目錄
- 1:何為梯度下降
- 1.1 簡單描述
- 1.2 直觀描述
- 1.3 假設
- 2.符號說明
- 3.具體步驟
- 4.簡單的證明
- 5.優化
- 5.1 模型的缺點
- 5.1.1效率
- 5.1.2 準確度
- 5.1.3 具有迷惑性的平原
- 5.1.4 區域最優解
- 5.2 優化演算法
- 5.2.1 Adagrad
- 5.2.2 SGDM
- 5.2.3 Adam
- 參考文獻
1:何為梯度下降
1.1 簡單描述
通過迭代的思想解決函式求最值的問題(下文會以求最小值為例)
1.2 直觀描述
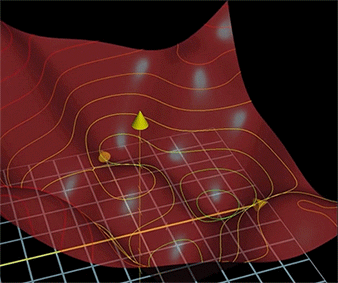
如上圖,從一個點出發,不斷的向能使函式值減小最快的方向移動點,直到找到最小值
1.3 假設
假設存在一個可微分函式 f ( x , y ) f(x,y) f(x,y),當然不僅僅局限于二次函式
2.符號說明
| 符號 | 意義 |
|---|---|
| η \eta η | 學習指數 |
| g i g_i gi? | d f d x i \frac{d f}{d x_i} dxi?df? |
| λ \lambda λ | 慣性系數 |
| β 1 \beta_1 β1? | 0.9 |
| β 2 \beta_2 β2? | 0.999 |
| ? \epsilon ? | 1 0 ? 8 10^{-8} 10?8 |
3.具體步驟
一:隨機取點
隨機在函式上取一點
(
x
0
,
y
0
)
(x_0,y_0)
(x0?,y0?)
二:反復迭代
x
1
=
x
0
?
η
?
?
f
?
x
∣
x
=
x
0
,
y
=
y
0
x_1=x_0-\eta* \left. \frac{\partial f}{\partial x} \right|_{x=x_0,y=y_0}
x1?=x0??η??x?f?∣∣∣?x=x0?,y=y0??
y
1
=
y
0
?
η
?
?
f
?
y
∣
x
=
x
0
,
y
=
y
0
y_1=y_0-\eta* \left. \frac{\partial f}{\partial y} \right|_{x=x_0,y=y_0}
y1?=y0??η??y?f?∣∣∣?x=x0?,y=y0??
x
2
=
x
1
?
η
?
?
f
?
x
∣
x
=
x
1
,
y
=
y
1
x_2=x_1-\eta* \left. \frac{\partial f}{\partial x} \right|_{x=x_1,y=y_1}
x2?=x1??η??x?f?∣∣∣?x=x1?,y=y1??
y
2
=
y
1
?
η
?
?
f
?
y
∣
x
=
x
1
,
y
=
y
1
y_2=y_1-\eta* \left. \frac{\partial f}{\partial y} \right|_{x=x_1,y=y_1}
y2?=y1??η??y?f?∣∣∣?x=x1?,y=y1??
…
三:結束迭代
結束迭代一般有2種條件,根據不同情況而定
1:規定一定的迭代次數,達到一定次數后結束迭代
2:定義一個合理的閾值,當連續多次迭代所得結果之間的差值小于該閾值時,迭代結束
(對于為什么要多次迭代,會在后面說明)
4.簡單的證明
假設 f ( x , y ) f(x,y) f(x,y)在點 ( x k , y k ) (x_k,y_k) (xk?,yk?)處 n n n階可導則 f ( x , y ) f(x,y) f(x,y)在 ( x k , y k ) (x_k,y_k) (xk?,yk?)的一個領域內有
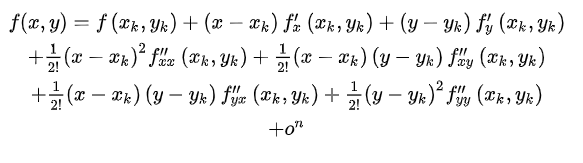
也就是泰勒公式,如果我們只考慮
(
x
k
,
y
k
)
(x_k,y_k)
(xk?,yk?)附加一個很小的領域,也就是能滿足
x
?
