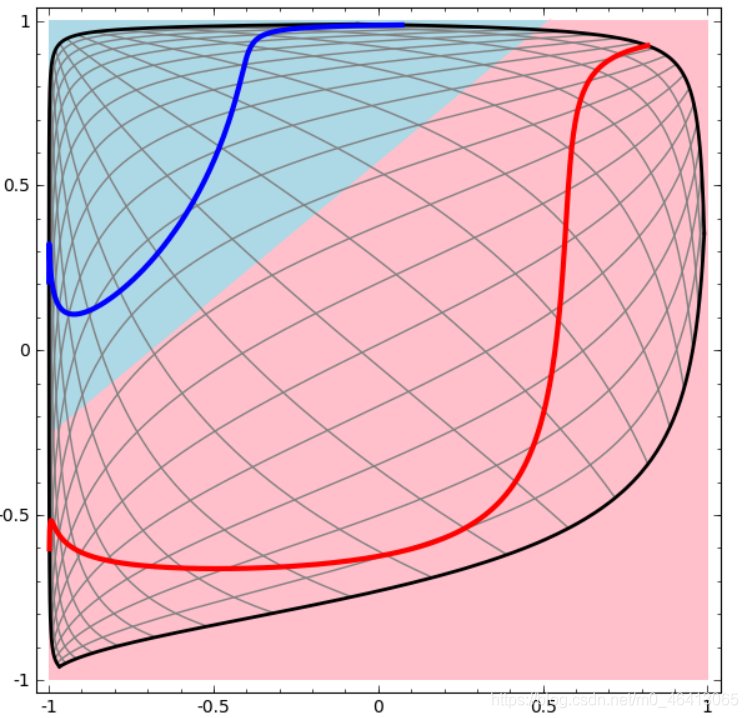
可以看到,輸出層的決策分界仍然是直線,關鍵就是,從輸入層到隱藏層時,資料發生了空間變換,也就是說,兩層神經網路中,隱藏層對原始的資料進行了一個空間變換,使其可以被線性分類,然后輸出層的決策分界劃出了一個線性分類分界線,對其進行分類,
這樣就匯出了兩層神經網路可以做非線性分類的關鍵–隱藏層,聯想到我們一開始推匯出的矩陣公式,我們知道,矩陣和向量相乘,本質上就是對向量的坐標空間進行一個變換,因此,隱藏層的引數矩陣的作用就是使得資料的原始坐標空間從線性不可分,轉換成了線性可分,
兩層神經網路通過兩層的線性模型模擬了資料內真實的非線性函式,因此,多層的神經網路的本質就是復雜函式擬合,
下面來討論一下隱藏層的節點數設計,在設計一個神經網路時,輸入層的節點數需要與特征的維度匹配,輸出層的節點數要與目標的維度匹配,而中間層的節點數,卻是由設計者指定的,因此,“自由”把握在設計者的手中,但是,節點數設定的多少,卻會影響到整個模型的效果,如何決定這個自由層的節點數呢?目前業界沒有完善的理論來指導這個決策,一般是根據經驗來設定,較好的方法就是預先設定幾個可選值,通過切換這幾個值來看整個模型的預測效果,選擇效果最好的值作為最終選擇,這種方法又叫做Grid Search(網格搜索),
訓練
下面簡單介紹一下兩層神經網路的訓練,
在Rosenblat提出的感知器模型中,模型中的引數可以被訓練,但是使用的方法較為簡單,并沒有使用目前機器學習中通用的方法,這導致其擴展性與適用性非常有限,從兩層神經網路開始,神經網路的研究人員開始使用機器學習相關的技術進行神經網路的訓練,例如用大量的資料(1000-10000左右),使用演算法進行優化等等,從而使得模型訓練可以獲得性能與資料利用上的雙重優勢,
機器學習模型訓練的目的,就是使得引數盡可能的與真實的模型逼近,具體做法是這樣的,首先給所有引數賦上隨機值,我們使用這些隨機生成的引數值,來預測訓練資料中的樣本,樣本的預測目標為yp,真實目標為y,那么,定義一個值loss,計算公式如下,
loss = (yp - y)2
這個值稱之為損失(loss),我們的目標就是使對所有訓練資料的損失和盡可能的小,
如果將先前的神經網路預測的矩陣公式帶入到yp中(因為有z=yp),那么我們可以把損失寫為關于引數(parameter)的函式,這個函式稱之為損失函式(loss function),下面的問題就是求:如何優化引數,能夠讓損失函式的值最小,
此時這個問題就被轉化為一個優化問題,一個常用方法就是高等數學中的求導,但是這里的問題由于引數不止一個,求導后計算導數等于0的運算量很大,所以一般來說解決這個優化問題使用的是梯度下降演算法,梯度下降演算法每次計算引數在當前的梯度,然后讓引數向著梯度的反方向前進一段距離,不斷重復,直到梯度接近零時截止,一般這個時候,所有的引數恰好達到使損失函式達到一個最低值的狀態,
在神經網路模型中,由于結構復雜,每次計算梯度的代價很大,因此還需要使用反向傳播演算法,反向傳播演算法是利用了神經網路的結構進行的計算,不一次計算所有引數的梯度,而是從后往前,首先計算輸出層的梯度,然后是第二個引數矩陣的梯度,接著是中間層的梯度,再然后是第一個引數矩陣的梯度,最后是輸入層的梯度,計算結束以后,所要的兩個引數矩陣的梯度就都有了,
反向傳播演算法可以直觀的理解為下圖,梯度的計算從后往前,一層層反向傳播,前綴E代表著相對導數的意思,
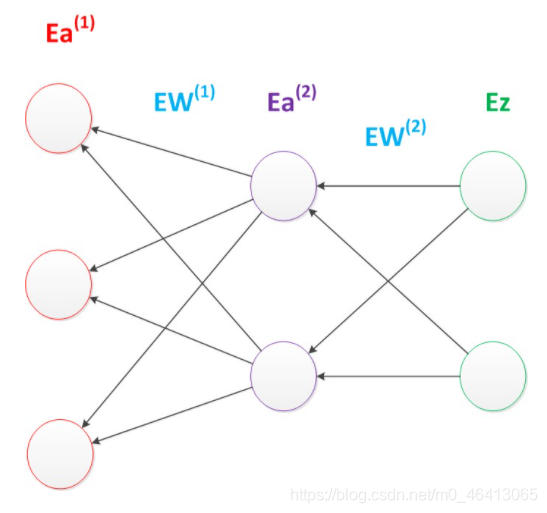
反向傳播演算法的啟示是數學中的鏈式法則,在此需要說明的是,盡管早期神經網路的研究人員努力從生物學中得到啟發,但從BP演算法開始,研究者們更多地從數學上尋求問題的最優解,不再盲目模擬人腦網路是神經網路研究走向成熟的標志,正如科學家們可以從鳥類的飛行中得到啟發,但沒有必要一定要完全模擬鳥類的飛行方式,也能制造可以飛天的飛機,
優化問題只是訓練中的一個部分,機器學習問題之所以稱為學習問題,而不是優化問題,就是因為它不僅要求資料在訓練集上求得一個較小的誤差,在測驗集上也要表現好,因為模型最終是要部署到沒有見過訓練資料的真實場景,提升模型在測驗集上的預測效果的主題叫做泛化(generalization),相關方法被稱作正則化(regularization),神經網路中常用的泛化技術有權重衰減等,
影響
兩層神經網路在多個地方的應用說明了其效用與價值,10年前困擾神經網路界的異或問題被輕松解決,神經網路在這個時候,已經可以發力于語音識別,影像識別,自動駕駛等多個領域,
歷史總是驚人的相似,神經網路的學者們再次登上了《紐約時報》的專訪,人們認為神經網路可以解決許多問題,就連娛樂界都開始受到了影響,當年的《終結者》電影中的阿諾都趕時髦地說一句:我的CPU是一個神經網路處理器,一個會學習的計算機,
但是神經網路仍然存在若干的問題:盡管使用了BP演算法,一次神經網路的訓練仍然耗時太久,而且困擾訓練優化的一個問題就是區域最優解問題,這使得神經網路的優化較為困難,同時,隱藏層的節點數需要調參,這使得使用不太方便,工程和研究人員對此多有抱怨,
90年代中期,由Vapnik等人發明的SVM(Support Vector Machines,支持向量機)演算法誕生,很快就在若干個方面體現出了對比神經網路的優勢:無需調參;高效;全域最優解,基于以上種種理由,SVM迅速打敗了神經網路演算法成為主流,

Vladimir Vapnik
神經網路的研究再次陷入了冰河期,當時,只要你的論文中包含神經網路相關的字眼,非常容易被會議和期刊拒收,研究界那時對神經網路的不待見可想而知,
多層神經網路(深度學習)
p.s. 在這里只論述普通的多層神經網路,
2006年,Hinton在《Science》和相關期刊上發表了論文,首次提出了“深度信念網路”的概念,與傳統的訓練方式不同,“深度信念網路”有一個“預訓練”(pre-training)的程序,這可以方便的讓神經網路中的權值找到一個接近最優解的值,之后再使用“微調”(fine-tuning)技術來對整個網路進行優化訓練,這兩個技術的運用大幅度減少了訓練多層神經網路的時間,他給多層神經網路相關的學習方法賦予了一個新名詞–“深度學習”,
很快,深度學習在語音識別領域暫露頭角,接著,2012年,深度學習技術又在影像識別領域大展拳腳,Hinton與他的學生在ImageNet競賽中,用多層的卷積神經網路成功地對包含一千類別的一百萬張圖片進行了訓練,取得了分類錯誤率15%的好成績,這個成績比第二名高了近11個百分點,充分證明了多層神經網路識別效果的優越性,
在這之后,關于深度神經網路的研究與應用不斷涌現,

Geoffery Hinton
結構
我們延續兩層神經網路的方式來設計一個多層神經網路,
在兩層神經網路的輸出層后面,繼續添加層次,原來的輸出層變成中間層,新加的層次成為新的輸出層,
依照這樣的方式不斷添加,我們可以得到更多層的多層神經網路,公式推導的話其實跟兩層神經網路類似,使用矩陣運算的話就僅僅是加一個公式而已,
在已知輸入a(1),引數W(1),W(2),W(3)的情況下,輸出z的推導公式如下:
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = a(3);
g(W(3) * a(3)) = z;
多層神經網路中,輸出也是按照一層一層的方式來計算,從最外面的層開始,算出所有單元的值以后,再繼續計算更深一層,只有當前層所有單元的值都計算完畢以后,才會算下一層,有點像計算向前不斷推進的感覺,所以這個程序叫做“正向傳播”,
下面討論一下多層神經網路中的引數,
首先我們看第一張圖,可以看出W(1)中有6個引數,W(2)中有4個引數,W(3)中有6個引數,所以整個神經網路中的引數有16個(這里我們不考慮偏置節點,下同),
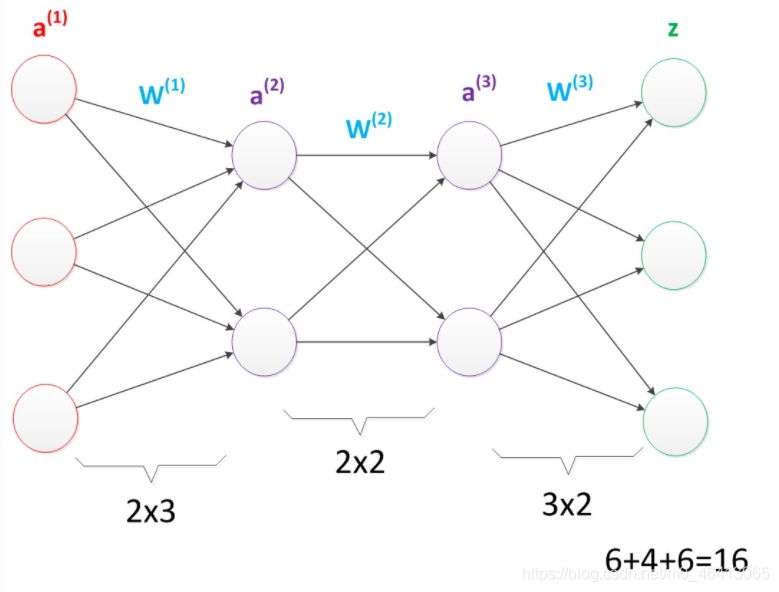 多層神經網路(較少引數)
多層神經網路(較少引數)
假設我們將中間層的節點數做一下調整,第一個中間層改為3個單元,第二個中間層改為4個單元,
經過調整以后,整個網路的引數變成了33個,