x
k
x-x_k
x?xk?和
y
?
y
k
y-y_k
y?yk?的值很小,那么可以不考慮泰勒展開中二次及二次以后的項,也就是只保留
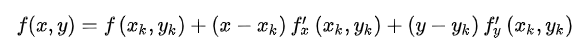
我們的目標是在這個很小的領域內找到使函式值減小最快的
(
x
,
y
)
(x,y)
(x,y)的移動方向,那么我們可以將問題簡化為在
(
x
?
x
k
)
2
+
(
y
?
y
k
)
2
≤
r
2
(x-x_k)^2+(y-y_k)^2\leq r^2
(x?xk?)2+(y?yk?)2≤r2(其中r很小)中研究
(
x
?
x
k
)
?
a
+
(
y
?
y
k
)
?
b
(x-x_k)*a+(y-y_k)*b
(x?xk?)?a+(y?yk?)?b隨
(
x
,
y
)
(x,y)
(x,y)的變化規律,其中a,b分表代表式中2個偏微分,其中
(
a
,
b
)
(a,b)
(a,b)是以
(
x
k
,
y
k
)
(x_k,y_k)
(xk?,yk?)為起點的一個向量,
(
x
?
x
k
,
y
?
y
k
)
(x-x_k,y-y_k)
(x?xk?,y?yk?)也是以
(
x
k
,
y
k
)
(x_k,y_k)
(xk?,yk?)為起點的一個向量,而我們要求的正好是這2個向量的乘積
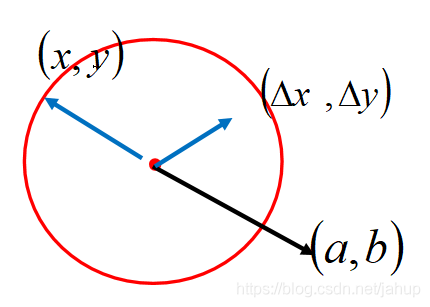
那么可得,當
(
x
,
y
)
(x,y)
(x,y)沿
(
a
,
b
)
(a,b)
(a,b)相反方向移動時
(
x
?
x
k
)
?
a
+
(
y
?
y
k
)
?
b
(x-x_k)*a+(y-y_k)*b
(x?xk?)?a+(y?yk?)?b減小的最快,也就是
f
(
x
,
y
)
f(x,y)
f(x,y)減小的最快,那么每次沿該方向迭代
(
x
,
y
)
(x,y)
(x,y)就能很快的找到此迭代所能找到的最小值,
x
1
=
x
0
?
η
?
?
f
?
x
∣
x
=
x
0
,
y
=
y
0
x_1=x_0-\eta* \left. \frac{\partial f}{\partial x} \right|_{x=x_0,y=y_0}
x1?=x0??η??x?f?∣∣∣?x=x0?,y=y0??
y
1
=
y
0
?
η
?
?
f
?
y
∣
x
=
x
0
,
y
=
y
0
y_1=y_0-\eta* \left. \frac{\partial f}{\partial y} \right|_{x=x_0,y=y_0}
y1?=y0??η??y?f?∣∣∣?x=x0?,y=y0??
上式中引入
η
\eta
η,是因為2個偏微分的值我們無法預測,如果過大會使得此次迭代2個坐標的位置改變較大,但證明成立的條件是在一個很小的領域內變動,故此處需要引入
η
\eta
η
5.優化

5.1 模型的缺點
5.1.1效率
x
1
=
x
0
?
η
?
?
f
?
x
∣
x
=
x
0
,
y
=
y
0
x_1=x_0-\eta* \left. \frac{\partial f}{\partial x} \right|_{x=x_0,y=y_0}
x1?=x0??η??x?f?∣∣∣?x=x0?,y=y0??
y
1
=
y
0
?