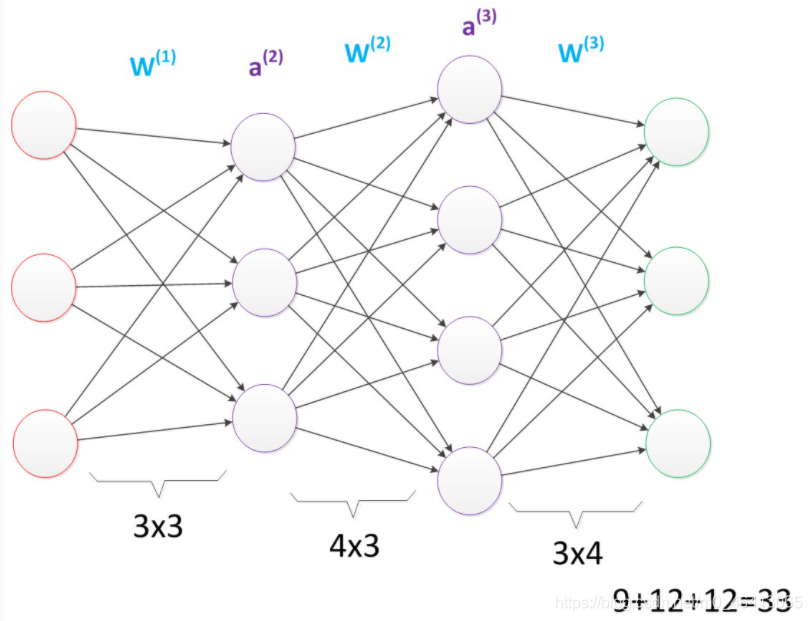
多層神經網路(較多引數)
雖然層數保持不變,但是第二個神經網路的引數數量卻是第一個神經網路的接近兩倍之多,從而帶來了更好的表示(represention)能力,表示能力是多層神經網路的一個重要性質,下面會做介紹,
在引數一致的情況下,我們也可以獲得一個“更深”的網路,
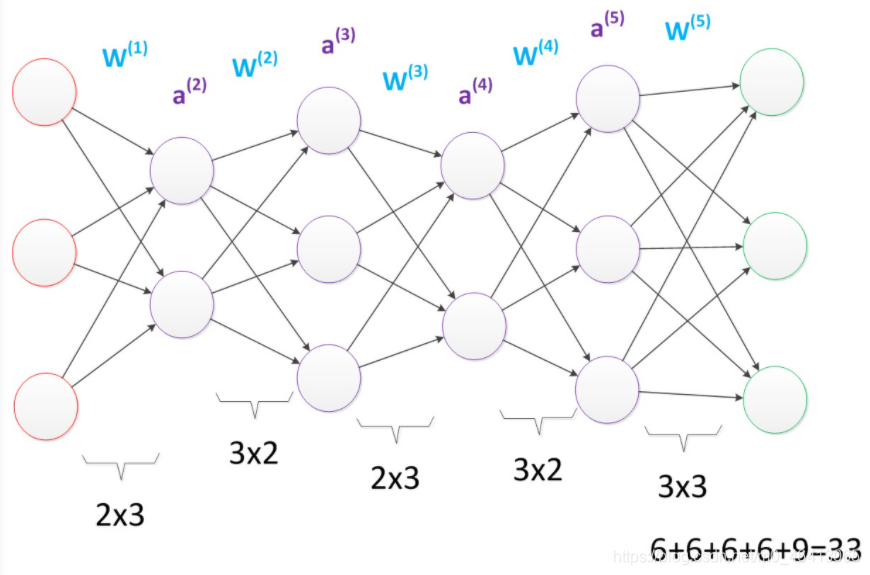
多層神經網路(更深的層次)
上圖的網路中,雖然引數數量仍然是33,但卻有4個中間層,是原來層數的接近兩倍,這意味著一樣的引數數量,可以用更深的層次去表達,
效果
與兩層層神經網路不同,多層神經網路中的層數增加了很多,
增加更多的層次有什么好處?更深入的表示特征,以及更強的函式模擬能力,
更深入的表示特征可以這樣理解,隨著網路的層數增加,每一層對于前一層次的抽象表示更深入,在神經網路中,每一層神經元學習到的是前一層神經元值的更抽象的表示,例如第一個隱藏層學習到的是“邊緣”的特征,第二個隱藏層學習到的是由“邊緣”組成的“形狀”的特征,第三個隱藏層學習到的是由“形狀”組成的“圖案”的特征,最后的隱藏層學習到的是由“圖案”組成的“目標”的特征,通過抽取更抽象的特征來對事物進行區分,從而獲得更好的區分與分類能力,
關于逐層特征學習的例子,可以參考下圖,
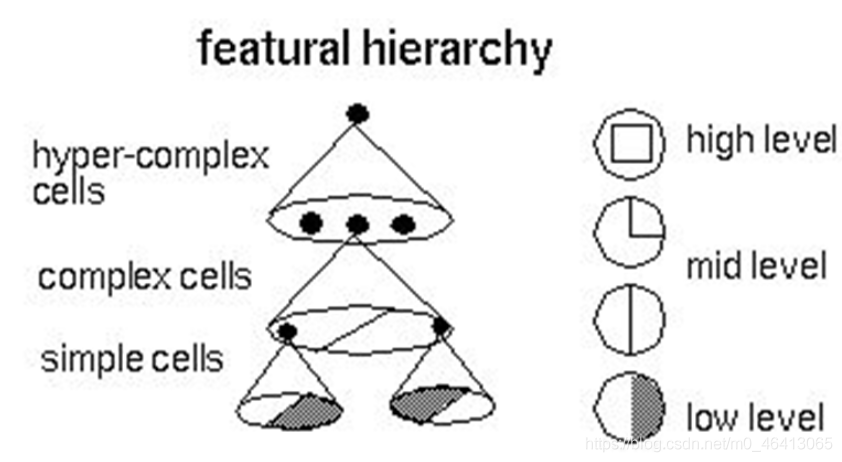
多層神經網路(特征學習)
更強的函式模擬能力是由于隨著層數的增加,整個網路的引數就越多,而神經網路其實本質就是模擬特征與目標之間的真實關系函式的方法,更多的引數意味著其模擬的函式可以更加的復雜,可以有更多的容量(capcity)去擬合真正的關系,
通過研究發現,在引數數量一樣的情況下,更深的網路往往具有比淺層的網路更好的識別效率,這點也在ImageNet的多次大賽中得到了證實,從2012年起,每年獲得ImageNet冠軍的深度神經網路的層數逐年增加,2015年最好的方法GoogleNet是一個多達22層的神經網路,
在最新一屆的ImageNet大賽上,目前拿到最好成績的MSRA團隊的方法使用的更是一個深達152層的網路!關于這個方法更多的資訊有興趣的可以查閱ImageNet網站,
訓練
在單層神經網路時,我們使用的激活函式是sgn函式,到了兩層神經網路時,我們使用的最多的是sigmoid函式,而到了多層神經網路時,通過一系列的研究發現,ReLU函式在訓練多層神經網路時,更容易收斂,并且預測性能更好,因此,目前在深度學習中,最流行的非線性函式是ReLU函式,ReLU函式不是傳統的非線性函式,而是分段線性函式,其運算式非常簡單,就是y=max(x,0),簡而言之,在x大于0,輸出就是輸入,而在x小于0時,輸出就保持為0,這種函式的設計啟發來自于生物神經元對于激勵的線性回應,以及當低于某個閾值后就不再回應的模擬,
在多層神經網路中,訓練的主題仍然是優化和泛化,當使用足夠強的計算芯片(例如GPU圖形加速卡)時,梯度下降演算法以及反向傳播演算法在多層神經網路中的訓練中仍然作業的很好,目前學術界主要的研究既在于開發新的演算法,也在于對這兩個演算法進行不斷的優化,例如,增加了一種帶動量因子(momentum)的梯度下降演算法,
在深度學習中,泛化技術變的比以往更加的重要,這主要是因為神經網路的層數增加了,引數也增加了,表示能力大幅度增強,很容易出現過擬合現象,因此正則化技術就顯得十分重要,目前,Dropout技術,以及資料擴容(Data-Augmentation)技術是目前使用的最多的正則化技術,
影響
目前,深度神經網路在人工智能界占據統治地位,但凡有關人工智能的產業報道,必然離不開深度學習,神經網路界當下的四位引領者除了前文所說的Ng,Hinton以外,還有CNN的發明人Yann Lecun,以及《Deep Learning》的作者Bengio,
前段時間一直對人工智能持謹慎態度的馬斯克,搞了一個OpenAI專案,邀請Bengio作為高級顧問,馬斯克認為,人工智能技術不應該掌握在大公司如Google,Facebook的手里,更應該作為一種開放技術,讓所有人都可以參與研究,馬斯克的這種精神值得讓人敬佩,

Yann LeCun(左)和 Yoshua Bengio(右)
多層神經網路的研究仍在進行中,現在最為火熱的研究技術包括RNN,LSTM等,研究方向則是影像理解方面,影像理解技術是給計算機一幅圖片,讓它用語言來表達這幅圖片的意思,ImageNet競賽也在不斷召開,有更多的方法涌現出來,重繪以往的正確率,
總結
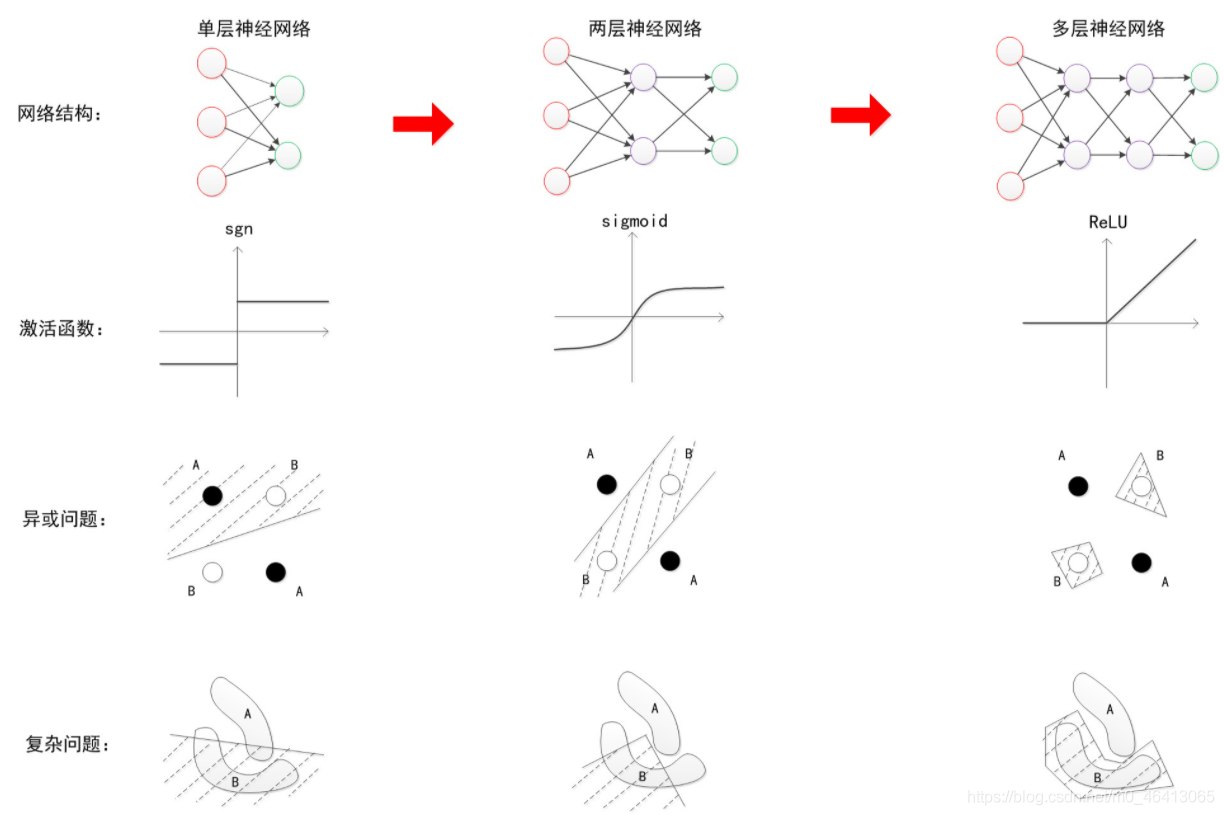
對上面的用下面兩個圖總結一下:
從單層神經網路,到兩層神經網路,再到多層神經網路,下圖說明了,隨著網路層數的增加,以及激活函式的調整,神經網路所能擬合的決策分界平面的能力逐漸增強,
神經網路的發展背后的外在原因可以被總結為:更強的計算性能,更多的資料,以及更好的訓練方法,
上面參考了博主目前看過寫的最好的神經網路的文章內容,接下來回歸李宏毅老師的課程:
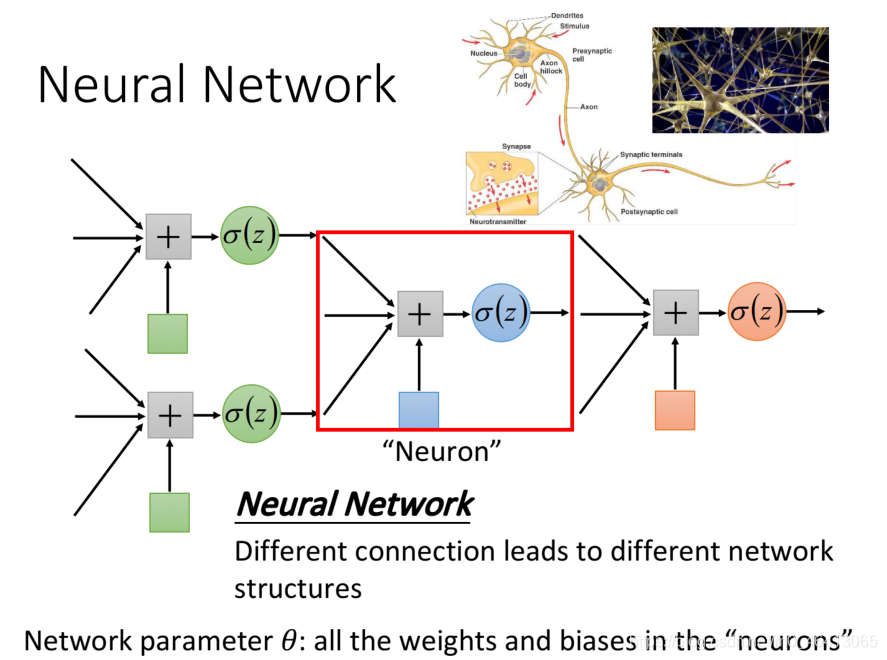
李宏毅老師定義
李老師把多個Logistic Regression前后connect在?起稱之為neural network,?個Logistic Regression稱之為neuron,neural network?的每?個Logistic Regression都有??的weight和bias,這些weight和bias集合起來,就是這個network的parameter,我們?θ來描述
Fully Connect Feedforward Network(全連接前饋?絡)
接下來李老師介紹了一種最常見的神經網路模型Fully Connect Feedforward Network(全連接前饋?絡)
解釋下名詞
- Fully connected: layer和layer之間,所有的neuron都是兩兩連接
- Feedforward: 傳遞的?向是從layer 1->2->3,由前往后傳,且沒有反饋(feedback)
(不會根據輸出結果對輸入結果的影響來進一步調整輸出結果)
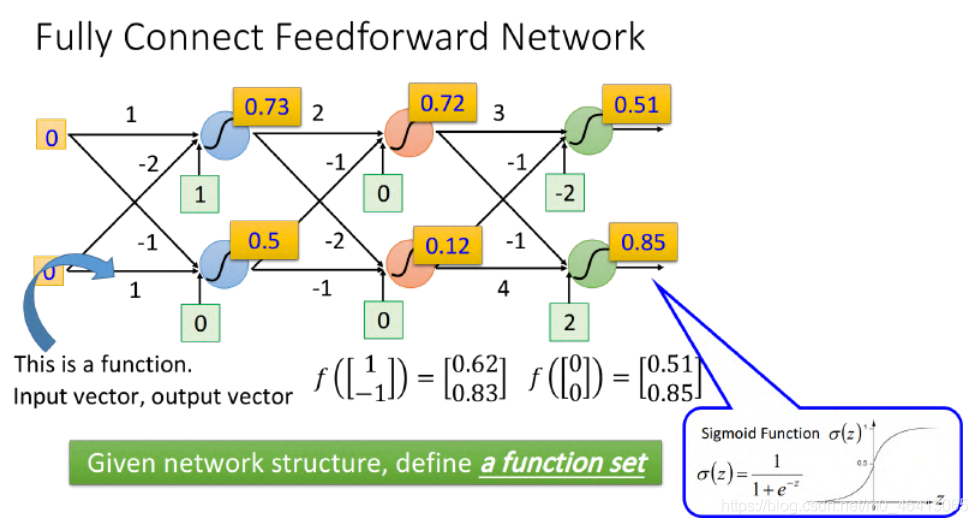
在這里李宏毅點明了神經網路和function的關系:
- ?個確定引數θ(weight和bias已知)的neural network是?個確定的function
- 一個未確定引數,但確定了結構的network structure是了?個function set(model)
(設定不同的引數,它就變成了不同的function,把這些可能的function集合起來,我們就得到了?個function set)
好處是?neural network決定function set的時候,這個function set是?較?的,它包含了很多原來你做Logistic Regression、做linear Regression所沒有辦法包含的function
這種由神經網路確定的function的input是?個vector,output是另?個vector,這個vector??放的是樣本點的feature,vector的dimension就是feature的個數
下圖中,每?排表??個layer,每個layer??的每?個球都代表?個neuron,layer和layer之間neuron是 兩兩互相連接 的,layer 1的neuron output會連接給layer 2的每?個neuron作為input
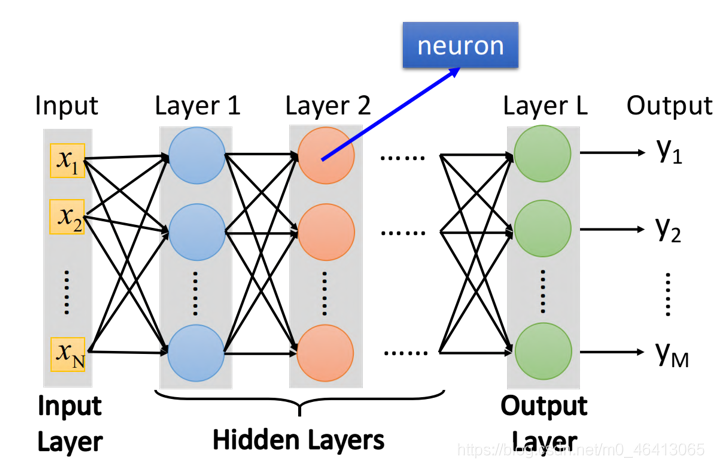
在這里我介紹一下關于神經網路的一些名詞:
- input layer(輸?層):input某個feature的vector的地?
(嚴格來說input layer其實不是?個layer,它跟其他layer不?樣,不是由neuron所組成的) - output layer(輸出層):最后那個layer L,由于它后?沒有接其它東西了,所以它的output就是整個network的output