η
?
?
f
?
y
∣
x
=
x
0
,
y
=
y
0
y_1=y_0-\eta* \left. \frac{\partial f}{\partial y} \right|_{x=x_0,y=y_0}
y1?=y0??η??y?f?∣∣∣?x=x0?,y=y0??
從式中可以看出
η
\eta
η的大小會直接影響點的偏移量,如果偏移量過小,需要大量的迭代次數才能得到理想結果,也就是上圖藍色箭頭表示的情況
5.1.2 準確度
當 η \eta η取的偏大時,點的偏移量會增大,而當我們很接近最低點時,過大的 η \eta η可能會導致直接跳過了最低點,也就是上圖綠色和黃色的情況
5.1.3 具有迷惑性的平原
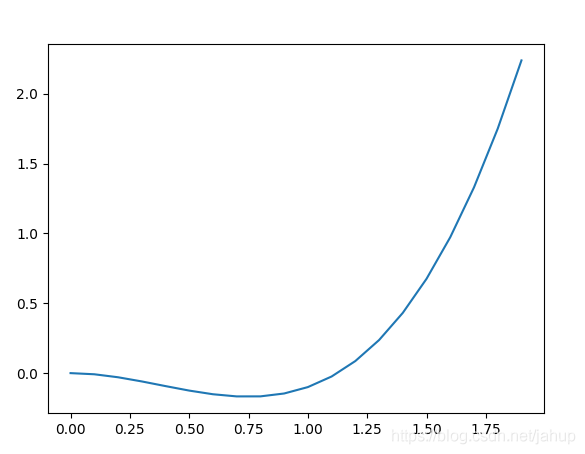
上文提過結束迭代的條件如下

如上圖函式所示,函式的左端是一段斜率極小的很平滑的曲線,下文簡稱為平原,當我們通過迭代使得點進入平原時,因為5.1.2所提及的原因,我們無法將
η
\eta
η設的太大,那么進入平原后,點的偏移量會大大減小,使得迭代的次數快速增加,對于結束迭代的條件1,我們可以通過犧牲效率提高迭代次數來避免最后結果落在平原.但對于條件2,因為平原偏移量可能非常的小,導致相鄰2次迭代結果的差可能低于閾值,所以我們通過多次迭代的差來判斷是否結束迭代,但這種方法只對較小的平原有用,對于較大的平原結果任然有可能落在平原.而且無論是對于條件1還是條件2在這種情況下效率都極低,
5.1.4 區域最優解
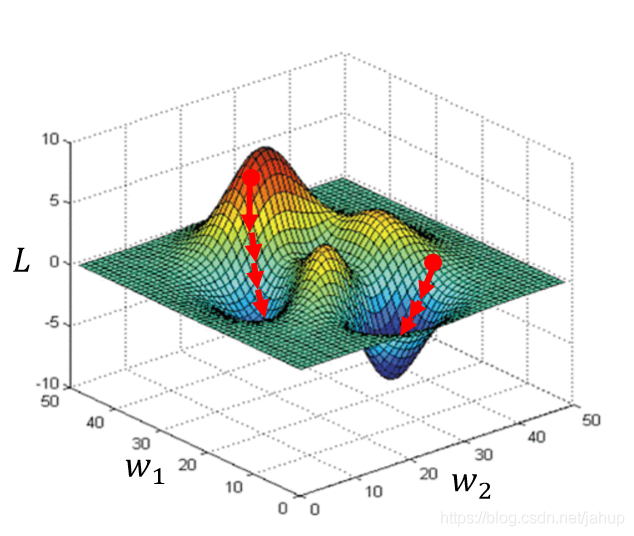
上圖很形象的說明了,迭代的起始點不同,可能會導致迭代的結果為區域最優解
5.2 優化演算法
對于上面的缺點,研究人員找出了一些優化方法,其能在一定程度上減弱這些缺點的影響
5.2.1 Adagrad
該模型對迭代式進行了一定程度上的改變(為了方便描述,這里以一元函式為例)
x
1
=
x
0
?