- hidden layer(隱藏層):除輸入層和輸出層以外的其他層,對layer 1的每?個neuron來說,它的input就是input layer的每?個dimension
- DNN(Deep Neural Network):有很多層layers的neural network
那所謂的deep,是什么意思呢?有很多層hidden layer,就叫做deep,具體的層數并沒有規定,現在只要是neural network base的?法,都被稱為Deep Learning,下圖是?些model使?的hidden layers層數舉例:
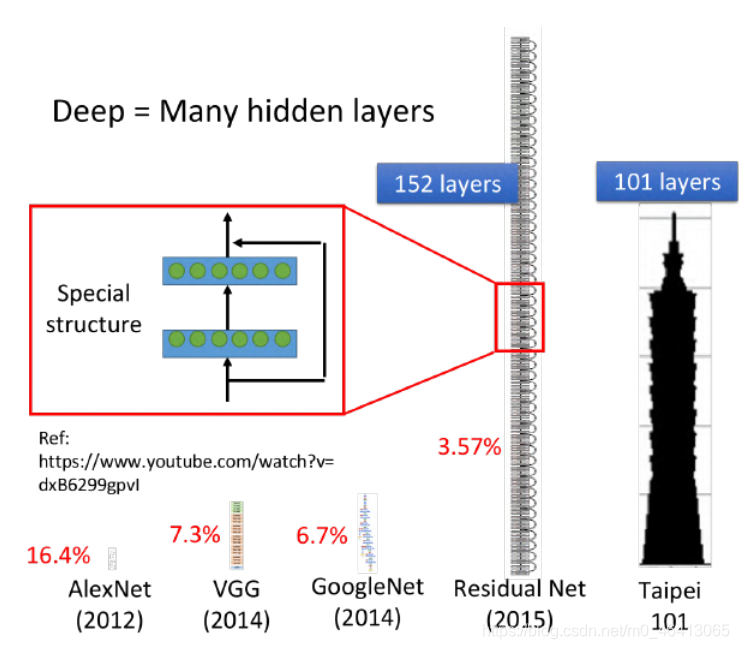
你會發現使?了152個hidden layers的Residual Net,它識別影像的準確率??類還要?當然它不是使
??般的Fully Connected Feedforward Network,它需要設計特殊的special structure才能訓練這么深的network
激勵函式
- activation function(激勵函式):在神經網路中,隱層和輸出層節點的輸入和輸出之間具有函式關系,這個函式稱為激勵函式(Activation Function),
這里就激勵函式延申一下:
- 激勵函式在神經網路的作用:將多個線性輸入轉換為非線性的關系, 不使用激勵函式的話,神經網路的每層都只是做線性變換,多層輸入疊加后也還是線性變換,因為線性模型的表達能力不夠,激勵函式可以引入非線性因素,
什么?還不夠形象?博主在這里參考我看過最形象的解釋:
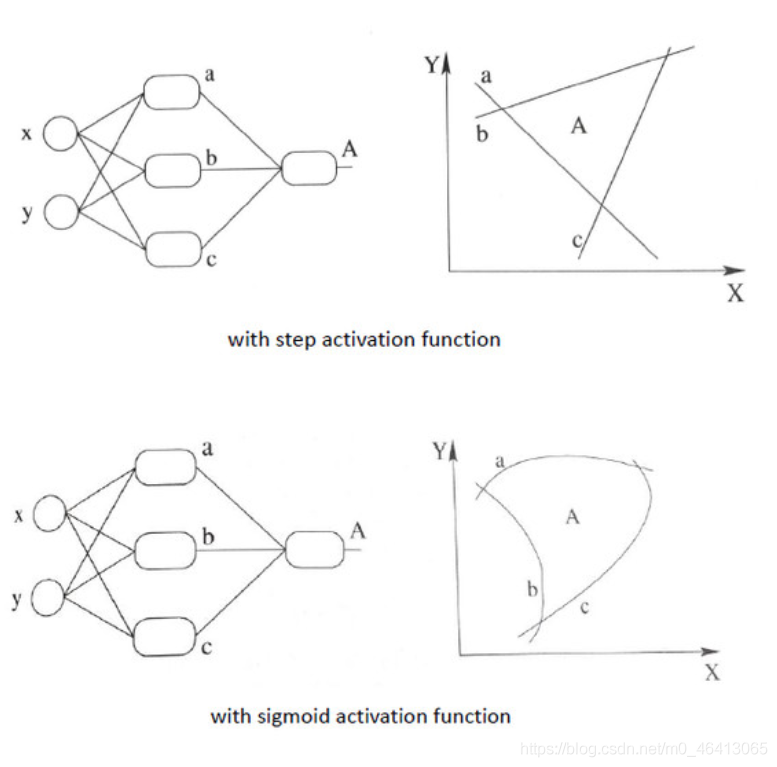
無激勵函式的神經網路
神經網路最簡單的結構就是單輸出的單層感知機,單層感知機只有輸入層和輸出層,分別代表了神經感受器和神經中樞,下圖是一個只有2個輸入單元和1個輸出單元的簡單單層感知機,圖中x1、w2代表神經網路的輸入神經元受到的刺激,w1、w2代表輸入神經元和輸出神經元間連接的緊密程度,b代表輸出神經元的興奮閾值,y為輸出神經元的輸出,我們使用該單層感知機劃出一條線將平面分割開,如圖所示:
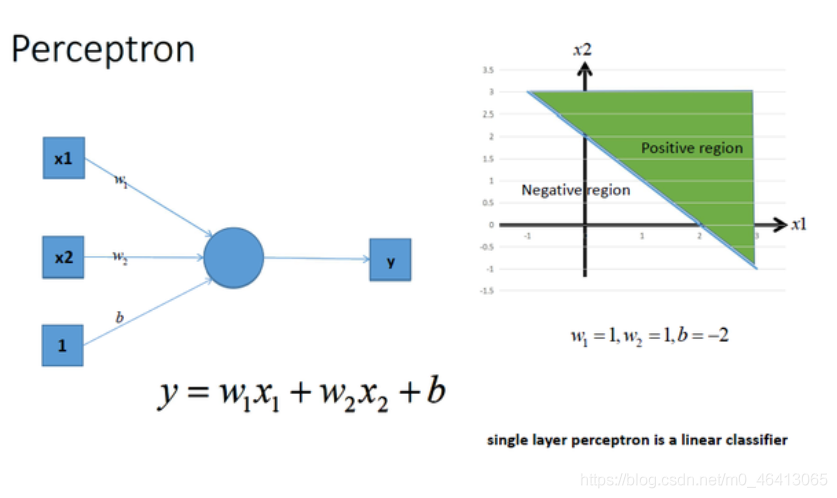
同理,我們也可以將多個感知機(注意,不是多層感知機)進行組合獲得更強的平面分類能力,如圖所示:
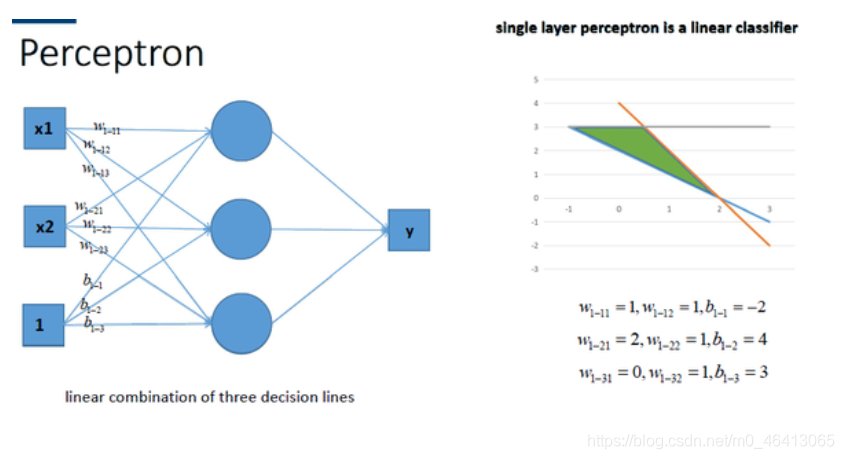
再看看包含一個隱層的多層感知機的情況,如圖所示:
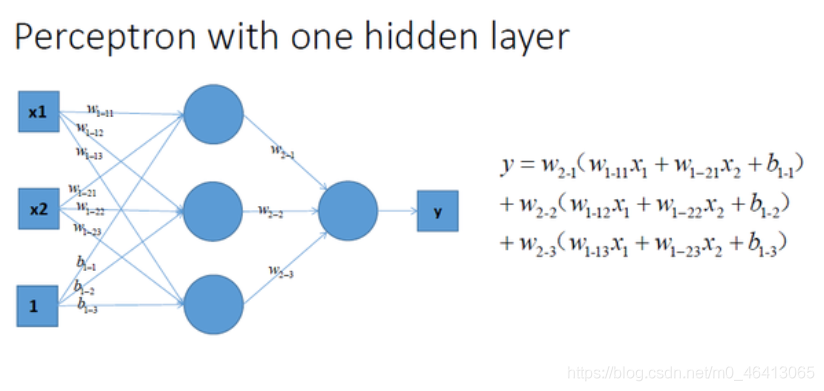
仔細看的話不難發現,上面三種沒有激勵函式的神經網路的輸出是線性方程,其在用復雜的線性組合來逼近曲線,
有激勵函式的神經網路
我們在神經網路每一層神經元做完線性變換以后,加上一個非線性激勵函式對線性變換的結果進行轉換,那么輸出就是一個不折不扣的非線性函式了,如圖所示:
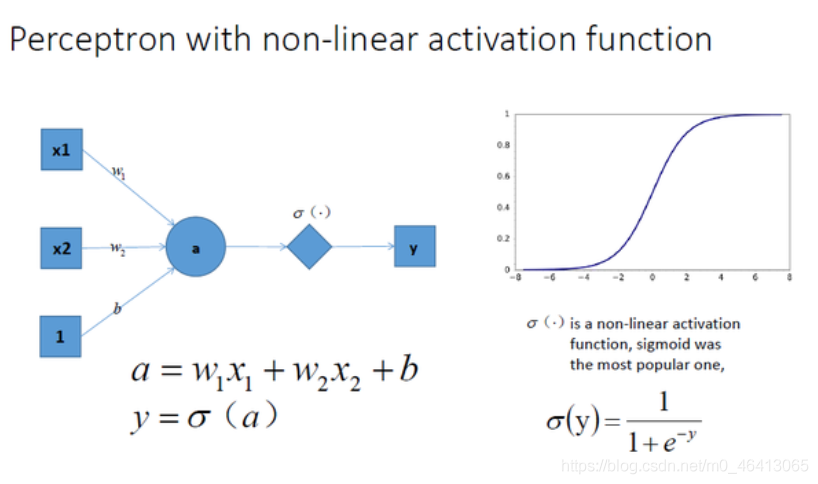
拓展到多層神經網路的情況, 更剛剛一樣的結構, 加上非線性激勵函式之后, 輸出就變成了一個復雜的非線性函式了,如圖所示:
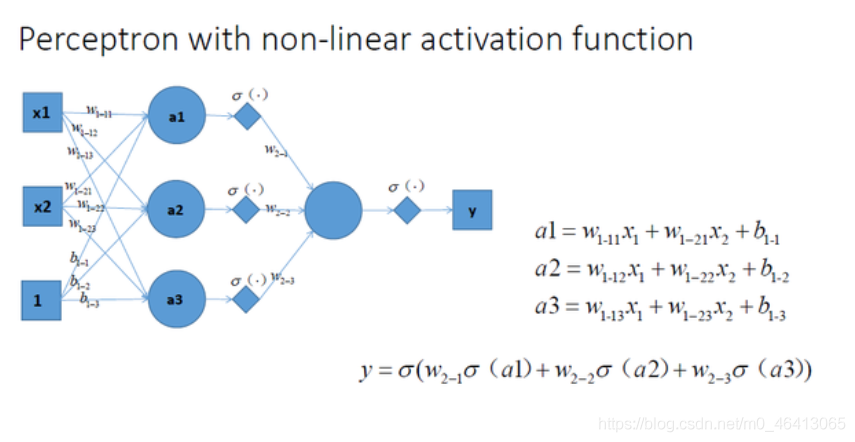
加入非線性激勵函式后,神經網路就有可能學習到平滑的曲線來分割平面,而不是用復雜的線性組合逼近平滑曲線來分割平面, 這就是為什么我們要有非線性的激活函式的原因,如下圖所示說明加入非線性激活函式后的差異,上圖為用線性組合逼近平滑曲線來分割平面,下圖為平滑的曲線來分割平面:
友情提示:
這里的激勵函式不?得?定是sigmoid function,還可以是其他function(sigmoid function是從Logistic Regression遷移過來的,現在已經較少在Deep learning?使?了,具體的常用激活函式,我總結為思維導圖如下:
Activation Function Mindmap(干貨!!!)
Matrix Operation
network的運作程序,我們通常會?Matrix Operation來表?,以下圖為例,假設第?層hidden layers的兩個neuron,它們的weight分別是w1=1,w2=2,w1’=-1,w2’=1,那就可以把它們排成?個matrix:
[
1
?
2
?
1
1
]
\left[ \begin{matrix} 1 & -2 \\ -1 & 1 \\ \end{matrix} \right]
[1?1??21?]
?我們的input?是?個2*1的vector:
[
1
?
1
]
\left[ \begin{matrix} 1 \\ -1 \\ \end{matrix} \right]
[1?1?]將w和x相乘,再加上bias的vector:
[
1
?
1
]
\left[ \begin{matrix} 1 \\ -1 \\ \end{matrix} \right]
[1?1?]就可以得到這?層的vector z,再經過activation function得到這?層的output:
(activation function可以是很多型別的function,這?還是?Logistic Regression遷移過來的sigmoid function作為運算)
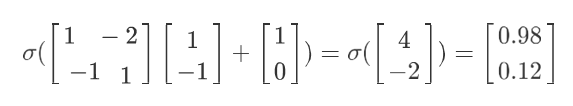
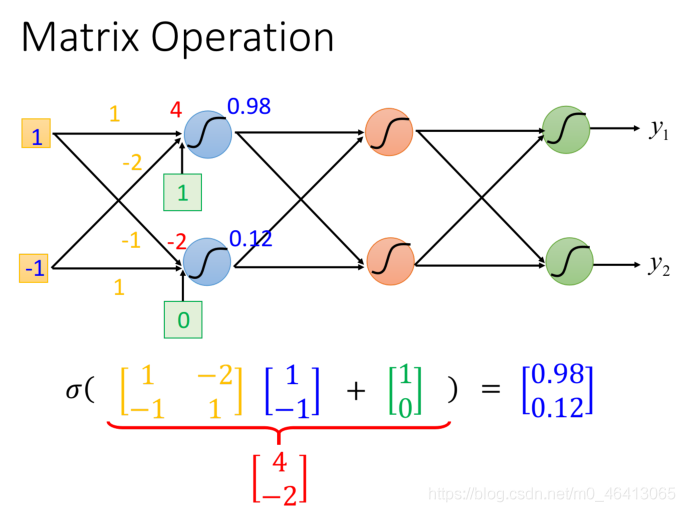
這?我們把所有的變數都以matrix的形式表?出來
Wi的matrix:
- 每??對應的是?個neuron的weight
- ?數就是feature的個數
(也是neuron的個數,neuron的本質就是把feature transform到另?個space)
input x,bias b和output y都是?個列向量
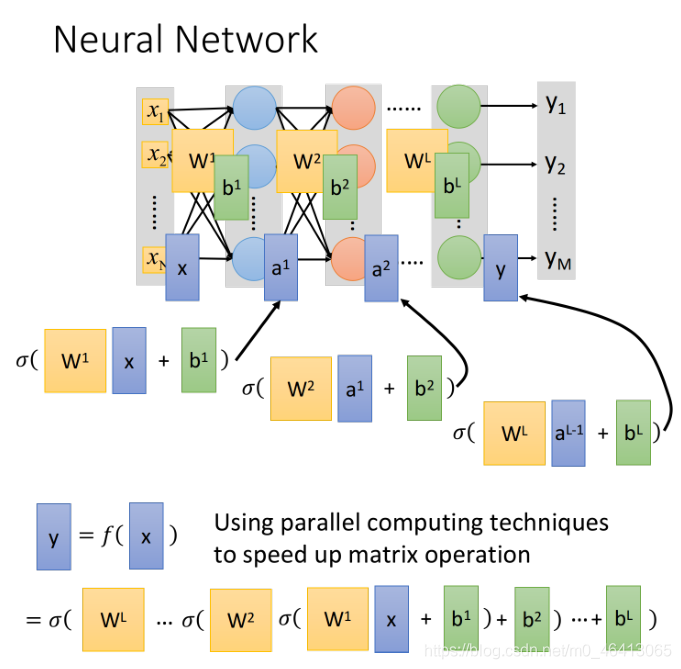
為什么非要表示成矩陣的形式呢?GPU對matrix的運算是?CPU要來的快的,所以我們寫neural network的時候,習慣把它寫成matrix operation,然后call GPU來加速它
Output Layer
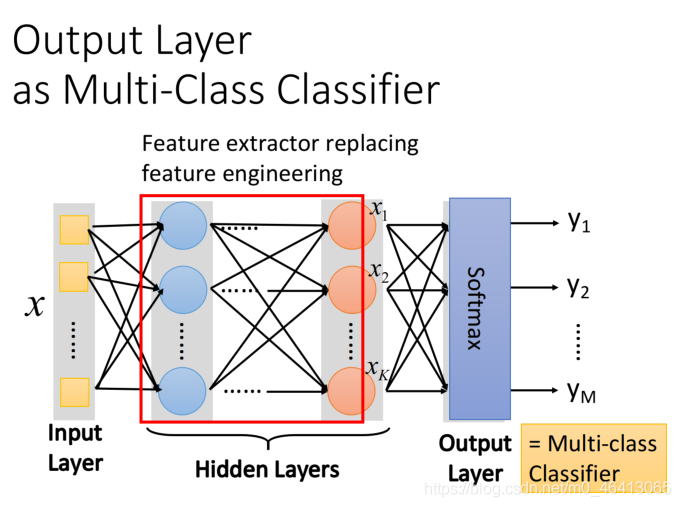
-
hidden layers -> feature extractor(特征提取器)
這個feature extractor就replace了我們之前?動做feature engineering,feature transformation這些事情,經過這個feature extractor得到的 就可以被當作?組新的feature -
output layer->Multi-class classifier
拿經過feature extractor轉換后的那?組?較好的feature(能夠被很好地separate)進?分類的
由于我們把output layer看做是?個Multi-class classifier,所以我們會在最后?個layer加上softmax
Backpropagation(反向傳播)
其實Backpropagation就是DL中的gradient decent演算法
因為network parameters θ=w1,w2,…,b1,b2,…??可能會有將近million個引數,所以我們引入這種比較有效率的gradient decent演算法,使得在計算這個近百萬維的gradient的vector的時候更有效率
Chain Rule
Backpropagation??的公式推演,唯?需要的就只有Chain Rule(鏈式法則)