η
(
∑
k
=
0
0
(
g
k
)
2
)
?
g
0
x_1=x_0- \frac{\eta}{\sqrt(\sum_{k=0}^0 (g_k)^2)}*g_0
x1?=x0??(
?∑k=00?(gk?)2)η??g0?
x
2
=
x
1
?
η
(
∑
k
=
0
1
(
g
k
)
2
)
?
g
1
x_2=x_1- \frac{\eta}{\sqrt(\sum_{k=0}^1 (g_k)^2)}*g_1
x2?=x1??(
?∑k=01?(gk?)2)η??g1?
x
3
=
x
2
?
η
(
∑
k
=
0
2
(
g
k
)
2
)
?
g
2
x_3=x_2- \frac{\eta}{\sqrt(\sum_{k=0}^2 (g_k)^2)}*g_2
x3?=x2??(
?∑k=02?(gk?)2)η??g2?
…
x
i
=
x
i
?
1
?
η
(
∑
k
=
0
i
?
1
(
g
k
)
2
)
?
g
i
?
1
x_i=x_{i-1}- \frac{\eta}{\sqrt(\sum_{k=0}^{i-1} (g_k)^2)}*g_{i-1}
xi?=xi?1??(
?∑k=0i?1?(gk?)2)η??gi?1?
從式子可以看出 η ( ∑ k = 0 i ( g k ) 2 ) \frac{\eta}{\sqrt(\sum_{k=0}^i (g_k)^2)} ( ?∑k=0i?(gk?)2)η?的值隨著迭代的不斷增加而減小,也就是在迭代開始時點的偏移量較大,迭代次數越多,越接近最低點時,偏移量逐漸減小,這樣既提高了效率,也能保持一定的準確度
5.2.2 SGDM
該模型也是對迭代式進行了改變
v
0
=
0
v_0=0
v0?=0
v
1
=
λ
?
v
0
?
η
?
g
0
v_1=\lambda*v_0-\eta*g_0
v1?=λ?v0??η?g0?
x
1
=
x
0
+
v
1
x_1=x_0+v_1
x1?=x0?+v1?_
v
2
=
λ
?
v
1
?
η
?
g
1
v_2=\lambda*v_1-\eta*g_1
v2?=λ?v1??η?g1?
x
2
=
x
1
+
v
2
x_2=x_1+v_2
x2?=x1?+v2?
…
v
i
=
λ
?
v
i
?
1
?
η
?
g
i
?
1
v_i=\lambda*v_{i-1}-\eta*g_{i-1}
vi?=λ?vi?1??η?gi?1?
x
i
=
x
i
?
1
+
v
i
x_i=x_{i-1}+v_i
xi?=xi?1?+vi?
對于該模型,每一次計算此次移動的偏移量時,都會考慮到此前產生的偏移量,下文我們稱為慣性,這點有點類似物理學中的慣性,此時的運動狀態不僅僅受此時的受力情況影響,還受之前的運動狀態影響,引入這一點,使得模型與真實的情況更加類似,
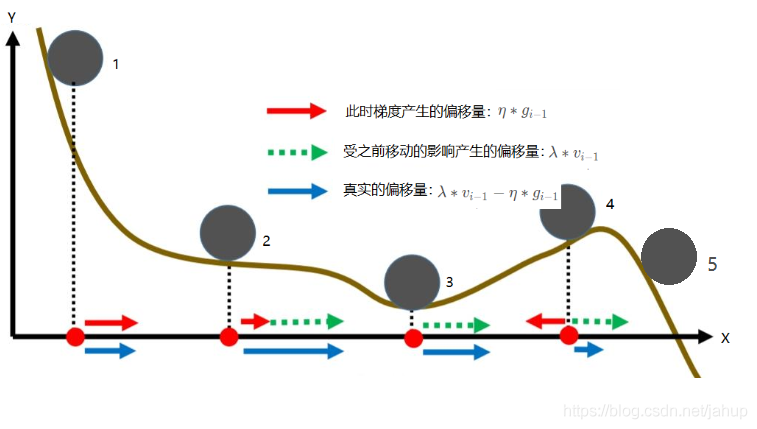
如上圖所示,引入慣性,可以在一定程度上解決因為平原導致的效率低下的問題,如球2所示,也能在一定程度上解決區域最優解的問題,如球3到球4到球5
5.2.3 Adam
該模型也是對迭代式進行了改變
m
0
=
g
0
m_0=g_0
m0?=g0?