在這里,博主又找了一篇博客來給你們回顧一下:
1 復合函式
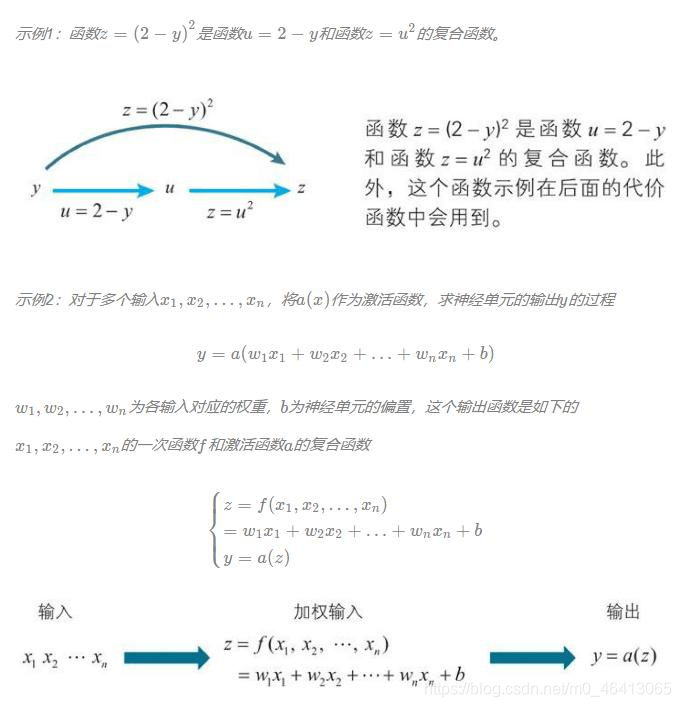
已知函式y=f(u),當u表示為u=g(x)時,y作為x的函式就可以表示為y=f(g(x))這樣的嵌套結構,這種嵌套結構的函式,就稱為f(u)、g(x)的復合函式,
2 鏈式法則
2.1 單變數函式鏈式法則
已知單變數函式y=f(u),當uu表示為單變數函式u=g(x)時,復合函式f(g(x))的導函式可以如下簡單地求出來,
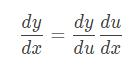
上面這個公式稱為單變數函式的復合函式求導公式,也稱為鏈式法則,
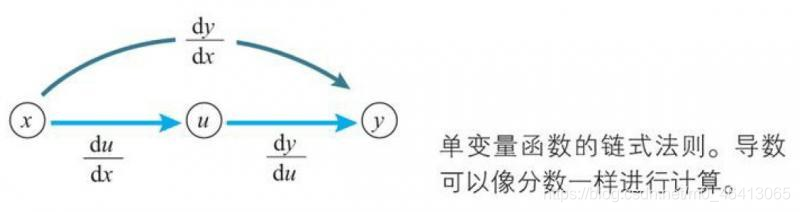
公式的右邊,如果將dx、dy、du都看作一個單獨的字母,那么公式的左邊可以看作將右邊進行簡單的約分的結果,這個看法總是成立的,通過將導數用dx、dy等表示,我們可以這樣記憶鏈式法則:復合函式的導數可以像分數一樣使用約分,但是這個約分的法則不適用于dx、dy的平方等情形,
下面我們來試試對sigmoid與wx+b的復合函式進行求導吧

2.2 多變數函式鏈式法則
在多變數函式的情況下,鏈式法則的思想也同樣適用,只要像處理分數一樣對導數的式子進行變形就行了,但是事情并沒有想的那么簡單,因為必須要對相關的全部變數應用鏈式法則,
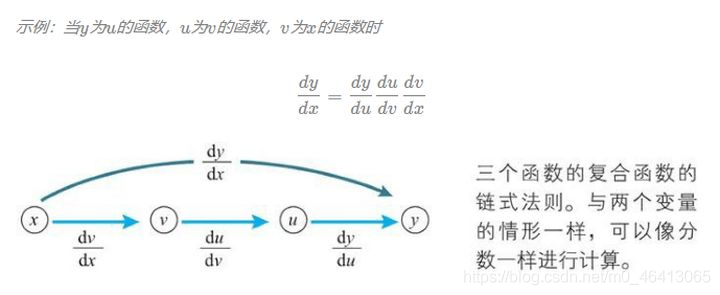
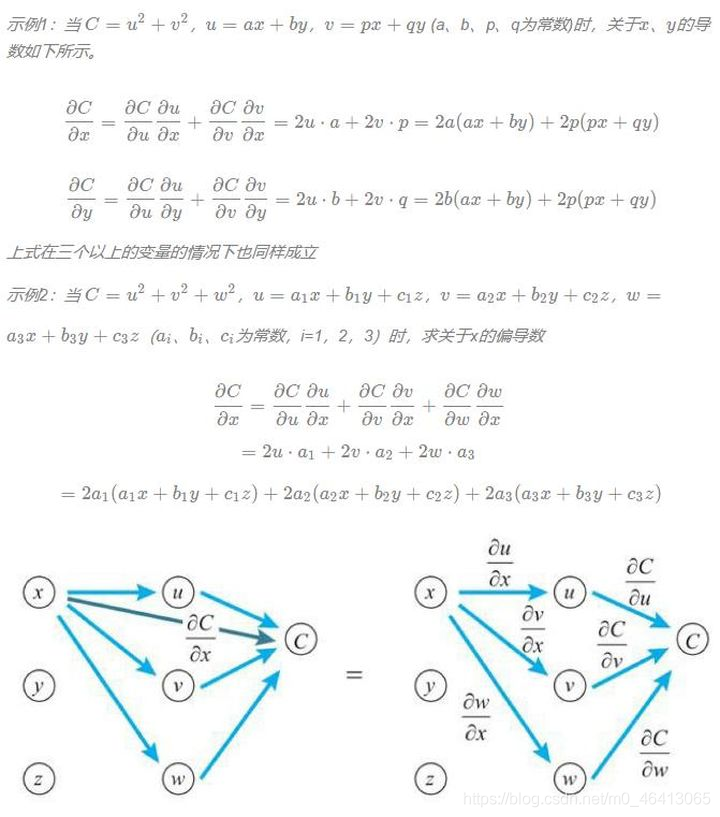
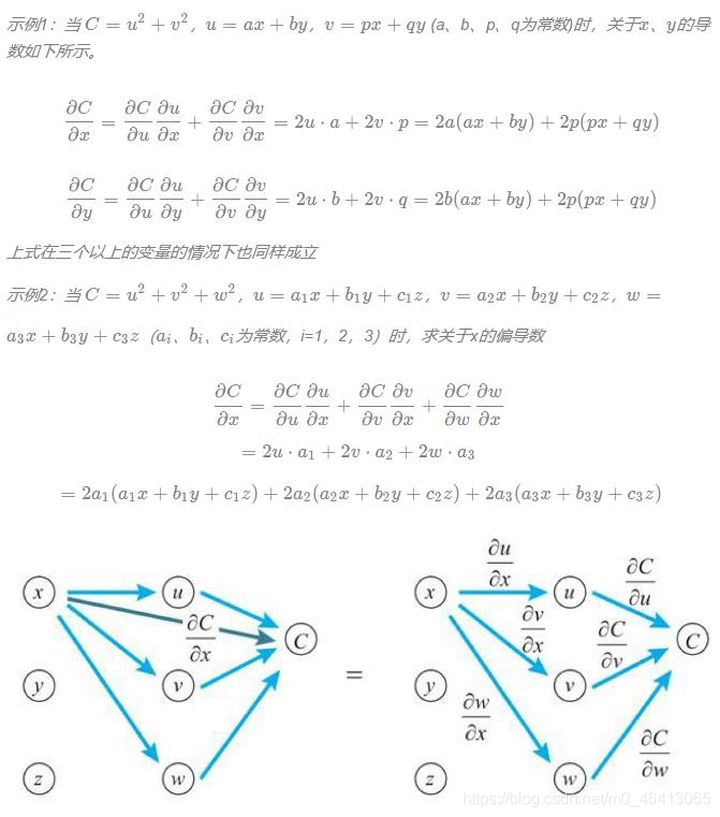
讓我們來看看兩個變數的情形,變數z為u、v的函式,如果u、v分別為x、y的函式,則z為x、y的函式,此時下方的多變數函式的鏈式法則成立,
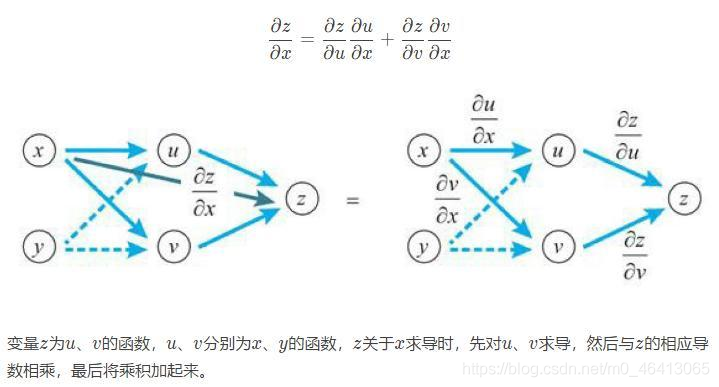
變數z為u、v的函式,u、v分別為x、y的函式,z關于x求導時,先對u、v求導,然后與z的相應導數相乘,最后將乘積加起來,
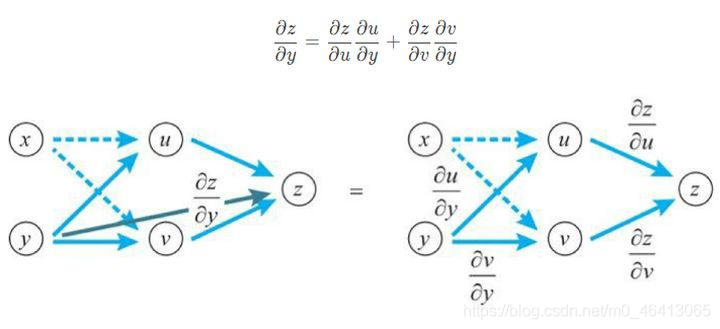
z關于y求導時,也是如此,下方式子依舊成立,
李宏毅老師回顧的Chain Rule試是這樣的:

對整個neural network,我們定義了?個loss function:
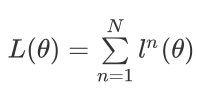
它等于所有training data的loss之和
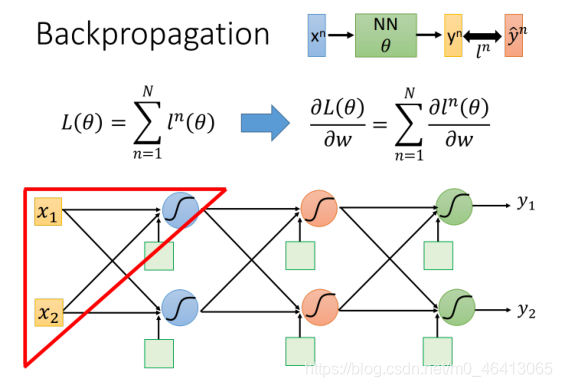
我們把training data?任意?個樣本點xn代到neural network??,它會output?個yn,我們把這個output跟樣本點本?的label標注的target
y
^
n
\hat{y}^n
y^?n作cross entropy,這個交叉熵定義了output 和target之間的距離 ,如果cross entropy?較?的話,說明output和target之間距離很遠,這個network的parameter的loss是?較?的,反之則說明這組parameter是?較好的然后summation over所有training data的cross entropy ln(θ),得到total lossL(θ) ,這就是我們的loss function,?這個L(θ)對某?個引數w做偏微分,運算式如下:
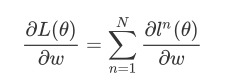
Backpropagation Mindmap(干貨!!!)
我把整個流程總結為如下思維導圖:
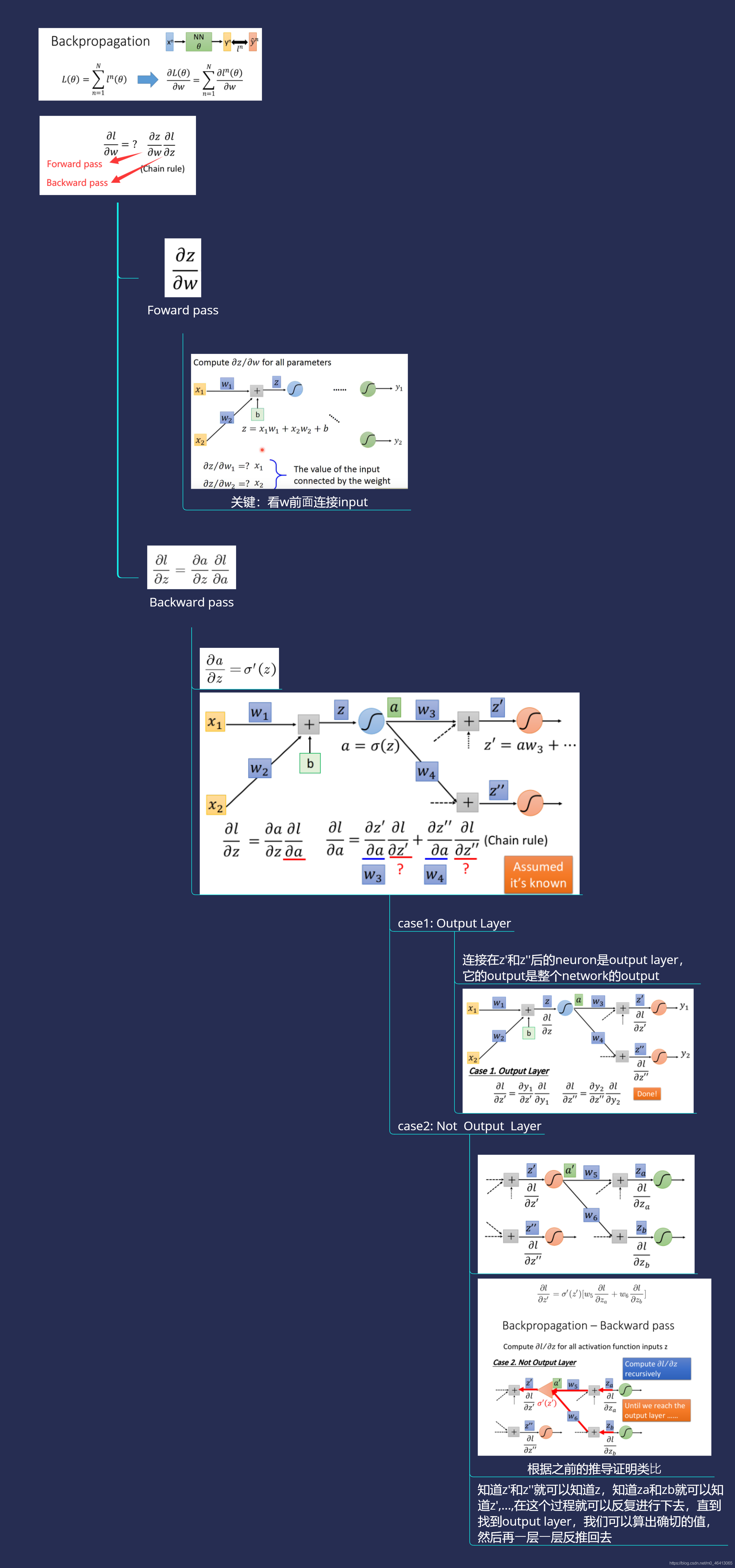
上面說到知道z’和z’‘就可以知道z,知道za和zb就可以知道z’,…,在這個程序就可以反復進行下去,直到找到output layer,我們可以算出確切的值,然后再?層?層反推回去,
但是轉念一想,每次要算?個微分的值,都要?路往后?,?直?到network的output,如果寫成運算式的話,?層?層往后展開,感徑訓是?個很可怕的式?,
但是!有沒有想過換?個?向計算會怎樣呢?
從output layer的 ? l ? z \frac{\partial l}{\partial z} ?z?l?開始算,你就會發現它的運算量跟原來的network的Feedforward path其實是?樣的,
假設現在有6個neuron,每?個neuron的activation function的input分別是z1、z2、z3、z4、z5、z6
,我們要計算l對這些z的偏微分,按照原來的思路,我們想要知道z1的偏微分,就要去算z3和z4的偏微分,想要知道z3和z4的偏微分,就?要去計算兩遍z5和z6的偏微分,因此如果我們是從z1、z2的偏微分開始算,那就沒有效率,
但是,如果反過來先去計算z5和z6的偏微分的話,這個process,就突然之間變得有效率起來了,
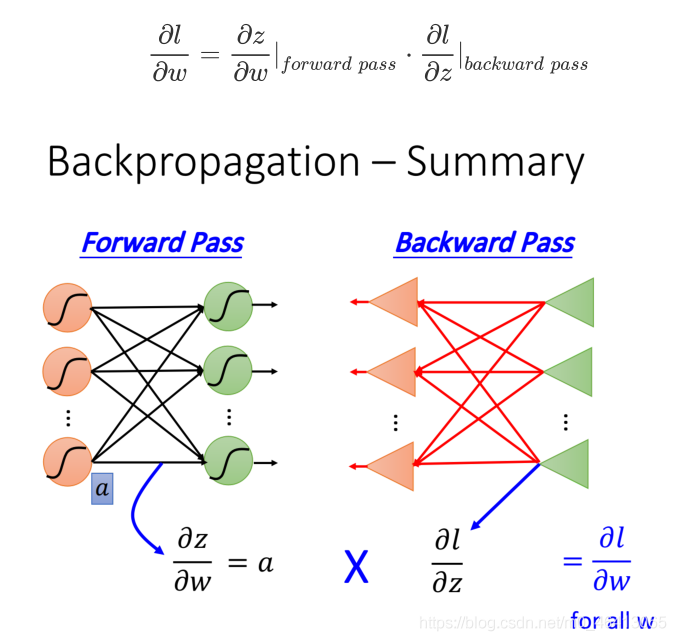
Summary
最后,我們來總結?下Backpropagation是怎么做的
-
Forward pass: 每個neuron的activation function的output,就是它所連接的weight的 ? z ? w \frac{\partial z}{\partial w} ?w?z?
-
Backward pass: 建?個與原來?向相反的neural network,它的三?形neuron的output就是 ? l ? z \frac{\partial l}{\partial z} ?z?l?
-
把通過forward pass得到的 ? z ? w \frac{\partial z}{\partial w} ?w?z?和通過backward pass得到的 ? l ? z \frac{\partial l}{\partial z} ?z?l?乘起來就可以得到l對w的偏微分
參考文章
Deep Learning 神經網路基礎
神經網路淺講:從神經元到深度學習
通俗理解神經網路之激勵函式(Activation Function)
深度學習數學基礎之鏈式法則
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/265634.html
標籤:AI
上一篇:(四 Hystrix 熔斷器 什么是熔斷器? 什么是Hystrix?為什么要熔斷器 Hystrix用來做什么? 作用是什么?)手摸手帶你一起搭建 Spring cloud 微服務 理論+實踐+決議