v
0
=
g
0
2
v_0=g_0^2
v0?=g02?
m
0
′
=
m
0
1
?
β
1
0
m_0'= \frac{m_0}{1-\beta_1^0}
m0′?=1?β10?m0??
v
0
′
=
v
0
1
?
β
2
0
v_0'= \frac{v_0}{1-\beta_2^0}
v0′?=1?β20?v0??
x
1
=
x
0
?
η
(
x
0
′
)
+
?
?
m
0
′
x_1=x_0-\frac{\eta}{\sqrt(x_0')+\epsilon}*m_0'
x1?=x0??(
?x0′?)+?η??m0′?
m
1
=
β
1
?
m
0
+
(
1
?
β
1
)
?
g
1
m_1=\beta_1*m_0+(1-\beta_1)*g_1
m1?=β1??m0?+(1?β1?)?g1?
v
1
=
β
2
?
v
0
+
(
1
?
β
2
)
?
g
1
2
v_1=\beta_2*v_0+(1-\beta_2)*g_1^2
v1?=β2??v0?+(1?β2?)?g12?
m
1
′
=
m
1
1
?
β
1
1
m_1'= \frac{m_1}{1-\beta_1^1}
m1′?=1?β11?m1??
v
1
′
=
v
1
1
?
β
2
1
v_1'= \frac{v_1}{1-\beta_2^1}
v1′?=1?β21?v1??
x
2
=
x
1
?
η
(
v
1
′
)
+
?
?
m
1
′
x_2=x_1-\frac{\eta}{\sqrt(v_1')+\epsilon}*m_1'
x2?=x1??(
?v1′?)+?η??m1′?
…
m
i
=
β
1
?
m
i
?
1
+
(
1
?
β
1
)
?
g
i
m_i=\beta_1*m_{i-1}+(1-\beta_1)*g_{i}
mi?=β1??mi?1?+(1?β1?)?gi?
v
i
=
β
2
?
v
i
?
1
+
(
1
?
β
2
)
?
g
i
2
v_i=\beta_2*v_{i-1}+(1-\beta_2)*g_i^2
vi?=β2??vi?1?+(1?β2?)?gi2?
m
i
′
=
m
i
1
?
β
1
i
m_i'= \frac{m_i}{1-\beta_1^i}
mi′?=1?β1i?mi??
v
i
′
=
v
i
1
?
β
2
i
v_i'= \frac{v_i}{1-\beta_2^i}
vi′?=1?β2i?vi??
x
i
+
1
=
x
i
?
η
(
v
i
′
)
+
?
?
m
i
′
x_{i+1}=x_i-\frac{\eta}{\sqrt(v_i')+\epsilon}*m_i'
xi+1?=xi??(
?vi′?)+?η??mi′?
其中引數的值在符號說明給出

Adam可以說是目前,同類演算法中綜合表現最出色的演算法,被廣泛的應用于翻譯等諸多場合
參考文獻
https://blog.csdn.net/hyg1985/article/details/42556847
https://www.zhihu.com/question/305638940
https://blog.csdn.net/luoxuexiong/article/details/90412213
https://blog.csdn.net/zb1165048017/article/details/78392623?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.baidujs&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.baidujs
https://zh.wikipedia.org/zh-hans/%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D%E6%B3%95
https://baike.baidu.com/item/%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D/4864937?fr=aladdin
https://www.youtube.com/watch?v=Syom0iwanHo

--某科學的超電磁炮
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/266321.html
標籤:AI
上一篇:如何使用idea